主成分分析的应用之sklearn.decomposition模块的PCA函数
主成分分析的应用之sklearn.decomposition模块的PCA函数
一、模型建立整体步骤
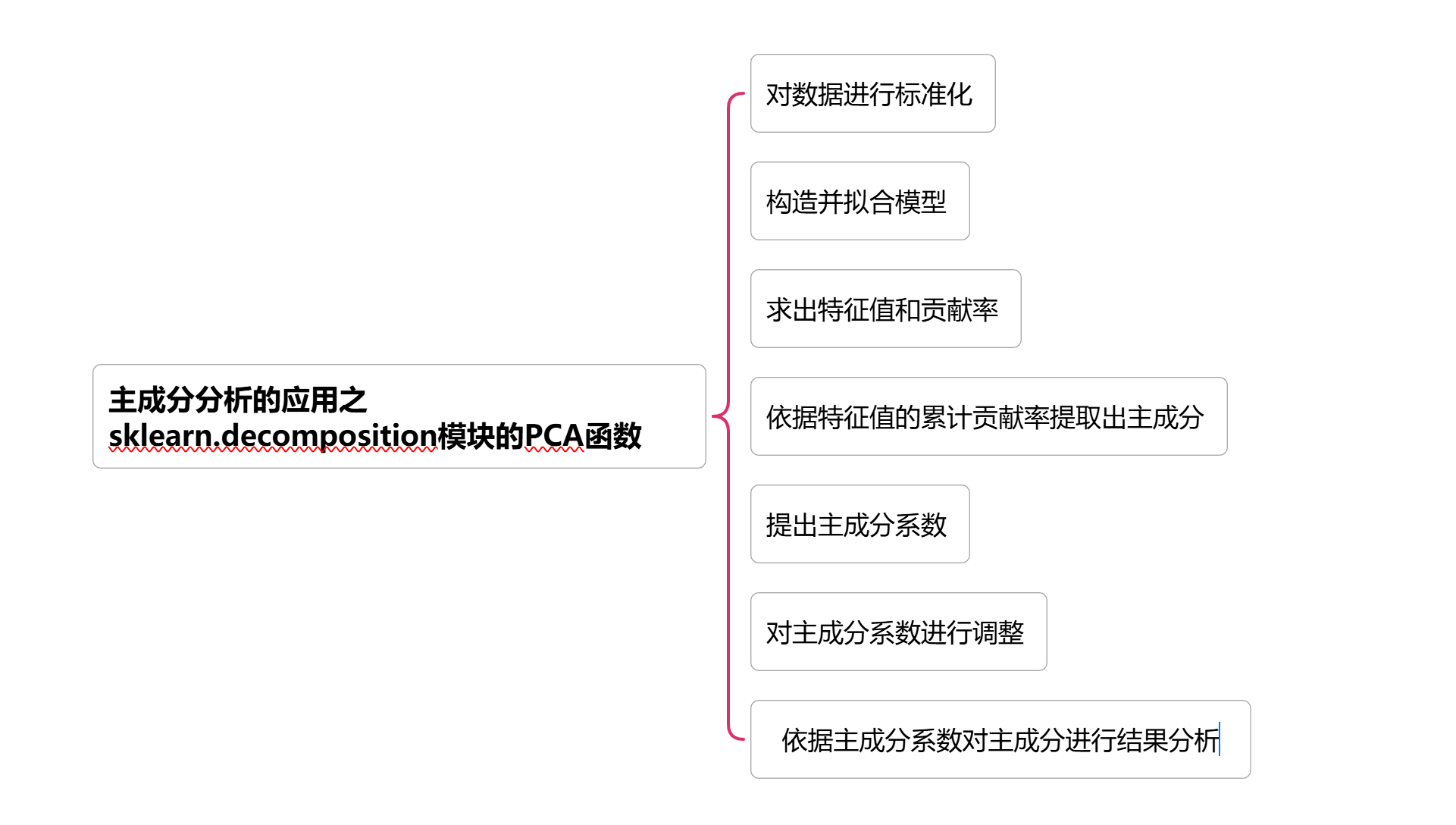
二、数据
2297.86 589.62 474.74 164.19 290.91 626.21 295.20 199.03
2262.19 571.69 461.25 185.90 337.83 604.78 354.66 198.96
2303.29 589.99 516.21 236.55 403.92 730.05 438.41 225.80
2308.70 551.14 476.45 293.23 406.44 785.74 494.04 254.10
2337.65 589.28 509.82 334.05 442.50 850.15 563.72 246.51
2418.96 618.60 454.20 429.60 615.00 1065.12 594.48 164.28
2702.34 735.01 475.36 459.69 790.26 1025.99 741.60 187.81
3015.32 779.68 474.15 537.95 865.45 1200.52 903.22 196.77
3135.65 849.53 583.50 629.32 929.92 1391.11 882.41 221.85
3415.92 1038.98 615.74 705.72 976.02 1449.49 954.56 242.26
三、代码实现(含详细注释)
#程序文件ex12_1.py
import numpy as np
from sklearn.decomposition import PCA
from scipy.stats import zscorea=np.loadtxt('data12_1.txt')
# scipy.stats的zscore函数对数组a中的数据进行标准化处理,并将结果赋值给变量b。
# 标准化处理是将数据转换为以0为均值,以标准差为1的分布,
# 这样做的目的是消除不同量纲的影响,使得数据具有可比性。
# zscore函数计算每个值与其均值的差,然后除以该数据的标准差,
# 从而得到Z分数(也称为标准分数)。
# 参数ddof=1指定在计算标准差时使用分母N-1(其中N是数据的数量),这是统计学中的样本标准差计算方式(无偏估计)。
# 如果ddof=0,则使用N作为分母计算标准差,这通常对应于总体标准差。
b=zscore(a, ddof=1) #数据标准化
# 创建一个PCA实例,使用数据集b来“拟合”这个实例(即计算PCA转换所需的参数)
md=PCA().fit(b) #构造并拟合模型
print('特征值为:', md.explained_variance_)
print('各主成分贡献率:', md.explained_variance_ratio_)
# .components_:这是md对象的一个属性,它通常存储了数据分解或降维后的结果。在PCA的上下文中,components_属性包含了主成分的方向(或者说是“轴”),
# 这些主成分是用来解释原始数据集方差的最大方向。每个主成分都是一个向量,向量的长度等于原始数据的特征数。
xs1=md.components_ #提出各主成分系数,每行是一个主成分
print('各主成分系数:\n',xs1)# axis=0代表沿着行的方向(即垂直方向,对列进行求和),而axis=1代表沿着列的方向(即水平方向,对行进行求和)。
# 因此,axis=1意味着会对xs1的每一行进行求和。
check=xs1.sum(axis=1,keepdims=True) #计算各个主成分系数的和
# xs1 * np.sign(check):这个操作是逐元素的乘法。
# xs1数组中的每个元素与np.sign(check)数组中对应位置的元素相乘。这意味着:
# 如果check中的某个元素为正,xs1中对应的元素保持不变(因为乘以1)。
# 如果check中的某个元素为负,xs1中对应的元素取反(因为乘以-1)。
# 如果check中的某个元素为零,xs1中对应的元素将变为零(因为乘以0)。
xs2=xs1*np.sign(check) #调整主成分系数,和为负时乘以-1
print('调整后的主成分系数:', xs2)
三、结果及其分析
特征值为: [6.27943341e+00 1.30599080e+00 2.74277611e-01 9.97624700e-022.31016993e-02 1.22233669e-02 4.69357480e-03 5.17066158e-04]
各主成分贡献率: [7.84929176e-01 1.63248850e-01 3.42847014e-02 1.24703088e-022.88771241e-03 1.52792086e-03 5.86696851e-04 6.46332697e-05]
各主成分系数:[[ 0.39186166 0.38439344 0.3059243 0.39231584 0.38537825 0.389613220.38389911 0.05908768][-0.0210478 0.02214509 0.47783697 -0.08905605 -0.19878256 -0.1043221-0.11376475 0.83634169][ 0.14762176 0.39254883 0.57745685 -0.20021017 -0.15914777 -0.1347164-0.4303164 -0.47108809][ 0.47832186 0.48941314 -0.44488132 -0.27708115 0.02393188 -0.465646730.07989617 0.18222681][-0.09762149 -0.27604773 0.34873203 -0.35508891 0.52307577 -0.456434080.4158212 -0.10824944][ 0.70552867 -0.53549607 0.049896 -0.32914209 -0.14716623 0.28505603-0.02367193 -0.03426265][-0.08102349 0.10492282 0.11905975 -0.07206231 -0.68369188 -0.020605350.68706375 -0.15212634][ 0.28557308 -0.29011082 0.09180137 0.6940343 -0.15286467 -0.55886444-0.05098258 -0.07665729]]
调整后的主成分系数: [[ 0.39186166 0.38439344 0.3059243 0.39231584 0.38537825 0.389613220.38389911 0.05908768][-0.0210478 0.02214509 0.47783697 -0.08905605 -0.19878256 -0.1043221-0.11376475 0.83634169][-0.14762176 -0.39254883 -0.57745685 0.20021017 0.15914777 0.13471640.4303164 0.47108809][ 0.47832186 0.48941314 -0.44488132 -0.27708115 0.02393188 -0.465646730.07989617 0.18222681][ 0.09762149 0.27604773 -0.34873203 0.35508891 -0.52307577 0.45643408-0.4158212 0.10824944][-0.70552867 0.53549607 -0.049896 0.32914209 0.14716623 -0.285056030.02367193 0.03426265][ 0.08102349 -0.10492282 -0.11905975 0.07206231 0.68369188 0.02060535-0.68706375 0.15212634][-0.28557308 0.29011082 -0.09180137 -0.6940343 0.15286467 0.558864440.05098258 0.07665729]]
由结果可知前两个特征值的累积量贡献率达到了94.82%,主成分分析效果很好,因此后续直接对这两个主成分的特征值进行详细的分析即可。