【Java基础】——集合篇
目标:
1.每个集合用的场景
2.每个集合的底层
一.概述

二.
三.Collection
1.通用方法

其中,contains方法,它的底层一定调用了equals方法进行比对,而且一定重写了equals方法,如果不重写equals方法,就是调用的老祖宗的equals方法,比的是对象(存放的地址)而不是值本身。同样remove也调用了equals方法,完成删除。
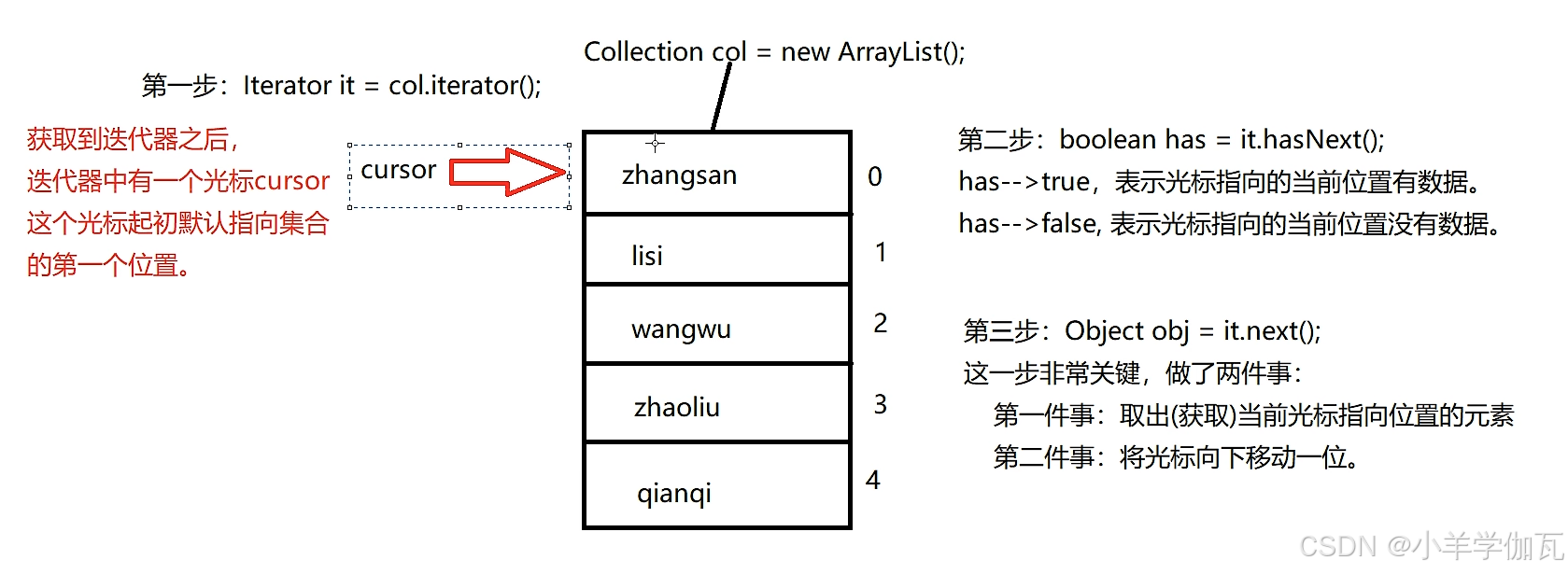
2.Collection的遍历(迭代)(子类型均可以使用)
四.泛型
1.为什么要使用泛型
当前程序先不使用泛型,分析存在什么缺点?
不好看,代码写的比较多。每一次从集合中取出的元素要想访间子类中特有的方法,必须向下转型大部分都是要写向下转型的。因为0bject类中的方法肯定是不够用的。一定会调用子类方法。可是obj类型调不了子类的方法。

2.泛型的擦除与补偿

3.自定义泛型
1.类上定义
直接加在类后面即可
2.接口上定义
与在类上定义相似,加在接口名后面。但

3.方法上定义
格式:修饰符 <代表泛型的变量> 返回值类型 方法名(参数){ }
/**
*
* @param t 传入泛型的参数
* @param <T> 泛型的类型
* @return T 返回值为T类型
* 说明:
* 1)public 与 返回值中间<T>非常重要,可以理解为声明此方法为泛型方法。
* 2)只有声明了<T>的方法才是泛型方法,泛型类中的使用了泛型的成员方法并不是泛型方法。
* 3)<T>表明该方法将使用泛型类型T,此时才可以在方法中使用泛型类型T。
* 4)与泛型类的定义一样,此处T可以随便写为任意标识,常见的如T、E等形式的参数常用于表示泛型。
*/
public <T> T genercMethod(T t){System.out.println(t.getClass());System.out.println(t);return t;
}//定义一个泛型方法,不返回内容
public <T> void print(T t){System.out.println(t);
}//定义一个泛型方法,传入多个泛型
public <T,F> void query(T t,List<F> f){System.out.println(t);
}//传入T, F 返回T
public <T,F> T query1(T t,F f){
}//静态的泛型方法 需要在static后用<>声明泛型类型参数
public static <E> void swap(E[] array, int i, int j) {E t = array[i];array[i] = array[j];array[j] = t;
}
4.泛型的通配符

五.集合的并发问题
1.案例
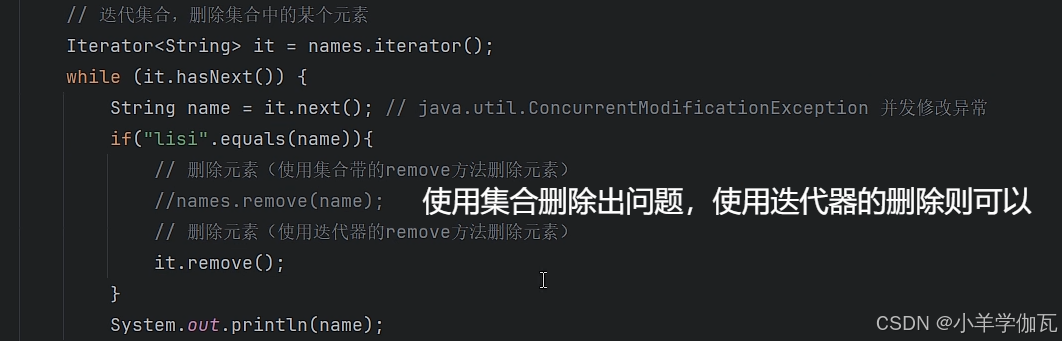
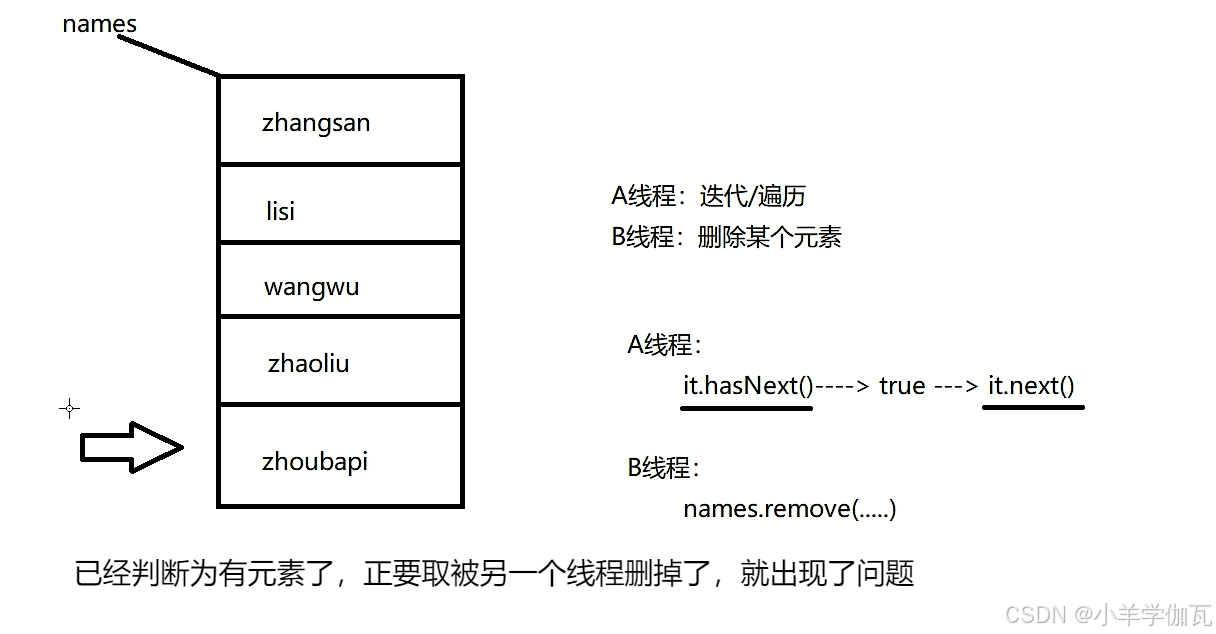
你是使用的迭代器去遍历,但用的另一种方式(集合的方法)去删除,虽然并没有开启多线程去做这件事,但会判定(感觉)你为并发修改异常
2.fail-fast机制

3.fail-safe机制

在fail-safe机制中,遍历的是一个数组,添加元素的是另一个数组。它牺牲了一致性。
六.List集合(有序,可重复)
1.介绍

2.特有的迭代方式

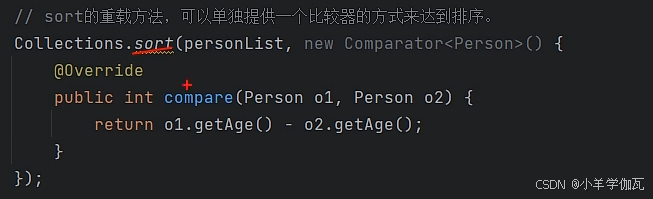
3.使用sort方法排序
1.回顾数组是如何排序的
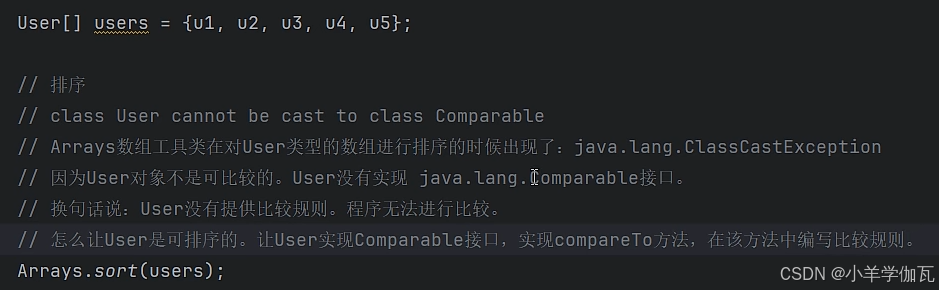
![]()
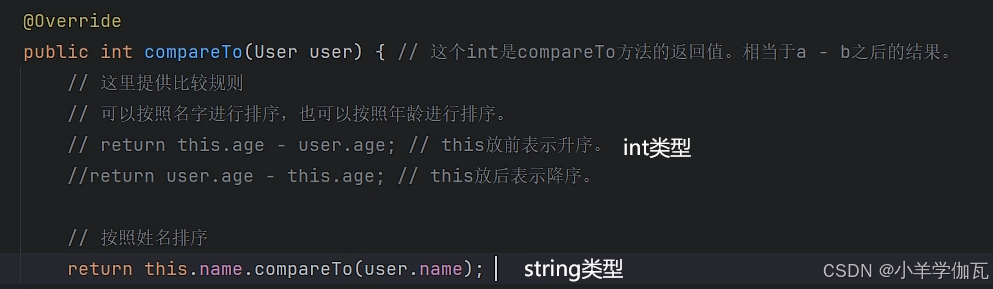
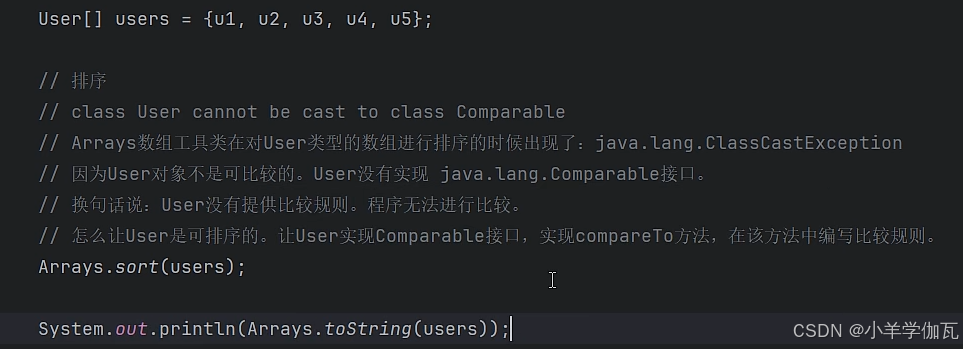
2.List集合中的sort方法
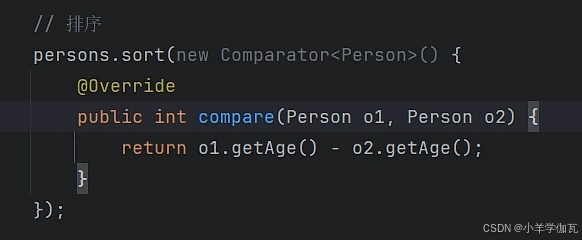
在上面数组中,是写在实体类中的,让想要排序的类去实现了comparable接口,并在该类中规定了比较规则,这种方法有些侵入式的,毕竟修改了类。但list集合中的方法则不同。新建了一个类(当然也可以用匿名内部类的方式更简单,总之就是一个新类)去实现comparator接口
七.***ArrayList****
1.优缺点

重点在于随机的增删,而不是增删数组尾的元素。
2.扩容机制

3.ArrayList与LinkedList对比

八.Map集合
1.继承结构
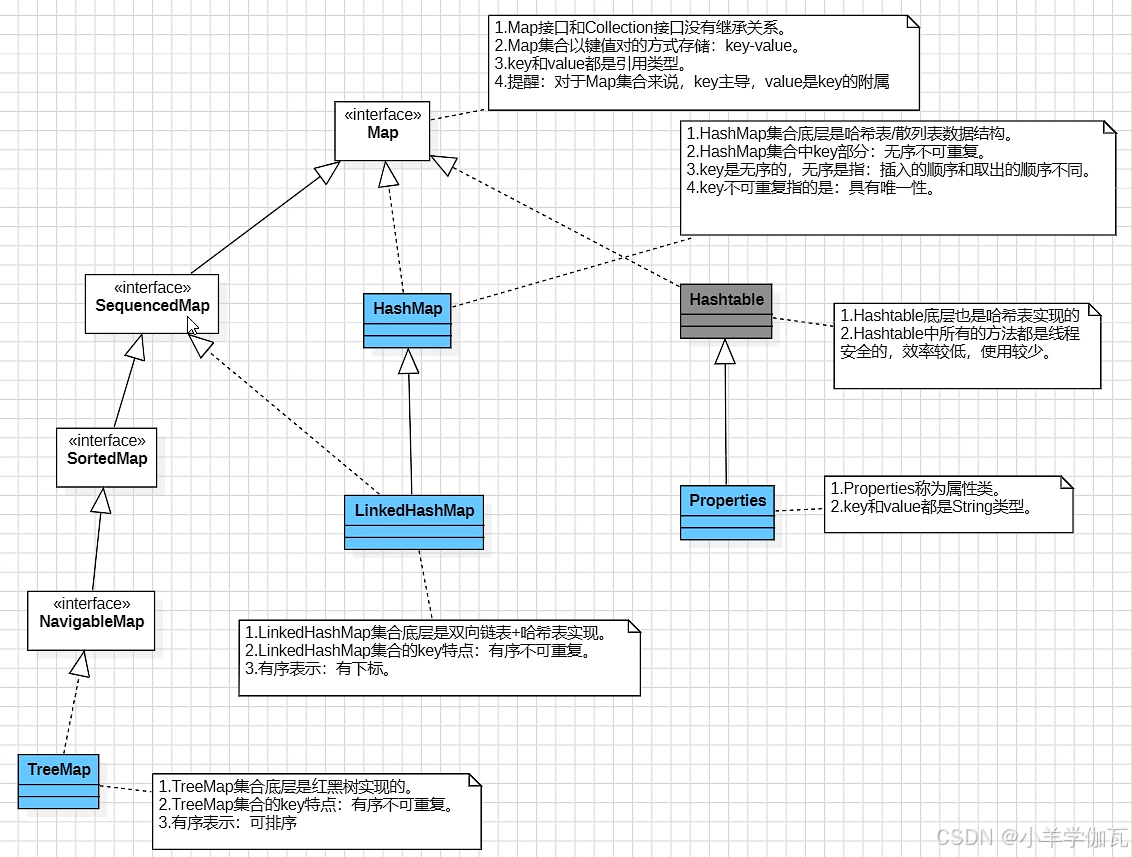
2.常用方法
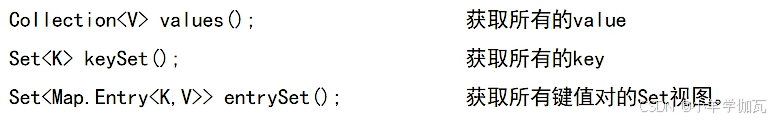
3.
4.
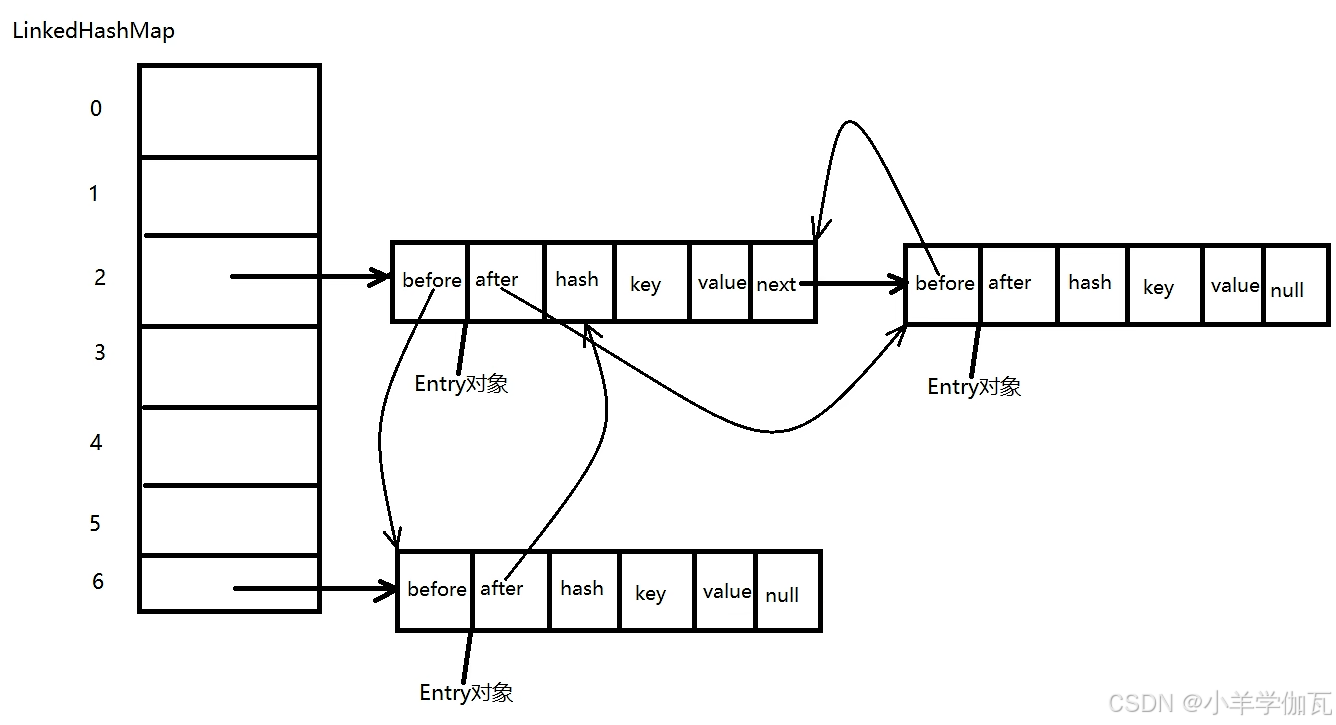
5.LinkedHashMap
有序指的是有下标。

6.HashTable下的properties属性类的使用(IO流)
与配置文件联合使用,属性配置文件的扩展名:xxxx.properties
key和value都是string类型
7.TreeMap
key可排序,但不可重复
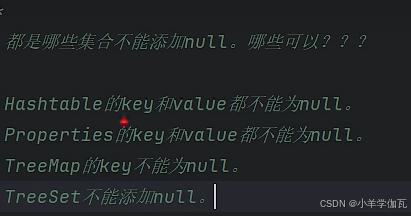
key不能为null
key需要重写hashcode和equals
底层数据结构采用红黑树
1.自定义类型的排序(两种方式)
1.实现comparable接口,然后重写compareTo,person implement comparable<person>
侵入式的编程
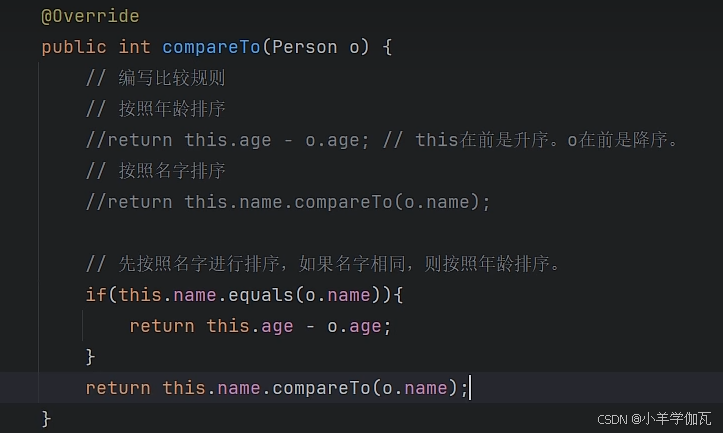
2.多写一个comparator比较器(独立的一个类)
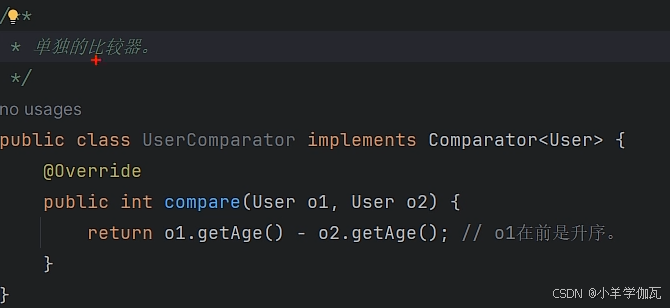
总结:如果比较规则经常不变,比如说你按照int string类型的比较,就用第一种
如果经常变,比如你自定义的类型,有时按年龄比有时按名字比等等,就用第二种比较器。
put的源码就是看你new Treemap的时候传没传比较器,传了就走比较器,没传就走comparable。
九.哪些集合的key不能为null
十.****HashMap****
1.数据结构

2.链表过长如何解决?
1.扩容
初始化容量是16,一次扩容2倍。扩容后,所有的元素需要重新计算,得到桶下标,所以扩容的成本非常大,所以在创建时,就要确定好初始化容量,避免扩容。
2.树化

退化成链表
1.扩容时
2.remove树节点时,根节点,根节点的左右孩子,和左孙子,在移除前都还存在,就不会退化成链表,若不存在则会退化为链表。注意:是移除前检查那几个节点。
3.索引的计算
1.索引是如何计算的?
任何一个对象都有一个hashcode方法得到原始hash,hashmap中还有一个hash()方法得到这个对象的二次hash值,然后这个hash值再和数组的容量进行一个取模运算得到一个余数,就是桶下标的位置。
取模运算其实可以优化,变成一个按位与(数组长度-1),这里要求数组长度必须是2的n次幂。
2.hashcode都有了,为何还要提供hash()方法?
hash方法,先拿到原始的hash值,然后右移16位,再与原始的hash值做一个异或运算得到二次hash值。有时在低位数字一样,模一个相同的数组长度就得到了相同的桶下标,二次hash可以让高位的数字参与进来。本质就是为了让hash分布更加均匀,避免链表过长。

3.数组的容量为何是2的n次幂?不是可不可以?

数组的容量是2的n次幂的话可以进行优化
1.扩容的时候,更加方便
2.计算桶下标位置的时候更快
那不用可以吗?
数组长度用2的n次幂时有一定的缺点。比如说如果选择的数字都是偶数,那么就会导致分布不均匀。
如果选择选择一个质数,甚至都不用二次hash了。就可以得到一个不错的分布性。
看追求的是什么,追求效率就选2的n次幂。追求更好的分布性,则选择一个不错的质数。
4.put的流程

添加元素时,是先把元素放进去,再检查是否需要扩容。
5.扩容因子为什么是0.75f

6.多线程下的问题
1. 数据错乱(1.7,1.8)
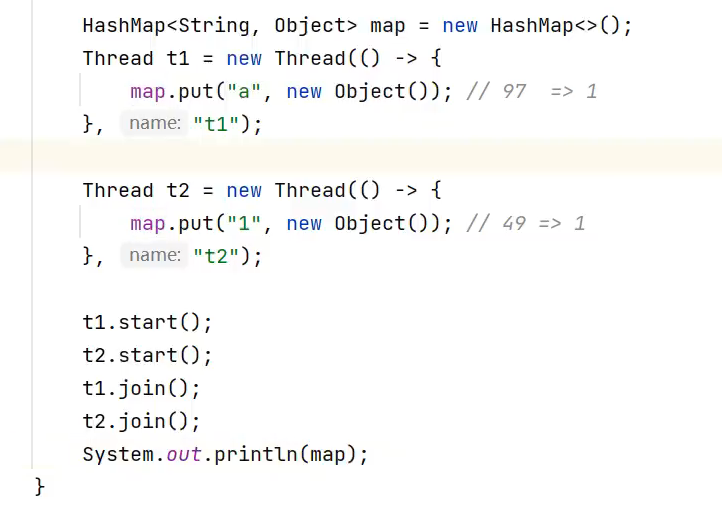
两个线程都检查到同一个桶下标没有元素,都往这个位置添加元素,导致后一个把前一个覆盖了,明明那个下标应该有2个元素,而现在就只有一个了。
2.并发死链(1.7)头插法和扩容时迁移导致
7.key的要求

而且key必须唯一,不可重复,如果key重复,value就会覆盖。
如果是自定义类型,必须同时重写equals和hashcode方法。
8.对象的hashcode是如何设计的?

十一.Set集合
本质上就是map集合然后取出key的部分,不要value就是set集合。
1.Hashset
1.特点
无序不可重复
2.面试题:

首先有一个student类,并且重写了hashcode方法,通过年龄和名字。现在是把张三的名字变成王五了。

问题1.set.remove(stu)能不能被删除?答:不能被删除
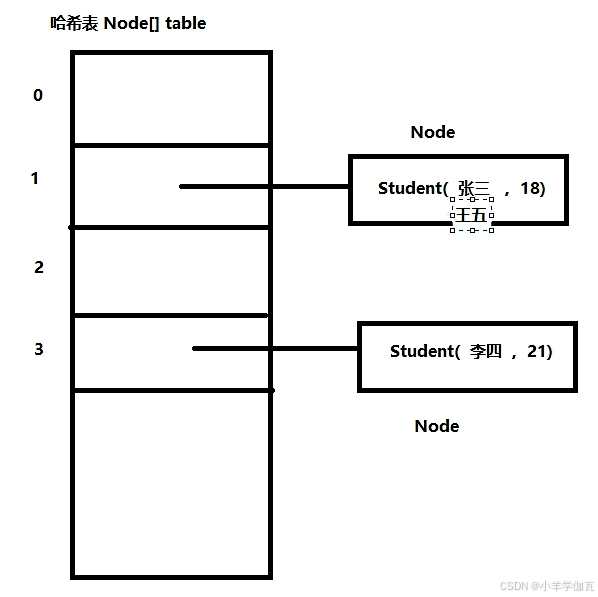
虽然将张三的名字改成了王五,但是它所在的位置并没有变,也就是说那个位置其实是张三和他的年龄18通过hashcode计算出来的下标。
remove方法:remove(stu),现在stu变成王五,remove方法先要找到数组下标,知道要删除的元素在哪,那就是通过hashcode方法来得到下标,但是王五和年龄18计算出来的下标有可能不是张三原来待的那个下标了,会是其他下标,所以当然就删不掉了。
2.问题2:set.add(new Student("王五",18))能不能添加成功?答:可以添加成功
本质和上一个其实是一样,添加王五这个对象到哈希表中,是通过王五和年龄18 hashcode方法计算出来得到的下标,和张三那个计算出来的下标当然不一样。所以可以添加成功。
3.问题3:set.add(new Student("张三",18))能不能添加成功?答:可以添加成功
因为虽然通过张三和18算出来的下标,与王五那个相同,这时就发生了哈希碰撞,会进行equals的比对,王五和张三并不同,所以添加成功。
2.LinkedHashMap
有序不可重复
有序:插入顺序有保障,放的什么顺序取出来就是什么顺序
3.TreeSet
不能存null
有序不可重复
有序:是可排序,实现方式与TreeMap相同,两种方式
十二.Collections工具类(操作集合的工具类)
1.collections.sort
专门针对List集合提供的排序方法。对于JDK内置的可以直接排序,如果是自定义类型的就得实现comparable接口,再用sorts排序。
当然还有sort的重载方法。就不用实现comparable接口了