Spark,在shell中运行RDD程序
在hdfs中/wcinput中创建一个文件:word2.txt在里面写几个单词
启动hdfs集群
[root@hadoop100 ~]# myhadoop start
[root@hadoop100 ~]# cd /opt/module/spark-yarn/bin
[root@hadoop100 ~]# ./spark-shell
写个1+1测试一下
按住ctrl+D退出
进入环境:spark-shell --master yarn
逐个写代码:
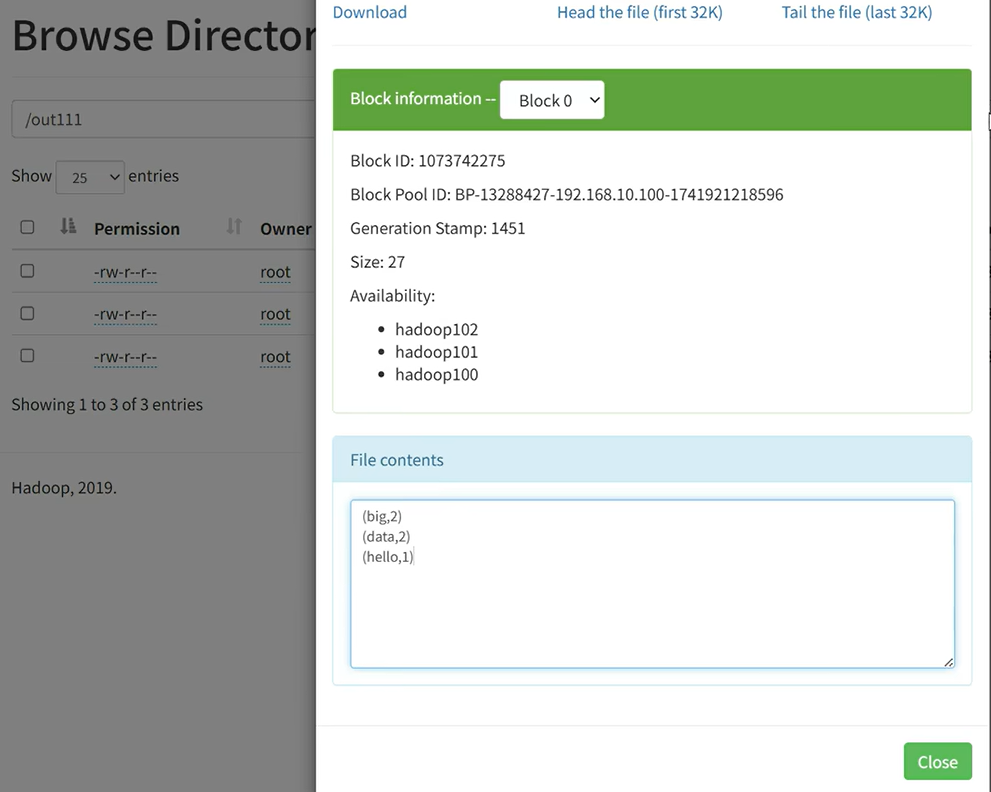
// 读取文件,得到RDDval rdd1 = sc.textFile("hdfs://hadoop100:8020/wcinput/word2.txt")// 将单词进行切割,得到一个存储全部单词的RDDval rdd2= rdd1.flatMap(line => line.split(" "))// 将单词转换为元组对象,key是单词,value是数字1val rdd3= rdd2.map(word => (word, 1))// 将元组的value按照key来分组,对所有的value执行聚合操作(相加)val rdd4= rdd3.reduceByKey((num1, num2) => num1 + num2)// 收集RDD的数据并打印输出结果rdd4.collect().foreach(println)// 将结果储存在out111中rdd.saveAsTextFile("hdfs://hadoop100:8020/out111")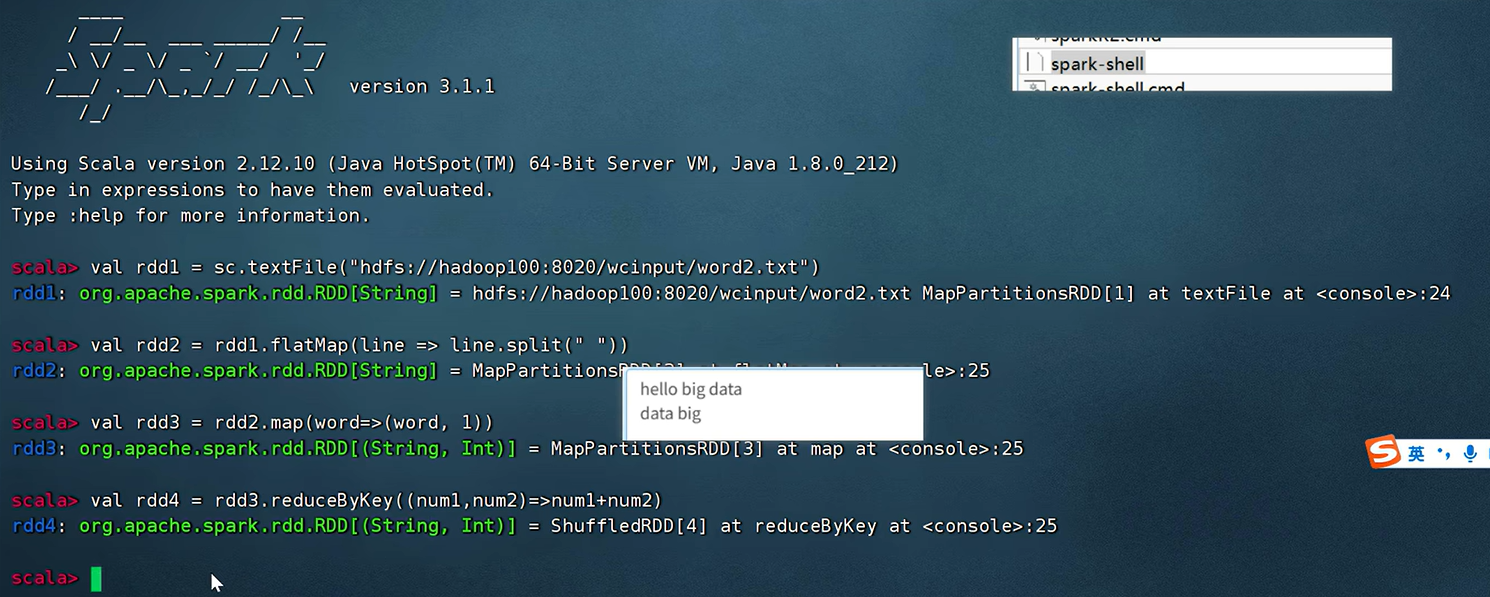
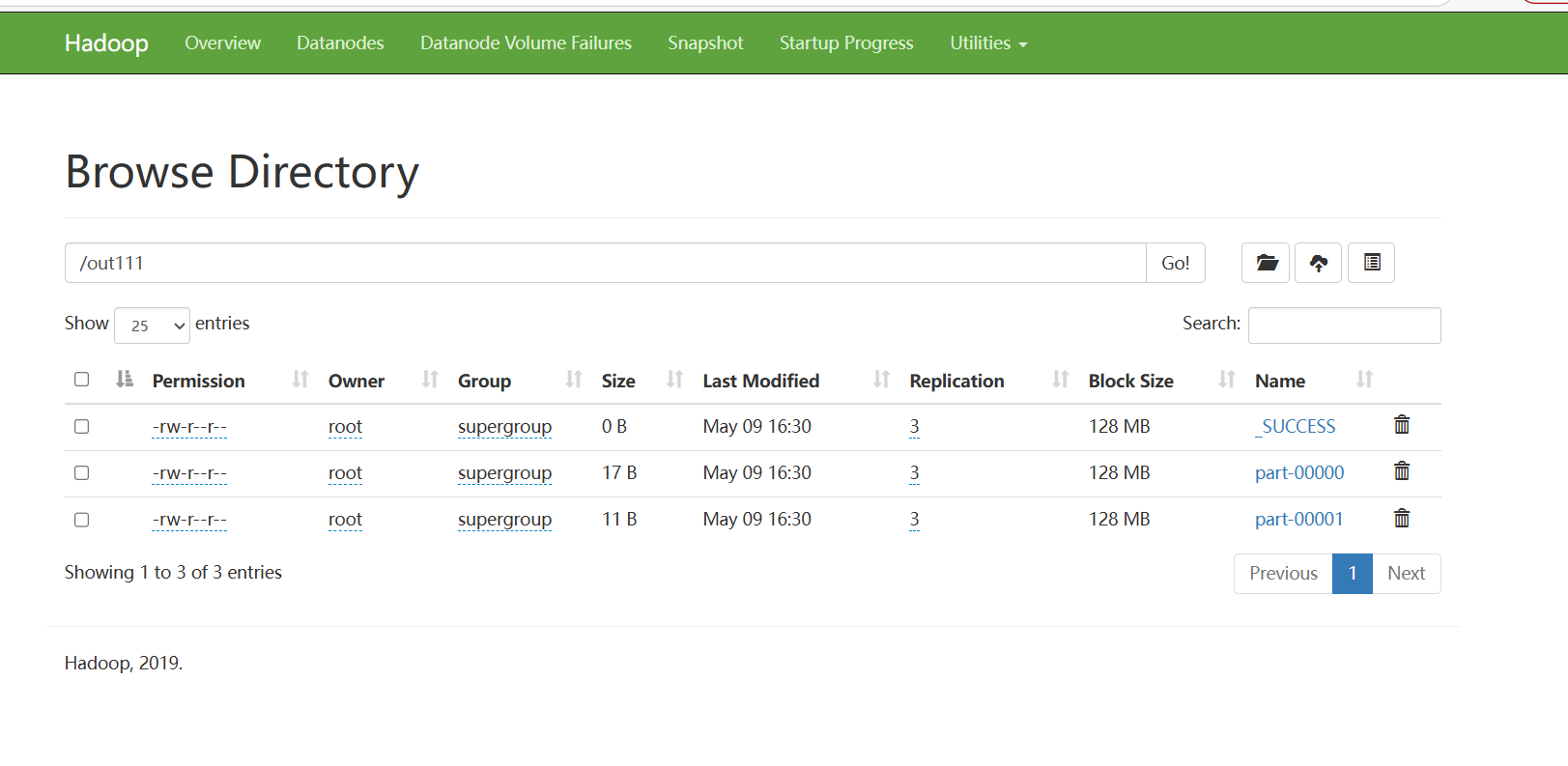
在根目录下可见out111文件,文件打开后可以看到,word2.txt文件内单词被拆分
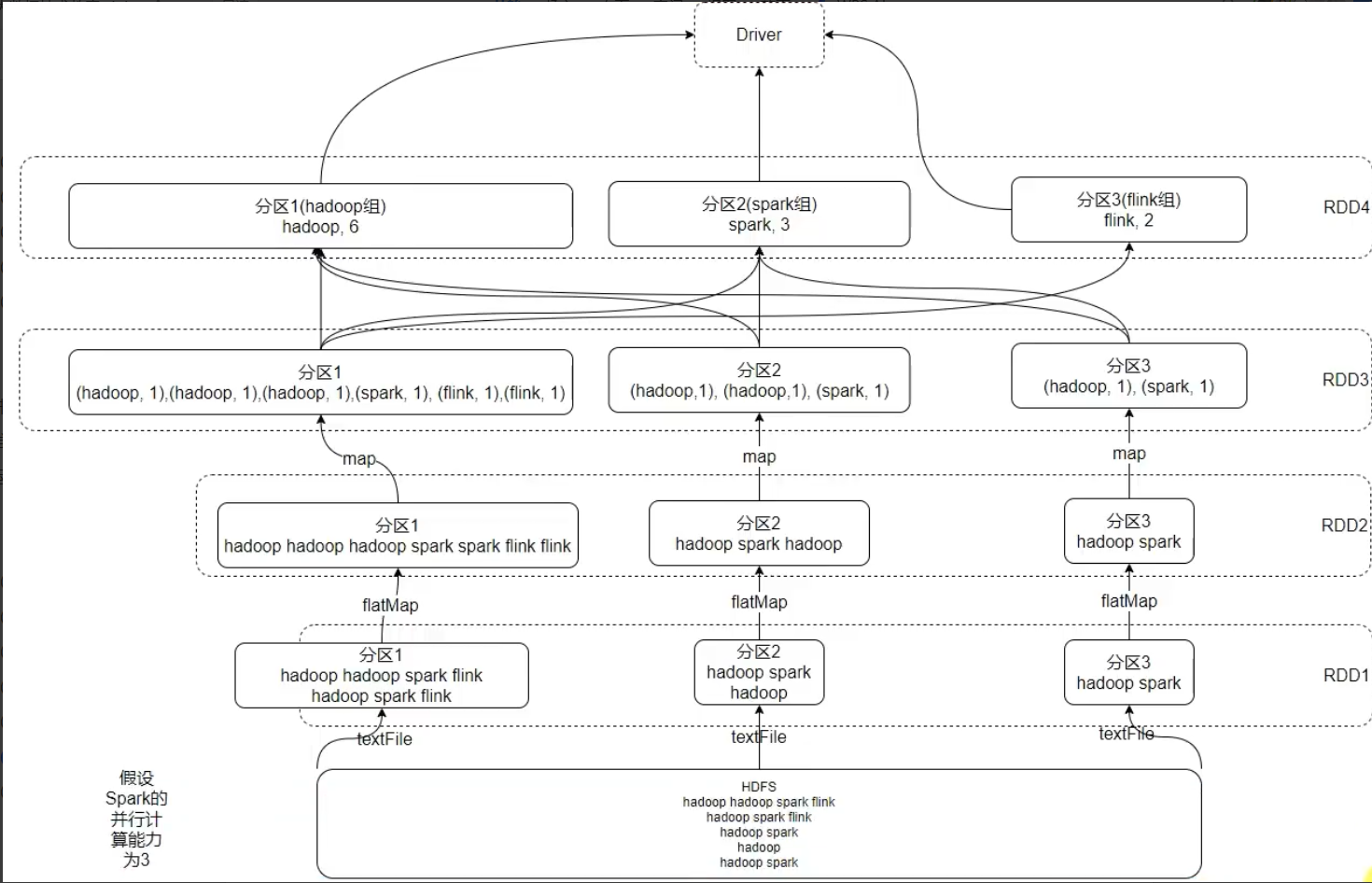
RDD的执行过程