Legal Query RAG(LQ-RAG):一种新的RAG框架用以减少RAG在法律领域的幻觉
人工智能正在迅速改变法律专业人士的工作方式——从起草合同到进行研究。但尽管大型语言模型(LLM)功能强大,它们在关键领域却常常出错:真实性。当人工智能在法律文件中“幻觉”出事实时,后果可能是严重的——问问那些无意中引用了虚假案例法的律师就知道了。
LQ-RAG是《IEEE Access》期刊上最近发表的论文。如果你想深入了解代码和方法,请查看 GitHub 仓库 和 完整论文。
LQ-RAG,一个专门构建的检索增强型生成框架,将特定领域的微调、递归反馈和基于代理的评估引入法律问答。该框架目标是对抗法律人工智能中的幻觉。
LQ-RAG 采用迭代过程来生成和优化其响应。它从用户查询开始,生成初始响应,并由评估代理评估其质量。评估代理评估生成响应的上下文相关性和有根性,并分配分数。根据这些分数,它确定响应是否令人满意,或者是否需要进一步优化。如果需要优化,评估代理会向提示工程代理提供反馈,以改进查询。这有助于生成代理产生更好的响应。更好的响应反映在逐渐接近最优值的评估分数中。此外,还采用了检索文档缩减方法来重新排序和筛选最相关的文档,减少内存使用并加速推理。
当前人工智能为何在法律领域失败
法律推理不仅仅是寻找答案——它还涉及解释细微差别、跟踪不断演变的立法,并避免灾难性的错误。在法律等高风险领域,人工智能幻觉的后果可能是严重的。我们已经看到律师因提交引用了人工智能生成的虚构案例法的法庭文件而受到纪律处分的案例。研究表明,通用 LLM 在面对法律查询时经常幻觉,报告的发生率惊人地在 58% 到 82% 之间。
“在法律等高风险领域,准确性不是可选的——它是至关重要的。2023 年,两名纽约律师因引用 ChatGPT 生成的虚构法律案例而登上头条。这只是日益严重的问题的一个例子:人工智能幻觉。”
这些问题部分源于当前 LLM 主要是在通用数据集上训练的,这限制了它们对全面、特定领域知识的访问和有效利用。它们还难以扩展其参数记忆,从而加剧了幻觉问题。尽管在金融(BloombergGPT)和医学(Med-PaLM)等其他领域已经出现了专业模型,但法律领域可靠且针对其独特需求量身定制的 LLM 数量相对较少。这种稀缺性严重阻碍了法律实践的数字化转型,这是一个需要准确、最新信息和细微解释的领域。
LQ-RAG
LQ-RAG 框架提出了一个复杂的法律问答方法,采用混合策略对 RAG 系统的关键组件进行微调,并将其与先进机制整合。该系统分为两个主要层级:微调(FT)层级和 RAG 层级。
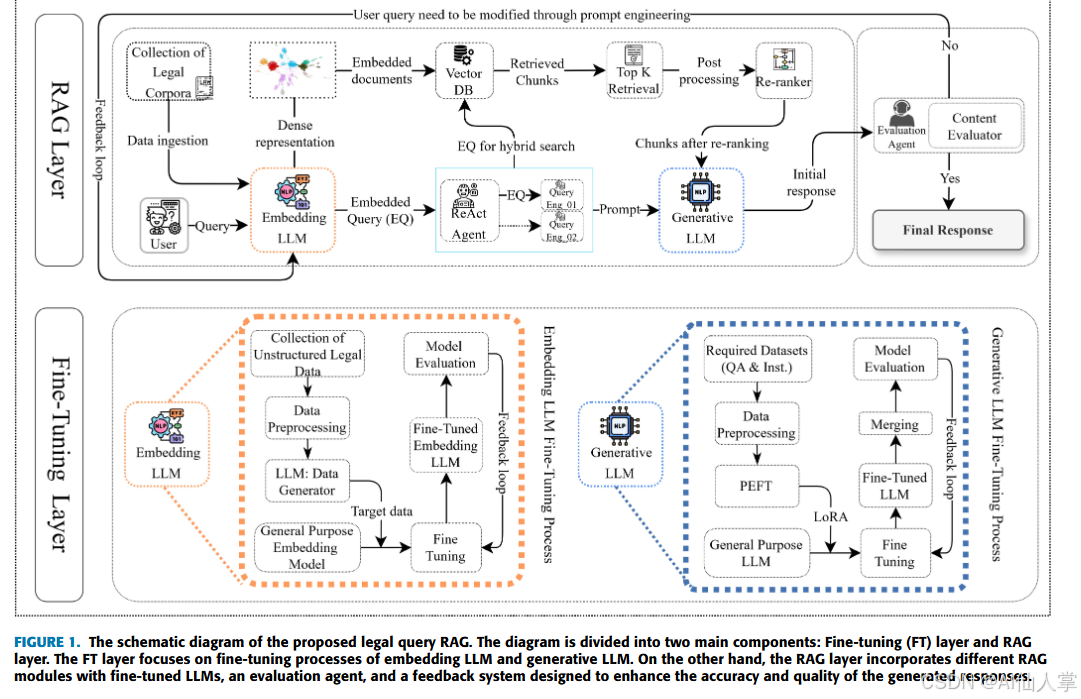
微调层:构建领域专业知识
FT 层级负责将通用 LLM 定制到法律领域。这涉及对 RAG 系统的两个主要组件进行单独微调:嵌入生成模块和响应生成模块。
- 微调嵌入 LLM:
- 过程从收集无结构的法律领域语料库开始,本研究中来自开放获取门户(如 Library Genesis)。
- 这些数据的一个子集经过预处理,然后输入由 OpenAI GPT-3.5-turbo 驱动的合成数据生成器。该生成器通过将无结构文本分解为片段并针对每个片段生成直接相关的问题,创建由查询 - 上下文对组成的合成数据集。
- 然后使用这个合成数据集对基线嵌入 LLM 进行微调。在本研究中,使用了 GIST Large Embedding v0 模型。
- 微调过程利用 多负样本排名损失(MNRL) 函数来优化模型。MNRL 的目标是最小化相似句子向量嵌入之间的距离,同时最大化不相似句子之间的距离。这种方法对于确保嵌入 LLM 学会捕捉与法律领域相关的语义关系至关重要,从而增强其识别上下文相似法律文本的能力。
- 微调过程涉及多个周期和批量更新,调整模型的参数以优化定义的目标函数。
2. 微调生成 LLM:
- 使用的基线生成模型是 LLaMA-3–8B,这是一个通用的预训练自回归 LLM。
- 收集并预处理两个不同的数据集用于微调:特定领域的问答数据集(DQA)和通用指令数据集(DInstr)。每个数据集由输入 - 目标序列对组成。
- 为了处理微调大型模型所需的大量内存和处理资源,研究采用了低秩适应(LoRA)和 4 位量化(使用 BitsAndBytesConfig)。LoRA 在微调期间减少了可训练参数的数量,使过程更加高效,而量化进一步减小了模型大小并提高了推理速度。
- 预训练的 LLM 分别使用 LoRA 与 DQA 和 DInstr 数据集进行微调。
- 微调旨在通过梯度更新优化对数似然目标,增强模型根据输入预测正确输出序列的能力。
- 在这些单独的微调步骤之后,将得到的模型使用 线性合并方法 结合起来,创建所需的混合微调生成 LLM(HFM)。
这种混合方法确保模型既获得了特定领域的法律知识,又增强了遵循指令的能力,这对于生成相关且准确的法律响应至关重要。
RAG 层:整合、检索和递归反馈
RAG 层级是将微调后的 LLM 与先进的 RAG 模块以及新颖的反馈机制整合的地方。这一层级协调从接收用户查询到生成和评估响应的整个过程。
- 数据摄取:剩余的无结构法律语料库用作外部知识源。并行工作者高效地将这些数据转换为文档对象。这些文档被分割成更小的文本片段。
- 嵌入和索引:将分割后的文本片段通过微调后的嵌入 LLM 处理,生成高维实值向量。然后使用像 Facebook AI Similarity Search(FAISS) 这样的系统对这些向量进行索引,并存储在向量数据库中。这种索引允许后续进行快速相似性搜索。
- 查询处理和检索:当用户提交法律查询时,它由微调后的嵌入 LLM 处理以生成查询向量。这些查询向量被发送到推理和行动(ReAct)代理,它选择合适的查询引擎工具从外部知识源检索相关文本片段。检索采用混合搜索方法,结合 BM25(基于词频的词汇方法)和 DPR(密集段检索,使用密集向量嵌入)。这种混合方法旨在通过结合关键词匹配和语义相似性来提高搜索精度。检索到的文档随后可选地由后处理单元进行评分和重新排序,以优先考虑最相关的信息并减少传递给生成模型的文档总体积。这解决了管理不断扩展的上下文窗口的挑战。
- 响应生成:构建一个提示,包含系统指令、用户查询和重新排序的检索上下文。将此提示输入混合微调生成 LLM(HFM)以合成初始响应。
- 评估和反馈循环:这是 LQ-RAG 显著区别于其他系统的地方。由 GPT-4 驱动的评估代理根据三个关键标准评估生成响应的质量:答案相关性、上下文相关性和有根性。评估使用链式思考(CoT)过程以确保彻底评估。
- 上下文相关性:代理验证仅使用从知识库检索到的相关上下文片段来生成响应,旨在减少由不相关细节引起的幻觉。
- 有根性:将响应分解为不同的主张,并在检索到的上下文中搜索支持证据以确保事实准确性。
- 答案相关性:代理检查生成的响应在多大程度上直接解决了用户的原始查询。
通过递归反馈机制,迭代地细化检索到的文档和生成的响应,通过持续评估答案相关性、上下文相关性和事实性,确保更高的准确性和与法律领域的对齐。
公式解释:
- RAG-Sequence模型:使用相同的检索文档生成整个响应。
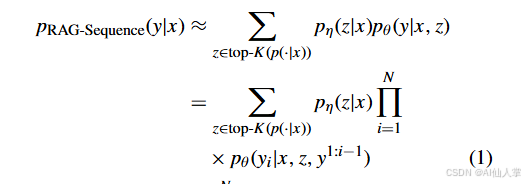
其中, 是输入序列, 是目标序列, 是检索到的文档, 表示目标序列长度, 提供给定 的文本段落的分布, 基于先前的标记、输入、检索到的文档和之前的标记生成当前标记。
- RAG-Token模型:使用多个检索到的文档生成答案。
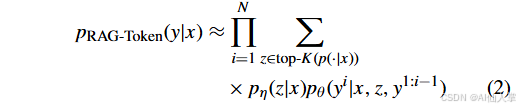
如果初始响应满足评估代理定义的预设质量标准,则将其作为最终输出呈现。至关重要的是,如果响应不满足标准,则用户查询进入反馈循环。提示工程代理修改初始用户查询,应用轻微调整以简化它,同时保留其主要思想。修改后的查询然后送回 RAG 系统,重复检索和生成过程。这种递归反馈机制通过持续评估相关性和有根性,迭代优化检索到的文档和生成的响应,努力实现更高的准确性和与法律领域的对齐。
这种由代理驱动的递归反馈过程是 LQ-RAG 的开创性功能,为优化响应质量和精度开辟了一条创新路径,超越了单次传递。
LQ-RAG整体工作流程
阶段1:文档处理与索引
- 文档上传:用户上传PDF格式的法律文档
- 文档解析:使用SimpleDirectoryReader加载文档
- 文本分割:
- 主要分块:512字符
- 子分块:256、512字符(用于递归检索)
- 向量化:使用专用法律嵌入模型生成向量表示
- 索引构建:
- FAISS向量索引
- BM25关键词索引
- 存储到本地存储上下文
阶段2:查询处理与响应生成
- 查询接收:用户输入法律相关查询
- 混合检索:
- 向量检索:基于语义相似性
- BM25检索:基于关键词匹配
- 递归检索:利用层次化节点结构
- 结果重排序:使用BGE-reranker-large模型
- 响应生成:基于检索到的上下文生成初始响应
阶段3:质量评估与迭代优化
- 多维度评估:
- 上下文相关性:评估检索内容与查询的相关性
- 答案相关性:评估生成答案与查询的相关性
- 事实依据性:评估答案的事实准确性
- 质量判断:
- 如果所有指标达标:返回最终响应
- 如果上下文相关性过低:使用LLM预训练知识生成响应
- 如果部分指标不达标:触发查询优化
- 查询优化:
- 使用CrewAI的提示工程代理
- 生成更清晰、更具体的查询
- 重新执行检索和生成流程
测试 LQ-RAG
论文详细介绍了对 LQ-RAG 及其组件的广泛评估,将其性能与各种基线模型和配置进行了比较。
嵌入 LLM 性能
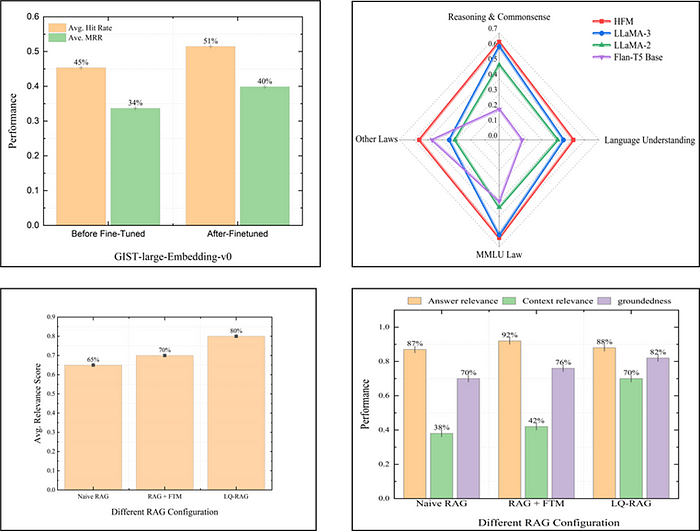
对微调后的 GIST Large Embedding v0 模型的评估显示了显著的改进。与预训练版本相比,微调后的模型在平均命中率(HR)上提高了 13%,在平均平均倒数排名(MRR)上提高了 15%。HR 衡量正确答案在前 k 个检索文档中的查询比例,而 MRR 根据第一个相关文档的排名评估排名算法的性能。这些结果表明,在微调后,模型在不同数据集上的泛化能力得到了增强。
将微调后的模型(命名为 GIST-Law-Embed)与其他基线嵌入模型进行比较,进一步突显了其有效性。GIST-Law-Embed 显著优于所有其他基线 LLM,在 top K=5 时,平均命中率达到 51%,平均 MRR 达到 40%。这种性能不仅体现在平均水平上,该模型在每个单独文档中都保持了最高分数,显示出其在检索相关法律信息方面的稳健性和一致性。
研究还发现,模型尺寸较大的版本通常优于其较小的版本,强调了模型尺寸对检索能力的积极影响。至关重要的是,经过特定领域微调的模型(如 GIST-Law-Embed)表现出增强的检索性能,进一步证明了针对特定领域定制模型的重要性。
对检索片段数量(top-k)的影响分析表明,增加 k 一致地增强了 RAG 从原始上下文中检索相关信息的能力。研究人员选择了 k=15 用于后续实验,因为它在超过 60% 的时间里成功检索到了原始段落,而不会过度增加输入提示的大小。
生成 LLM 性能
混合微调生成 LLM(HFM) 在两组任务中进行了全面评估:一般推理任务和特定法律领域的任务。
结果显示,微调和合并显著提高了模型在两个类别的性能。在第一组(一般任务)中,HFM 的平均性能提高了 9%。在第二组(法律任务)中,提升更为显著,性能提高了 38%。这清楚地表明,微调和合并技术在提高特定领域性能方面非常有效。
HFM 在几个关键的法律领域数据集上表现出色:
- MMLU 国际法:HFM 得分为 0.81 ± 0.03,而 LLaMA-3–8B 为 0.77 ± 0.0443。
- MMLU 职业法:HFM 领先,得分为 0.47 ± 0.01,而 LLaMA-3–8B 为 0.46 ± 0.0143。
- Abercrombie 分类:HFM 达到 0.54 ± 0.04,而 LLaMA-3–8B 为 0.45 ± 0.0543。
- 法律推理因果关系(LRC):HFM 表现卓越,得分为 0.75 ± 0.01,显著优于 LLaMA-3–8B 的 0.52 ± 0.0143。
- 合同问答(CQA):HFM 达到 0.56 ± 0.01,超过了 LLaMA-3–8B 的 0.19 ± 0.0143。
尽管 HFM 在许多法律任务中表现出色,但其他模型(如 Flan-T5 large)在 Law Stack Exchange(LSE) 和 加拿大税务法庭结果(CTCO) 等数据集上表现更好。然而,总体而言,HFM 在两个评估组中均实现了最高性能,显示出其在处理一般语言理解和特定法律查询方面的稳健性和有效性。研究强调了微调和合并技术在提高下游任务的泛化能力和性能方面的价值。
作者制作的图片
LQ-RAG 系统性能
将 LQ-RAG 系统与 简单 RAG 配置和 带有微调 LLM 的 RAG(FTM) 配置进行了比较。评估侧重于开放领域和封闭领域法律问答。
对于开放领域法律问题,这些问题模拟了关于宪法条款、修正案和假设场景的真实世界查询,LQ-RAG 在响应相关性方面表现出显著改进。平均相关性分数为:
- 简单 RAG:65%44
- 带有 FTM 的 RAG:70%(比简单 RAG 提高 7%)
- LQ-RAG:80%44
这代表了与简单 RAG 相比,相关性分数提高了 23%,与带有 FTM 的 RAG 相比提高了 14%。这一显著提升归功于 LQ-RAG 的先进整合、微调组件和递归反馈机制,这些机制增强了其理解并检索上下文相关信息的能力,从而产生了更连贯、更准确的答案。
使用 “RAG 三元组”(答案相关性、上下文相关性和有根性)进行的评估进一步强化了 LQ-RAG 在开放场景中的有效性。LQ-RAG 在答案相关性上得分为 88%,在上下文相关性上得分为 70%,在有根性上得分为 82%。相比之下,简单 RAG 在上下文相关性方面表现不佳,而带有 FTM 的 RAG 虽然比简单 RAG 表现更好,但其分数仍不令人满意。这些指标对于确保对生成的法律响应的准确性和可靠性有信心至关重要。答案相关性衡量答案准确回答查询的程度,上下文相关性衡量检索到的上下文与查询的契合程度,有根性通过检查答案是否得到检索到的上下文的支持来评估答案的真实性。
对于 封闭领域法律问题,其中相关的信息在领域内有限或缺失,结果有所不同。简单 RAG 和带有 FTM 的 RAG 在答案相关性分数上均达到了 88%。然而,对于 LQ-RAG 系统,答案相关性分数下降到了 72%。在封闭领域测试中,所有配置的上下文相关性和有根性分数均低于 50%。这一结果在意料之中,因为系统没有提供必要的相关上下文信息。研究指出,根据这些发现,在没有相关上下文的封闭领域场景中,RAG 系统生成的答案可能不正确,这质疑了在上下文相关性和有根性较低时报告的答案相关性分数的有效性。这强调了在评估 RAG 系统时,尤其是在高风险的法律领域,考虑所有三个标准(答案相关性、上下文相关性和有根性)的重要性。
先进人工智能系统的一个实际问题是时间复杂度。研究测量了不同 RAG 配置的平均响应生成时间。如预期的那样,简单 RAG 系统最快,处理五组问题需要 7.2 秒。带有 FTM 的 RAG 需要更长时间,为 11.2 秒,而提出的 LQ-RAG 系统需要 14.6 秒,大约是简单系统的两倍。这表明,尽管引入先进模块可以提高准确性和相关性,但也会增加系统的时间复杂度。
创新点
LQ-RAG 框架是解决人工智能在法律领域面临的特定领域挑战的重要一步,特别是幻觉这一关键问题以及对精确、上下文相关响应的需求。通过将递归反馈机制与专门的微调 LLM 和以代理驱动的响应评估及查询工程方法相结合,LQ-RAG 有效地减少了幻觉并提高了特定领域的准确性。
实验结果展示了这种方法的力量。微调后的嵌入 LLM 在命中率上提高了 13%,在 MRR 上提高了 15%。当整合到 LQ-RAG 中时,混合微调生成 LLM(HFM)比通用 LLM 的性能提高了 24%。此外,LQ-RAG 架构始终优于基线模型,在相关性分数上比简单配置提高了 23%,比带有微调 LLM 的 RAG 提高了 14%。
LQ-RAG 的可适应设计表明其有可能在经过最小调整后应用于其他特定领域,使专业人士能够做出更高质量、更明智的决策。
不足
尽管 LQ-RAG 展示了显著的进步,但作者承认当前工作存在一些限制,包括:
- 依赖 GPT-4 作为评估代理。
- 与简单配置相比,响应生成时间相对较长。
- 当前评估过程中缺乏来自人类领域专家的反馈。
未来的努力将致力于解决这些限制。这将包括:
- 优化时间复杂度以提高响应速度。
- 开发具有特定领域专业知识的专门法律评估代理。
- 通过纳入法律从业者的反馈来提升评估代理的性能,以确保模型的实际效用和与现实世界法律推理及上下文的一致性。
- 纳入专门针对法律领域设计的基准数据集,以进一步验证该方法。
- 应用最先进的优化技术,以进一步提高命中率和 MRR。
- 在现实世界的法律场景中进行实证实验,以展示系统的实际效果。
这些计划中的改进强调了这项研究的持续性质以及致力于使人工智能成为法律专业人士更可靠、更有效工具的承诺。LQ-RAG 框架 通过直接解决人工智能幻觉这一关键问题,通过智能检索、专门模型和递归自我校正,为实现这一目标提供了一条有希望的途径。
总体结论
这篇论文提出的LQ-RAG框架通过集成递归反馈机制、专门的LLM和代理驱动的响应评估和查询工程,解决了法律领域中信息检索增强生成的问题。微调后的嵌入LLM和混合微调生成LLM显著提高了模型的性能,LQ-RAG系统在各种任务中表现出色,具有广泛的应用潜力。未来的工作将集中在优化时间复杂性、开发专业的法律评估代理以及整合领域专家的反馈,以进一步提高模型的实际效用和对齐法律推理和上下文。
关键问题及回答
问题1:LQ-RAG框架中的自定义评估代理是如何工作的?它如何提高响应的准确性和相关性?
自定义评估代理是基于OpenAI GPT-4的模型,用于独立评估模型生成的响应的准确性和相关性。具体工作流程如下:
- 评估标准:评估代理根据预设的标准评估响应的相关性、上下文相关性和事实性。
- 反馈机制:如果生成的响应满足预设标准,评估代理会将其作为最终输出;否则,评估代理会将查询发送给提示工程代理。
- 提示工程:提示工程代理对查询进行微调,以简化查询并保留其主要思想,然后重新提交给RAG系统进行新一轮的检索和生成过程。
- 递归反馈:这个过程是递归的,每次生成的响应都会经过评估代理的评估,并根据评估结果进行相应的调整,直到生成的响应满足预设标准。
通过这种递归反馈机制,LQ-RAG框架能够不断改进生成的响应,确保其准确性和相关性。
问题2:在生成LLM的微调过程中,为什么选择了LLaMA-3-8B模型,并且采用了Low-Rank Adaptation(LoRA)技术?
- 选择LLaMA-3-8B模型的原因:
- 预训练模型:LLaMA-3-8B是一个通用的预训练自回归LLM,具有丰富的语言建模能力,适合用于各种自然语言处理任务。
- 计算资源:尽管LLaMA-3-8B模型需要较大的计算资源和内存,但通过PEFT和4位量化等优化技术,可以有效平衡计算资源和模型性能。
- 采用Low-Rank Adaptation(LoRA)技术的原因:
- 减少参数数量:LoRA技术通过低秩矩阵分解,减少了模型的可训练参数数量,从而降低了计算复杂度和内存需求。
- 提高泛化能力:LoRA技术可以在不显著增加模型参数的情况下,提高模型的泛化能力和性能,特别是在有限数据的情况下。
- 优化训练过程:通过减少可训练参数,LoRA技术可以加快模型的收敛速度,并提高训练过程的稳定性。
通过这些技术手段,LLaMA-3-8B模型在微调过程中能够更高效地学习领域知识,提高其在法律领域的适用性和性能。
问题3:LQ-RAG系统在开放域和封闭域问答任务中的表现如何?与其他配置相比有哪些优势?
- 开放域问答任务:
- 平均相关性得分:LQ-RAG系统在开放域问答任务中的平均相关性得分为80%,比朴素RAG提高了23%,比微调后的RAG提高了14%。
- 评估指标:在开放域问答任务中,LQ-RAG系统在答案相关性、上下文相关性和事实性得分上分别达到了88%、70%和82%。
- 优势:LQ-RAG系统通过递归反馈机制和专业的LLM,能够生成更加准确和相关性更高的响应,特别是在处理复杂的法律查询时表现出色。
- 封闭域问答任务:
- 答案相关性得分:LQ-RAG系统在封闭域问答任务中的答案相关性得分为72%。
- 评估指标:在封闭域问答任务中,LQ-RAG系统的上下文相关性和事实性得分分别为48%和35%。
- 优势:尽管在封闭域问答任务中,LQ-RAG系统的表现略逊于开放域任务,但仍然显著优于朴素RAG和微调后的RAG系统,特别是在答案相关性方面。
总体而言,LQ-RAG系统在开放域和封闭域问答任务中都表现出色,通过递归反馈机制和专业的LLM,能够生成更加准确和相关性更高的响应,显著提高了法律领域中信息检索增强生成的性能和准确性。