英伟达微调qwen2.5-32B模型,开源推理模型:OpenCodeReasoning-Nemotron-32B
一、模型概述
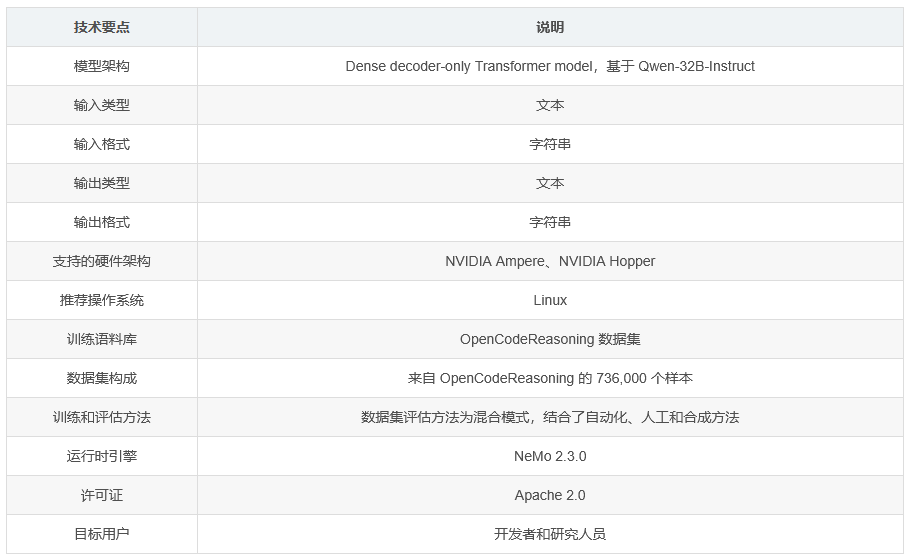
OpenCodeReasoning-Nemotron-32B 是一个大型语言模型,基于 Qwen2.5-32B-Instruct 开发,专为代码生成推理任务进行了后续训练,支持 32,768 个标记的上下文长度,适用于商业和非商业用途。
二、性能表现
在 LiveCodeBench 和 CodeContest 等基准测试中的表现如下表:
| 模型 | LiveCodeBench 平均值 | CodeContest 全部 |
|---|---|---|
| DeepSeek-R1 | 65.6 | 26.2 |
| QwQ-32B | 61.3 | 20.2 |
| Bespoke-Stratos-7B | 14.7 | 2.0 |
| OpenThinker-7B | 25.5 | 5.0 |
| R1-Distill-Qwen-7B | 38.0 | 11.1 |
| OlympicCoder-7B | 40.9 | 10.6 |
| OCR-Qwen-7B | 48.5 | 16.3 |
| OCR-Qwen-7B-Instruct | 51.3 | 18.1 |
| R1-Distill-Qwen-14B | 51.3 | 17.6 |
| OCR-Qwen-14B | 57.7 | 22.6 |
| OCR-Qwen-14B-Instruct | 59.4 | 23.6 |
| Bespoke-Stratos-32B | 30.1 | 6.3 |
| OpenThinker-32B | 54.1 | 16.4 |
| R1-Distill-Qwen-32B | 58.1 | 18.3 |
| OlympicCoder-32B | 57.4 | 18.0 |
| OCR-Qwen-32B | 61.8 | 24.6 |
| OCR-Qwen-32B-Instruct | 61.7 | 24.4 |
三、使用方法
- 导入必要的库:
import transformers
import torch
- 创建文本生成管道:
model_id = "nvidia/OpenCodeReasoning-Nemotron-32B"
pipeline = transformers.pipeline("text-generation",model=model_id,model_kwargs={"torch_dtype": torch.bfloat16},device_map="auto",
)
- 定义提示信息:
prompt = """You are a helpful and harmless assistant. You should think step-by-step before
Please use python programming language only.
You must use ```python for just the final solution code block with the following format: ```python # Your code here ```
{user} """
- 生成消息并获取输出:
messages = [{"role": "user", "content": prompt.format(user="Write a program to calculate the sum of the first $"}]
outputs = pipeline(messages, max_new_tokens=32768)
print(outputs[0]["generated_text"][-1]['content'])
四、数据集和评估
训练语料库是 OpenCodeReasoning 数据集,包含来自 OpenCodeReasoning 的 736,000 个样本,包括编程竞赛问题和 DeepSeek-R1 生成的响应。数据收集和标记方法为混合模式,结合了自动化、人工和合成方法。
五、核心优势
-
推理与代码生成:专为代码生成推理任务进行了后续训练。
-
长上下文支持:支持 32,768 个标记的上下文长度。
-
硬件优化:专为 NVIDIA GPU 加速系统设计,利用 NVIDIA 硬件和软件框架实现更快的训练和推理时间。
-
适应性:适用于开发者和研究人员构建大型语言模型。
六、原文链接
论文原文可在 arXiv 上找到。
七、核心技术汇总