无anaconda搭建yolo11环境
1.下载python3.10
Python Releases for Windows | Python.org
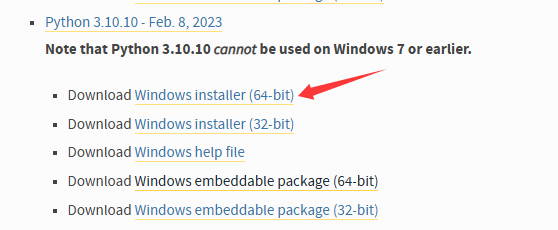

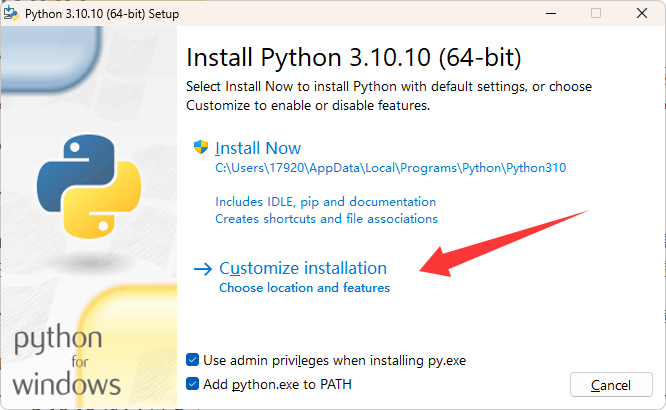
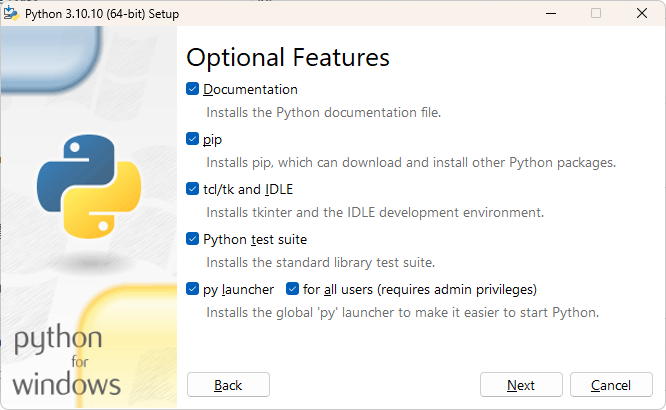
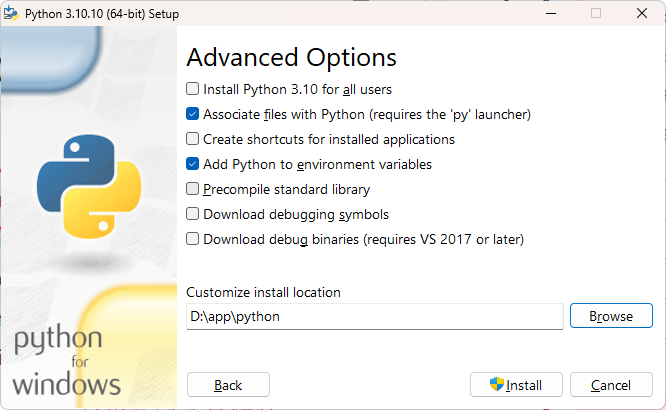
Ctrl+R cmd
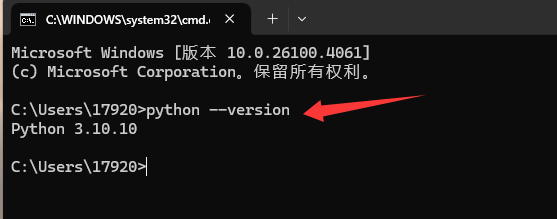
cd到python下载目录下
下载pytorch
D:\app\python>pip install torch==2.0.0+cu118 torchvision==0.15.1+cu118 --extra-index-url https://download.pytorch.org/whl/cu118
pip install numpy==1.26.3
![]()
data

JPEGImages
labels
classes.txt
![]()
VOCdevkit
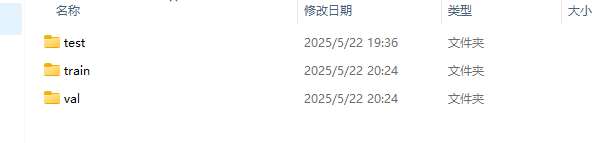
![]()
data.yaml
train: D:/app/yolo11/ultralytics-main/VOCdevkit/train/images # train images (relative to 'path') 128 images
val: D:/app/yolo11/ultralytics-main/VOCdevkit/val/images # val images (relative to 'path') 128 images
test: D:/app/yolo11/ultralytics-main/VOCdevkit/test/imagesnc: 2# Classes
names: ['hat','nohat']![]()
data_divide.py
# 作者:CSDN-笑脸惹桃花 https://blog.csdn.net/qq_67105081?type=blog
# github:peng-xiaobai https://github.com/peng-xiaobai/Dataset-Conversion
import os
import shutil
import random# random.seed(0) #随机种子,可自选开启
def split_data(file_path, label_path, new_file_path, train_rate, val_rate, test_rate):images = os.listdir(file_path)labels = os.listdir(label_path)images_no_ext = {os.path.splitext(image)[0]: image for image in images}labels_no_ext = {os.path.splitext(label)[0]: label for label in labels}matched_data = [(img, images_no_ext[img], labels_no_ext[img]) for img in images_no_ext if img in labels_no_ext]unmatched_images = [img for img in images_no_ext if img not in labels_no_ext]unmatched_labels = [label for label in labels_no_ext if label not in images_no_ext]if unmatched_images:print("未匹配的图片文件:")for img in unmatched_images:print(images_no_ext[img])if unmatched_labels:print("未匹配的标签文件:")for label in unmatched_labels:print(labels_no_ext[label])random.shuffle(matched_data)total = len(matched_data)train_data = matched_data[:int(train_rate * total)]val_data = matched_data[int(train_rate * total):int((train_rate + val_rate) * total)]test_data = matched_data[int((train_rate + val_rate) * total):]# 处理训练集for img_name, img_file, label_file in train_data:old_img_path = os.path.join(file_path, img_file)old_label_path = os.path.join(label_path, label_file)new_img_dir = os.path.join(new_file_path, 'train', 'images')new_label_dir = os.path.join(new_file_path, 'train', 'labels')os.makedirs(new_img_dir, exist_ok=True)os.makedirs(new_label_dir, exist_ok=True)shutil.copy(old_img_path, os.path.join(new_img_dir, img_file))shutil.copy(old_label_path, os.path.join(new_label_dir, label_file))# 处理验证集for img_name, img_file, label_file in val_data:old_img_path = os.path.join(file_path, img_file)old_label_path = os.path.join(label_path, label_file)new_img_dir = os.path.join(new_file_path, 'val', 'images')new_label_dir = os.path.join(new_file_path, 'val', 'labels')os.makedirs(new_img_dir, exist_ok=True)os.makedirs(new_label_dir, exist_ok=True)shutil.copy(old_img_path, os.path.join(new_img_dir, img_file))shutil.copy(old_label_path, os.path.join(new_label_dir, label_file))# 处理测试集for img_name, img_file, label_file in test_data:old_img_path = os.path.join(file_path, img_file)old_label_path = os.path.join(label_path, label_file)new_img_dir = os.path.join(new_file_path, 'test', 'images')new_label_dir = os.path.join(new_file_path, 'test', 'labels')os.makedirs(new_img_dir, exist_ok=True)os.makedirs(new_label_dir, exist_ok=True)shutil.copy(old_img_path, os.path.join(new_img_dir, img_file))shutil.copy(old_label_path, os.path.join(new_label_dir, label_file))print("数据集已划分完成")if __name__ == '__main__':file_path = r"D:\app\yolo11\ultralytics-main\data\JPEGImages" # 图片文件夹label_path = r'D:\app\yolo11\ultralytics-main\data\labels' # 标签文件夹new_file_path = r"D:\app\yolo11\ultralytics-main\VOCdevkit" # 新数据存放位置split_data(file_path, label_path, new_file_path, train_rate=0.7, val_rate=0.15, test_rate=0.15)

yolov11_predict.py
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':model = YOLO('D:/app/yolo11/ultralytics-main/ultralytics/cfg/models/11/yolo11n.yaml')model.load('D:/app/yolo11/ultralytics-main/yolo11n.pt') #注释则不加载results = model.train(data='D:/app/yolo11/ultralytics-main/data.yaml', #数据集配置文件的路径epochs=50, #训练轮次总数batch=16, #批量大小,即单次输入多少图片训练imgsz=640, #训练图像尺寸workers=8, #加载数据的工作线程数device= 0, #指定训练的计算设备,无nvidia显卡则改为 'cpu'optimizer='SGD', #训练使用优化器,可选 auto,SGD,Adam,AdamW 等amp= True, #True 或者 False, 解释为:自动混合精度(AMP) 训练cache=False # True 在内存中缓存数据集图像,服务器推荐开启
)yolov11_train.py
from ultralytics import YOLO
# 加载训练好的模型,改为自己的路径
model = YOLO('D:/app/yolo11/ultralytics-main/runs/detect/train2/weights/best.pt') #修改为训练好的路径
source = 'D:/app/yolo11/ultralytics-main/VOCdevkit/train/images/' #修改为自己的图片路径及文件名
# 运行推理,并附加参数
model.predict(source, save=True)