Linux开发工具(apt,vim,gcc)
目录
yum/apt包管理器
Linux编辑器 vim
1.见一见vim
2.vim的多模式
3.命令模式底行模式等
4.vim的配置
Linux编译器 gcc/g++
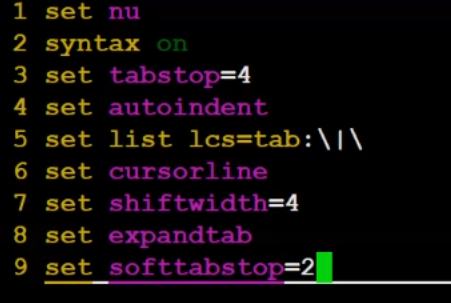
1.预处理(宏替换)
2.编译(生成汇编)
3.汇编(生成机器可识别代码)
4.连接(生成可执行文件或库文件)
几个问题
如何理解条件编译?
为什么C/C++编译,要先变成汇编?
什么叫做动静态库,什么叫做动静态连接,如何理解?
yum/apt包管理器
在Linux系统中安装软件 有三种方法
1.通过源码安装
2.通过软件包安装 --- rpm
3.包管理器 apt/apt -get(Ubuntu) yum(Centos)
源码安装安装过程复杂,技术门槛高,安装时间长,资源消耗大,版本管理和升级困难,因此我们不推荐源码安装
软件包安装,平常安装软件的时候,并非只是安装一个软件,而是要把其所有的依赖也要安装到本地,所以我们安装一个软件,显示是10mb的软件,安装到系统可能是安装了100mb的东西
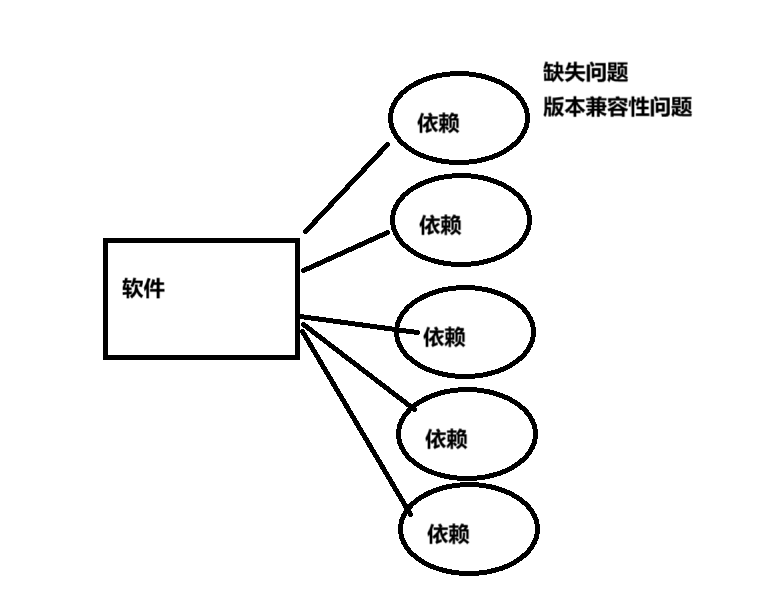
我们平常使用软件包安装时,很容易发生依赖缺失和版本兼容性问题,而一个软件如果依赖缺失,就无法正常运行,或者依赖的版本与软件不一致,也会导致软件发生运行错误,因此我们也不推荐软件包安装。
那么就剩最后包管理器安装了。
安装一个软件,不管怎么样,第一个解决的问题就是先从网络中下载,然后进行安装,安装并不复杂,就是拷贝,所以我们的根目录才会有这么多子目录,bin是装可执行程序的
etc是用来放配置文件的
var是程序运行后写日志的
tmp是程序运行时存放临时文件的
所以Linux系统会分门别类的建立出各种目录,是为了方便 我们在网络下载下来的软件,把其日志,临时文件,动静态库分别拷贝到不同的目录下去进行管理
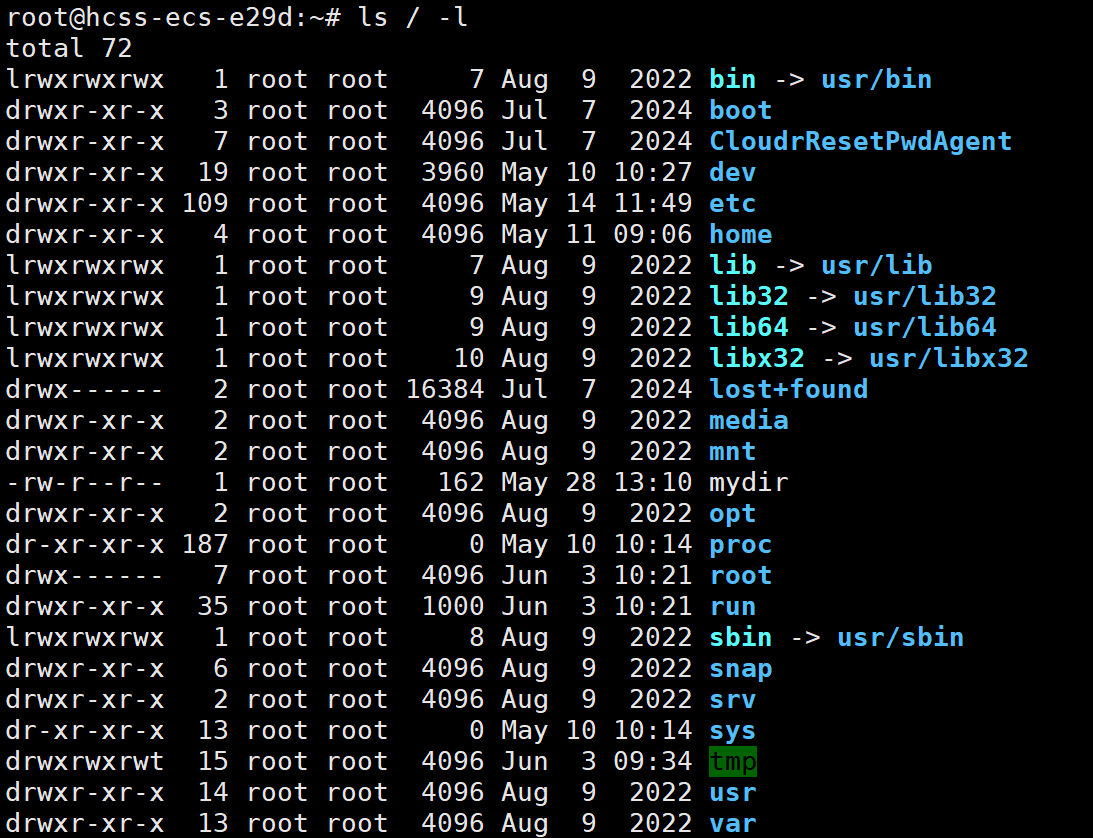
我们可以看到像我上述所说的目录,拥有者所属组都是root,other是无法访问的,这就注定了安装软件时,必须使用root权限,安装到系统

而安装到usr/bin目录下,尽管拥有者和所属组都是root,但是他给了other可执行权限x,这就是为什么usr/bin目录下,随便一个指令任何一个人都能使用的原因,所以在Linux系统中,只要安装一次,任何人都能使用。
因为他没有安装到home目录下,而是系统根目录,谁都能使用
为什么我们推荐包管理器安装,因为他会自动给我们解决包的依赖问题
什么是包管理器
类似于我们手机上面的应用商店
那么问题就来了,你说包管理器类似于我们手机的应用商店,那么我们在手机上下载的抖音,是字节跳动公司提供的,人用的多,他们才能盈利,所以他们提供。
那Linux上的软件,是谁提供的? 那么此时又回到了另一个问题上
如何去评估一个操作系统的好坏?
通过内核版本,社区,文档,适用人群,提供的问题等等,即操作系统的生态问题
那么一款操作系统背后的配套软件算不算生态的一环? 肯定算的,如果一款操作系统没有对应的配套软件,那么他就没有什么竞争力,就会被其他的操作系统所淘汰。
因此为了让操作系统有竞争力,就会提供相应的Linux软件
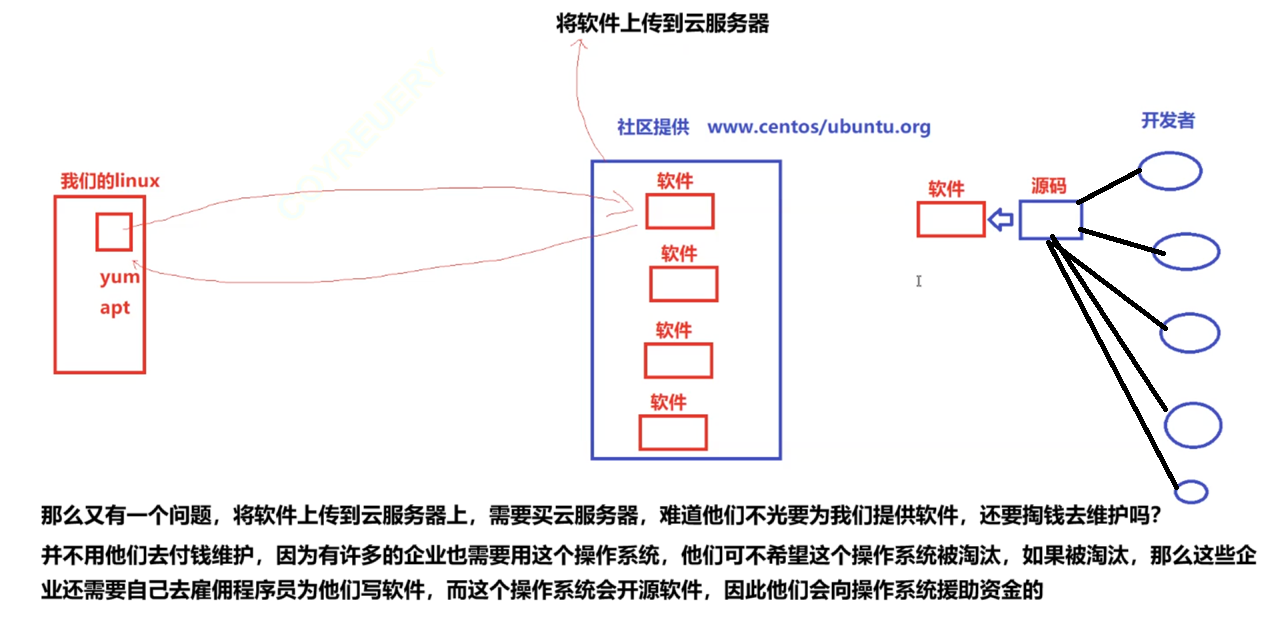
开源:本质是一种商业模式
我的机器怎么知道下载软件的链接呢?
操作系统内置链接
而这个由于操作系统是国外引进国内的,它们的链接都是国外的,而我们如果直接通过链接下载,会非常卡,非常慢,除非我们使用特殊手段。所以我们就在国内将国外的软件镜像到国内,其实就是拷贝一份 ,在把内置链接修改,这样我们下载软件,直接到国内网站下载,就解决了下载卡慢的问题。
演示一下apt install
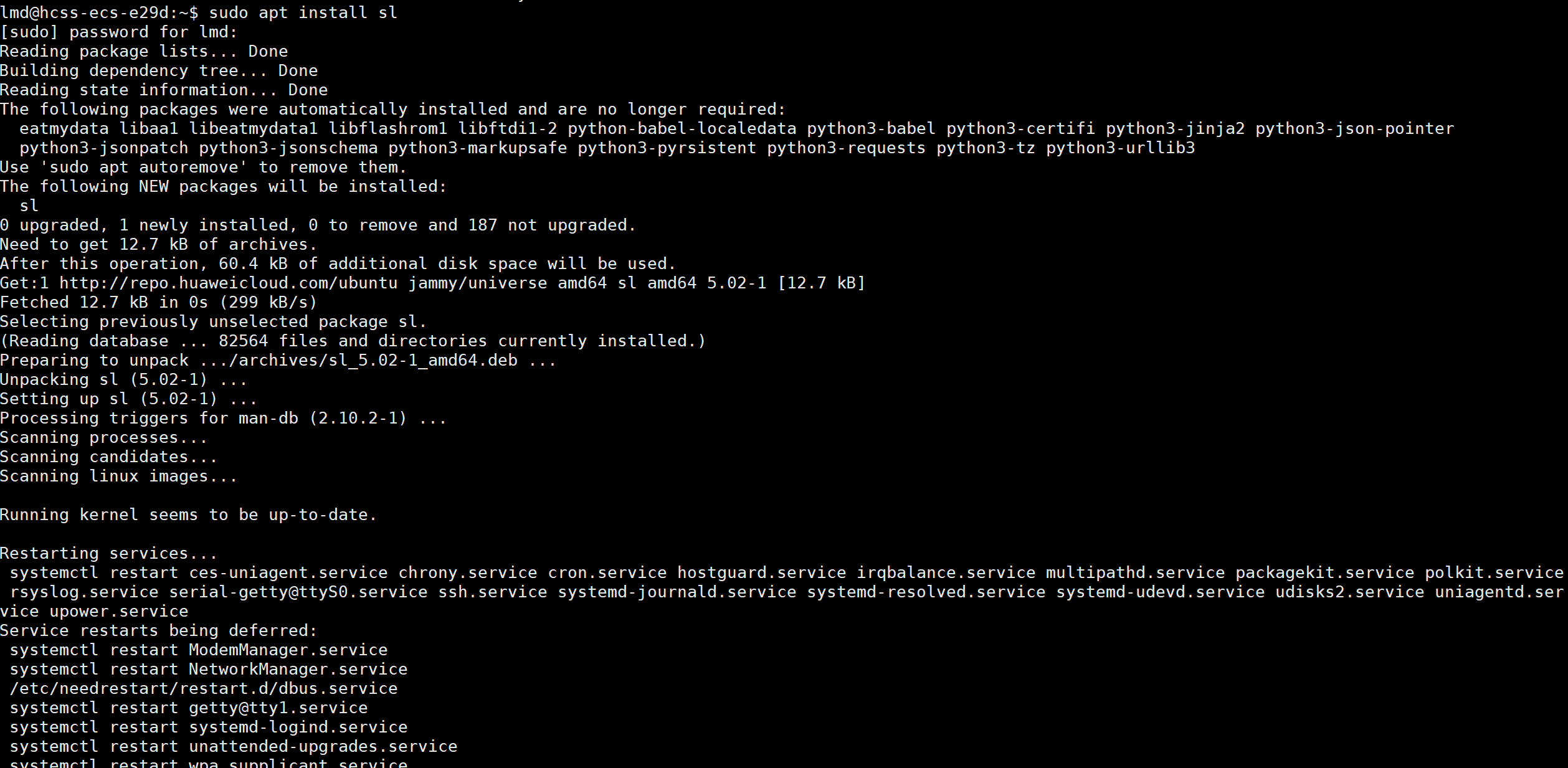
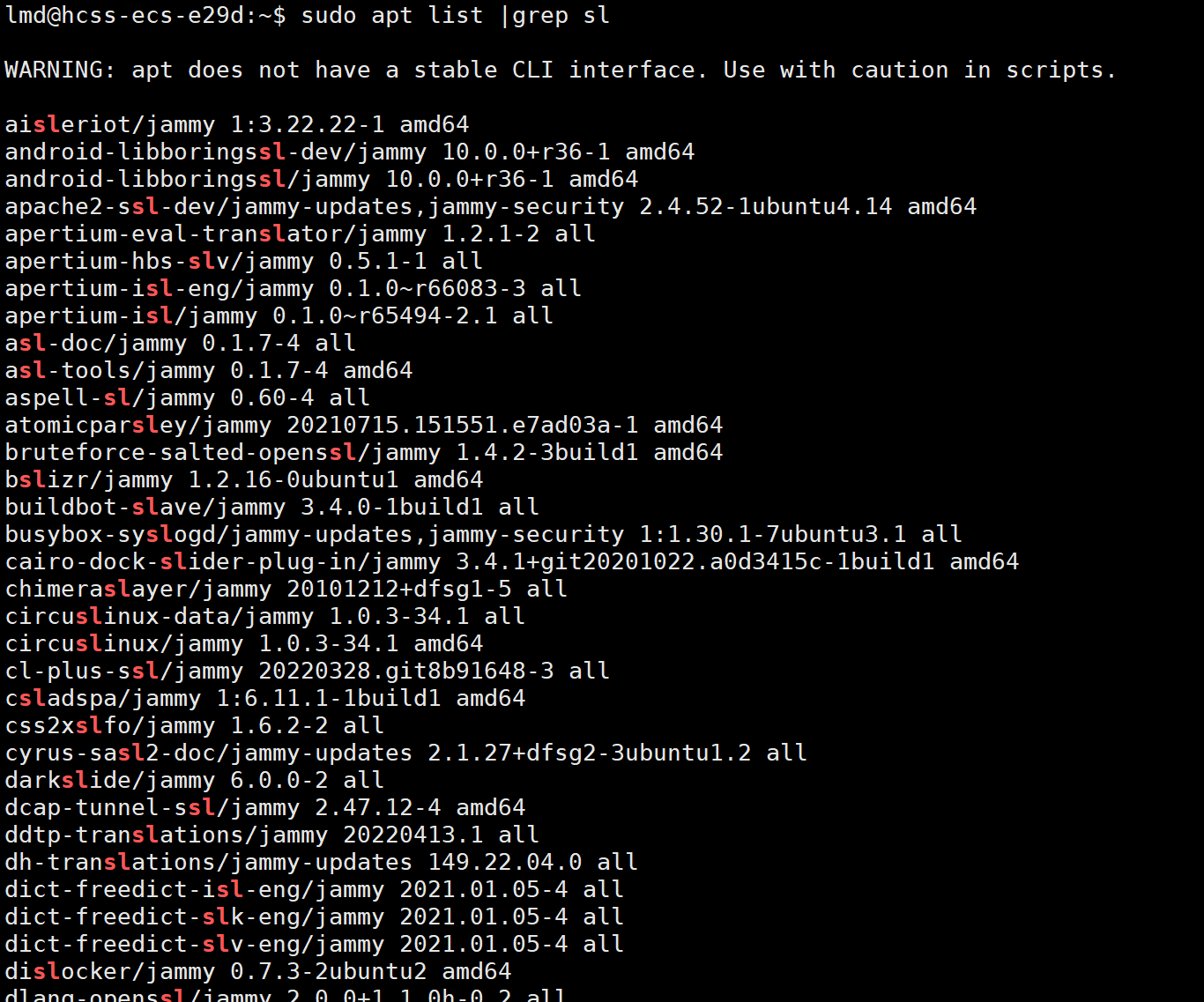
我们通过apt list 命令 可以查看我们能安装的软件
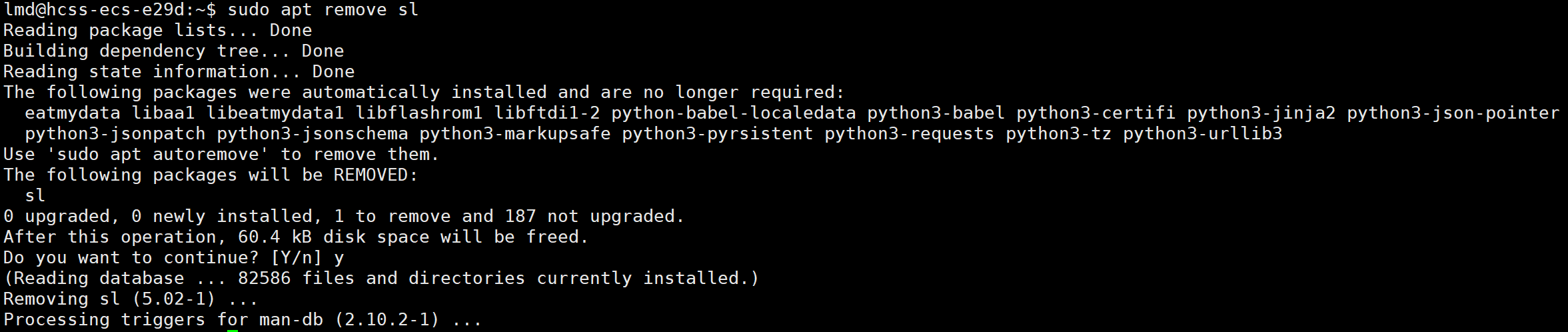
卸载软件 使用 apt remove 命令
 上面的是Ubuntu系统下的命令,Centos系统可以用下面的命令
上面的是Ubuntu系统下的命令,Centos系统可以用下面的命令
在Ce
ntos系统下
在 配置文件 /etc/yum.repos.d/中存在Centos-Base.repo文件,可以通过下面的命令查看
![]()
而这个文件里就是yum源,存在对应的软件下载链接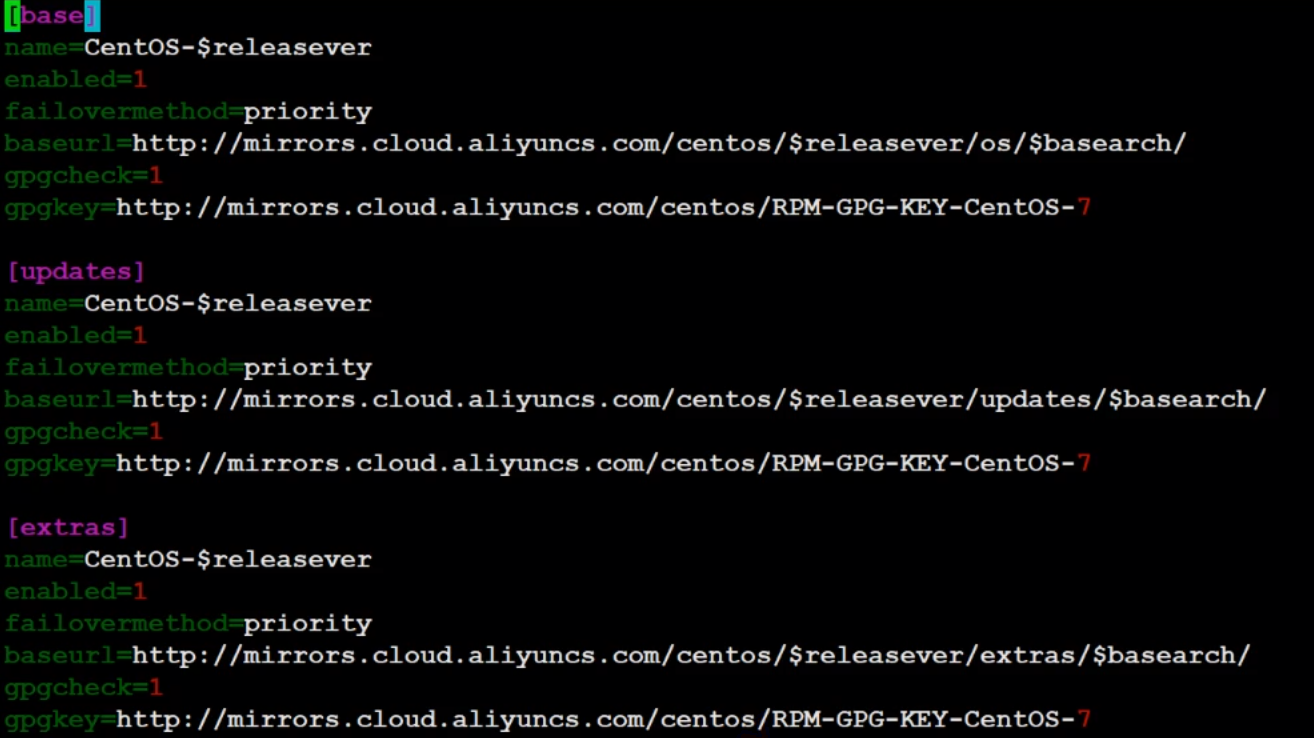
Linux编辑器 vim
我们之前学习C/C++的时候,别人问你写代码用什么,VS2022,调试用什么? VS2022,所以我们之前用的VS2022是集编译编写开发调试发布为一体的集成开发环境,简称IDE,而在Linux下开发,所有的工具都是独立的,写代码用vim,编译用gcc/g++,调代码用gdb,构建用Makefile。
其实IDE底层就是一个个零散的工具,所以在装VS2022的时候,可能安装了好多可执行程序
今天我们学习的vim,是Linux的编辑器
输入vim --version 命令查看你的vim版本
输入vim 可以进入vim
进入后想退出可以,按住shift+ z键 快速按两下自动退出
或者 shift + : 进入底行模式 输入q 回车退出
1.见一见vim
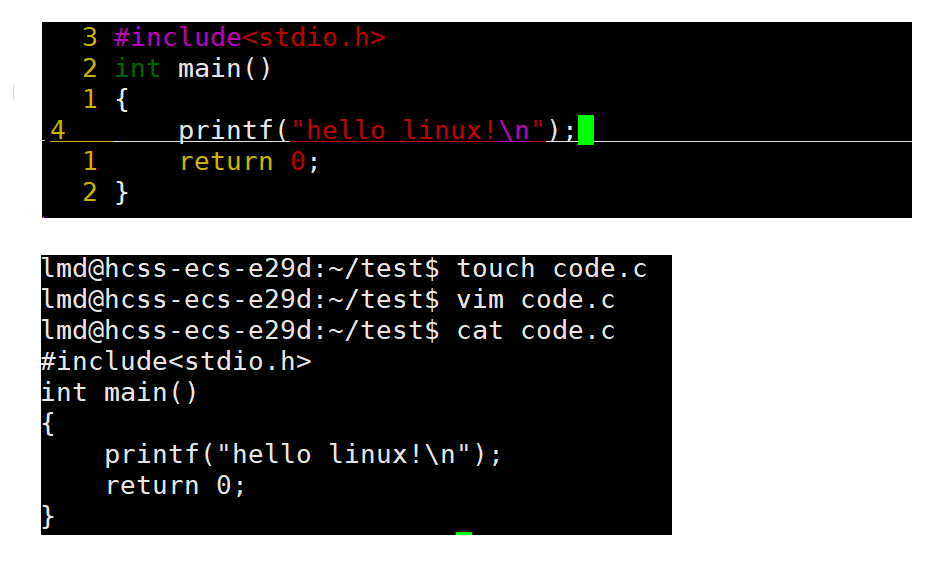
在目录下创建一个code.c
再用vim code.c打开就能对code.c进行编写代码
但是此时你的vim还没有配置,顶多有几个语法提示,像一个记事本一样
2.vim的多模式
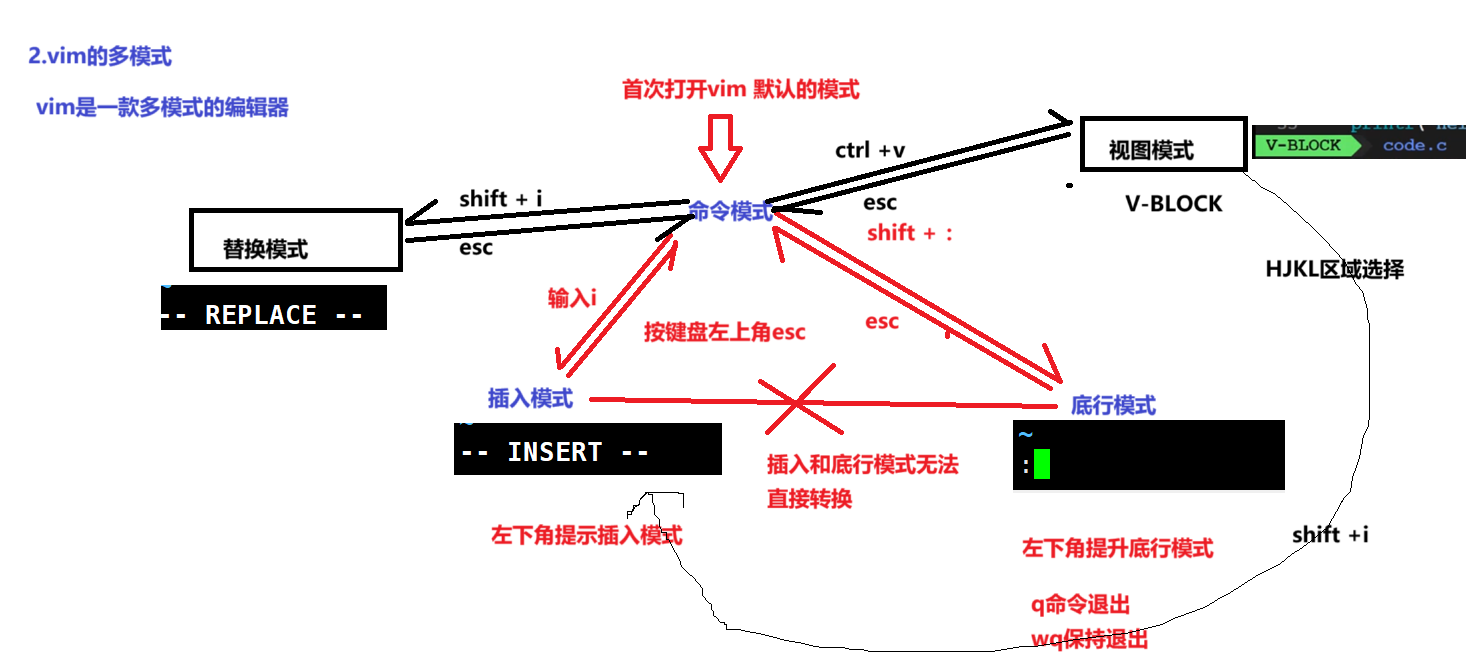
3.命令模式底行模式等
命令模式:
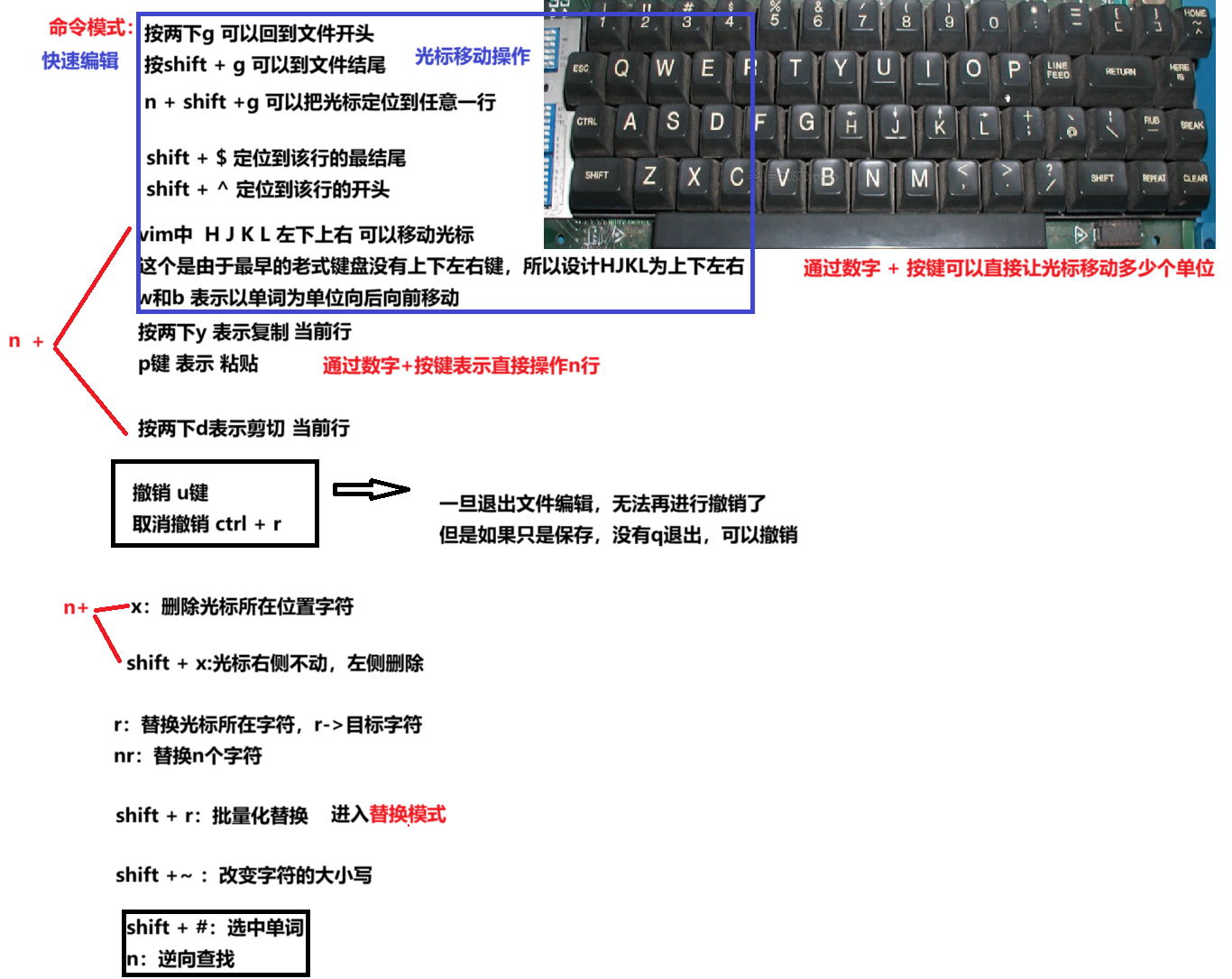
命令模式转插入模式 有三个键 aio
i:从光标位置进入
a:从光标下一个位置进入
o:另起一行进入
底行模式:
w:保存 q:退出 !:强制执行命令
set nu:显示行号 no nu:取消显示行号
底行输入vs + 文件名命令
可以分屏两个终端
我们对应操作,以及底行输命令,都会在光标所在的终端执行
我们可以进行切换光标从左切到右
按两下 ctrl + w 就能实现光标切换
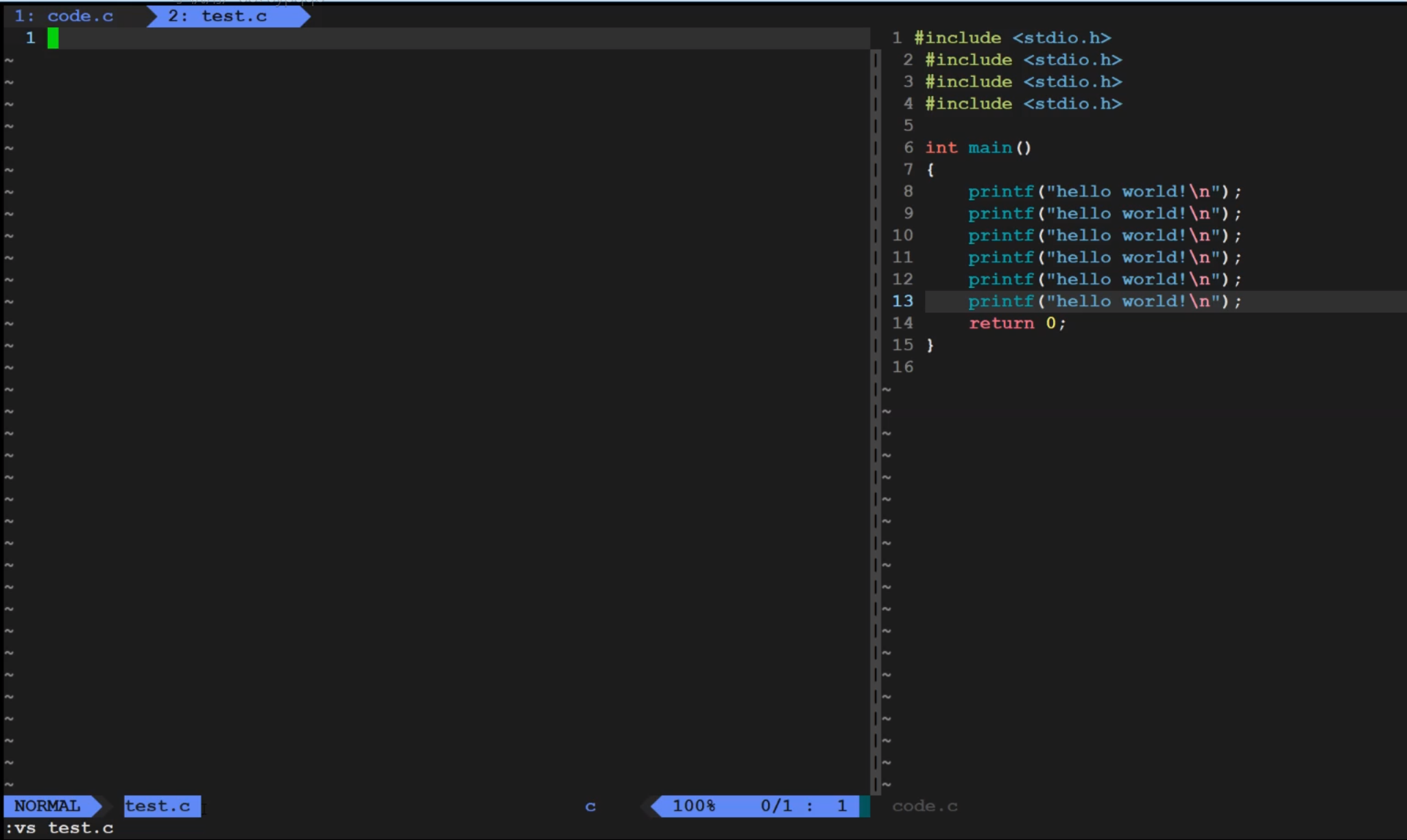
我们使用vs命令,不只局限于两个,可以形成多个分屏终端,三个四个都可以
我们还可以用 /+搜索的内容 ,vim会直接给你把搜索的目标高亮出来,然后按n,可以帮你找到下一个搜索的内容,和shift+#功能重叠
使用vim的小技巧
当你用vim打开文件时,光标会出现在上次退出时光标所在的位置
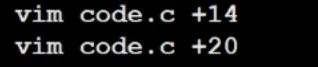
我们可以用 vim src +n 让文件打开时,让光标定位到指定行
在命令行中输入 !后跟字母,系统会查找本地历史上最近的以此字母开头的命令,并执行
!v就会执行vim命令
4.vim的配置
在你自己的家目录下,会存在有些隐藏文件,会存在一个.vimrc的文件,如果没有可以自己创建一个,然后vim打开,可以在里面输入对应的配置信息,这样vim在打开时,会自动在你的家目录中,搜索访问vimrc文件,如果没有,vim就使用默认行为,如果有配置文件,vim就会读取其中的配置项,并进行配置
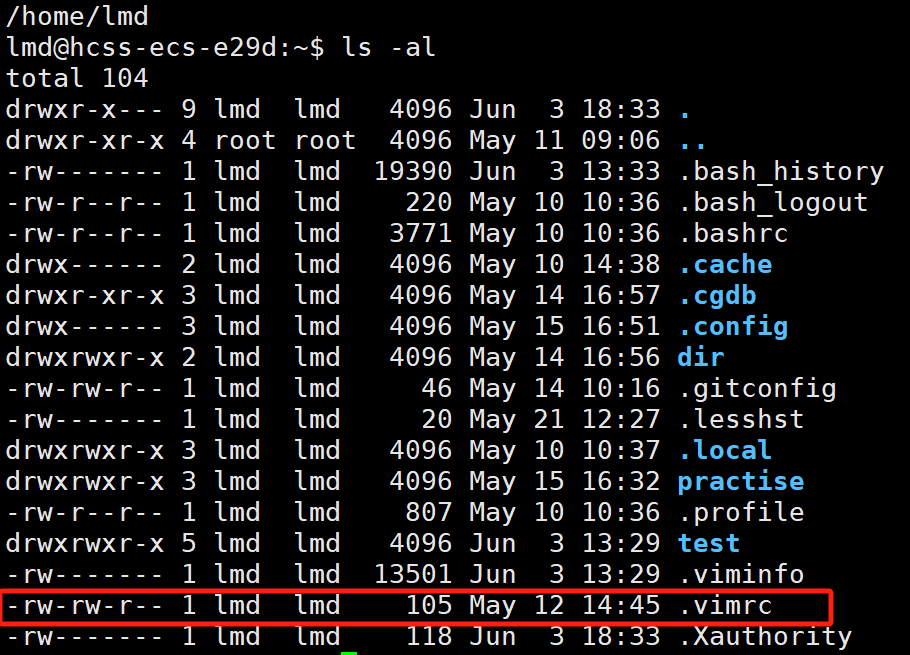
以下就是一些vimrc中的配置信息,他可以设置行号,tab步数,高亮,相对行号,自动折行等等
如果你想配置,可以去网上搜索,直接拷贝一份,粘贴到你对应的vimrc文件中,但是如果想要一些更加高级的功能,自动补齐,分屏操作,就需要打一些插件了
Linux编译器 gcc/g++
gcc和g++对应的选项是完全一样的,只不过gcc只能用来编译c语言,而g++既能编译c也能编译c++
我们用vim写一个code.c文件
在Linux中编译一个程序,通过命令
gcc code.c -o mycode-o表示目标
1.预处理(宏替换)
预处理阶段会完成 头文件展开,去除注释,宏替换
gcc -E code.c -o code.i-E选项表示开始进行程序翻译,在预处理完成后,就停下来
即在完成对文件的头文件展开,去除注释和宏替换后,就形成了code.i的临时文件
那么此时的code.i文件还是c语言吗?
code.i还是c语言
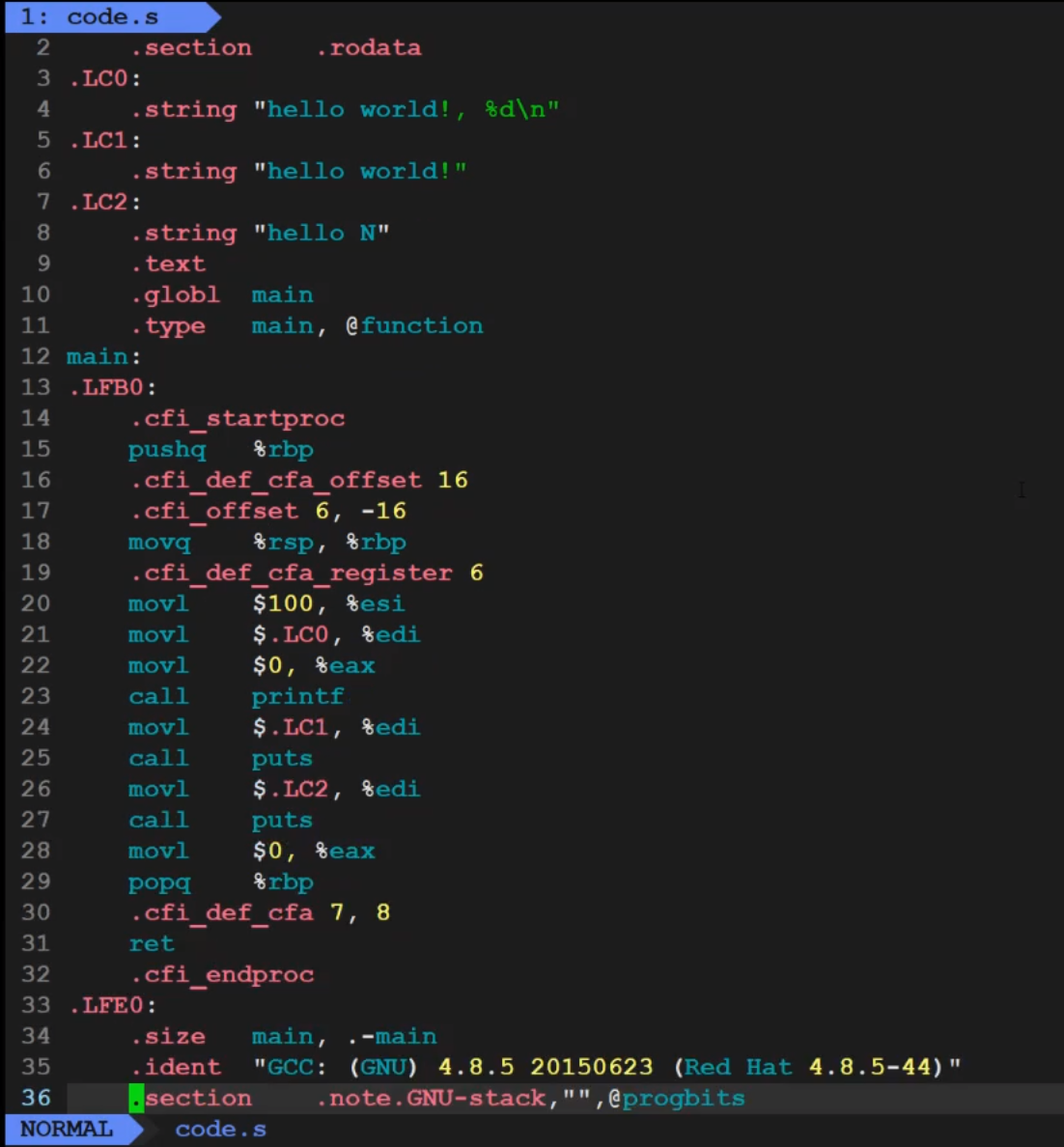
2.编译(生成汇编)
编译将c语言变成汇编语言
gcc -S code.i -o code.s
-S表示开始翻译,编译完了就停下来
3.汇编(生成机器可识别代码)
gcc -c code.s -o code.o-c 表示开始翻译,汇编完成,就停下来
如果我们不带-o选项,默认生成同名.o
code.o叫做可重定位目标文件 ,在win,VS2022中这类文件后缀是.obj
此时.o文件已经变成了一堆乱码,因为它已经变成了二进制文件了
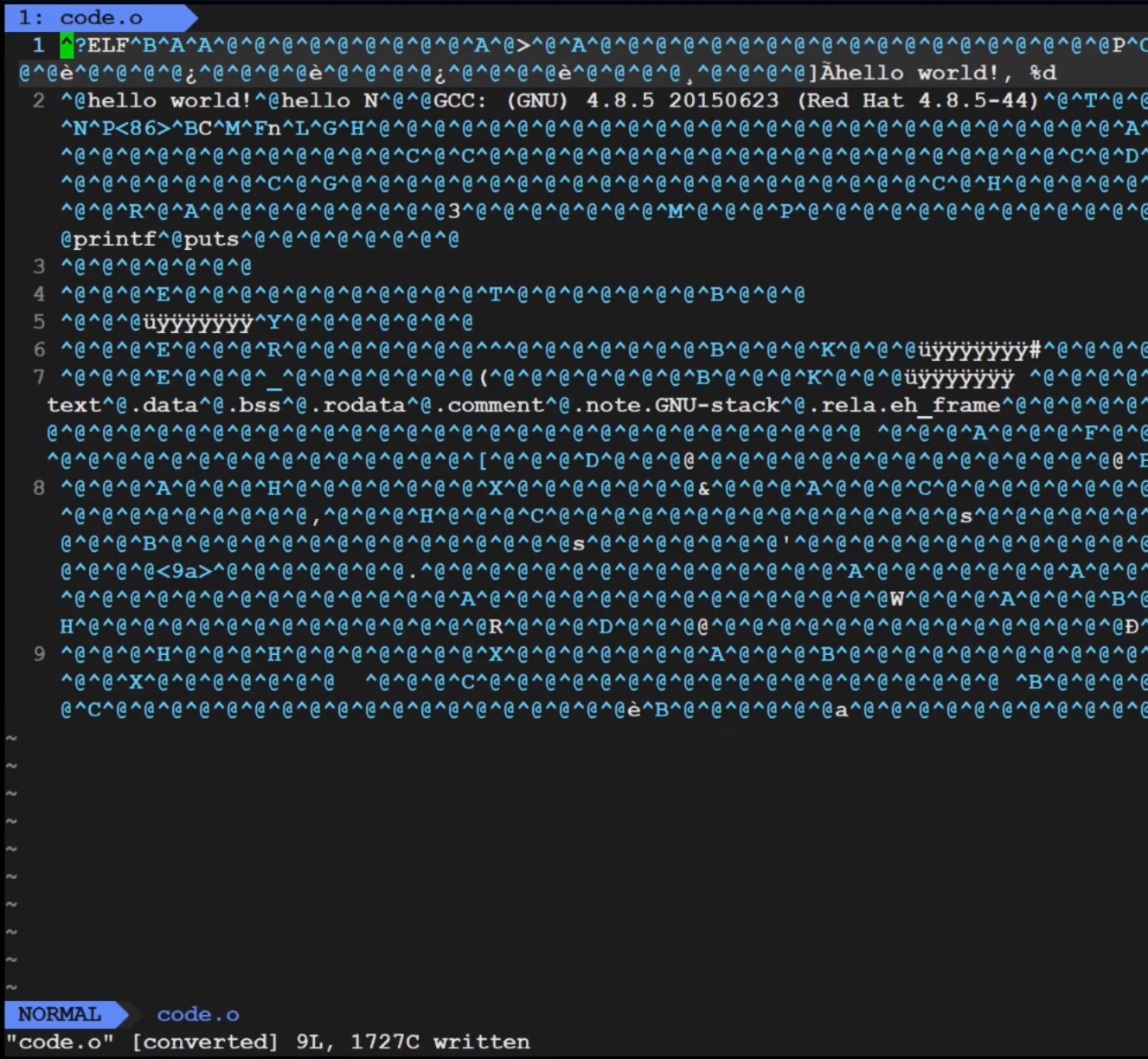
而此时这个文件也没有办法直接执行![]()
即便加上了可执行权限x也无法执行
![]()
我们的源文件中会包含很多的库方法
4.连接(生成可执行文件或库文件)
gcc code.o -o code在Linux中ldd命令可以查看可执行程序依赖哪些库

由于我们的代码中使用了printf函数,这个函数并不是我实现的,我只是调用了printf,那么他的实现在哪里
他的实现在系统的C标准库中
所以我们的c程序需要依赖c标准库
而c标准库就是libc.so
 而库分两类:
而库分两类:
1.动态库: Linux(.so),win(.dll)
2.静态库:Linux (.a),win(.lib)
系统中的可执行程序也要依赖库,我们写的可执行程序也要依赖库
几个问题
如何理解条件编译?
命令行级别的宏定义
![]()
gcc在命令中可以进行动态添加宏 ,-D后面加所要定义的宏,如上就是定义了M
![]()
预处理的本质就是在修改编辑我们的代码
条件编译的用途?
1.软件进行专业度,收费情况进行区分(业务),使用条件编译,可以进行代码动态裁剪
2.内核源代码也是采用条件编译进行代码裁剪
3.通过条件编译来适配开发工具,应用软件
为什么C/C++编译,要先变成汇编?
这个就要追溯到历史原因了,早期计算机没有编程,是通过开关来给计算机输入0/1的,但是过于麻烦,等到七八十年代,用纸带打孔编程,通过光敏信号源,纸带透光不透光来代表0/1,进行编程,但还是二进制编程说到底还是过于麻烦,于是人们发明了汇编语言
有了汇编语言就要有编译器了,来把汇编语言映射成二进制
后来人们觉得汇编语言也太麻烦了
于是汇编语言出现了特别多的分支,70年代丹尼斯里奇发明了C语言
后面就是C++,JAVA,GO等等
此时想一下,有了c语言之后,也是要把c语言变成二进制的,
此时是直接把c语言变成二进制,还是把c语言翻译成汇编语言,再翻译成二进制呢?
我们肯定会选择后者
1.C语言到汇编还是文本语言到文本语言,翻译难度较低
2.在C语言产生时,汇编语言已经发展了好几年了,我们直接把C语言翻译成汇编语言,就省去了将C语言变成二进制语言的过程,算是站在了巨人的肩膀上。
况且如果忽略成本,把C语言直接翻译成二进制,等到C++出现,JAVA出现,还是要继续研发将语言直接变成二进制语言,成本过大了。
因此为什么C/C++编译,要先变成汇编?是因为历史的过程
什么叫做动静态库,什么叫做动静态连接,如何理解?
库是一套方法或者数据集,为我们开发提供最基本的保证(基本接口,功能,加速我们二次开发)
libc.so libc.a
在Linux中,库的命名有固定规则
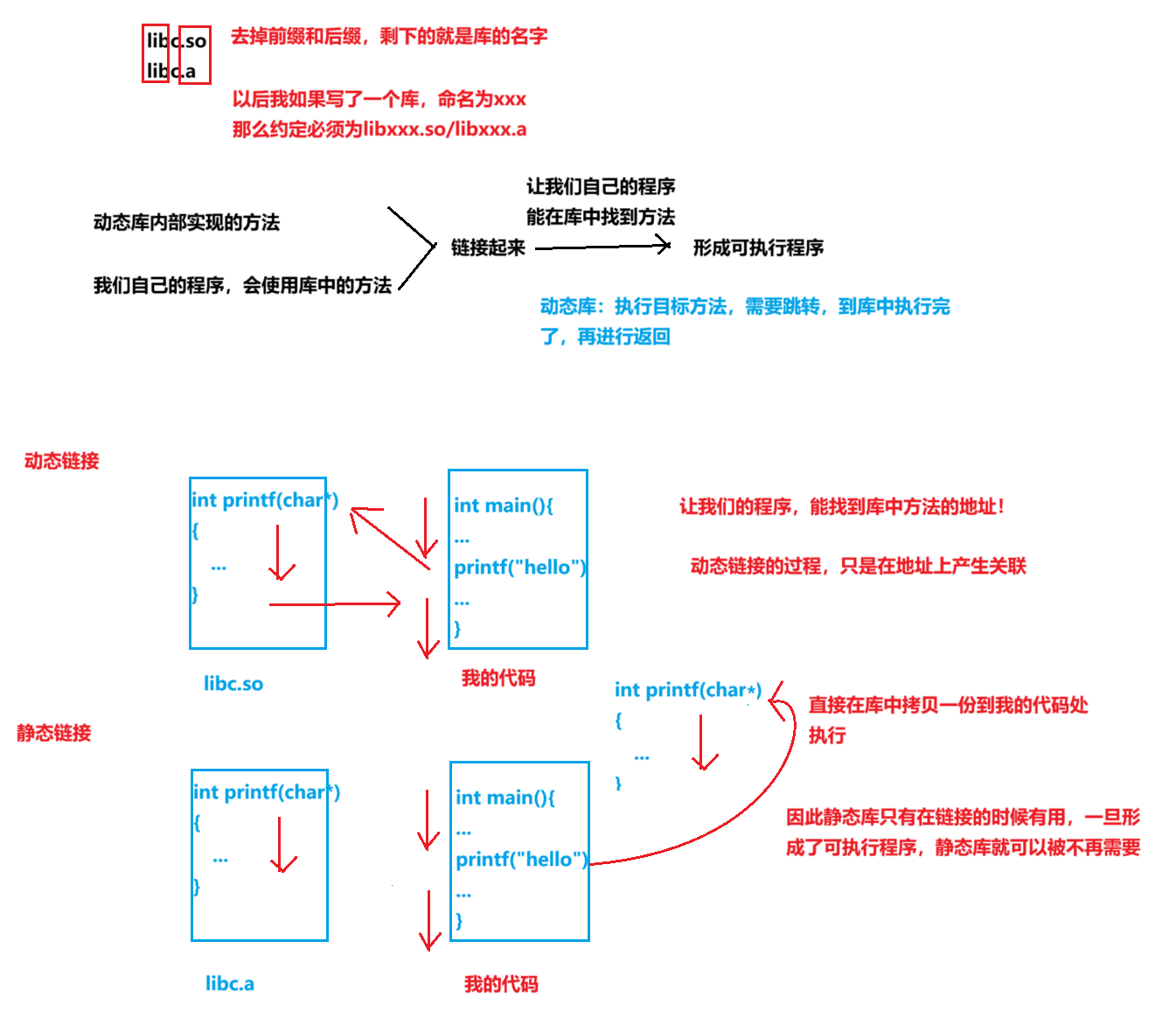
动静态库的对比
- 动态库形成的可执行程序体积一定很小
- 可执行程序对静态库的依赖度小,动态库不能缺失
- 程序运行,需要加载到内存,静态链接的,会在内存中出现大量的重复代码
- 动态链接,比较节省内存和磁盘资源
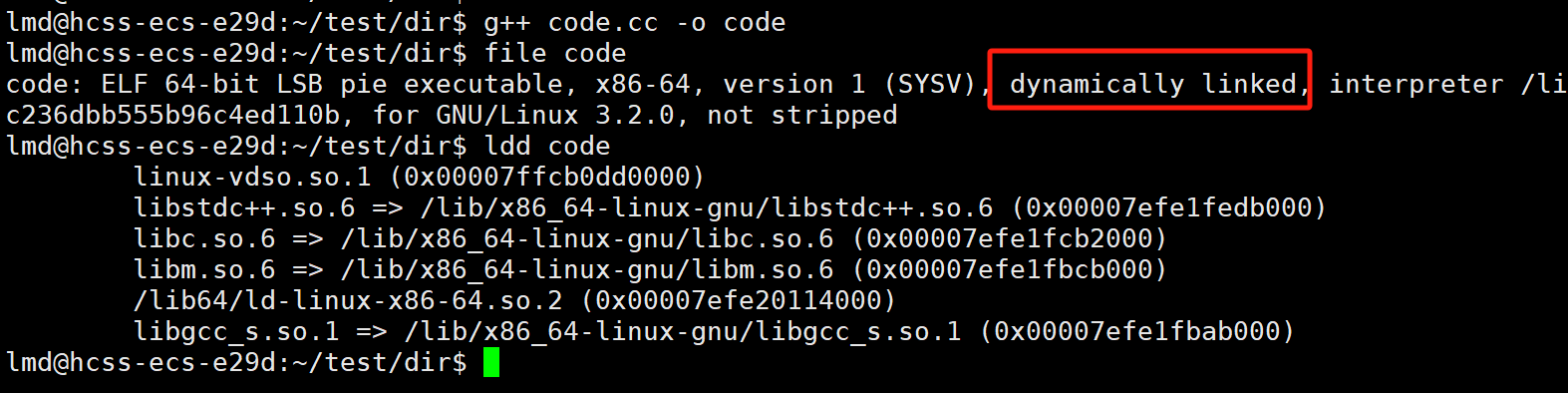
我们在使用gcc编译可执行程序,默认就是动态链接
我们用file命令,查看code,也能看到其为动态链接
 进行动态链接的前提是这个库必须存在
进行动态链接的前提是这个库必须存在

很显然它是存在的
如果想进行静态链接,是需要我们手动添加选项的 ,且C静态库也要存在

我们用ldd命令去查,可执行程序所依赖的库,是没有办法查到的,因为他是静态链接,没有依赖的库
我们可以看一下动态链接的程序和静态链接的程序的大小差异

可以发现静态比动态程序的大小多了特别多
g++编译C++程序也是一样的,默认动态链接