Ai学习之LLM
一、什么是LLM(Large Language Model)
可以把LLM当作一个知识特别渊博的大博士,他经过海量文本数据的训练,这些文本就像是给它 “喂” 的知识,他脑子里有超级多的神经元(参数),因此他学富五车,你可以通过他帮你写作,解答问题,文本翻译等。
但是他和普通人一样,也会一本正经的胡说八道(幻觉),但是绝大多数场景他都可以帮你解决,是你工作中生活中必不可少的工具。
他有四个知:
| 知识丰富 | 拥有海量的知识,可以回答各种类型的问题,涉及的领域也非常广泛,包括历史、文化、科学、技术等诸多方面。 |
| 知人晓事 | 能够根据上下文理解人们的意图和兴趣,提供个性化的回答和解决方案。它会基于聊天的过程中了解到的用户信息做出最为切合的回应。 |
| 知错就改 | 能在对话中不断学习和改进。如果用户指出它的某个回答存在问题,它会承认错误,并学习从中改进,在将来的对话中避免类似错误。 |
| 知法守法 | 会遵守道德和法律规范,不会作出危险、不道德或违法的回应,也不会对危险问题给予回应。这样既确保了用户交互的合法性和安全性,也确保了自己不会被利用去破坏社会秩序 |
这样的人不止一个,每家大公司都有自己的大博士。(DeepSeek,ChatGPT,通义千问…)
因此不同的大博士遵循的规则都有所区别。毕竟GPT都可以搞擦边了。
而从技术视角考虑,其基本的实现原理就是通过一定的逻辑方式进而预测选择下一个词(token),例如我们平时玩的选词填空。
例如: 天马()、一劳永()、每天早上我都要()
但是大博士每次能 “记住” 和处理的文本量是有限的(上下文窗口),超过一定量的 token 后,前面的就记不住了。
当你想让大博士说话不要太正经的时候,可以把他的神经元活跃度提高(温度),这样他说话就比较奇特,例如你让他形容一只猫,温度较低时,他会说猫有着柔软的毛发,喜欢在地上跑来跑去,但是温度较高的时候,他可能会说猫有着像彩虹一样绚烂的毛发,能像鸟儿一样在空中飞翔。
对大博士来说,他的语言是由 token 组成的,token可能是一个成语、一个单词、一个短句等。但是我们的自然语言一般都是一串字符串(一段话),那么字符串是怎么转成 token的呢。
大博士使用的是 One-Hot编码 进行token的存储:
它将分类变量转换为二进制向量,向量的长度等于分类变量的类别数量。在向量中,对应变量所在类别的位置设为 1,其余位置设为 0。例如,对于 “颜色” 这一分类变量,有红、绿、蓝三种颜色,那么 “红色” 用 One - Hot 编码表示就是 [1, 0, 0],“绿色” 为 [0, 1, 0],“蓝色” 为 [0, 0, 1]。
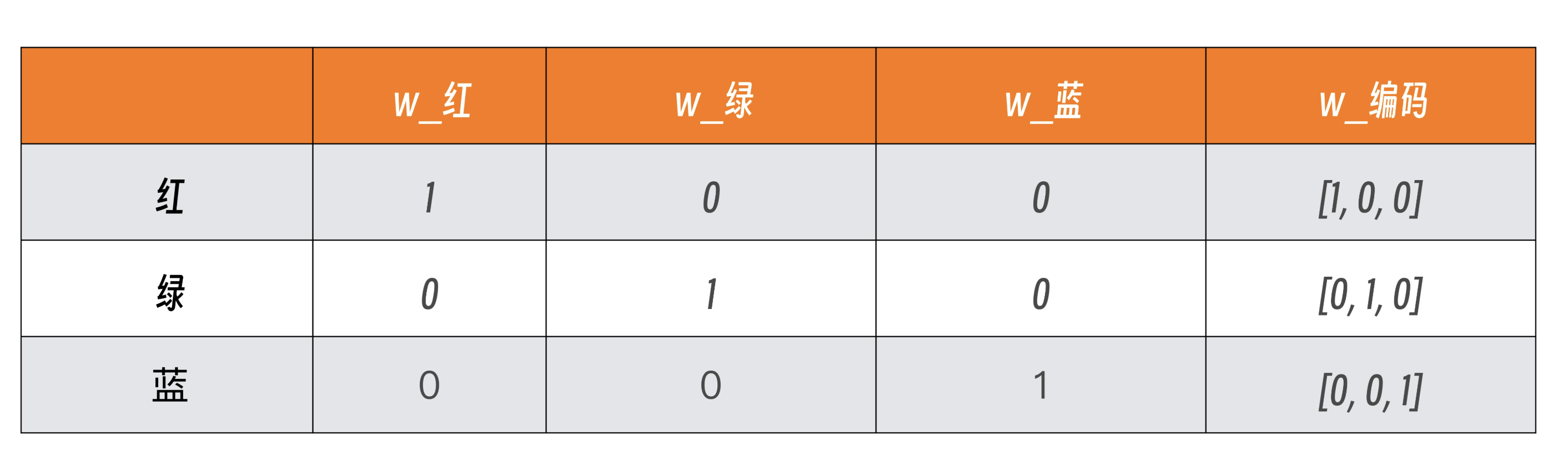
本质上就是通过二进制的方式存储数据。其实和计算机的原理是一样的。
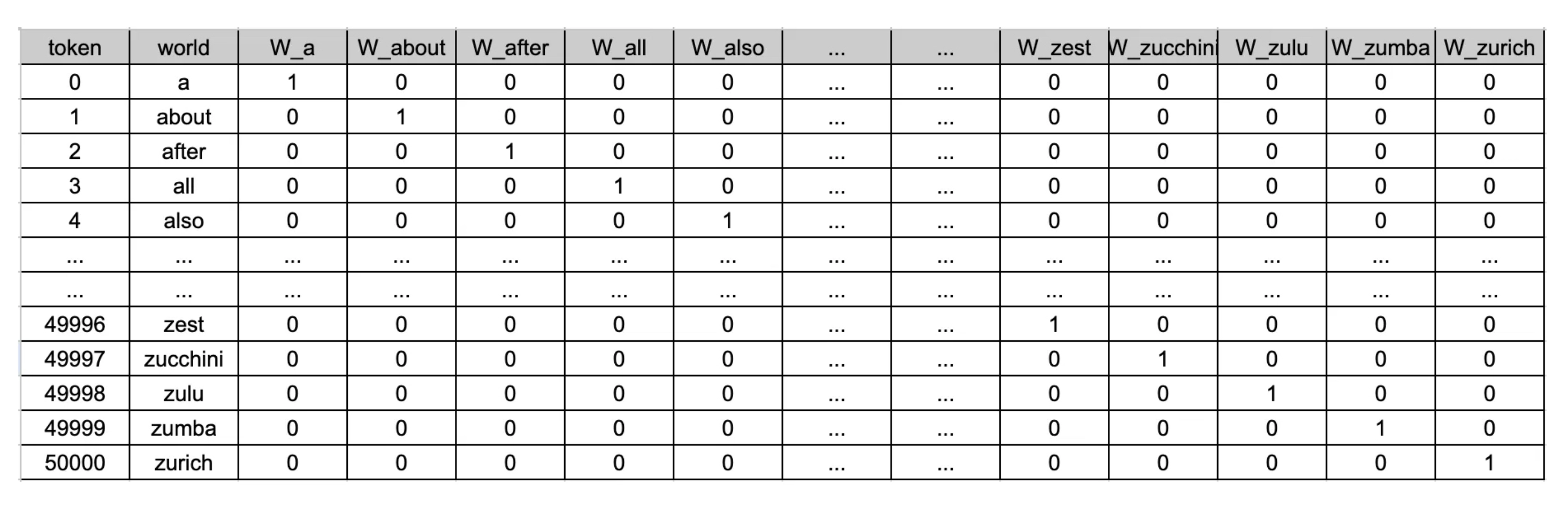
获得了二进制数据之后,通常使用把 Embedding 训练成神经网络的方法,也就是把我们前一步得到的向量送给一个神经网络,得到最终的压缩过的向量。很复杂,可以自行了解:Inside GPT – I : Understanding the text generation
二、如何正确和LLM沟通
1、用好GPT
定义任务目标
一个明确的、清晰的目标可以使GPT更好的蕾姐用户的意图,帮助用户生成更加符要求的内容
给GPT下达命令(提示词)
提示词公式:提示词=定义角色+背景信息+任务目标+输出要求
定义角色:为GPT赋予特定的角色,让其从特定的角度进行思考和回答
背景信息:为GPT提供与任务相关的背景知识,包括但不限于相关概念、事件、人物等
任务目标和输出要求:可以告诉GPT用什么样的方式完成任务,比如格式上是纯文字还是要有表格
根据生成的结果进行调整
与GPT的连续对话可以让我们更好地理解问题,更加清晰的表达自己的需求
举个栗子(以豆包为例)
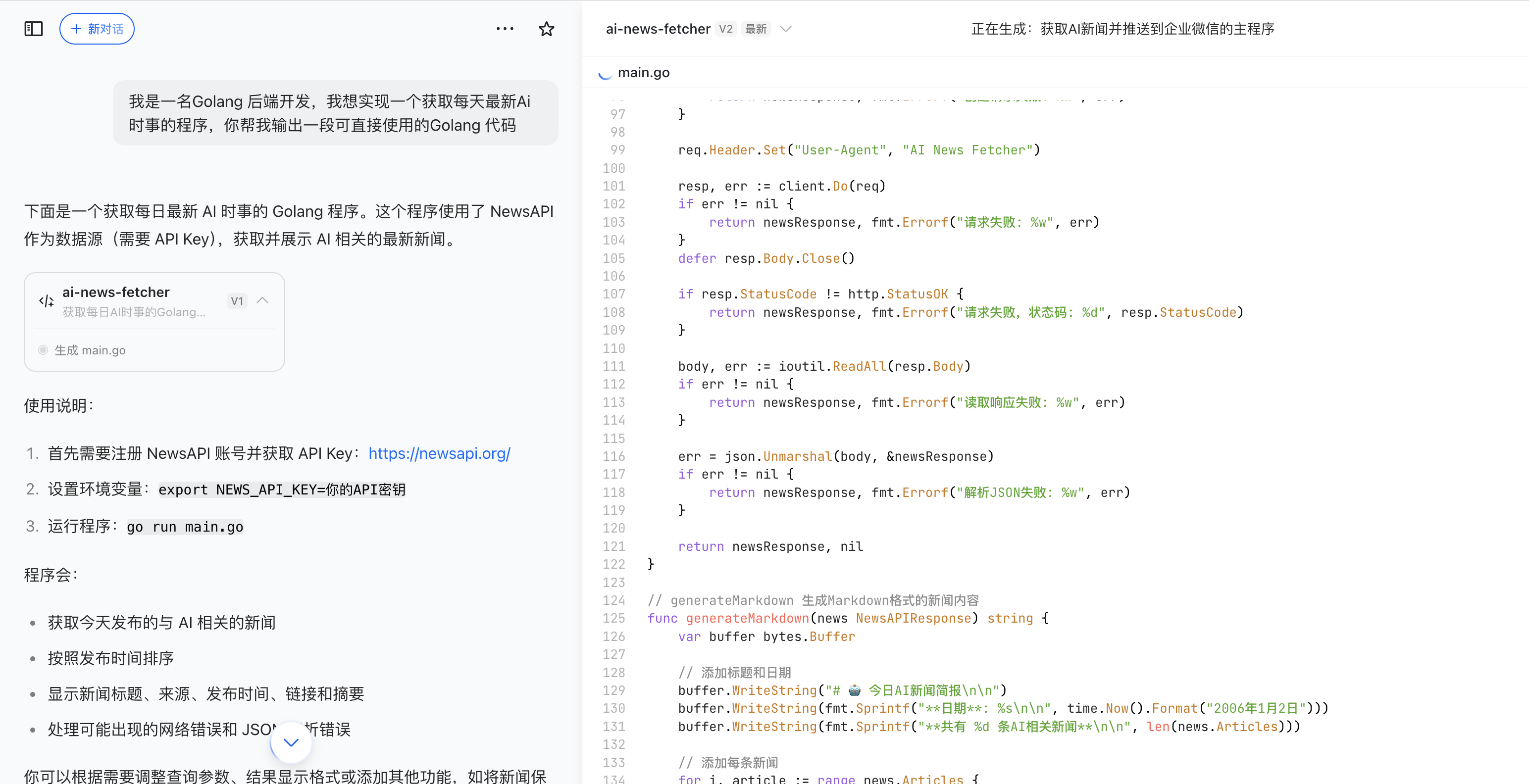
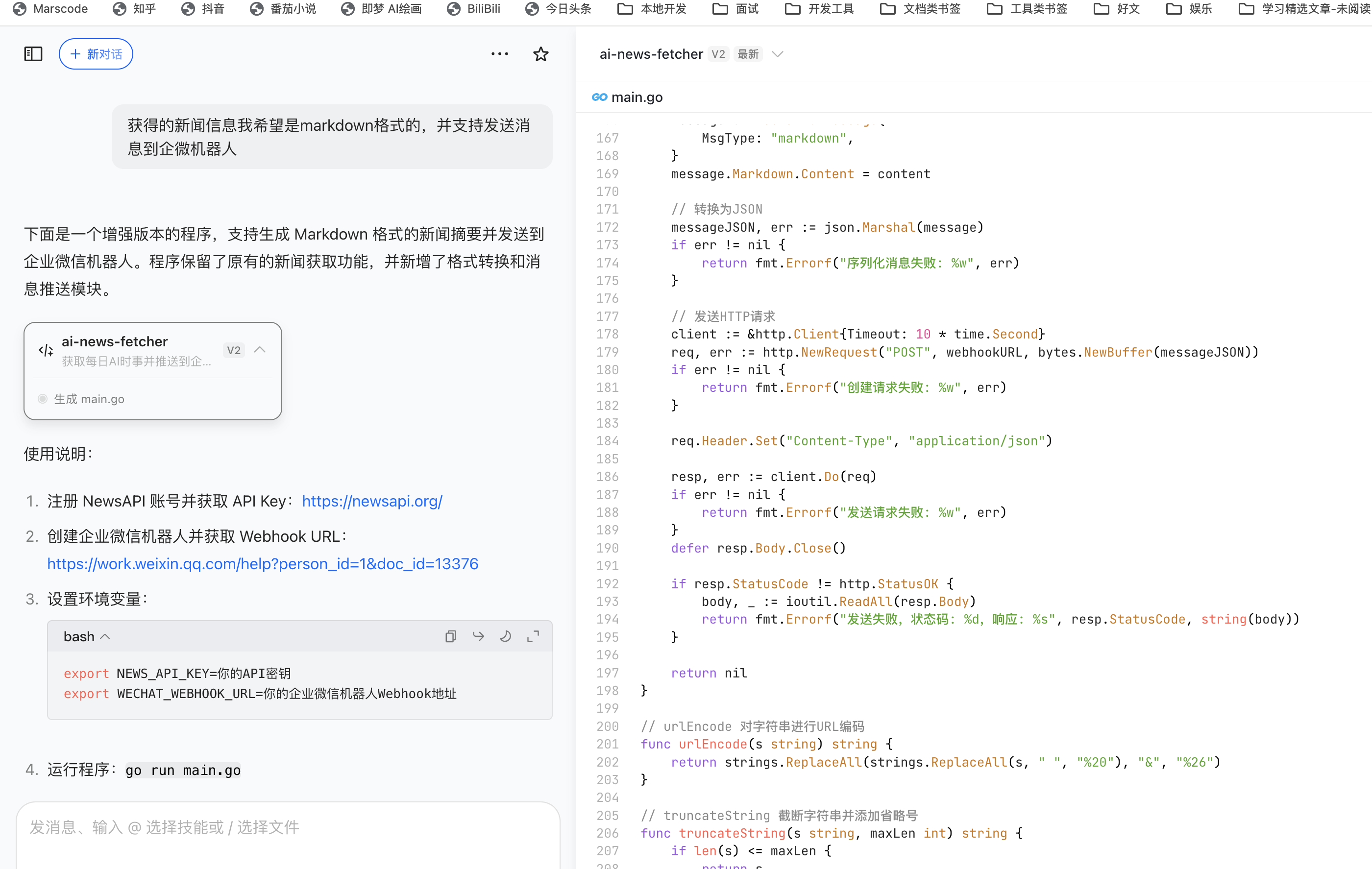
2、提示词工程
提示词工程(Prompt Engineering)是一门新兴的技术,主要涉及到如何设计和优化提示词,以引导人工智能模型(如大型语言模型)生成更符合预期的输出。
打个比方,你就把人工智能想象成一个很聪明但有点 “死板” 的助手。它需要你告诉它具体要做什么、怎么做,而这个 “告诉” 的过程就是通过提示词来实现的。比如你想让它写一个故事,你直接说 “写个故事”,它可能写得比较普通。但如果你说 “写一个科幻故事,主角是一个勇敢的太空探险家,在探索神秘星球时遇到了奇怪的生物”,它就会根据你这个更详细的提示,写出更符合你想法的故事。
其相关的技术有:
零样本提示 (Zero-Shot Prompting)
定义:
直接向模型提出任务,不提供任何示例或上下文,依赖模型自身的泛化能力完成任务。
通俗解释:
就像你让一个有经验的助手「帮我写一份会议纪要」,对方能直接完成,不需要你额外说明格式或内容细节。
技术要点:
- 提示词结构:通常是一个清晰的指令,如「总结以下文章的核心观点」或「将这段文本翻译成法语」。
- 适用场景:简单任务、模型已预训练过的领域(如基础翻译、常识问答)。
- 局限性:复杂任务可能导致不准确或偏离预期的输出。
示例:
{"need_search": false, "keywords": ["零样本提示", "Zero-Shot Prompting"]}
少样本提示 (Few-Shot Prompting)
定义:
在提示中提供少量(通常1-5个)任务示例,引导模型学习模式并应用到新任务中。
通俗解释:
类似教助手写会议纪要时,先给一个示例:「比如上次会议记录是这样写的…现在请按这个格式写新的纪要」。
技术要点:
- 示例设计:选择典型案例,包含输入和期望输出。
- 格式一致性:所有示例和最终任务保持相同格式(如JSON、表格)。
- 适用场景:特定领域任务(如代码生成、结构化数据提取)。
示例:
{"need_search": true, "keywords": ["少样本提示", "Few-Shot Learning", "AI 示例学习"]}
思维链提示 (Chain of Thought, CoT)
定义:
要求模型在生成答案时显式展示推理步骤,类似人类解题时的思考过程。
通俗解释:
不仅要答案,还要模型告诉你「怎么想」的。例如:「为什么选这个方案?请写出推理过程」。
技术要点:
- 提示词触发:添加「请逐步解释」「首先…其次…最后」等引导语。
- 适用场景:复杂推理任务(数学题、逻辑分析、诊断)。
- 效果:显著提升模型的准确率和可解释性。
示例:
{"need_search": true, "keywords": ["思维链提示", "Chain of Thought", "AI 推理过程"]}
ReAct 框架 (Reason + Act)
定义:
将推理(Reasoning)和行动(Action)结合,允许模型在生成答案时调用外部工具(如搜索引擎、数据库)。
通俗解释:
模型不仅能思考,还能「动手」查资料。比如遇到不确定的问题时,它会说「我需要查一下最新数据」,然后调用搜索API获取信息。
技术要点:
- 提示词结构:
{"need_search": true, "keywords": ["ReAct框架", "AI 工具调用", "Reasoning and Acting"]} - 工具设计:封装外部API为模型可调用的函数(如
search("关键词"))。 - 适用场景:需要实时信息或专业知识库的任务(如医疗诊断、金融分析)。
示例:
用户问题:「新冠疫苗的最新研究进展?」
模型输出:
{"need_search": true, "keywords": ["2025年新冠疫苗 新变种 有效性", "mRNA疫苗 奥密克戎"]}
(模型先判断需要搜索,生成关键词,再调用搜索引擎获取最新数据)
对比与应用建议
| 技术 | 适用场景 | 提示词复杂度 | 效果提升 |
|---|---|---|---|
| 零样本 | 简单任务、常识问答 | 低 | 基础可用 |
| 少样本 | 特定格式任务(如JSON生成) | 中 | 显著提升准确性 |
| 思维链 | 复杂推理任务(数学、逻辑) | 中 | 提升准确率+可解释性 |
| ReAct 框架 | 需要外部知识的任务(实时信息) | 高 | 突破模型知识边界 |
开发者实践建议
- 从简单开始:先尝试零样本,再逐步添加示例或思维链。
- 工具集成:对需要实时数据的任务,优先使用ReAct框架(如封装搜索API)。
- 评估指标:针对具体任务,对比不同提示技术的准确率、耗时和资源消耗。
- 组合使用:复杂场景可结合多种技术(如少样本+思维链)。