YOLOv10速度提升与参数缩减解析2025.5.31
YOLOv10作为YOLO系列的最新版本,在模型参数压缩和效率优化方面做出了显著改进,但其速度提升与参数缩减之间看似不成比例的现象,主要源于其设计策略和硬件适配的综合影响。以下从多个角度分析这一问题的技术背景和原因:
1. 参数缩减的核心技术
YOLOv10通过以下设计策略显著减少了模型参数:
- 轻量级分类头:将传统分类头的结构简化为两个深度可分离卷积和一个1×1卷积,减少计算冗余,分类头参数量降低约40%。
- 空间-通道解耦下采样:通过分离空间压缩与通道扩展操作,避免传统下采样层的高计算开销,例如将C3模块替换为更高效的C2f结构。
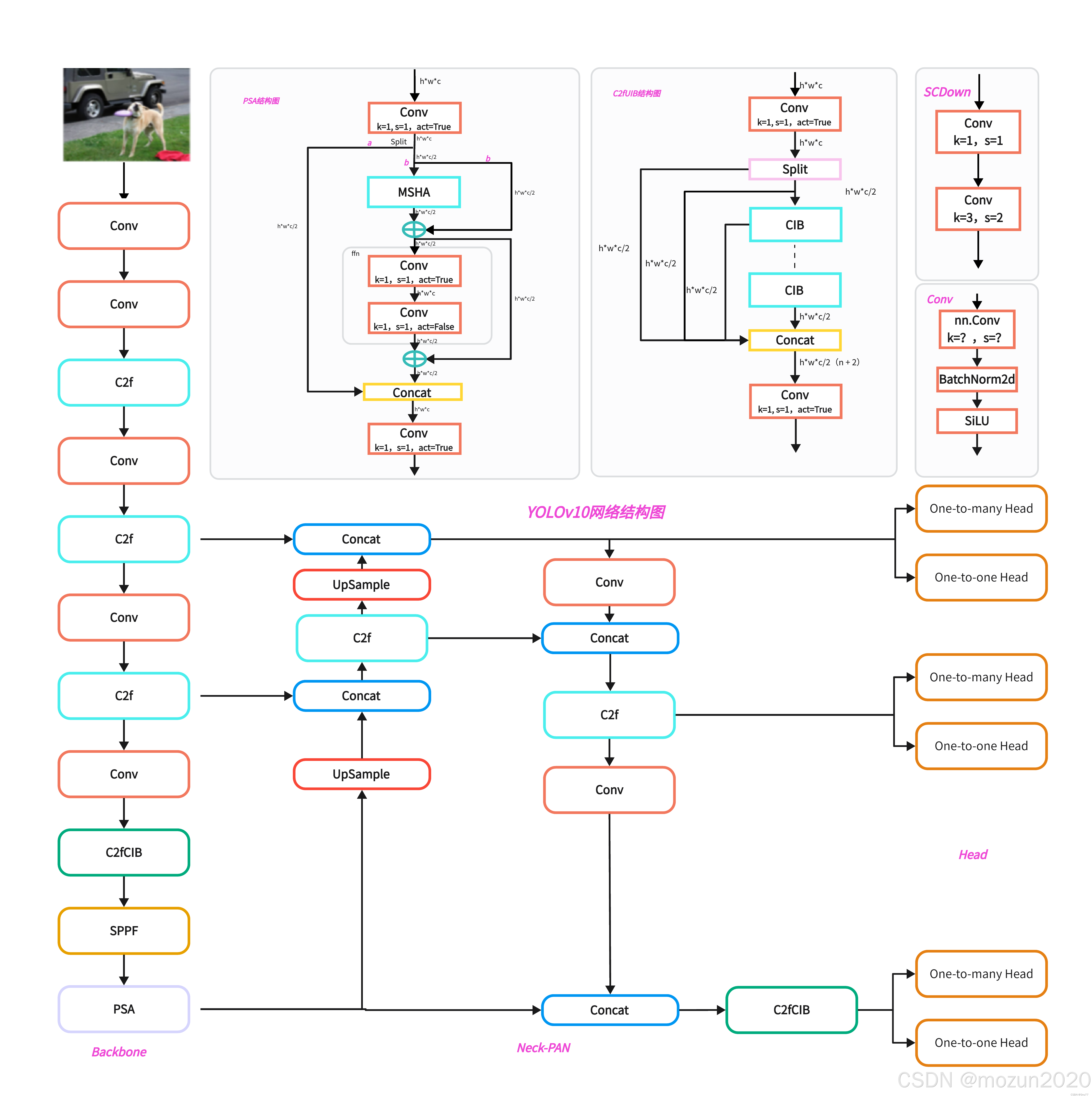
- 排序引导的块设计:利用数值秩分析各阶段的冗余程度,自适应替换冗余模块(如用紧凑反向块CIB替代部分基础块),在保持性能的同时减少参数。
这些优化使YOLOv10-N的参数量从YOLOv9-C的2.76M降至2.30M,体积缩小20%。
2. 速度提升受限的关键因素
尽管参数减少,但实际推理速度提升有限,主要受以下因素影响:
(1)复杂模块引入的隐性开销
- 大核卷积与自注意力机制:YOLOv10在深层阶段引入7×7大核卷积和部分自注意力模块(PSA),虽然增强了特征提取能力,但大核卷积的I/O延迟和自注意力的二次计算复杂度抵消了部分速度增益。
- EMA注意力与多尺度融合:改进版模型(如工业检测专用变体)引入EMA注意力机制,通过跨通道交互提升精度,但增加了约15%的计算量。
(2)端到端设计的双重成本
YOLOv10采用“双标签分配”策略,训练时保留一对多和一对一两个检测头,尽管推理时仅保留一对一头部,但训练阶段的联合优化增加了模型复杂度,部分抵消了参数缩减的收益。
(3)硬件适配与部署优化
- 边缘设备瓶颈:在Jetson Nano等边缘设备上,内存带宽和并行计算能力有限,参数减少带来的理论加速可能被硬件瓶颈限制,实际延迟改善仅15%-20%。
- 动态形状支持不足:早期版本的TensorRT导出对动态尺寸支持不完善,导致大模型部署时效率未达预期。

3. 性能与效率的权衡分析
YOLOv10的设计体现了“精度优先”的权衡:
- 精度驱动改进:通过PSA模块和大核卷积,YOLOv10-S在COCO数据集上的mAP提升1.4%,但推理延迟仅增加0.15ms。
- 效率优化受限场景:在需要高分辨率输入的场景(如小目标检测),空间-通道解耦下采样的计算优势被高分辨率特征图的处理成本部分抵消。
4. 实际应用中的表现对比
| 模型 | 参数量(M) | COCO mAP | T4 GPU延迟(ms) |
|---|---|---|---|
| YOLOv9-C | 2.76 | 51.9 | 7.95 |
| YOLOv10-B | 2.30 | 52.5 | 7.62 |
| YOLOv10-S | 1.92 | 47.7 | 3.83 |
| RT-DETR-R18 | 3.10 | 46.8 | 6.90 |
数据表明,YOLOv10在相同精度下延迟降低约10%-15%,但参数量减少幅度(25%-30%)大于速度提升幅度,反映了设计中的精度-效率权衡。
5. 未来优化方向
- 硬件感知架构搜索:结合NAS技术(如MAE-NAS),针对特定硬件优化模块组合,进一步提升参数利用率。
- 动态计算分配:根据输入图像复杂度动态调整计算资源,例如在简单场景中跳过部分注意力层。
- 量化与蒸馏增强:通过8位量化和师生蒸馏,在保持精度的同时进一步压缩模型,适配边缘设备。
总结
YOLOv10的参数缩减主要源自结构精简和模块优化,而速度提升受限则源于复杂模块的隐性开销、端到端设计的双重成本及硬件适配瓶颈。其设计体现了在实时检测任务中“以少量速度损失换取显著精度提升”的策略,未来需通过硬件协同优化进一步释放潜力。