【AI】CUDA 是如何成功的?(AI 计算的民主化,第 3 部分)
如果我们作为一个生态系统希望取得进步,我们需要了解CUDA 软件帝国是如何变得如此主导地位的。理论上,存在替代方案——AMD 的 ROCm、英特尔的 oneAPI、基于 SYCL 的框架——但实际上,CUDA 仍然是GPU 计算领域无可争议的王者。
这是怎么发生的?
答案不仅仅在于技术卓越——尽管技术卓越也发挥了一定作用。CUDA 是一个开发者平台,它建立在卓越的执行力、深度战略投资、持续性、生态系统锁定,当然,还有一点点运气的功劳。
这篇文章将深入剖析CUDA 如此成功的原因,并探索 NVIDIA 战略的多个层面——从早期押注于推广并行计算,到PyTorch和TensorFlow等 AI 框架的紧密耦合。最终,CUDA 的主导地位不仅是软件的胜利,更是长期平台思维的典范。
让我们开始吧。🚀
本文是 Modular “ AI 计算民主化”系列文章的第三部分。更多信息,请参阅:
- 第一部分:DeepSeek 对 AI 的影响
- 第 2 部分:“CUDA”到底是什么?
- 第三部分:CUDA 如何成功?(本文)
- 第 4 部分:CUDA 是现任者,但它好用吗?
- 第 5 部分:OpenCL 和 CUDA C++替代品怎么样?
- 第 6 部分:TVM、XLA 和 AI 编译器怎么样?
- 第 7 部分:Triton 和 Python eDSL 怎么样?
- 第 8 部分:MLIR 编译器基础设施怎么样?
- 第九部分:硬件公司为何难以构建人工智能软件?
- 第十部分:Modular 打破矩阵格局的策略
CUDA 的早期发展
构建计算平台的一个关键挑战是吸引开发者学习和投资,如果只瞄准小众硬件,很难获得发展动力。在精彩的“Acquired”播客中,黄仁勋分享了 NVIDIA 早期的一个关键策略,即保持其 GPU 跨代兼容。这使得 NVIDIA 能够利用其已经广泛普及的游戏 GPU的安装基础,这些 GPU 主要用于运行基于 DirectX 的 PC 游戏。此外,它还使开发者能够在低价台式电脑上学习 CUDA,并扩展到功能更强大、价格更高的硬件上。
现在看来,这或许显而易见,但在当时,这可谓一次大胆的尝试:NVIDIA 没有创建针对不同用例(笔记本电脑、台式机、物联网、数据中心等)进行优化的独立产品线,而是构建了一条连续的 GPU 产品线。这意味着需要做出一些权衡——例如功耗或成本效率低下——但作为回报,它创建了一个统一的生态系统,让每位开发者对 CUDA 的投资都能从游戏 GPU 无缝扩展到高性能数据中心加速器。这一策略与苹果维护和推动其 iPhone 产品线发展的方式颇为相似。
这种方法有双重好处:
- 降低进入门槛——开发人员可以使用他们已有的 GPU 学习 CUDA,从而轻松进行实验和采用。
- 创造网络效应——随着越来越多的开发人员开始使用 CUDA,更多的软件和库被创建,使得该平台更有价值。
早期的安装基础使 CUDA 得以从游戏领域扩展到科学计算、金融、人工智能和高性能计算 (HPC)。一旦 CUDA 在这些领域获得发展,其相对于其他竞争对手的优势就变得显而易见:NVIDIA 的持续投资确保了 CUDA 始终处于 GPU 性能的前沿,而竞争对手则难以构建可比的生态系统。
抓住并引领人工智能软件的浪潮
随着深度学习的爆发式发展, CUDA 的主导地位更加巩固。2012 年,开启现代人工智能革命的神经网络AlexNet使用两块 NVIDIA GeForce GTX 580 GPU 进行训练。这一突破不仅证明了GPU 在深度学习方面速度更快,更证明了它们对于人工智能发展至关重要,并促使CUDA 迅速成为深度学习的默认计算后端。
随着深度学习框架的兴起——其中最引人注目的是TensorFlow(谷歌,2015 年)和PyTorch(Meta,2016 年)—— NVIDIA抓住了机遇,投入巨资优化其高级 CUDA 库,以确保这些框架在其硬件上尽可能高效地运行。NVIDIA 没有让AI 框架团队自行处理低级 CUDA 性能调优,而是主动承担了这项任务,积极优化cuDNN和TensorRT,正如我们在第二部分中讨论的那样。
此举不仅显著提升了 PyTorch 和 TensorFlow在 NVIDIA GPU 上的运行速度,还减少了与 Google 和 Meta 的协调,使 NVIDIA 能够紧密集成其硬件和软件(这一过程被称为“软硬件协同设计”)。每一代主流硬件都会推出新版本的 CUDA,以充分利用硬件的新功能。追求速度和效率的 AI 社区非常乐意将这一责任委托给 NVIDIA,这直接导致这些框架与 NVIDIA 硬件绑定。
但谷歌和 Meta 为何会让这种情况发生?事实上,谷歌和 Meta并非专注于构建广泛的 AI 硬件生态系统,而是专注于利用 AI 来推动收入增长、改进产品并开启新的研究。他们的顶尖工程师优先考虑高影响力的内部项目,以提升公司内部指标。例如,这些公司决定 打造自己的专有 TPU 芯片,倾注全部精力优化自家的第一方硬件。将GPU的控制权交给 NVIDIA是合情合理的。
替代硬件制造商面临着一场艰苦的战斗——试图复制庞大且不断扩展的 NVIDIA CUDA 库生态系统,却缺乏同等程度的硬件集中度。竞争对手的硬件供应商不仅举步维艰,还陷入了无休止的循环,总是在 NVIDIA 硬件上追逐下一个 AI 进步。这也影响了谷歌和 Meta 的内部芯片项目,并催生了包括 XLA 和 PyTorch 2 在内的众多项目。我们可以在后续文章中深入探讨这些项目,但尽管抱有希望,我们今天仍然可以看到,没有任何硬件创新者能够匹敌 CUDA 平台的能力。
随着每一代硬件的推出,NVIDIA 都不断扩大差距。然后突然之间,在 2022 年末,ChatGPT 爆发式增长,随之而来的是GenAI 和 GPU 计算成为主流。
利用生成式人工智能的浪潮
几乎一夜之间,人工智能计算的需求飙升——它成为了数十亿美元产业、消费应用和竞争性企业战略的基础。大型科技公司和风险投资公司向人工智能研究初创企业和资本支出项目投入了数十亿美元——这些资金最终直接流向了英伟达——唯一一家能够满足爆炸式增长的计算需求的公司。
随着对 AI 计算的需求激增,企业面临着一个严峻的现实:训练和部署 GenAI 模型的成本极其高昂。每一次效率提升——无论多小——都会转化为大规模的巨大节省。由于NVIDIA 的硬件已经在数据中心站稳脚跟,AI 公司面临着一个严峻的选择:针对 CUDA 进行优化,否则就会落后。几乎在一夜之间,该行业就转向编写特定于 CUDA 的代码。结果如何?AI 的突破不再纯粹由模型和算法驱动——它们现在取决于从CUDA 优化代码中榨取每一滴效率的能力。
以FlashAttention-3为例:这项尖端优化大幅降低了运行 Transformer 模型的成本,但它专为Hopper GPU打造,从而确保最佳性能仅在其最新硬件上实现,从而强化了NVIDIA 的垄断地位。持续的研究创新也遵循了同样的轨迹,例如DeepSeek 直接采用 PTX 汇编,在尽可能低的层面上获得了对硬件的完全控制。随着全新NVIDIA Blackwell架构的即将问世,我们可以期待行业再次从头改写一切。
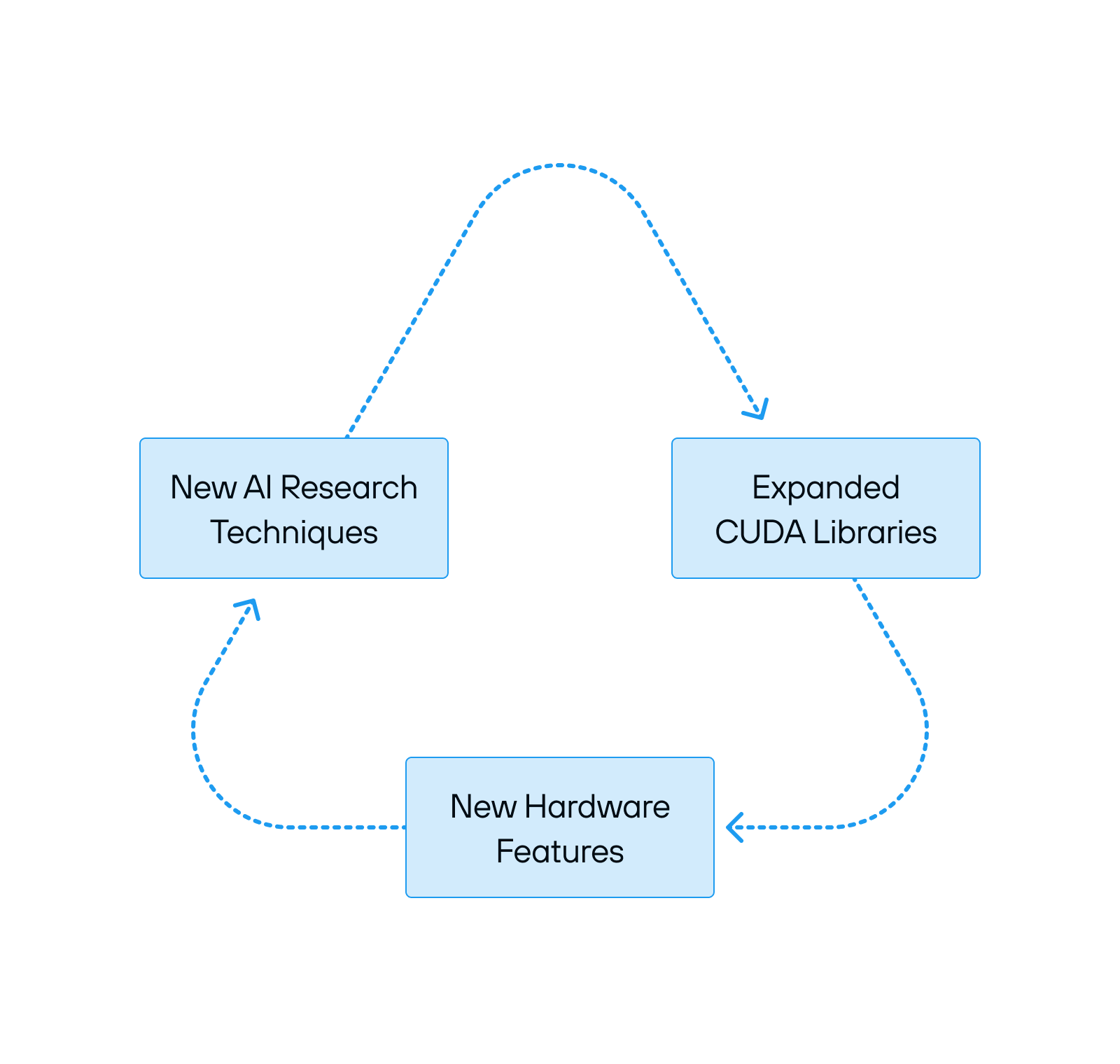
增强 CUDA 控制力的强化循环
这个系统正在加速发展并自我强化。生成式人工智能已成为一股不可阻挡的力量,推动着对计算的无限需求,而NVIDIA 则占据了主导地位。最大的安装基础确保了大多数人工智能研究都基于CUDA进行,这反过来又推动了对优化 NVIDIA 平台的投资。
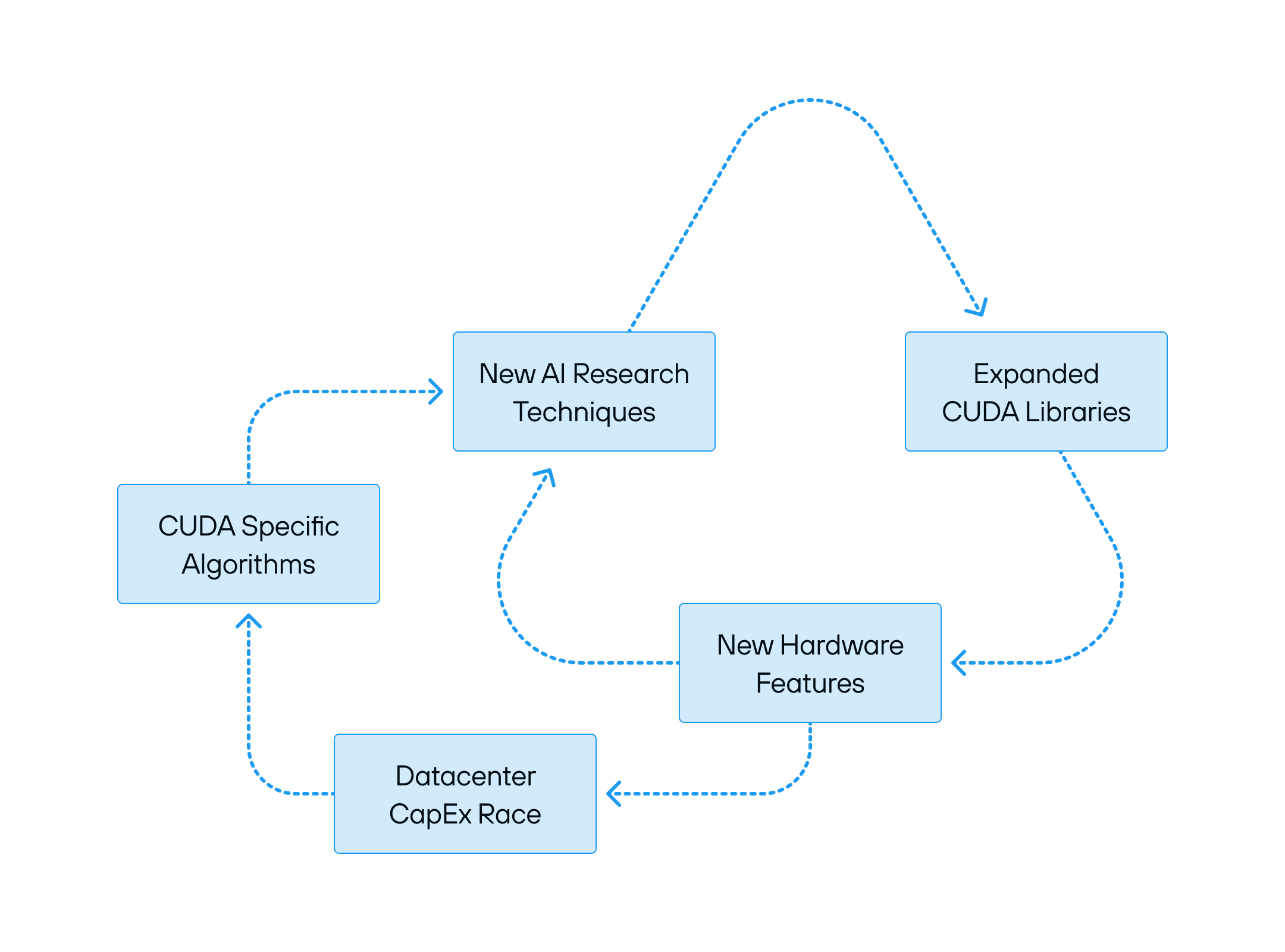
每一代 NVIDIA 硬件都会带来新的功能和更高的效率,但也需要新的软件重写、新的优化以及对 NVIDIA 堆栈更深层次的依赖。未来似乎不可避免:CUDA 对 AI 计算的控制只会越来越紧。
但 CUDA 并不完美。
那些巩固CUDA 主导地位的力量也正在成为瓶颈——技术挑战、效率低下以及更广泛创新的障碍。这种主导地位真的能服务于人工智能研究界吗?CUDA对开发者有利,还是仅仅对 NVIDIA 有利?
让我们回顾一下:我们了解了CUDA 是什么以及它为何如此成功,但它真的好用吗?我们将在第四部分探讨这个问题——敬请期待!如果您觉得本系列文章有用,或者有任何建议/需求,请随时告诉我们!🚀