Spring AI 系列之使用 Spring AI 开发模型上下文协议(MCP)
1. 概述
现代网页应用越来越多地集成大型语言模型(LLMs)来构建解决方案,这些解决方案不仅限于基于常识的问答。
为了增强 AI 模型的响应能力,使其更具上下文感知,我们可以将其连接到外部资源,比如搜索引擎、数据库和文件系统。然而,整合和管理多种格式和协议不同的数据源是一个挑战。
由 Anthropic 提出的模型上下文协议(Model Context Protocol,简称 MCP)解决了这一整合难题,提供了一种标准化的方式,将AI驱动的应用与外部数据源连接。通过MCP,我们可以在原生大型语言模型基础上构建复杂的智能代理和工作流。
在本教程中,我们将通过实际实现MCP的客户端-服务器架构,结合 Spring AI 来理解 MCP 的概念。我们将创建一个简单的聊天机器人,并通过 MCP 服务器扩展其功能,实现网页搜索、文件系统操作以及访问自定义业务逻辑。
2. 模型上下文协议基础(Model Context Protocol )
在深入实现之前,让我们先仔细了解 MCP 及其各个组成部分:
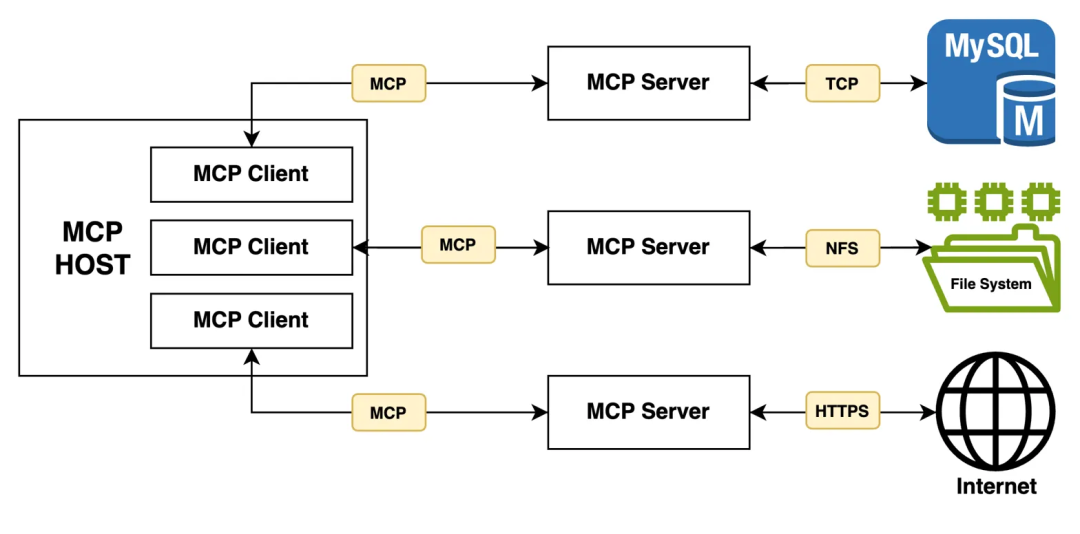
MCP 遵循客户端-服务器架构,围绕以下几个关键组件展开:
-
MCP Host(主机): 我们的主应用程序,集成了大型语言模型(LLM),并需要通过它连接外部数据源。
-
MCP Clients(客户端):负责与 MCP 服务器建立并维护一对一连接的组件。
-
MCP Servers(服务器): 集成外部数据源的组件,向客户端暴露交互功能。
-
Tools(工具):指 MCP 服务器暴露供客户端调用的可执行函数或方法。
此外,为了实现客户端与服务器之间的通信,MCP 提供了两种传输通道:
-
标准输入/输出(stdio)用于通过本地进程和命令行工具的标准输入输出流进行通信。
-
服务器发送事件(Server-Sent Events,SSE)用于基于 HTTP 的客户端和服务器之间的通信。
MCP是一个复杂且内容丰富的话题,建议参考官方文档以获得更多详细信息。
3. 创建 MCP 主机
既然我们已经对 MCP 有了一个整体的了解,接下来就开始动手实践 MCP 架构的实现。
我们将使用 Anthropic 的 Claude 模型来构建一个聊天机器人,作为我们的 MCP 主机。当然,也可以使用 Hugging Face 或 Ollama 上的本地大型语言模型,具体使用哪个 AI 模型对文中例子并不是关键的。
3.1 依赖项
首先,我们来向项目的 pom.xml 文件中添加所需的依赖项:
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-anthropic-spring-boot-starter</artifactId><version>1.0.0-M6</version>
</dependency>
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-mcp-client-spring-boot-starter</artifactId><version>1.0.0-M6</version>
</dependency>Anthropic starter 依赖是对 Anthropic 消息 API 的封装,我们将在应用中使用它与 Claude 模型进行交互。此外,我们还引入了
MCP client starter 依赖,它允许我们在Spring Boot 应用中配置客户端,从而与MCP 服务器保持一对一连接。由于当前版本1.0.0-M6 是一个里程碑版本,我们还需要在 pom.xml 中添加 Spring Milestones 仓库:
<repositories><repository><id>spring-milestones</id><name>Spring Milestones</name><url>https://repo.spring.io/milestone</url><snapshots><enabled>false</enabled></snapshots></repository>
</repositories>这个仓库用于发布里程碑版本,与标准的 Maven Central 仓库不同。鉴于我们在项目中使用了多个Spring AI的starter,接下来我们还将在 pom.xml中引入Spring AI的版本管理(Bill of Materials,BOM):
<dependencyManagement><dependencies><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-bom</artifactId><version>1.0.0-M6</version><type>pom</type><scope>import</scope></dependency></dependencies>
</dependencyManagement>添加了 BOM 之后,我们可以去掉两个 starter 依赖中的版本号。BOM 能避免版本冲突风险,确保我们的 Spring AI 依赖相互兼容。
接下来,我们在 application.yaml 文件中配置 Anthropic 的 API 密钥和聊天模型:
spring:ai:anthropic:api-key: ${ANTHROPIC_API_KEY}chat:options:model: claude-3-7-sonnet-20250219我们使用 ${} 属性占位符从环境变量中加载 API 密钥的值。
此外,我们指定了 Anthropic 最新且最智能的模型 Claude 3.7 Sonnet,模型 ID 为 claude-3-7-sonnet-20250219。你也可以根据需求使用其他模型。
配置好上述属性后, Spring AI会自动创建一个类型为ChatModel的 Bean,方便我们与指定模型进行交互。
3.2 配置 MCP 客户端以连接 Brave Search 和文件系统服务器
接下来,让我们为两个预构建的 MCP 服务器实现——Brave Search 和 Filesystem,配置 MCP 客户端。这些服务器将使我们的聊天机器人能够执行网页搜索和文件系统操作。
首先,在 application.yaml 文件中注册 Brave Search MCP 服务器的 MCP 客户端:
spring:ai:mcp:client:stdio:connections:brave-search:command: npxargs:- "-y"- "@modelcontextprotocol/server-brave-search"env:BRAVE_API_KEY: ${BRAVE_API_KEY}这里我们配置了一个使用 stdio 传输的客户端。我们指定了通过 npx 命令来下载并运行基于TypeScript 的
@modelcontextprotocol/server-brave-search 包,并使用 -y 参数自动确认所有安装提示。
此外,我们还提供了 BRAVE_API_KEY 作为环境变量。
接下来,我们配置一个用于文件系统 MCP 服务器的 MCP 客户端:
spring:ai:mcp:client:stdio:connections:filesystem:command: npxargs:- "-y"- "@modelcontextprotocol/server-filesystem"- "./"与之前的配置类似,我们指定了运行文件系统 MCP 服务器包所需的命令和参数。通过这个配置,我们的聊天机器人可以在指定目录执行创建、读取和写入文件等操作。
这里我们只配置了当前目录(./)作为文件系统操作的路径,但也可以通过将多个目录添加到 args 列表中来指定更多目录。
应用启动时,Spring AI 会扫描我们的配置,创建 MCP 客户端, 并与对应的MCP服务器建立连接。同时,它会创建一个类型为 SyncMcpToolCallbackProvider 的 Bean,提供所有配置的 MCP 服务器暴露的工具列表。
3.3 构建一个基础聊天机器人
在配置好AI模型和 MCP 客户端之后,我们来构建一个简单的聊天机器人:
@Bean
ChatClient chatClient(ChatModel chatModel, SyncMcpToolCallbackProvider toolCallbackProvider) {return ChatClient.builder(chatModel).defaultTools(toolCallbackProvider.getToolCallbacks()).build();
}我们首先使用 ChatModel 和 SyncMcpToolCallbackProvider 这两个 Bean 创建一个 ChatClient 类型的 Bean。ChatClient 类将作为我们与聊天完成模型(即 Claude 3.7 Sonnet)交互的主要入口。
接下来,我们注入ChatClient Bean 来创建一个新的 ChatbotService 类:
String chat(String question) {return chatClient.prompt().user(question).call().content();
}我们创建了一个chat()方法,在该方法中将用户的问题传递给 chatClient Bean,并直接返回 AI 模型的响应结果。
既然我们已经实现了服务层,接下来我们来基于它暴露一个 REST API:
@PostMapping("/chat")
ResponseEntity<ChatResponse> chat(@RequestBody ChatRequest chatRequest) {String answer = chatbotService.chat(chatRequest.question());return ResponseEntity.ok(new ChatResponse(answer));
}
record ChatRequest(String question) {}
record ChatResponse(String answer) {}我们将在本教程后续部分使用上述 API 端点与聊天机器人进行交互。
4. 创建自定义 MCP 服务器
除了使用预构建的 MCP 服务器之外,我们还可以创建自己的 MCP 服务器,以便通过自定义业务逻辑扩展聊天机器人的功能。
接下来,我们来探索如何使用 Spring AI 创建自定义 MCP 服务器。
本节将创建一个新的 Spring Boot 应用。
4.1 依赖项
首先,在我们的 pom.xml 文件中添加必要的依赖:
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-mcp-server-webmvc-spring-boot-starter</artifactId><version>1.0.0-M6</version>
</dependency>我们引入了 Spring AI 的 MCP 服务器依赖,该依赖提供了创建支持基于 HTTP 的 SSE 传输的自定义 MCP 服务器所需的相关类。
4.2 定义并暴露自定义工具
接下来,我们定义一些自定义工具,这些工具将由我们的 MCP 服务器对外暴露。
我们将创建一个 AuthorRepository 类,提供获取作者详情的方法:
class AuthorRepository {@Tool(description = "Get Baeldung author details using an article title")Author getAuthorByArticleTitle(String articleTitle) {return new Author("John Doe", "john.doe@baeldung.com");}@Tool(description = "Get highest rated Baeldung authors")List<Author> getTopAuthors() {return List.of(new Author("John Doe", "john.doe@baeldung.com"),new Author("Jane Doe", "jane.doe@baeldung.com"));}record Author(String name, String email) {}
}在本示例中,我们返回的是硬编码的作者信息,但在真实应用中,这些工具通常会与数据库或外部 API 进行交互。
我们使用@Tool注解为两个方法添加标记,并为每个方法提供简要描述。这个描述有助于AI模型根据用户输入判断是否调用这些工具,并将结果整合到其响应中。
接下来,我们将这些工具注册到 MCP 服务器中:
@Bean
ToolCallbackProvider authorTools() {return MethodToolCallbackProvider.builder().toolObjects(new AuthorRepository()).build();
}我们使用 MethodToolCallbackProvider 从 AuthorRepository 类中定义的工具创建一个 ToolCallbackProvider 类型的 Bean。那些使用 @Tool 注解的方法会在应用启动时作为 MCP 工具对外暴露。
4.3 为自定义 MCP 服务器配置 MCP 客户端
最后,为了在我们的聊天机器人应用中使用这个自定义的 MCP 服务器,我们需要为它配置一个对应的 MCP 客户端:
spring:ai:mcp:client:sse:connections:author-tools-server:url: http://localhost:8081在 application.yaml 文件中,我们为自定义 MCP 服务器配置了一个新的客户端。注意,这里我们使用的是 sse(服务器发送事件)传输类型。
此配置假设 MCP 服务器运行在 http://localhost:8081,如果你的服务器运行在不同的主机或端口,请确保更新该 URL。
通过这个配置,我们的MCP客户端现在除了可以调用Brave Search和文件系统MCP服务器提供的工具外,还可以调用自定义 MCP 服务器所暴露的工具。
5. 与我们的聊天机器人交互
现在我们已经构建好了聊天机器人,并将其集成了多个 MCP 服务器,接下来我们就来实际与它进行交互并测试效果。
我们将使用 HTTPie CLI 工具调用聊天机器人的 API 端点:
http POST :8080/chat question="How much was Elon Musk's initial offer to buy OpenAI in 2025?"在这里,我们向聊天机器人发送了一个关于 LLM 知识截止日期之后发生事件的简单问题。让我们看看它会返回什么样的回答:
{"answer": "Elon Musk's initial offer to buy OpenAI was $97.4 billion. [Source](https://www.reuters.com/technology/openai-board-rejects-musks-974-billion-offer-2025-02-14/)."
}正如我们所看到的,聊天机器人能够使用配置好的 Brave Search MCP 服务器执行网页搜索,并提供一个准确的答案以及相应的来源。
接下来,我们来验证聊天机器人是否可以通过 Filesystem MCP 服务器执行文件系统操作:
http POST :8080/chat question="Create a text file named 'mcp-demo.txt' with content 'This is awesome!'."我们指示聊天机器人创建一个名为mcp-demo.txt的文件,并写入特定内容。让我们看看它是否能够完成这个请求:
{"answer": "The text file named 'mcp-demo.txt' has been successfully created with the content you specified."
}聊天机器人返回了一个成功的响应。我们可以在 application.yaml 文件中指定的目录中验证该文件是否确实已被创建。
最后,我们来验证聊天机器人是否能够调用我们自定义 MCP 服务器所暴露的工具。我们将通过提及一篇文章的标题来询问作者的详细信息:
http POST :8080/chat question="Who wrote the article 'Testing CORS in Spring Boot?' on Baeldung, and how can I contact them?"让我们调用这个 API,看看聊天机器人的响应中是否包含了我们预设的作者信息:
{"answer": "The article 'Testing CORS in Spring Boot' on Baeldung was written by John Doe. You can contact him via email at [john.doe@baeldung.com](mailto:john.doe@baeldung.com)."
}上述响应验证了聊天机器人是通过我们自定义MCP服务器所暴露的getAuthorByArticleTitle() 工具获取信息的。
我们强烈建议你在本地搭建完整的代码环境,并尝试使用不同的提示语与聊天机器人进行交互,深入体验其功能。
6. 总结
在本文中,我们深入探讨了 模型上下文协议(Model Context Protocol, MCP),并通过 Spring AI 实现了其客户端-服务器架构。
首先,我们使用 Anthropic 的 Claude 3.7 Sonnet 模型构建了一个简单的聊天机器人,作为我们的 MCP 主机(Host)。
接着,为了让聊天机器人具备网页搜索能力并支持文件系统操作,我们分别为 Brave Search API 和 Filesystem 的MCP服务器配置了对应的 MCP 客户端。
最后,我们创建了一个自定义的MCP 服务器,并在MCP 主机应用中配置了对应的 MCP 客户端,使聊天机器人能够调用我们自己的业务逻辑工具。
关注我不迷路,系列化的给您提供当代程序员需要掌握的现代AI工具和框架