机器学习-人与机器生数据的区分模型测试 - 模型选择与微调
内容继续机器学习-人与机器生数据的区分模型测试
整体模型的准确率
X_train_scaled = pd.DataFrame(X_train_scaled,columns =X_train.columns )
X_test_scaled = pd.DataFrame(X_test_scaled,columns =X_test.columns)from ngboost.distns import Bernoulli
# 模型训练和评估
models = {'Random Forest': RandomForestClassifier(n_estimators=100, random_state=42),'XGBoost': XGBClassifier(n_estimators=100, random_state=42), # 假设使用XGBoost模型,'Logistic Regression': LogisticRegression(random_state=42), # 假设使用逻辑回归模型,'K-Nearest Neighbors': KNeighborsClassifier(), # 假设使用KNN模型,'Decision Tree': DecisionTreeClassifier(random_state=42), # 假设使用决策树模型,'LightGBM': LGBMClassifier(n_estimators=100, random_state=42), # 假设使用LightGBM模型,'CatBoost': CatBoostClassifier(n_estimators=100, random_state=42), # 假设使用CatBoost模型,#'NGBoost': NGBClassifier(Dist=Bernoulli,n_estimators=100, random_state=42) # 假设使用NGBoost模型,
}# 训练模型并评估
for name, model in models.items():model.fit(X_train_scaled, y_train) # 训练模型y_pred = model.predict(X_test_scaled) # 预测测试集accuracy = accuracy_score(y_test, y_pred) # 计算准确率print(f"{name} Accuracy: {accuracy}") # 打印准确率# 绘制混淆矩阵cm = confusion_matrix(y_test, y_pred) # 计算混淆矩阵sns.heatmap(cm, annot=True, fmt='d', cmap='Blues') # 绘制混淆矩阵plt.xlabel('Predicted') # 设置x轴标签plt.ylabel('True') # 设置y轴标签plt.title('Confusion Matrix') # 设置标题plt.show() # 显示混淆矩阵代码输出准确率与混淆矩阵,最后模型选择 随机森林,xgboost,lightgbm catboost四个模型。结果不一一展示。

输出准确率
def plot_param_impact(model_class, param_name, param_values):"""绘制不同参数值对模型训练集和测试集准确率的影响曲线。:param model_class: 模型类,例如 RandomForestClassifier、LogisticRegression 等:param param_name: 要调整的参数名称,字符串类型:param param_values: 要测试的参数值列表"""# 用于存储不同参数值下训练集的准确率train_acc = []# 用于存储不同参数值下测试集的准确率test_acc = []for value in param_values:# 创建模型实例,使用 ** 解包字典的方式传递当前参数值,并固定 random_state 以保证结果可复现model = model_class(**{param_name: value}, random_state=42)# 使用训练集数据对模型进行训练model.fit(X_train_scaled, y_train)# 计算模型在训练集上的准确率,并添加到 train_acc 列表中train_acc.append(model.score(X_train_scaled, y_train))# 计算模型在测试集上的准确率,并添加到 test_acc 列表中test_acc.append(model.score(X_test_scaled, y_test))# 创建一个新的图形,设置图形大小为 8x5 英寸plt.figure(figsize=(8, 5))# 绘制训练集准确率曲线,蓝色圆点连线plt.plot(param_values, train_acc, 'bo-', label='Training Accuracy')# 绘制测试集准确率曲线,红色方块虚线plt.plot(param_values, test_acc, 'rs--', label='Testing Accuracy')# 设置 x 轴标签为要调整的参数名称plt.xlabel(param_name)# 设置 y 轴标签为准确率plt.ylabel('Accuracy')# 设置图形标题,显示参数名称和模型类名plt.title(f'Impact of {param_name} on {model_class.__name__} Performance')# 显示图例plt.legend()# 显示网格线plt.grid(True)# 显示绘制好的图形plt.show()catboost 这里需要单独处理
def catboost_plot_param_impact(model_class, param_name, param_values):"""绘制不同参数值对 CatBoost 模型训练集和测试集准确率的影响曲线。:param model_class: 模型类,通常为 CatBoostClassifier:param param_name: 要调整的参数名称,字符串类型:param param_values: 要测试的参数值列表"""# 用于存储不同参数值下训练集的准确率train_acc = []# 用于存储不同参数值下测试集的准确率test_acc = []for value in param_values:# 创建 CatBoost 模型实例,使用 ** 解包字典的方式传递当前参数值# grow_policy='Lossguide':设置树的生长策略为损失引导# random_state=42:固定随机种子以保证结果可复现# eval_metric='Accuracy':使用准确率作为评估指标# verbose=False:不输出训练过程信息model = model_class(**{param_name: value}, grow_policy='Lossguide', random_state=42,eval_metric='Accuracy',\verbose=False)# 使用训练集数据对模型进行训练model.fit(X_train_scaled, y_train)# 计算模型在训练集上的准确率,并添加到 train_acc 列表中train_acc.append(model.score(X_train_scaled, y_train))# 计算模型在测试集上的准确率,并添加到 test_acc 列表中test_acc.append(model.score(X_test_scaled, y_test))# 创建一个新的图形,设置图形大小为 8x5 英寸plt.figure(figsize=(8, 5))# 绘制训练集准确率曲线,蓝色圆点连线plt.plot(param_values, train_acc, 'bo-', label='Training Accuracy')# 绘制测试集准确率曲线,红色方块虚线plt.plot(param_values, test_acc, 'rs--', label='Testing Accuracy')# 设置 x 轴标签为要调整的参数名称plt.xlabel(param_name)# 设置 y 轴标签为准确率plt.ylabel('Accuracy')# 设置图形标题,显示参数名称和模型类名plt.title(f'Impact of {param_name} on {model_class.__name__} Performance')# 显示图例plt.legend()# 显示网格线plt.grid(True)# 显示绘制好的图形plt.show()
模型的评估与比对
#随机模型调参
def model_tuning_pipeline(model_class,default_params=None,param_grid=None,search_cv=GridSearchCV,search_cv_args=None,X_train=X_train_scaled,y_train=y_train,X_test=X_test_scaled,y_test=y_test,random_state=42,title_suffix=""
):"""通用模型调参流水线(训练默认模型+超参数搜索+结果对比)参数:model_class: 模型类 (RandomForestClassifier/XGBClassifier等)default_params: 默认参数字典param_grid: 调参参数空间search_cv: 搜索器类 (GridSearchCV/RandomizedSearchCV)search_cv_args: 搜索器参数字典X_train: 训练特征数据(默认使用缩放后的数据)y_train: 训练标签数据X_test: 测试特征数据(默认使用缩放后的数据)y_test: 测试标签数据random_state: 随机种子title_suffix: 图表标题后缀返回:包含所有结果的字典"""# 参数初始化default_params = default_params or {}search_cv_args = search_cv_args or {}# 合并随机种子参数merged_params = {**default_params, "random_state": random_state}# ========== 默认模型训练 ==========default_model = model_class(**merged_params)default_model.fit(X_train_scaled, y_train)default_train_acc = default_model.score(X_train_scaled, y_train)default_test_acc = model.score(X_test_scaled, y_test)# ========== 参数搜索优化 ==========# 配置搜索器参数param_key = "param_grid" if search_cv == GridSearchCV else "param_distributions"search_args = {"estimator": model_class(**merged_params),param_key: param_grid,**search_cv_args}# 执行参数搜索search = search_cv(**search_args)search.fit(X_train_scaled, y_train)# ========== 最佳模型评估 ==========best_model = search.best_estimator_tuned_train_acc = best_model.score(X_train_scaled, y_train)tuned_test_acc = best_model.score(X_test_scaled, y_test)# ========== 可视化对比 ==========plt.figure(figsize=(10, 6))labels = ['Default (Train)', 'Default (Test)', 'Tuned (Train)', 'Tuned (Test)']values = [default_train_acc, default_test_acc, tuned_train_acc, tuned_test_acc]colors = ['#1f77b4', '#ff7f0e', '#1f77b4', '#ff7f0e'] # 保持颜色一致性bars = plt.bar(labels, values, color=colors, alpha=0.7)plt.ylabel("Accuracy", fontsize=12)plt.title(f"Model Performance Comparison: {title_suffix}", fontsize=14)plt.ylim(min(values)-0.05, max(values)+0.05)# 添加数值标签for bar in bars:height = bar.get_height()plt.text(bar.get_x() + bar.get_width()/2., height,f"{height:.4f}", ha="center", va="bottom")plt.grid(axis="y", linestyle="--", alpha=0.7)plt.tight_layout()plt.show()# 输出最佳参数print("="*50)print(f"Best parameters for {model_class.__name__}:")print(json.dumps(search.best_params_, indent=2))return {"default_model": default_model,"best_model": best_model,"performance": {"default_train": default_train_acc,"default_test": default_test_acc,"tuned_train": tuned_train_acc,"tuned_test": tuned_test_acc},"best_params": search.best_params_}添加模型验证的范围
随机森林
from sklearn.model_selection import RandomizedSearchCV
num_classes = len(np.unique(y_train))# 随机森林调参
# 调用 model_tuning_pipeline 函数对随机森林模型进行超参数调优
rf_result = model_tuning_pipeline(# 指定要调参的模型类为随机森林分类器model_class=RandomForestClassifier,# 设置随机森林模型的默认参数,这里设置了树的数量为 100default_params={"n_estimators": 100},# 定义要搜索的超参数空间,包含树的数量、最大深度、最小样本分割数和最大特征数param_grid={"n_estimators": [100, 200], # 尝试不同的树的数量"max_depth": [None, 10, 20], # 尝试不同的最大深度,None 表示不限制深度"min_samples_split": [2, 5], # 尝试不同的最小样本分割数"max_features": ["sqrt", "log2"] # 尝试不同的最大特征数选择方法},# 指定使用网格搜索进行超参数搜索search_cv=GridSearchCV,# 设置网格搜索的参数,cv 表示交叉验证的折数,n_jobs=-1 表示使用所有可用的 CPU 核心search_cv_args={"cv": 5, "n_jobs": -1},# 设置图表标题的后缀,用于标识当前调参的模型title_suffix="Random Forest"
)
xgboost
xgb_result = model_tuning_pipeline(# 指定要调优的模型类为 XGBClassifier,即 XGBoost 分类器model_class=XGBClassifier,# 设置 XGBoost 模型的默认参数default_params={# 多分类任务使用 softmax 作为目标函数"objective": "multi:softmax",# 分类的类别数量,由 num_classes 变量指定"num_class": num_classes},# 定义要搜索的超参数空间param_grid={# 尝试不同的树的数量"n_estimators": [50, 100, 150, 200],# 尝试不同的树的最大深度"max_depth": [3, 4, 5, 6],# 尝试不同的学习率"learning_rate": [0.001, 0.01, 0.1]},# 指定使用随机搜索(RandomizedSearchCV)进行超参数搜索search_cv=RandomizedSearchCV,# 设置随机搜索的参数search_cv_args={"n_iter": 20, "cv": 3},# 设置图表标题的后缀,用于标识当前调优的模型title_suffix="XGBoost"
)
lightgbm
# 调用 model_tuning_pipeline 函数对 LightGBM 模型进行超参数调优
lgb_result = model_tuning_pipeline(# 指定要调优的模型类为 LGBMClassifier,即 LightGBM 分类器model_class=LGBMClassifier,# 设置 LightGBM 模型的默认参数default_params={# 多分类任务使用 multiclass 作为目标函数"objective": "multiclass",# 分类的类别数量,由 num_classes 变量指定"num_class": num_classes,# 设置日志输出级别为 -1,即不输出日志信息"verbose": -1},# 定义要搜索的超参数空间param_grid={# 尝试不同的树的数量"n_estimators": [50, 100, 150, 200],# 尝试不同的树的最大深度"max_depth": [3, 4, 5, 6],# 尝试不同的学习率"learning_rate": [0.001, 0.01, 0.1],# 尝试不同的叶子节点数量"num_leaves": [31, 50, 100],# 尝试不同的叶子节点最小样本数"min_child_samples": [20, 50, 100]},# 指定使用随机搜索(RandomizedSearchCV)进行超参数搜索search_cv=RandomizedSearchCV,# 设置随机搜索的参数search_cv_args={"n_iter": 20, "cv": 3},# 设置图表标题的后缀,用于标识当前调优的模型title_suffix="LightGBM"
)
catboost
# CATBoost调参
cat_result = model_tuning_pipeline(model_class=CatBoostClassifier,default_params={'silent':True, 'random_state':42},param_grid={'iterations': [100, 200, 300], # 树的数量'depth': [4, 6, 8], # 树深度'learning_rate': [0.01, 0.1, 0.2], # 学习率'l2_leaf_reg': [1, 3, 5], # L2正则化系数'border_count': [32, 64, 128], # 特征分箱数(适用于数值特征)'bagging_temperature': [0, 0.5, 1.0] # 贝叶斯自助采样强度},search_cv=RandomizedSearchCV,search_cv_args={"n_iter": 20, "cv": 3},title_suffix="CATBoost"
)
手动调参
# 随机森林
plot_param_impact(RandomForestClassifier, 'n_estimators', [10, 50, 100, 200, 300])
plot_param_impact(RandomForestClassifier, 'max_depth', [None, 5, 10, 20, 30])
plot_param_impact(RandomForestClassifier, 'min_samples_split', [2, 5, 10, 20])
plot_param_impact(RandomForestClassifier, 'max_features', ['sqrt', 'log2'])# XGBoost
plot_param_impact(XGBClassifier, 'n_estimators', [50, 100, 150, 200,250,300])
plot_param_impact(XGBClassifier, 'max_depth', [3, 4, 5, 6,7])
plot_param_impact(XGBClassifier, 'learning_rate', [0.1, 0.01, 0.001])
plot_param_impact(XGBClassifier, 'lambda', [0.1, 1, 5, 10])
plot_param_impact(XGBClassifier, 'alpha', [0.01, 0.01, 0.05, 1])# lightgbm
plot_param_impact(LGBMClassifier,'num_leaves', [5, 50, 100, 200,300]) # 控制模型复杂度
plot_param_impact(LGBMClassifier,'max_depth', [3, 5, 7, 10,12])
plot_param_impact(LGBMClassifier,'learning_rate', [0.01, 0.1, 0.2, 0.3]) # 学习率影响
plot_param_impact(LGBMClassifier,'lambda_l1', [0, 0.01, 0.05, 0.1, 0.5]) # 正则
plot_param_impact(LGBMClassifier,'lambda_l2', [0, 0.1, 0.5, 1, 2]) # 正则
#$bagging_freq,bagging_fraction feature_fraction lambda_l2# catboost
#catboost_plot_param_impact(CatBoostClassifier,'num_leaves', [15, 31, 63, 127]) # 控制模型复杂度
catboost_plot_param_impact(CatBoostClassifier,'learning_rate', [0.01, 0.1, 0.2, 0.3]) # 学习率影响
catboost_plot_param_impact(CatBoostClassifier,'max_depth', [3, 5, 7, 10])
catboost_plot_param_impact(CatBoostClassifier,'n_estimators', [50, 100, 150, 200,300,500]) 随机调参的结果如下。数量很多不一一截图。
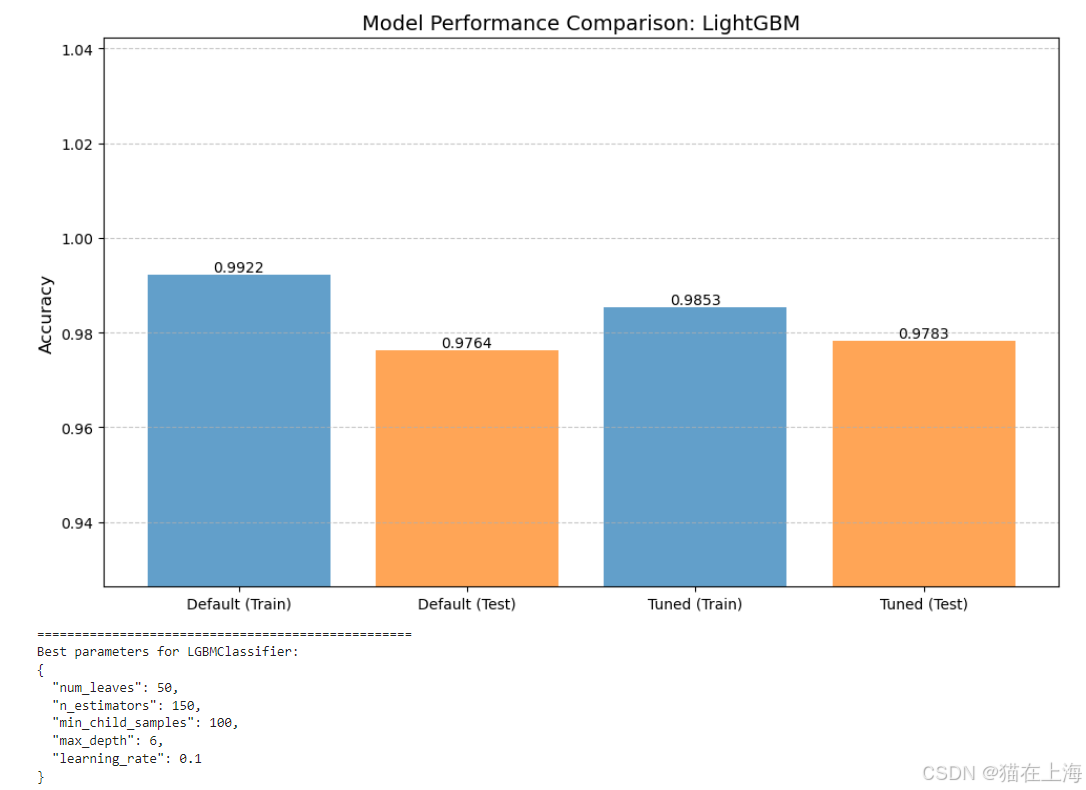
手动调参:
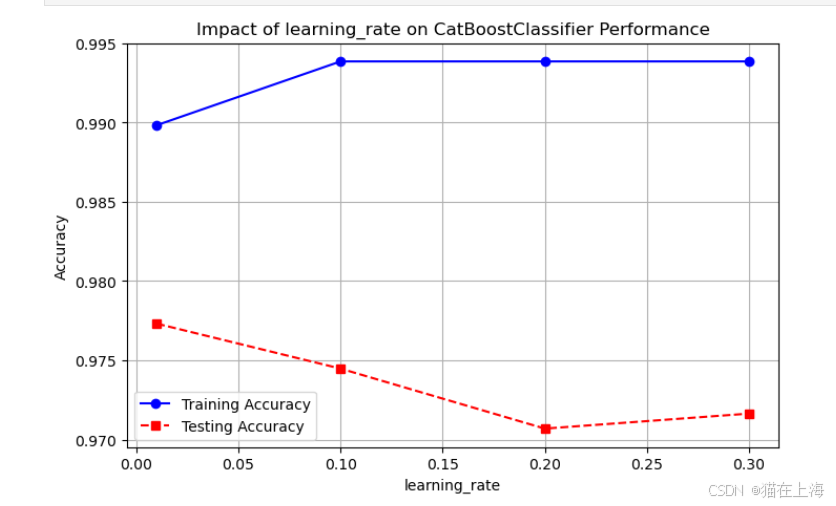
最后综合比对模型的参数效果。