大模型与训练与微调
文章目录
- 大模型预训练
- 预训练的概念
- 预训练的目标
- 预训练的原理
- 预训练中参数
- 预训练的优势
- 预训练的后续
- 大模型微调
- 微调的概念
- 微调的概念
- 微调的原因
- 微调的类型
- 微调的步骤
- 微调的方法
大模型预训练
预训练的概念
-
预训练属于迁移学习。传统的神经网络在进行训练时,一般基于反向传播算法,先对网络中的参数进行随机初始化,再利用随机梯度下降等优化算法不断优化模型参数。而预训练的思想是模型参数不再是随机初始化,而是通过一些任务进行预先训练,得到一套模型参数,然后用这套参数对模型进行初始化,再进行训练。
-
预训练利用大量低成本数据学习共性知识,再通过少量领域标注数据微调,使模型快速适应特定任务。例如,不懂英文的人无法提取法律文书关键词,但英语母语者只需学习关键词提取方法即可完成任务。这里的英语能力是共性知识,可通过广泛阅读获得。传统训练相当于直接让不懂英文的人完成任务,而预训练+微调则类似先系统学习英语再处理任务。
-
大语言模型预训练通过构建大型神经网络,用海量数据训练模型,其核心特点是数据规模大、模型参数量多。
预训练的目标
预训练技术能有效解决机器学习中的关键问题:
- 数据稀缺:利用大量未标注数据训练模型,减少对昂贵标注数据的依赖。
- 先验知识:让模型从通用数据中学习基础规律(如语言结构),增强任务表现。
- 迁移学习:通过共享已学共性(如语义理解),快速适应新任务,提升泛化能力。
- 可解释性:学习抽象特征(如词向量),使模型决策更透明。
- 该技术显著提升模型性能、降低训练成本,适用于自然语言处理等广泛领域。
预训练的原理
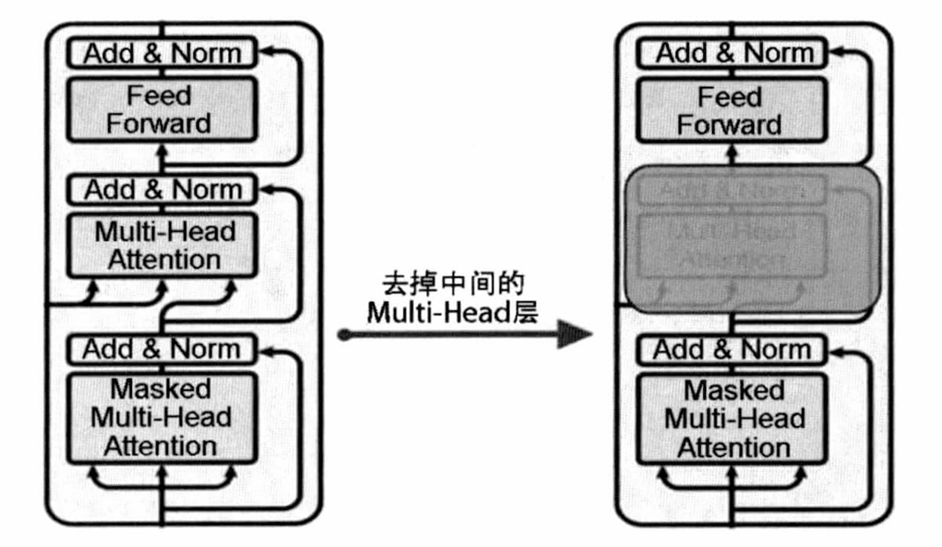
- 大语言模型预训练采用了Transformer模型的解码器部分,由于没有编码器部分,大语言模型去掉了中间的与编码器交互的多头注意力层。
- 左边是Transformer模型的解码器,右边是大语言模型的预训练架构。
预训练中参数
- 批量训练:通常将批量训练的大小(batch_size)设置为较大的数值来维持训练的稳定性。在最新的大语言模型训练中,采用了动态调整批量训练大小的方法,最终在训练期间批量训练大小达到百万规模。结果表明,动态调度批量训练的大小可以有效地稳定训练过程。
- 学习率:大语言模型训练的学习率通常采用预热和衰减的策略。学习率的预热是指模型在最初训练过程的0.1%~0.5%逐渐将学习率提高到最大值。学习率衰减策略在后续训练过程中逐步降低学习率使其达到最大值的10%左右或者模型收敛。
- 优化器:Adam优化器和AdamW优化器是常用的训练大语言模型的优化方法,它们都是基于低阶自适应估计矩的一阶梯度优化。优化器的超参数通常设置为β1=0.9、β2=0.95等。
- 训练稳定性问题:大语言模型预训练时,损失函数突变可能导致训练中断。常用解决方法包括梯度裁剪(阈值1.0)和正则化(系数0.1)。但随着模型规模增大,损失突变风险更高。解决方案:当损失突变时,回滚到上一个检查点(Checkpoint),跳过异常数据继续训练,以维持稳定性。
预训练的优势
- 大语言模型通过海量数据预训练并结合微调,显著提升机器学习的效果和效率,主要优势包括:
- 更强的泛化能力:从大规模数据中学习通用知识,提升对未知数据的适应能力。
- 节省训练成本:复用预训练权重,减少新任务的训练时间和数据需求。
- 提升计算效率:以预训练模型为起点,避免从头训练,降低资源消耗。
- 广泛的任务适配:支持文本分类、情感分析、机器翻译等多种NLP任务,增强技术通用性。
- 更高的模型精度:通过大规模预训练优化模型表现,提升各类任务的性能。
预训练的后续
-
大语言模型的预训练是指使用大量的数据来训练大规模的模型,以获得初始化的模型参数。预训练完成后,还会采用监督学习、奖励模型以及强化学习进行进一步的微调,这被称为RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)。
-
大语言模型预训练后的优化阶段(RLHF流程),该流程通过人类反馈不断精炼模型表现,使其输出更符合人类预期。
- 监督微调(SFT):人工标注数据指导模型调整,训练基础对话能力
- 奖励模型训练:人工标注偏好数据,建立回答质量评估体系
- 强化学习优化(PPO):结合奖励模型反馈,迭代优化模型输出质量,持续提升对话效果
大模型微调
-
随着大型语言模型(LLM)规模的不断扩大,微调这些模型以适应特定任务已成为自然语言处理领域的关键挑战。传统的全参数微调方法虽然效果显著,但面临着计算资源消耗巨大、存储需求高昂等问题,这使得在资源受限环境下难以实施 。
-
大模型微调的重要性体现在多个方面:首先,通过微调可以使通用预训练模型适应特定领域或任务,提升模型在目标场景的性能;其次,微调能够帮助模型学习新知识或更新已有知识,保持模型的时效性;此外,微调还能够解决预训练模型在某些任务上的偏见或不足,使模型输出更符合人类价值观和伦理标准。
微调的概念
- 大模型微调(Fine-Tuning)是指在已经预训练好的大型语言模型基础上,使用特定的数据集进行进一步的训练,以使模型适应特定任务或领域。
微调的概念
- 大模型微调(Fine-Tuning)是指在已经预训练好的大型语言模型基础上,使用特定的数据集进行进一步的训练,以使模型适应特定任务或领域。
- 微调的优势在于,它能够利用预训练模型中已学到的知识,从而在较小的数据集上也能实现较好的效果,节省了训练时间和计算资源。
- 微调的应用广泛,包括文本分类、情感分析、问答系统、机器翻译等多个领域。
- 在微调过程中,通常需要选择合适的超参数,如学习率、批次大小等,以避免过拟合,同时确保模型能够有效学习新任务。
- 常见的微调技术包括全模型微调和冻结某些层的微调。全模型微调对所有参数进行更新,而冻结某些层则只更新特定层的参数,适用于小数据集的情况。
- 微调的效果评估通常通过在特定任务上进行验证和测试,以确保模型能够在实际应用中表现良好。
微调的原因
- 预训练模型(Pre-Trained Model),或者说基础模型(Foundation Model),已经可以完成很多任务,比如回答问题、总结数据、编写代码等。但是,行业内的专业问答、关于某个组织自身的信息等,这是通用大模型无法触及的。在这种情况下,就需要使用特定的数据集对合适的基础模型进行微调,以完成特定的任务、回答特定的问题等。在这种情况下,就需要对模型进行微调。
微调的类型
-
根据微调使用的数据集的类型,大模型微调还可以分为监督微调(Supervised Fine-tuning)和无监督微调(Unsupervised Fine-tuning)两种。
-
监督微调:在进行微调时使用有标签的训练数据集。标签提供正确的目标输出。在监督微调中,通常使用带有标签的任务特定数据集,例如分类任务的数据集,其中每个样本都有一个与之关联的标签。通过使用这些标签来指导模型的微调,可以使模型更好地适应特定任务。
-
无监督微调:在进行微调时使用无标签的训练数据集。模型只能利用输入数据本身的信息,而没有明确的目标输出。这些方法通过学习数
据的内在结构或生成数据来进行微调,以提取有用的特征或改进模型的表示能力。
- 监督微调通常在含有标签的任务特定数据集上执行,使得可以直接针对特定任务优化模型的性能。无监督微调则更侧重于从无标签数据中进行特征学习和表示学习,目的是提取更有用的特征表示或增强模型的泛化能力。
- 这两种微调方法可以单独使用,也可以结合使用,取决于具体任务的需求和可用数据的类型和数量。
微调的步骤
- 准备数据集:收集和准备与目标任务相关的训练数据集,确保数据集质量和标注准确性,并进行必要的数据清洗和预处理。
- 选择预训练模型/基础模型:根据目标任务的性质和数据集的特点,选择适合的预训练模型。
- 设定微调策略:根据任务需求和可用资源,选择适当的微调策略。考虑是进行全微调还是部分微调,以及微调的层级和范围。
- 设置超参数:确定微调过程中的超参数,如学习率、批量大小、训练轮数等。这些超参数的选择对微调的性能和收敛速度有重要影响。
- 初始化模型参数:根据预训练模型的权重,初始化微调模型的参数。对于全微调,所有模型参数都会被随机初始化;对于部分微调,只有顶层或少数层的参数会被随机初始化。
- 进行微调训练:使用准备好的数据集和微调策略对模型进行训练。根据设定的超参数和优化算法逐渐调整模型参数以最小化损失函数。
- 模型评估和调优:训练过程中,使用验证集对模型进行定期评估,并根据评估结果调整超参数或微调策略。提高模型的性能和泛化能力。
- 测试模型性能:在微调完成后,使用测试集对最终的微调模型进行评估,以获得最终的性能指标。评估模型在实际应用中的表现。
- 模型部署和应用:将微调完成的模型部署到实际应用中,并进行进一步的优化和调整,以满足实际需求。
微调的方法
- 大模型微调方法对比研究