MySQL:零基础入门(狂神版)
前言
本笔记是学习狂神的java教程,建议配合视频,学习体验更佳。
【狂神说Java】HTML5完整教学通俗易懂_哔哩哔哩_bilibili
第1-2章:Java零基础入门笔记:(1-2)入门(简介、基础知识)-CSDN博客
第3章:Java零基础入门笔记:(3)程序控制-CSDN博客
第4章:Java零基础入门笔记:(4)方法-CSDN博客
第5章:Java零基础入门笔记:(5)数组-CSDN博客
第6章:Java零基础入门笔记:(6)面向对象-CSDN博客
第7章:Java零基础入门笔记:(7)异常-CSDN博客
多线程:Java零基础入门笔记:多线程_callable-CSDN博客
HTML:HTML零基础入门笔记:狂神版_狂神说java html笔记-CSDN博客
CSS:CSS零基础入门笔记:狂神版-CSDN博客
JavaScript:JavaScript零基础入门笔记:狂神版_head 加 scripe-CSDN博客
-
-
1. 简介
数据库
数据库是一种用于存储、组织、管理和检索数据的系统化集合。它按照一定的结构和规则将数据组织起来,以便用户能够高效地访问和操作数据。数据库的核心目标是提供一种可靠、高效且易于管理的方式来处理大量数据。
数据库可以分为多种类型,其中最常见的是关系型数据库和非关系型数据库。
- 关系型数据库(如MySQL、Oracle、SQL Server等)基于关系模型,将数据存储在表格中,每个表格由行(记录)和列(字段)组成,通过主键和外键等关系来关联不同的表格。这种结构使得数据之间的关系清晰明确,便于进行复杂的查询和分析。
- 非关系型数据库(如MongoDB、Redis等)则采用了不同的数据存储方式,例如文档存储、键值存储、列存储或图形存储等,它们通常在处理大规模数据、高并发访问或灵活的数据结构方面具有优势。
数据库的主要功能包括数据存储、数据检索、数据更新和数据管理。数据存储是数据库的基本功能,它将数据以结构化或非结构化的方式保存在存储介质中。数据检索则允许用户通过查询语言(如SQL)或API来查找特定的数据。数据更新功能使得用户能够插入、修改或删除数据,以保持数据的时效性和准确性。数据管理则涉及到用户权限管理、数据备份与恢复、性能优化等方面,确保数据库的安全性、可靠性和高效性。
数据库在现代信息技术中扮演着至关重要的角色。几乎所有的应用程序,无论是企业级的ERP系统、电子商务平台,还是个人使用的社交媒体应用、移动应用程序,都依赖于数据库来存储用户信息、交易记录、内容数据等。例如,一个电商平台需要通过数据库来存储商品信息、用户订单、库存数据等,以便用户能够快速浏览商品、下单购买,同时商家能够有效地管理库存和订单。
总之,数据库是现代信息技术的基石之一。它通过高效、安全、灵活的方式管理数据,为各种应用程序提供了强大的数据支持,推动了信息技术的快速发展和广泛应用。
-
MySQL
MySQL是一种广泛使用的开源关系型数据库管理系统(RDBMS)。它基于客户端-服务器架构,允许用户通过SQL(结构化查询语言)来管理和操作数据库中的数据。MySQL以其高性能、可靠性和灵活性而闻名,适用于从小型应用程序到大型企业级系统的各种场景。
MySQL的核心是其存储引擎,它负责数据的存储和检索。其中最常用的存储引擎是InnoDB,它支持事务处理、行级锁定和外键约束,能够确保数据的完整性和一致性。此外,MySQL还提供了其他存储引擎,如MyISAM,适用于读密集型应用,以及Memory引擎,用于快速临时数据存储。
总的来说,MySQL是一种功能强大、性能卓越且易于使用的数据库管理系统。它凭借其开源优势、灵活的架构和丰富的功能,成为了全球众多开发者和企业的首选数据库解决方案。
-
安装MySQL
安装建议:
-
尽量不要使用exe,(卸载麻烦,会写注册表)
-
尽可能使用压缩包
安装过程:
-
下载后得到zip压缩包
-
解压到自己想要安装到的目录。本人解压到的是D:\Environment\mysql-8.0.31
-
添加环境变量
-
我的电脑->属性->高级->环境变量
-
选择PATH,在起后面添加:你的mysql安装文件下面的bin文件夹
-
在D:\Environment\mysql-8.0.31下新建my.ini文件
-
编辑my.ini文件,注意替换文件路径
[mysqld] basedir:E:\Java_Demo\mysql-9.3.0\mysql-9.3.0 datadir=E:\Java_Demo\mysql-9.3.0\mysql-9.3.0\data post=3306 skip-grant-tables -
启动管理员模式下的CMD,并将路径切换至mysql下的bin目录,再输入mysqld -install(安装mysql)
-
再输入
mysqld --initialize-insecure --user=mysql初始化数据文件 -
然后再次启动mysql(net start mysql),然后命令mysql -u root -p进入mysql管理界面(密码为空)
-
更改root密码
-
user mysql;
-
select host,user,plugin from user;
-
update user set plugin='mysql_native_password' where user='root';
-
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '123456';
-
update mysql.user set host='%' where user='root';
-
flush privileges; 刷新权限
-
为什么还要使用mysql_native_password? 虽然最新版MySql换了新的身份验证插件(caching_sha2_password), 原来的身份验证插件为(mysql_native_password)。但是一些客户端工具比如Navicat 中还找不到新的身份验证插件(caching_sha2_password),因此,我们需要将mysql用户使用的 登录密码加密规则 还原成 mysql_native_password,方便客户端工具连接使用。
-
-
重启mysql即可正常使用
net stop mysqlnet start mysql
-
安装SQLyog
-
无脑安装
-
注册
-
打开连接数据库
-
新建一个数据库school
每一个sqlyog的执行操作,本质就是对应了有个sql,可以再(工具)->(历史记录)查看
-
新建一张表student
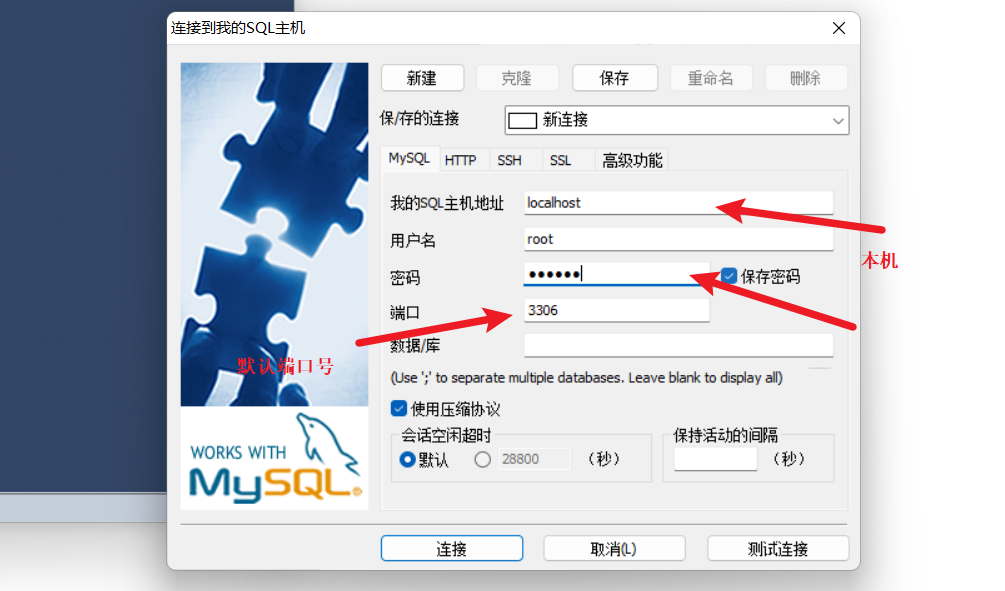
连接数据库
命令行连接!
mysql -uroot -p123456 --连接数据库update mysql.user set authentication_string=password('123456') where user='root' and Host ='localhost'; --修改用户名密码
flush privileges; --刷新权限 ------------------------------
--所有的语句都使用;结尾
show database; --查看所有的数据库
mysql> use school --切换数据库 use 数据库名
Database changed show tables; --查看数据库中所有的表
describe student; --显示数据库中所有表的信息 -- Ctrl+c create database westos; --创建一个数据库
exit; --退出连接 -- 单行注释(sql本来的注释) /* 多行注释 */-
-
2. 操作数据库
学习顺序:操作数据库>操作数据库中的表>操作数据库中表的数据
-
注意:myql关键字不区分大小写
-
操作数据库(了解)
创建数据库
CREATE DATABASE westos
--如果存在,不报错
CREATE DATABASE IF NOT EXISTS westos删除数据库
DROP DATABASE westos
--如果不存在,不报错
DROP DATABASE IF NOT EXISTS westos使用数据库
`位于tab键的上面,如果你的表名或者字段名是有个特殊字符,就需要带``
USE `school`查看数据库
-- 查看所有数据库
SHOW DATASET-
数据类型
数值
| 数据类型 | 表示的范围 | 字节数 |
|---|---|---|
| tinyint | 十分小的数 | 1个字节 |
| smallint | 较小的数据 | 2个字节 |
| mediemint | 中等大小的数据 | 3个字节 |
| int(常用的) | 标准的整数 | 4个字节 |
| bigint | 较大的数据 | 8个字节 |
| float | 浮点数 | 4个字节 |
| double(精度问题) | 浮点数 | 8个问题 |
| decimal(金融计算) | 字符串形式的浮点数 |
字符串
| 数据类型 | 表示范围 | 取值范围 |
|---|---|---|
| char | 字符串固定大小的 | 0~255 |
| varchar(常用变量) | 可变字符串 | 0~65535 |
| tinytext | 微型文本 | 2^8-1 |
| text(保存文本) | 文本串 | 2^16-1 |
时间日期
| 数据类型 | 格式 | 用途 |
|---|---|---|
| date | YYYY-MM-DD | 日期格式 |
| time | HH:mm:ss | 时间格式 |
| datetime | YYYY-MM-DD HH:mm:ss | 最常用的时间格式 |
| timestamp | 1970.1.1到现在的毫秒数 | 较为常用 |
| year | 年份表示 |
空值null
-
没有值,未知
-
注意,不要使用NULL进行运算,结果为NULL
-
数据库的字段属性(重点)
Unsigned:
-
无符号整数
-
声明了该列不能声明为负数
zerofill
-
0填充的
-
不足位数,使用0来填充,int(3),5 -----> 005
auto-increment自增
-
通常理解为自增,自动在上一条记录的基础上+1(默认)
-
通常用来设计唯一的主键~index,必须是整数类型
-
可以自定义设计主键自增的起始和步长
非空 NULL not null
-
假设设置为not null,如果不给它赋值,就会报错!
-
NULL,如果不填写值,默认就是null!
默认
-
设置默认的值!
-
sex,默认值为 男,如果不指定该列的值,则会有默认的值!
-
拓展
每一个表,都必须存在以下五个字段!未来做项目用,表示一个记录存在意义
- id 主键
- `version` 乐观锁
- is_delete 伪删除
- gmt_create 创建时间
- gmt_update 修改时间
-
创建数据库表(重点)
CREATE TABLE [IF NOT EXISTS] `表名`(`字段名` 列类型 [属性] [索引] [注释],......PRIMARY KEY('id')
)[表类型][字符集设置][s]目标:创建有个school数据库
创建学生表(列,字段)使用SQL创建
学号int 登录密码varchar(20)姓名,性别varchar(2),出生日期(datatime),家庭住址,email
/*
目标:创建有个school数据库
创建学生表(列,字段)使用SQL创建
学号int 登录密码varchar(20)姓名,性别varchar(2),出生日期(datatime),家庭住址,email注意点,使用英文(),表的名称 和 字段 尽量使用 `` 括起来
AUTO INCREMENT 自增
字符串使用 单引号 括起来
所有语句后面夹 , (英文的),最后一个不用加
PRIMARY KEY 主键,一般一个表只有一个唯一的主键!*/CREATE TABLE IF NOT EXISTS `student`(`id` INT(4) NOT NULL AUTO_INCREMENT COMMENT '学号',`name` VARCHAR(30) NOT NULL DEFAULT '匿名' COMMENT '姓名',`pwd` VARCHAR(20) NOT NULL DEFAULT '123456' COMMENT '密码',`sex` VARCHAR(2) NOT NULL DEFAULT '女' COMMENT '性别',`birthday` DATETIME DEFAULT NULL COMMENT '出生日期',`address` VARCHAR(100) DEFAULT NULL COMMENT '家庭住址',`email` VARCHAR(50) DEFAULT NULL COMMENT '邮箱',PRIMARY KEY(`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
常用命令
SHOW CREATE DATABASE school /*查看创建数据库的语句*/
SHOW CREATE TABLE student /*查看student数据表的定义语句*/
DESC student /*显示表的结构*/-
数据表的类型
数据引擎:数据库引擎是数据库管理系统(DBMS)的核心组件,它负责管理数据库的存储、检索、更新和维护等操作。数据库引擎的性能和功能直接影响到数据库的整体性能、可靠性和可扩展性。不同的数据库引擎可能具有不同的特点和优化策略,适用于不同的应用场景。
- INNODB:InnoDB是MySQL的默认存储引擎,支持事务处理、行级锁定和外键约束。它通过MVCC实现高并发性能,并且具有良好的数据恢复能力。InnoDB适用于需要高可靠性和高性能的场景,如在线事务处理(OLTP)系统。
- MYISAM:MyISAM是MySQL早期的默认存储引擎,支持全文索引,但不支持事务处理和行级锁定。它更适合读密集型的场景,如数据仓库或日志系统。由于其性能优势,MyISAM在某些特定场景下仍然被使用,但逐渐被InnoDB取代。
| INNODB | MYISAM | |
|---|---|---|
| 事务支持 | 不支持 | 支持 |
| 数据行锁定 | 不支持 | 支持 |
| 外键约束 | 不支持 | 支持 |
| 全文索引 | 支持 | 不支持 |
| 表空间的大小 | 较小 | 较大,约为2倍 |
常规使用操作:
-
MYISAM 节约空间,速度较快
-
INNODB 安全性高,事务的处理,多表多用户操作
所有的数据库文件都存在data目录下,一个文件夹对应一个数据库,本质还是文件存储
MYSQL引擎在物理文件上区别
-
INNODB在数据库表中只有*.frm文件,以及上级目录下的ibdata1文件
-
MYISAM对应文件对应文件
-
*.frm -表结构对应的定义文件
-
*.MYD 数据文件(data)
-
*.MYI 索引文件(index)
-
设置数据库的字符集编码
CHARSET =utf8不设置的话,会是mysql默认的字符集编码~(不支持中文)
MySQL的默认编码是Latin1,不支持中文
在my.ini中配置默认的编码
character-set-sever=-
修改删除表
修改
-- 修改表名:ALTER TABLE 旧表名 RENAME AS 新表名
ALTER TABLE teacher RENAME AS teacher1
-- 增加表的字段:ALTER TABLE 表名 ADD 字段名 列属性
ALTER TABLE teacher1 ADD age INT(11)-- 修改表的字段(重命名,修改约束!)
-- ALTER TABLE 表名 MODIFY 字段名 列属性[]
ALTER TABLE teacher1 MODIFY age VARCHAR(11) --修改约束
-- ALTER TABLE 表名 CHANGE 旧名字 新名字 列属性[]
ALTER TABLE teacher1 CHANGE age age1 INT(1) --字段重命名删除
-- 删除表的字段:ALTER TABLE 表名 DROP 字段名
ALTER TABLE teacher1 DROP age1-- 删除表(如果表存在再删除)
DROP TABLE IF EXISTS teacher1-
注意
- 所有的创建和删除操作尽量加上判断,以免报错
-
sql关键字的小写不敏感,建议大家写小写
-
所有符号用英文
-
-
3. MySQL数据管理
外键(了解即可)
方式一、在创建表的时候,增加约束(麻烦,比较复杂)
CREATE TABLE IF NOT EXISTS`grade`(`gradeid` INT(10) NOT NULL AUTO_INCREMENT COMMENT '年级id',`gradename` VARCHAR(50) NOT NULL COMMENT '年级名称',PRIMARY KEY (`gradeid`)
)ENGINE=INNODB DEFAULT CHARSET=utf8mb4
/*
学生表的gradeid字段 要引用年级表的gradeid
定义外键key
给这个外键添加约束(执行引用) references 引用
*/
CREATE TABLE IF NOT EXISTS `student`(`id` INT(4) NOT NULL AUTO_INCREMENT COMMENT '学号',`name` VARCHAR(30) NOT NULL DEFAULT '匿名' COMMENT '姓名',`pwd` VARCHAR(20) NOT NULL DEFAULT '123456' COMMENT '密码',`sex` VARCHAR(2) NOT NULL DEFAULT '女' COMMENT '性别',`birthday` DATETIME DEFAULT NULL COMMENT '出生日期',`gradeid` INT(10) NOT NULL COMMENT '学生的年级',`address` VARCHAR(100) DEFAULT NULL COMMENT '家庭住址',`email` VARCHAR(50) DEFAULT NULL COMMENT '邮箱',PRIMARY KEY(`id`),KEY `FK_gradeid` (`gradeid`),CONSTRAINT `FK_gradeid` FOREIGN KEY (`gradeid`) REFERENCES `grade` (`gradeid`)
)ENGINE=INNODB DEFAULT CHARSET=utf8mb4删除有外键关系的表的时候,必须先删除引用了别人的表(从表),再删除被引用的表(主表)
方式二、创建表成功后,添加外键约束
CREATE TABLE IF NOT EXISTS`grade`(`gradeid` INT(10) NOT NULL AUTO_INCREMENT COMMENT '年级id',`gradename` VARCHAR(50) NOT NULL COMMENT '年级名称',PRIMARY KEY (`gradeid`)
)ENGINE=INNODB DEFAULT CHARSET=utf8mb4
/*
学生表的gradeid字段 要引用年级表的gradeid
定义外键key
给这个外键添加约束(执行引用) references 引用
*/
CREATE TABLE IF NOT EXISTS `student`(`id` INT(4) NOT NULL AUTO_INCREMENT COMMENT '学号',`name` VARCHAR(30) NOT NULL DEFAULT '匿名' COMMENT '姓名',`pwd` VARCHAR(20) NOT NULL DEFAULT '123456' COMMENT '密码',`sex` VARCHAR(2) NOT NULL DEFAULT '女' COMMENT '性别',`birthday` DATETIME DEFAULT NULL COMMENT '出生日期',`gradeid` INT(10) NOT NULL COMMENT '学生的年级',`address` VARCHAR(100) DEFAULT NULL COMMENT '家庭住址',`email` VARCHAR(50) DEFAULT NULL COMMENT '邮箱',PRIMARY KEY(`id`))ENGINE=INNODB DEFAULT CHARSET=utf8mb4/*
创建表的时间没有外键关系
*/
ALTER TABLE `student`
ADD CONSTRAINT `FK_gradeid` FOREIGN KEY(`gradeid`) REFERENCE `grade`(`gradeid`);
/*
alter table 表
add constraint 约束名 foreign key(作为外键的列) reference 哪个表(哪个字段);
*/以上的操作都是物理外键,数据库级别的外键,不建议使用!(避免数据库过多造成困扰,了解即可)
最佳实现
-
数据库就是单纯的表,只用来存数据,有行(数据)和列(字段)
-
我们想使用多张表的数据,想使用外键,用程序去实现
-
DML语言
添加 insert
语法如下:
插入语句(添加)
insert into 表名([字段1,字段2,字段三]) values(‘值1’),('值2'),(‘值3’)如
/*
一般插入语句,我们一定要数据和字段一一对应
插入多个字段
*/
INSERT INTO `grade`(`gradename`) VALUES(1,'大一')
INSERT INTO `grade`(`gradeid`,`gradename`) VALUES(2,'大二')
INSERT INTO `grade`(`gradeid`,`gradename`) VALUES(3,'大三'),(4,'大四')
INSERT INTO `student` VALUES('1','sher','asdfg','男','1900-12-22','3','苏州','111111111@qq.com')
注意事项:
-
字段和字段之间使用英文逗号隔开
-
字段和面的值必须要一一对应,如省略字段则值需全部填写
-
多个设置的属性之间,使用英文逗号隔开
-
修改update
语法:update 修改谁 (条件) set原来的值=新值
update 表名 set colnum_name = value,[colnum_name = value,...] where [条件]列如
--修改id为1的学生的姓名为sher
UPDATE `student` SET `name`= 'sher' WHERE id=1;--不指定条件的情况下,会改动所有的表
UPDATE `student` SET `name`='kuangshen'--修改多个属性,逗号隔开
UPDATE `student` SET `name`='sher',`email`='247234@qq.com' WHERE id = 2条件: where子句 运算符 id等于某个值,大于某个值,在某个区间内修改
操作符返回布尔值
-
= 等于
-
<> 或 != 不等于
-
between...and... 在某个范围内
-
and 和
-
or 或
-
删除delete
语法:
delete from 表名 [where 条件]如
-- 删除数据(避免这样,会全部删除)
delete from `student`-- 删除指定数据
delete from `student`where id = 1;-
TRUNCATE命令
作用:完全清空一个数据库表,表的结构和索引约束不会变
-- 清空student表
TRUNCATE `student`delete 和 TRUNCATE 的区别
-
相同点:都能删除数据,都不会删除表结构
-
不同:
-
TRUNCATE 重新设置自增列,计数器会归零
-
TRUNCATE 不会影响事务
-
--测试delete 和 TRUNCATE 的区别
create table `test`(`id` int(4) not null auto_increment,`coll` varchar(20) not null,primary key (`id`)
)engine=innodb default charset=utf8mb4insert into `test`(`id`,`coll`) values(1,`1`);
insert into `test`(`id`,`coll`) values(2,`3`);
insert into `test`(`id`,`coll`) values(3,`3`);delete from `test`truncate table `test`-
-
4.DQL查询数据(重点)
DQL
(Data Query Language:数据查询语言)
-
所有的查询操作都在用它 select
-
简单的查询,复杂的查询它都能做~
-
数据库中最核心的语言,最重要的语句
-
使用频率最高的语句
-
select
select语法
-- select 字段 from 表SELECT [ALL | DISTINCT]
{* | table.* | [table.field[as alias1][,table.field2[as alias2]][,...]]}
FROM table_name [as table_alias][left |right | inner join table_name2] -- 联合查询[WHERE ...] -- 指定结果满足的条件[GROUP BY ...] -- 指定结果按照哪几个字段来分组[HAVING] -- 过滤分组的记录必须满足的次要条件[ORDER BY ...] -- 指定查询记录按一个或多个条件排序[LIMIT {[offset,]row_count | row_countOFFSET offset}]; -- 指定查询的记录从哪条至哪条-
-- 查询全部的学生
select * from student--查询指定字段
select `StudentNO`,`StudentName` from student--别名,给结果起一个名字 AS 可以给字段起别名,也可以给表起别名
select `StudentNo` as 学号,`StudentName` as 学生姓名 from student as s-- 函数 拼接 concat(a,b)
select concat('姓名:',StudentName) as 新名字 from student有的时候,列名字不是那么的见名知意。我们起别名 AS
-
去重 distinct
作用:去除select语句查询出来的结果中重复的数据,重复的数据只显示一条
-- 查询一下有哪些同学参加了考试
selcet * from result -- 查询全部的考试成绩
select `StudentNo` from result -- 查询有哪些同学参加了考试
select distinct `StudentNo` from result -- 发现重复数据,去重-
数据库的列(表达式)
select version() -- 查询系统版本(函数)
select 100*3-1 as 计算结果 -- 用来计算(表达式)
select @@auto_increment_increment --查询自增的步长(变量)-- 学员考试成绩+1分 查看
select `StudentNo`,`StudentResult`+1 as '提分后' from result数据库中的表达式:文本值,列,Null,函数,计算表达式,系统变量....
-
where条件子句
作用:检索数据中符合条件的值
搜索的条件由一个或者多个表达式组成!结果 返回布尔值
-
逻辑运算符
| 运算符 | 语法 | 描述 |
|---|---|---|
| and && | a and b a&&b | 逻辑与,两个为真,结果为真 |
| or || | a or b a||b | 逻辑或,其中一个为真则结果为真 |
| not ! | not a !a | 逻辑非,真为假,假为真! |
-- where
select StudentNo,`StudentResult` from reslut-- 查询考试成绩在95~100分之间
select StudentNo,`StudentResult` from reslut
where StudentResult>=95 and StudentResult<=100-- and &&
select StudentNo,`StudentResult` from reslut
where StudentResult>=95 && StudentResult<100-- 模糊查询(区别)
select StudentNo,`StudentResult` from reslut
where StudentResult between 95 and 100-- 除了1000号学生之外的同学成绩
select StudentNo,`StudentResult` from reslut
where StudentNo != 1000;-- != not
select StudentNo,`StudentResult` from reslut
where not StudentNo = 1000-
模糊查询:比较运算符
| 运算符 | 语法 | 描述 |
|---|---|---|
| is null | a is null | 如果操作符为null,结果为真 |
| is not nul | a is not null | 如果操作符不为null,结果为真 |
| between | a between b and c | 若a在b和c之间,则结果为真 |
| like | a like b | SQL匹配,如果a匹配b,则结果为真 |
| in | a in (a1,a2,a3...) | 假设a在某一集合中,结果为真 |
/*
模糊查询
查询姓刘的同学
like结合 %(代表0到任意个字符) _(一个字符)
*/
select `StudentNo`,`StudentName` from `studnet`
where StudentName like '刘%'--查询姓刘的同学,名字后面只有一个字的
select `StudentNo`,`StudentName` from `studnet`
where StudentName like '刘_'
--查询姓刘的同学,名字后面只有2个字的
select `StudentNo`,`StudentName` from `studnet`
where StudentName like '刘__'-- =======in=======
--查询1001,1002,1003号学员
select `StudentNo`,`StudentName` from `studnet`
where StudentNo in (1001,1002,1003);-- 查询在北京、上海、南京的学生
select `StudentNo`,`StudentName` from `studnet`
where `Adress` in ('北京','上海','南京');--=============null 、not null==============
--查询地址为空的学生 null
select `StudentNo`,`StudentName` from `studnet`
where adress='' or adress is null--查询由出生日期的同学 不为空
select `StudentNo`,`StudentName` from `studnet`
where `BornDate` is not null-
联表查询
JOIN 对比
连表查询的条件如下:
from 表 xxx join 连接的表 on交叉条件| 操作 | 描述 |
|---|---|
| Inner join | 如果表中至少有一个匹配,就返回行 |
| left join | 会从左表中返回所有的值,即使右表中没有匹配 |
| right join | 会从右表中返回所有的值,即使左表中没有匹配 |
--=========== 联表查询 join =================
-- 查询参加了考试的同学(学号,姓名,科目编号,分数)
/*思路
1.分析需求,分析查询的字段来自哪些表,(连接查询)
2.确定使用哪种连接查询? 7种
确定交叉点(这两个表中哪个数据是共同的)
判断条件:学生表中studnetNo = 成绩表 studnetNo
*/
--join(连接的表) on(判断条件) 连接查询
--where 等值查询select s.StudentNo,StudentName,SubjectNo,StudentResult
from student as s
inner join result as r
where s.StudentNo = r.StudentNo--Right join
select s.StudentNo,StudentName,SubjectNo,StudentResult
from student s
right join result r
on s.StudentNo=r.StudentNo--left join
select s.StudentNo,StudentName,SubjectNo,StudentResult
from student s
left join result r
on s.StudentNo=r.StudentNo-- 查询缺考的同学
select s.StudentNo,StudentName,SubjectNo,StudentResult
from student s
left join result r
on s.StudentNo=r.StudentNo
where StudentResult is null/*思考题(查询参加考试的同学信息:学号,学生姓名,科目名,分数)
思路
1.分析需求,分析查询的字段来自哪些表,student,result,subject(连接查询)
2.确定使用哪种连接查询? 7种
确定交叉点(这两个表中哪个数据是共同的)
判断条件:学生表中studnetNo = 成绩表 studnetNo
*/
select s.StudentNo,StudnetName,SubjectName,StudnetResult
from student s
right join result r
on r.StudentNo = s.StudentNo
inner join `subject` sub
on r.SubjectNo = sub.SubjectNo假设存在一种多张表查询,先查两张表然后一个一个增加
自连接
自己的表和自己的表连接,核心:一张表拆为两张一样的表即可
-- 查询父子信息:把一张表看为两个一模一样的表
select a.`categoryName` as '父栏目',b.`categoryName` as '子栏目'
from 'category' as a,'category' as b
where a.'categoryid' = b.'pid'-- 练习
-- 查询学员所属的年级(学号,学生姓名,年级名称)
select studentNo,studentName,GradeName
from student s
inner join 'grade' g
on s.'GradeID' = g."GradeID"-- 查询科目所属的年级(科目名称,年级名称)
select 'SubjectName','GradeName'
from 'subject' sub
inner join 'grade' g
on sub.'GradeID' = g.'GradeID'-- 查询参加了 数据库结构-1 考试的同学信息:学号,学生姓名,科目名,分数
select s.'StudentNo','StudentName','SubjectName','StudentResult'
from student s
inner join 'result'r
on s.StudnetNo = r.StudentNo
inner join 'subject' sub
on r.'SubjectNo' = sub.'SubjectNo'
where sbujectName = '数据库结构-1'-
分页和排序
排序
-- 排序:升序 ASC , 降序 DESC
-- ORDER BY 通过哪个字段,怎么排
-- 查询的结果根据 成绩降序 排序
select s.'StudentNo','StudentName','SubjectName','StudentResult'
from student s
inner join 'result'r
on s.StudnetNo = r.StudentNo
inner join 'subject' sub
on r.'SubjectNo' = sub.'SubjectNo'
where sbujectName = '数据库结构-1'
order by StudentReslt ASC分页
为什么要分页?
缓解数据库压力,给人的体验更好,瀑布流
语法:
-- 语法:limit 起始页,页面大小
-- 起始页:(n-1)*pageSize 第n页
-- 参数【pageSize ()*pageSize n 数据总数/页面大小=总页数】limit (查询起始下标,pageSize)-- 列如
-- limit 0,5 1~5 (1-1)*5 第一页
-- limit 5,5 (2-1)*5 第二页-- 分页,每页只显示五条数据
select s.'StudentNo','StudentName','SubjectName','StudentResult'
from student s
inner join 'result'r
on s.StudnetNo = r.StudentNo
inner join 'subject' sub
on r.'SubjectNo' = sub.'SubjectNo'
where sbujectName = '数据库结构-1'
order by StudentReult ASC
limit 0,5 -- 练习
-- 查询 JAVA第一学年,课程成绩排名前十的学生,并且分数要求大于80的学生信息(学号,姓名,课程名称,分数)
select s.StudentNo,StudentName,SubjectName,StudentResult
from student s
inner join result r
on s.StudentNo = r.StudentNo
inner join `subject` sub
on sub.SubjectNo = r.SubjectNo
where SubjectName = 'JAVA第一学年' and StudentResult>=80
order by StudentResult DESC
limit 0,10-
子查询
本质:在where语句中嵌套一个子查询语句
-- 查询 数据库结构-1 的所有考试结果(学号,科目编号,成绩),降序排序
-- 方式一: 使用连接查询
select `StudentNo`,r.`SubjectNo`,`StudentResult`
from `result` r
inner join `subject` sub
on r.SubjectNo = sub.SubjectNo
where SubjectName = '数据结构-1'
order by StudentResult DESC-- 方式二:使用子查询(由里及外)
select `StudentNo`,`SubjectNo`,`StudentResult`
from `result`
where SubjectNo = (select SubjectNo from `subject`where SubjectName = '数据库结构-1'
)-- 分数不小于80分的学生的学号和姓名
select distinct s.`StudentNo`,`StudnetName`
from student s
innerr join result r
on r.StudentNo=s.StudentNo
where `StudentResult`>=80--在这个基础上增加一个科目, 高等数学-2
select distinct s.`StudentNo`,`StudentName`
from student s
inner join result r
on r.StudentNo = s.StudentNo
where `StudentResult`>=80 and `SubjectNo` =(select `SubjectNo` from `subject`where `SubjectName` = '高等数学-2'
)-- 查询课程为 高等数学-2 且分数不小于 80 的同学学号、姓名(由里及外)
select StudentNo,StudentName from student where StudentNo in(select StudentNo from result where StudentResult>80 and SubjectNo =(select SubjectNo from `subject` where `SubjectName` = `高等数学-2`)
)-
分组过滤
-- 查询不同课程的平均分,最高分,最低分,平均分大于80
-- 核心:(根据不同的课程分组)
select SubjectName,AVG(StudentResult) as 平均分,MAX(StudentResult) as 最高分,MIN(StudentResult) as 最低分
from result r
inner join `subject` sub
or r.`SubjectNo` = sub.`SubjectNo`
group by r.SubjectNo -- 通过什么字段来分组
having 平均分>80-
-
5.MySQL函数
常用函数
-- 数学运算
select abs(-8) -- 绝对值
select ceiling(9.4) -- 向上取整
select floor(9.4) --向下取整
select rand() -- 返回一个 0~1 之间的随机数
select sign(10) -- 判断一个数的符号 0-0 负数 - -1 正数 - 1-- 字符串函数
select char_length('asfgdsg') -- 字符串长度
select contat('sdf','shg','hui') -- 拼接字符串
select insert('我爱编程helloworld',1,2,'超级热爱') -- 查询从某个位置开始替换某个长度
select lower('Kuangshen') -- 小写字母
select upper('Kuangshen') -- 大写字母
select instr('Kuangshen','h') -- 返回第一次出现的字串索引
select replace('狂神说坚持就能成功','坚持','努力') -- 替换出现的字符串
select substr('狂神说坚持就能成功',4,6) -- 返回指定的字符串(源字符串,截取位置,截取的长度)
select reverse('清晨我上马') --反转-- 查询姓周的同学 ,将姓改为邹
select replace(studentname,'周','邹') from student
where studentName like '周%'-- 时间和日期函数(记住)
select current_date() -- 获取当前日期
select curdate() --获取当前日期
select now() -- 获取当前时间
select localtime() -- 本地时间
select sysdate() -- 系统时间-- 系统
select system_user()
select user()
select version()-
聚合函数(常用)
| 函数名称 | 描述 |
|---|---|
| COUNT() | 计数 |
| SUM() | 求和 |
| AVG() | 平均值 |
| MAX() | 最大值 |
| MIN() | 最小值 |
-- ========== 聚合函数 ============
-- 都能够统计 表中的数据 (想查询一个表中由多少记录,就用这个count())
select count('BornDate') from student; -- count(字段),会忽略所有null值
select count(*) from student; -- count(*),不会忽略null值,本质计算行数
select count(1) from result; -- count(1),不会忽略所有的null值, 本质 计算行数-
数据库级别的MD5加密(扩展)
什么是MD5?
主要增强算法复杂度和不可逆性
MD5不可逆,具体的值的MD5是一样的
MD5破解网站的原理,背后有一个字典-->MD5加密后的值,加密前的值
-- ========== 测试MD5 加密 =========
create table 'testmd5'(`id` int(4) not null,`name` varchar(20) not null,`pwd` varchar(50) not null,primary key(`id`)
)engine=innodb default charset=utf8mb4-- 明文密码
insert into testmd5 values(1,'zhangsan','123456')-- 加密
update testmd5 set pwd=MD5(pwd) where id = 1
update testmd5 set pwd=MD5(pwd) -- 加密全部-- 插入时加密
insert into testmd5 values(2,'xiaoming',MD5('123456'))-- 如何校验:将用户传递进来的密码,进行MD5加密,然后对比加密后的值
select * from testmd5 where `name`='xiaoming' and pwd=MD5('123456')-
-
6.事务
MySQL中的事务是一种机制,用于将一组SQL语句作为一个整体来执行,要么全部成功,要么全部失败。事务的核心目的是确保数据的完整性和一致性,特别是在复杂的数据库操作中,例如在涉及多个表的更新、插入或删除操作时,事务能够保证这些操作要么完整地完成,要么在遇到错误时能够恢复到操作之前的状态,从而避免数据的不一致。
事务原则:ACID原则 原子性,一致性,隔离性,持久性 (脏读,幻读...)
- 原子性(Atomicity):要么成功,要么失败
- 一致性(Consistency):事务前后的数据完整性要保证一致
- 隔离性(Isolation):事务的隔离性是多个用户并发访问数据库时,数据为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离
- 持久性(Durability):事务一旦提交则不可逆,被持久化到数据库中
隔离所导致的一些问题
- 脏读:指一个事务读取了另外一个事务未提交的数据。
- 不可重复读:在一个事务内读取表中的某一行数据,多次读取结果不同。(这个不一定是错误,只是某些场合不对)
- 虚读(幻读):是指在一个事务内读取到了别的事务插入的数据,导致前后读取数量总量不一致。
执行事务
-- mysql 是默认开启事务自动提交的
set autocommit = 0 /* 关闭 */
set autocommit = 1 /* 开启 */-- 手动处理事务
-- 事务开启
start transaction -- 标记一个事务的开始,从这个之后的sql都在同一个事务内
-- 提交:持久化(成功!)
commit
-- 回滚:回到原来的样子 (失败!)
rollback
-- 事务结束
set autocommit = 1 -- 开启自动提交-- 了解
savepoint 保存点名称 -- 设置一个事务的保存点
rollback to savepoint 保存点名称 -- 回滚到保存点
release savepoint -- 撤销保存点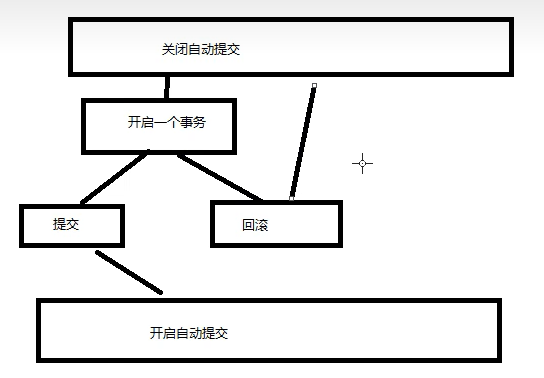
模拟转账
-- 转帐
create database shop character set utf8 collate utf8_general_ci
use shopcreate table `account`(`id` int(3) not null auto_increment,`name` varchar(30) not null,`money` decimal(9,2) not null,primary key (`id`)
)engine=innodb default charset=utf8insert into account(`name`,`money`) values ('A',2000.00)
insert into account(`name`,`money`) values ('B',10000.00)-- 模拟转账: 事务
set autocommit = 0; -- 关闭自动提交
start transaction -- 开启一个事务(一组事务)update accoount set money =money-500 where `name` = 'A' -- A减500
update accoount set money =money+500 where `name` = 'B' -- B加500
commit; -- 提交事务,就被持久化了
rollback; -- 回滚set autocommit = 1; -- 恢复默认值-
-
7.索引
索引是数据库中用于优化数据检索性能的一种数据结构。它类似于书籍的目录,通过在表中创建索引,数据库系统可以快速定位到表中的特定行,而无需扫描整个表的数据。
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。
索引的分类
-
主键索引(primary key)
-
唯一标识,主键不可重复,只能有一个列作为主键
-
-
唯一索引(unique key)
-
唯一索引则要求索引列中的值必须是唯一的,多个列都可以标识为 唯一索引
-
-
常规索引(key/index)
-
默认的,index、key关键字来设置
-
-
全文索引(FullText)
-
在特定的数据库引擎下才有,MyISAM
-
快速定位数据
-
基础语法
-- 索引的使用
-- 1、在创建表的时候给字段增加索引
-- 2、创建完毕后,增加索引-- 显示所有的索引信息
show index from student-- 增加一个全文索引 索引名(列名)
alter table school.student add fulltext index `studentName`(`studentName`);-- explain 分析sql执行情况
explain select * from student; -- 非全文索引explain select * from student where match(studnetName) against('刘')100万数据测试索引
索引在小数据量的时候,用处不大,但是在大数据的时候,区别十分明显
create table `app_user` (`id` bigint(20) unsigned not null auto_increment,`name` varchar(50) default '' comment '用户昵称',`email` varchar(50) not null comment '用户邮箱',`phone` carchar(20) default '' comment '手机号',`gender` tinyint(4) unsigned default '0' comment '性别(0:男;1:女)',`password` varchar(100) not null comment '密码',`age` tinyint(4) default '0' comment '年龄',`create_time` datetime default current_timestamp,`update_time` timestamp null default current_timestamp on update current_timestamp,primary key (`id`)
) engine=innodb default charset=utf8mb4 comment='app用户表'-- 插入100万数据
delimiter $$ -- 写函数之前必须要写,标志create function mock_data()
returns int
begindeclare num int default 1000000;declare i int default 0;while i<num do-- 插入insert into app_user(`name`,`email`,`phone`,`gender`,`password`,`age`)
values(concat('用户',i),'2347863@qq.com',concat('18',floor(rand()*((999999999-100000000)+100000000))),floor(rand()*2),uuid(),floor(rand()*100));set i = i + 1;end whilereturn i;
end;explain select * from app_user where `name`='用户9999'; -- 0.993 sec(查询了991749 rows)
select * from student; -- 对比- id_表名_字段名
-- create index 索引名 on 表(字段)
create index id_app_user on app_user(`name`);explain select * from app_user where `name`='用户9999'; -- 0.001 sec(查询了1 row)-
索引原则
-
索引不是越多越好
-
不要对进程变动数据加索引
-
小数据量的表不要加索引、
-
索引一般一般加在常用来查询的字段上
索引的数据结构
- Hash类型的索引
- Btree:InnoDB的默认数据结构
阅读:http://blog.codinglabs.org/articles/theory-of-mysql-index.html
-
-
8.权限管理和备份
用户管理
本质:对这张表进行增删改查
-- 创建用户 create user 用户名 identified by '密码'
create user kagnshen identified by '123456'-- 修改密码(修改当前用户密码)
set password = password('123456')
-- (修改指定用户密码)
set password for kuangshen = password('123456')-- 重命名 rename user 原来名字 to 新名字
rename user kuangshen to kuangshen2-- 用户授权 all privileges 全部权限 ,库.表
-- all privileges 除了给别人授权,其它的都能干
grant all privileges on *.* to kuagnshen2-- 查询权限
show grants for kuangshen2 -- 查看指定用户的权限
show grants foe root@localhost -- 查看root权限-- root用户权限:GRANT ALL PRIVILEGES ON *.* TO 'root'@'localhost' WITH GRANT OPTION
-- 撤销权限 revoke 哪些权限,在哪个库撤销,给谁撤销
revoke all privileges on *.* from kuangshen2-- 删除用户
drop user kuangshen-
MySQL备份
为什么要备份:
-
保证重要的数据不丢失
-
数据转移
MySQL数据库备份的方式
-
直接拷贝物理文件
-
在SQLyog这种可视化工具中手动导出
-
在想要导出的表或库中,右键,选择备份或导出
-
-
使用命令行导出
mysqldump命令行使用
# mysqldump -h主机 -u用户名 -p密码 数据库 表名 >物理磁盘位置/文件名
mysqldump -hlocalhost -uroot -p123456 school >D:/a.sql# mysqldump -h主机 -u用户名 -p密码 数据库 表1 表2 表3 >物理磁盘位置/文件名
mysqldump -hlocalhost -uroot -p123456 student result >D:/b.sql# mysqldump -h主机 -u用户名 -p密码 数据库 >物理磁盘位置/文件名
mysqldump -hlocalhost -uroot -p123456 school >D:/c.sql# 导入
# 登录的情况下,切换到指定的数据库
# source 备份文件
source d:/a.sqlmysql -u用户名 -p密码 库名< 备份文件-
-
9.规范数据库设计
三大范式
第一范式(1NF)
原子性:保证每一列不可再分
第二范式(2NF)
前提:满足第一范式
每张表只描述一件事
第三范式(3NF)
前提:满足第一范式和第二范式
第三范式需要确保数据表中每一列数据都和主键直接相关,而不能间接相关
详细资料:关系型数据库设计:三大范式的通俗理解 - 景寓6号 - 博客园
-
规范性 和 性能的问题
关联查询的表不得超过三张表
-
考虑商业化的需求和目标,(成本,用户体验!)数据库的性能更加重要
-
在规范性能问题的时候,需要适当的考虑一下 规范性!
-
故意给某些表增加一些冗余的字段。(从多表查询变为单表查询)
-
故意增加一些计算列(从大数据量降低为小数据量的查询:索引)
-
-
10.JDBC(重点)
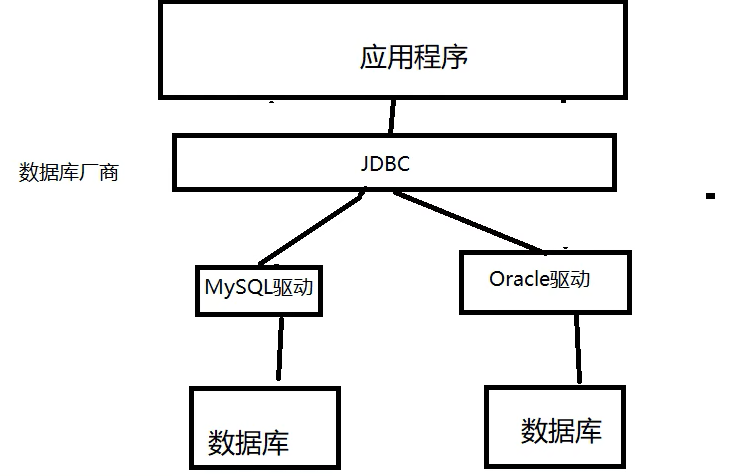
JDBC(Java Database Connectivity)是Java语言中用于执行SQL语句的一个标准API,它提供了一种统一的方式来访问各种关系数据库管理系统(RDBMS)。
JDBC的主要作用是为Java程序提供与数据库交互的接口,使得Java程序能够方便地连接数据库、执行SQL语句、处理查询结果等。它屏蔽了不同数据库之间的差异,使得Java程序可以通过相同的API来操作不同的数据库。
这些规范的实现由具体的厂商去做,对于开发人员来说,我们只需要掌握JDBC接口的操作即可。
数据库驱动
JDBC驱动程序是JDBC架构的核心组件,它充当Java应用程序和数据库管理系统之间的桥梁。当Java程序通过JDBC API向数据库发送请求时,JDBC驱动程序会将这些请求转换为数据库能够理解的协议,并将数据库返回的结果再转换为Java程序可以处理的形式。
第一个JDBC程序
创建测试数据库
CREATE DATABASE jdbcStudy CHARACTER SET utf8 COLLATE utf8_general_ci;USE jdbcStudy;CREATE TABLE users(id INT PRIMARY KEY,NAME VARCHAR(40),PASSWORD VARCHAR(40),email VARCHAR(60),birthday DATE
);INSERT INTO users(id,NAME,PASSWORD,email,birthday)
VALUES(1,'zhansan','123456','zs@sina.com','1980-12-04');
INSERT INTO users(id,NAME,PASSWORD,email,birthday)
VALUES(2,'lisi','123456','lisi@sina.com','1981-12-04');
INSERT INTO users(id,NAME,PASSWORD,email,birthday)
VALUES(3,'wangwu','123456','wangwu@sina.com','1979-12-04');SELECT * FROM users导入数据库驱动
编写测试代码
- 加载驱动
- 连接数据库 DriverManager
- 获得执行sql的对象 Statement
- 获得返回的结果集
- 释放连接
//我的第一个JDBC程序
public class JdbcFirstDemo {public static void main(String[] args) throws ClassNotFoundException, SQLException {//1. 加载驱动Class.forName("com.mysql.jdbc.Driver"); //固定写法//2. 用户信息和url//useUnicode=true characterEncoding=utf8 useSSL=true//支持中文编码 设置中文字符集 安全连接String url = "jdbc:mysql://localhost:3306/jdbcstudy?useUnicode=true&characterEncoding=utf8&useSSL=true";String username = "root";String password = "123456";//3. 连接成功,数据库对象Connection connection = DriverManager.getConnection(url, username, password);//4.执行SQL对象Statement statement = connection.createStatement();//5. 用SQL对象去执行SQL,可能存在结果,查看返回结果String sql = "SELECT * FROM users";ResultSet resultSet = statement.executeQuery(sql); // 结果集中封装了我们全部的查询出来的结果while (resultSet.next()){System.out.println("id="+resultSet.getObject("id"));System.out.println("name="+resultSet.getObject("NAME"));System.out.println("pwd="+resultSet.getObject("PASSword"));System.out.println("email="+resultSet.getObject("email"));System.out.println("birth="+resultSet.getObject("birthday"));System.out.println("=================================");}// 6. 释放连接resultSet.close();statement.close();connection.close();}
}DriverManager
// DriverManager.registerDriver(new com.mysql.cj.jdbc.Driver()); // 不推荐
Class.forName("com.mysql.cj.jdbc.Driver"); //固定写法,加载驱动URL
//useUnicode=true&characterEncoding=utf8&useSSL=true
//支持中文编码 设置中文字符集 安全连接
String url = "jdbc:mysql://localhost:3306/jdbcstudy?useUnicode=true&characterEncoding=utf8&useSSL=true";
// mysql -- 3306
// 协议://主机地址:端口号/数据库名?参数1&参数2&参数3// oralce -- 1521
// jdbc:oracle:thin:@localhost:1521:sidStatement执行SQL的对象
String sql = "SELECT * FROM users"; // 编写SQLstatement.executeQuery(); // 查询操作返回 ResultSet
statement.execute(); // 执行任何SQL
statement.executeUpdate(); // 更新、插入、删除 都是用这个,返回一个受影响的行数ResultSet查询的结果集:封装了所有的查询结果。
获得指定的数据类型
resultSet.getObject(); // 在不知道列类型的情况下使用
// 如果知道列的使用类型就使用指定的类型
resultSet.getString();
resultSet.getInt();
resultSet.getFloat();
resultSet.getDate();遍历,指针
resultSet.beforeFirst(); // 移动到最前面
resultSet.afterLast(); // 移动到最后面
resultSet.next(); // 移动到下一个数据
resultSet.previous(); // 移动到前一行
resultSet.absolute(row); // 移动到指定行释放资源
// 6. 释放连接
resultSet.close();
statement.close();
connection.close(); //耗资源,用完关掉-
statement对象
Jdbc中的statement对象用于向数据库发送SQL语句,想完成对数据库的增删改查,只需要通过这个对象向数据库发送增删改查语句即可。
- Statement.executeUpdate方法,用于向数据库发送增、删、改的语句,executeUpdate执行完后,将会返回一个整数(即增删改语句导致了数据库几行数据发生了变化)
- Statement.executeQuery方法用于向数据库发送查询语句,executeQuery方法返回代表查询结果的ResultSet对象
CRUD操作-create
使用executeUpdate(String sql) 方法完成数据库添加操作,示例操作:
Statement st = conn.createStatement();
String sql = "insert into user(...) values(...)";
int num = st.executeUpdate(sql);
if(num>0){System.out.println("插入成功!");
}CRUD操作-delete
使用executeUpdate(String sql) 方法完成数据库删除操作,示例操作:
Statement st = conn.createStatement();
String sql = "delete from user where id=1";
int num = st.executeUpdate(sql);
if(num>0){System.out.println("删除成功!");
}CRUD操作-update
使用executeUpdate(String sql) 方法完成数据库修改操作,示例操作:
Statement st = conn.createStatement();
String sql = "update user set name='' where name=''";
int num = st.executeUpdate(sql);
if(num>0){System.out.println("修改成功!");
}CRUD操作-read
使用executeQuery(String sql) 方法完成数据查询操作,示例操作:
Statement st = conn.createStatement();
String sql = "select * from users where id=1";
ResultSet rs = st.executeQuery(sql);
while(rs.next()){// 根据获取列的数据类型,分别调用rs的相应方法映射到java对象中
}代码实现
1、提取工具类
public class JdbcUtils {private static String driver = null;private static String url = null;private static String username = null;private static String password = null;static {try{InputStream in = JdbcUtils.class.getClassLoader().getResourceAsStream("db.properties");Properties properties = new Properties();properties.load(in);driver = properties.getProperty("driver");url = properties.getProperty("url");username = properties.getProperty("username");password = properties.getProperty("password");// 1.驱动只加载一次Class.forName(driver);} catch (Exception e) {e.printStackTrace();}}//获取连接public static Connection getConnection() throws SQLException {return DriverManager.getConnection(url, username, password);}//释放资源public static void release(Connection conn, Statement st, ResultSet rs){if (rs!=null){try {rs.close();} catch (SQLException e) {e.printStackTrace();}}if (st!=null){try {st.close();} catch (SQLException e) {e.printStackTrace();}}if (conn!=null){try {conn.close();} catch (SQLException e) {e.printStackTrace();}}}}2、编写增删改的方法executeUpdate
public class TestInsert {public static void main(String[] args) {Connection conn = null;Statement st = null;ResultSet rs = null;try {conn = JdbcUtils.getConnection(); // 获取数据库连接st = conn.createStatement(); // 获得SQL的执行对象String sql = "INSERT INTO users(id,`NAME`,`PASSWORD`,`email`,`birthday`)" +"VALUES(4,'kuagnshen','123456','24736743@qq.com','2020-01-01')";int i = st.executeUpdate(sql);if (i>0){System.out.println("插入成功!");}} catch (SQLException e) {e.printStackTrace();}finally {JdbcUtils.release(conn,st,rs);}}
}
public class TestDelete {public static void main(String[] args) {Connection conn = null;Statement st = null;ResultSet rs = null;try {conn = JdbcUtils.getConnection(); // 获取数据库连接st = conn.createStatement(); // 获得SQL的执行对象String sql = "DELETE FROM users WHERE id =4";int i = st.executeUpdate(sql);if (i>0){System.out.println("删除成功!");}} catch (SQLException e) {e.printStackTrace();}finally {JdbcUtils.release(conn,st,rs);}}
}
public class TestUpdate {public static void main(String[] args) {Connection conn = null;Statement st = null;ResultSet rs = null;try {conn = JdbcUtils.getConnection(); // 获取数据库连接st = conn.createStatement(); // 获得SQL的执行对象String sql = "UPDATE users SET `NAME`='kuangshen' WHERE id=1";int i = st.executeUpdate(sql);if (i>0){System.out.println("更新成功!");}} catch (SQLException e) {e.printStackTrace();}finally {JdbcUtils.release(conn,st,rs);}}
}3、查询executeQuery
public class TestSelect {public static void main(String[] args) {Connection conn = null;Statement st = null;ResultSet rs = null;try {conn = JdbcUtils.getConnection();st = conn.createStatement();//SQLString sql = "select * from users where id =1";rs = st.executeQuery(sql); //查询完会返回一个结果集while (rs.next()){System.out.println(rs.getString("name"));System.out.println(rs.getString("email"));}} catch (SQLException e) {e.printStackTrace();}finally {JdbcUtils.release(conn,st,rs);}}
}SQL注入的问题
SQL注入是一种常见的安全漏洞,它发生在应用程序将用户输入直接嵌入SQL语句中时,攻击者可以通过精心构造的输入,篡改SQL语句的结构,从而执行恶意的SQL命令。这种攻击可能会导致数据泄露、数据篡改、权限提升,甚至控制整个数据库服务器。
// sql注入
public class SqlInjection {public static void main(String[] args) {
// login("kuangshen","123456");login(" 'or '1=1"," 'or '1=1"); //技巧}// 登录业务public static void login(String username,String password){Connection conn = null;Statement st = null;ResultSet rs = null;try {conn = JdbcUtils.getConnection();st = conn.createStatement();//SQL//SELECT * FROM users WHERE `name`='kuangshen' AND `password`= '123456'//SELECT * FROM users WHERE `name`=''or'1=1' AND `password`= ''or'1=1'String sql = "SELECT * FROM users WHERE `name`='"+username+"' AND `password`= '"+password+"'";rs = st.executeQuery(sql); //查询完会返回一个结果集while (rs.next()){System.out.println(rs.getString("name"));System.out.println(rs.getString("email"));}} catch (SQLException e) {e.printStackTrace();}finally {JdbcUtils.release(conn,st,rs);}}
}-
PreparedStatement对象
PreparedStatement 是 Java JDBC API 中的一个类,用于执行参数化的 SQL 语句。它是防止 SQL 注入攻击的关键工具,同时也能提高数据库操作的性能和可维护性。通过使用 PreparedStatement,可以将 SQL 语句与参数分开处理,从而避免了将用户输入直接拼接到 SQL 语句中所带来的安全风险。
1、新增
public class TestInsert {public static void main(String[] args) {Connection conn = null;PreparedStatement st = null;try {conn = JdbcUtils.getConnection();//区别//使用?占位符代替参数String sql = "insert into users(id,`name`,`password`,`email`,`birthday`) values(?,?,?,?,?)";st = conn.prepareStatement(sql);// 预编译SQL,先写SQL,然后不执行//手动给参数赋值st.setInt(1,4);st.setString(2,"xie");st.setString(3,"123456");st.setString(4,"2944268313@qq.com");// 注意点:数据库的Date和util包下的Date不一样 获取时间戳st.setDate(5,new Date(new java.util.Date().getTime()));//执行int i = st.executeUpdate();if (i>0){System.out.println("插入成功!");}} catch (SQLException e) {e.printStackTrace();}finally {JdbcUtils.release(conn,st,null);}}
}2、删除
public class TestDelete {public static void main(String[] args) {Connection conn = null;PreparedStatement st = null;try {conn = JdbcUtils.getConnection();//区别//使用?占位符代替参数String sql = "delete from users where id=?";st = conn.prepareStatement(sql);// 预编译SQL,先写SQL,然后不执行//手动给参数赋值st.setInt(1,4);//执行int i = st.executeUpdate();if (i>0){System.out.println("删除成功!");}} catch (SQLException e) {e.printStackTrace();}finally {JdbcUtils.release(conn,st,null);}}
}3、更新
public class TestUpdate {public static void main(String[] args) {Connection conn = null;PreparedStatement st = null;try {conn = JdbcUtils.getConnection();//区别//使用?占位符代替参数String sql = "update users set name=? where id=? ;";st = conn.prepareStatement(sql);// 预编译SQL,先写SQL,然后不执行//手动给参数赋值st.setString(1,"狂神");st.setInt(2,1);//执行int i = st.executeUpdate();if (i>0){System.out.println("更新成功!");}} catch (SQLException e) {e.printStackTrace();}finally {JdbcUtils.release(conn,st,null);}}
}4、查询
public class TestSelect {public static void main(String[] args) {Connection conn = null;PreparedStatement st = null;ResultSet rs = null;try {conn = JdbcUtils.getConnection();//区别//使用?占位符代替参数String sql = "select * from users where id=?";st = conn.prepareStatement(sql);// 预编译SQL,先写SQL,然后不执行//手动给参数赋值st.setInt(1,1);//执行rs = st.executeQuery();while (rs.next()){System.out.println(rs.getString("name"));}} catch (SQLException e) {e.printStackTrace();}finally {JdbcUtils.release(conn,st,rs);}}
}5、防止SQL注入
public class SqlInjection {public static void main(String[] args) {
// login("kuangshen","123456");login(" 'or '1=1"," 'or '1=1"); //技巧
// login("lisi","123456");}// 登录业务public static void login(String username,String password){Connection conn = null;PreparedStatement st = null;ResultSet rs = null;try {conn = JdbcUtils.getConnection();//SQL//SELECT * FROM users WHERE `name`='kuangshen' AND `password`= '123456'//SELECT * FROM users WHERE `name`=''or'1=1' AND `password`= ''or'1=1'String sql = "select * from users where `name`=? and `password`=?";//PreparedStatement 防止SQL注入的本质,把传递进来的参数当作字符//假设其中存在转义字符,比如说 ` 会被直接转义st = conn.prepareStatement(sql);st.setString(1,username);st.setString(2,password);rs = st.executeQuery(); //查询完会返回一个结果集while (rs.next()){System.out.println(rs.getString("name"));System.out.println(rs.getString("email"));}} catch (SQLException e) {e.printStackTrace();}finally {JdbcUtils.release(conn,st,rs);}}
}-
事务
代码实现
- 开启事务
conn.setAutoCommit(false); - 一组业务执行完毕,提交事务
- 可以在catch语句中显示地定义回滚语句,但默认失败就会回滚
public class TestTransaction1 {public static void main(String[] args) {Connection conn = null;PreparedStatement st = null;ResultSet rs = null;try {conn = JdbcUtils.getConnection();//关闭数据库自动提交,自动会开启事务conn.setAutoCommit(false);// 开启事务String sql1 = "update account set money = money-100 where name = 'A';";st = conn.prepareStatement(sql1);st.executeUpdate();String sql2 = "update account set money = money+100 where name ='B';";st = conn.prepareStatement(sql2);st.executeUpdate();//业务完毕提交事务conn.commit();System.out.println("成功!");} catch (SQLException e) {try {conn.rollback();} catch (SQLException ex) {ex.printStackTrace();}e.printStackTrace();}finally {JdbcUtils.release(conn,st,rs);}}
}-
数据库连接池
数据库连接池是一种用于管理数据库连接的技术,它通过复用数据库连接来提高数据库访问的效率和性能。在实际应用中,频繁地创建和关闭数据库连接会消耗大量的系统资源和时间,尤其是在高并发环境下,这可能会导致性能瓶颈。数据库连接池通过预先创建并维护一定数量的数据库连接,并在需要时将这些连接分配给请求的客户端,从而避免了每次访问数据库时都重新创建和关闭连接的开销。
池化技术:准备一些预先的资源,过来就连接预先准备好的
数据库连接池的工作原理可以概括为以下步骤:
-
初始化连接池:在应用启动时,连接池会根据配置参数(如最小连接数、最大连接数等)预先创建一定数量的数据库连接,并将这些连接存储在连接池中。
-
分配连接:当客户端请求数据库连接时,连接池会从池中取出一个空闲的连接并分配给客户端。如果连接池中没有可用的连接,连接池会根据配置策略(如等待、超时或创建新连接)进行处理。
-
使用连接:客户端获取到连接后,就可以通过该连接执行SQL语句,进行数据库操作。
-
归还连接:客户端完成数据库操作后,将连接归还给连接池。连接池会检查该连接是否仍然有效,如果有效,则将其标记为可用,以便下次分配;如果无效,则将其关闭并重新创建一个新连接。
-
清理连接:连接池会定期检查池中的连接,关闭那些长时间未被使用的连接,以释放系统资源。
以下是一些常用的数据库连接池:
-
C3P0:C3P0 是一个功能强大的数据库连接池,支持自动回收空闲连接、自动重连等特性。它还提供了丰富的配置选项,可以根据不同的需求进行灵活配置。
-
Druid:Druid 是阿里巴巴开源的一个数据库连接池,它不仅提供了高效的连接管理功能,还集成了SQL解析、SQL监控等功能。Druid 的配置灵活,支持多种数据库,并且具有良好的扩展性。
-
DBCP:DBCP(Database Connection Pool)是Apache Commons的一部分,是一个轻量级的数据库连接池。它提供了基本的连接池功能,但性能相对较低,适合小型应用程序。
-
-
🌟 如果这篇文章对你有帮助,或者让你有所收获,别忘了点赞👍、收藏📝和关注我呀!你的每一个支持都是我继续创作的动力!感谢你来过这里,希望我们能一起成长,一起进步!✨