第十四章:生产之路:LLM 应用部署、运维与优化
章节引导:理论构建和本地实验只是我们 LLM 应用开发之旅的起点。将我们在前面章节精心构建的 RAG 系统或智能 Agent 成功部署到生产环境,并确保其持续稳定、高效、安全地运行,才是真正的挑战所在。这“最后一公里”充满了工程、运维和成本等多方面的复杂性。本章将聚焦于 LLM 应用的生产化实践,探讨常见的部署模式与架构选择,动手实践主流的部署工具(LangServe, FastAPI, BentoML),深入容器化与编排技术(Docker, Kubernetes),构建关键的可观测性体系(LangSmith, OpenTelemetry, Logging, Metrics),并分享性能优化、成本控制和安全防护的最佳实践。最终,我们将引入 MLOps 的理念,助你铺设一条通往稳定、可维护、可持续优化的 LLM 应用生产之路。
核心前提: 生产化是一个系统工程,需要跨越模型、应用、基础设施等多个层面进行考量和投入。本章侧重于应用层的部署、运维和优化实践。
14.1 部署架构蓝图:模式选择与权衡
将 LLM 应用投入生产,首先需要选择合适的部署模式和架构。常见的选择包括:
- 简单 API 服务:
- 模式: 将整个 RAG 或 Agent 逻辑封装在一个独立的 Web 服务中,通过 API (如 RESTful) 对外提供服务。
- 优点: 结构简单,易于开发和部署,适合功能相对单一的应用。
- 缺点: 随着应用逻辑变复杂,可能变成难以维护的“单体应用”;扩展性受限于单个服务。
- 前后端分离 + API:
- 模式: 构建一个独立的前端应用(Web/App)与用户交互,前端通过调用后端 LLM 应用 API 来获取结果。这是构建交互式 Web 应用(如 Chatbot)的标准模式。
- 优点: 前后端职责分离,便于独立开发、部署和扩展。
- 缺点: 增加了前后端接口设计和维护的复杂度。
- 微服务架构:
- 模式: 将 LLM 应用的不同功能模块拆分成独立的微服务,例如:用户请求处理服务、RAG 检索服务、Agent 核心逻辑服务、模型推理服务(如果自托管模型)。服务间通过 API 或消息队列通信。
- 优点: 高度解耦,各服务可独立扩展、更新和使用不同技术栈;容错性更好(单个服务故障不影响整体)。
- 缺点: 架构复杂,引入了服务发现、分布式事务、跨服务调用等挑战;运维成本更高。
- 流式处理架构:
- 模式: 对于需要实时、流式响应的应用(如实时语音助手、流式对话生成),采用支持流式输入输出的 API (如 WebSockets, Server-Sent Events) 和后端处理逻辑。
- 优点: 提供更流畅、实时的用户体验。
- 缺点: 实现复杂度更高,需要框架和模型支持流式处理。
架构选型考量:
- 应用复杂度: 简单的问答或 RAG 可能适合 API 服务,复杂的、多步骤的 Agent 可能更适合微服务。
- 可扩展性需求: 预期用户量和请求量有多大?是否需要独立扩展某个组件(如检索)?
- 团队技能与规模: 微服务对团队的架构能力和运维能力要求更高。
- 成本预算: 微服务通常需要更多的基础设施资源。
- 响应时间要求: 流式架构对实时性要求最高。
选择没有绝对好坏,关键在于匹配业务需求和团队能力。
14.2 部署工具实战:服务化你的 LLM 应用
选定架构后,需要使用工具将我们的 Python 应用代码部署为稳定、高效的 API 服务。以下是三种常用工具的实战介绍:
LangServe: (LangChain 生态首选)

- 优势: 与 LangChain
Runnable(LCEL 链, Agent, LangGraph App) 无缝集成,代码量极少即可快速部署,自带 Playground UI 方便调试和演示。 - 动手实验: 将第六章的 RAG 链 (如
rag_chain_concise) 使用 LangServe 部署。
# --- deploy_rag_langserve.py ---
from fastapi import FastAPI
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_chroma.vectorstores import Chroma
from langserve import add_routes # Core LangServe function
import uvicorn
import os
from dotenv import load_dotenvload_dotenv()# --- 1. 定义或导入你的 RAG Runnable ---
# (复用 Ch6 的 rag_chain_concise 定义)
persist_directory = "./chroma_db_lc"
embedding_function = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = Chroma(persist_directory=persist_directory, embedding_function=embedding_function, collection_name="my_rag_collection")
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
llm = ChatOpenAI(model="gpt-4o")
output_parser = StrOutputParser()
template = """Answer based on context: {context}\n\nQuestion: {question}"""
prompt = ChatPromptTemplate.from_template(template)
def format_docs(docs): return "\n\n".join(doc.page_content for doc in docs)rag_chain_concise = ({"context": retriever | format_docs, "question": RunnablePassthrough()}| prompt| llm| output_parser
)# --- 2. 创建 FastAPI 应用 ---
app = FastAPI(title="LangChain RAG Server",version="1.0",description="A simple API server using Langchain's Runnable interfaces",
)# --- 3. 使用 add_routes 将 Runnable 部署到 FastAPI 应用 ---
# '/rag-chain' 是 API 路径
add_routes(app,rag_chain_concise, # Your runnable objectpath="/rag-chain",# input_type=str, # Optional: Specify input type hint for UI# output_type=str # Optional: Specify output type hint for UI
)# --- 4. (可选) 添加其他自定义路径 ---
@app.get("/")
async def read_root():return {"message": "Welcome to the RAG API!"}# --- 5. 启动服务器 ---
if __name__ == "__main__":# 运行: python deploy_rag_langserve.pyuvicorn.run(app, host="0.0.0.0", port=8000)- 运行:
python deploy_rag_langserve.py - 访问:
- API 文档和 Playground:
http://localhost:8000/docs - RAG 链 Playground:
http://localhost:8000/rag-chain/playground/ - 可以直接通过 POST 请求调用
/rag-chain/invoke,/rag-chain/stream等端点。
- API 文档和 Playground:
- 解读: LangServe 极大地简化了部署过程,只需几行代码即可将
Runnable暴露为功能完善的 API。
FastAPI: (通用高性能 Web 框架)

- 优势: 极其灵活,高性能,基于 Python 类型提示自动生成 API 文档,社区庞大。适合需要高度定制 API、集成非 LangChain 逻辑或构建复杂 Web 应用的场景。
- 动手实验: 使用 FastAPI 封装一个 RAG 应用逻辑。
# --- deploy_rag_fastapi.py ---
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
# ... (导入 LangChain RAG 组件的代码,同上) ...
import uvicorn
import os
from dotenv import load_dotenvload_dotenv()# --- 1. 定义 RAG 链 (同上) ---
# rag_chain_concise = ...# --- 2. 定义 API 输入输出模型 (使用 Pydantic) ---
class RAGQuery(BaseModel):question: strclass RAGResponse(BaseModel):answer: str# You could add retrieved_docs, etc. if needed# --- 3. 创建 FastAPI 应用 ---
app = FastAPI(title="Custom RAG API with FastAPI")# --- 4. 定义 API 端点 ---
@app.post("/query", response_model=RAGResponse)
async def query_rag(query: RAGQuery):"""Receives a question and returns the RAG chain's answer."""try:# 调用 LangChain Runnableresult = rag_chain_concise.invoke(query.question)return RAGResponse(answer=result)except Exception as e:# Add proper error handlingprint(f"Error during RAG invocation: {e}")raise HTTPException(status_code=500, detail=f"Internal Server Error: {e}")@app.get("/")
async def root():return {"message": "FastAPI RAG Service is running!"}# --- 5. 启动服务器 ---
if __name__ == "__main__":# 运行: python deploy_rag_fastapi.pyuvicorn.run(app, host="0.0.0.0", port=8001)- 运行:
python deploy_rag_fastapi.py - 访问: API 文档:
http://localhost:8001/docs。可以通过 POST/query端点发送 JSON 请求{"question": "..."}。 - 解读: FastAPI 提供了完全的控制权,你需要手动定义 API 输入输出模型 (
Pydantic) 和端点逻辑,并在其中调用 LangChain 的invoke(或其他方法)。灵活性更高,但代码量比 LangServe 多。
BentoML: (专注 ML 模型服务化)

- 优势: 专为 ML 模型(包括 LLM)设计,提供模型打包 (
Bento)、版本管理、依赖管理、高性能 API Server(带自动批处理优化)、灵活部署(Docker, K8s, Serverless)等特性。特别适合需要管理多个模型(LLM, Embedding, Reranker)并追求推理性能的场景。 - 动手实验: 使用 BentoML 打包和部署 RAG 应用服务。
# --- service.py (BentoML service definition) ---
import bentoml
import typing as t
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# ... (导入其他 LangChain RAG 组件) ...
from dotenv import load_dotenv
import os# Load env vars for keys used during build/runtime
load_dotenv()# --- 1. 定义或加载 LangChain Runnable ---
# (同上的 rag_chain_concise 定义)
# It's better to initialize components *inside* the BentoML service
# or load them if they are saved with the Bento, to ensure correct context.# --- 2. 定义 BentoML Service ---
# Use a tag for versioning
@bentoml.service(traffic={"timeout": 300})
class RAGService:# Better practice: Initialize client/chain in __init__# This ensures they are loaded once per worker/replicadef __init__(self) -> None:print("Initializing RAG Chain components...")persist_directory = "./chroma_db_lc" # Make sure this is accessible at runtimetry:embedding_function = OpenAIEmbeddings(model="text-embedding-3-small")vectorstore = Chroma(persist_directory=persist_directory,embedding_function=embedding_function,collection_name="my_rag_collection")self.retriever = vectorstore.as_retriever(search_kwargs={"k": 3})self.llm = ChatOpenAI(model="gpt-4o")self.output_parser = StrOutputParser()template = """Answer based on context: {context}\n\nQuestion: {question}"""self.prompt = ChatPromptTemplate.from_template(template)def format_docs(docs): return "\n\n".join(doc.page_content for doc in docs)self.rag_chain = ({"context": self.retriever | format_docs, "question": RunnablePassthrough()}| self.prompt| self.llm| self.output_parser)print("RAG Chain initialized.")except Exception as e:print(f"FATAL: Failed to initialize RAG components: {e}")# Raise or handle appropriatelyraise# Define the API endpoint# Use type hints for automatic validation and OpenAPI spec generation@bentoml.apiasync def query(self, question: str) -> str:"""Accepts a question string and returns the RAG answer."""print(f"Received query: {question}")try:# Invoke the chain asynchronously if possible (though base chain might be sync)# result = await self.rag_chain.ainvoke(question) # Use ainvoke if chain supports asyncresult = self.rag_chain.invoke(question) # Use invoke for sync chainprint("Query processed successfully.")return resultexcept Exception as e:print(f"Error processing query: {e}")# Consider returning a proper error response instead of raising# raise HTTPException(status_code=500, detail=str(e))return f"Error: {e}" # Simple error return for demo# --- 3. 创建 bentofile.yaml (定义依赖和 Bento 信息) ---
# bentofile.yaml
# service: "service:RAGService" # Points to the service definition file and class
# description: "A RAG application deployed with BentoML"
# include:
# - "*.py" # Include Python files
# - "./chroma_db_lc/" # IMPORTANT: Include vector store data if needed at runtime!
# python:
# packages:
# - langchain
# - langchain-openai
# - langchain-chroma
# - chromadb
# - pydantic
# - python-dotenv
# # Add other necessary packages
# models: # Optional: if you want BentoML to manage models directly
# # - my_embedding_model: # Example
# # module: sentence_transformers
# # model_id: BAAI/bge-small-en-v1.5# --- 4. 构建 Bento ---
# 在终端运行: bentoml build# --- 5. 运行 BentoML Server ---
# 在终端运行: bentoml serve service:RAGService --reload # --reload for development- 运行: 先创建
bentofile.yaml,然后bentoml build,最后bentoml serve service:RAGService。 - 访问: API 文档和 UI:
http://localhost:3000。可以通过 UI 或 POST/query端点发送 JSON{"question": "..."}。 - 解读: BentoML 需要定义
service.py和bentofile.yaml。它更侧重于打包整个应用(包括代码、依赖甚至模型和数据)为一个可部署单元 (Bento)。它提供了更高级的 ML 服务特性,如自动批处理,对于需要极致推理性能和管理复杂模型依赖的场景更有优势。
工具对比与选择建议:
- 快速部署 LangChain Runnable: -> LangServe
- 构建通用、高度定制的 API: -> FastAPI
- 专注于 ML 模型服务化、性能优化、多模型管理: -> BentoML
14.3 走向标准:容器化 (Docker) 与编排 (Kubernetes)
为了实现环境一致性、可移植性和可伸缩性,容器化是现代应用部署的标准实践。
- 为何需要容器化?
- 环境一致性: 打包应用及其所有依赖(Python 版本、库、系统工具),确保在开发、测试、生产环境运行一致。
- 可移植性: Docker 镜像可以在任何支持 Docker 的机器或云平台上运行。
- 资源隔离: 容器提供一定程度的资源隔离。
- 易于扩展: 可以快速启动多个相同的容器实例来处理负载。
- Docker 核心实践:
- 编写 Dockerfile: 定义如何构建包含你的 LLM 应用的镜像。需要包括:
- 基础镜像 (如
python:3.11-slim)。 - 复制应用代码 (
COPY . .)。 - 安装依赖 (
pip install -r requirements.txt)。 - (如果需要) 复制模型文件或数据(如 ChromaDB 持久化目录)。
- 暴露端口 (
EXPOSE 8000)。 - 定义启动命令 (
CMD ["python", "your_server_script.py"]或CMD ["bentoml", "serve", "..."])。
- 基础镜像 (如
- 构建镜像:
docker build -t my-llm-app:latest . - 运行容器:
docker run -p 8000:8000 -e OPENAI_API_KEY=$OPENAI_API_KEY my-llm-app:latest(注意挂载密钥或使用其他安全方式)。
- 编写 Dockerfile: 定义如何构建包含你的 LLM 应用的镜像。需要包括:
- Kubernetes (K8s) 基础:
- 当需要管理大量容器、实现自动扩展、滚动更新、服务发现和负载均衡时,就需要容器编排工具,Kubernetes 是事实标准。
- 核心概念:
Pod: 运行一个或多个容器的最小部署单元。Service: 为一组 Pod 提供稳定的网络入口和负载均衡。Deployment: 定义期望运行的 Pod 副本数量,并管理其生命周期(更新、回滚)。Ingress: (可选) 管理外部访问集群内服务的规则 (HTTP/S 路由)。
- 部署 LLM 服务: 通常会将你的 Docker 镜像定义为一个
Deployment,并通过Service暴露出来。可以使用kubectl apply -f deployment.yaml进行部署。
- (可选) K8s 上的 ML 服务框架: KServe (原 KFServing) 或 Seldon Core 提供了在 Kubernetes 上部署机器学习模型(包括 LLM)的更高级抽象和功能(如 Serverless 推理、多模型服务、Canary 部署、请求/响应转换)。
14.4 可观测性基石:看见你的应用在做什么

生产环境的应用不能是黑盒。可观测性 (Observability) 是指通过 Tracing (追踪), Logging (日志), Metrics (指标) 来理解系统内部状态和行为的能力,对于问题排查、性能分析和容量规划至关重要。
- 追踪 (Tracing): 记录请求在分布式系统中的完整调用路径和耗时。
- LangSmith: (LLM 应用调试利器)
- 价值: 自动捕获 LangChain 应用的详细执行步骤,包括 LLM 调用、Prompt 内容、工具使用、Agent 思考链等。
- 实践: (如 7.5 节所述) 设置环境变量即可启用。重点在于利用其 UI 解读复杂的调用链,调试 Prompt 和 Agent 步骤,监控 Token 消耗和特定步骤的延迟。
- OpenTelemetry (OTel): (开放标准)
- 价值: 提供与供应商无关的 API 和 SDK,用于生成、收集和导出遥测数据(Traces, Metrics, Logs),实现跨服务、跨语言的分布式追踪。
- 实践:
- 安装 OTel Python SDK (
opentelemetry-api,opentelemetry-sdk,opentelemetry-exporter-otlp). - 配置 Exporter 将数据发送到后端(如 Jaeger, Grafana Tempo, Datadog)。
- 在代码中获取 Tracer (
tracer = trace.get_tracer(__name__))。 - 手动在 RAG/Agent 流程的关键代码段(如
retriever.invoke, 工具执行函数, LLM 调用前后)使用with tracer.start_as_current_span("span_name"):来创建和管理 Span (跨度),记录操作名称、耗时和关键属性 (Attributes)。
# Conceptual OTel tracing example # from opentelemetry import trace # tracer = trace.get_tracer(__name__) # # def my_retrieval_step(query): # with tracer.start_as_current_span("rag_retrieval") as span: # span.set_attribute("query.length", len(query)) # results = retriever.invoke(query) # Actual retrieval # span.set_attribute("retrieved.docs.count", len(results)) # return results - 安装 OTel Python SDK (
- 整合: 可以将 LangSmith 追踪与更广泛的 OTel 分布式追踪结合,全面了解请求链路。
- LangSmith: (LLM 应用调试利器)
- 日志 (Logging): 记录离散事件信息。
- 记录什么?
- 请求入口信息 (时间、用户、输入)。
- 关键业务逻辑步骤。
- 错误和异常 (包括完整堆栈跟踪)。
- 关键决策或状态变更。
- 外部调用(LLM API, 工具 API)的耗时和状态。
- 工具:
- Python 内置
logging模块。 - 结构化日志 (JSON): 使用
python-json-logger等库,将日志输出为 JSON 格式,便于机器解析和查询。 - 日志聚合系统:将所有服务/容器的日志集中收集、存储和查询(如 Elasticsearch + Logstash + Kibana (ELK Stack), Grafana Loki + Promtail)。
- Python 内置
- 记录什么?
- 指标 (Metrics): 可聚合的数值型数据,反映系统状态和性能趋势。
- 监控什么?
- 请求量 (QPS/RPM)。
- 延迟分布 (Latency): 平均值、P95、P99 百分位延迟。
- 错误率 (Error Rate): 按类型区分 (HTTP 5xx, 4xx)。
- LLM 相关: Token 输入/输出数量、API 调用次数、API 调用成本(估算)。
- 资源使用率: CPU, GPU, 内存。
- 工具:
- 客户端库:
prometheus-client(Python),micrometer(Java) 等,在代码中暴露指标。 - 收集与存储: Prometheus (时序数据库)。
- 可视化与告警: Grafana, Datadog。
- 客户端库:
- 监控什么?
- 体系建设: 理想状态是将 Tracing, Logging, Metrics 关联起来。例如,在高延迟 Trace 中可以快速跳转到相关的 Log 查看错误详情,或者根据 Metrics 告警触发 Trace 的采样。
14.5 核心挑战应对:性能、成本与安全
生产环境永远离不开对性能、成本和安全的关注。
性能优化实践
- 应用层:
- 异步处理 (
asyncio): 对于 I/O 密集型操作(如并发调用 LLM API、等待工具响应),使用async/await可以显著提高吞吐量。FastAPI, LangServe, BentoML 都支持异步。确保你的 LangChain Runnable 或 Agent 逻辑是异步兼容的 (ainvoke,astream)。 - 缓存:
- LLM 响应缓存: 对于相同的输入,缓存 LLM 的昂贵响应 (
langchain.cache.InMemoryCache,RedisCache等)。 - 嵌入向量缓存: 避免重复计算文本的嵌入向量。
- 检索结果缓存: 对于相似的查询,可以缓存检索到的文档。
- LLM 响应缓存: 对于相同的输入,缓存 LLM 的昂贵响应 (
- 请求批处理 (Batching): 将多个对 LLM 或 Embedding API 的请求合并成一个批次发送,通常能提高吞吐量并可能降低单位成本。LangChain 的
Runnable支持.batch()和.abatch()。BentoML 提供自适应微批处理。
- 异步处理 (
- 模型层 (回顾):
- 优化推理引擎: 使用 vLLM, TensorRT-LLM 等代替基础 Transformers。
- 模型量化: 使用 INT8, FP8 等低精度格式减少模型大小和显存占用,加速计算(可能牺牲少量精度)。
- 选择更小/更快的模型: 在效果可接受的前提下,选用更小的模型。
成本控制策略
- 精细化追踪: 利用 LangSmith 或自定义日志/指标,精确追踪每个请求的 Token 消耗和 API 调用次数。
- 模型选型: 根据任务需求选择性价比最高的模型。并非所有步骤都需要 GPT-4o,简单的任务可以用 GPT-3.5-Turbo 或更便宜的模型。
- Prompt 优化: 尽量缩短输入 Prompt 和期望输出的长度,减少 Token 消耗。
- 缓存: 有效利用缓存避免重复的 API 调用。
- 限制输出长度: 设置
max_tokens或类似参数。 - 采样与限流: 控制高成本 API 的调用频率。
安全最佳实践
- Prompt 注入防护:
- 输入验证与清洗: 对用户输入进行过滤,去除潜在的恶意指令或脚本。
- 输出过滤/解析: 不直接将 LLM 的原始输出用于危险操作(如数据库查询、代码执行),进行必要的解析和验证。
- 使用特定 Prompt 技术: 例如,明确指示 LLM 忽略后续用户输入中的指令。
- 权限分离: 限制 LLM 应用本身及其调用工具的权限。
- 数据隐私:
- 避免敏感信息入 Prompt: 不要在 Prompt 中直接包含 PII 或其他敏感数据。
- 数据脱敏: 在将用户数据传入 LLM 前进行脱敏处理。
- 日志审查: 确保日志中不记录敏感信息。
- 合规性: 遵守 GDPR, CCPA 等数据保护法规。
- API Key 安全管理: (重中之重)
- 绝不硬编码!
- 使用环境变量或配置文件(注意访问权限)。
- 生产环境推荐使用 Secrets Management 工具 (如 HashiCorp Vault, AWS Secrets Manager, Google Secret Manager, Azure Key Vault) 或 KMS (Key Management Service)。
- 访问控制与认证:
- 对 LLM 应用 API 进行认证和授权,确保只有授权用户/服务可以访问。
- DoS 防护:
- 对 API 进行速率限制 (Rate Limiting)。
- 部署 Web 应用防火墙 (WAF)。
14.6 MLOps for LLM Apps:自动化与生命周期管理
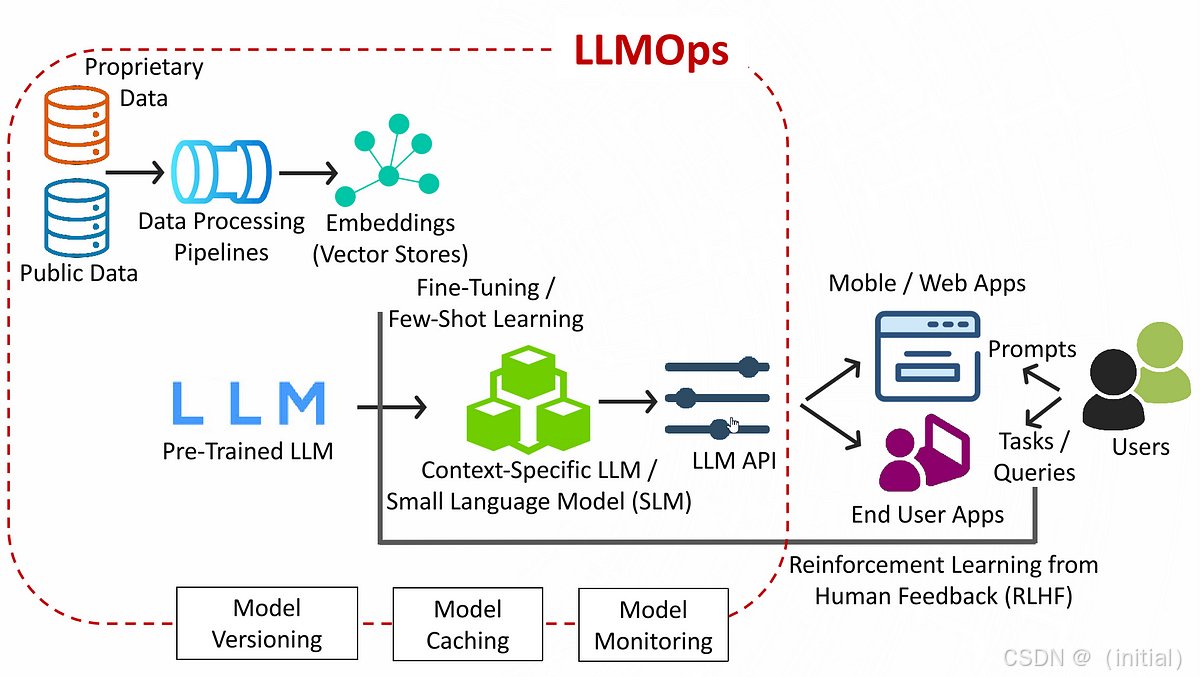
将 LLM 应用投入生产并持续维护,需要借鉴机器学习运维 (MLOps) 的理念,但要针对 LLM 应用的特点进行调整。
- 超越基础 CI/CD: 不仅仅是代码的持续集成和部署,LLM 应用的 MLOps 涉及更广泛的生命周期管理。
- 关键环节:
- 数据管理 (RAG):
- 知识库的自动化更新流程(例如,定期爬取新文档、处理、嵌入、索引)。
- 知识库版本控制与回滚。
- 数据质量监控。
- 模型管理:
- 基础 LLM 的版本跟踪与切换(评估新模型,安全切换)。
- 微调模型的版本管理、部署与 A/B 测试。
- Embedding 模型的管理与更新。
- Prompt 管理与版本控制:
- 将 Prompt 视为核心资产进行管理。
- 使用 Git 或专门的 Prompt Management Platform (如 PromptHub, HumanLoop) 对 Prompt 进行版本控制、协作编辑、A/B 测试和部署。
- 自动化评估流水线:
- 将第十三章讨论的评估流程(特别是自动化评估如 RAGAs)集成到 CI/CD 或定时任务中,实现持续评估 (Continuous Evaluation)。
- 当关键指标下降时自动触发告警或阻止部署。
- 监控、反馈与迭代循环:
- 建立完善的可观测性体系 (14.4)。
- 收集用户反馈。
- 基于监控数据和用户反馈,驱动数据、模型、Prompt 和应用代码的持续迭代优化。
- 数据管理 (RAG):
MLOps for LLM Apps 是一个新兴且快速发展的领域,目标是实现 LLM 应用开发、部署和运维的自动化、标准化和可重复性。
14.7 章节总结:生产环境的挑战与持续投入
本章,我们一起走过了将 LLM 应用从本地实验推向生产环境的关键路径。我们探讨了不同的部署架构,实践了 LangServe, FastAPI, BentoML 等部署工具,学习了 Docker 容器化和 Kubernetes 编排的基础,构建了包含追踪、日志和指标的可观测性体系,并深入讨论了应对性能、成本和安全这三大核心挑战的最佳实践。最后,我们引入了 MLOps 的理念,强调了对 LLM 应用进行全生命周期管理的重要性。
生产环境的复杂性远超本地开发。 我们需要应对网络延迟、资源限制、并发请求、数据漂移、模型更新、安全威胁以及不断变化的用户需求。
应对策略的核心在于:
- 选择合适的工具与架构: 没有银弹,根据应用需求和团队能力做出权衡。
- 构建强大的可观测性: 看不见就无法管理和优化。
- 持续优化: 性能、成本、效果都需要持续迭代。
- 安全优先: 将安全意识贯穿设计、开发、部署、运维全过程。
- 拥抱自动化与 MLOps: 通过自动化流程提高效率、降低风险、加速迭代。
将 LLM 应用成功投入生产并保持高质量运行,是一个需要持续投入工程和运维努力的过程。希望本章提供的知识和实践能够为你在这条道路上提供坚实的指引。下一章,我们将对整个专栏进行总结,并展望 LLM 应用开发的未来。