X-R1:训练医疗推理大模型
X-R1:训练医疗推理大模型
- 医疗推理的实现流程
- 数据集
- 推理过程的生成与验证机制
- 格式验证
- 推理步骤奖励(reasoning_steps_reward)
- 答案正确性验证(accuracy_reward)
- 如何保证推理的正确性
- 数据处理
- 奖励函数(核心医疗推理能力的实现)
- 训练流程
- 配置与复现
- 深度诊疗思维链
项目:https://github.com/dhcode-cpp/X-R1
X-R1 是一个基于端到端强化学习(RL)的训练框架,目标是以极低成本提升大模型的推理能力,尤其强调“aha moment”式的推理觉悟。
支持多种规模模型(0.5B/1.5B/3B/7B),可用于数学、医学等多领域推理任务。
X-R1 的医疗推理核心在于:
- 用高质量医疗数据集驱动 RL 训练。
- 用 GPT-4o-mini 作为奖励模型,自动化评估医学答案的语义正确性。
- 通过奖励函数引导模型学会“推理-作答”分离、格式规范和多步推理。
医疗推理的实现流程
数据集
数据集:主要使用 FreedomIntelligence/medical-o1-verifiable-problem 作为医疗推理数据集。
可以在 HuggingFace 上直接搜索该数据集,查看其详细介绍、样本示例和字段定义
数据集:
{"开放式可验证问题": "一名45岁的男性出现胸痛和呼吸急促。最可能的诊断是什么?","标准答案": "急性心肌梗死"
}
推理生成提示词:
SYSTEM_PROMPT = ("用户与助手之间的对话。用户提出一个问题,助手进行解答。助手首先在脑海中进行推理过程,""然后再向用户提供答案。推理过程和答案分别用 <think> </think> 和 <answer> </answer> 标签括起来,""即:<think> 这里是推理过程 </think><answer> 这里是答案 </answer>"
)
医疗思维链:
<think>
Step 1: 分析症状
- 胸痛和呼吸急促是急性心肌梗死的典型症状。
Step 2: 考虑患者年龄和性别
- 45岁男性是心血管疾病的高危人群。
Step 3: 排除其他可能
- 症状与急性心肌梗死最匹配,其他可能性较低。
</think>
<answer>急性心肌梗死</answer>
训练配置文件(如 recipes/examples/medical_zero_3B_config.yaml)中指定了该数据集。
推理过程的生成与验证机制
SYSTEM_PROMPT = ("用户与助手之间的对话。用户提出一个问题,助手进行解答。助手首先在脑海中进行推理过程,""然后再向用户提供答案。推理过程和答案分别用 <think> </think> 和 <answer> </answer> 标签括起来,""即:<think> 这里是推理过程 </think><answer> 这里是答案 </answer>"
)
格式验证
在 src/x_r1/rewards.py 中,format_reward 函数检查模型输出是否符合 …… 的格式
pattern = r"^<think>.*?</think><answer>.*?</answer>$"matches = [re.match(pattern, content) for content in completion_contents]rewards = [1.0 if match else 0.0 for match in matches]# 如果格式不符合,奖励为 0,强制模型遵循格式。
推理步骤奖励(reasoning_steps_reward)
在 src/x_r1/rewards.py 中,reasoning_steps_reward 函数检查推理过程是否包含清晰的步骤标记(如“Step 1:”、“1.”、“-”、“”等):
def reasoning_steps_reward(completions, **kwargs):"""Reward function that checks for clear step-by-step reasoning."""pattern = r"(Step \d+:|^\d+\.|\n-|\n\*|First,|Second,|Next,|Finally,)"completion_contents = [completion[0]["content"] for completion in completions]matches = [len(re.findall(pattern, content)) for content in completion_contents]rewards = [min(1.0, count / 3) for count in matches]return rewards
如果推理步骤少于 3 步,奖励会按比例降低,鼓励模型生成更详细的推理过程。
答案正确性验证(accuracy_reward)
在 src/x_r1/rewards.py 中,accuracy_reward 函数检查最终答案( 部分)是否与标准答案一致:
# 对于医学文本答案,提取 <answer> 标签内容,用 GPT-4o-mini 评估语义一致性answer_content = extract_answer(content)reward = evaluate_answer_similarity(normalized_content, normalized_solution)# 如果答案语义一致,奖励为 1.0,否则为 0.0。
如何保证推理的正确性
- 多重奖励机制:模型同时受到格式、推理步骤和答案正确性的奖励约束,只有同时满足这些条件才能获得高奖励。
- GPT-4o-mini 作为奖励模型:对于医学答案,项目使用 GPT-4o-mini 作为“医疗答案评估器”,自动比对模型输出和标准答案的语义一致性,确保推理结果符合医学知识。
- 强化学习训练:通过 RL 训练,模型会逐渐学会生成符合格式、步骤清晰且答案正确的推理过程。训练过程中,模型会不断调整策略,最大化奖励。
<think>
Step 1: 分析症状
- 胸痛和呼吸急促是急性心肌梗死的典型症状。
Step 2: 考虑患者年龄和性别
- 45岁男性是心血管疾病的高危人群。
Step 3: 排除其他可能
- 症状与急性心肌梗死最匹配,其他可能性较低。
</think>
<answer>急性心肌梗死</answer>
格式验证:检查是否包含 和 标签。
推理步骤奖励:检查是否包含“Step 1:”、“-”等步骤标记。
答案正确性验证:用 GPT-4o-mini 比对“急性心肌梗死”与标准答案的语义一致性。
数据处理
在 src/x_r1/grpo.py 中,针对医疗数据集做了字段重命名适配:Apply to X_R1_zero_0d…
if script_args.dataset_name == "FreedomIntelligence/medical-o1-verifiable-problem":dataset = dataset.rename_columns({"Open-ended Verifiable Question": "problem","Ground-True Answer": "solution"})
每个样本会被格式化为对话形式,系统提示要求模型先推理再给答案,分别用 和 标签包裹。
奖励函数(核心医疗推理能力的实现)
主要在 src/x_r1/rewards.py 实现。
医学答案评估:采用 GPT-4o-mini 作为“医疗答案评估器”,对模型输出和标准答案进行语义比对,只输出 1.0(语义一致)或 0.0(不一致),保证评测的客观性和自动化。
Apply to X_R1_zero_0d…
def evaluate_answer_similarity(answer, solution):# ... 省略 ...response = client.chat.completions.create(model="gpt-4o-mini",messages=[{"role": "system", "content": "You are a medical answer evaluator. ..."},{"role": "user", "content": f"Student answer: {answer}\nCorrect solution: {solution}\nOutput only 1.0 or 0.0:"}],temperature=0)# ... 省略 ...
奖励流程:如果是医学文本答案,先提取 标签内容,再用上述方法评估;如果是数学题则用 latex 解析和比对。
训练流程
通过 src/x_r1/grpo.py 的主流程,加载数据集、格式化样本、注册奖励函数、初始化模型和训练器(XGRPOTrainer),然后执行 RL 训练。
奖励函数可配置,医疗推理任务通常会用 accuracy(准确性)、format(格式)、reasoning_steps(推理步骤)等多重奖励。
配置与复现
训练配置文件(如 recipes/examples/medical_zero_3B_config.yaml)详细指定了模型、数据集、训练参数和奖励函数。
只需一条命令即可复现训练流程,适合快速实验和迁移到其他医疗推理数据集。
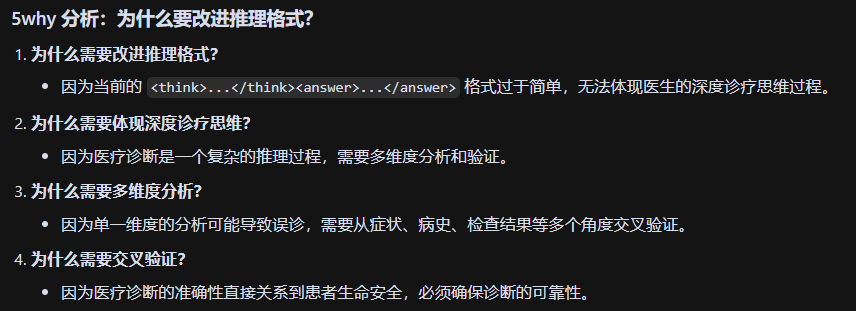
深度诊疗思维链