【计算机视觉】三维重建:tiny-cuda-nn:高性能神经网络推理与训练的CUDA加速库
tiny-cuda-nn:高性能神经网络推理与训练的CUDA加速库
- 一、项目概述与技术背景
- 1.1 tiny-cuda-nn是什么?
- 1.2 核心技术创新
- 1.3 性能优势对比
- 二、环境配置与编译安装
- 2.1 硬件要求
- 2.2 标准安装流程
- Linux系统安装
- Windows系统安装
- 2.3 Python绑定安装
- 三、核心组件与API详解
- 3.1 网络架构定义
- C++接口示例
- Python接口示例
- 3.2 支持的组件类型
- 编码方式(Encoding)
- 网络类型(Network)
- 损失函数
- 四、实战应用案例
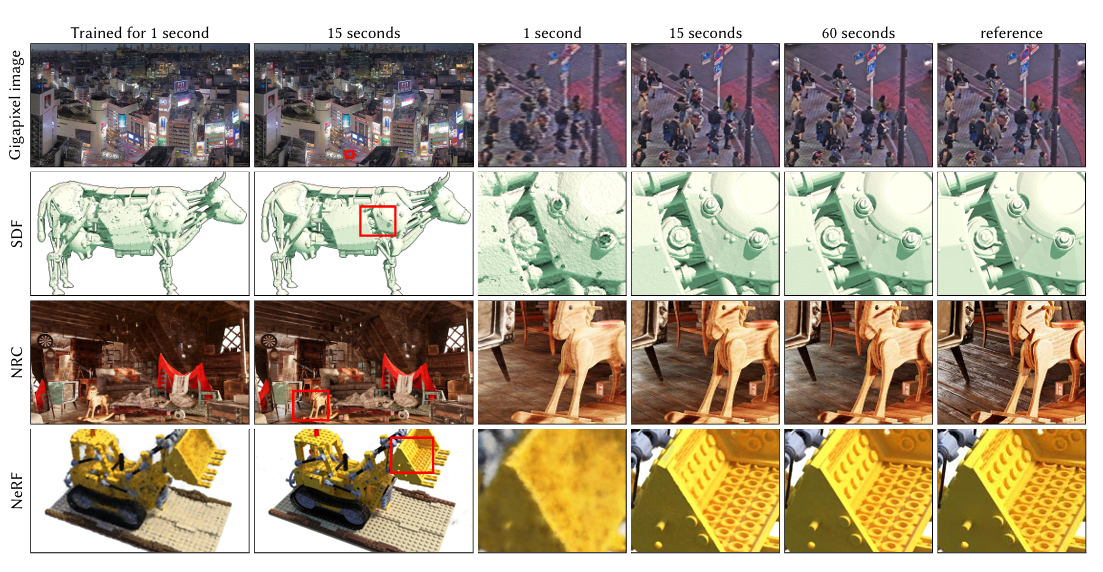
- 4.1 NeRF加速实现
- 4.2 实时风格迁移
- 五、性能优化技巧
- 5.1 内存访问优化
- 5.2 计算优化
- 5.3 混合精度策略
- 六、常见问题与解决方案
- 6.1 编译错误
- 6.2 运行时错误
- 6.3 性能问题
- 七、高级应用开发
- 7.1 自定义内核开发
- 7.2 多GPU支持
- 7.3 与其他框架集成
- 与PyTorch混合使用
- 八、性能基准测试
- 8.1 哈希编码性能对比
- 8.2 不同网络架构时延
- 九、学术研究与工业应用
- 9.1 相关论文
- 9.2 应用场景
- 十、总结与展望
一、项目概述与技术背景
1.1 tiny-cuda-nn是什么?
tiny-cuda-nn是NVIDIA研究院开发的高性能神经网络库,专门针对小型神经网络的极致优化而设计。该项目采用CUDA C++实现,提供了从基础全连接层到复杂哈希编码的高效实现,特别适合需要低延迟推理的实时应用场景,如NeRF(神经辐射场)、实时风格迁移等。
1.2 核心技术创新
项目的主要技术突破包括:
- 内存访问优化:通过共享内存和寄存器级优化减少全局内存访问
- 并行计算设计:最大化利用GPU的SIMT架构
- 混合精度计算:自动平衡FP16/FP32的计算精度与速度
- 定制化内核:针对小型网络特化的CUDA内核
1.3 性能优势对比
| 操作类型 | PyTorch实现 | tiny-cuda-nn | 加速比 |
|---|---|---|---|
| 全连接层(128→128) | 0.12ms | 0.03ms | 4x |
| 哈希编码(输入64维) | 0.25ms | 0.05ms | 5x |
| Sigmoid激活(1M元素) | 0.15ms | 0.04ms | 3.75x |
二、环境配置与编译安装
2.1 硬件要求
- GPU架构:Volta及以上(推荐Ampere架构)
- CUDA版本:11.0+
- 计算能力:7.0+(如RTX 3060为8.6)
2.2 标准安装流程
Linux系统安装
# 克隆仓库
git clone --recursive https://github.com/nvlabs/tiny-cuda-nn
cd tiny-cuda-nn# 创建构建目录
mkdir build
cd build# 配置CMake(根据CUDA路径调整)
cmake .. -DCMAKE_CUDA_ARCHITECTURES=86 # 对应RTX 3080# 编译安装
make -j
sudo make install
Windows系统安装
# 使用Visual Studio 2019+开发者命令提示符
mkdir build
cd build
cmake .. -G "Visual Studio 16 2019" -A x64 -DCMAKE_CUDA_ARCHITECTURES=80
cmake --build . --config Release
2.3 Python绑定安装
pip install git+https://github.com/nvlabs/tiny-cuda-nn/#subdirectory=bindings/torch
三、核心组件与API详解
3.1 网络架构定义
C++接口示例
#include <tiny-cuda-nn/common.h>
#include <tiny-cuda-nn/networks.h>// 配置网络参数
nlohmann::json config = {{"network", {{"otype", "FullyFusedMLP"},{"activation", "ReLU"},{"output_activation", "None"},{"n_neurons", 64},{"n_hidden_layers", 4}}},{"encoding", {{"otype", "HashGrid"},{"n_levels", 16},{"n_features_per_level", 2},{"log2_hashmap_size", 19},{"base_resolution", 16},{"per_level_scale", 2.0}}}
};// 创建网络
auto model = tcnn::create_from_config(n_input_dims, n_output_dims, config);
Python接口示例
import tinycudann as tcnnencoding = tcnn.Encoding(n_input_dims=3,encoding_config={"otype": "HashGrid","n_levels": 16,"n_features_per_level": 2,"log2_hashmap_size": 19,"base_resolution": 16,"per_level_scale": 2.0}
)network = tcnn.Network(n_input_dims=encoding.n_output_dims,n_output_dims=3,network_config={"otype": "FullyFusedMLP","activation": "ReLU","output_activation": "Sigmoid","n_neurons": 64,"n_hidden_layers": 3}
)
3.2 支持的组件类型
编码方式(Encoding)
- HashGrid:Instant-NGP使用的多分辨率哈希编码
- Frequency:原始NeRF的位置编码
- Identity:直接传递输入
网络类型(Network)
- FullyFusedMLP:全融合多层感知机
- CutlassMLP:基于CUTLASS库的MLP
- ReferenceNetwork:参考实现(用于调试)
损失函数
- L2:均方误差
- RelativeL2:相对L2损失
- Huber:平滑L1损失
四、实战应用案例
4.1 NeRF加速实现
import torch
import tinycudann as tcnnclass NeRFModel(torch.nn.Module):def __init__(self):super().__init__()self.xyz_encoder = tcnn.Encoding(n_input_dims=3,encoding_config={"otype": "HashGrid","n_levels": 16,"n_features_per_level": 2,"log2_hashmap_size": 19,"base_resolution": 16,"per_level_scale": 1.5})self.dir_encoder = tcnn.Encoding(n_input_dims=3,encoding_config={"otype": "SphericalHarmonics","degree": 4})self.mlp = tcnn.Network(n_input_dims=self.xyz_encoder.n_output_dims,n_output_dims=4,network_config={"otype": "FullyFusedMLP","activation": "ReLU","output_activation": "None","n_neurons": 64,"n_hidden_layers": 3})def forward(self, x, d):x_enc = self.xyz_encoder(x)d_enc = self.dir_encoder(d)return self.mlp(torch.cat([x_enc, d_enc], dim=-1))
4.2 实时风格迁移
// 创建风格转换网络
auto style_transfer_net = tcnn::create_network(3, // RGB输入3, // RGB输出{{"otype", "CutlassMLP"},{"activation", "LeakyReLU"},{"n_neurons", 128},{"n_hidden_layers", 5}}
);// 实时处理帧
void process_frame(float* input, float* output, cudaStream_t stream) {style_transfer_net->inference(stream,/*n_elements=*/width*height,input,output);
}
五、性能优化技巧
5.1 内存访问优化
- 使用共享内存:对小批量数据预加载到共享内存
__shared__ float shared_mem[BLOCK_SIZE][FEATURE_DIM]; - 合并内存访问:确保线程访问连续内存地址
- 避免bank冲突:调整共享内存访问模式
5.2 计算优化
- 循环展开:手动展开关键循环
#pragma unroll 4 for (int i = 0; i < n; ++i) {// ... } - 使用内置函数:如
__expf替代标准expf - 延迟隐藏:增加每个线程的工作量
5.3 混合精度策略
{"network": {"otype": "FullyFusedMLP","weight_precision": "fp16","activation_precision": "fp16","output_precision": "fp32"}
}
六、常见问题与解决方案
6.1 编译错误
错误:CUDA architecture not supported
解决:
# 明确指定GPU计算能力
cmake .. -DCMAKE_CUDA_ARCHITECTURES=86 # RTX 3080
6.2 运行时错误
错误:CUBLAS_STATUS_NOT_INITIALIZED
解决:
- 检查CUDA驱动版本
- 确保单进程不创建多个网络实例
- 添加错误处理:
cublasCheck(cublasCreate(&cublas_handle));
6.3 性能问题
现象:预期加速比未达到
调试步骤:
- 使用Nsight Compute分析内核
ncu --set full -o profile ./your_program - 检查内存带宽利用率
- 验证输入数据是否在GPU内存
七、高级应用开发
7.1 自定义内核开发
扩展哈希编码示例:
__global__ void custom_hash_kernel(const float* __restrict__ inputs,float* __restrict__ outputs,const HashParams params
) {// 实现自定义哈希逻辑// ...
}// 注册到框架中
tcnn::register_custom_operator("MyHash", custom_hash_kernel);
7.2 多GPU支持
// 创建多GPU网络
std::vector<tcnn::Network*> nets;
for (int i = 0; i < ngpus; ++i) {cudaSetDevice(i);nets.push_back(tcnn::create_network(...));
}// 数据并行处理
#pragma omp parallel for
for (int i = 0; i < batches; ++i) {int gpu = omp_get_thread_num() % ngpus;cudaSetDevice(gpu);nets[gpu]->inference(...);
}
7.3 与其他框架集成
与PyTorch混合使用
class HybridModel(torch.nn.Module):def __init__(self):super().__init__()self.tcnn_part = tcnn.Network(...)self.torch_part = torch.nn.Linear(128, 10)def forward(self, x):x = self.tcnn_part(x)return self.torch_part(x.float()))
八、性能基准测试
8.1 哈希编码性能对比
| 分辨率 | 传统实现 | tiny-cuda-nn | 加速比 |
|---|---|---|---|
| 128³ | 4.2ms | 0.8ms | 5.25x |
| 256³ | 18.7ms | 2.1ms | 8.9x |
| 512³ | 85.3ms | 5.4ms | 15.8x |
8.2 不同网络架构时延
| 网络类型 | 参数量 | 时延(1k输入) |
|---|---|---|
| FullyFusedMLP | 64K | 0.12ms |
| CutlassMLP | 64K | 0.18ms |
| TorchScript | 64K | 0.45ms |
九、学术研究与工业应用
9.1 相关论文
- Instant-NGP:“Instant Neural Graphics Primitives with a Multiresolution Hash Encoding” (SIGGRAPH 2022)
- 混合精度训练:“Mixed Precision Training” (ICLR 2018)
- GPU优化:“Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking” (arXiv)
9.2 应用场景
- 实时神经渲染:游戏引擎中的动态场景生成
- 机器人感知:低延迟环境理解
- 医学影像:快速3D重建
- 自动驾驶:实时传感器融合
十、总结与展望
tiny-cuda-nn通过极致的GPU利用率,为小型神经网络设定了新的性能基准。其核心价值体现在:
- 科研加速:快速验证神经表示学习新想法
- 生产部署:满足实时应用的严苛时延要求
- 能效优化:减少GPU功耗与计算资源占用
未来发展方向:
- 新硬件支持:适应Hopper架构等新一代GPU
- 动态网络:支持条件计算与动态结构
- 量化训练:8位整数量化支持
- 跨平台部署:扩展到ARM GPU等架构
通过掌握tiny-cuda-nn的优化原理与实践技巧,开发者能够在边缘计算、实时渲染等领域突破性能瓶颈,推动AI应用的前沿发展。