MySQL相关查询
将上一章末尾的相关数据进行插入到数据库中,下面进行查找,查找有不同的方法不同的形式,大家可以跟着一起学习。
简单查询表中的数据:
-- 查询所有学生的所有信息
SELECT stu_id,stu_name,stu_sex,stu_birth,stu_addr,col_idFROM tb_student;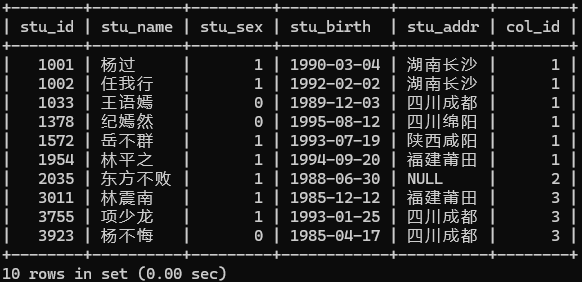
我们可以看见表头为设置的英文展示,现在想更加直观用中文展示。
中文展示表头(as):
-- 查询学生的学号、姓名和籍贯(投影和别名)
SELECT stu_id AS 学号,stu_name AS 姓名,stu_addr AS 籍贯FROM tb_student;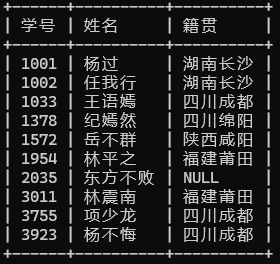
准确的数据筛选(where):
-- 查询所有女学生的姓名和出生日期(数据筛选)
SELECT stu_name,stu_birthFROM tb_studentWHERE stu_sex = 0;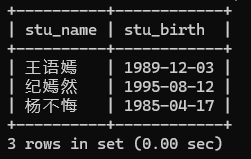
准确数据筛选基础上加上更多条件(and or):
-- 查询籍贯为“四川成都”的女学生的姓名和出生日期(数据筛选)
SELECT stu_name,stu_birthFROM tb_studentWHERE stu_sex = 0AND stu_addr = '四川成都';-- 查询籍贯为“四川成都”或者性别是女的学生(数据筛选)
SELECT stu_name,stu_birthFROM tb_studentWHERE stu_sex = 0OR stu_addr = '四川成都';当然我们也可以使用<=等比较符来确定范围
-- 查询所有80后学生的姓名、性别和出生日期(数据筛选)
SELECT stu_name,stu_sex,stu_birthFROM tb_studentWHERE '1980-1-1' <= stu_birth AND stu_birth <= '1989-12-31';SELECT stu_name,stu_sex,stu_birthFROM tb_studentWHERE stu_birth BETWEEN '1980-1-1' AND '1989-12-31';如果想查询奇数相关数据。
-- 查询学分是奇数的课程的名称和学分(数据筛选)
SELECT cou_name,cou_creditFROM tb_courseWHERE cou_credit MOD 2 <> 0;其中MOD是进行除法得余数的计算
<>是检查余数是否不等于 0
中文展示数据(case end)(if as):
-- 查询名字叫“杨过”的学生的姓名和性别(数据筛选)
SELECT stu_name AS 姓名, CASE stu_sex WHEN 1 THEN '男' ELSE '女' END AS 性别FROM tb_studentWHERE stu_name = '杨过';或者SELECT stu_name AS 姓名, IF(stu_sex, '男', '女') AS 性别FROM tb_studentWHERE stu_name = '杨过';第一种方法,
CASE stu_sex:表示根据stu_sex列的值进行判断。
WHEN 1 THEN '男':如果stu_sex的值等于1,那么返回字符串'男'。
ELSE '女':如果stu_sex的值不等于1,那么返回字符串'女'。
END AS 性别:结束CASE表达式,并将结果命名为“性别”。
第二种方法:
IF(stu_sex, '男', '女'):这是一个条件函数,stu_sex为真则返回'男',否则返回女。
模糊匹配(% _):
使用%可以匹配零个或者任意多个字符。
-- 查询姓“杨”的学生姓名和性别(模糊匹配)
-- 通配符 % 匹配零个或任意多个字符
SELECT stu_name AS 姓名, CASE stu_sex WHEN 1 THEN '男' ELSE '女' END AS 性别FROM tb_studentWHERE stu_name LIKE '杨%';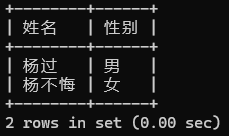
使用_匹配一个字符,可以使用多个_来匹配相应数量的字符。
-- 查询姓“杨”名字两个字的学生姓名和性别(模糊匹配)
-- 通过符 _ 匹配一个字符
SELECT stu_name AS 姓名, CASE stu_sex WHEN 1 THEN '男' ELSE '女' END AS 性别FROM tb_studentWHERE stu_name LIKE '杨_';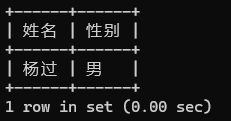
将模糊匹配与or结合
-- 查询名字中有“不”字或“嫣”字的学生的学号和姓名(模糊匹配和并集运算)
SELECT stu_id,stu_nameFROM tb_studentWHERE stu_name LIKE '%不%'OR stu_name LIKE '%嫣%';或者SELECT stu_id,stu_nameFROM tb_studentWHERE stu_name LIKE '%不%'UNION
SELECT stu_id,stu_nameFROM tb_studentWHERE stu_name LIKE '%嫣%';union完成将两个 结果合并在一起,删除重复的行。
空值处理(is null):
-- 查询没有录入籍贯的学生姓名(空值处理)
SELECT stu_nameFROM tb_studentWHERE TRIM(stu_addr) = ''OR stu_addr is null;去重(distinct):
-- 查询学生选课的所有日期(去重)
SELECT DISTINCT sel_dateFROM tb_record; 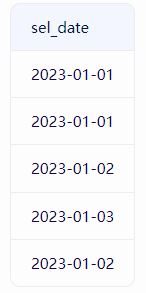
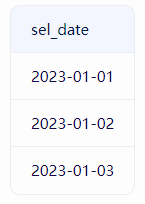
如果一开始输出是左边的,经过distinct就会变成右边的。
排序(order by):
-- 查询男学生的姓名和生日按年龄从大到小排列(排序)
SELECT stu_name,stu_birthFROM tb_studentWHERE stu_sex = 1ORDER BY stu_birth ASC;使用order by排序,asc其实是对数据从小到大排序(因为生日数字越小,年龄越大)那现在我们抛开年龄这个例子。
asc表示从小到大排序,desc表示从大到小排序。
聚合(max min )
-- 查询年龄最大的学生的出生日期(聚合函数)
SELECT MIN(stu_birth)FROM tb_student;计算平均分,标准差等
-- 查询学号为1001的学生考试成绩的最低分、最高分、平均分、标准差、方差(聚合函数)
SELECT MIN(score) AS 最低分,MAX(score) AS 最高分,ROUND(AVG(score), 1) AS 平均分,STDDEV(score) AS 标准差,VARIANCE(score) AS 方差FROM tb_recordWHERE stu_id = 1001;分组(count group by):
-- 查询男女学生的人数(分组和聚合函数)
SELECT CASE stu_sex WHEN 1 THEN '男' ELSE '女' END AS 性别,COUNT(*) AS 人数FROM tb_studentGROUP BY stu_sex;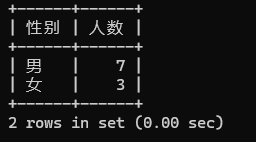
count是一个聚合函数,计算分组中达到行数
group by 按照stu_sex进行分组
子查询:
-- 查询年龄最大的学生的姓名(子查询)
SELECT stu_nameFROM tb_studentWHERE stu_birth = (SELECT MIN(stu_birth)FROM tb_student);表连接(两个表中数据作为筛选项)
SELECT stu_name,stu_birth,col_nameFROM tb_student AS t1, tb_college AS t2WHERE t1.col_id = t2.col_id;说明:
MySQL 中支持多种类型的运算符,包括:算术运算符(+、-、*、/、%)、比较运算符(=、<>、<=>、<、<=、>、>=、BETWEEN...AND...、IN、IS NULL、IS NOT NULL、LIKE、RLIKE、REGEXP)、逻辑运算符(NOT、AND、OR、XOR)和位运算符(&、|、^、~、>>、<<),我们可以在 DML 中使用这些运算符处理数据。
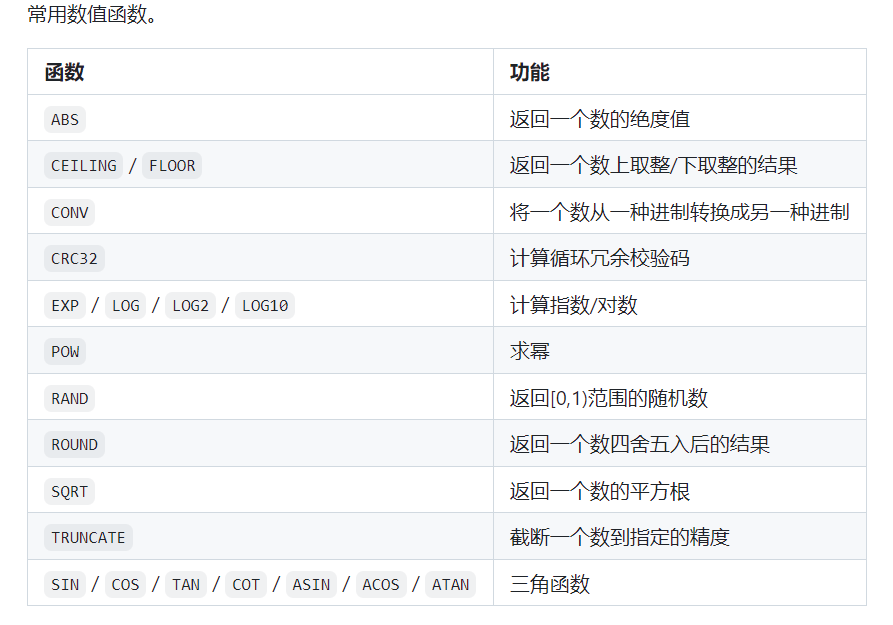
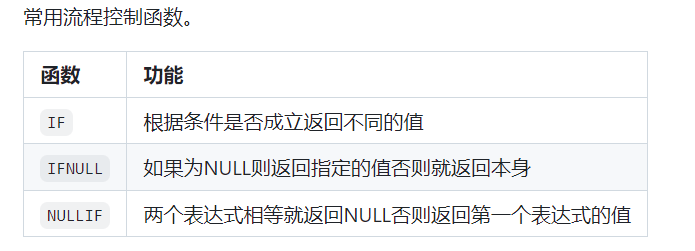
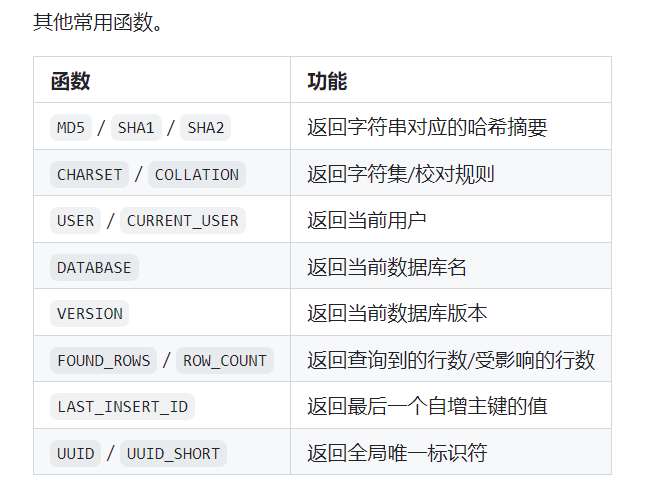
在查询数据时,可以在SELECT语句及其子句(如WHERE子句、ORDER BY子句、HAVING子句等)中使用函数,这些函数包括字符串函数、数值函数、时间日期函数、流程函数等,如下面的表格所示。