[machine learning] Transformer - Attention (三)
上一篇文章我们介绍实现了带训练参数的self-attention类。本文在上一篇文章基础上进一步介绍因果attention(causal attention)。
Causal attention,也叫masked attention,是self-attention的一种特殊形式。跟标准的self-attention考虑输入序列的全部单词不同,causal attention只允许考虑当前单词之前的单词(即屏蔽当前单词未来的单词)。下面是屏蔽过程的示意图:
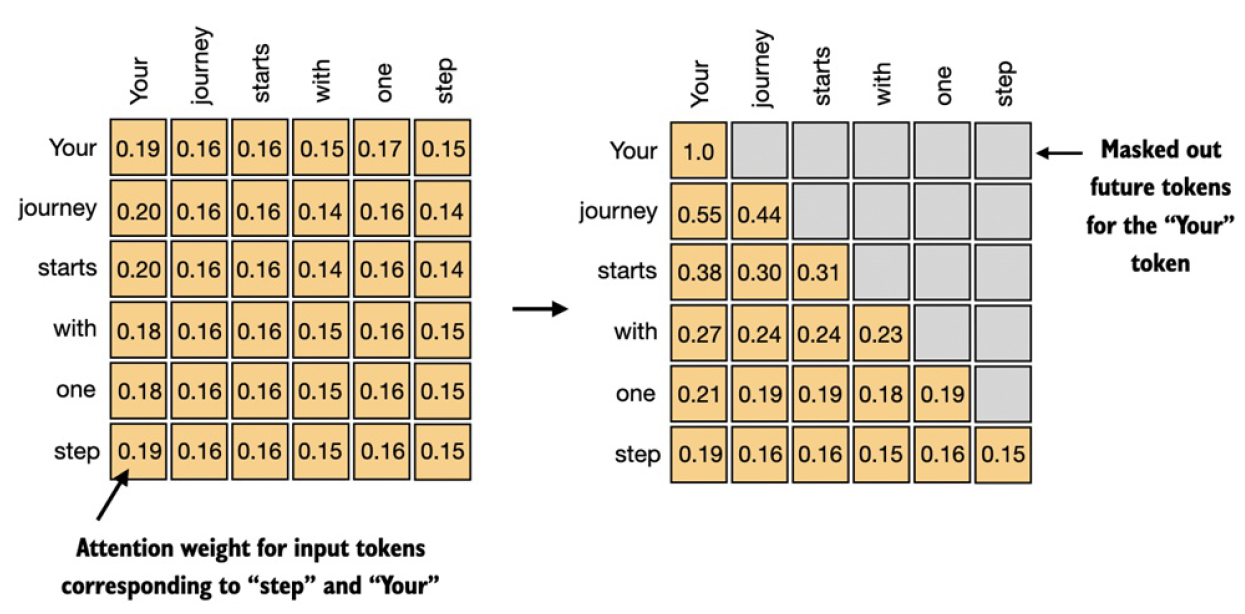
下面是给causal attention添加mask的一个例子:
# Reuse the query and key weight matrices of the
# 这里使用上一篇文章介绍的 SelfAttention_v2 类
queries = sa_v2.W_query(inputs)
keys = sa_v2.W_key(inputs)
attn_scores = queries @ keys.Tattn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
print(attn_weights)
# 输出:
#tensor([[0.1921, 0.1646, 0.1652, 0.1550, 0.1721, 0.1510],
# [0.2041, 0.1659, 0.1662, 0.1496, 0.1665, 0.1477],
# [0.2036, 0.1659, 0.1662, 0.1498, 0.1664, 0.1480],
# [0.1869, 0.1667, 0.1668, 0.1571, 0.1661, 0.1564],
# [0.1830, 0.1669, 0.1670, 0.1588, 0.1658, 0.1585],
# [0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]],
# grad_fn=<SoftmaxBackward0>)context_length = attn_scores.shape[0]
# 屏蔽上三角,即每个单词只能看到它之前的单词
mask_simple = torch.tril(torch.ones(context_length, context_length))
print(mask_simple)
# 输出:
#tensor([[1., 0., 0., 0., 0., 0.],
# [1., 1., 0., 0., 0., 0.],
# [1., 1., 1., 0., 0., 0.],
# [1., 1., 1., 1., 0., 0.],
# [1., 1., 1., 1., 1., 0.],
# [1., 1., 1., 1., 1., 1.]])# 屏蔽后的attention weights
masked_simple = attn_weights*mask_simple
print(masked_simple)
# 输出
#tensor([[0.1921, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
# [0.2041, 0.1659, 0.0000, 0.0000, 0.0000, 0.0000],
# [0.2036, 0.1659, 0.1662, 0.0000, 0.0000, 0.0000],
# [0.1869, 0.1667, 0.1668, 0.1571, 0.0000, 0.0000],
# [0.1830, 0.1669, 0.1670, 0.1588, 0.1658, 0.0000],
# [0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]],
# grad_fn=<MulBackward0>)# 归一化屏蔽后的attention weights,使得每一行和为1
row_sums = masked_simple.sum(dim=-1, keepdim=True)
masked_simple_norm = masked_simple / row_sums
print(masked_simple_norm)
# 输出:
# tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
# [0.5517, 0.4483, 0.0000, 0.0000, 0.0000, 0.0000],
# [0.3800, 0.3097, 0.3103, 0.0000, 0.0000, 0.0000],
# [0.2758, 0.2460, 0.2462, 0.2319, 0.0000, 0.0000],
# [0.2175, 0.1983, 0.1984, 0.1888, 0.1971, 0.0000],
# [0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]],
# grad_fn=<DivBackward0>)
上面的这个例子是做完Softmax之后再加mask,这打破了Softmax创建的概率分布,因此需要重新归一化使得每一行的和重新为1。这种做法虽然最后依然能够使得每一行和为1,但是重新归一化的操作增加了复杂度并可能引入意想不到的效果。
下面介绍一种利用Softmax的特性一步到位的方法:
mask = torch.triu(torch.ones(context_length, context_length), diagonal=1)
masked = attn_scores.masked_fill(mask.bool(), -torch.inf)
print(masked)
# 输出:
#tensor([[0.2899, -inf, -inf, -inf, -inf, -inf],
# [0.4656, 0.1723, -inf, -inf, -inf, -inf],
# [0.4594, 0.1703, 0.1731, -inf, -inf, -inf],
# [0.2642, 0.1024, 0.1036, 0.0186, -inf, -inf],
# [0.2183, 0.0874, 0.0882, 0.0177, 0.0786, -inf],
# [0.3408, 0.1270, 0.1290, 0.0198, 0.1290, 0.0078]],
# grad_fn=<MaskedFillBackward0>)attn_weights = torch.softmax(masked / keys.shape[-1]**0.5, dim=-1)
print(attn_weights)
# 输出:
#tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
# [0.5517, 0.4483, 0.0000, 0.0000, 0.0000, 0.0000],
# [0.3800, 0.3097, 0.3103, 0.0000, 0.0000, 0.0000],
# [0.2758, 0.2460, 0.2462, 0.2319, 0.0000, 0.0000],
# [0.2175, 0.1983, 0.1984, 0.1888, 0.1971, 0.0000],
# [0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]],
# grad_fn=<SoftmaxBackward0>)
这种方法把需要屏蔽的值设为负无穷,而对于负无穷,softmax会转换成0。因此,巧妙地既把屏蔽值权重降为0,又保证每一行的概率和为1。
下面介绍怎么在causal attention的计算中添加dropout。dropout是用来防止模型过拟合,并且只在训练的时候用,推理的时候不用dropout。在transformer架构中,attention机制中的dropout主要有两种用法:一种是在attention scores上做dropout;另一种是在attention weights上做dropout。目前,主流的做法是在attention weights上做dropout,示意图如下:
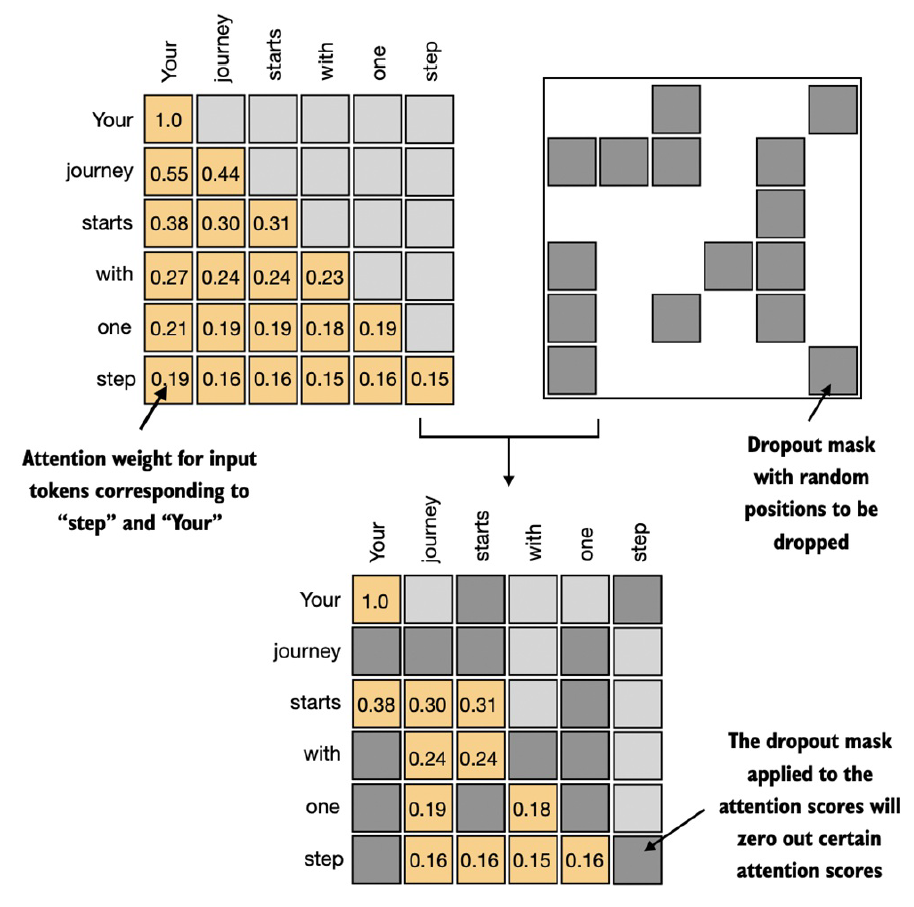
下面在一个6×6的全1矩阵上做dropout,以这个简单例子介绍dropout机制:
torch.manual_seed(123)
dropout = torch.nn.Dropout(0.5) # dropout rate of 50%
example = torch.ones(6, 6) # create a matrix of onesprint(dropout(example))
# 输出:
#tensor([[2., 2., 0., 2., 2., 0.],
# [0., 0., 0., 2., 0., 2.],
# [2., 2., 2., 2., 0., 2.],
# [0., 2., 2., 0., 0., 2.],
# [0., 2., 0., 2., 0., 2.],
# [0., 2., 2., 2., 2., 0.]])
可以看到,有一半的值被drop了(即被赋值0)。还有一个注意点是,dropout之后,没有被drop的值数值也改变了。这是因为,为了弥补有些值被drop了的影响,没有被drop的值会被放大(scale up)。这种放大机制对于维持attention weights的整体平衡至关重要,因为它确保了在训练和推理时attention机制的平均影响保持一致。没有被drop的值的放大公式是:1 / (1 - dropout_rate)
下面我们对之前的attention weights做dropout(在不同的操作系统上,结果会有不同):
torch.manual_seed(123)
print(dropout(attn_weights))# 输出:
#tensor([[2.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
# [0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
# [0.7599, 0.6194, 0.6206, 0.0000, 0.0000, 0.0000],
# [0.0000, 0.4921, 0.4925, 0.0000, 0.0000, 0.0000],
# [0.0000, 0.3966, 0.0000, 0.3775, 0.0000, 0.0000],
# [0.0000, 0.3327, 0.3331, 0.3084, 0.3331, 0.0000]],
# grad_fn=<MulBackward0>)
了解了causal attention和dropout masking这两种机制后,下面我们实现一个causal attention类:
class CausalAttention(nn.Module):def __init__(self, d_in, d_out, context_length,dropout, qkv_bias=False):super().__init__()self.d_out = d_outself.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)self.dropout = nn.Dropout(dropout) # Newself.register_buffer('mask', torch.triu(torch.ones(context_length, context_length), diagonal=1)) # Newdef forward(self, x):b, num_tokens, d_in = x.shape # New batch dimension b# For inputs where `num_tokens` exceeds `context_length`, this will result in errors# in the mask creation further below.# In practice, this is not a problem since the LLM (chapters 4-7) ensures that inputs # do not exceed `context_length` before reaching this forward method. keys = self.W_key(x)queries = self.W_query(x)values = self.W_value(x)attn_scores = queries @ keys.transpose(1, 2) # Changed transposeattn_scores.masked_fill_( # New, _ ops are in-placeself.mask.bool()[:num_tokens, :num_tokens], -torch.inf) # `:num_tokens` to account for cases where the number of tokens in the batch is smaller than the supported context_sizeattn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)attn_weights = self.dropout(attn_weights) # Newcontext_vec = attn_weights @ valuesreturn context_vec
在这个类中,新加了self.register_buffer()方法,这个方法不是必须的,但是使用它的好处是:buffers会自动移到模型使用的device上(CPU或GPU),这样我们就不必手动去确保和模型的device一致,避免了device不一致的错误。
下面我们使用CausalAttention类来计算上下文向量:
batch = torch.stack((inputs, inputs), dim=0)
print(batch.shape) # 2 inputs with 6 tokens each, and each token has embedding dimension 3
# 输出:
# torch.Size([2, 6, 3])torch.manual_seed(123)context_length = batch.shape[1]
ca = CausalAttention(d_in, d_out, context_length, 0.0)context_vecs = ca(batch)print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)
# 输出:
#tensor([[[-0.4519, 0.2216],
# [-0.5874, 0.0058],
# [-0.6300, -0.0632],
# [-0.5675, -0.0843],
# [-0.5526, -0.0981],
# [-0.5299, -0.1081]],# [[-0.4519, 0.2216],
# [-0.5874, 0.0058],
# [-0.6300, -0.0632],
# [-0.5675, -0.0843],
# [-0.5526, -0.0981],
# [-0.5299, -0.1081]]], grad_fn=<UnsafeViewBackward0>)
# context_vecs.shape: torch.Size([2, 6, 2])
这里简单使用了torch.stack来模拟batch输入。
参考资料:
《Build a Large Language Model from Scratch》