基于AI自动生成测试用例

学习一门技术语言最好的方式还是多敲多练多实践,deepseek的出现让之前一直辗转于各大网站搜索各种想要知道的内容变得十分便捷高效,只要你能准确的描述想要知道的信息,基本它就像一个专家级别的咨询师一样,给你答疑解惑,还是免费的,解决了各种翻来覆去都找不到解决方案。要不就是没有强关联的解决方案,要不就是各种需要付费看广告的博客文章视频,过程稍长且很容易让人放弃寻找答案的热情。
看到视频号说的deepseek的出现会让广大自媒体特别是那种咨询类博主先失业,中国即将迈向共产主义,也不是不可能了。春节期间在家深度使用了一下deepseek,除了经常服务器超时这个问题外,总体感觉还是不错的。只要能给出明确的指令,把它当成自的小助手,至少问了10次,总有一次能够准确给出你想要的回答的。这种体验问题如果放到百度搜索首页也许就是P0级别故障了,但是在最近deepseek的官网上出现,好像就变得可以理解,问题不大,访问量激增导致的服务端底层算力要跟不上了。

01. AI 在软件测试领域的解决方案
作为一名软件测试开发人员,对于AI 在测试领域的运用实践问了下deekseep , 虽然给出的方案好像没有特别创新,但是它还是能够针对每种方案给出具体的技术实现细节的,此时感觉又自我质疑了一波测试开发这个工作岗位的价值所在。
deepseek 关于这个问题的思考过程:(此时感觉自己对于这个问题的思考有点过于简单了,哎,人和AI有啥可比的呢~)

02. 自动生成测试用例
在测试领域的应用AI 的运用,也许第一时间想到的就是自动分析需求文档生成测试用例,不管是人工的还是自动化测试用例,执行这部分也许就稍微难了一些,暂时没有看到比较好的例子。
关于借助大模型的能力智能生成用例,deepseek给出的根据Git Diff代码差异来生成增量用例这个想法感觉还不错,适合自动生成单测。
deepseek的回答:

03. 本地部署实践
小白开始了第一个本地化体验项目,【基于需求文档生成测试用例】,把这个实践过程记录一下,(多年后回看会不会觉得当前的技术也太low了吧)当然这个方案都是让deepseek给出的,感觉以后很多岗位是不是就变成了那种纯执行的工作方式了,思考过程,检索信息的过程,AI 都一一给你列出来了。
1.技术选型
由于没有云服务器,也只是自己玩玩,也不想用openAI 的接口,免费为先

看到的deepseek给的技术选型,啥是llama.cpp 看不懂,搜索一下:开源项目,它专门为在本地CPU上部署量化模型而设计。

实现流程:

2.下载llama.cpp
下载完后需要进行编译
$ cmake -B build $ cmake --build build --config Release

项目根目录或者bin目录下是生成的可执行文件。此目录下的 llama-cli 和main 就是llama.cpp的命令行程序。
编译成功后可以加载模型测试一下效果:(交互模式)
$ ./llama-cli -m /Users/fengruxue/Documents/AIWorkplace/autoGenCase/model/tinyllama-1.1b-chat-v1.0.Q2_K.gguf --prompt "北京有什么好玩的地方"
输入问题,就可以看到终端在输出答案,证明llama.cpp 已经编译成功,并能使用TinyLlama 模型进行问题的推理回答。
使用 DeepSeek-R1-Distill-Qwen-1.5B-Q2_K.gguf 的推理答案,奇怪会有重复的回答

3.创建python环境
要会用大模型解决实际问题还是需要先懂点python 语法,要不代码别说不会写,语法规则看都看不懂,之前还是写JAVA 比较多,python基本没有用过,春节期间在b站快速学了一轮python基本的语法,好歹也能看懂deepseek回答中给出的技术编码实现了。
1.创建python虚拟环境: python -m venv testgen-env

2.激活: source testgen-env/bin/activate
4.下载deepseek官方模型
到这个网站下个deepseek的官方大模型,需要科学上网,(HuggingFace 为AI 开发者的github):
huggingface官网: https://huggingface.co/deepseek-ai
deepseek官网: https://www.deepseek.ai/
此时不懂deepseek 这些版本的区别在哪,感觉自己的电脑要跑不起来,deepseesk 找不到GGUF 格式的文件,换个TinyLlama的试用一下

https://huggingface.co/TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF/tree/main

5. 需求文档解析文件
创建 doc_parser.py:
from unstructured.partition.auto import partition
import spacydef parse_requirements(file_path):# 解析文档elements = partition(filename=file_path)text = "\n".join([str(e) for e in elements])# 提取关键需求nlp = spacy.load("en_core_web_sm")doc = nlp(text)requirements = []for sent in doc.sents:if "shall" in sent.text.lower() or "必须" in sent.text.lower():requirements.append(sent.text)return {"function": "用户登录", # 示例功能名称"inputs": ["用户名", "密码", "验证码"],"constraints": ["用户名长度6-20字符", "密码需包含字母和数字"],"expected_outputs": ["登录成功跳转主页", "显示错误原因"]}
6. 模型调用脚本
需要修改llama.cpp 的路径和模型的路径
创建 generate_cases.py:
import subprocess
import jsondef generate_with_llama(prompt):template = f"""以下是一份需求文档的摘要,请生成测试用例:
[需求]
{json.dumps(prompt, ensure_ascii=False)}[要求]
1. 输出JSON格式,包含用例编号、测试步骤、输入数据、预期结果
2. 覆盖正向、反向、边界值场景
3. 用中文编写"""cmd = ["./llama.ccp/build/bin/llama-cli", "-m", "/Users/fengruxue/Documents/AIWorkplace/autoGenCase/model/tinyllama-1.1b-chat-v1.0.Q2_K.gguf","-p", template,"-n", "512", # 生成长度"--temp", "0.3"]result = subprocess.run(cmd, capture_output=True, text=True)return parse_output(result.stdout)def parse_output(text):# 提取JSON部分try:start = text.index('{')end = text.rindex('}') + 1return json.loads(text[start:end])except:return {"error": "格式解析失败"}if __name__ == "__main__":from doc_parser import parse_requirementsreq = parse_requirements("spec.docx")cases = generate_with_llama(req)print(json.dumps(cases, indent=2, ensure_ascii=False))
7. 运行
整个运行过程中各种python 安装包依赖的问题,看来对phthon 各种安装包的下载依赖,调试还需要深入理解一下,好不容百度各种安装成功了,第一次还是执行报错了:
# 执行文件
python generate_cases.py > testcases.json
这个deepseek没有给出需求文档的格式,代码看不太懂? 让我看下代码先,今天先到这~
llama.ccp的一些命令解析:
https://blog.csdn.net/shebao3333/article/details/132895064
8. 报错排查
1、发现命令行执行会默认进入交互模式,python就不会有输出,然后加上了关闭对话模式的参数-no-cnv ,但是只是补全了问题,并没有给出提示。
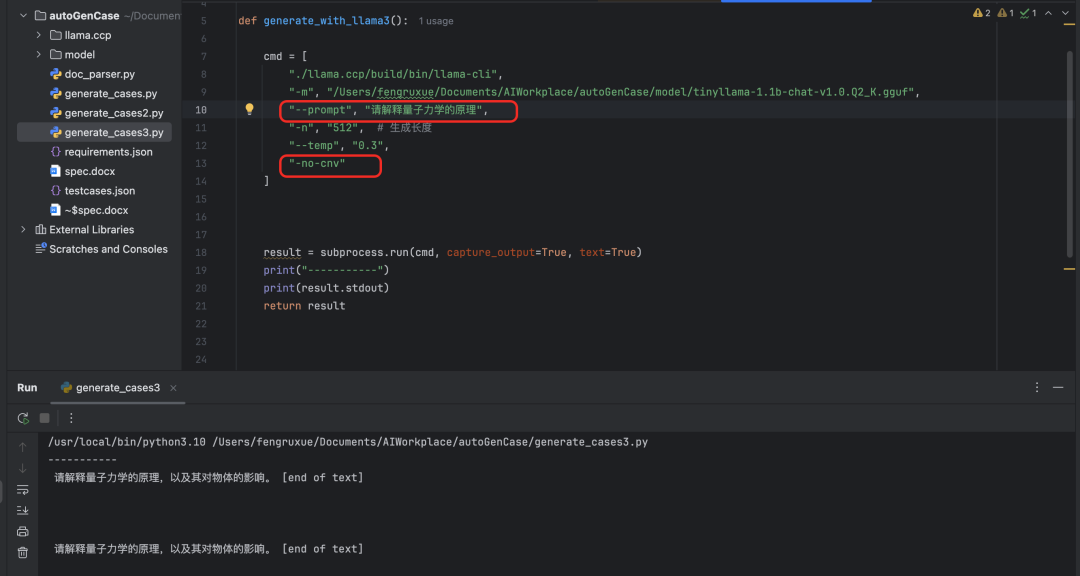
deepseek 在无数次超时后,终于解答了我的困惑:

可是我编译完后并没有main指令,看来得解决这个问题,初步感觉要不就是编译问题,要不就是环境变量设置有问题,好吧,这里面又涉及到了c++的编译问题了~

解决了git 项目的问题,还是没看到有生成main文件,编译看起来也没有报错,换了个公司的电脑重新执行了一遍,还是不行,搞了几天,我要放弃了,此时deepseek给的各种方案都没法解决我的问题,我要放弃了~~
9. 使用ollama 来部署
实在搞不定llama.cpp ,换个ollama来加载下deepseek模型。
本地安装后执行命令:ollama run deepseek-r1:1.5b

还是deepseek 的回答靠谱一下,还是ollama 比较好用,结合一下python 跑一下:
有两种方式,通过python 执行终端命令,或者通过调用ollama 的api 调用本地模型
# 通过 ollama 的 API 调用本地模型response = requests.post("http://localhost:11434/api/generate",json={"model": "deepseek-coder:33b-instruct-q4_K_M","prompt": prompt,"stream": False,"options": {"temperature": 0.3,"num_predict": 1000}})
输入指定的场景,就可以返回格式的测试用例,感觉还是挺方便的,至少1.5b 的模型推理效果不会超时了~
deepseek 的推理过程:

生成的用例重复了,看来需要调整下prompt:

调整prompt后的答案

终于把python 和deepseek 结合跑完一个小例子了,不容易,各种问题由于不懂走了好多弯路,还是因为不够熟悉导致,结合大模型生成测试用例的在实际项目中的应用应该就是输入详细的需求文档,然后解析成固定的格式作为prompt 给到大模型去回答,然后对输出结果进行处理,这里面还有python 各种方法的实现,因为不太懂,后面再详细做个例子深入学习一下,这篇初步熟悉先到这里。
从上面这个小例子的实践中还是能够认识到自己的对知识掌握的程度是在哪,感觉连初级入门都算不上,对python 的基本字符串处理,还有各种安装包的依赖,json的处理,还有更深一点像文档的解析,自然语言包的应用等都需要深入去学习,另外就是AI 大模型这块,不同公司不同类别不同参数的各种模型的了解,方法参数的设置及细节点区别,学不完,根本学不完~~