python-Pandas库详细教程
python-Pandas库详细教程1
- 定义
- 使用方法:
- 一、导入Pandas库
- 代码
- 二、DataFrame用法
- Pandas索引
- groupby()
- 数值计算
定义
python中特定用于数据分析、处理的模板库。
优点: 处理数据便捷、简单。
使用方法:
处理“.csv”数据:read_csv()
DataFrame:与SQL数据库相似,是二维表格,每列表可以是不用的数据类型(如数值、字符串、日期等), 并且具有列名和行索引。 DataFrame是Pandas库中核心数据结构,含有
一、导入Pandas库
如果电脑中的环境变量安装python,就在命令指令中“win+R+cmd”,写入以下pip内容。如果pycham环境中还是无法使用,就在pycham终端复制以下命令行。
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
代码
import Pandas as pd
二、DataFrame用法
- 基本操作
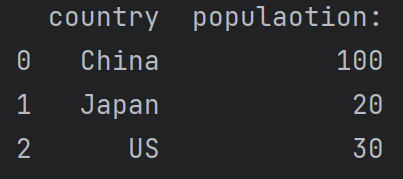
data = {'country':['China','Japan','US'],'populaotion:':[100,20,30]}
df1 = pd.DataFrame(data)
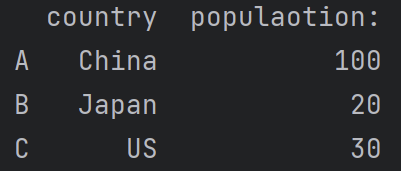
df1 = pd.DataFrame(data,index =['A','B','C'])
print(df1)
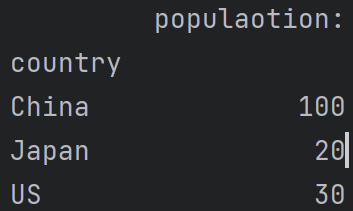
print(df1.set_index('country'))
print(df1.head(2))
print(df1.columns)
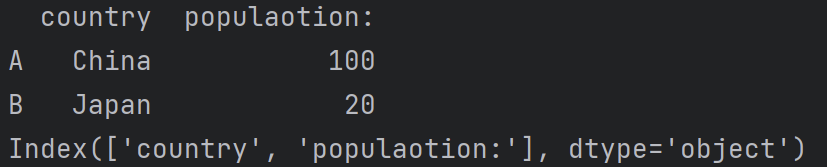
Pandas索引
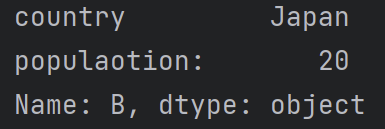
loc():标签定位索引
print(df1.loc['B'])
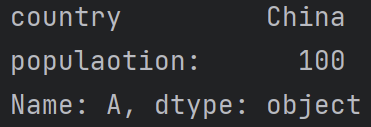
iloc():值定位索引
print(df1.iloc[0])
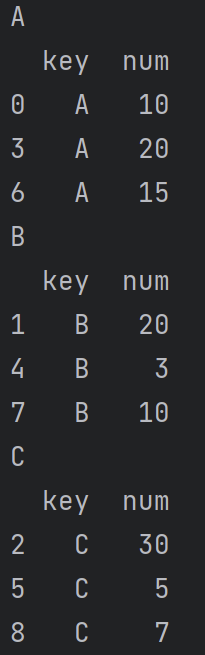
groupby()
针对相同的数据进行组索引访问。
df2 = pd.DataFrame({'key':['A','B','C','A','B','C','A','B','C'],'num':[10,20,30,20,3,5,15,10,7]})
for key in['A','B','C']:print(key)print(df2[df2['key'] == key])
print(df2.groupby('key')['num'].mean())
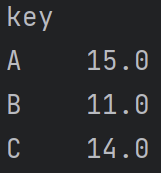
数值计算
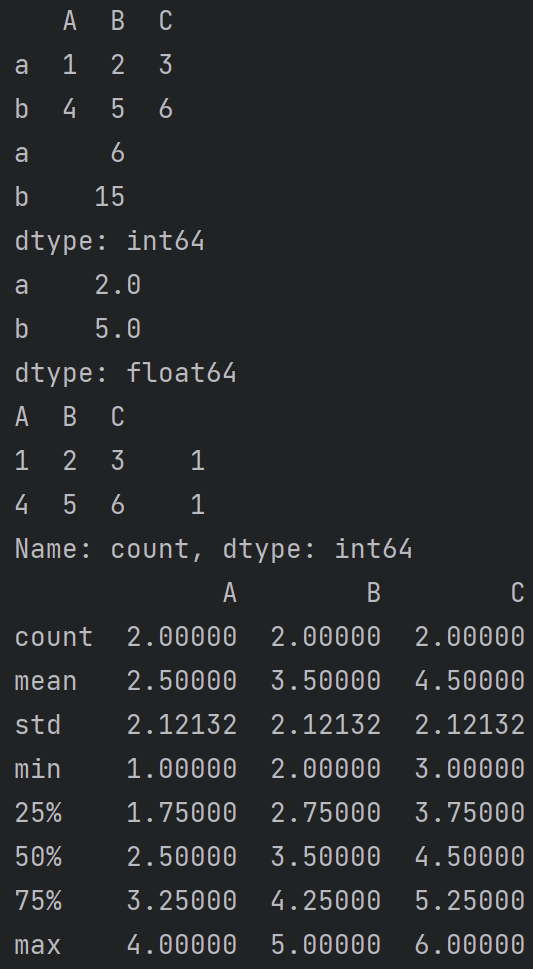
df3 = pd.DataFrame([[1,2,3],[4,5,6]],index = ['a','b'],columns=['A','B','C'])
print(df3)
#axis=0:列总和。axis=1:行总和
print(df3.sum(axis=1))
print(df3.mean(axis=1))
print(df3.value_counts())
print(df3.describe())