【推荐算法】推荐系统核心算法深度解析:协同过滤 Collaborative Filtering
推荐系统核心算法深度解析:协同过滤
- 一、协同过滤的算法逻辑
- 协同过滤的两种实现方式
- 二、算法原理与数学推导
- 1. 相似度计算关键公式
- 2. 矩阵分解(MF)进阶
- 三、模型评估
- 1. 准确性指标
- 2. 排序指标(Top-N推荐)
- 3. 多样性 & 新颖性
- 四、应用案例
- 五、面试常见问题
- 六、详细优缺点
- 优点
- 缺点
- 七、优化方向
- 总结
一、协同过滤的算法逻辑
协同过滤的核心思想是利用群体智慧:
假设:相似用户对物品有相似偏好,相似物品会被相似用户喜欢。
输入:用户-物品交互矩阵(如评分、点击行为)。
输出:预测用户对未交互物品的偏好。
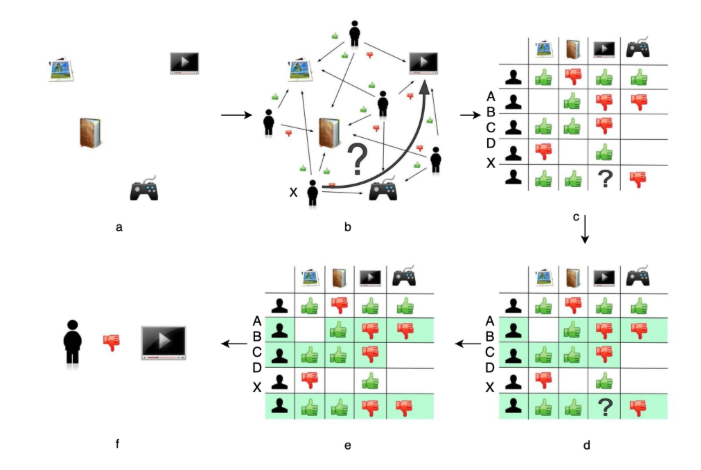
协同过滤的两种实现方式
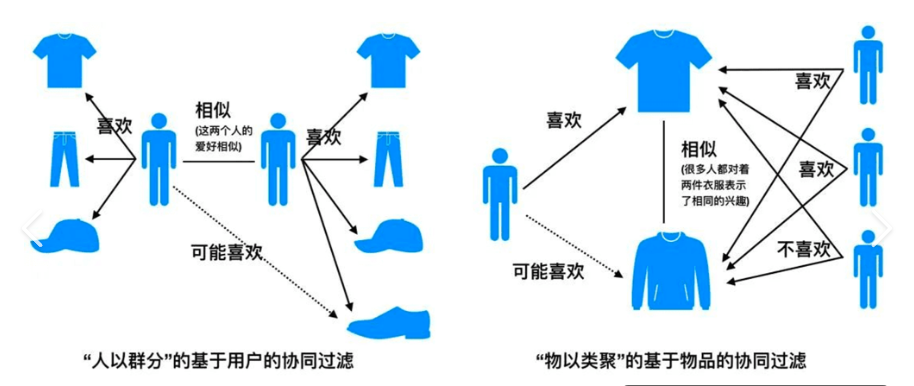
- 基于用户的协同过滤(User-Based CF)
- 步骤:
- 计算用户相似度(如余弦相似度)
- 找到目标用户的K个最近邻(相似用户)
- 根据邻居的评分加权预测目标用户评分
r ^ u i = r u ˉ + ∑ v ∈ N ( u ) s i m ( u , v ) ⋅ ( r v i − r v ˉ ) ∑ v ∈ N ( u ) ∣ s i m ( u , v ) ∣ \hat{r}_{ui} = \bar{r_u} + \frac{\sum_{v \in N(u)} sim(u,v) \cdot (r_{vi} - \bar{r_v})}{\sum_{v \in N(u)} |sim(u,v)|} r^ui=ruˉ+∑v∈N(u)∣sim(u,v)∣∑v∈N(u)sim(u,v)⋅(rvi−rvˉ)
- 步骤:
- 基于物品的协同过滤(Item-Based CF)
- 步骤:
- 计算物品相似度(如调整余弦相似度)
- 根据目标用户历史交互物品,推荐相似物品
r ^ u i = ∑ j ∈ S ( i ) s i m ( i , j ) ⋅ r u j ∑ j ∈ S ( i ) ∣ s i m ( i , j ) ∣ \hat{r}_{ui} = \frac{\sum_{j \in S(i)} sim(i,j) \cdot r_{uj}}{\sum_{j \in S(i)} |sim(i,j)|} r^ui=∑j∈S(i)∣sim(i,j)∣∑j∈S(i)sim(i,j)⋅ruj
- 步骤:
二、算法原理与数学推导
1. 相似度计算关键公式
-
余弦相似度(用户/物品向量夹角):
s i m ( u , v ) = r u ⋅ r v ∥ r u ∥ ⋅ ∥ r v ∥ sim(u,v) = \frac{\mathbf{r_u} \cdot \mathbf{r_v}}{\|\mathbf{r_u}\| \cdot \|\mathbf{r_v}\|} sim(u,v)=∥ru∥⋅∥rv∥ru⋅rv
缺点:未考虑评分尺度差异。 -
皮尔逊相关系数(修正尺度偏差):
KaTeX parse error: Unexpected end of input in a macro argument, expected '}' at end of input: … \bar{r_v})^2}
其中 ( I_{uv} ) 是用户 ( u ) 和 ( v ) 共同评分的物品集合。 -
调整余弦相似度(Item-Based专用):
s i m ( i , j ) = ∑ u ∈ U i j ( r u i − r u ˉ ) ( r u j − r u ˉ ) ∑ u ∈ U i j ( r u i − r u ˉ ) 2 ∑ u ∈ U i j ( r u j − r u ˉ ) 2 sim(i,j) = \frac{\sum_{u \in U_{ij}}(r_{ui} - \bar{r_u})(r_{uj} - \bar{r_u})}{\sqrt{\sum_{u \in U_{ij}}(r_{ui} - \bar{r_u})^2} \sqrt{\sum_{u \in U_{ij}}(r_{uj} - \bar{r_u})^2}} sim(i,j)=∑u∈Uij(rui−ruˉ)2∑u∈Uij(ruj−ruˉ)2∑u∈Uij(rui−ruˉ)(ruj−ruˉ)
通过减去用户平均分消除评分偏差。
2. 矩阵分解(MF)进阶
为解决数据稀疏性,引入隐语义模型(如SVD):
- 目标:将用户-物品矩阵 ( R \in \mathbb{R}^{m \times n} ) 分解为:
R ≈ P ⋅ Q T , P ∈ R m × k , Q ∈ R n × k R \approx P \cdot Q^T, \quad P \in \mathbb{R}^{m \times k}, \ Q \in \mathbb{R}^{n \times k} R≈P⋅QT,P∈Rm×k, Q∈Rn×k
其中 ( k \ll m,n ) 为隐因子维度(如主题、风格)。
-
优化目标(最小化损失函数):
min P , Q ∑ ( u , i ) ∈ κ ( r u i − p u T q i ) 2 + λ ( ∥ p u ∥ 2 + ∥ q i ∥ 2 ) \min_{P,Q} \sum_{(u,i) \in \kappa} (r_{ui} - \mathbf{p_u}^T \mathbf{q_i})^2 + \lambda (\|\mathbf{p_u}\|^2 + \|\mathbf{q_i}\|^2) P,Qmin(u,i)∈κ∑(rui−puTqi)2+λ(∥pu∥2+∥qi∥2)
( \kappa ) 为已知评分集合,( \lambda ) 为正则化系数。 -
求解方法:随机梯度下降(SGD)
p u ← p u + γ ( e u i ⋅ q i − λ p u ) \mathbf{p_u} \leftarrow \mathbf{p_u} + \gamma (e_{ui} \cdot \mathbf{q_i} - \lambda \mathbf{p_u}) pu←pu+γ(eui⋅qi−λpu)
q i ← q i + γ ( e u i ⋅ p u − λ q i ) \mathbf{q_i} \leftarrow \mathbf{q_i} + \gamma (e_{ui} \cdot \mathbf{p_u} - \lambda \mathbf{q_i}) qi←qi+γ(eui⋅pu−λqi)
其中 ( e_{ui} = r_{ui} - \mathbf{p_u}^T \mathbf{q_i} ),( \gamma ) 为学习率。
三、模型评估
1. 准确性指标
- 均方根误差(RMSE):
R M S E = 1 N ∑ ( u , i ) ( r u i − r ^ u i ) 2 RMSE = \sqrt{\frac{1}{N} \sum_{(u,i)} (r_{ui} - \hat{r}_{ui})^2} RMSE=N1(u,i)∑(rui−r^ui)2 - 平均绝对误差(MAE):
M A E = 1 N ∑ ( u , i ) ∣ r u i − r ^ u i ∣ MAE = \frac{1}{N} \sum_{(u,i)} |r_{ui} - \hat{r}_{ui}| MAE=N1(u,i)∑∣rui−r^ui∣
2. 排序指标(Top-N推荐)
- 精确率(Precision@K):
P r e c i s i o n @ K = 推荐中用户喜欢的物品数 K Precision@K = \frac{\text{推荐中用户喜欢的物品数}}{K} Precision@K=K推荐中用户喜欢的物品数 - 召回率(Recall@K):
R e c a l l @ K = 推荐中用户喜欢的物品数 用户喜欢的物品总数 Recall@K = \frac{\text{推荐中用户喜欢的物品数}}{\text{用户喜欢的物品总数}} Recall@K=用户喜欢的物品总数推荐中用户喜欢的物品数 - NDCG(归一化折损累积增益):
考虑排序位置权重,对高相关物品在前给予更高分。
3. 多样性 & 新颖性
- 覆盖率(Coverage):
C o v e r a g e = ∣ 被推荐过的物品 ∣ ∣ 总物品 ∣ Coverage = \frac{|\text{被推荐过的物品}|}{|\text{总物品}|} Coverage=∣总物品∣∣被推荐过的物品∣ - 基尼系数(Gini Index):
衡量推荐分布均匀性,避免头部效应。
四、应用案例
-
亚马逊(Item-Based CF)
- 应用场景: “购买此商品的顾客也买了”
- 技术细节: 使用改进的余弦相似度,实时更新物品相似矩阵。
-
Netflix 推荐大赛
- 背景:2006年举办,奖金100万美元。
- 关键发现:
- 矩阵分解(SVD++)显著优于传统CF
- 融合时间动态因素(如用户兴趣漂移)提升预测精度
-
Spotify 音乐推荐
- 混合模型: CF + 内容特征(音频MFCC特征)
- 解决冷启动: 新歌曲通过内容特征映射到隐空间。
五、面试常见问题
-
User-CF 和 Item-CF 如何选择?
- User-CF 适用于用户数少、物品更新快的场景(如新闻推荐)
- Item-CF 适用于物品数少、用户行为稳定的场景(如电商)
-
如何解决数据稀疏性问题?
- 矩阵分解(SVD, ALS)
- 加入隐式反馈(点击、浏览时长)
- 图神经网络(GNN)聚合高阶邻居信息
-
冷启动问题有哪些方案?
- 用户冷启动:利用人口统计信息/社交关系
- 物品冷启动:结合内容特征(文本、图像嵌入)
- 系统冷启动:用非个性化推荐(热门榜)过渡
- 相似度计算为何用调整余弦而非普通余弦?
- 答: 普通余弦未考虑用户评分偏差(如严苛用户常打低分),调整余弦通过减去用户平均分消除偏差。
六、详细优缺点
优点
- 无需领域知识:仅依赖用户行为数据,通用性强。
- 可解释性(Item-Based): “因为喜欢A,所以推荐相似B” 符合直觉。
- 发现隐式关联:能挖掘非显性特征(如“啤酒与尿布”)。
缺点
- 冷启动问题:新用户/物品无行为数据导致无法推荐。
- 数据稀疏性:真实场景中99%的矩阵可能为空(如百万用户×十万商品)。
- 可扩展性挑战:User-CF计算用户相似度复杂度为 ( O(m^2) ),难以应对大规模数据。
- 流行度偏差:倾向于推荐热门物品,降低长尾覆盖率。
七、优化方向
-
混合模型:
- CF + 内容过滤(Content-Based) → 缓解冷启动
- 例:深度学习模型如NeuMF(神经矩阵分解)
-
图神经网络(GNN):
- 将用户-物品交互视为二部图,通过消息传递聚合高阶关系。
-
加入上下文信息:
- 时间(用户兴趣漂移)、位置、社交关系等。
-
消除偏差:
- 显式建模流行度偏差(如Debiased CF)。
总结
协同过滤作为推荐系统的基石,其核心思想“集体智慧”至今仍被广泛应用。尽管存在稀疏性、冷启动等挑战,但通过矩阵分解、混合模型及图神经网络等技术的演进,CF在现代推荐系统中持续焕发活力。理解其数学本质(如SGD优化、相似度度量)和工程实践(如增量更新、分布式计算),是构建高效推荐系统的关键。