LLM大语言模型系列1-token
一,什么是token
1,什么是token:
参考:https://en.wikipedia.org/wiki/Token
https://en.wikipedia.org/wiki/Lexical_analysis#Token
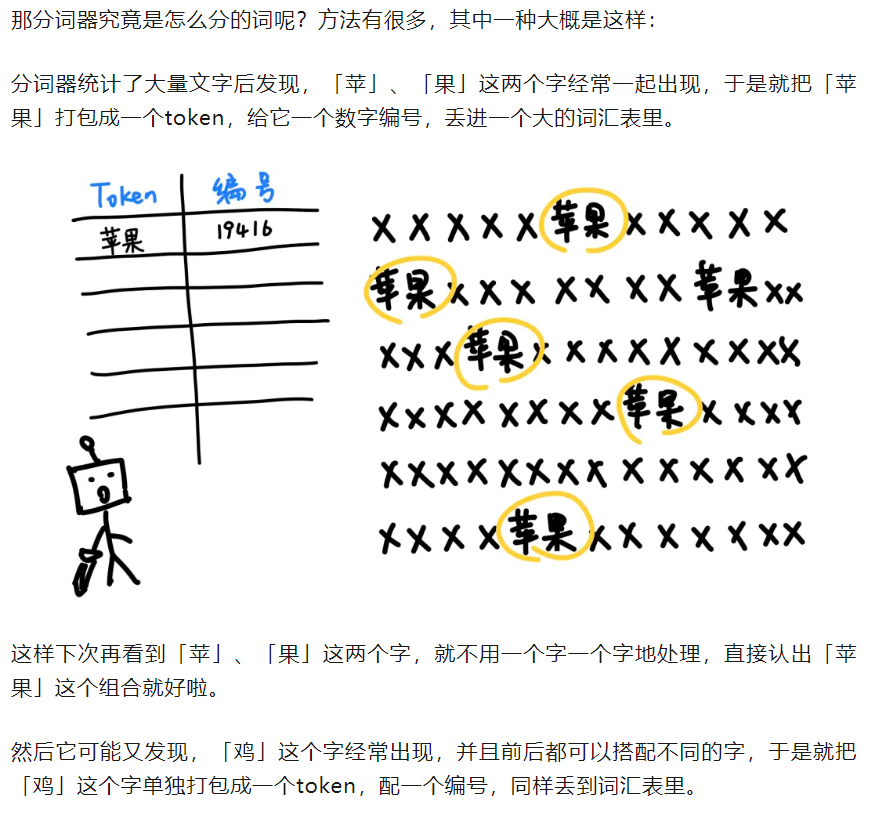
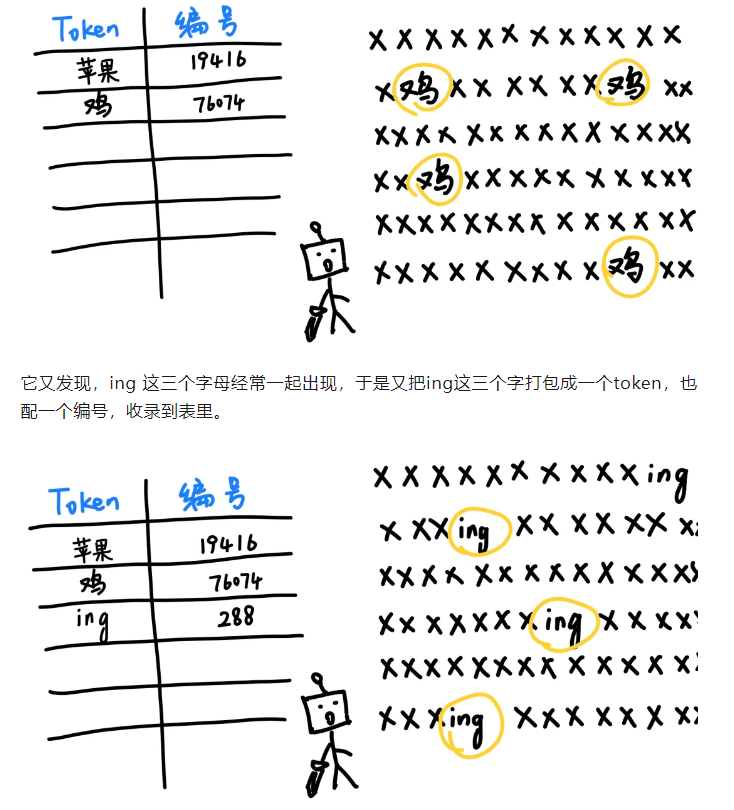
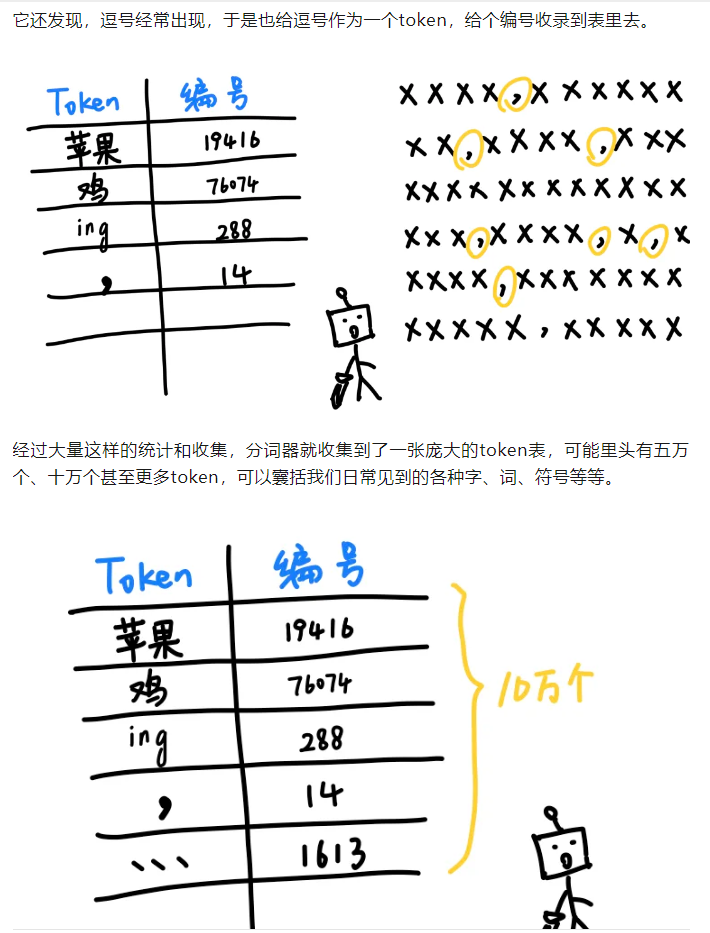
我们有很多描述token的解释,建议是汇总在一起进行综合理解:
1️⃣Token 是大语言模型(LLM, Large Language Model)中最基本的输入单元,它是语言被模型“理解”的方式;
2️⃣token:是一个原子解析级别(即不可再分,从语言内容角度上通俗来讲)的word,这个概念是联系英语语言学(一般是词法分析部分的),简单理解就是自然语言处理的词元(词的单元)

从语言的角度,我们可以找到很多和token有类似概念或者说是神韵的词,比如说词素、词的基本单元
参考:https://learn.microsoft.com/en-us/dotnet/ai/conceptual/understanding-tokens
3️⃣token是大型语言模型(LLMs)在分解文本时生成的单词、字符集或单词和标点符号的组合。
(words, character sets, or combinations of words and punctuation that are generated by large language models (LLMs) )
Tokenization分词化是训练的第一步。
LLM 分析token之间的语义关系,例如它们一起使用的频率或是否在相似的场景中使用。
训练后,LLM 利用这些模式和关系,根据输入序列生成输出标记序列。

LLM 在训练中使用的唯一token集称为其词汇表(vocabulary)。
The set of unique tokens that an LLM is trained on is known as its vocabulary.

2,Tokenization
参考:https://en.wikipedia.org/wiki/Lexical_analysis#Tokenization
从词法分析(也就是语言学的角度)来讲所谓的tokenization,其实就是一种转换,即分词(化)、(到/去)分词、(转换为)分词、,本意是指将文本text转换为(语义或句法)上有意义的词汇标记的过程;
什么是有意义的词汇标记,对于纯语言学来讲,我们有名词、动词、形容词等概念;
对于计算机来讲,我们有标识符、运算符、数据类型、关键字等概念(不同的编程语言中共同的概念)。
语言学中的分词化与LLM即大语言模型中的分词化的区别在于:
语言学中的词汇分词化通常基于词汇语法,而 LLM 中的分词化通常基于概率。
其次,LLM 分词化执行第二步,将这些分词,也就是token转换为数值。


https://platform.openai.com/tokenizer

3,tokenizer
tokenization是一个过程,那么执行这个过程需要相应的tokenizer(分词器);
简单举例来说,加法是一个运算过程,我们需要执行这个过程的一个函数、一个抽象的映射,也就是1个操作符,即加法的运算操作符。
再用语言举一个例子,比如说"hello world",我怎么将这个输入的文本text,进行分词化,
我可以认为这个文本中最基本的2个词元是hello、world,
我也可以认为是he、llo、world这3个,以及等等,有各种不同的划分/映射规则/操作逻辑,就表明有不同的分词器。


可以参考:https://en.wikipedia.org/wiki/Word_(computer_architecture)看看,但不是相同的概念
我们区分的话,可以从语言学角度的lexical token和大语言模型角度的probabilistic token去区分,但是理解的化,可以类比在一起进行理解:



我们随便举一个编程语言的例子来看看:

我们再回到自然语言处理(也就是大语言模型背景下)的token中:
这里有一篇非常有趣的科普文章:
参考https://mp.weixin.qq.com/s/NiQXAdr6EzAHCLelAWWZGQ

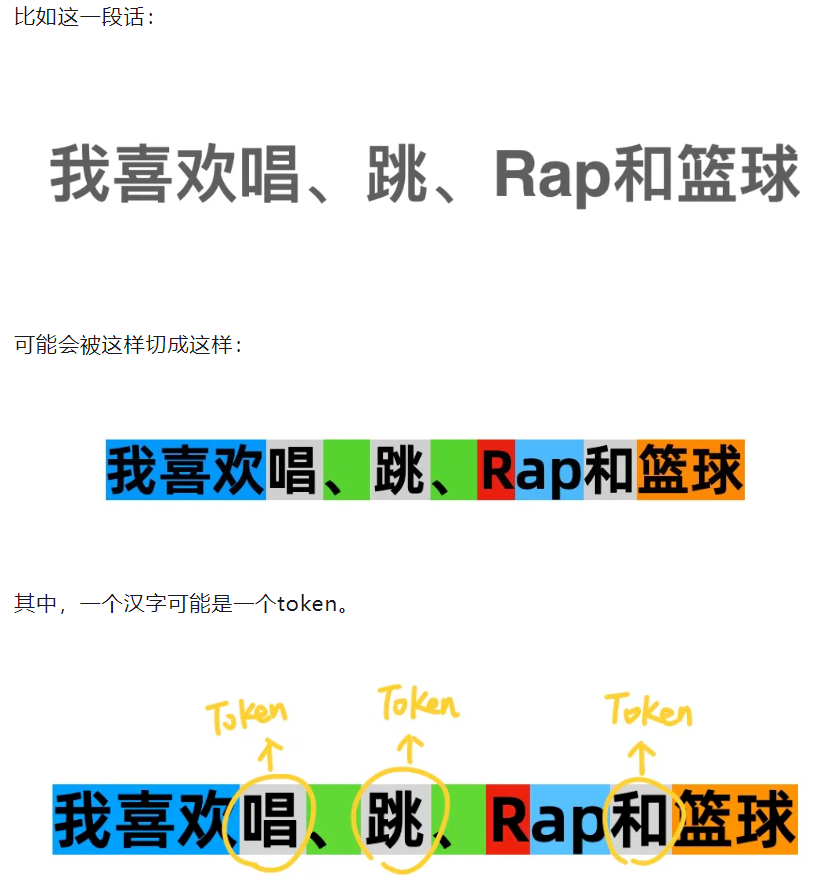
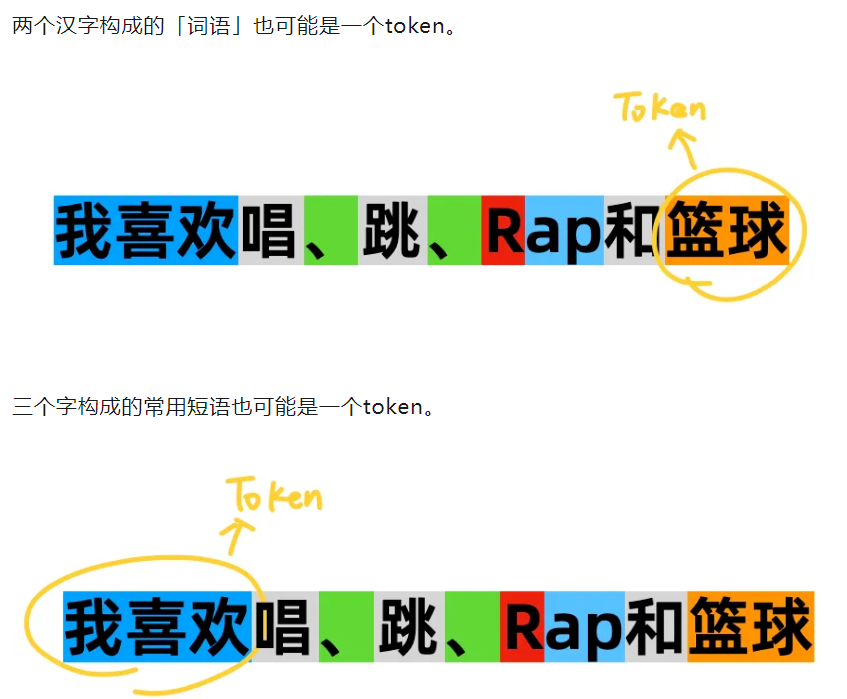
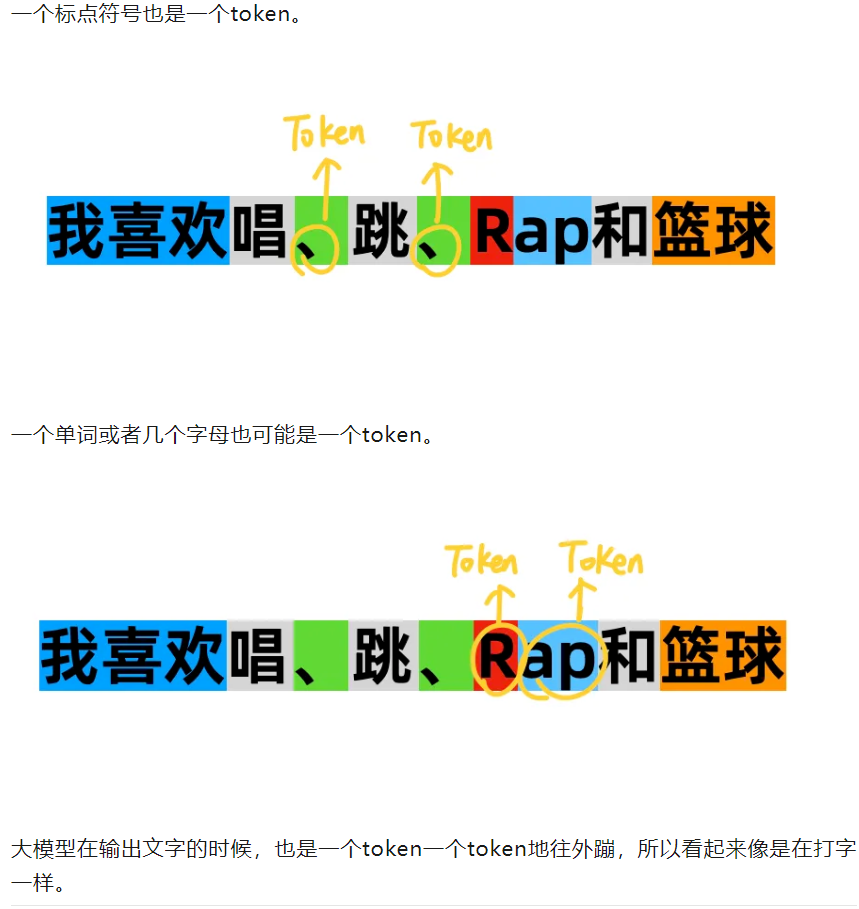
有一个网站,可以用来演示分词器的作用:
https://tiktokenizer.vercel.app/?model=deepseek-ai%2FDeepSeek-R1
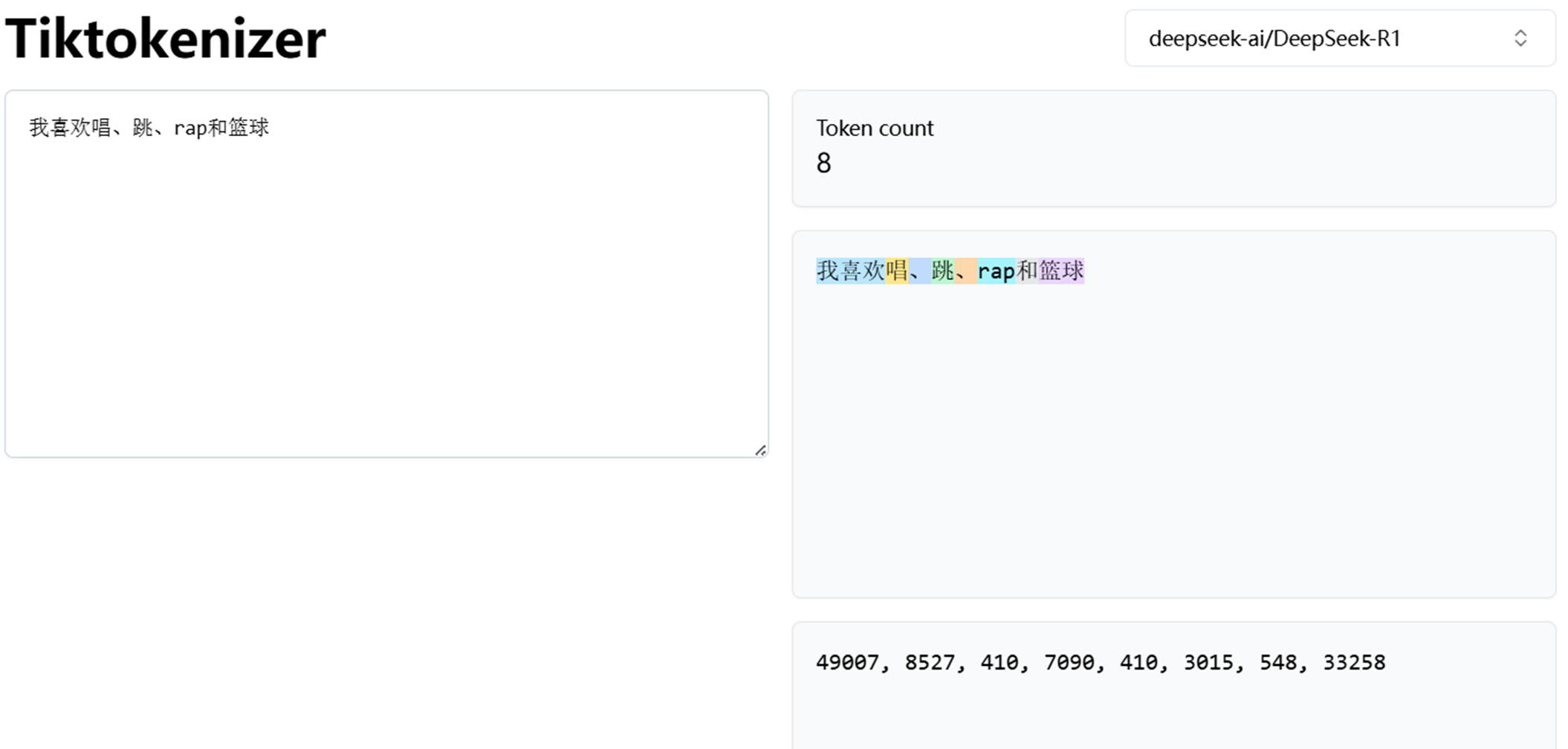
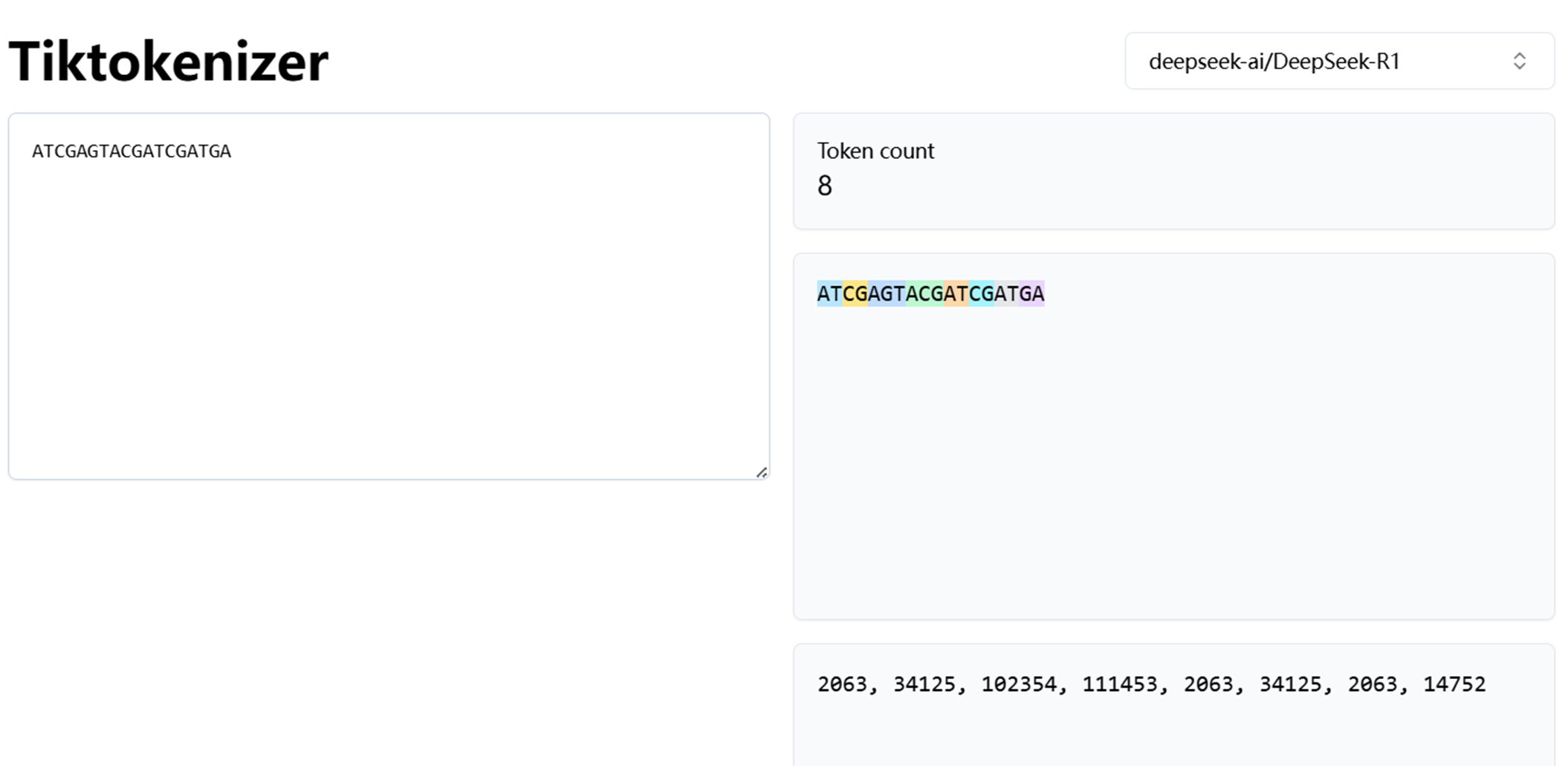
就比如说有一个问题,我们的输入是"what do i like eating?",假设说这里按照概率拆分成了5个token,
即what、do、i、like、eating,然后对于这5个token,分词器建立了1个hash表的索引分别为10、15、20、25、30,
相当于你给大模型输入了这么一串数字,也就是1个向量,[10,15,20,25,30],
然后如果这个大模型学到的另外一个单词,比如说KFC也是1个token,假设是666,
那么对于大模型而言,这个回答,或者说这整个的操作过程,其实就是输入[10,15,20,25,30],输出666的过程;
相当于我们实际理解中的"what do i like eating?—— KFC"。
这么一个数值向量的映射过程,我们可以简单理解为大模型学会了饮食知识,成功地依据饮食知识解答了这个问题。
参考:https://learn.microsoft.com/en-us/dotnet/ai/conceptual/understanding-tokens




在模型的最大上下文窗口限制下,输入和输出的总token数量不能超过模型的最大上下文窗口大小。换句话说,模型在一次处理过程中,输入和输出的token数量加起来不能超过其最大上下文窗口的限制。
核心概念
- 最大上下文窗口(Context Window):模型在一次处理过程中能够处理的最大token数量,包括输入和输出。
- 输入token:模型接收的文本被分词后得到的token数量。
- 输出token:模型生成的文本被分词后得到的token数量。
关键点
- 输入和输出的总token数量不能超过最大上下文窗口。例如,如果模型的最大上下文窗口是100个token,那么输入和输出的token数量加起来不能超过100个。
- 分词方法会影响输入和输出的token数量。不同的分词方法会将相同的文本分割成不同数量的token,从而影响输入和输出的可用token数量。
举例说明
假设模型的最大上下文窗口是100个token:
使用基于词的分词方法
- 输入文本:“I heard a dog bark loudly at a cat”。
- 通过基于词的分词方法,这句话被分成9个token。
- 剩下的91个token可以用于输入和输出的总和,而不是单独用于输出。
如果模型需要生成一个完整的句子作为输出,假设输出句子是“ The cat ran away quickly”,通过基于词的分词方法,这句话可能被分成6个token。那么,输入和输出的总token数量为:
- 输入:9个token
- 输出:6个token
- 总计:9 + 6 = 15个token,这在100个token的限制范围内。
使用基于字符的分词方法
- 输入文本:“I heard a dog bark loudly at a cat”。
- 通过基于字符的分词方法,这句话被分成34个token(包括空格)。
- 剩下的66个token可以用于输入和输出的总和,而不是单独用于输出。
如果模型需要生成一个完整的句子作为输出,假设输出句子是“ The cat ran away quickly”,通过基于字符的分词方法,这句话可能被分成22个token(包括空格)。那么,输入和输出的总token数量为:
- 输入:34个token
- 输出:22个token
- 总计:34 + 22 = 56个token,这也符合100个token的限制。
1. token限制的本质
token限制是指模型在一次处理过程中能够处理的最大token数量,包括输入和输出的总和。这个限制是模型架构和计算资源的约束,而不是对输出内容的具体词汇的限制。
2. 输出内容的多样性
- token限制只限制数量,不限制内容:模型的输出内容可以是任何符合上下文逻辑和语法的文本,只要这些文本的总token数不超过限制。
- 输出内容的多样性取决于模型的训练和上下文:即使token数量有限,模型仍然可以生成多种不同的内容。例如,模型可以用有限的token生成一个长句子、多个短句子,或者一个详细的描述,只要这些内容的总token数不超过限制。
3. 举例说明
假设一个模型的最大上下文窗口为100个token,输入占用了30个token,那么输出最多可以有70个token。这70个token可以是以下任何一种情况:
- 一个长句子:由70个单词组成的长句子。
- 多个短句子:例如3个句子,每个句子约20-30个单词。
- 详细描述:用70个单词详细描述一个场景或概念。
4. 分词方法的影响
不同的分词方法会导致不同的token数量:
- 基于单词的分词:每个单词是一个token。例如,“I love AI”会被分成3个token。
- 基于字符的分词:每个字符是一个token。例如,“I love AI”会被分成9个token。
- 基于子词的分词(如 BERT 的 WordPiece 或 GPT 的 Byte Pair Encoding):单词会被拆分成更小的子词单元。例如,“loving”可能会被拆分成“lov”和“ing”两个子词。

参考:https://en.wikipedia.org/wiki/Large_language_model#Tokenization

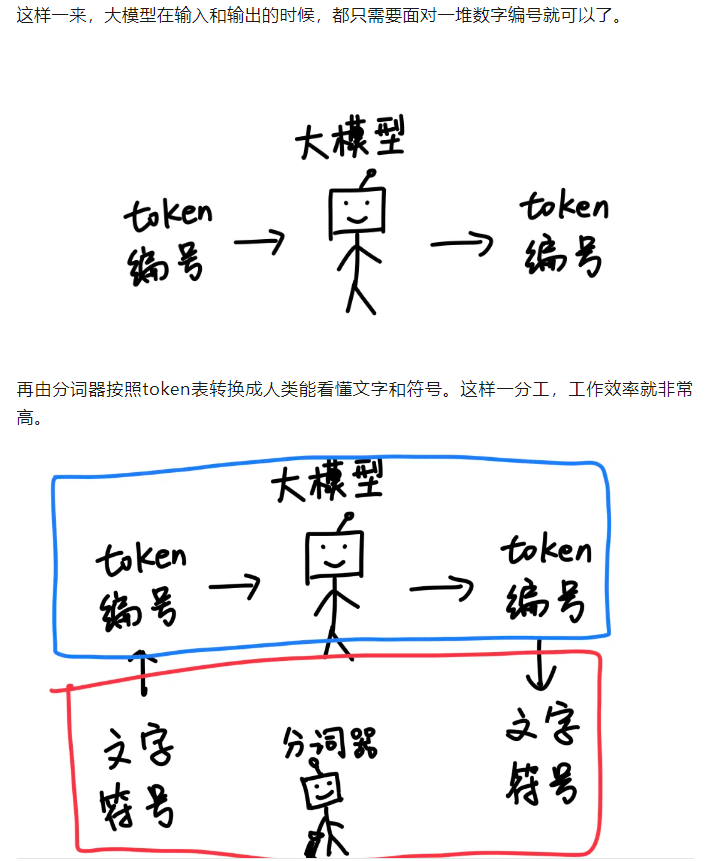
我想说的是:计算机/大模型能够理解的是数字,一切都得以数值形式的内容去呈现,分词器干的就是给大模型建立1张token(词元)到数值索引(数字)的一张hash表(可以这么理解),
然后大模型要做的就是从一堆输入的数字中,输出一堆数字;
分词器要做的就是输入端以及输出端的解码,首先输入端是给机器也就是大模型做翻译,也就是给机器解码,把我们的sequence序列数据(比如说text文本)解码为token——》数字;
在输出端的话相当于是给我们做翻译,也就是给我们解码,把机器输出的数字再转换为我们输入时候的sequence一样的语言(一样的text文本语言形式)。
本质就是模型能够理解的是数字,我们人类大脑能够理解的是自然语言,都可以看作是不同的语言,都有各自的语言基本单位,核心是不同语言基本单位之间的映射(hash)罢了。
(1)以字节对编码为基础的分词器:


参考:https://en.wikipedia.org/wiki/Byte_pair_encoding


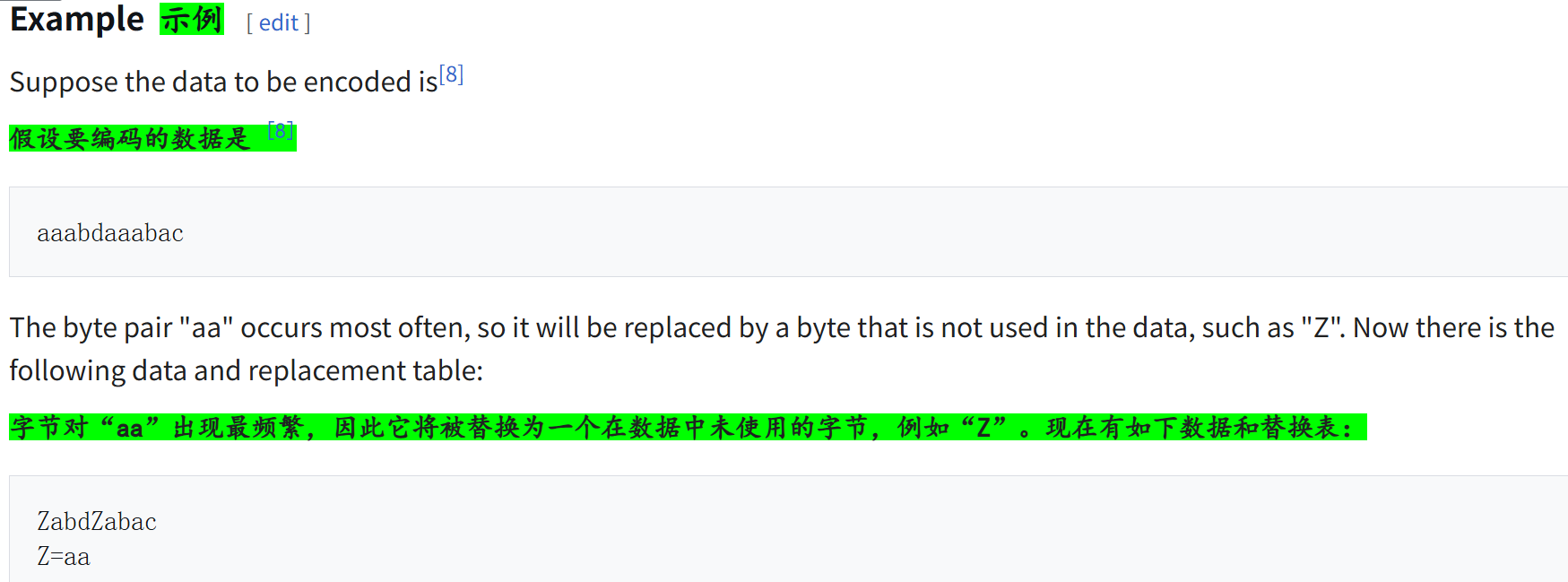
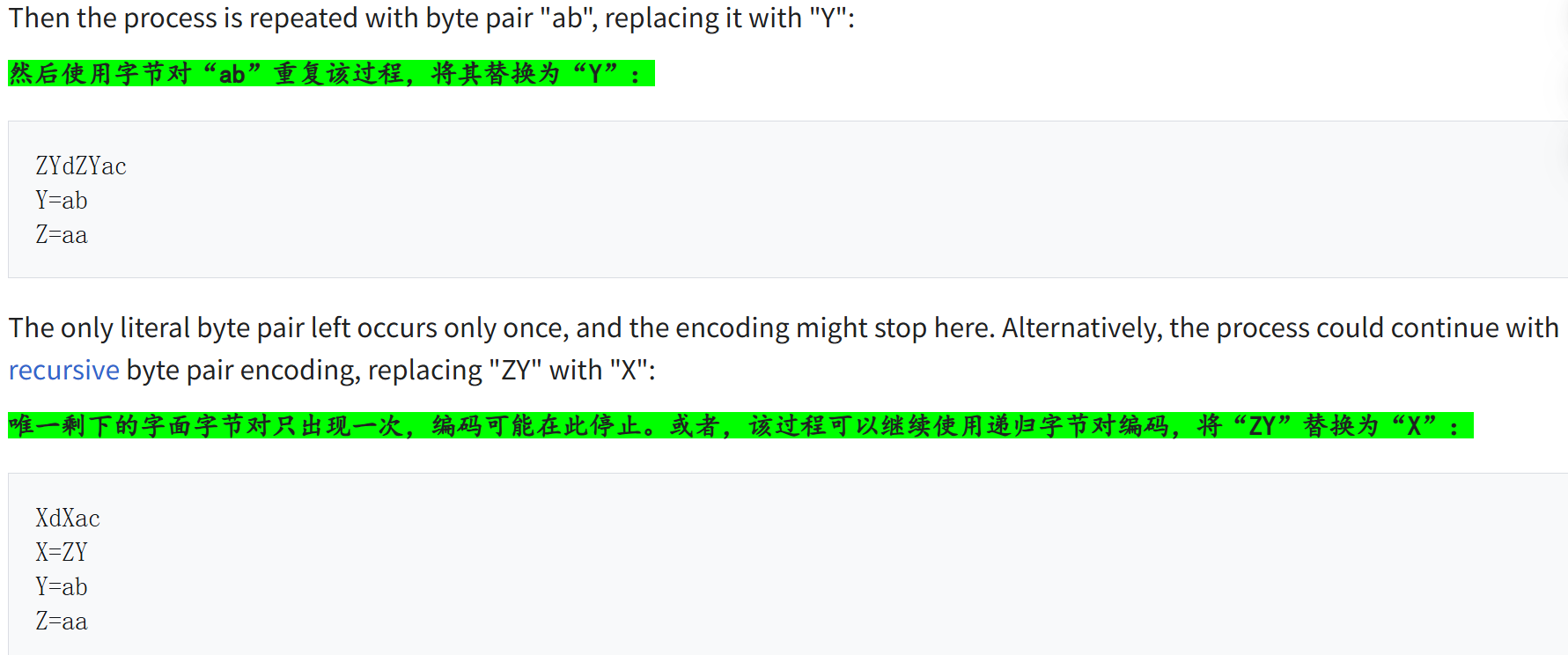


其实算法的核心就在:
将唯一字符集视为 1 个字符长的 n-gram(初始标记)。然后,逐步地将最频繁的相邻标记对合并成一个新的、更长的 n-gram,并将该对的所有实例替换为这个新标记。重复此过程,直到获得规定大小的词汇表。
我们可以以1个DNA序列为例进行说明(下面例子中部分token的统计频率仅作为演示参考,纯粹数字,重点在于理解这个操作的原理以及流程,数据例子不是重点)
假设我们有一个DNA序列:
ATGCGTACGTTAGC
1. 初始阶段:将唯一字符集视为1个字符长的n-gram
- DNA序列中只有四种字符:A、T、C、G。
- 初始的token词汇表可以定义为:
A = 0
T = 1
C = 2
G = 3
- 将DNA序列编码为token序列:
ATGCGTACGTTAGC
↓
0 1 3 2 3 1 0 3 1 1 0 2
2. 合并最频繁的相邻token对
- 第一次合并:统计相邻token对的频率:
(0, 1): 2次 # 仅作参考,假设序列中出现过2次
(1, 3): 2次 # 同上
(3, 2): 2次 # 同上
(2, 3): 1次
(3, 1): 1次
(1, 1): 1次
(0, 2): 1次
- 最频繁的相邻token对是
(0, 1)和(1, 3)和(3, 2),都出现了2次。假设我们选择(0, 1)进行合并。 - 创建一个新的token:
(0, 1) = 4
- 更新token词汇表:
A = 0
T = 1
C = 2
G = 3
AT = 4
- 替换序列中的
(0, 1):
0 1 3 2 3 1 0 3 1 1 0 2
↓
4 3 2 3 1 4 3 1 1 2
- 第二次合并:统计新的相邻token对的频率:
(4, 3): 2次
(3, 2): 2次
(2, 3): 1次
(1, 4): 1次
(3, 1): 1次
(1, 1): 1次
- 最频繁的相邻token对是
(4, 3)和(3, 2),都出现了2次。假设我们选择(4, 3)进行合并。 - 创建一个新的token:
(4, 3) = 5
- 更新token词汇表:
A = 0
T = 1
C = 2
G = 3
AT = 4
ATG = 5
- 替换序列中的
(4, 3):
4 3 2 3 1 4 3 1 1 2
↓
5 2 3 1 5 1 1 2
3. 重复合并过程,直到达到预设的词汇表大小
假设我们希望词汇表大小为10,继续合并:
- 第三次合并:统计新的相邻token对的频率:
(5, 2): 2次
(2, 3): 1次
(3, 1): 1次
(1, 5): 1次
(1, 1): 1次
- 最频繁的相邻token对是
(5, 2),出现了2次。 - 创建一个新的token:
(5, 2) = 6
- 更新token词汇表:
A = 0
T = 1
C = 2
G = 3
AT = 4
ATG = 5
ATGC = 6
- 替换序列中的
(5, 2):
5 2 3 1 5 1 1 2
↓
6 3 1 6 1 1
- 假设继续合并,直到词汇表达到预设的大小(这里简化为10)。
最终结果
假设经过多次合并后,词汇表大小达到10,最终的token词汇表可能如下:
A = 0
T = 1
C = 2
G = 3
AT = 4
ATG = 5
ATGC = 6
...
原始DNA序列 ATGCGTACGTTAGC 被编码为:
6 3 1 6 1 1
BPE的token编码方式原理
- 从最简单的单位(单字符)开始:将每个字符视为一个独立的token。
- 逐步合并:通过统计相邻token对的频率,将最频繁的相邻token对合并成一个新的token。
- 动态更新词汇表:每次合并后,更新token词汇表,并用新的token替换序列中的相应部分。
- 重复过程:直到达到预设的词汇表大小。
- 高效表示:最终的token序列比原始字符序列更短,同时保留了原始序列的信息。
以上仅作为示例展示,总得来说,n-gram合并的时候,我们可以合并相邻的2个:
每次合并两个符号,可以逐步构建出更复杂的token,同时保持token的粒度适中,便于模型学习;
另外一方面,语言的结构通常是层次化的,从字符到单词,再到句子,逐步合并两个符号可以更好地捕捉这种层次结构。如果一次性合并三个或更多符号,可能会错过一些重要的中间层次信息。
而且从实操上讲,这种逐步的合并方式可以很容易地通过迭代实现,而不需要复杂的多符号组合逻辑


其实生物大分子序列进行token化,最常用的是BPE,也就是上面的字节对编码方式(通过统计频繁出现的字节对,逐步替换,并合并成较大的单元),以及k-mer k串方式。
对tokenizerg感兴趣的,可以huggingface上试一下,https://github.com/huggingface/tokenizers
二,为什么是token?
正如前面所述:Token 是大语言模型(LLM, Large Language Model)中最基本的输入单元,它是语言被模型“理解”的方式。
不同于人类可以直接看懂一段自然语言文本,LLM 只能处理数字,而这些数字就是由 token 转换而来的。
我们在一中已经简单讨论过了以下问题:
- 什么是 token,它和文字的关系是什么?
- 为什么 LLM 不直接处理文字,而是需要 token?
- tokenizer 是做什么的,它的原理是什么?
- 常见的 tokenizer 类型和编码方式有哪些?
大模型如何接收输入
我们平常使用大模型,比如 ChatGPT、Deepseek等,都是通过输入一段文字(也就是“提示词”,Prompt)与模型进行交互,看似模型直接把这段文字作为输入,并处理了这段文本。但真实的处理流程情况并非如此。
模型内部并不会直接接收自然语言文本,而是接收经过token转换器编码后的 token 序列。
为什么需要这个转换过程?
- 神经网络只能处理数字。
- 文本需要映射成固定的向量才能进入模型计算。
- 使用 token 可以让模型更好地压缩、理解和预测语言结构。
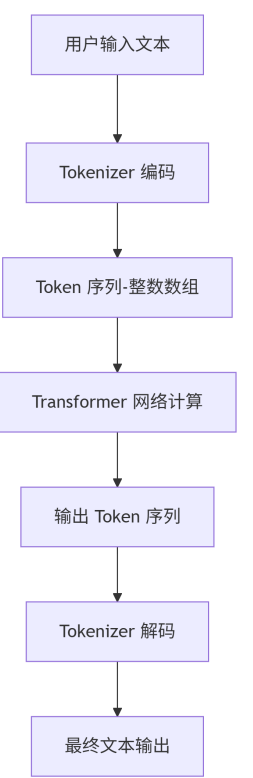
这个过程不仅用于模型输入,也用于模型输出。Transformer生成的是一个个 token,它们最终会通过一个Tokenizer解码器再被转换回自然语言。
Token 是整数序列
神经网络不理解文本,只能处理数字。因此,token 需要被编码为整数,再被嵌入成向量,供模型处理。
示例流程:
文本输入:
“你好,世界”
Tokenizer 切分:
[“你”, “好”, “,”, “世界”]
编码为整数 ID:
[9234, 8721, 13, 45012]
这些整数再被转换成向量(通过嵌入层),输入给 Transformer 模型进行计算。
为什么是整数?
因为神经网络的嵌入层(Embedding Layer)就是通过“整数索引”去查一个巨大的向量表:
embedding[token_id] → 向量
所以 token 最终表现为一串整数 ID,是大模型能够理解语言的桥梁。
Tokenizer(Token 转换器)
Tokenizer 是完成文本和 token 之间转换的关键工具。
它的作用分为两部分:
- 编码(Encode):将原始自然语言转为 token 数组。
- 解码(Decode):将 token 数组转换回文本。
一个优秀的 tokenizer 应该具备以下特点:
- 高效:转换速度快,节省内存
- 可压缩:长文本能切分成较少 token
- 泛化性强:对未知单词也能合理切分
常见的 Token 编码算法
不同的模型和任务,会使用不同的 tokenizer 和编码方式,主要包括以下几种:
1. BPE****(Byte Pair Encoding)
- 原理:通过统计频繁出现的字节对,逐步合并成较大的单元。
- 应用:GPT 系列(如 GPT-2/3/4)。
- 特点:压缩效率高,适合多语言场景。
2. WordPiece
- 原理:将词拆解成词根 + 后缀,用于解决罕见词问题。
- 应用:BERT、RoBERTa。
- 特点:词表更小,训练更稳定。
3. SentencePiece
- 原理:不依赖空格分词,基于字符级建模。
- 应用:T5、XLNet、ALBERT。
- 特点:适用于无空格语言,如中文、日文。
4. Tiktoken(OpenAI 专用)
- 特点:优化 GPT 使用场景,速度极快,token 估算准确。
- 提供工具支持编码、解码和 token 计数。
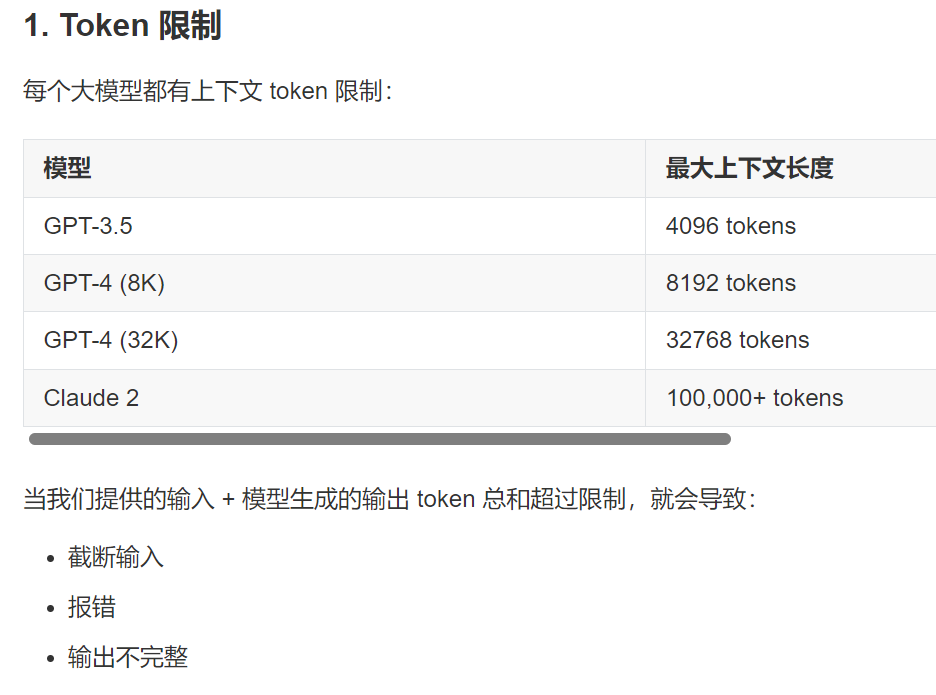
至于token限制问题,我们在熟悉理论之前,想必在使用chatbot过程中已经非常熟悉了,前面一中也有简略的讨论:
参考:https://mp.weixin.qq.com/s/8MAlBNJnRW6uBGwd9eNOAg
三,生物序列的Tokenization
此处我仅举几个例子,详细的细节可以查看原始文献:
参考:https://rpubs.com/yuchenz585/1161578
1,DNABERT: pre-trained Bidirectional Encoder Representations from Transformers model for DNA-language in genome (2021)
DNABERT,以基于上游和下游核苷酸上下文捕获基因组 DNA 序列的全局和可转移理解
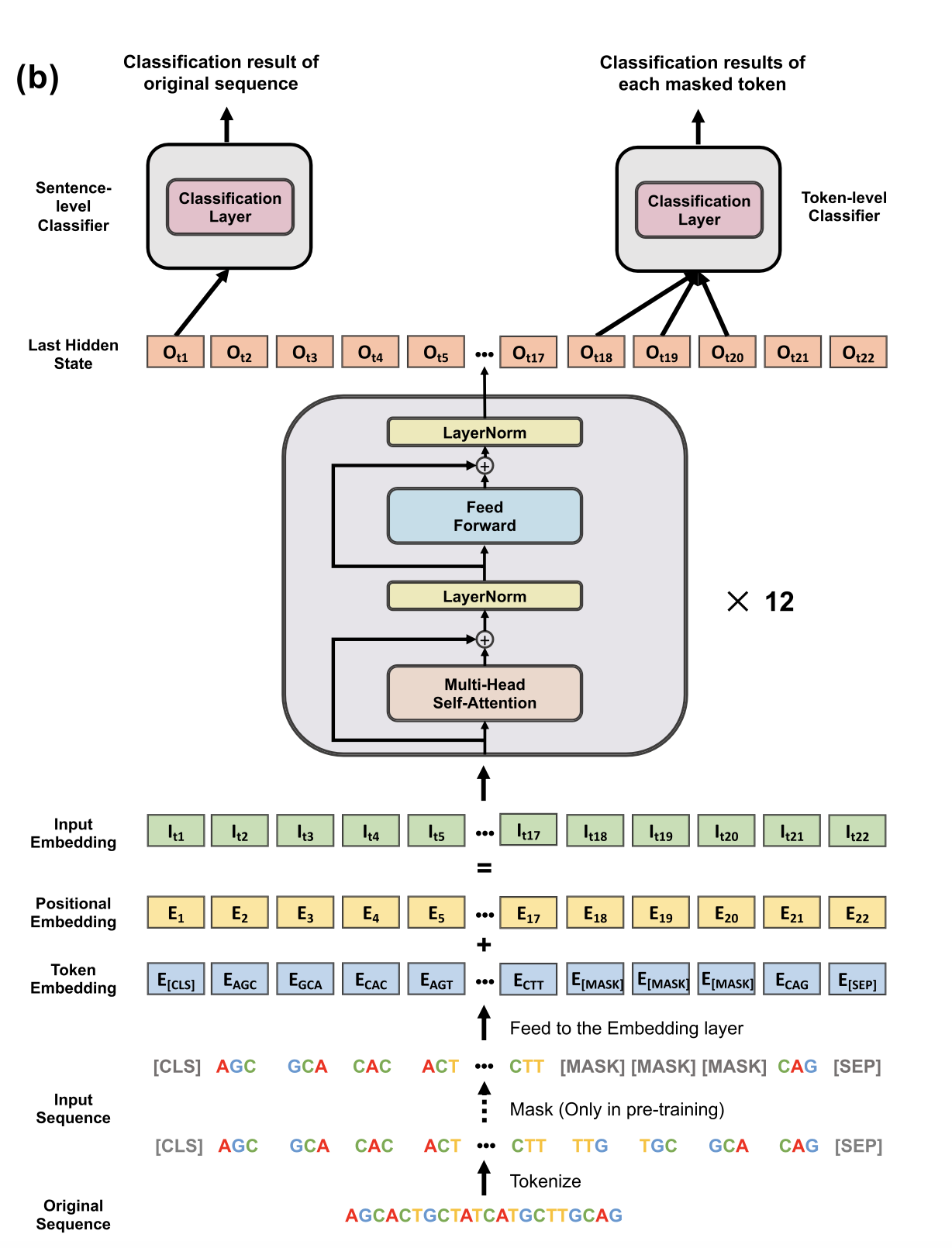
可以看到这里的tokenization就是k-mer 表示(广泛应用于分析 DNA 序列),
例如,DNA 序列“ATGGCT”可以被分词:
4个 3-mer:{ATG, TGG, GGC, GCT}
2个 5-mer:{ATGGC, TGGCT}
不同的 k 会导致 DNA 序列的不同分词,比如说DNABERT-3, DNABERT-4, DNABERT-5, DNABERT-6等等。
对于 DNABERT-k,它的词汇表由所有 k-mer 的排列以及 5 个特殊标记组成:
[CLS]代表分类标记
[PAD]代表填充标记
[UNK]代表未知标记
[Mask]表示被掩盖的 token
因此,DNABERT-k 的词汇中有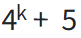 个 token。
个 token。
2,DNABERT-2: Efficient Foundation Model and Benchmark For Multi-Species Genome (2023)
DNABERT 的一项局限性:k-mer 分词导致预训练期间信息泄露和整体计算效率低下。
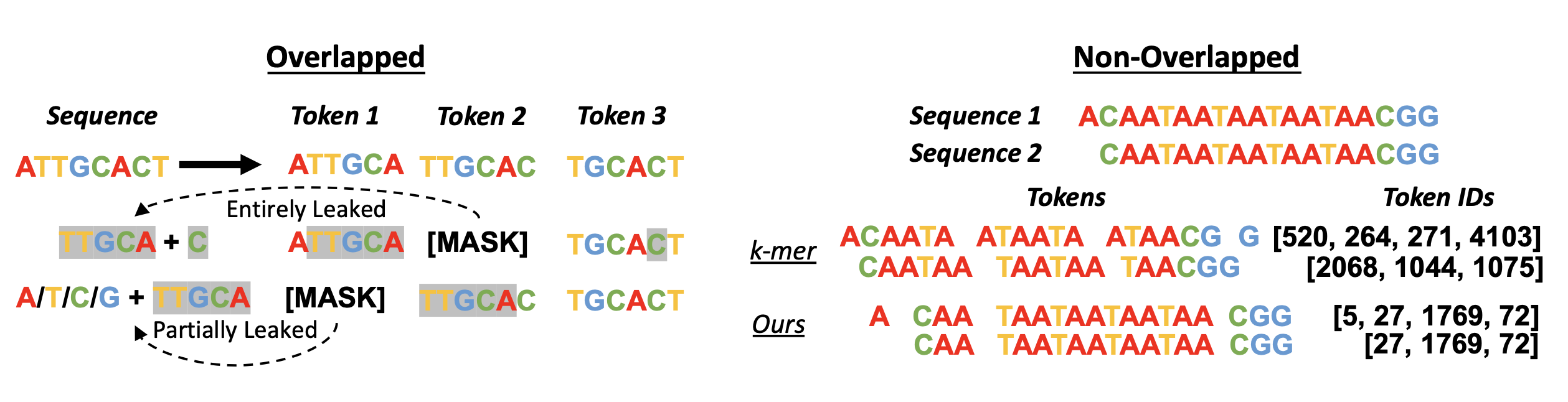
所以改进的地方在于:
用字节对编码(BPE)替换 k-mer 分词;
DNABERT-2 通过用带有线性偏差的注意力机制(ALiBi)替换学习位置嵌入,克服了 DNABERT 的限制,从而消除了输入长度的限制。
在分词过程中,采用窗口大小为 k、步长为 t 的滑动窗口将原始基因组序列转换为一系列 k-mer。
这里,步长 t 设置为 1 或 k,其中 1 代表 k-mer 分词的重叠版本,另一个代表非重叠版本。
但事实上,两个版本都不够理想。
(1)Overlapping:
对于长度为 L 的输入,其分词序列由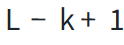 个长度为 k 的标记组成。这导致分词序列具有相当大的冗余,长度几乎等同于原始序列,从而降低了计算效率。
个长度为 k 的标记组成。这导致分词序列具有相当大的冗余,长度几乎等同于原始序列,从而降低了计算效率。
(2)Non-overlapping:
尽管其通过将序列长度减少 k 倍的优势,但存在一个显著的样本效率问题。
这种轻微的偏移导致标记化输出发生剧烈变化,这使得难以将相同或近乎相同的输入的独特表示进行对齐。
(3)Subword tokenization 框架
所以,DNABERT-2 采用了 SentencePiece [Kudo 和 Richardson, 2018] 与字节对编码(BPE)[Sennrich 等,2016] 来对 DNA 序列进行分词。
它基于字符的共现频率学习一个固定大小的、可变长度的词汇表。

3,Nucleotide Transformer(Dalla-Torre et al. 2023)
使用 6-mer 标记作为序列长度(最长 6kb)和嵌入大小之间的权衡,并且与其他标记长度相比,它实现了最高的性能。