PPO: Proximal Policy Optimization Algorithms
一、PPO 的创新点与思路
(一)模型训练流程
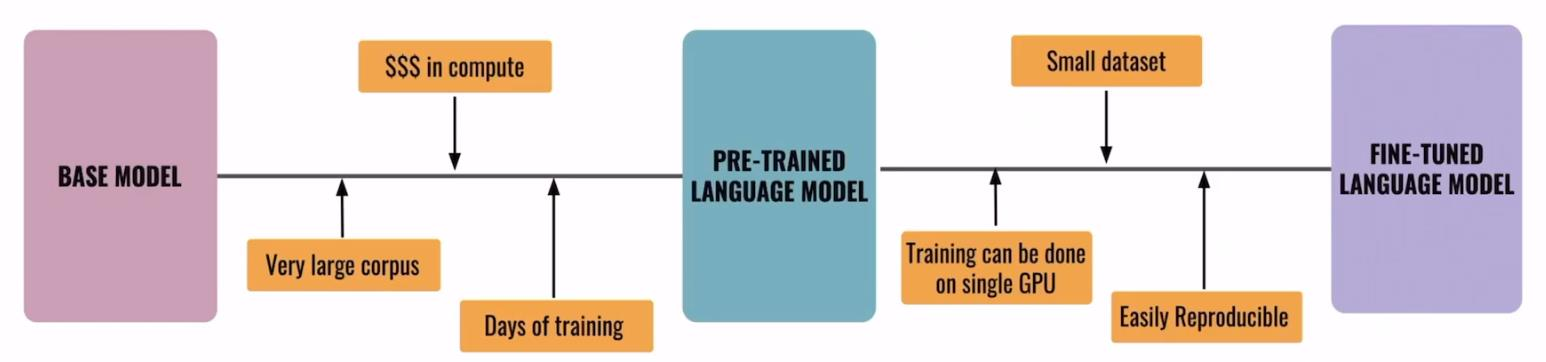
模型训练包含预训练(Pretrain)和微调(Fine-tuning)两个阶段。预训练是让模型学习通用的特征表示、语言模式等能力的过程,此阶段基于非常大的语料库,可在单个 GPU 上完成训练,训练时长通常为几天,且易于复现。微调则是对预训练模型的参数进行小范围调整优化,使模型学习指令跟随、对话等能力,该阶段适用于小数据集。
(二)ChatGPT 训练流程
ChatGPT 的训练分为三个步骤。第一步是收集示范数据并训练监督策略,从提示数据集中采样一个提示,由标注员展示期望的输出行为,这些数据用于通过监督学习对 GPT-3 进行微调,例如向 6 岁儿童解释登月事件。第二步是收集比较数据并训练奖励模型,采样一个提示和多个模型输出,标注员对输出从最佳到最差进行排序,这些数据用于训练奖励模型,如对关于解释月亮、重力、战争等内容的不同输出进行排序。第三步是使用强化学习针对奖励模型优化策略,从数据集中