无相关标签的精确零镜头密集检索
摘要
虽然密集检索已经被证明是跨任务和跨语言的有效和高效的,但是当没有可用的相关性标签时,仍然难以创建有效的完全零触发密集检索系统。在本文中,我们认识到零触发学习和编码相关性的困难。相反,我们建议以假设文档嵌入(HyDE)为中心。给定一个查询,HyDE第一个零触发提示一个遵循查询的语言模型(例如,指示GPT)生成一个假设文档。该文档捕获了相关性模式,但它是“假的”,可能包含幻觉。然后,无监督的对比学习编码器(例如,Contriever)将文档编码为嵌入向量。该向量标识语料库嵌入空间中的邻域,基于向量相似性从该邻域检索相似的真实的文档。第二步将生成的文档与实际的语料库进行比较,编码器的密集瓶颈过滤掉了幻觉。我们的实验表明,HyDE显着优于最先进的无监督密集检索器Contriever,并在各种任务(例如网络搜索,QA,事实验证)和非英语语言(例如,瑞士法郎、瑞士法郎、西班牙法郎、西班牙法郎)
一、引言
密集检索(Lee等人,2019年; Karpukhin等人,2020),使用语义嵌入相似性检索文档的方法,已被证明在Web搜索,问答和事实验证等任务中是成功的。各种方法,如负面挖掘(Xiong et al.,2021年; Qu等人,2021)、蒸馏(Qu等人,2021; Lin等人,2021年b;霍夫施泰特等人,2021),检索特定的预训练(Izacard等人,2021;高和Callan,2021; Lu等人,2021; Gao和Callan,2022; Liu和Shao,2022)和缩放(Ni等人,2022)已经被提出来提高监督密集检索模型的有效性。
然而,零炮密集检索仍然是困难的。最近的许多工作考虑了替代的迁移学习设置,其中密集检索器在高资源数据集上进行训练,然后在来自不同领域的查询上进行评估。MS MARCO(Bajaj等人,2016),一个包含大量人工判断的查询-文档对的数据集,是最常用的。然而,正如Izacard等人(2021)所指出的那样,在实践中,不能总是假设存在如此大的数据集。此外,MS MARCO限制了商业用途,不能在各种现实世界的搜索场景中采用。
在本文中,我们的目标是建立有效的完全零射击密集检索系统,不需要相关监督,开箱即用,并在新兴的搜索任务中进行概括。由于监督是不可用的,我们从检查自我监督的表示学习方法开始。现代深度学习支持两种截然不同的方法。在标记级,在大型语料库上预先训练的生成式大型语言模型(LLM)已经显示出强大的自然语言理解(NLU)和生成(NLG)能力(Brown等人,2020年; Chen等人,2021年; Rae等人,2021年;霍夫曼等人,2022年; Thoppilan等人,2022年;乔杜里等人,2022年)的报告。在文档级,用对比目标预先训练的文本(块)编码器学习将文档相似性编码成内积(Izacard等人,2021年; Gao和Callan,2022年)。
除此之外,还借用了来自LLM的一个额外的见解:进一步训练以遵循指令的LLM可以零触发概括为各种不可见的指令(Ouyang等人,2022年; Sanh等人,2022年; Min等人,2022年; Wei等人,2022年)的报告。特别是,InstructGPT表明,使用少量数据,GPT-3(Brown等,2020)模型可以与人类意图保持一致,以忠实地遵循指令。
有了这些成分,我们建议通过假设文档嵌入(HyDE)进行枢轴旋转,并将密集检索分解为两个任务:由遵循语言模型执行的生成任务和由对比编码器执行的文档文档相似性任务(图1)。首先,我们将查询馈送到生成模型,并指示它“编写一个回答问题的文档”,即,一份假想的文件我们期望生成过程通过提供示例来捕获“相关性”;生成的文档不是真实的,可能包含事实错误,但“像”相关文档。在第二步中,我们使用一个无监督的对比编码器将该文档编码成一个嵌入向量。在这里,我们希望编码器的密集瓶颈作为一个有损压缩器,其中额外的(幻觉)细节从嵌入中过滤掉。我们使用这个向量来搜索语料库嵌入。检索并返回最相似的真实的文档。检索利用在对比预训练阶段学习的内积中编码的文档-文档相似性。
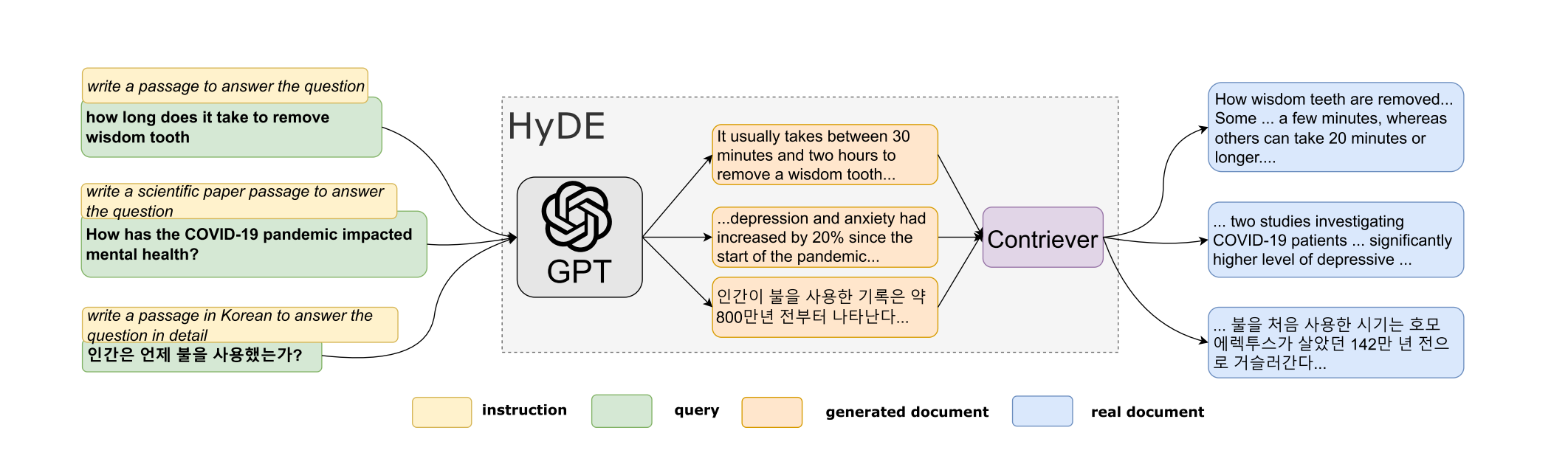
图1:HyDE模型的示意图。显示文档片段。HyDE服务于所有类型的查询,而不改变底层的InstructGPT和Contriever/mContriever模型。
注意,有趣的是,使用我们提出的HyDE因子分解,查询文档相似性分数不再显式建模或计算。相反,检索任务被转换为两个任务(NLU和NLG)。构建HyDE不需要监督,并且在这项工作中没有训练新的模型:生成模型和对比编码器都是“开箱即用”的,没有任何调整或修改。
在我们的实验中,我们表明使用InstructGPT的HyDE(Ouyang et al.,2022)和Contriever(Izacard等人,2021年)“按现状”的表现明显优于之前的最先进水平在11个查询集上的Contriever-only zero-shot模型,涵盖网络搜索,问答,事实验证等任务,以及斯瓦希里语,韩语,日语和孟加拉语等语言。
二、相关工作
自监督学习
这种方法是NLP中最流行的主题之一(Devlin等人,2019年; Brown等人,2020年)的报告。像BERT这样的屏蔽语言模型(Devlin等人,2019年)已经展示了强大的文本表示能力。具有数千亿个参数的大型语言模型(LLM)已经在跨各种任务的少触发和零触发设置下显示出显著的泛化能力(Brown等人,2020年;乔杜里等人,2022年)的报告。尽管它们获得了广泛的成功,但在LLM中的零次或少次机会学习很少直接用于排序(Liang等人,2022年),唯一的例外是Sachan等人(2022年),其执行零镜头重新排序。
除了语言建模之外,对比学习方法帮助神经语言模型学习表示块(例如,句子或段落)作为嵌入向量。在不需要任何监督的情况下,这种对比编码器可以将同质文本块嵌入到矢量空间中,在该矢量空间中,类似内积的某种距离函数捕获相似性(Gao等人,2021年; Izacard等人,2021年)的报告。
遵循指令模型
在LLM出现之后不久,几组研究人员发现,在由指令组成的数据上训练的LLM及其执行可以零触发概括以利用新指令来执行新任务(Ouyang等人,2022年; Sanh等人,2022年; Min等人,2022年; Wei等人,2022年)的报告。这可以使用标准的有监督的序列到序列学习技术或更有效的方法利用来自人类反馈的强化学习来完成。
与我们同时,Asai et al.(2022)和Su et al.(2022)研究了具有指令的任务感知检索。他们对密集编码器进行了微调,这些编码器还可以对查询前的特定任务指令进行编码。相比之下,我们使用无监督编码器,并使用生成LLM处理不同的任务,而无需执行任何微调。
密集检索
密集向量空间中的文档检索(Lee等,2019年; Karpukhin等人,2020)已经在预训练的Transformer语言模型出现之后被广泛研究(Devlin等人,2019年度)。研究人员已经研究了度量学习问题,例如训练损失(Karpukhin等,2020)和阴性采样(Xiong等人,2021年; Qu等人,2021),并且还引入了蒸馏(Qu等人,2021; Lin等人,2021年b;霍夫施泰特等人,2021年)的报告。后来的工作研究了专门用于检索的语言模型的第二阶段预训练(Izacard等人,2021年; Gao和Callan,2021年; Lu等人,2021年; Gao和Callan,2022年; Liu和Shao,2022年)以及模型缩放(Ni等人,2022年)的报告。所有这些方法都依赖于有监督的对比学习。
密集检索的流行可部分归因于在非常大(十亿)规模下的有效最小内积搜索(MIPS)中的补充研究(约翰逊等人,2021年)的报告。
零炮密集检索
Thakur et al.(2021)在经验上突出了零射(密集)检索任务对神经检索社区的重要性;他们的BEIR基准包括各种检索任务。该论文和许多后续研究考虑了迁移学习设置,其中密集检索器首先使用不同的和大的手动标记的数据集进行训练,即MS MARCO(Thakur等人,2021; Wang等人,2022年; Yu等人,2022年)的报告。
然而,如Izacard等人(2021)所述,很少能假设如此大的采集量。因此,在本文中,我们研究的问题,建立有效的密集检索系统没有任何相关标签。与他们的工作类似,我们也不假设在训练期间可以访问测试语料库。这是一个更现实的设置,更好地符合新兴的零镜头搜索需求。
根据Sachan等人(2022)的定义,我们的设置是无监督的。与此类似,我们也依赖于指令跟随大模型执行搜索任务的能力。在本文的其余部分中,我们不会对零次和无监督进行精确区分,并将互换使用这些术语来描述我们的设置:我们假设不存在测试时查询,文档或大规模监督。
自动贴标
与我们处理新兴的看不见的搜索任务的设置相反,几个先前的工作已经研究了构建密集搜索系统,其中存在文档集合但是没有相关性标签可用。虽然直观的默认方法是从人类注释者收集相关性判断(Bajaj等人,2016年; Kwiatkowski等人,2019年; Clark等人,2020; Craswell等人,2020),Wang等人(2022)提出了一种由问题生成组成的流水线(Ma等人,2021;刘易斯等人,2021),负面挖掘和使用大型语言模型的自动标记,并已证明它是一种有效的替代方案。Dai等人(2023)表明,流水线可以从使用更大的千亿级语言模型中受益。Bonifacio等人(2022)表明,类似的流水线可用于训练重新排序器。
生成检索
生成性搜索是使用神经生成模型作为搜索索引的一类新的检索方法(Metzler等人,2021年; Tay等人,2022年;贝维拉夸等人,2022年; Lee等人,2022年)的报告。这些模型使用(受约束的)解码来生成直接映射到真实的文档的文档标识符。它们必须通过对相关性数据的特殊训练过程;有效的搜索可能还需要使用新颖形式的搜索索引结构(贝维拉夸等人,2022年; Lee等人,2022年)的报告。相比之下,我们的方法使用标准的MIPS索引,不需要训练数据。我们的生成式模型生成一个中间的假设文档。
三、方法论
在本节中,我们首先正式定义(零镜头)密集检索的问题。然后我们将介绍如何设计HyDE来解决这个问题。
3.1预赛
密集检索模型的目标是捕获查询和文档之间的相似性与内积相似。给定查询q和文档d,该方法使用两个编码器函数encq和encd(可能相同)来映射两个文本分段为D维向量vq和vd,其内积被用作用于捕获相关性的相似性度量:
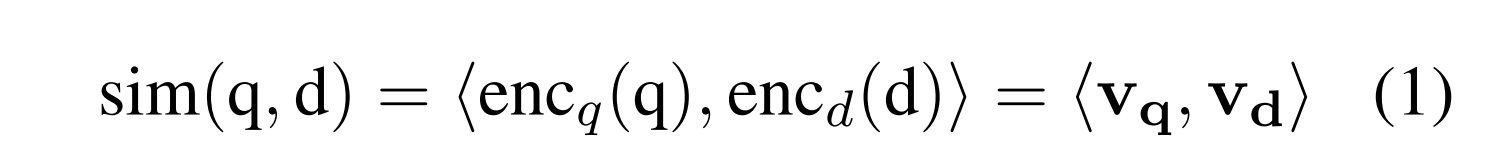
对于零镜头检索,我们考虑L个查询集Q1,Q2,.,QL和我们搜索的相应语料库,文档集D1、D2、...、DL.将来自第i个集合查询集Qi的第j个查询表示为qij。我们需要完全定义编码器encq和encd,而不访问任何查询集Qi、文档集Di或任何相关性判断rij。
zero-shot密集检索的困难恰恰在于等式1:它需要学习两个嵌入函数(分别针对查询和文档)到同一个嵌入空间中,其中内积捕获相关性。没有相关性判断和/或分数作为训练数据,学习变得困难。
3.2 HyDE
HyDE规避上述学习的挑战,执行搜索的只有文档嵌入空间,捕捉文档-文档的相似性。这可以使用无监督对比学习技术(Izacard等人,2021; Gao等人,2021年; Gao和Callan,2022年)。我们将文档编码器encd直接设置为对比编码器enccon:
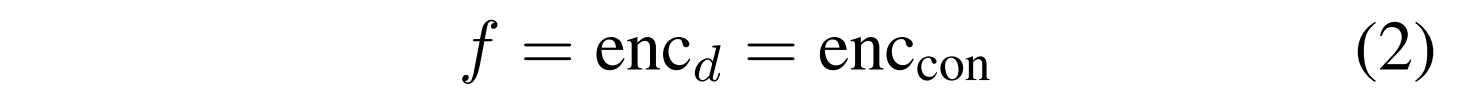
为简单起见,该函数被表示为f。这个无监督的对比编码器将被所有传入的文档共享。
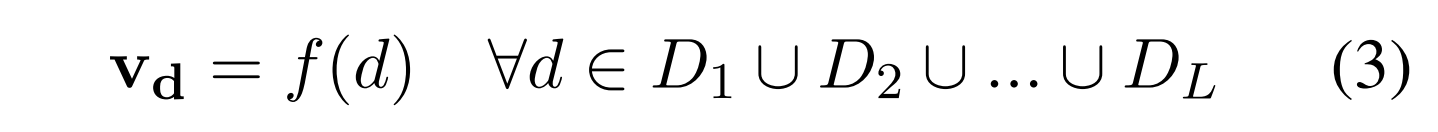
为了构建查询向量,我们还考虑了一个遵循查询的LM,即InstructLM。它接受一个查询q和一个文本指令INST,并遵循它们来执行由INST指定的任务。为简单起见,表示为:

现在,我们可以使用g将查询映射到“假设”文档,方法是从g中采样,将INST设置为“编写一个回答问题的段落”(或类似的提示)。
我们要强调的是,生成的文档不是真实的。事实上,它可以而且很可能是毫无根据的,患有幻觉(Brown等人,2020年; Thoppilan等人,2022年)的报告。我们只需要“假”文档来捕获相关性模式。这是通过生成文档来完成的,即,并提供了一些例子。重要的是,这里我们将相关性建模从表示学习模型卸载到NLG模型,该模型明显更容易、自然和有效地进行概括(Brown等人,2020年;欧阳等人,2022年)的报告。生成示例也可以替代相关性分数的显式建模。
现在,我们可以使用文档编码器f对生成的文档进行编码。具体地说,对于来自查询集合Qi的某个查询qij,我们可以使用一个指令Qij和compute:
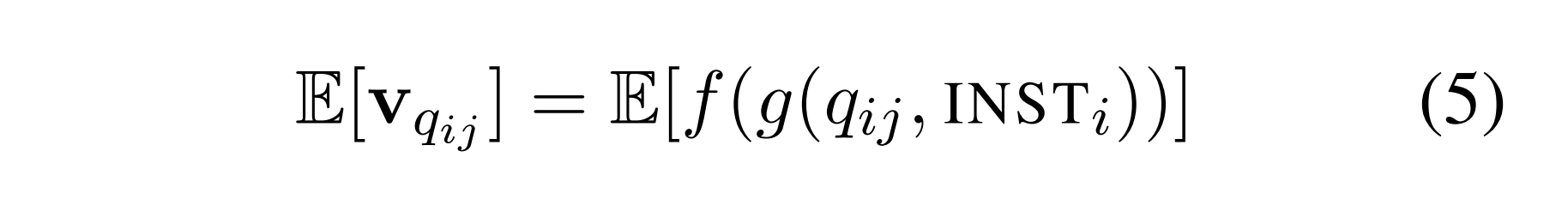
形式上,g定义了基于链式规则的自然语言序列上的概率分布。在本文中,我们只考虑期望,假设vqij的分布是单峰的。我们通过从g,[k d1,k d2,...,d [N]评估了等式5:
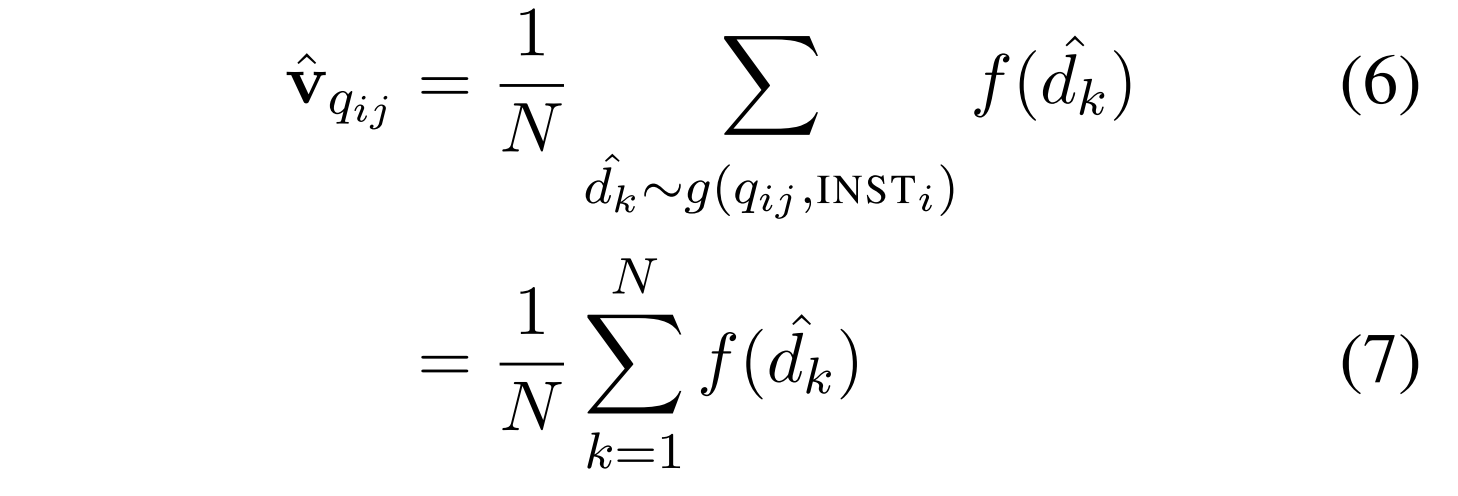
我们还将查询视为一个可能的假设:
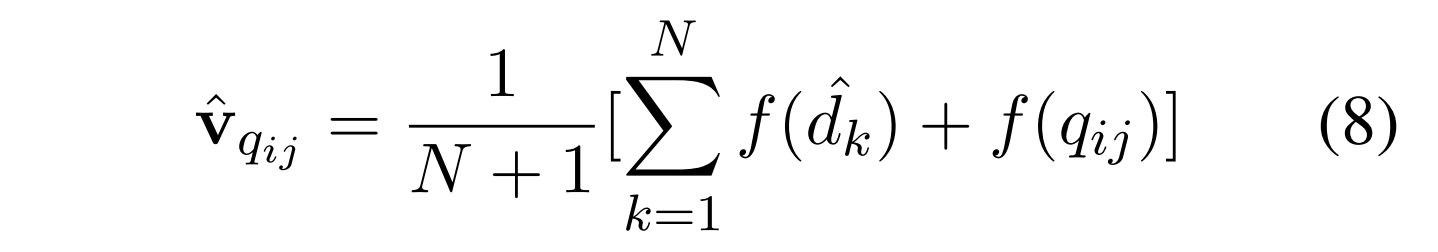
内积是在所有文档向量的集合和所有文档向量的集合之间计算的:
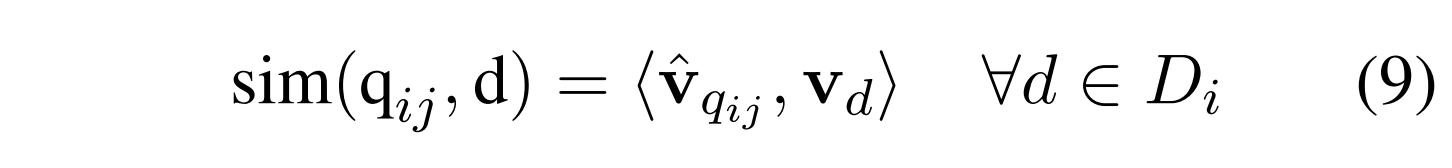
将检索最相似的文档。这里,编码器函数f用作有损压缩器,其输出密集向量,其中额外细节被过滤并被排除在向量之外。它进一步将假设向量”基于“实际语料库和真实的文档。完整的HyDE方法如图1所示。
四、实验
在本节中,我们将讨论如何实现HyDE,并将其作为一个零命中开箱即用的搜索系统进行测试。我们展示了HyDE在基础无监督密集编码器上的改进程度,以及它与具有丰富监督的模型的比较。
4.1设置
实现
我们的HyDE方法可以使用任何一对指令遵循语言模型和对比文本编码器来实现。不失一般性,我们挑选当代的和广泛采用的模型:我们使用InstructGPT来实现HyDE,InstructGPT是来自Instruction系列的GPT-3模型(Ouyang等人,2022)2和Contriever模型变体(Izacard等人,2021年)的报告。我们使用Izacard et al.(2021)设计的仅英语的Contriever模型进行英语检索任务,并使用多语言的mContriever进行非英语任务。InstructGPT模型适用于所有任务。我们使用OpenAI API从InstructGPT中采样,对于开放式生成,默认温度为0.7。我们使用Pyserini工具包进行了检索实验(Lin等人,2021年a)。
数据集
我们希望证明HyDE是一种有效的开箱即用的解决方案,适用于各种搜索任务。值得注意的是,由于我们的生成模型和编码器模型都没有学习任何搜索任务的知识,我们可以使用任何测试集合来评估HyDE处理不同搜索需求的能力。
我们首先考虑一般的Web测试集合。我们使用来自TREC DL19数据(Craswell等人,2020年)和DL20(Craswell等人,2021),其基于MS MARCO数据集(Bajaj等人,(2016年版)。我们报告了官方指标、mAP、nDCG@10和Recall@1k。
除了网络集合,我们使用一组七个低资源检索数据集,包括来自BEIR的不同主题和格式(Thakur et al.,2021年),包括Scifact(科学论文摘要; Wadden等人,2020),Arguana(参数检索; Wachsmuth et al. 2018),TREC-COVID(COVID 19科学论文; Voorhees等人,2020),FiQA(金融文章;马亚等人,2018),DBPedia(实体检索; Hasibi et al. 2017),TREC-新闻(新闻文章; Soboroff et al. 2019),气候发烧(气候事实验证; Diggelmann et al. 2020)。我们报告官方指标,nDCG@10和Recall@100。
最后,我们对HyDE在非英语检索上的应用进行了测试。为此,我们考虑来自TyDi先生的斯瓦希里语、韩语、日语和孟加拉语(Zhang等,2021),从TyDi QA构建的开放检索数据集(Clark等人,2020年)的报告。我们报告了官方指标MRR@100。
我们对每个数据集使用不同的指令。它们共享类似的结构,但具有不同的提示来控制生成的假设文档的确切形式。这些说明可在A.1小节中找到。
比较系统
两个Contriever模型变体,Contriever和mContriever,是我们的主要比较点。使用无监督的对比学习对它们进行训练。HyDE使用Contriever和mContriever作为编码器,因此与它们共享完全相同的嵌入空间。唯一的区别是查询向量的构建方式。通过这些比较,我们可以很容易地检查HyDE的影响。还包括传统的基于启发式的词汇检索器BM 25,在许多情况下,其已经被显示(令人惊讶地)比先前的零击方法更有效(Thakur等人,2021年; Izacard等人,2021年)的报告。
几个系统,涉及微调大量相关性数据作为参考。我们考虑在MS MARCO上微调并从BEIR论文中跨域DPR和ANCE转移的模型。对于多语言检索,我们包括来自TyDi先生论文的mDPR模型和来自Contriever论文的MS MARCO微调mBERT和XLM-R。
我们还包括最先进的迁移学习模型:在MS MARCO上微调的Contriever和mContriever,分别表示为Contriever-ft和mContriever-ft。这些模型是HyDE基本编码器的微调版本。他们已经通过了最先进的检索模型训练管道,该管道涉及第二阶段检索特定的预训练(Lee等人,2019)和几轮微调(Qu等人,2021年);这些应该被认为是“经验上限”方面的现代最佳实践的可实现性。假定可以访问测试文档的其他模型并没有被考虑因为和我们的设置不一样。我们承认测试文档上的人工和/或自动标记与零触发系统相比可以提高性能(Wang等人,2022年)的报告。然而,这样的设置以牺牲系统的灵活性和通用性为代价来获得性能。
4.2网络搜索
在表1中,我们显示了TREC DL19和TREC DL20的检索结果。我们看到HyDE为Contriever带来了相当大的改进,包括精度导向和召回指标。虽然无监督的Contriever可能不如词法BM25方法,但HyDE的性能远远优于BM25。
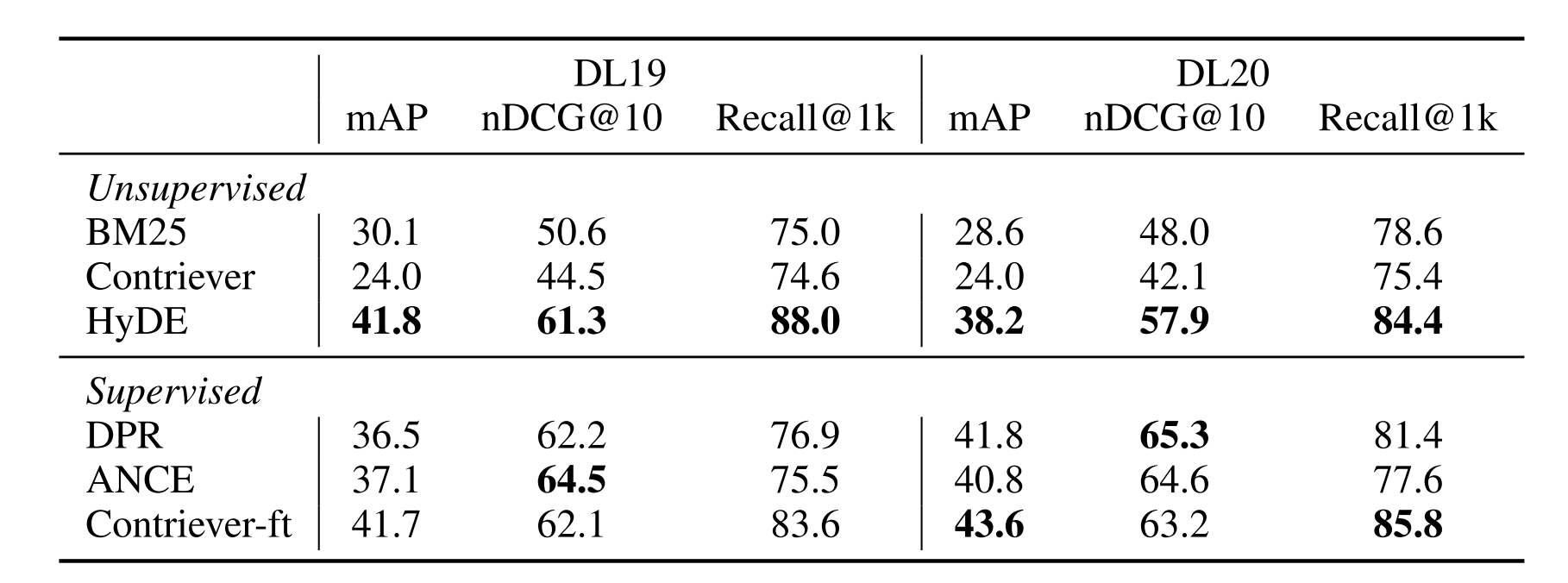
表1:DL 19/20的网络检索结果。表现最好的w/o相关性和整体系统用粗体标记。DPR,ANCE和Contriever-ft是在MS MARCO训练数据上进行微调的域内监督模型。
即使与微调模型相比,HyDE仍然具有竞争力。请注意,TREC DL 19/20是在MS MARCO上定义的搜索任务,所有经过微调的模型都得到了大量的监督。在TREC DL 19上,HyDE显示出与Contriever-ft相当的mAP和nDCG@10以及最佳Recall@1k。在DL 20上,HyDE的mAP和nDCG@10比Contriever-ft低约10%,但与Recall@1k相似。与HyDE相比,ANCE模型显示出更好的nDCG@10数字,但召回率较低,这表明它可能偏向于查询和/或相关文档的子集。
4.3低资源检索
在表2中,我们显示了从BEIR中选择的低资源任务的检索结果。与网络搜索类似,HyDE在nDCG@10和Recall@100方面再次为Contriever带来了全面的大幅改进。HyDE只在一个数据集TREC-COVID上被BM 25超过,但其在nDCG@10上仅略优于;相比之下,仅基础Contriever模型的表现就差了50%以上
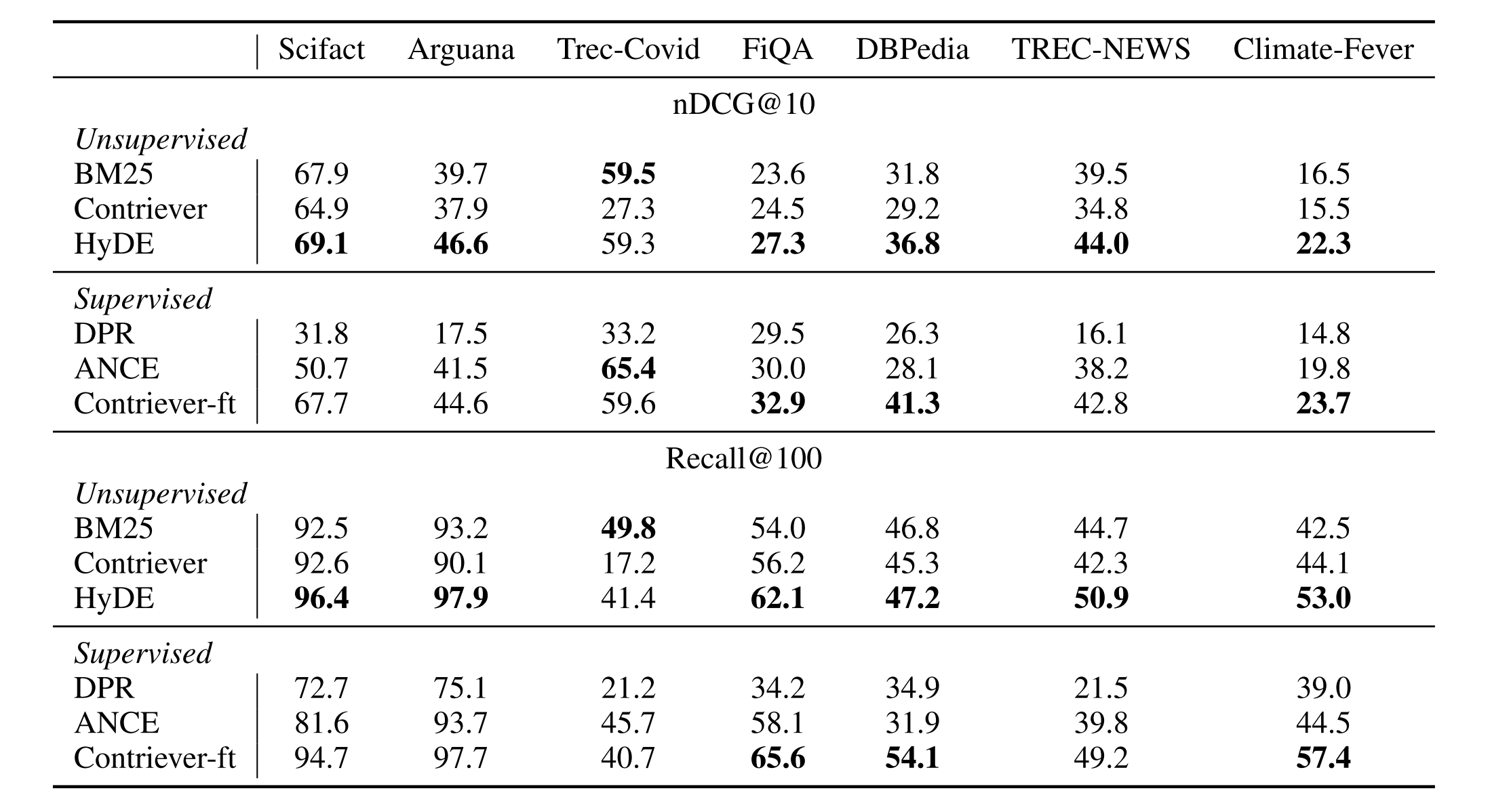
表2:来自BEIR的低资源任务的选择结果。表现最好的w/o相关性和整体系统用粗体标记
我们还观察到,HyDE表现出强大的性能相比,微调模型。我们的方法通常表现出比ANCE和DPR更好的性能,尽管这两个模型在MS MARCO上进行了微调,并且ANCE还利用了硬否定挖掘技术。Contriever-ft在FiQA和DBPedia上表现出了非平凡的性能优势。这涉及分别收回财务员额和实体。我们认为,性能差异可以归因于说明不够规范;更详细的提示可能会有所帮助。
4.4多语言检索
多语言设置给HyDE带来了几个额外的挑战。小的对比编码器随着语言数量的增加而饱和(Conneau等人,2020年; Izacard等人,2021年)的报告。与此同时,我们的生成式LLM面临着相反的问题:由于语言没有英语或法语那样高的资源,LLM过度参数化并因此训练不足(Hoffmann等人,2022年)的报告。
尽管如此,在表3中,我们仍然发现HyDE能够改进mContriever模型。它可以超越非Contriever模型微调和转移从MS MARCO。另一方面,我们确实观察到HyDE和微调mContriever-ft之间的一些差距。由于HyDE和mContriever-ft使用类似的对比编码器,我们假设这是因为我们考虑的非英语语言在预训练和预防学习阶段都训练不足。
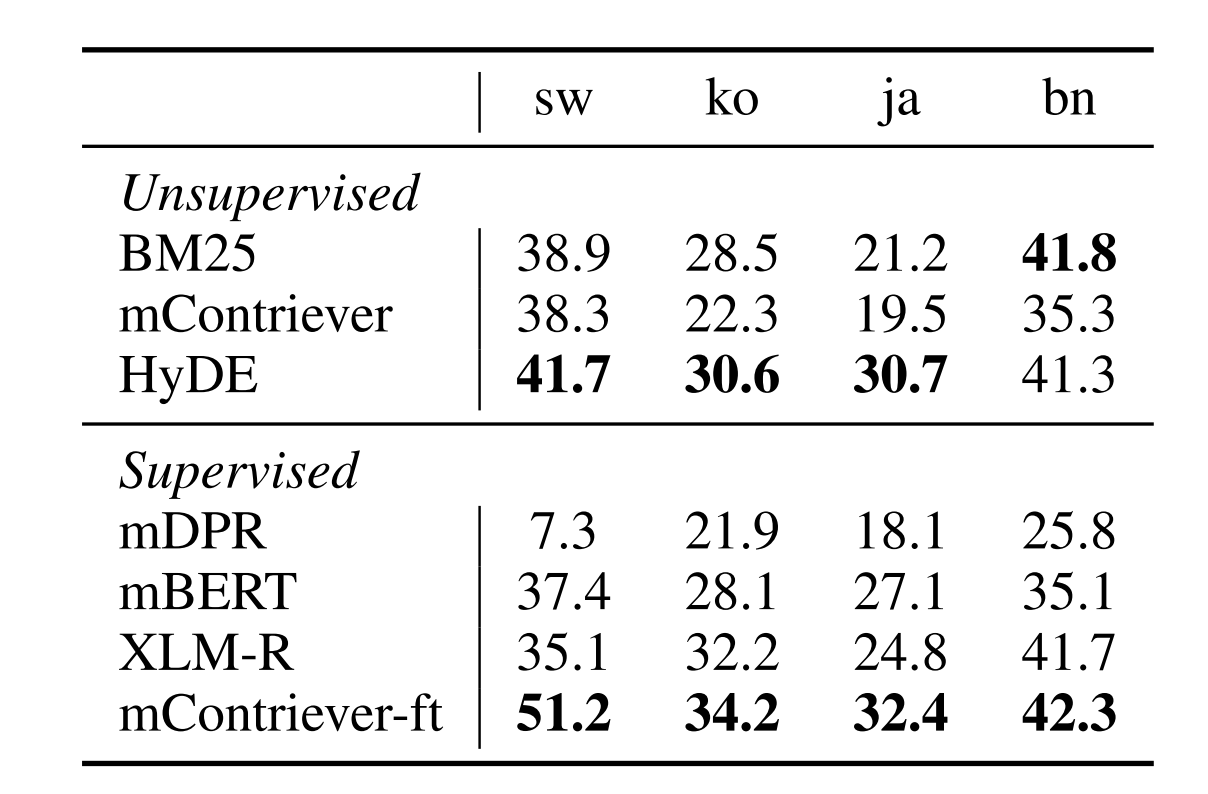
表3:关于TyDi先生的MRR@100的结果。表现最好的无监督和整体系统标记为粗体。
五、分析
生成式LLM和对比式编码器构成了HyDE的两个核心部件。在本节中,我们将研究改变其实现的影响。特别是,我们考虑较小的语言模型(LM),LM没有指令遵循和微调编码器。我们还展示了一种可视化和更好地理解HyDE的方法。
5.1不同生成模型的影响
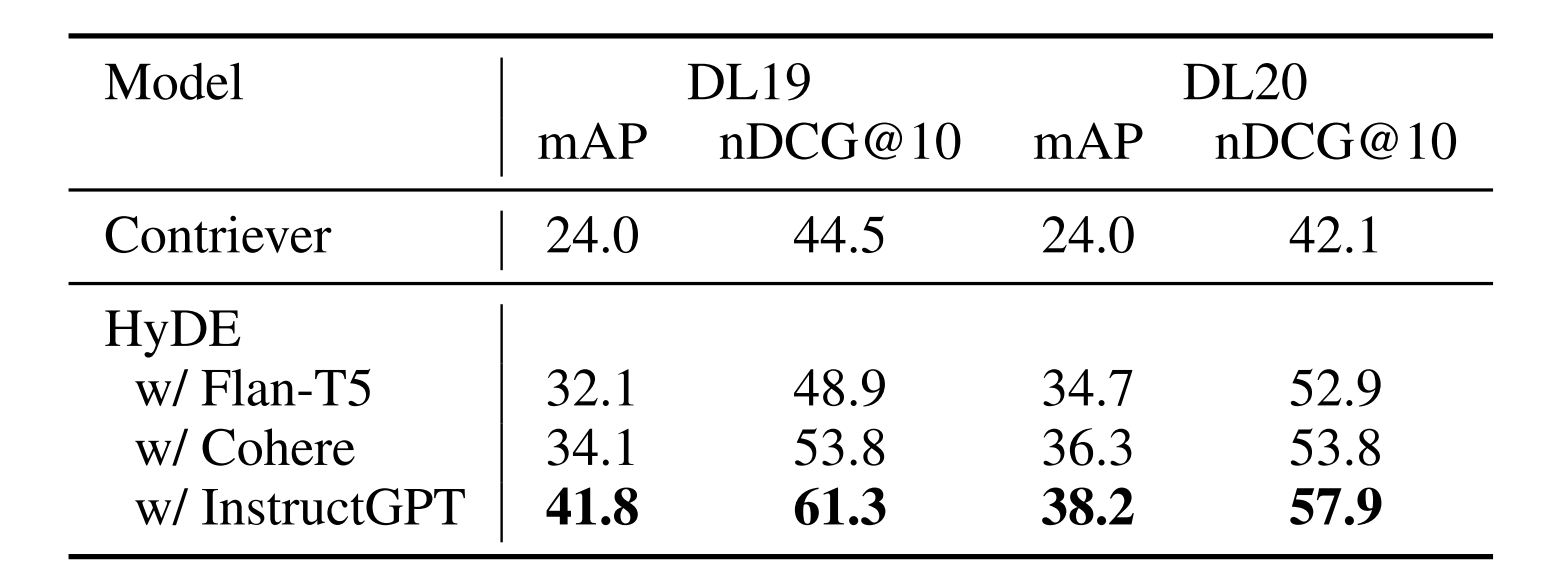
在表4中,我们展示了HyDE使用的其他解释性语言模型。特别地,我们考虑520亿参数相干模型(command-xlarge-20221108)和110亿参数FLAN模型(FLAN-T5-xxl)(Wei等人,一般来说,我们观察到所有模型都会对无监督Contriever带来改进,更大的模型会带来更大的改进。在我们工作的时候,凝聚模型仍然是实验性的,没有太多的细节。我们只能初步假设,训练技巧可能也在表现差异中发挥了一定作用。
表4:TREC DL 19/20上的nDCG@10比较了改变不同指令LM对无监督Contriever的影响。表现最好的结果用粗体标记
5.2 HyDE与基本语言模型
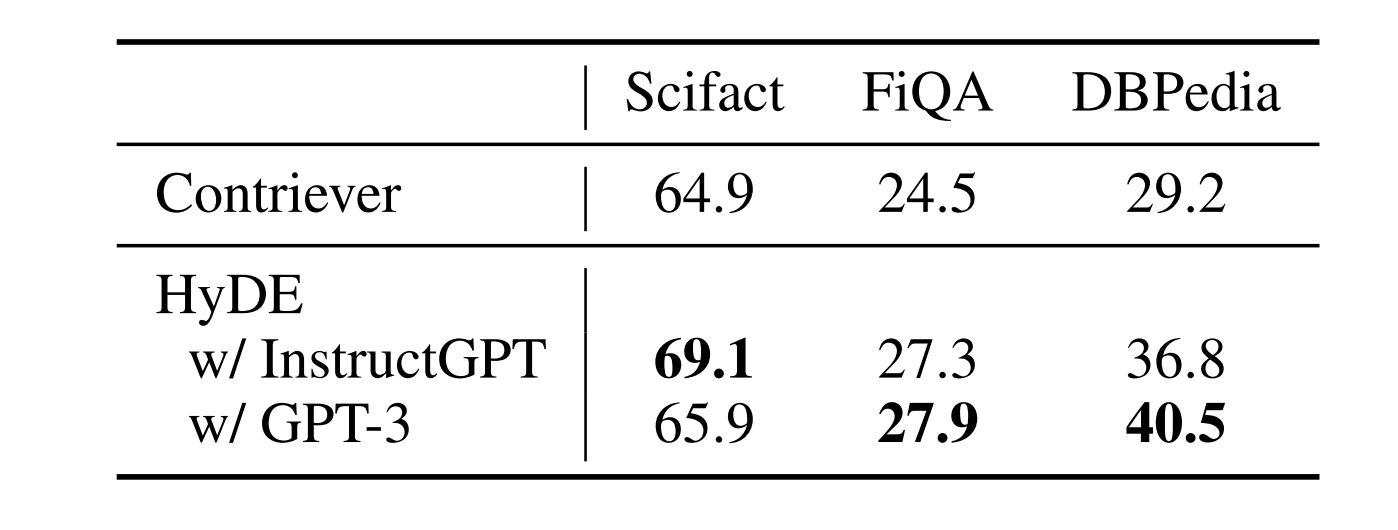
在本节中,我们考虑将HyDE与基础GPT-3模型一起使用,该模型尚未经过训练以与人类意图保持一致,并且不能很好地遵循指令。当无法访问所需大小和/或语言的编译调优语言模型时,这可能是一个有用的设置。我们使用上下文学习方法(Brown et al.,2020),并在三个带有训练示例的BEIR数据集上进行实验。我们在表5中报告了结果。在这里,少镜头模型的性能不太稳定:它在Scifact上有一个小的改进,但在FiQA和DBPedia上的性能优于InstructGPT。
表5:nDCG@10比较InstructGPT与BEIR上的3次注射GPT-3。最佳结果用粗体标记
5.3带微调编码器的HyDE
开始,我们强调,HyDE与微调编码器不是预期的用途:我们的方法是专门设计的情况下,没有相关性标签。对监督的访问(微调编码器)自然会削弱我们方法的影响。
然而,我们有兴趣了解HyDE嵌入是否以及如何使已经微调的编码器受益。我们考虑两个微调编码器,包含110 M参数的前述Contriever-ft和大得多的GTR-XL模型(Ni等人,2022),具有1.2B参数。在表6中,我们看到较大的GTRXL模型通常优于Contriever-ft,但HyDE仍然可以为两种微调编码器带来改进。我们看到较小的改进,GTR-XL,大概是因为它没有经过对比预训练来明确学习文档相似性。
表6:TREC DL 19/20上的nDCG@10,比较HyDE对监督模型的影响。最佳结果用粗体标记。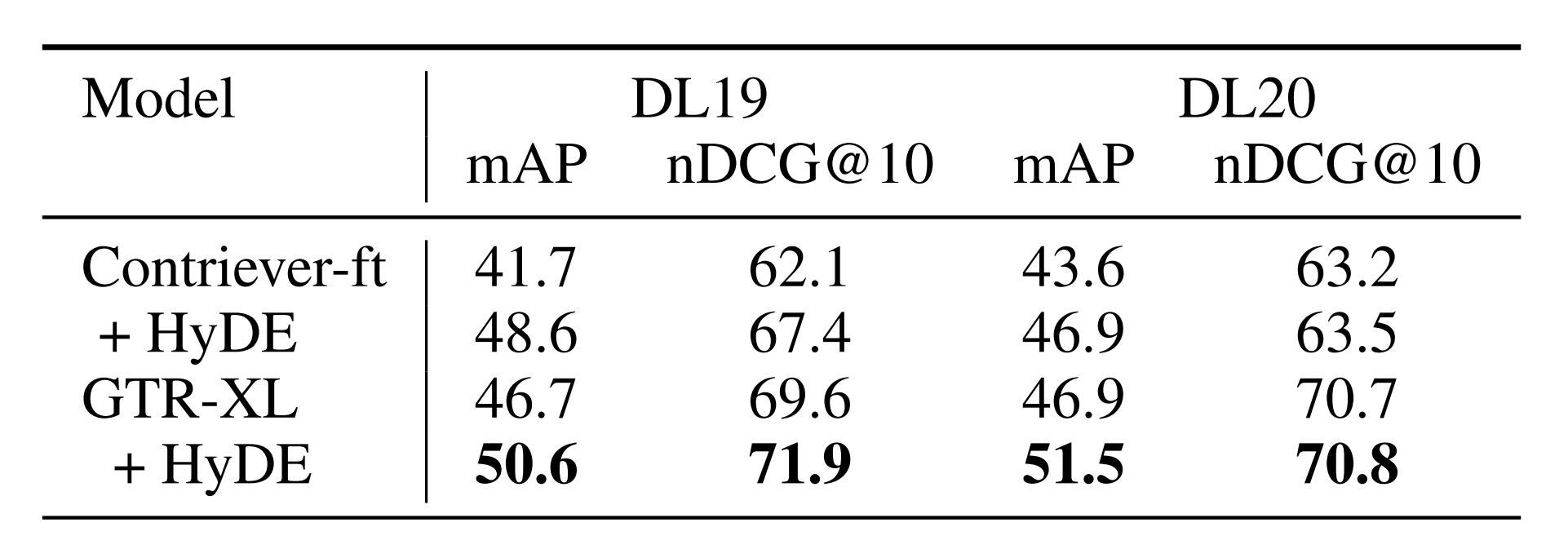
5.4可视化HyDE的效果
在图3中,我们从TREC-COVID和DBPedia中随机选取了两个查询示例,以可视化HyDE的效果。我们使用T-SNE降维方法在Contriever的嵌入空间中绘制海德向量和原始查询向量。在每个图中,我们可以看到HyDE生成的向量(红点)比原始查询向量(绿色点)更接近相关文档向量的聚类(蓝点)。这说明了HyDE的最近邻搜索如何更有效地识别相关文档。
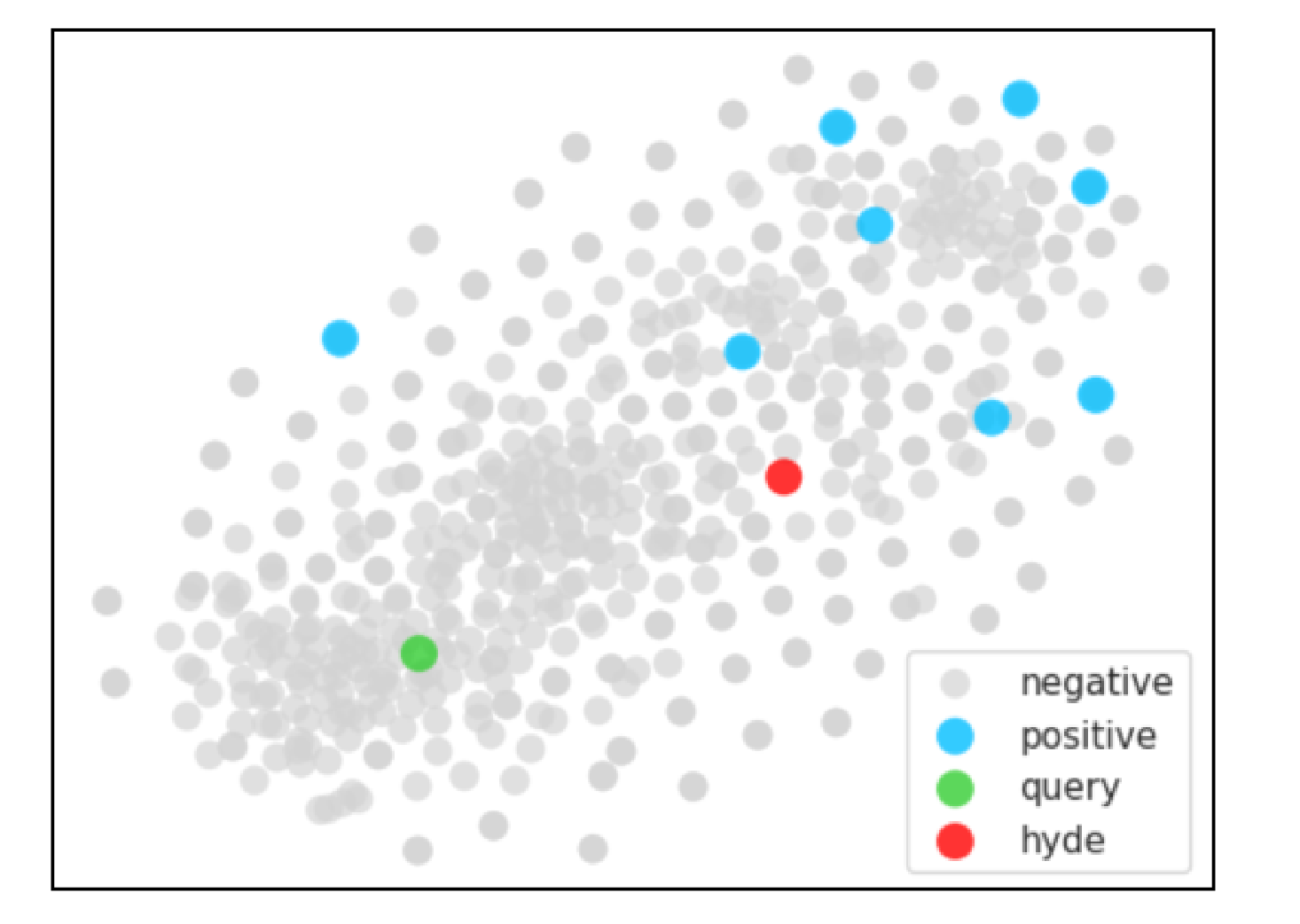
(a)来自TREC-COVID的查询示例:COVID-19病例的炎症反应和发病机制是什么?
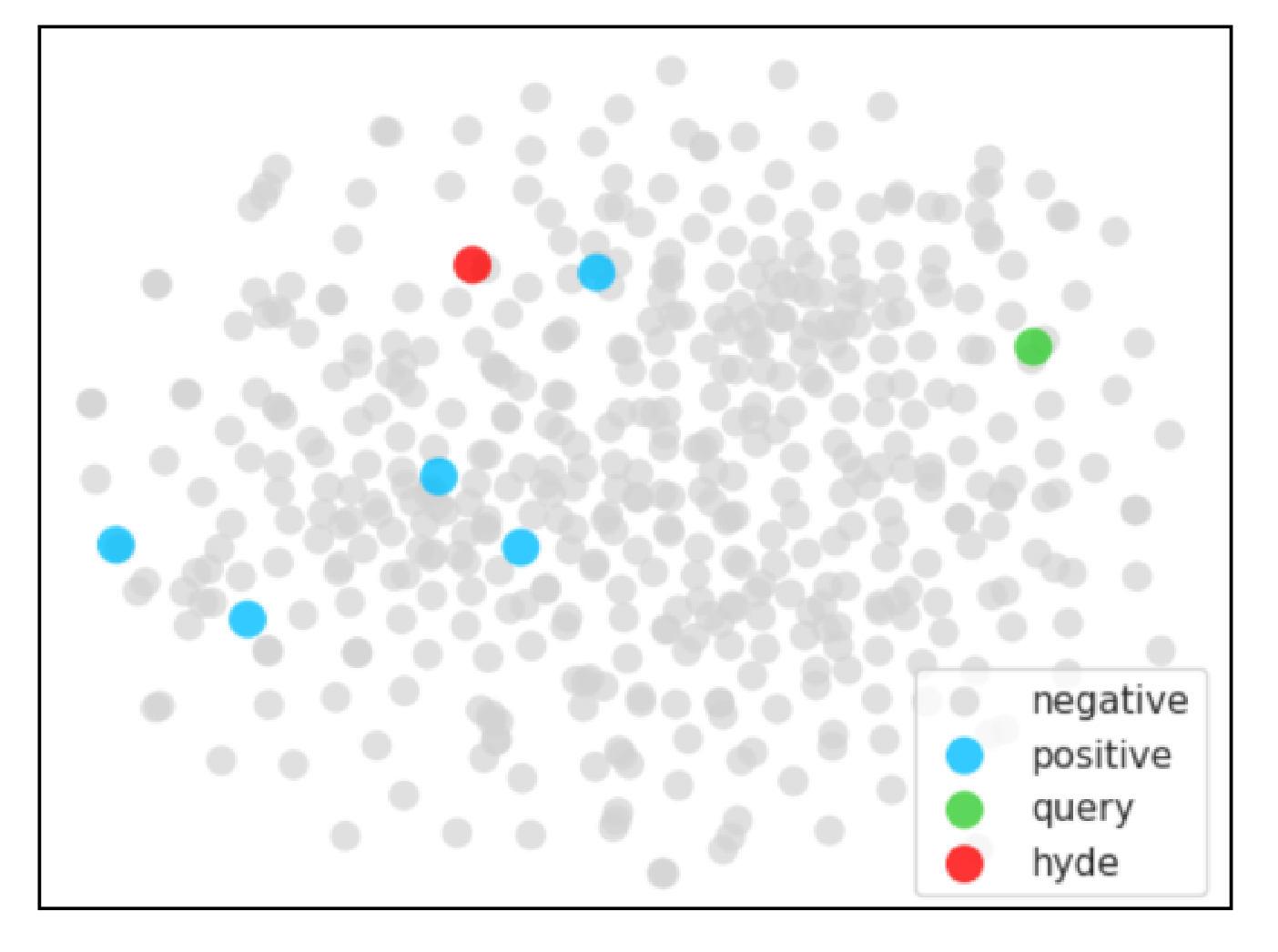
(b)来自DBPedia的查询示例:哪座山比南迦帕尔巴特山更高?
图3:Contriever的嵌入空间的T-SNE图,用于查询示例及其在嵌入空间中的附近文档。红点表示假设的文档向量。
六、结论
在本文中,我们介绍了HyDE,这是一种以完全无监督的方式构建有效的密集检索器的新方法,无需任何相关标签。我们证明了相关性建模的某些方面可以委托给一个更强大,更灵活,更通用的LLM,还没有专门适应搜索任务。因此,对相关性标签的需求被消除,取而代之的是纯粹的生成。我们很高兴看到这是否可以进一步推广到更复杂的任务,如多跳检索/QA和会话搜索。
尽管它依赖于LLM,我们认为HyDE在现实世界的应用中是有实际用途的,虽然不一定在整个生命周期的搜索系统。在构建搜索系统的最初阶段,使用HyDE服务查询提供的性能可与微调模型相媲美,这是其他无相关性模型无法提供的。随着搜索日志的增长和相关数据的积累,可以逐步训练并推出有监督的密集检索器。随着密集检索器变得更有能力,它可以处理“域内”的查询,而HyDE仍然可以用于新的,意外的或新兴的查询。
不足之处
我们的HyDE方法依赖于LLM的实时生成,因此可能不适合需要高吞吐量或低延迟的任务。然而,多年来,我们已经看到硬件成本的降低和模型压缩技术的进步,这可能有助于提高LLM推理的效率。同时,正如我们在结论中所描述的,HyDE可以用来实时收集相关性判断,并逐步帮助建立一个有效的监督密集检索模型。
此外,与大多数当代LLM一样,HyDE可能会在其生成过程中偏好某些内容,因此会使最终搜索结果产生偏差。我们乐观地认为,当使用InstructGPT实现HyDE时,该问题将得到解决,并且OpenAI将花费大量精力来减少模型偏倚和毒性(Ouyang等人,2022年)的报告。此外,用户还可以使用更精细的提示来进一步指导生成过程。相比之下,典型的密集检索系统依赖于不透明的嵌入,其中它们的偏差可能更难适当地发现和减轻。
A 附录
A.1 指令
Web Search

SciFact

Arguana

TREC-COVID

FiQA

DBPedia-Entity
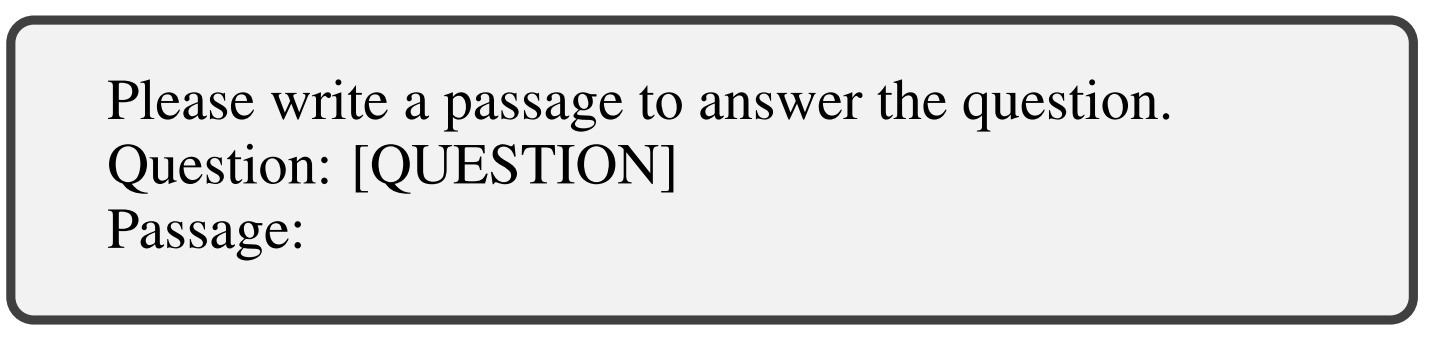
TREC-NEWS
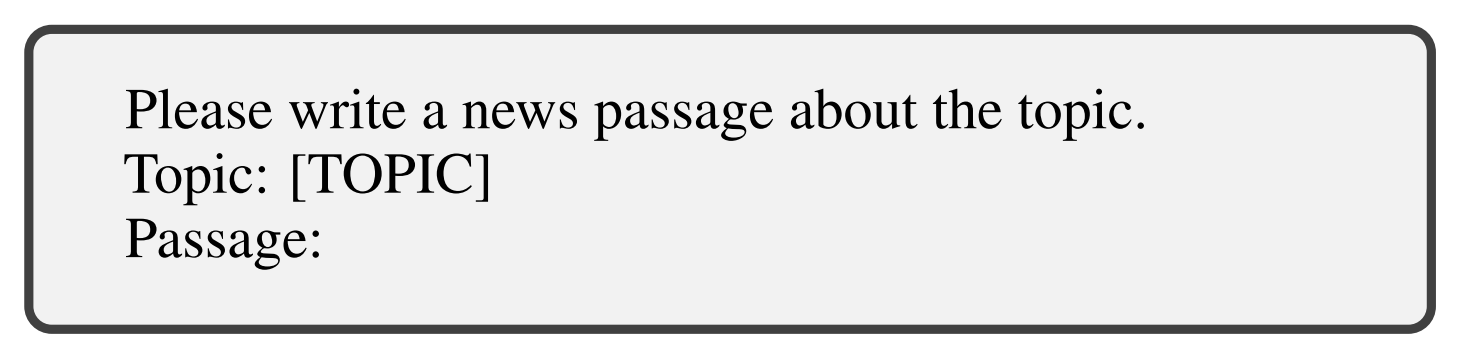
Climate-Fever
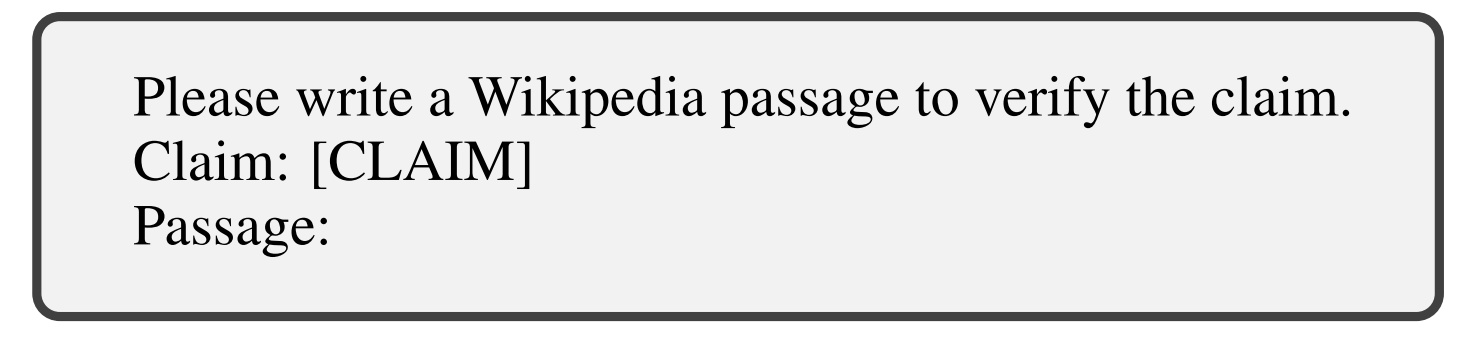
Mr.TyDi

A.2 模型
我们使用了以下模型:
Contriever
它使用BERT-base作为主干,具有110 M参数。CC BY-NC 4.0许可证。
GTR
其使用T5-XL作为骨干并且具有1.24B参数。这是Apache 2.0许可证。
FlanT5
其使用T5-XXL作为骨架并且具有11B参数。这是Apache 2.0许可证。
Cohere
它不是开源的,只能通过API请求访问。
GPT3
它不是开源的,只能通过API请求访问。
A.3数据集
我们使用了以下数据集:
TREC DL19/DL20
这是在麻省理工学院许可证下的非商业研究目的。该语料库包含8.84 M文档。
BEIR,
Apache 2.0许可证。它包含18个独立的数据集,包含不同的检索任务。
SciFact
CC BY-NC 4.0许可证。语料库包含5 K文档
Arguana, DBPedia,
CC BY-SA 3.0许可证。Arguana包含8.67K文档。DBPedia包含460万个文档。
TREC-COVID,
这是数据集许可协议的一部分。该语料库包含171K文档。
FiQA, Climate-Fever,
这是未知的许可证。FiQA包含57 K文档。Climate-Fever包含540万个文档。
TREC-NEWS,
这是有版权的语料库包含595K文档
Mr.TyDi,
Apache 2.0许可证。斯瓦希里语语料库包含136 K文档;韩语语料库,150万文档;日语语料库,700万文档;孟加拉语语料库,300 K文档。