userfaultfd内核线程D状态问题排查
问题现象
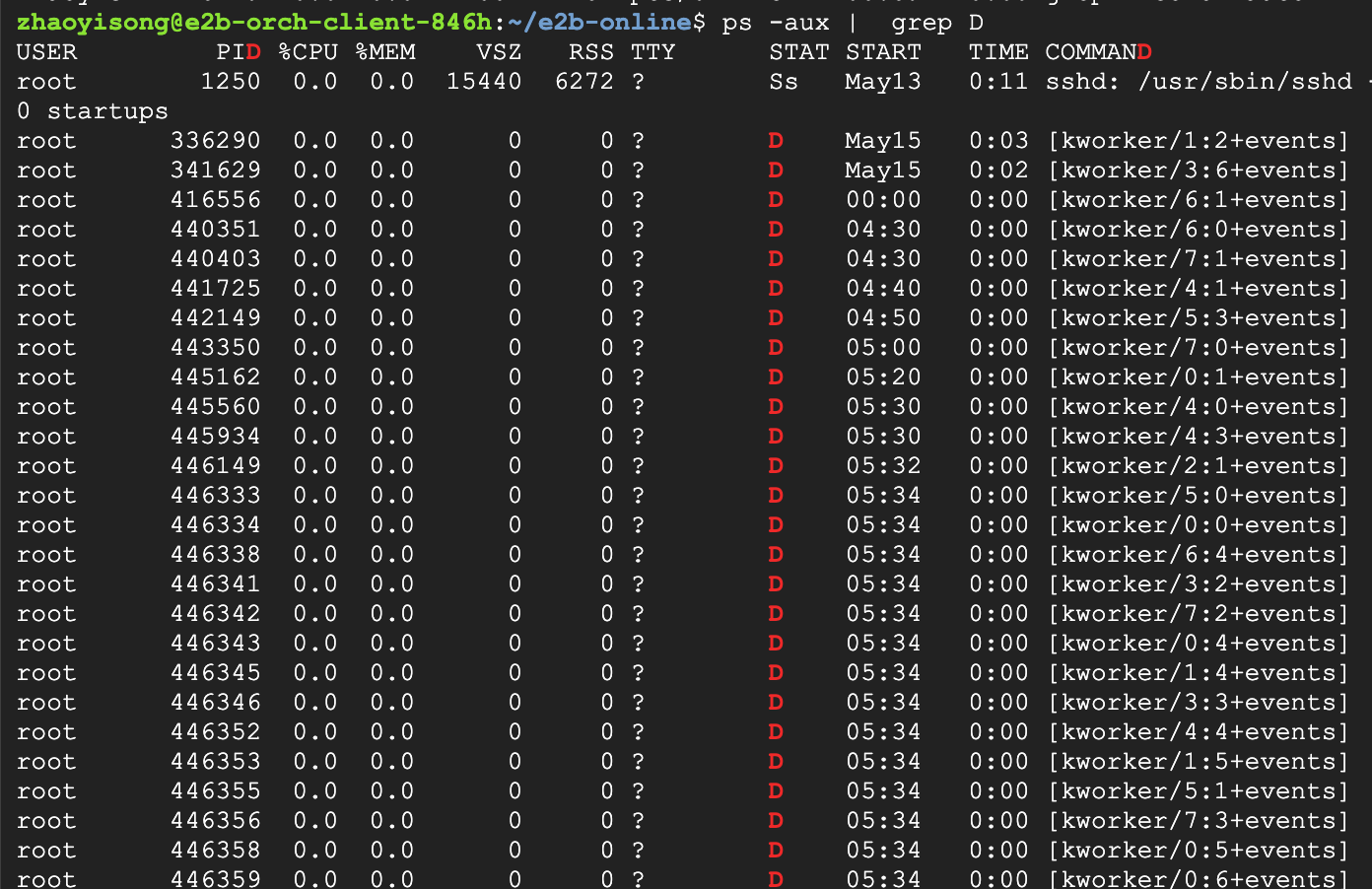
运维反应机器上出现了很多D状态进程,也kill不掉,然后将现场保留下来进行排查。
排查过程
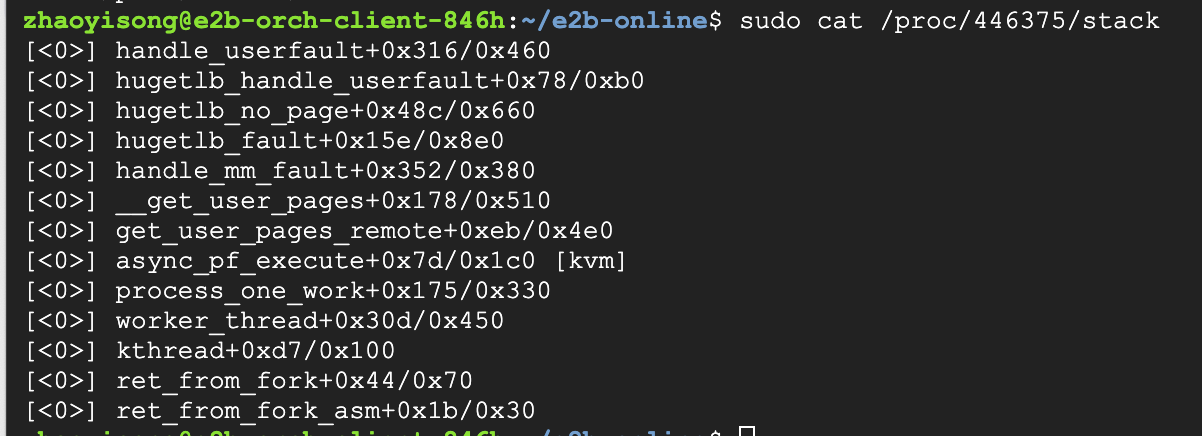
都是内核线程,先看下内核栈D在哪了,发现D在了userfaultfd的pagefault流程。
uffd知识补充
uffd探究
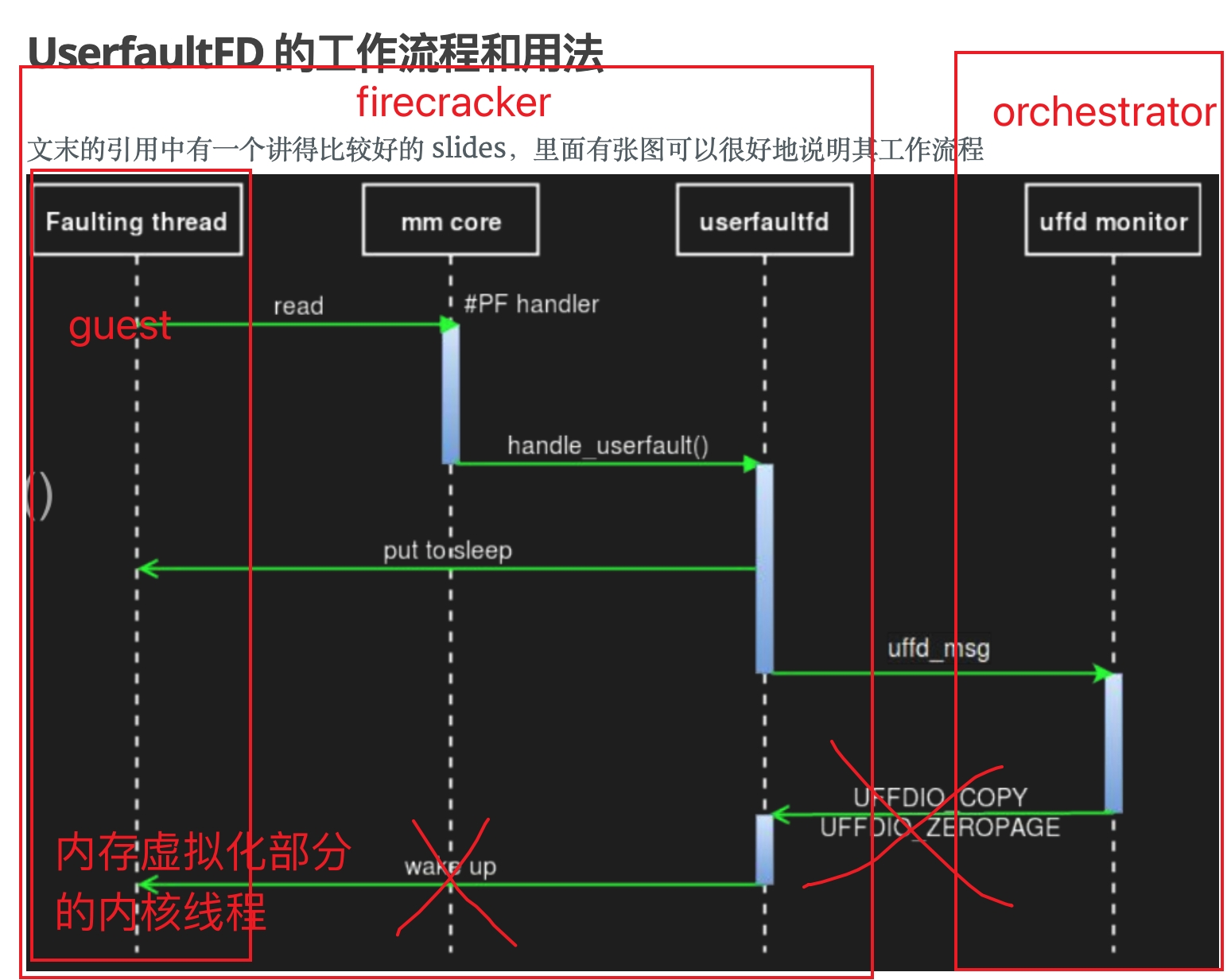
uffd在firecracker与e2b的架构下使用方式如下:
1.firecracker注册uffd共享给orchestrator,并将guest内存地址空间提交给orchestrator。
2.guest触发缺页,vm-exit出来,创建内核线程通知orchestrator有需要处理的pf请求,然后等待处理。
3.orchestrator会调用ioctl从内存快照文件中将数据写入到对应的内存页中
查看handle_userfault代码进行分析。
vm_fault_t handle_userfault(struct vm_fault *vmf, unsigned long reason)
{struct vm_area_struct *vma = vmf->vma;struct mm_struct *mm = vma->vm_mm;struct userfaultfd_ctx *ctx;struct userfaultfd_wait_queue uwq;vm_fault_t ret = VM_FAULT_SIGBUS;bool must_wait;unsigned int blocking_state;/** We don't do userfault handling for the final child pid update.** We also don't do userfault handling during* coredumping. hugetlbfs has the special* hugetlb_follow_page_mask() to skip missing pages in the* FOLL_DUMP case, anon memory also checks for FOLL_DUMP with* the no_page_table() helper in follow_page_mask(), but the* shmem_vm_ops->fault method is invoked even during* coredumping and it ends up here.*/if (current->flags & (PF_EXITING|PF_DUMPCORE))goto out;assert_fault_locked(vmf);ctx = vma->vm_userfaultfd_ctx.ctx;if (!ctx)goto out;BUG_ON(ctx->mm != mm);/* Any unrecognized flag is a bug. */VM_BUG_ON(reason & ~__VM_UFFD_FLAGS);/* 0 or > 1 flags set is a bug; we expect exactly 1. */VM_BUG_ON(!reason || (reason & (reason - 1)));if (ctx->features & UFFD_FEATURE_SIGBUS)goto out;if (!(vmf->flags & FAULT_FLAG_USER) && (ctx->flags & UFFD_USER_MODE_ONLY))goto out;/** If it's already released don't get it. This avoids to loop* in __get_user_pages if userfaultfd_release waits on the* caller of handle_userfault to release the mmap_lock.*/if (unlikely(READ_ONCE(ctx->released))) {/** Don't return VM_FAULT_SIGBUS in this case, so a non* cooperative manager can close the uffd after the* last UFFDIO_COPY, without risking to trigger an* involuntary SIGBUS if the process was starting the* userfaultfd while the userfaultfd was still armed* (but after the last UFFDIO_COPY). If the uffd* wasn't already closed when the userfault reached* this point, that would normally be solved by* userfaultfd_must_wait returning 'false'.** If we were to return VM_FAULT_SIGBUS here, the non* cooperative manager would be instead forced to* always call UFFDIO_UNREGISTER before it can safely* close the uffd.*/ret = VM_FAULT_NOPAGE;goto out;}/** Check that we can return VM_FAULT_RETRY.** NOTE: it should become possible to return VM_FAULT_RETRY* even if FAULT_FLAG_TRIED is set without leading to gup()* -EBUSY failures, if the userfaultfd is to be extended for* VM_UFFD_WP tracking and we intend to arm the userfault* without first stopping userland access to the memory. For* VM_UFFD_MISSING userfaults this is enough for now.*/if (unlikely(!(vmf->flags & FAULT_FLAG_ALLOW_RETRY))) {/** Validate the invariant that nowait must allow retry* to be sure not to return SIGBUS erroneously on* nowait invocations.*/BUG_ON(vmf->flags & FAULT_FLAG_RETRY_NOWAIT);
#ifdef CONFIG_DEBUG_VMif (printk_ratelimit()) {printk(KERN_WARNING"FAULT_FLAG_ALLOW_RETRY missing %x\n",vmf->flags);dump_stack();}
#endifgoto out;}/** Handle nowait, not much to do other than tell it to retry* and wait.*/ret = VM_FAULT_RETRY;if (vmf->flags & FAULT_FLAG_RETRY_NOWAIT)goto out;/* take the reference before dropping the mmap_lock */userfaultfd_ctx_get(ctx);init_waitqueue_func_entry(&uwq.wq, userfaultfd_wake_function);uwq.wq.private = current;uwq.msg = userfault_msg(vmf->address, vmf->real_address, vmf->flags,reason, ctx->features);uwq.ctx = ctx;uwq.waken = false;blocking_state = userfaultfd_get_blocking_state(vmf->flags);/** Take the vma lock now, in order to safely call* userfaultfd_huge_must_wait() later. Since acquiring the* (sleepable) vma lock can modify the current task state, that* must be before explicitly calling set_current_state().*/if (is_vm_hugetlb_page(vma))hugetlb_vma_lock_read(vma);spin_lock_irq(&ctx->fault_pending_wqh.lock);/** After the __add_wait_queue the uwq is visible to userland* through poll/read().*/__add_wait_queue(&ctx->fault_pending_wqh, &uwq.wq);/** The smp_mb() after __set_current_state prevents the reads* following the spin_unlock to happen before the list_add in* __add_wait_queue.*/set_current_state(blocking_state);spin_unlock_irq(&ctx->fault_pending_wqh.lock);if (!is_vm_hugetlb_page(vma))must_wait = userfaultfd_must_wait(ctx, vmf, reason);elsemust_wait = userfaultfd_huge_must_wait(ctx, vmf, reason);if (is_vm_hugetlb_page(vma))hugetlb_vma_unlock_read(vma);release_fault_lock(vmf);if (likely(must_wait && !READ_ONCE(ctx->released))) {wake_up_poll(&ctx->fd_wqh, EPOLLIN);schedule();}__set_current_state(TASK_RUNNING);/** Here we race with the list_del; list_add in* userfaultfd_ctx_read(), however because we don't ever run* list_del_init() to refile across the two lists, the prev* and next pointers will never point to self. list_add also* would never let any of the two pointers to point to* self. So list_empty_careful won't risk to see both pointers* pointing to self at any time during the list refile. The* only case where list_del_init() is called is the full* removal in the wake function and there we don't re-list_add* and it's fine not to block on the spinlock. The uwq on this* kernel stack can be released after the list_del_init.*/if (!list_empty_careful(&uwq.wq.entry)) {spin_lock_irq(&ctx->fault_pending_wqh.lock);/** No need of list_del_init(), the uwq on the stack* will be freed shortly anyway.*/list_del(&uwq.wq.entry);spin_unlock_irq(&ctx->fault_pending_wqh.lock);}/** ctx may go away after this if the userfault pseudo fd is* already released.*/userfaultfd_ctx_put(ctx);out:return ret;
}
看起来像是不知道什么原因导致调度出去后,一直没有被唤醒
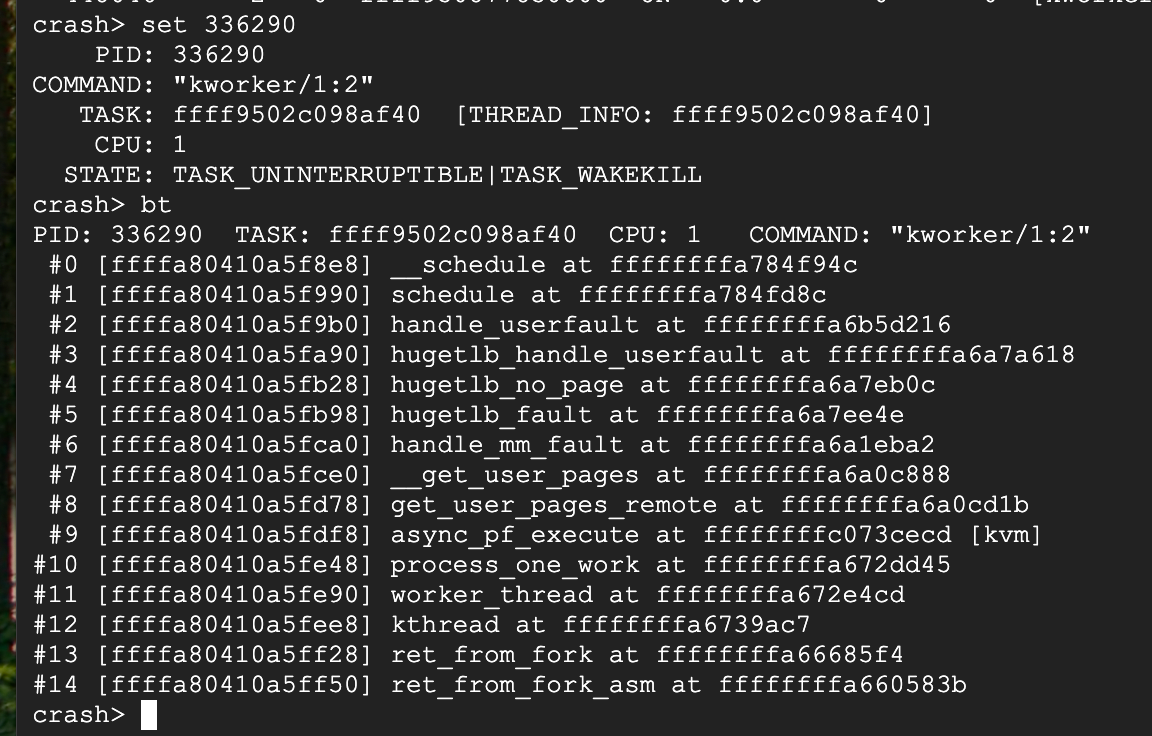
使用crash进一步验证猜想,随便找一个bt看下,确实是schedule调度出去之后没有再被唤醒。
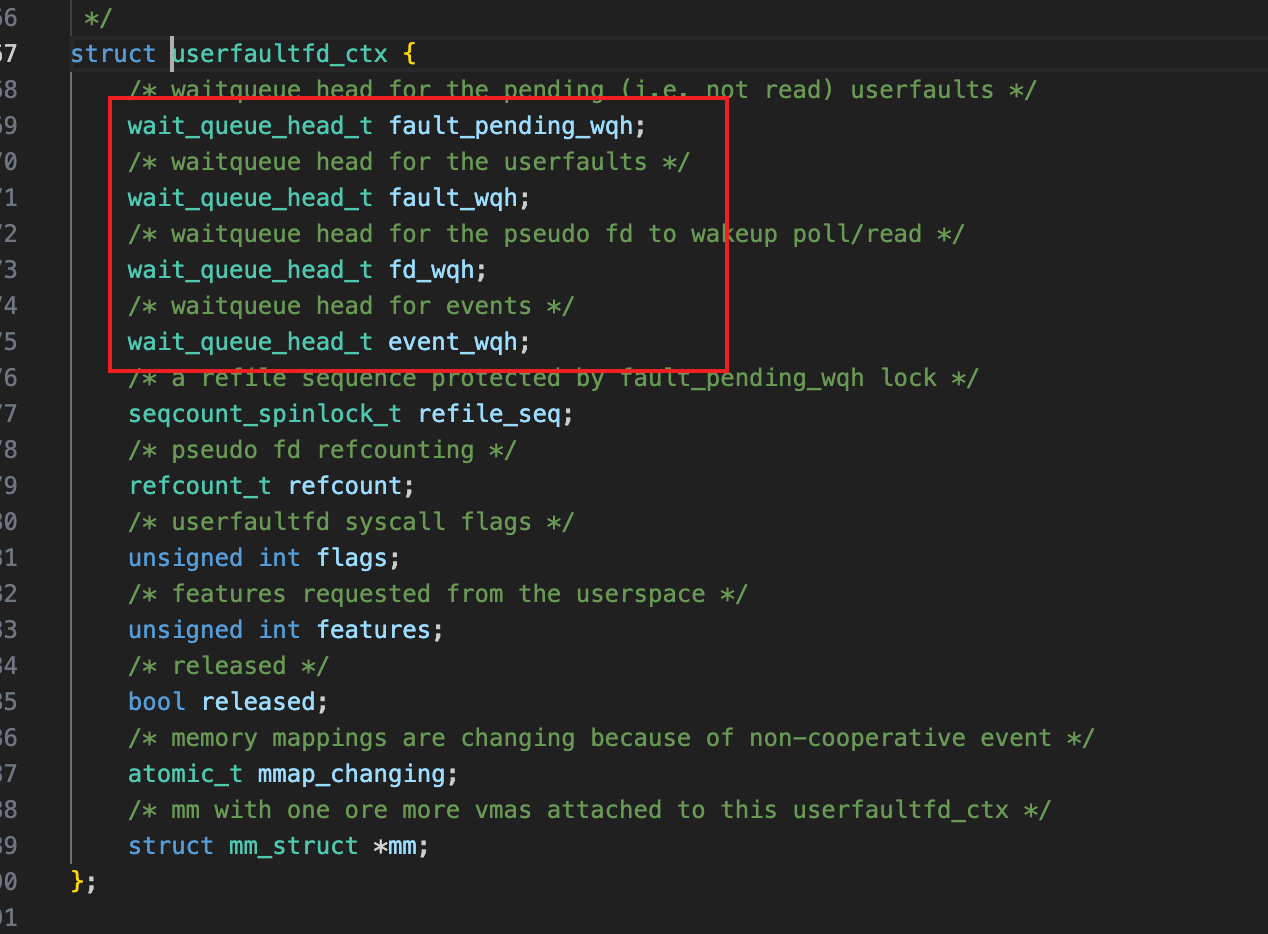
先看一下uffd ctx里的这几个工作队列情况
需要找到ctx地址
vm_fault->vm_area_struct->vm_userfaultfd_ctx,vm_fault结构体是第一个参数传进来的,
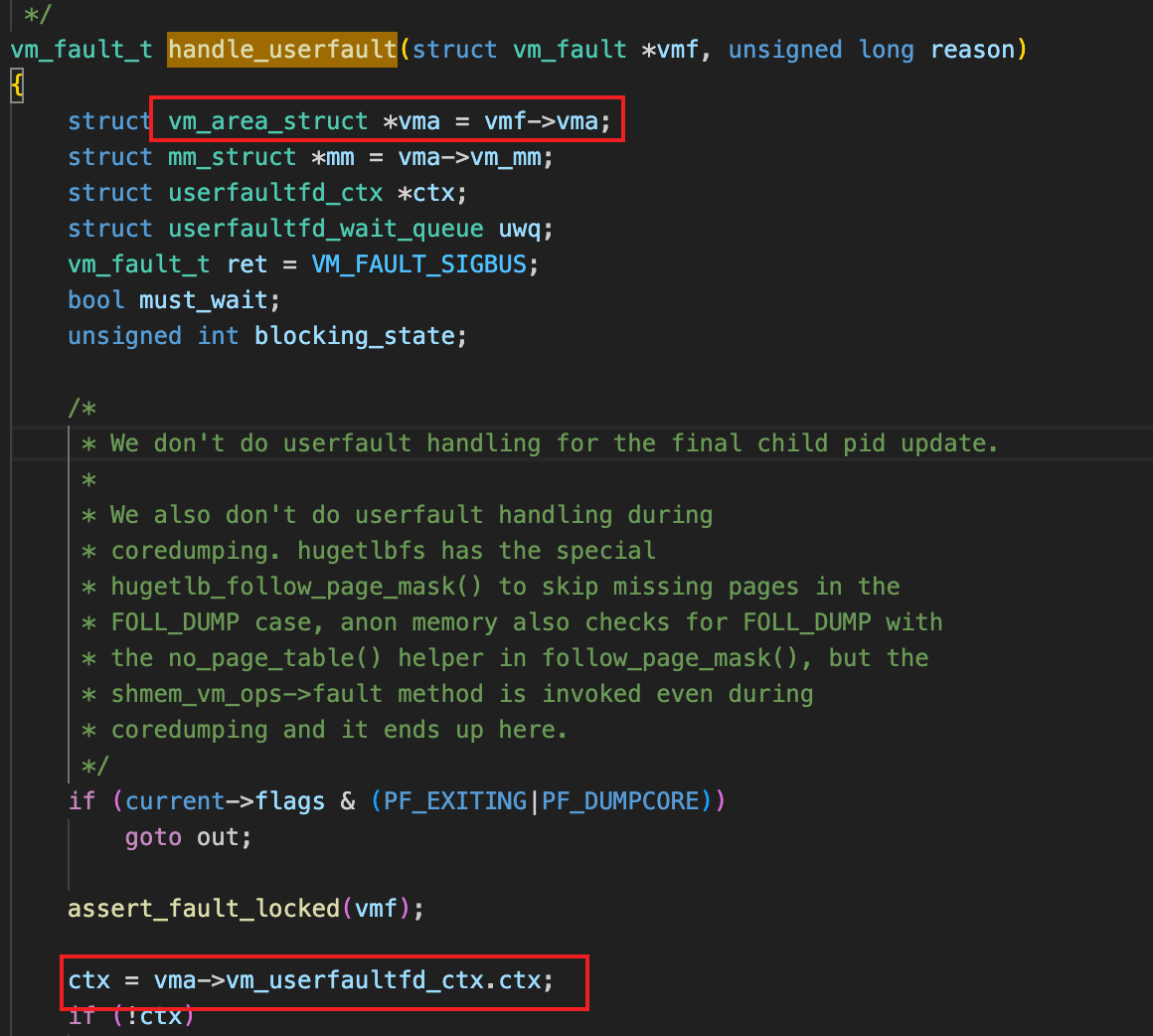
handle_userfault这个函数的汇编比较复杂,往上找找,在上层函数把vmf变量定义在了栈里,
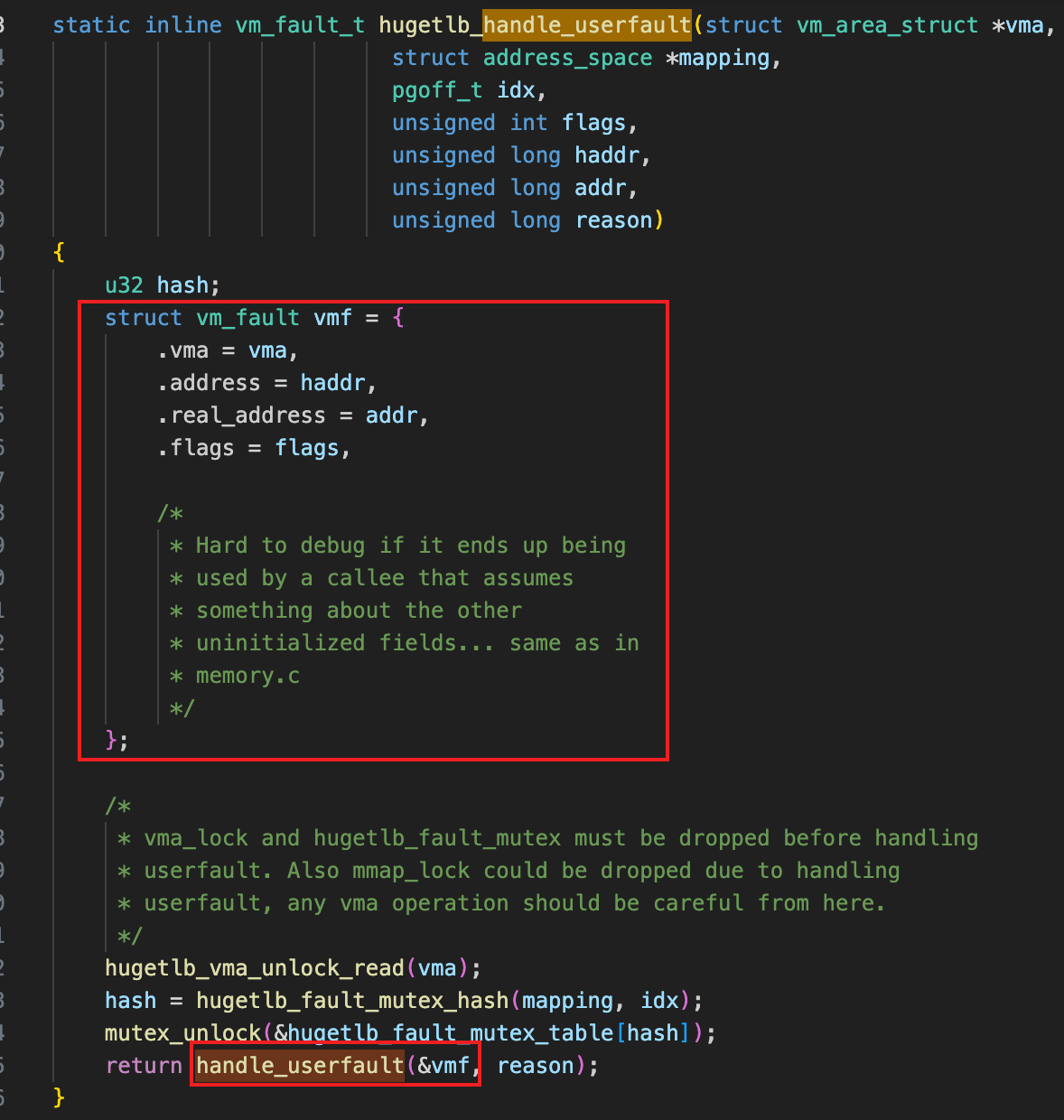
bt -f查看栈帧,hugetlb_handle_userfault帧里的前几个地址看起来像是给结构体赋值的参数,尝试解析一下
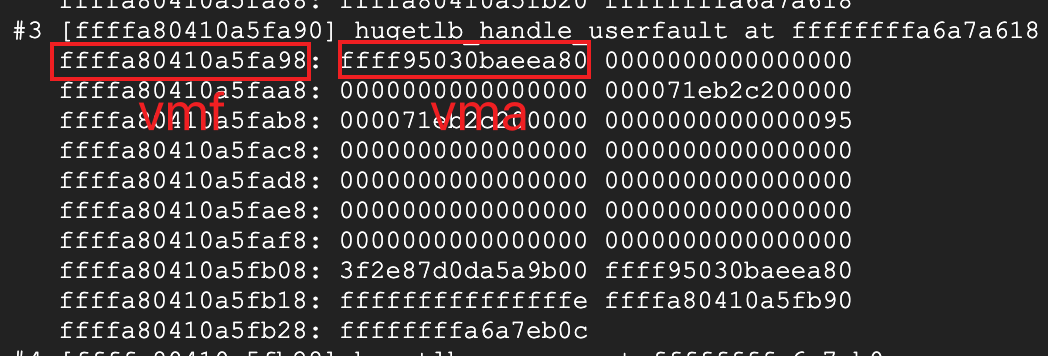
vm_ops解析出了<hugetlb_vm_ops>,看起来没啥问题,那解析下ctx
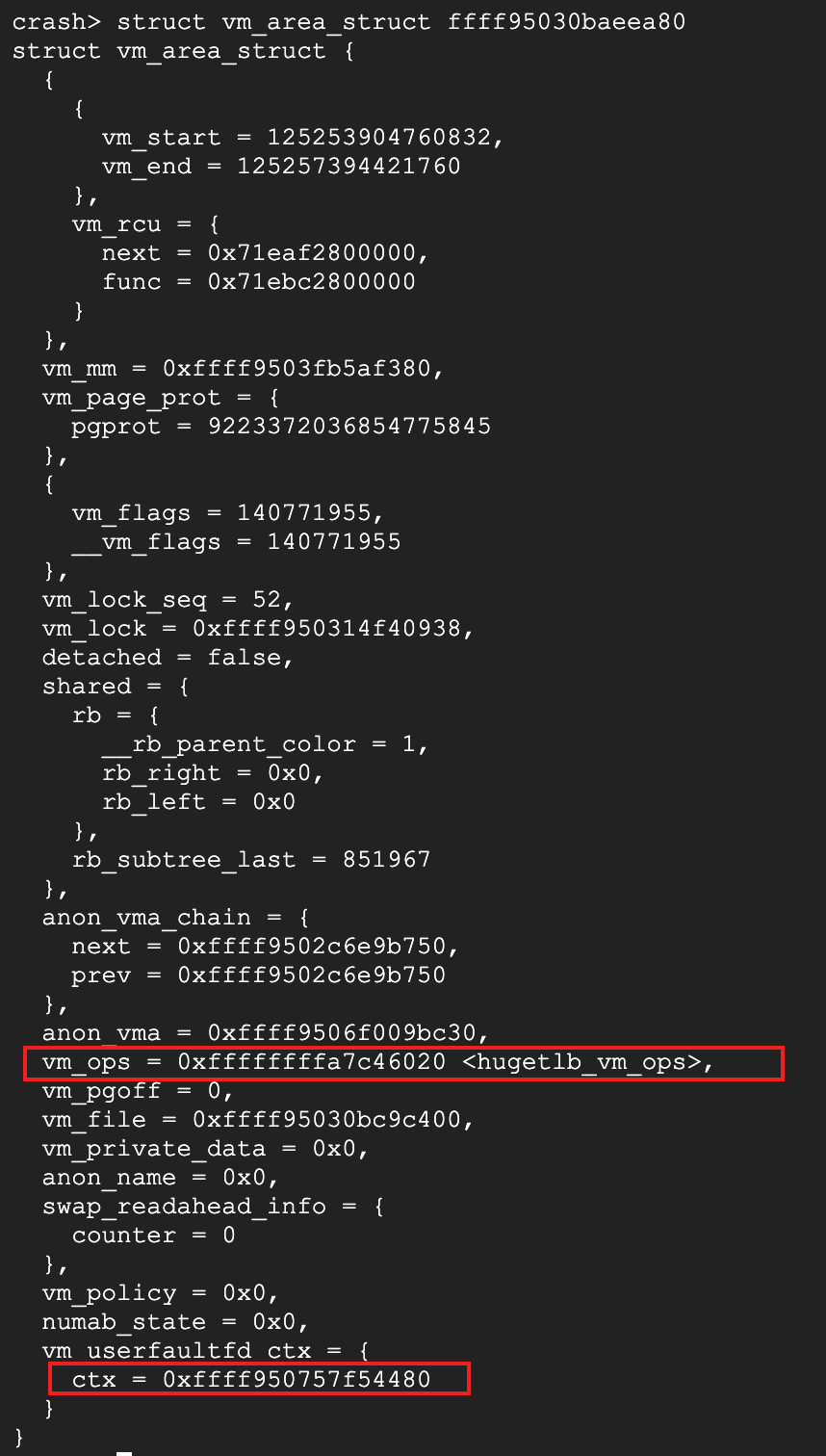
fault_pending_wqh队列的next!=prev,说明有pf请求没有被处理,所以D住了,其他队列的next=prev,都是空的。
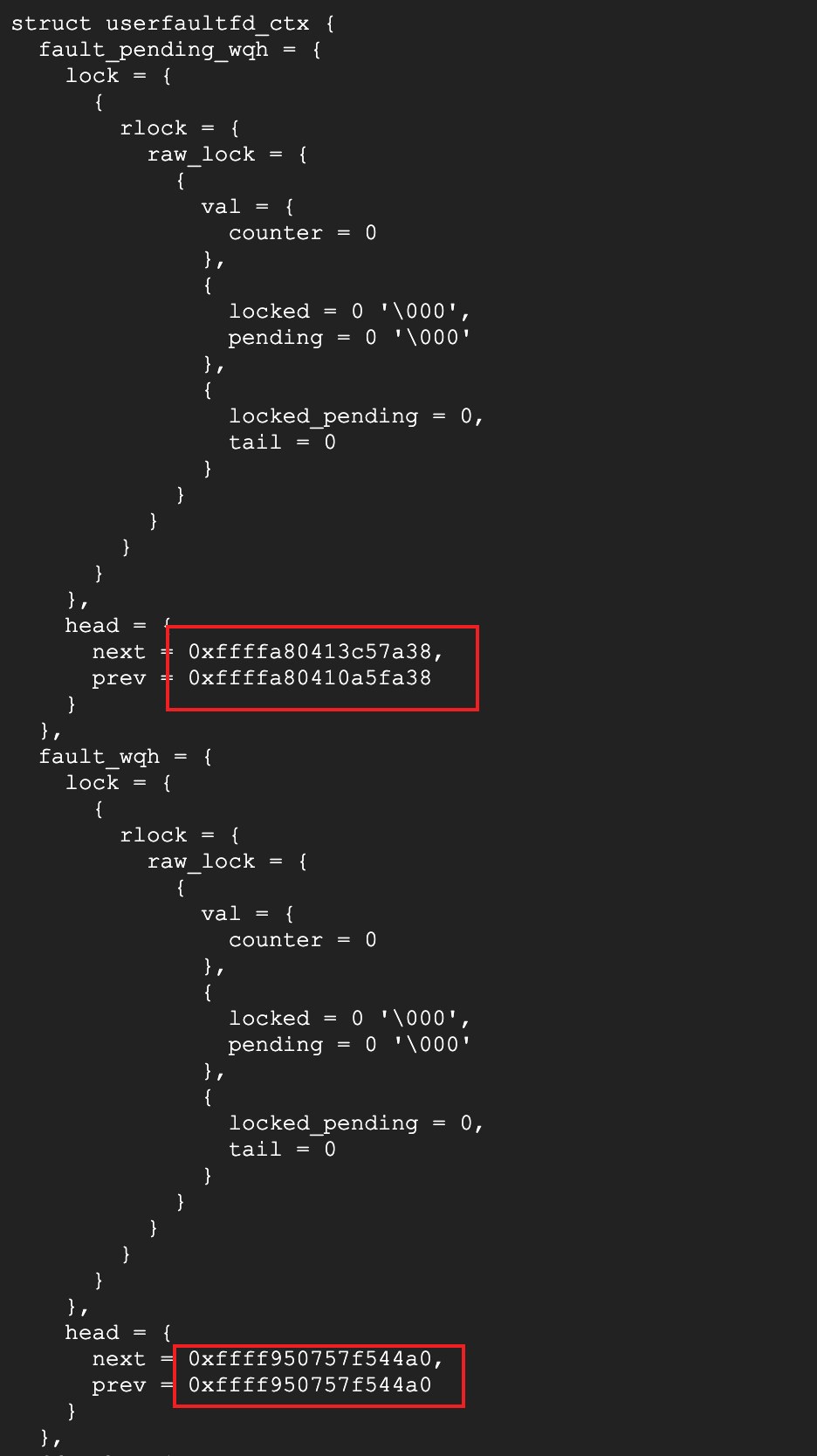
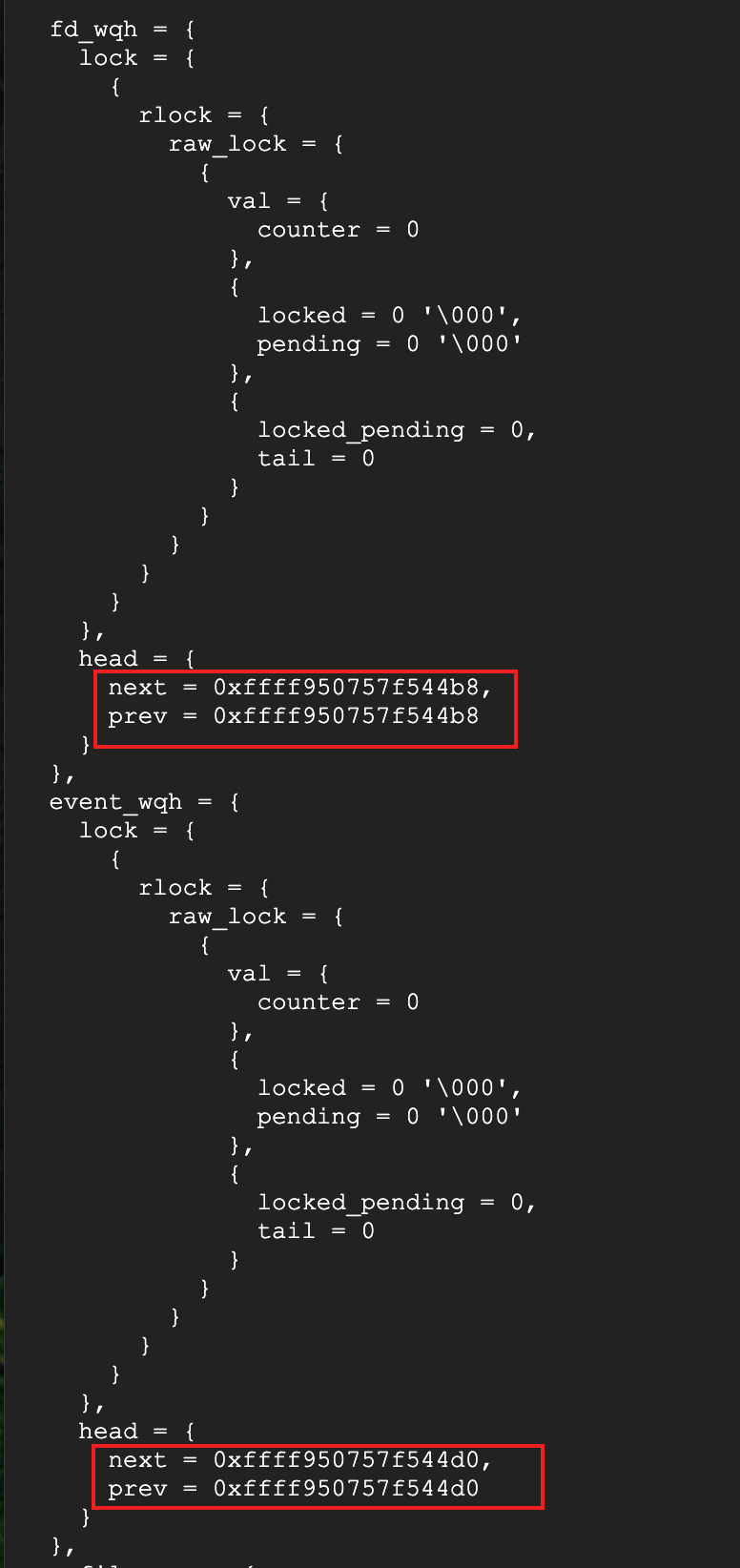
waitq看一下pending队列,结构体的第一个元素,地址就是结构体的地址,可以看到这5个kworker就是对应的pf请求线程,由于没有被处理,导致D住了,那么接下来就要看一下pf请求为什么没有被处理。
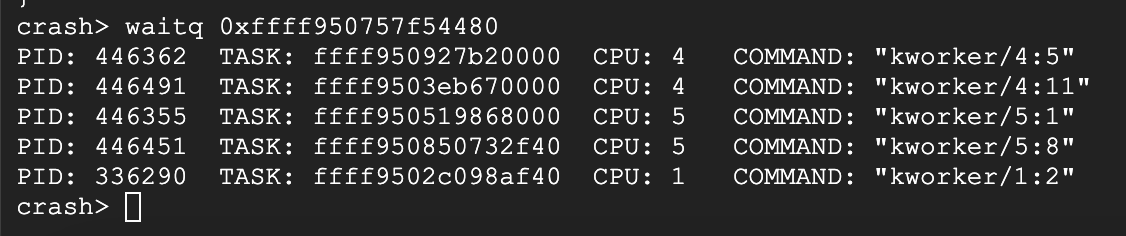
同时也观察到,引用计数为6,但是5个kworker+firecracker+orchestrator应该是7才对,看一下firecracker和orchestrator的状态,由于是pf请求没有被处理,着重排查orchestrator
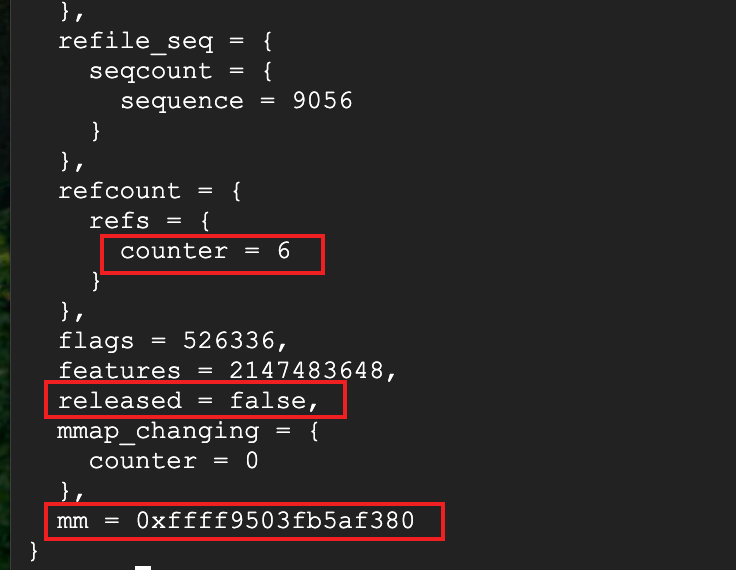
通过mm找到对应的firecracker进程
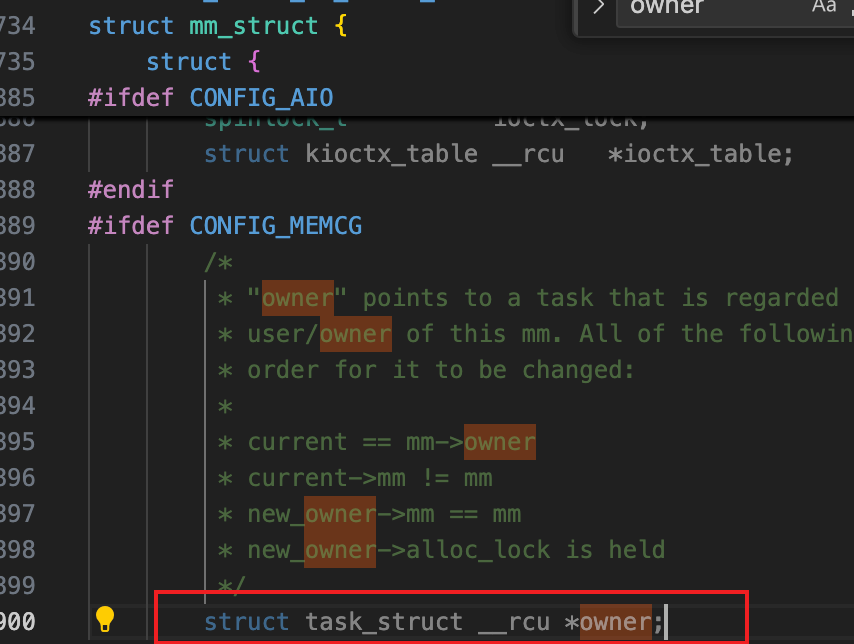
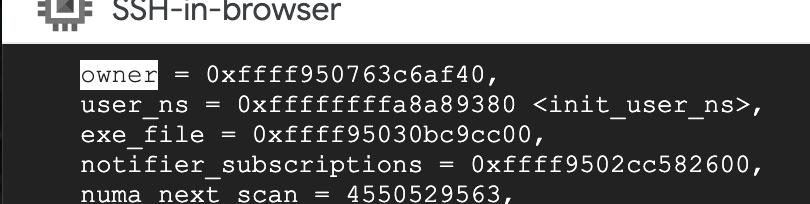
找到task_struct中的pid,就是对应的firecracker进程号

firecracker进程还在,引用计数那就是少了orchestrator的,可能是close了,也可能是orchestrator进程退了

ps一看发现orchestrator服务的启动时间居然在firecracker之后,
而且查看e2b代码发现,orchestrator服务close uffd之前会先kill掉firecracker进程,猜测可能是orchestrator重启了,而且没有走正常的关闭sandbox的流程,导致这些firecracker进程残留了,同时也没法再处理这些firecracker的pagefault请求,导致内核线程进入了D状态。
与运维确认是我们发布了新版本,orchestrator服务确实重启过了,问题确认清楚了,解决办法先完善发布流程,升级重启前先进行排水。