[Pandas]数据处理
一.Series对象
1.创建一个简单的Series对象
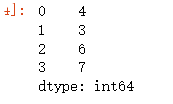
data = pd.Series([4,3,6,7])
输出:0 1 2 3 是默认的索引
2.Series对象的属性
values:本质numpy的数组


index:索引
#指定index
data1 = pd.Series([4,3,6,7,5],index=['星期一','星期二','星期三','星期四','星期五'])
data1
3.使用字典生成
方法一:
#传字典生成对象
exp_dit = {'星期一':4,"星期二":3,"星期三":6}
exp_series = pd.Series(exp_dit)
exp_series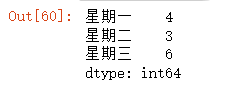
方法二:
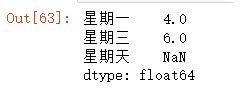
exp_dit = {'星期一':4,"星期二":3,"星期三":6}exp1_series = pd.Series(exp_dit,index=["星期一","星期三","星期天"])
exp1_series此方法如果自己指定索引,如果字典中不存在的索引会显示Nan
小技巧:使用字符串生成列表索引
#1.把'abcd'强转成list形式,['a','b','c','d'] 2.填写一个数,默认是全部为此数
data1 = pd.Series(10,index=list('abcd'))
data1
4.获取Series对象的值
样本:
data = pd.Series([40,45,39],index={"一班","二班","三班"})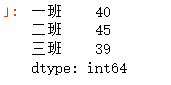
1)获取某行的值
#获取某行值
data["一班"] #40 按照key获取
data[0] #40 按照索引2)获取某个范围,按照key 是[index1,index2] 闭区间,按照索引是[index1,index2)
#获取某个范围,按照key 是[index1,index2] 闭区间
data["一班":"三班"]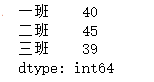
#获取某个范围,按照索引是[index1,index2)
data[0:2] #没有第三行
3.引出情况
样本:
data =pd.Series(['x1','x2','x3'],index=[1,2,3])
假如我们想取到第二行的值,也就是x2,我们使用索引去取的时候,会使用data[1],但是此时,优先使用的key ,会发现data[1] 输出为x1,因为此时的1,是一个key
所以为了防止这种情况,以下方法可以取到第二行的值
说白了就是key=1 和 index=1 有歧义。
data.loc[2] #取key为2
data.iloc[1] #取索引为1此时输出就是x2
二.DataFrame对象
1.使用Series对象生成
#使用series构建
population_dict = {"beijing":300,"chengdu":400,"shanghai":400} #可以看作是一行数据
area_dict = {"beijing":200,"shanghai":500,"chengdu":300} #键值对匹配,不一定要顺序一样
p_s = pd.Series(population_dict)
a_s = pd.Series(area_dict)citys=pd.DataFrame({"population":p_s,"area":a_s}) #可以认为是构建列名
citys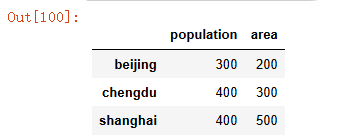
2.使用Series对象列表生成
#法二:
population_dict = {"beijing":300,"chengdu":400,"shanghai":400} #可以看作是一行数据
area_dict = {"beijing":200,"shanghai":500,"chengdu":300} #键值对匹配,不一定要顺序一样
p_s = pd.Series(population_dict)
a_s = pd.Series(area_dict)citys1 = pd.DataFrame([p_s,a_s],index=["population","area"])
citys1 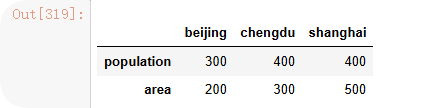
是使用Series对象生成的”转置”
3.使用Numpy数组创建
import numpy as np
data = pd.DataFrame(np.random.randint(0,10,(3,2)),columns=['y1','y2'],index=['x1','x2','x3'])
data
4.获取DataFrame对象
样本:
data = pd.DataFrame(np.random.randint(0,10,(3,2)),columns=['y1','y2'],index=['x1','x2','x3'])
1.获取某一列 #这里要嵌套列表,单个的时候可以使用一层列表
data[['y1']] #获取列名为y1的列 
2.获取两列
data[['y1','y2']] 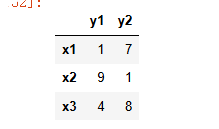
3.根据索引获取第一行第一列的值
data.iloc[0,0] #14.根据key获取第一行第一列的值
data.loc['x1','y1'] #15.根据索引获取第一行的值
#eg:根据索引获取第一行的值
data.iloc[0,:]6.根据key获取第一行的值
data.loc['x1',:]
7.输出整个
data.iloc[:] #key
data.loc[:] #index
三.条件过滤
样本:
name_list=['zhangsan','lisi','wangwu']
sno_list=['1001','1002','1003']
sex_list=['man','woman','man']
age_list=[17,18,19]
score_list=[99,59,100]mydata = pd.DataFrame({"Sno":sno_list,"Sex":sex_list,
"Age":age_list,"Score":score_list},index=name_list)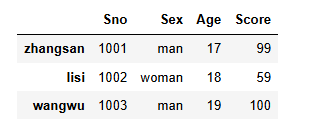
1.数学方法
#获取年龄的平均值,最小值,最大值,样本方差,样本标准差
ages=mydata['Age']
ages.mean(),ages.min(),ages.max(),ages.var(),ages.std()![]()
2. 排序
#排序 ascending = Ture 默认升序
ages.sort_values()
3.过滤
输出Series类型
#筛选出大于60分的数据
scores = mydata['Score']
scores_ok = scores[scores>60]
scores_ok
输出DF类型
#筛选出及格以及年龄大于18岁的
mydata[(mydata['Score']>=60) & (mydata["Age"]>18)]
4.处理缺失值
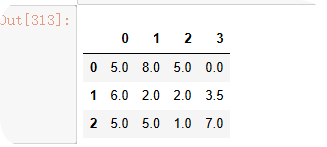
样本:
data = np.random.randint(0,9,size=(3,4)).astype(float)
data[[2,1],[1,3]]=np.nan
data = pd.DataFrame(data)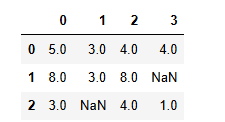
1)得到缺失值信息,info()
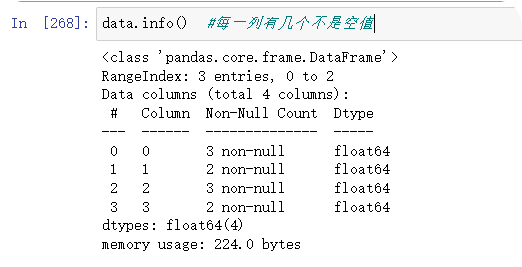
2)data.isnull() 判断是否为空值
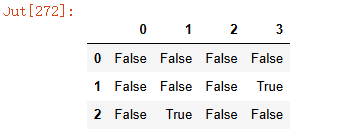
3) data.notnull() 判断不是空值
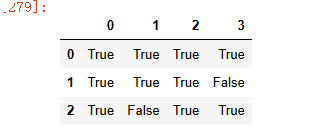
4)删除缺失值dropna()
data.dropna(axis=1) #axis :0为行 1为列 参数how:'all' 全部缺失才删除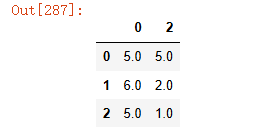
5)填补缺失值 ffill():用上一个 bfill():用下一个填补
#填充缺失值 method参数:ffill 上面一个数填充 当前面或者后面 没值得时候,先用前一个填,再按后一个去填,就一定能填满
data.fillna(method='ffill',axis=0) 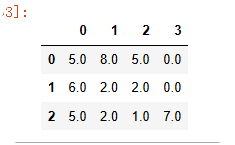
6)用平均值填补
data.fillna(data.mean(axis=0)) #axis 按照行的平均还是按照列的平均