InternLM2/LM2.5/ViT/VL1.5/VL2.0笔记: 核心点解析
00 前言
本文主要是记录一下关于多模态大模型InternLM/InternVL系列的一些要点的理解。还是那句话,好记性,不如烂笔头。本文当成个人笔记用,行文风格和先前写的LLaVA系列一致。本文的重点是讲解多模态模型InternVL 1.5,但是InternVL 1.5选择了InternLM2作为LLM底座,以及使用InternViT-6B作为视觉理解模型。因此,本文也先从InternLM2和InternViT开始讲起。InternLM2和InternViT以简单说明为主。推荐先阅读,DefTruth:[LLaVA系列] CLIP/LLaVA/LLaVA1.5/VILA笔记(https://zhuanlan.zhihu.com/p/683137074)。
01 InternLM2 简析
-
InternLM2 模型结构: LLaMA + GQA

InternLM2模型结构
InternLM2采用了LLaMA的模型结构,并且和LLaMA一样,使用了GQA。LLaMA大家都比较熟悉了,就不再重复说明了。不过比较有意思的是,为了提高Tensor Parallel的效率,InternLM2对Wqkv的权重进行了交织重排,下一小节将会继续介绍这个技术。
Interleaving Wq, Wk, Wv

InternLM2权重交织
InternLM2对比InternLM一个比较大的改变就是,对Wqkv的堆叠权重矩阵进行了交织重排,根据论文的说明,这个操作降低了Tensor Parallel下权重矩阵分发的复杂度。InternLM采用和LLaMA完全一样的做法,Wqkv是由Wq, Wk和Wv顺序stack在一起构成,这种做法,在使用Tensor Parallel时,需要执行更多的操作(比如各种slice、cat)才能将权重矩阵正确地切分到不同的GPU上,导致这块会产生一个非常碎片化的子图,对backward/forward效率都有一些影响。而InternLM2的Wqkv矩阵不是直接顺序stack的,而是对三个矩阵进行交织重排(上边这个图表达地应该很清晰了),使用Tensor Parallel的时候,只需要一个split操作就能完成矩阵切分,减少了大量冗余的操作。这个交织重排操作,大概能提高5%的训练效率

不过,这个权重交织的操作,虽然可以提升训练效率,但是对下游的部署任务来说,就不是那么友好了。虽然InternLM2是LLaMA结构,但是Wqkv使用权重交织后,就没办法使用常用的部署方式了。因此,目前看到社区对InternLM2的部署支持也分为两种方式,分别是(1)LMDeploy原生支持,LMDeploy无缝衔接InternLM2系列的部署,开箱即用,性能也不错;(2)de-Interleaving Wq, Wk, Wv -> LLaMA,即先对权重解交织,还原成标准的LLaMA结构和参数保存格式,然后就可以开心地使用现有的众多框架进行部署了。InternLM官方也提供了转换工具,非常nice,具体请参考:
InternLM Convert Toolshttps://github.com/InternLM/InternLM/tree/main/tools
其中解交织部分的代码如下。这个gs表示就是上图中有多少个query head和kv的权重交织在一起,num_key_value_groups就是query head的数量,这些query head对应相同的KV,2是指k和v各占一份。torch.split在dim=1按照 [num_key_value_groups, 1, 1] 进行切分,这是由于使用了GQA,多个query head对应一组KV head,在split的时候要符合GQA的要求。split得到Wq,Wk,Wv权重矩阵后,在reshape回原来的二维矩阵的维度。其他剩余的逻辑主要就是权重name的一对一匹配了,这个很好理解。关于rearrange用法,推荐阅读(非常清晰):科技猛兽:PyTorch 70.einops:优雅地操作张量维度(https://zhuanlan.zhihu.com/p/342675997)
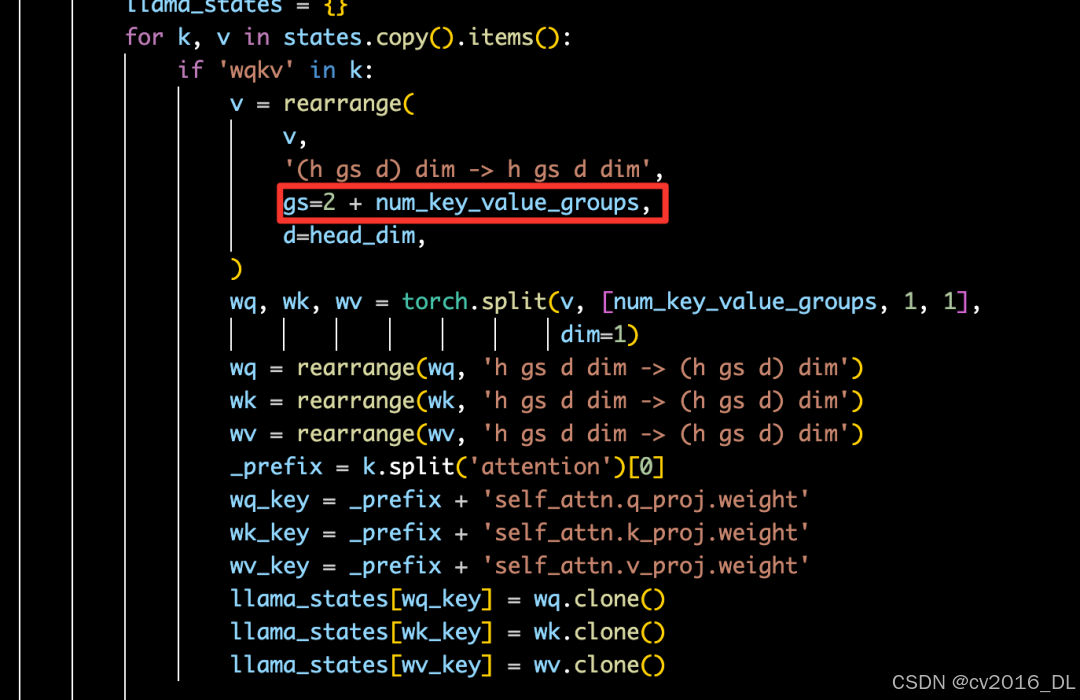
权重解交织逻辑

num_key_value_groups计算逻辑
-
TensorRT-LLM中的InternLM2权重解交织
另外,目前在TensorRT-LLM中,支持直接使用InternLM2原生模型进行checkpoint转换、build engine和推理,我们可以从convert_checkpoint.py中的逻辑可以看到,其中执行了权重解交织操作,然后使用TensorRT-LLM的API进行权重的赋值以及组网操作,并且调用了tensorrt_llm.models.llama中的convert组件,来对权重进行正确的转换。不过,在目前的实现中,还不支持FP8/SQ量化,只支持Weight Only。因此,如果需要走FP8量化部署的方案,还是建议走”de-Interleaving Wq, Wk, Wv -> LLaMA“的方案。TensorRT-LLM中示例见:https://github.com/NVIDIA/TensorRT-LLM/tree/main/examples/internlm2
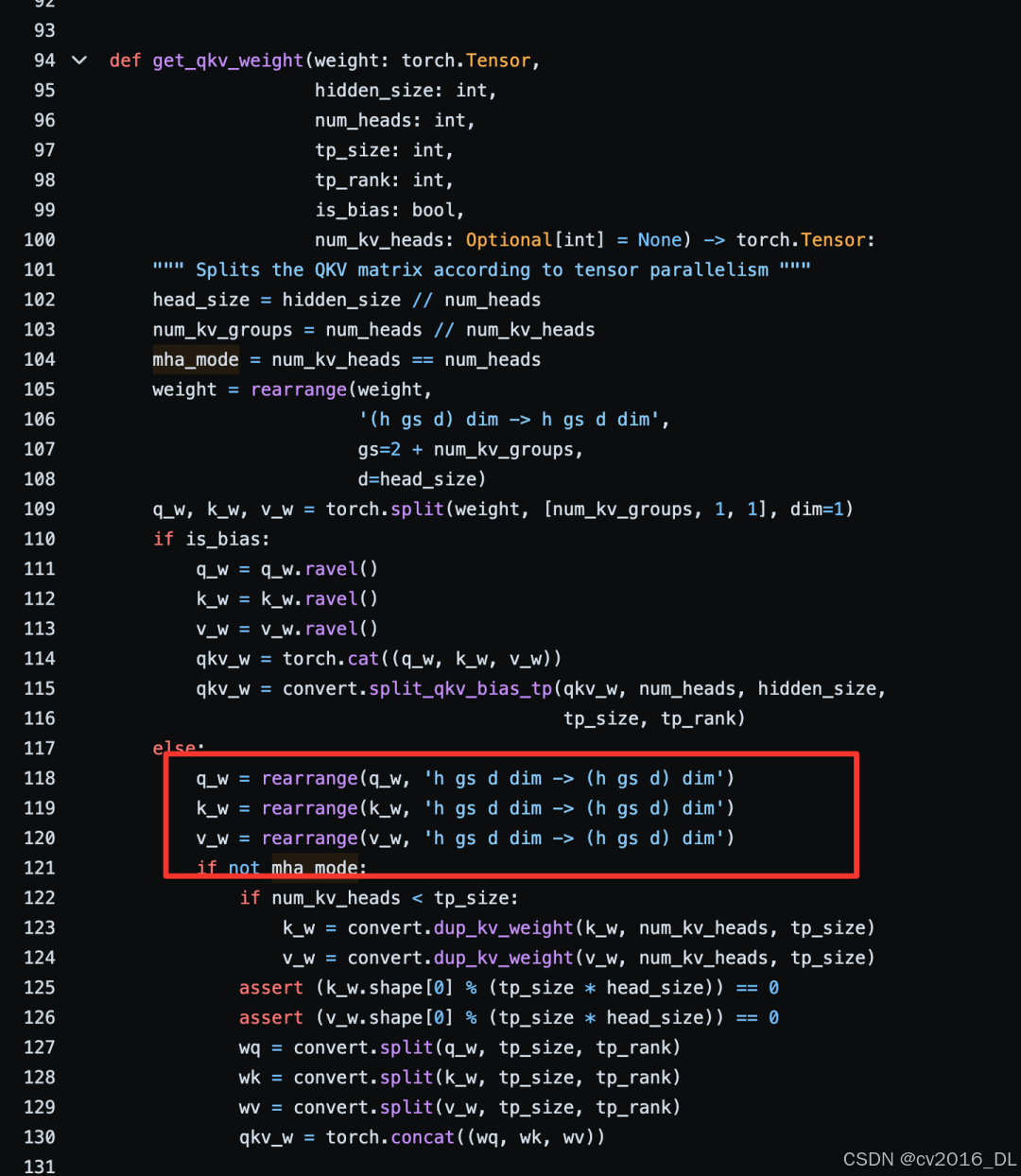
TensorRT-LLM InternLM2 权重解交织
-
LMDeploy中的InternLM2的权重解交织
另外,我们再回到LMDeploy的源码看下交织后的权重是如何妥善处理,并利用TurboMind后端推理的。具体代码如下。从代码中看到,LMDeploy的实现,实际上也是先将权重进行解交织,并且对权重按照name一对一匹配,接着使用LLaMa结构进行转换,InternLM2Reader继承的是LlamaReader。详细代码见:
https://github.com/InternLM/lmdeploy/blob/main/lmdeploy/turbomind/deploy/source_model/internlm2.py
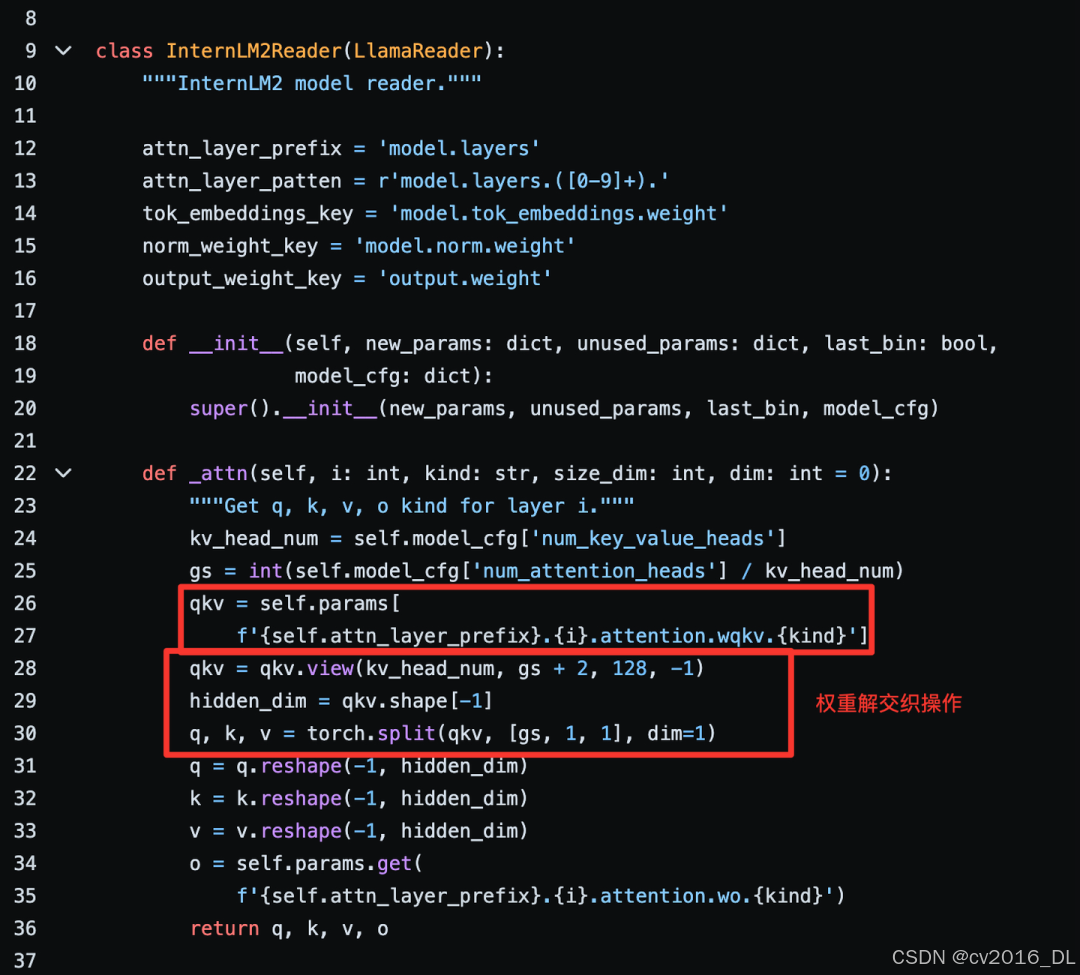
LMDeploy中的权重解交织
-
vLLM中的InternLM2权重解交织
作为LLM推理主流框架之一的vLLM,自然也是支持InternLM2的部署,大致瞄了一眼其中的实现,对于权重解交织的处理和TensorRT-LLM以及LMDeploy是完全一致的。(PS:这么说,权重交织这个事儿对于推理来说是不是有点多余了,实际部署的时候全都是得先解交织一遍...),代码见:
https://github.com/vllm-project/vllm/blob/main/vllm/model_executor/models/internlm2.py#L313
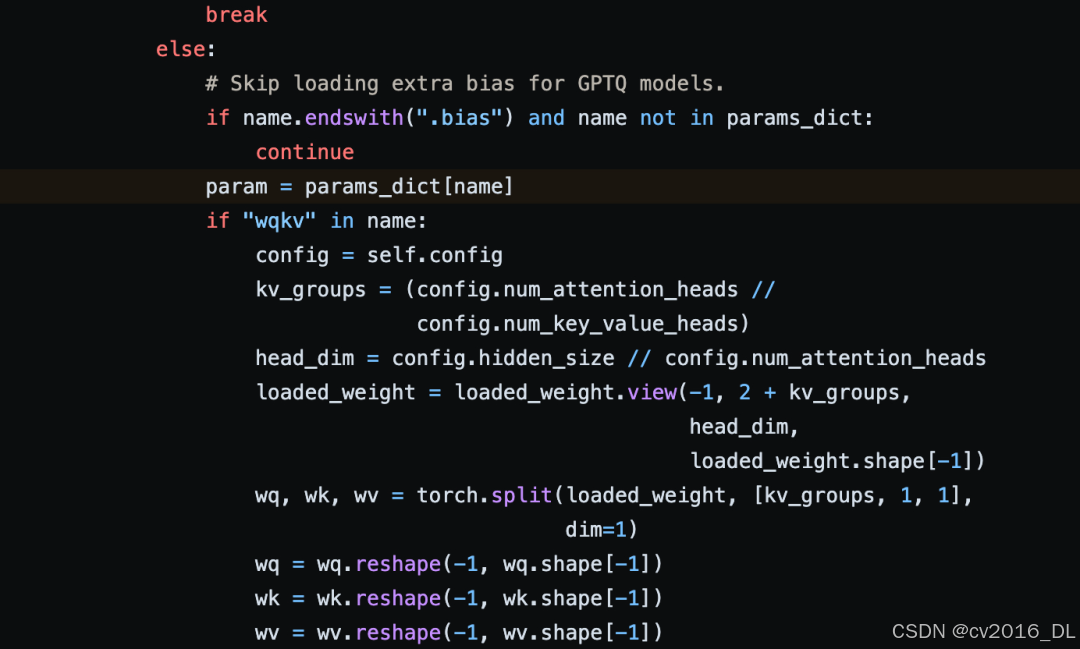
InternLM2权重交织
02 InternLM2.5简析
-
InternLM2.5最新进展
2024年7月3日,InternLM团队发布了InternLM2.5,模型结构和InternLM2一样,效果更好。大概看了下,这次主要是更新了7B系列的Chat模型。其中InternLM2.5-7B-Chat-1M模型支持百万长度的上下文窗口。这次发布的主要核心点有三个:(1)卓越的模型推理能力,在数学推理的任务上达到了SOTA,超过了同等规模参数量的其他模型,如LLaMA3-8B和Gemma-9B;(2)支持百万长度上下文长度的推理,并且可以通过LMDeploy快速部署,开箱即用(PS: 他们家训推一整套无缝衔接做的真的太棒了!赞!LMDeploy性能和用户体验都不错。);(3)增加了更多的应用工具的支持,比如快速对大量的网页信息进行聚合,后续也将会整和到Agent工具中。
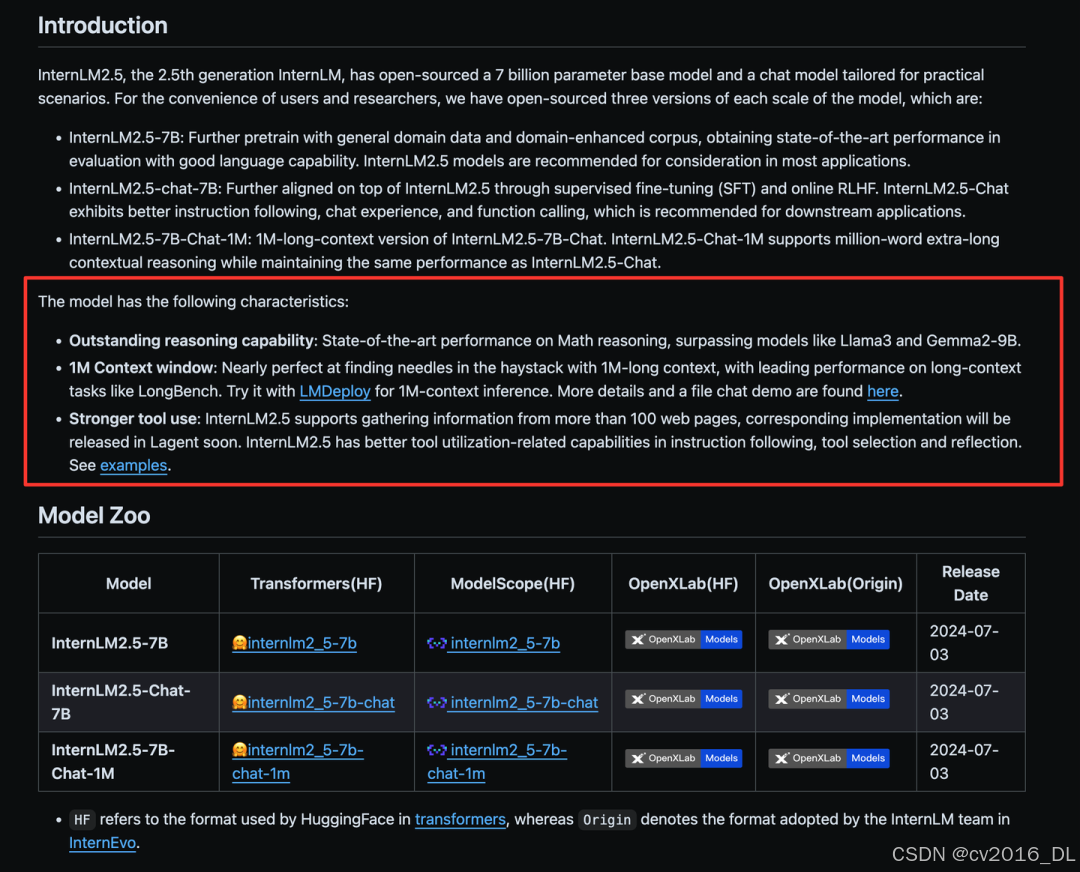 InternLM2.5
InternLM2.5
-
InternLM2.5 Benchmark
可以看到,InternLM2.5 7B Chat模型在多项任务上都达到了同等参数规模模型的SOTA水平,并且在Math任务上,比LLaMA3-8B-Instruct和Gemma2-9B-IT要高出一大截啊,说实话,有点被震惊到了。
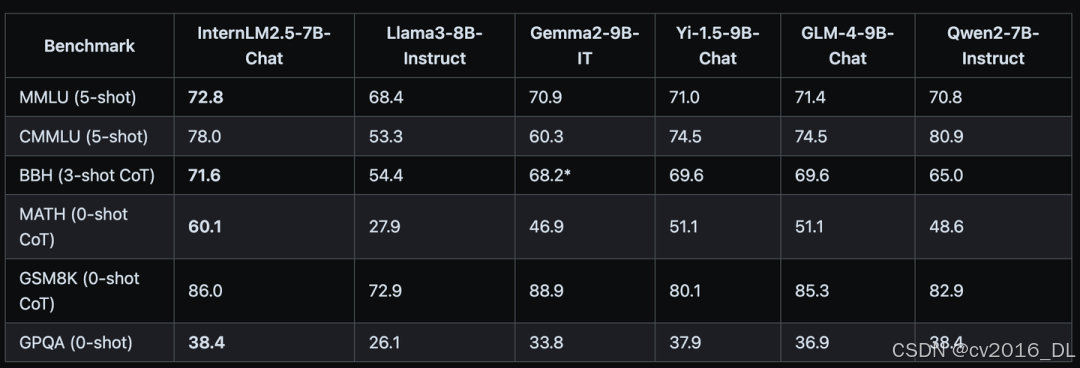
InternLM2.5 Benchmark
03 InternViT简析
-
InternViT模型结构解析

InternViT-6B
InternViT-6B采用的就是经典的ViT模型结构,作为InternVL的视觉模块进行使用,不单独使用。ViT参考文献:arxiv.org/abs/2010.1192(https://arxiv.org/abs/2010.11929)9;ViT经典模型结构如下:
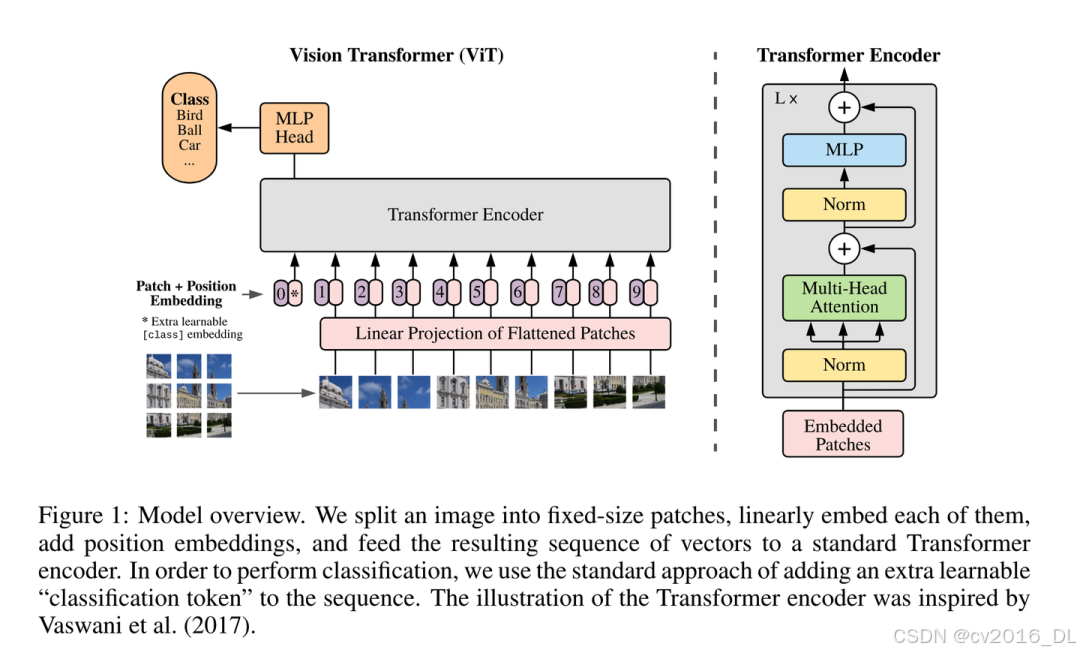
ViT经典模型结构
从实现的代码上看,InternViT主要由VisionEmbeddings和VisionEncoder两个大模块组成,VisionEmbeddings负责将图像编码成Embedding,并且position embedding采用了可学习的方式,forward时,会将图像patch embedding和position embedding相加,得到ViT的输入,然后送入VisionEncoder进行推理。VisionEncoder中包含多层标准的Transformer层,也就是InternVisionEncoderLayer。
更详细的实现,可以参考官方的代码:https://github.com/OpenGVLab/InternVL/blob/v2.0.0/internvl_chat/internvl/model/internvl_chat/modeling_intern_vit.py
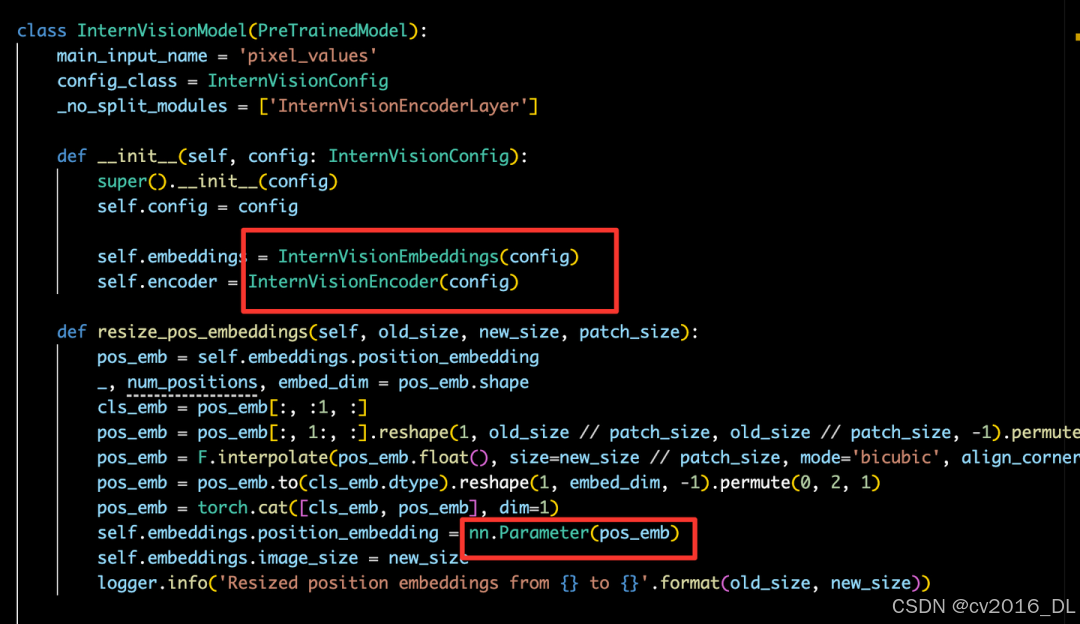
InternViT模型源码

position embedding
04 InternVL1.5简析
-
InternVL1.5整体结构
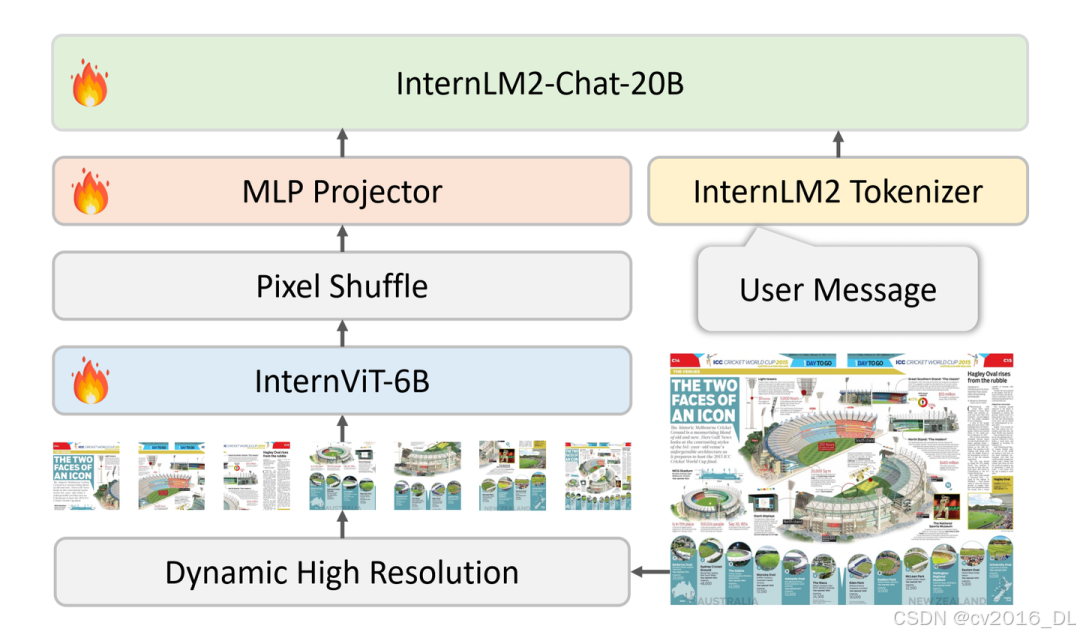 InternVL1.5整体结构
InternVL1.5整体结构
InternVL 1.5整体结构包括3个部分:ViT、MLP Projector和LLM底座。ViT模型选择的是一个6B的模型,作为强视觉特征提取器,参数规模由以前的几百M,跃升到和大模型一个级别;MLP Projector则是负责将视觉特征和语言模型的特征空间进行对齐,InternLM2-Chat-20B的embedding维度是6144,MLP Projector会将视觉特征转换到相同的维度;LLM底座选择的是自家的InternLM2-Chat-20B。InternVL 1.5的总体参数量是26B。并且,在整体框架中我们还看到另外两个技术手段,分别是Pixel Shuffle和Dynamic High Resolution;Pixel Shuffle主要是用来重排ViT提取到的pixel feature,目的是减少visual token的数量并保持特征信息不丢失,而Dynamic High Resolution,即动态高分辨率,则是为了让ViT模型能够尽可能获取到更细节的图像信息,提高视觉特征的表达能力。接下来,本文会对这个两个技术做详细的解析。
-
Pixel Shuffle: 减少visual token数量
Pixel Shuffle在超分任务中是一个常见的操作,PyTorch中有官方实现,即nn.PixelShuffle(upscale_factor) 该类的作用就是将一个tensor中的元素值进行重排列,假设tensor维度为[B, C, H, W], PixelShuffle操作不仅可以改变tensor的通道数,也会改变特征图的大小,先看官方文档:
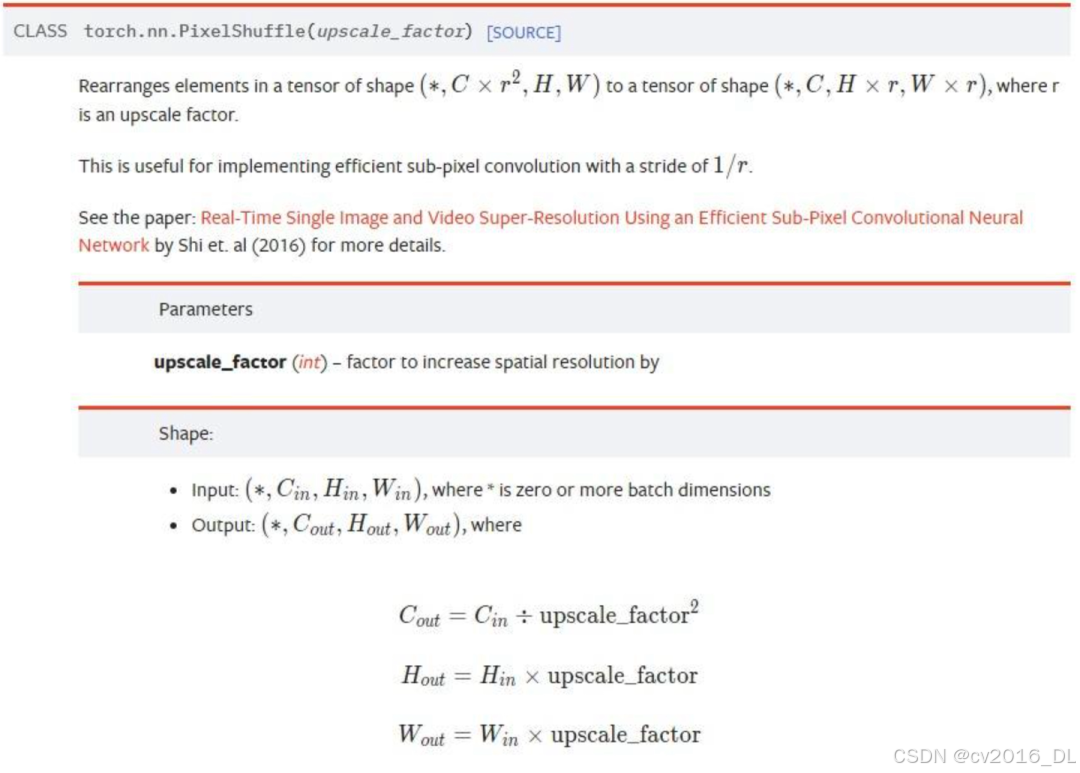 nn.PixelShuffle
nn.PixelShuffle
即把维度(B, C x r x r, H,w) reshape成 (B, C, H x r,w x r), 给出的例子,假设upscale因子是3,输入通道是9,则输出通道是9/3/3=1, 输出大小为输入大小乘以upscale。nn.PixelShuffle的解释,参考自:像阳光 像春天:torch.nn.PixelShuffle(upscale_factor)函数详解(https://zhuanlan.zhihu.com/p/562932795)。如果upscale_factor值大于1,则相当于H,W变大,channel数变少,是一个上采样操作。InternVL 1.5中的pixel shuffle与torch中略有不同,但原理是一样的,InternVL 1.5中是自己写了一个pixel shuffle的操作,他的这个操作刚好相反,是一个下采样操作,实际使用的scale_factor为0.5,其实就相当于把更多的像素保存在channel维度上,所以pixel shuffle后,H, W变小了,channel数变多了。对于scale_factor,比如0.5,pixel shuffle将输入[N, W, H, C]转换成shape为[N, H x scale, W x scale, C//(scale^2)]的Tensor。

pixel shuffle
我们来看下InternVL-Chat-V1.5中的实际调用链路,具体逻辑如下图,其中pixel_values是指组batch后原始的图像输入,比如shape为[5,3,448,448]。InternVL 1.5中默认select_layer为-1,即提取最后一层的hidden_state作为feature map。提取到feature map之后就会调用pixel shuffle函数对feature map进行处理。
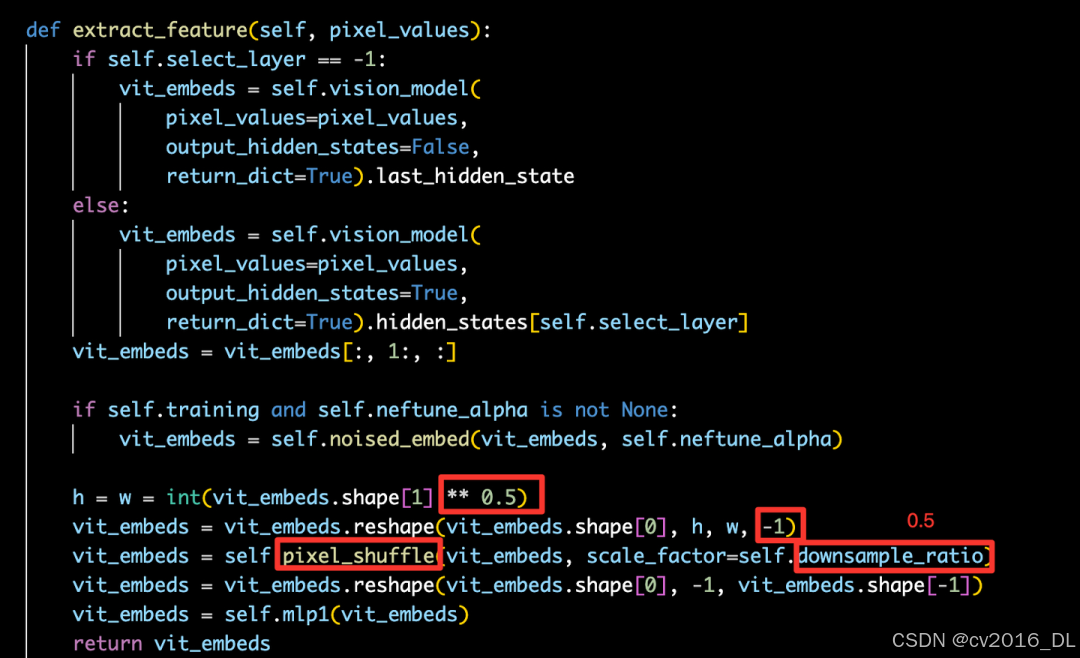
pixel shuffle at extract_feature
通过打印日志,我们可以清晰地看到visual embedding在extract_feature过程中shape变化:
[INFO]: extract_feature pixel_values: torch.Size([5, 3, 448, 448])[INFO]: extract_feature vit_embeds: torch.Size([5, 1025, 3200])[INFO]: extract_feature vit_embeds[:, 1:, :]: torch.Size([5, 1024, 3200])[INFO]: extract_feature vit_embeds after reshape: torch.Size([5, 32, 32, 3200])[INFO]: extract_feature vit_embeds after pixel_shuffle: torch.Size([5, 16, 16, 12800]), downsample_ratio: 0.5[INFO]: extract_feature vit_embeds before mlp1: torch.Size([5, 256, 12800])[INFO]: extract_feature vit_embeds after mlp1: torch.Size([5, 256, 6144])[INFO]: input_embeds: torch.Size([1, 2596, 6144])[INFO]: input_embeds [B*N, C]: torch.Size([2596, 6144])
可以看到,这个示例中,pixel shuffle的ratio=r=downsample_ratio=0.5。并且pixel shuffle是在提取的vit emb上调用的,而不是在原始图像上,具体可以看上图源码的逻辑,举个实际的例子,[5, 3, 448, 448]的pixel_values经过InternViT-6B后,得到[5, 1024, 3200]大小的feature map,按照hxw的空间布局reshape后为[5, 32, 32, 3200],其中32x32就是原始的visual token数,3200就是特征channel数。接着对[5, 32, 32, 3200]的feature map进行pixel shuffle处理,r=0.5,变换得到[5, 16, 16, 12800]。我们可以看到,pixel shuffle之后visual token数量变成了原来的1/4,即16x16=256。最后,再将[5, 16, 16, 12800]reshape为[5,256,12800],并经过MLP1,得到[5, 256, 6144]。这个6144就是LLM语言模型InternLM2-20B的hidden_size,见config.json中的配置:
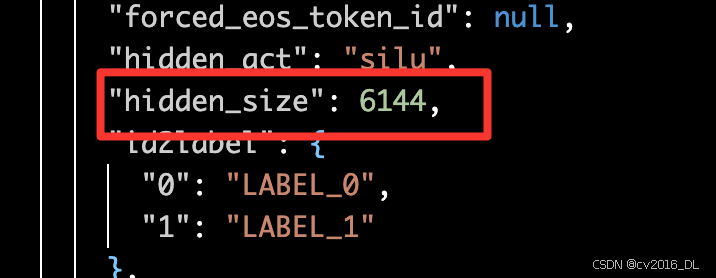
InternLM2-20B的hidden_size
可见,对于一个448x448的image来说,经过ViT + pixel shuffle后,visual token数由原来的32x32下降到了16x16,token数下降到了原来的1/4,既保留了原始的feature信息,又达到了减少上下文长度的效果。
-
Dynamic High Resolution: 动态高分辨率
Dynamic High Resolution具体的做法为:对于输入的图片,首先resize成448的倍数,比如InternVL 1.5中,设置的比例为2:3,也就是resize成(H=448x2=896, W=448x3=1344),然后按照预定义的尺寸比例从图片上crop对应的区域。首先,将图片划分成2x3的块,Aspect Ratio=1:1就是表示取最左上角的块,而1:2则是取第一行中间的块,以此类推其他的Ratio代表的含义。并且,为了能够捕获全局的信息,还将整图resize成448x448,作为Thumbnail和其他crop出来的图像stack到一起作为输入。

Dynamic High Resolution
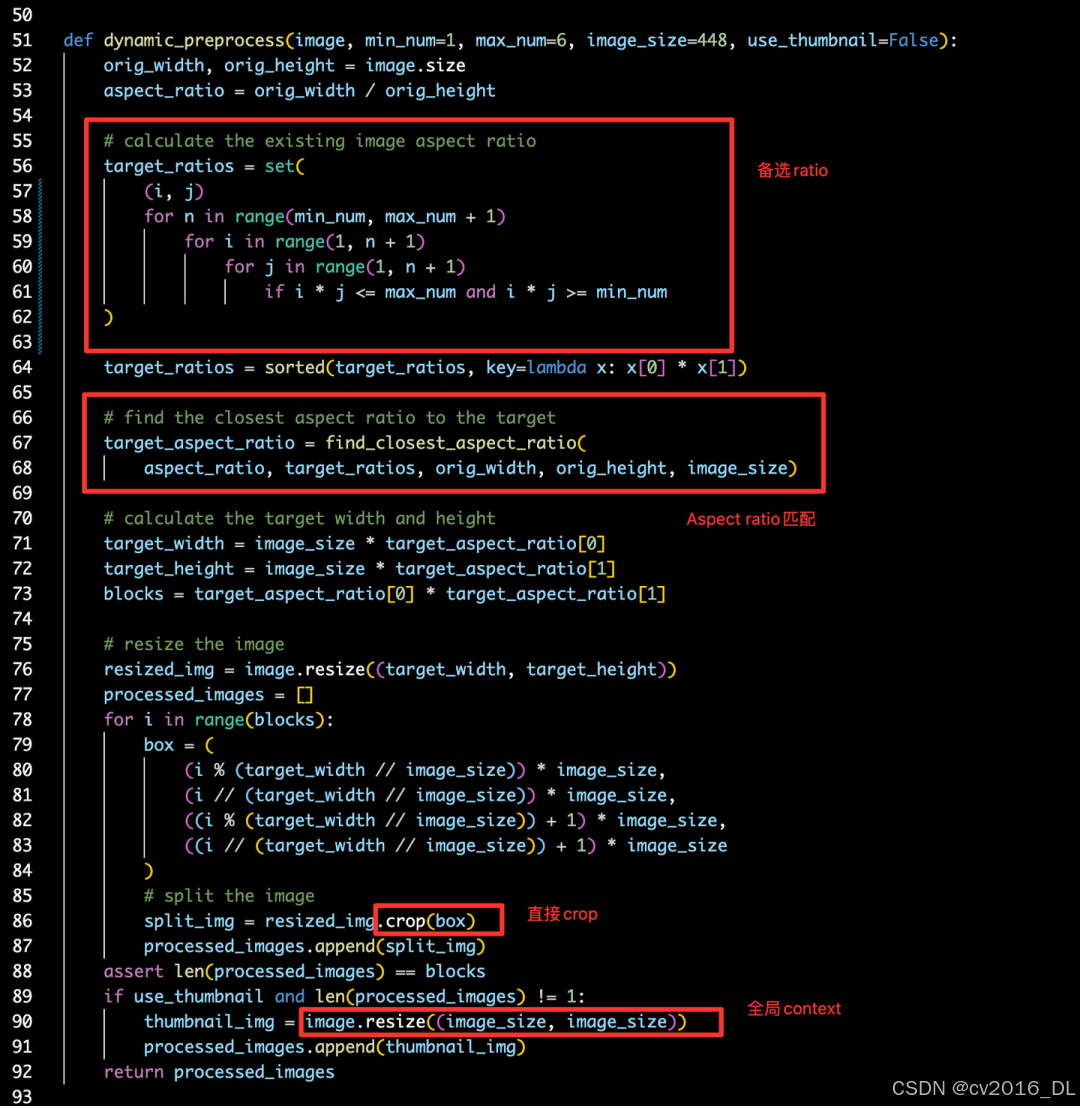
具体到InternVL 1.5的预处理代码,我们可以看到,代码中首先会根据max_num生成一系列备选的ratio,并且通过set去重,然后是调用find_closet_aspect_ratio找到和aspect_ratio最匹配的target_aspect_ratio,这是为了保持一致的宽高比,避免不合理的resize导致图片失真。比如输入是800x1300的图片,会找到最优的ratio为2:3,然后会根据这个ratio以及image_size=448,将输入图片resize为448的倍数,即896x1344。所有需要crop的blocks数量等于2x3=6,需要留意的是,由于在获取target_ratios的时候,已经限制了 i*j <= max_num,因此,blocks的值总是满足max_num的限制的。
# calculate the existing image aspect ratio
target_ratios=set(
(i,j)
forninrange(min_num,max_num+1)
foriinrange(1,n+1)
forjinrange(1,n+1)
ifi*j<=max_numandi*j>=min_num
)
接下来,就是通过一个for循环来计算第i个block对应的图片块范围,然后crop对应的区域获得的当前的图像块,图像块之间不存在跳变和跨越。我们推测,如果max_num值越小,那么对应的target_aspect_ratio的值也会越小,输入图像会在resize到一个相对小的尺寸,然后crop对应的blocks(但是这个尺寸也是比原图要大的),也就是,能够catch到的图像细节就越少;反之,输入图像会在resize到一个更大的尺寸,然后crop对应的blocks,能够catch到的图像细节就越多。在实际训练的时候,由于训练资源的限制,InternVL 1.5选择了最大的max_num为12,加上thumbnail就是13个块,对应到visual token数就是256x13=3328,而在推理时则没有这个限制,最大max_num可以到40,也就是visual token数可以到256x41=10496。
dynamic preprocess源码
-
模型训练、Prompt拼接和实验结果
模型训练:InternVL 1.5训练分为2个阶段。阶段一:对MLP Projector和InternViT-6B模型做预训练,LLM底座权重冻结,这个阶段主要是针对视觉特征提取器进行优化;阶段二:InternViT-6B + MLP Projector + InternLM2-20B总共26B的参数全部参与训练,上下文长度设置为4096,并且采用和LLaVA一样的prompt格式。
Prompt拼接:Prompt拼接逻辑也比较简单,具体操作是,将img_tokens放在用户prompt的前边,并根据对话模版进行填充。以下代码片段来自InternVL 1.5 HuggingFace仓库源码:
image_tokens =IMG_START_TOKEN+IMG_CONTEXT_TOKEN*self.num_image_token*image_bs+IMG_END_TOKENquestion=image_tokens+'\n'+questiontemplate.append_message(template.roles[0],question)template.append_message(template.roles[1],None)query=template.get_prompt()
img_token_id是通过一个fake的特殊token先进行填充的,等Vision Model提取到真实的特征后,会进行替换:
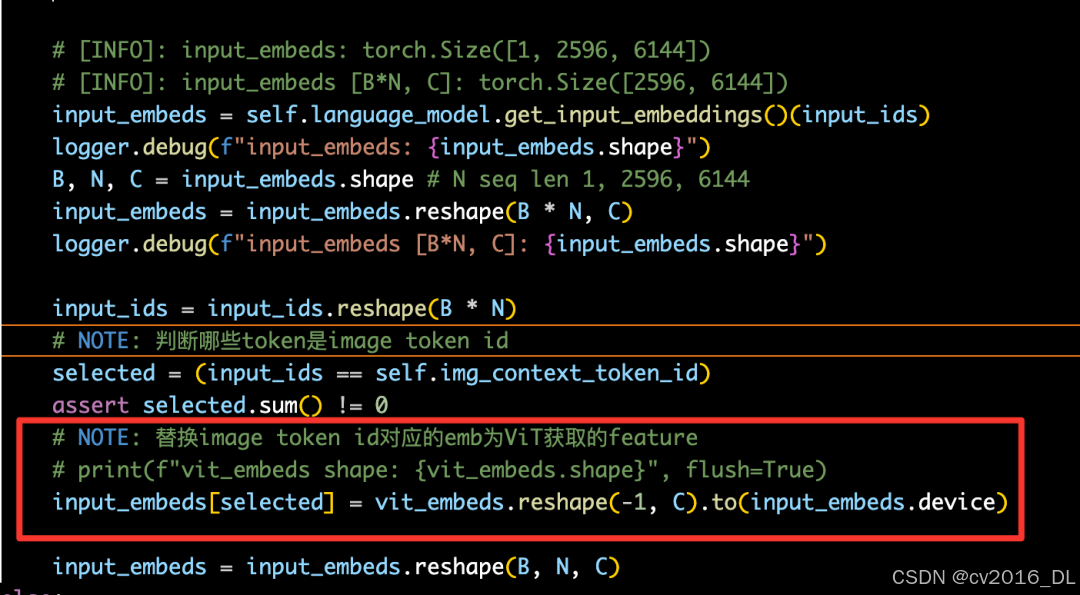
填充真实的img feature
不过需要注意的是,实际上img_token_id并不是在整个prompt的最前方的,因为还会根据chat template进行填充,真正输入LLM模型的input_ids是填充后的prompt分词的ids,实际的prompt长这样:
<|im_start|>system
You are an AI assistant whose name is InternLM (书生·浦语).<|im_end|><|im_start|>user
<img><IMG_CONTEXT><IMG_CONTEXT>...<IMG_CONTEXT></img>
describe this image<|im_end|><|im_start|>assistant
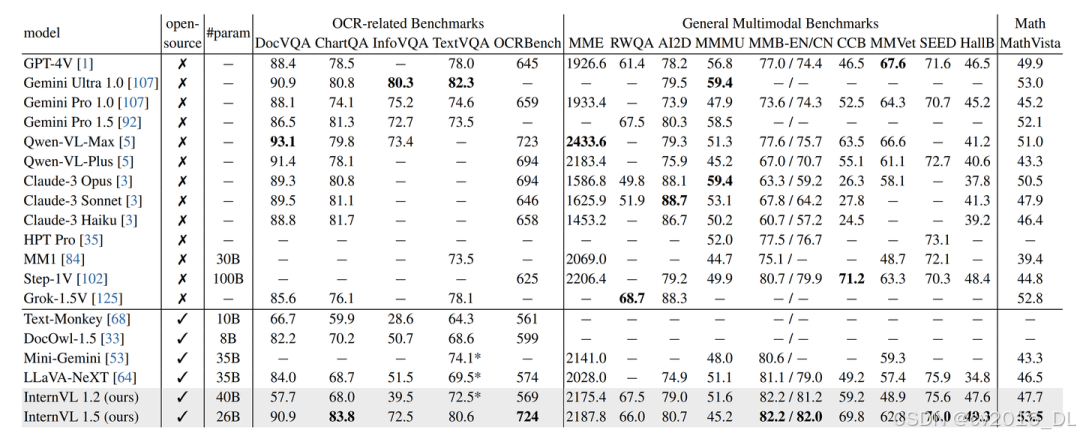
实验结果:剩下就是各种高质量的数据集的整理和说明了,模型结构都是主流的,训练数据的质量很大程度影响模型的效果,具体的细节请看InternVL 1.5的论文,本文不再单独说明。最后,放一下InternVL 1.5的benchmark:
InternVL 1.5 Benchmark
可以看到,InternVL 1.5在多个任务和评估标准下都达到了SOTA的水平。
-
LMDeploy部署及性能瓶颈分析
目前,针对InternVL系列的部署方案,最丝滑的,还是推荐使用LMDeploy。之前还有部署之后输出效果随机性明显的问题(greedy采样下),后来都修复了,见:https://github.com/InternLM/lmdeploy/pull/1741。不过,测试下来,发现,在BS变大后,性能瓶颈或许已经不在LLM模型,而是在没有经过优化的InternViT-6B的视觉模型上了。具体见issue:https://github.com/InternLM/lmdeploy/issues/1869。
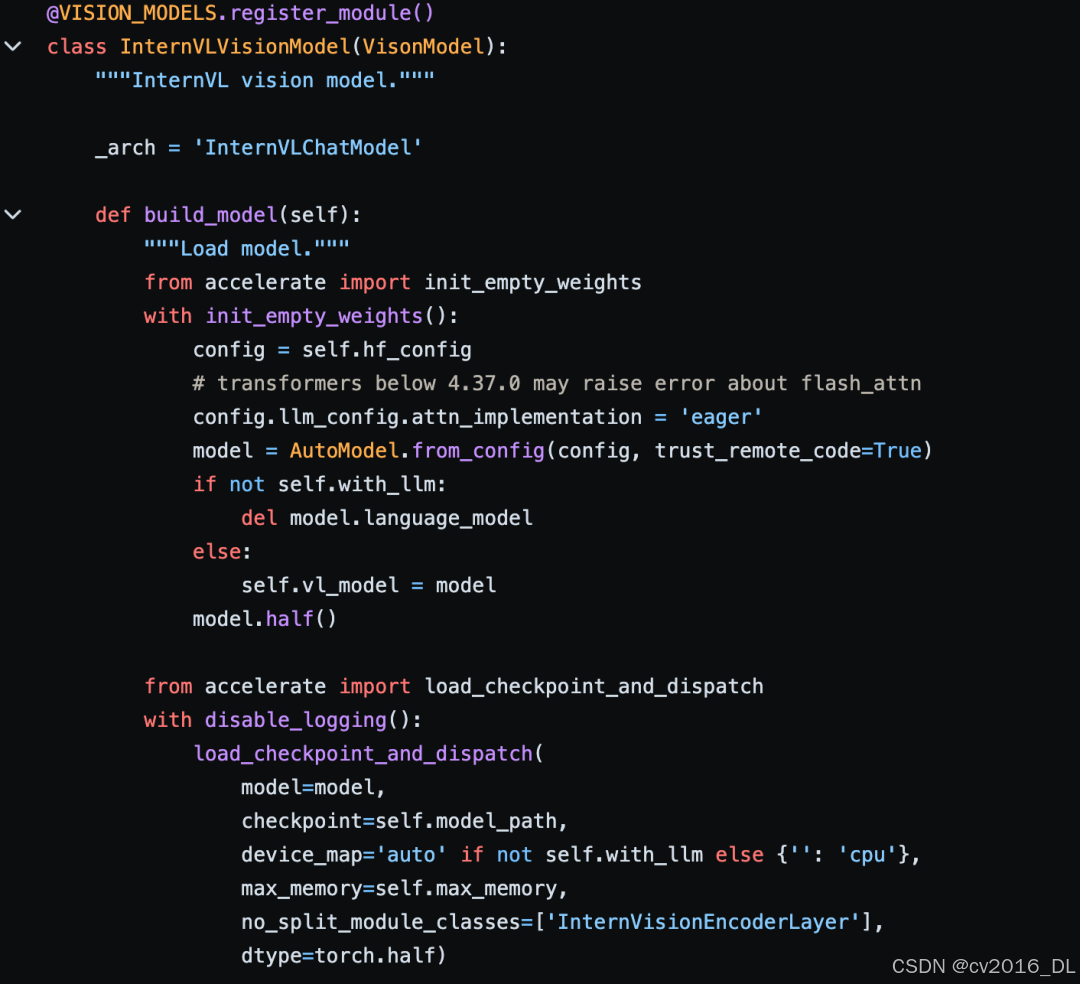
LMDeploy VL 视觉模型推理
我们可以看到,InternViT-6B视觉模型,使用了HF+accelerate推理,虽然权重平均分配到两张卡上,但是推理是逐层串行的,没有通过Tensor Parallel利用双卡的算力。随着视觉模块参数量的不断增大,比如未来VLM是否会出现搭配10B、20B以上参数量级的视觉模块?如果出现,那么对视觉模块+LLM基座结合起来做深度的性能优化,应该是不可避免的。
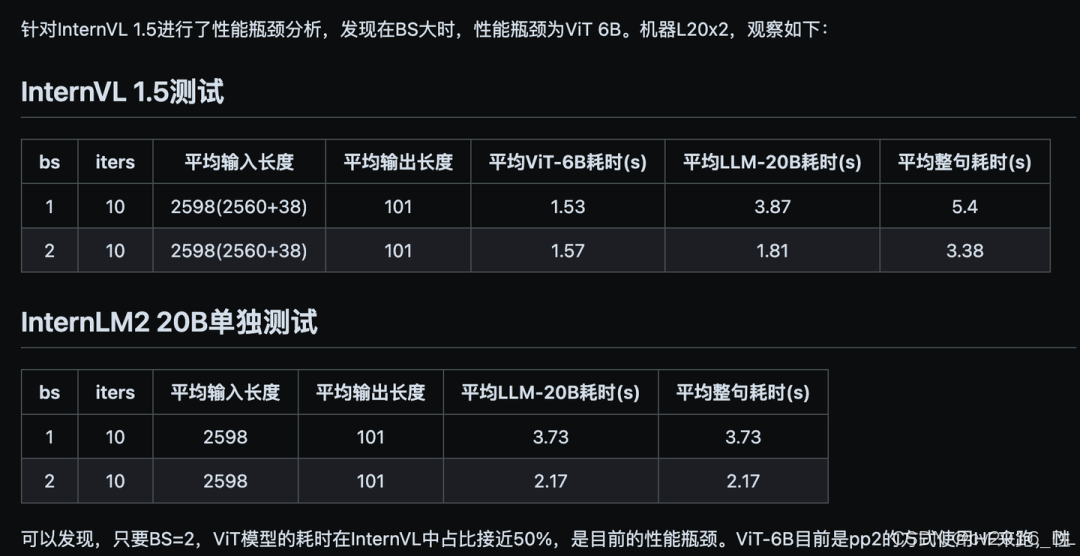
InternVL 部署性能分析
05 InternVL2.0简析
-
InternVL2.0最新进展
2024年7月份,InternVL团队发布了InternVL 2.0,效果比InternVL 1.5更好。InternVL 2.0整体的网络结构和InternVL 1.5是一样的,Pixel Shuffle和Dynamic High Resolution的技术从InternVL 1.5继承了下来。但是InternVL 2.0进一步支持了医疗图像和视频作为输入,在功能上是比较大的变化。这次没有发布论文,不过有blog进行的说明,具体见:https://internvl.github.io/blog/2024-07-02-InternVL-2.0/
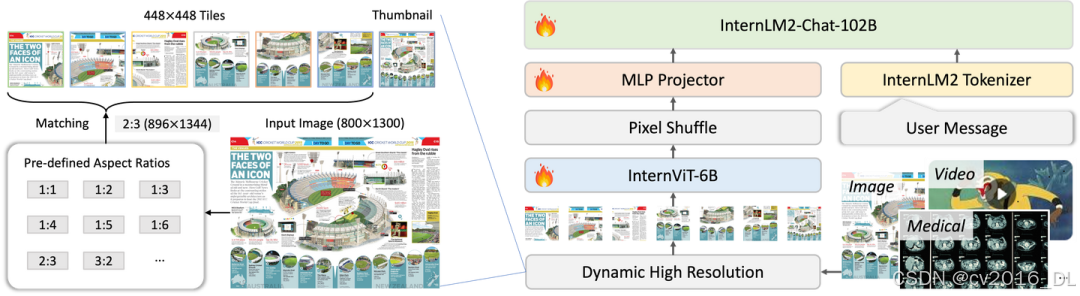
InternVL2 整体结构
相对于InternVL 1.5,这次更新的InternVL 2.0主要的创新有:(1)提出了渐进式对齐的训练策略:实现了与LLM原生对齐的视觉基座模型,渐进式训练策略使得模型从小到大,数据从粗到细训练。InternVL2.0以相对较低的成本完成了大模型的训练。这种方法在有限的资源下表现出了出色的性能。(2)多模态输入:通过一组统一的参数,InternVL2.0模型支持多种输入模态,包括文本、图像、视频和医疗数据。(3)多任务输出:基于VisionLLMv2,InternVL2.0模型支持各种输出格式,例如图像、边界框和掩模,具有广泛的多功能性。并且,通过将 MLLM 与多个下游任务解码器连接,InternVL2 可以推广到数百个视觉语言任务,同时实现与专家模型相当的性能。
 InternVL 2.0创新点
InternVL 2.0创新点
-
InternVL2.0 Benchmark
InternVL 2.0在多项测试标准中均达到了SOTA,并且,这次还发布了一个108B参数量级的模型,可以说是把开源多模态大模型参数量的天花板又往上提了一提。真是力大飞砖啊,不得不感叹,有钱真好~
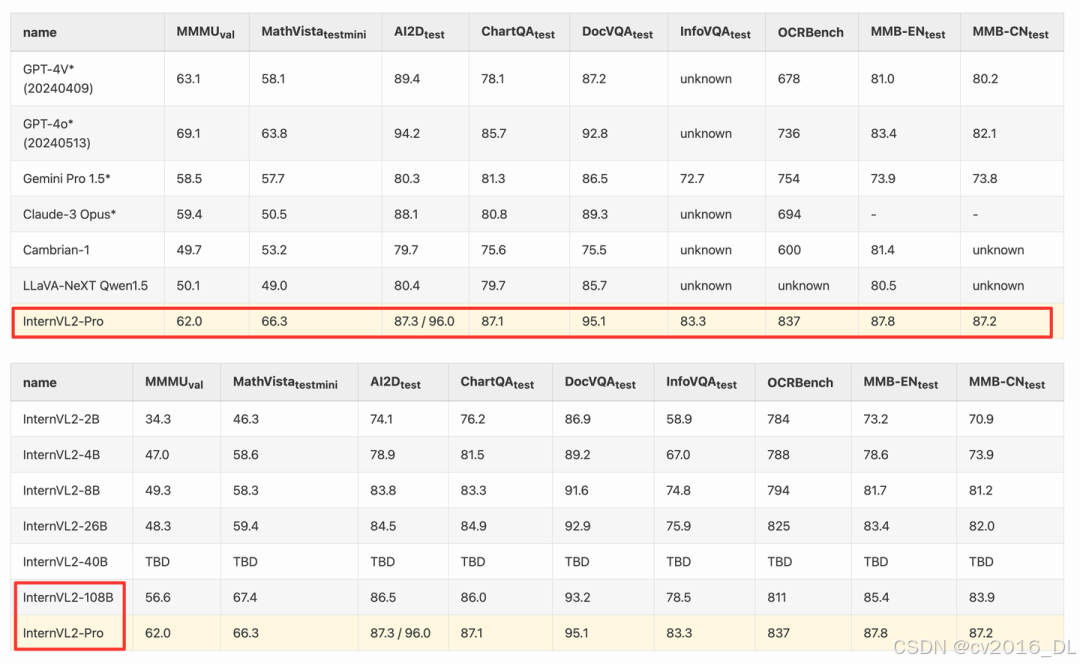
InternVL 2.0 Benchmark
06 总结
本文梳理了InternLM/InternVL系列的模型结构,详细讲解了InternLM2/InternVL1.5的算法原理,包括权重交织、Pixel Shuffle和Dynamic High Resolution等关键技术的细节理解。最后,LLM推理部署各方向新进展,推荐我整理的Awesome-LLM-Inference,传送门:https://github.com/xlite-dev/Awesome-LLM-Inference