OpenStack Yoga版安装笔记(25)Nova Cell理解
1、Nova Cell概述
(官方文档:Cells (v2) — nova 25.2.2.dev5 documentation)
Nova中的cells功能的目的是允许较大的部署将其多个计算节点分割成多个cell。所有的nova部署都默认是cell部署,即使大多数情况下只有单一cell。这意味着多cell部署与“标准”nova部署不会有根本性的区别。
详细讲解:
1. 什么是 Cells 功能?
Nova 的 cells 功能是为了在大型 OpenStack 部署中提供扩展性和分片支持。随着云环境中计算节点(虚拟机托管服务器)数量的增加,单个数据库和单一调度器可能会成为瓶颈。为了应对这种扩展性问题,OpenStack Nova 引入了 cell v2 结构,将多个计算节点分成不同的 cell,以便将资源分布到不同的数据库和服务中。
Cell 是对计算节点和资源的逻辑划分,使得在一个 OpenStack 部署中,可以将计算资源分成多个 细分单元,每个单元负责自己的数据库、计算节点和资源。
这种分片机制的目的是减少数据库压力、优化资源调度、提高可扩展性,尤其在大型部署中非常有用。
2. 所有 Nova 部署默认是 Cells 部署
无论你是部署单一 cell 还是多个 cell,所有的 Nova 部署从架构上来说都是 cell 部署。这意味着,即使你只在一个 cell 中运行计算节点,你依然是在使用 cells 功能的。换句话说,单一 cell 只不过是 cell 功能的一种默认实现,并没有禁用这一功能。
这对于大多数普通用户来说意味着什么呢?
即便你的部署只有一个 cell(只有一个数据库和一组计算节点),你依然可以按照 cell v2 架构运行 OpenStack,只是没有启用多个 cell 来进行资源分片。
如果未来需要扩展部署,可以更轻松地启用 多个 cells,而不会大幅度改变现有的架构。
3. 多 cell 部署与标准部署的区别
多 cell 部署:对于大规模的 OpenStack 环境,多个 cell 可以显著提升管理和调度能力。每个 cell 负责一组计算节点和数据库,它们通过消息队列相互协作。
例如,cell1 可以管理一个数据中心的计算节点,cell2 可以管理另一个数据中心的计算节点。每个 cell 都有独立的数据库、消息队列。调度请求会根据资源分布情况和 cell 的状态来决定在哪个 cell 中运行虚拟机。
标准部署(单 cell 部署):如果只有一个 cell,Nova 将会将所有计算资源集中在一个 cell 中,所有计算节点、数据库、消息队列都在同一个单元中。这样一来,数据库的访问和计算节点的调度不会被分片,所有的负载都集中在一个地方。
4. Multi-cell 部署的优势
扩展性:通过将计算节点分配到多个 cell,每个 cell 可以独立地进行资源管理、数据库操作等,减轻单一节点的压力。这种架构能支持更大规模的 OpenStack 部署。
故障隔离:一个 cell 的故障不会直接影响到其他 cell。这为大规模部署提供了更高的容错性。
资源管理优化:不同的 cell 可以分别负责不同区域或不同数据中心的计算资源。每个 cell 都有独立的数据库,能够减少单一数据库的访问压力,提高资源调度的效率。
5. 总结
cells 功能 旨在支持大规模的 OpenStack 部署,将计算资源和数据库进行分片管理。
所有的 Nova 部署 都是 cell 部署,即使默认配置下只有一个 cell,OpenStack 依然会按 cell 的方式处理。
多 cell 部署 适用于需要大规模扩展的环境,而单一 cell 部署更适合较小的环境。
即使未来需要扩展到多个 cell,原本的 单一 cell 部署 也不会对架构造成根本性的影响。
这意味着,即使你目前只运行一个 cell,你也可以在未来轻松地将部署扩展到多个 cell,支持更多的计算节点和更高的可用性。
考虑这样一个部署,它将包括以下组件:
-
nova-api 服务,提供对用户的外部 REST API。
-
nova-scheduler 和 placement 服务,负责跟踪资源并决定实例应部署到哪个计算节点上。
-
一个 “API 数据库”,主要供 nova-api 和 nova-scheduler(以下称为 API 级服务)使用,用来跟踪实例的位置信息,以及用于存储尚未调度但正在构建的实例的临时位置。
-
nova-conductor 服务,负责卸载 API 级服务的长时间运行任务,并将计算节点与数据库访问隔离开来。
-
nova-compute 服务,管理虚拟化驱动和虚拟化主机。
-
一个 “cell 数据库”,被 API、conductor 和 compute 服务使用,存储大多数与实例相关的信息。
-
一个 “cell0 数据库”,它与 cell 数据库相似,但只包含未成功调度的实例。这个数据库类似于常规的 cell,但不包含计算节点,仅用来存放那些未能成功调度到实际计算节点的实例(因此也不会落在真实的 cell 上)。
-
一个 消息队列,允许各服务通过 RPC 进行通信。
详细讲解:
这个部署描述了一个 OpenStack Nova 的多组件架构,其中涉及到多个服务和数据库,分别处理不同的任务。下面是各个组件的详细说明:
1. nova-api 服务:
功能:
nova-api是 Nova 的外部 API 服务,它暴露了 REST API 供用户进行操作,例如启动虚拟机、获取实例状态等。工作:当用户发出请求时,
nova-api会处理这些请求并将其传递给其他服务(如nova-scheduler、nova-conductor)进行后续处理。2. nova-scheduler 和 placement 服务:
功能:
nova-scheduler和placement服务负责资源的调度和实例的部署决策。工作:
nova-scheduler根据计算资源(如 CPU、内存、存储等)选择合适的计算节点来部署虚拟机。
placement服务跟踪每个计算节点的资源使用情况,确保合理的资源分配,并返回哪些节点有足够的资源来容纳新的实例。3. API 数据库:
功能:
API 数据库是nova-api和nova-scheduler使用的数据库,主要用于存储实例的位置信息及与虚拟机创建和调度相关的临时信息。工作:这个数据库包含了正在构建但尚未调度的虚拟机的临时数据。它还存储了与实例调度相关的元数据(如实例当前状态)。
4. nova-conductor 服务:
功能:
nova-conductor服务的作用是将长时间运行的任务从 API 级服务中分离出来,并提供与计算节点的通信桥梁。工作:
nova-conductor可以执行一些需要较长时间的操作,如实例的迁移、快照、卷扩展等,同时也防止了nova-api直接访问数据库,从而提高了系统的效率和可靠性。它会向nova-compute和nova-scheduler等服务发送 RPC 请求,处理一些需要异步执行的任务。5. nova-compute 服务:
功能:
nova-compute服务负责管理虚拟化驱动程序和 hypervisor 主机(如 KVM、QEMU 等)。工作:
nova-compute在计算节点上执行虚拟机的创建、管理和销毁等操作,它负责启动和管理实例,并将实例的状态与nova-api和其他服务同步。6. cell 数据库:
功能:
cell 数据库存储了大多数关于实例的核心信息,包括虚拟机的状态、配置信息等。工作:每个 cell 拥有自己的数据库,存储着属于该 cell 的实例数据。
nova-compute、nova-conductor等服务会与对应的 cell 数据库交互,从而保持各个 cell 之间的数据隔离并提高可扩展性。7. cell0 数据库:
功能:
cell0 数据库是一个特殊的数据库,它与其他 cell 数据库非常相似,但只存储那些失败的实例。工作:当一个实例无法在正常的计算节点上调度时,它会被暂时存储在
cell0中。这个数据库专门用于存储无法调度的实例,直到它们能够成功调度到其他的计算节点上。cell0并没有计算节点,因此它主要作为一个临时存储失败实例的地方。8. 消息队列:
功能:消息队列(通常使用 RabbitMQ 或其他消息队列)是 OpenStack 服务之间进行通信的机制。
工作:服务之间通过消息队列进行 RPC 通信,例如,
nova-api会通过消息队列将调度任务发送到nova-scheduler,并通过nova-conductor与nova-compute进行通信。通过这种方式,服务之间可以解耦并异步处理请求。总结:
这个部署架构描述了 OpenStack Nova 在多组件环境下如何工作,以及各个服务如何协同配合以管理计算资源、虚拟机调度和管理。各个组件的作用如下:
nova-api提供外部 API 接口。
nova-scheduler和placement决定实例应该部署在哪个计算节点。
nova-conductor执行长时间运行的任务,解耦数据库访问。
nova-compute负责虚拟机的实际管理。数据库和消息队列在各个服务之间传递必要的信息和请求。
通过这些服务的协作,OpenStack Nova 能够高效地管理大规模的计算资源,并实现弹性扩展。
在较小的部署中,通常会有一个共享的消息队列和一个数据库服务器,该服务器托管 API 数据库、单个 cell 数据库以及所需的 cell0 数据库(a single message queue that all services share and a single database server which hosts the API database, a single cell database, as well as the required cell0 database.)。因为我们只有一个“真实”的 cell,所以这被认为是一个“单一 cell 部署”。(本次的OpenStack Yoga安装就是采用较小的部署,在controller节点安装了1个MQ软件,给所有服务使用;一个mysql database软件,里面安装了nova-api db,nova db,nova-cell0 db,nova db也就是cell1的db,还有其他db)。
在较大的部署中,我们可以选择使用多个 cell 来进行分片。在这种配置中,虽然仍然只有一个全局 API 数据库,但每个 cell 都会有一个 cell 数据库(存储大多数实例信息),每个 cell 数据库包含整个部署中一部分实例的数据,并且每个 cell 都会有单独的消息队列和 nova-conductor 实例。还会有一个额外的 nova-conductor 实例,称为超级 conductor,用于处理 API 级操作。
在这些较大的部署中,每个 nova 服务将使用特定于 cell 的配置文件,每个配置文件至少会指定一个消息队列端点(即 transport_url)。大多数服务还会包含数据库连接配置信息(即 database.connection),而需要访问全局路由和调度信息的 API 级服务,还需要配置以访问 API 数据库(即 api_database.connection)。
详细讲解:
这段文字描述了在 OpenStack Nova 部署中,单一 cell 部署 和 多 cell 部署 的不同配置和架构。我们可以根据部署的规模选择不同的架构来满足扩展性和高可用性的要求。下面是对每部分的详细解释。
1. 单一 Cell 部署:
在较小的 OpenStack 环境中,通常只有一个计算节点池和数据库实例,所有的服务(包括 API 服务、计算服务、调度服务等)共享一个 消息队列 和一个数据库。
单一 cell 部署意味着只有一个 cell 数据库,存储所有实例的信息。这里没有进行数据分片,所有的实例信息都集中在一个数据库中。这种部署适用于规模较小的 OpenStack 环境。
在 单一 cell 部署 中:
只有 一个全局 API 数据库,用于存储实例的位置、状态等信息。
一个 cell 数据库 存储所有实例的详细数据。
一个 cell0 数据库 只包含未能成功调度的实例信息,作为一个临时存储区。
共享消息队列:所有服务使用相同的消息队列进行通信,这简化了配置,但可能会成为性能瓶颈。
2. 多 Cell 部署:
当 OpenStack 部署变得更大时,单一数据库和单个消息队列可能会成为瓶颈,因此可以选择 多 cell 部署。在多 cell 部署中,系统将多个计算节点分成多个 cell,每个 cell 都有自己的数据库、消息队列和
nova-conductor实例。在 多 cell 部署 中:
依然有一个全局的 API 数据库,用于存储全局的路由信息、调度信息和 API 级别的数据。
每个 cell 数据库 存储该 cell 下所有实例的具体数据。每个 cell 包含整个部署的一部分实例数据,不同的 cell 数据库负责不同的计算节点池。
每个 cell 都有独立的 消息队列 和 nova-conductor 实例,这使得各个 cell 可以独立地处理实例调度、资源管理等任务。
超级 conductor(super conductor)是一个额外的
nova-conductor实例,用于处理 API 级操作,特别是跨 cell 的任务和全局数据操作。3. 配置文件和服务:
在多 cell 部署中,为了确保每个 cell 独立运行,每个 Nova 服务都会使用 特定于 cell 的配置文件。这些配置文件包括:
消息队列端点(
transport_url):每个服务的配置文件中都会指定一个消息队列的端点,这样服务就知道如何通过消息队列与其他服务进行通信。每个 cell 使用自己的消息队列来进行内部通信,但仍然通过全局 API 数据库进行必要的协调。数据库连接(
database.connection):除了消息队列,很多服务还需要指定数据库连接信息,告诉服务要连接哪个 cell 的数据库。例如,每个 cell 的nova-compute、nova-conductor等服务会配置连接到其对应的 cell 数据库。API 数据库连接(
api_database.connection):某些服务(如nova-api和nova-scheduler)需要访问全局的 API 数据库,以便获取关于实例调度的全局信息。因此,它们的配置文件中会指定一个连接到全局 API 数据库的连接字符串。4. 多 Cell 部署的优势:
扩展性:每个 cell 可以独立管理一组计算节点和实例数据,这样可以轻松扩展到数千个节点,减少单个数据库的负载。
性能优化:每个 cell 拥有独立的消息队列和
nova-conductor实例,减少了对单一服务的依赖,使得资源调度和任务处理更加高效。故障隔离:单个 cell 发生故障时,不会影响到其他 cell 的运行,因为每个 cell 都有独立的数据库、消息队列和计算节点。
灵活的资源调度:每个 cell 可以根据自己的资源和需求进行调度,适应不同的数据中心和区域要求。
5. 总结:
单一 cell 部署 适用于小规模的环境,所有服务共享一个数据库和消息队列。
多 cell 部署 适用于大规模环境,通过分片和独立的配置提供更好的扩展性、性能和故障隔离。
在 多 cell 部署 中,每个服务使用特定的配置文件来连接消息队列和数据库,同时需要通过全局 API 数据库协调跨 cell 操作。
API 级服务需要能够与所有 cell 中的其他服务进行通信。由于它们只配置了一个 transport_url 和 database.connection,因此它们通过在 API 数据库 中查找其他 cell 的信息,具体通过叫做 cell mappings 的记录来实现。
详细讲解:
这段话讲述了 API 级服务(如
nova-api、nova-scheduler等)如何与不同 cell 中的服务进行通信,以及如何通过查找 cell mappings 来获取其他 cell 的信息。1. API 级服务与所有 cell 通信的需求:
在 OpenStack 部署中,API 级服务 需要能够与所有 cell 中的服务进行通信。这是因为 OpenStack 的服务通常是分布式的,特别是在 多 cell 部署 中,实例、计算资源和调度任务会分布在不同的 cell 中。为了确保 API 级服务能够协调并管理整个 OpenStack 部署,它们需要知道如何访问每个 cell 中的服务。
API 级服务(如
nova-api)并不直接和每个 cell 中的数据库或消息队列进行交互,而是通过 API 数据库 和 cell mappings 来间接获取所需的连接信息。2. 单个配置的 transport_url 和 database.connection:
每个 API 级服务配置文件中只会有一个 transport_url 和 database.connection 配置。这些配置项指定了服务所使用的 消息队列 和 数据库,但是这些配置项只对应某一个特定的 cell。
由于 API 级服务需要能够与多个 cell 进行通信,它们并不会硬编码每个 cell 的连接信息,而是依赖于 API 数据库 中的 cell mappings 记录来动态获取其他 cell 的相关信息。
3. cell mappings 记录:
cell mappings 是存储在 API 数据库 中的一种记录,包含了关于每个 cell 的配置信息。它们通常包括每个 cell 的 消息队列端点(
transport_url)、数据库连接(database.connection)等。通过查找 cell mappings,API 级服务能够动态地知道如何与其他 cell 的服务进行通信。这意味着,API 级服务不需要在配置中直接定义每个 cell 的具体连接信息,而是通过查找这些 cell mappings 来决定如何访问其他 cell 的服务。
4. 如何工作:
当 API 级服务 需要与其他 cell 的服务进行交互时,它会访问 API 数据库,并通过查询 cell mappings 来获取该 cell 的 消息队列 和 数据库连接 信息。
例如,假设 nova-api 需要调度一个实例到
cell2,它会查询 cell mappings 来获取cell2的 transport_url 和 database.connection,然后使用这些信息与cell2的服务进行通信。5. 多 Cell 部署中的作用:
在 多 cell 部署 中,由于每个 cell 都可能有独立的资源、调度和计算服务,API 级服务需要能够跨越所有 cell 进行操作。例如,nova-scheduler 需要了解所有 cell 中的资源情况,以便在多个 cell 之间进行实例调度。
cell mappings 在这种部署中起到了关键作用,它们确保了 API 级服务能够查询到每个 cell 的配置信息,并进行必要的跨 cell 操作。
6. 总结:
API 级服务 需要与 所有 cell 的服务进行通信,但它们只配置了一个 transport_url 和 database.connection。
通过查询 API 数据库 中的 cell mappings,它们能够获取其他 cell 的连接信息,确保跨 cell 通信的能力。
cell mappings 存储了每个 cell 的 消息队列端点 和 数据库连接 等信息,是 API 级服务与多个 cell 服务之间实现通信的桥梁。
2、Nova服务布局
每个服务(nova service)通常具有明确定义的通信模式,这决定了它们在部署中的布局。在一个小型/简单的场景中,这些规则的影响不大,因为所有服务可以在一个单一的消息总线和一个单一的 cell 数据库中相互通信。然而,随着部署规模的扩大,扩展性和安全性问题可能促使服务的分离和隔离。
详细讲解:
这段话描述了 OpenStack 部署中各个服务之间的通信模式及其如何随着部署规模的增长而发生变化,尤其是在 扩展性 和 安全性 方面的考虑。
1. 服务的通信模式:
OpenStack 中的每个服务(如
nova-api、nova-compute、nova-scheduler等)都有一个 通信模式,即它们如何通过消息队列(如 RabbitMQ)和数据库(如 MySQL)进行交互。每个服务之间通过特定的协议(如 RPC)进行通信。在 小型或简单的部署 中,所有服务通常会共享一个 消息总线(即消息队列)和一个 单一的 cell 数据库。这种模式下,服务之间的通信是简单且直接的,它们能够轻松地相互访问和协作。
2. 小型部署的通信模式:
在 小型/简单的场景 中,OpenStack 的服务通常不会面临很大的负载或扩展问题。所有服务都可以通过一个 共享的消息总线 进行通信,且所有实例数据都存储在一个 单一的 cell 数据库 中。
由于服务间的通信没有太多复杂的隔离要求,部署和配置较为简单。这使得在这种场景下,通信模式的规则(即各个服务如何配置消息队列和数据库连接)对部署的影响相对较小。
3. 随着部署规模的增长:
当 OpenStack 的部署规模增大时,问题就开始出现了。服务的数量增加,负载也随之增大。在这种情况下,单一的消息总线和单一的数据库可能成为瓶颈。
此外,扩展性 和 安全性 的问题开始变得更加重要。为了应对更大规模的计算资源和更高的并发需求,部署可能需要采用 多 cell 部署,即将不同的服务和实例分配到不同的 cell 中。
在 多 cell 部署 中,不同的 cell 之间通常会有更严格的 隔离,每个 cell 都有自己的消息队列、数据库和计算节点池。服务之间的通信也可能被分隔开来,这样可以更有效地管理资源、优化性能,并提高安全性。
4. 扩展性和安全性驱动的服务分离与隔离:
扩展性:当部署规模增大时,服务的分离 允许每个 cell 独立扩展,避免了单个服务或单一数据库的瓶颈。通过将服务分配到不同的 cell 中,可以更灵活地处理计算资源的需求,支持更多的节点和实例。
安全性:在多 cell 部署中,服务的 隔离 提高了安全性。例如,敏感数据和关键服务可以被放置在特定的 cell 中,而不与其他 cell 共享资源。这种隔离可以减少服务之间的不必要干扰,并降低潜在的安全风险。
另外,不同的 cell 可以使用不同的消息队列、数据库和网络配置,这使得每个 cell 更容易控制和保护自己的资源,避免被其他 cell 影响。
5. 总结:
在 小型部署 中,OpenStack 服务通过单一的消息总线和数据库通信,通信规则的影响较小,配置简单。
随着部署规模的增长,尤其是 扩展性 和 安全性 的考虑,部署模式需要进行优化。这可能会促使服务 分离 和 隔离,例如通过 多 cell 部署 来实现更高效的资源管理和更好的安全控制。
扩展性 和 安全性 是推动服务分离和隔离的主要因素,它们有助于优化性能、提高可维护性,并降低潜在的风险。
2.1 Single cell
2.1.1 服务布局
这是一个单cell部署中基本服务的示意图,以及它们之间的关系(即通信路径):
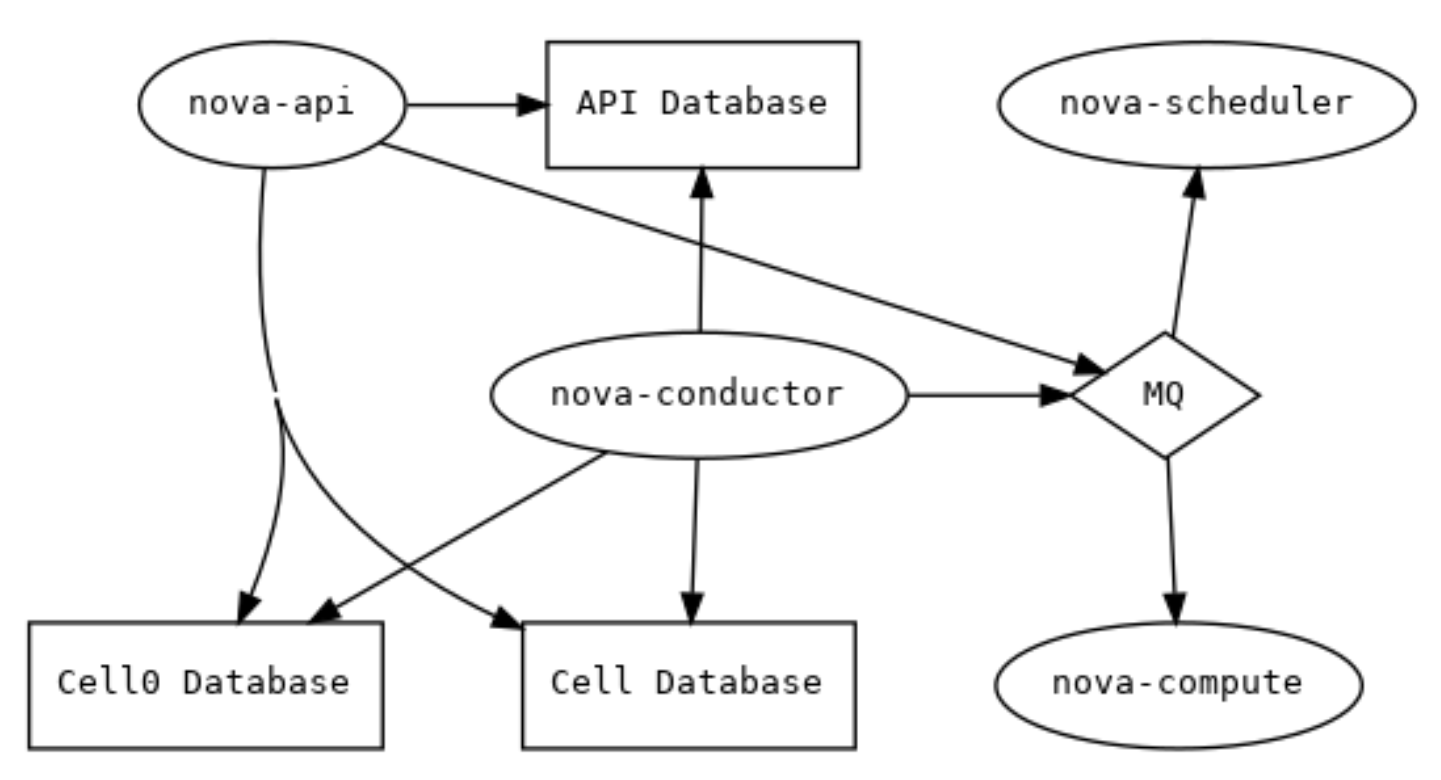
所有的服务都被配置为通过同一个消息总线进行通信,并且只有一个 cell 数据库用于存储实时实例数据。cell0 数据库存在(并且是必须的),但是由于没有计算节点连接到它,这仍然是一个“单一 cell”部署。
在 单 cell 部署 中,OpenStack 的服务相互连接,形成了一个简单的通信架构。所有服务共享一个消息队列(图中MQ)和数据库(Cell Database),因此配置和管理相对简单。但随着部署规模的增长,这种结构可能变得不再适用,可能需要拆分为多个 cell 以应对高负载和安全需求。
2.1.2 服务调用关系
在 单一 cell 部署 中,以创建一个虚拟机(VM)场景为例,涉及到的服务及其相互调用关系如下:
-
nova-api:-
用户通过
nova-api发起创建虚拟机的请求。 -
nova-api接收到请求后,会首先与 API 数据库 交互,记录虚拟机的创建信息和状态。
-
-
nova-scheduler:-
接着,
nova-api会将请求转发给nova-scheduler。nova-scheduler的任务是决定虚拟机应该调度到哪个计算节点(nova-compute)上。 -
nova-scheduler会根据集群的资源情况(如 CPU、内存、存储等)选择一个合适的计算节点。
-
-
nova-conductor:-
一旦
nova-scheduler做出调度决策,nova-scheduler会通过 消息队列(MQ) 向nova-conductor发送消息。nova-conductor会处理实际的任务,例如访问数据库、获取必要的资源信息,并进行其他需要长时间运行的操作。 -
nova-conductor会与 Cell 数据库 和 Cell0 数据库 交互,更新相关信息,确保虚拟机创建的操作得到正确的记录。
-
-
nova-compute:-
最后,
nova-conductor将调度信息传递给nova-compute,指示它在选定的计算节点上启动虚拟机。 -
nova-compute负责在物理计算节点上实际启动虚拟机,配置网络、存储、以及其他虚拟机所需的资源。
-
具体的调用流程:
-
用户通过
nova-api发起虚拟机创建请求。 -
nova-api记录请求信息,并通过 API 数据库 更新实例状态。 -
nova-api将请求转发给nova-scheduler。 -
nova-scheduler选择合适的计算节点后,将任务发送给nova-conductor。 -
nova-conductor在 Cell 数据库 中查找资源,更新状态,并与 Cell0 数据库 交互(如果实例调度失败)。 -
最后,
nova-conductor通过消息队列向nova-compute发送创建虚拟机的命令。 -
nova-compute在计算节点上启动虚拟机,并将状态反馈给nova-conductor。
通过这个流程,所有相关的服务和数据库共同协作,确保虚拟机的创建操作顺利进行,并且实例的状态在不同的组件间保持同步。
2.2 Multiple cells
2.2.1 服务布局
为了将服务分片到多个 cells,必须进行若干操作。首先,消息总线必须按与 cell 数据库相同的方式进行拆分。其次,必须为 API 级别的服务运行一个专门的 conductor,具有访问 API 数据库的权限并拥有一个专用的消息队列。我们称之为 super conductor,以区别于每个 cell 的 conductor 节点。
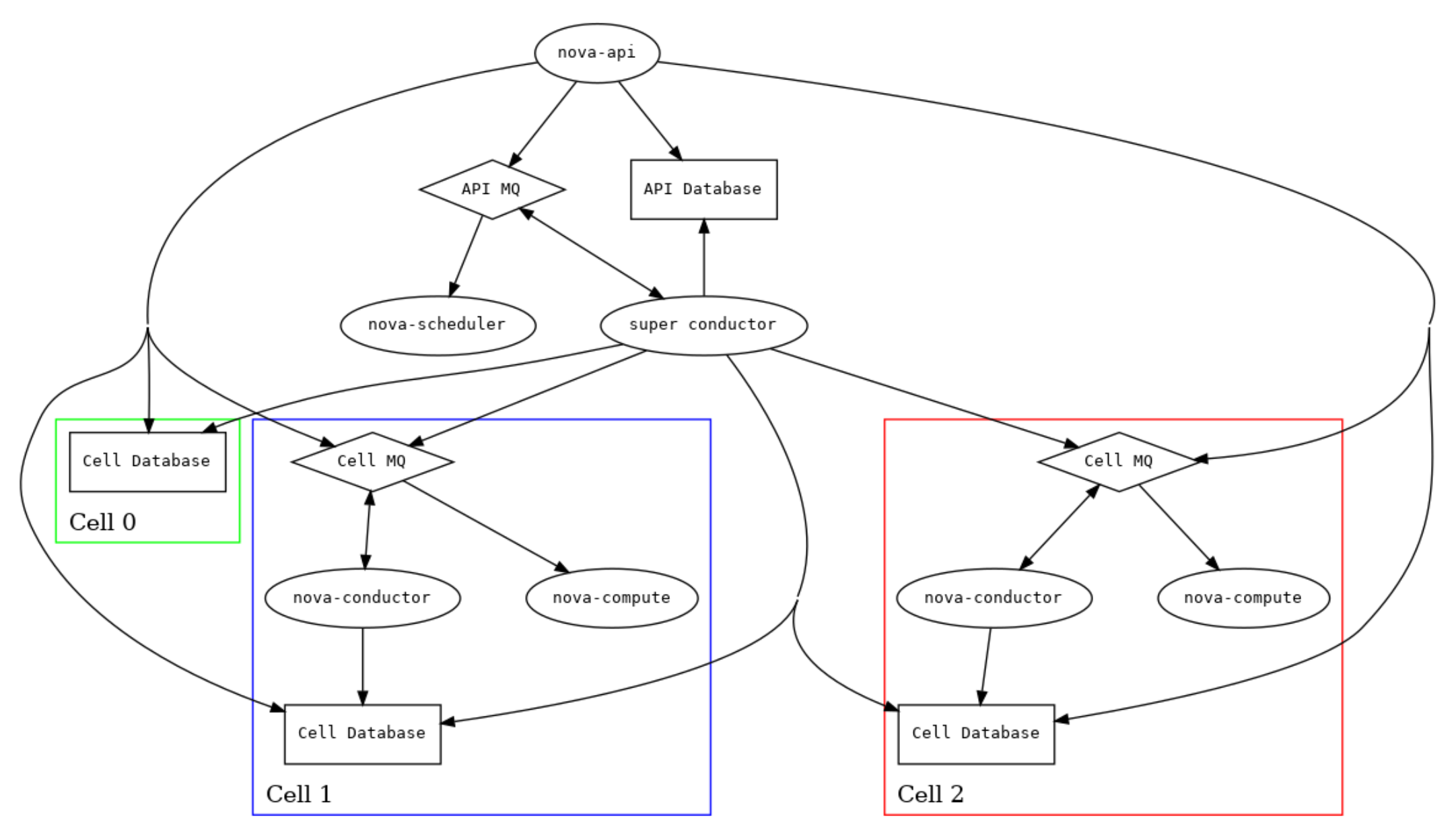
详细讲解:
这段话描述了如何将 OpenStack 的服务分片(shard)到多个 cell 中,以及如何配置相应的服务以支持这种多 cell 部署。下面是详细的解析:
1. 将消息总线拆分为多个部分:
在 单一 cell 部署中,所有服务共享一个 消息总线(例如,RabbitMQ)。但在 多 cell 部署中,为了将服务分布到多个 cell 中,每个 cell 都会有自己的消息总线(或者至少是不同的消息队列)。这就意味着消息总线会根据 cell 数据库 的划分进行拆分,使得每个 cell 内的服务能够独立地通过本地的消息队列进行通信。
这种拆分有助于确保每个 cell 的服务之间的通信更加高效,并且减少了跨 cell 的通信延迟。
2. 专门的 conductor 为 API 级别服务提供支持:
在多 cell 部署中,除了每个 cell 运行一个 conductor 服务外,还需要一个专门的 super conductor 来处理 API 级别的操作。API 级别服务(例如
nova-api和nova-scheduler)需要访问全局的 API 数据库,并且它们需要处理来自不同 cell 的信息。super conductor 主要负责协调各个 cell 之间的操作,它与其他 cell 中的 conductor 区别开来,作用是处理更高层次的请求,确保 API 级别服务能够跨 cell 正常工作。
3. super conductor 的作用和位置:
super conductor 是与每个 cell 内的 conductor 节点不同的,它主要服务于全局操作,如查询、调度实例的跨 cell 操作等。它是一个独立的服务,具有访问全局 API 数据库 和独立消息队列的权限。
super conductor 不直接管理实例,它的职责是协调多个 cell 之间的服务调用,确保整个 OpenStack 环境在多 cell 部署下能够一致运行。
4. 每个 cell 的 conductor 节点:
每个 cell 都会有自己的 conductor 节点,负责与本 cell 相关的资源和实例的管理。它的作用是处理与计算节点和存储节点的交互,不同的 cell 会有不同的 conductor 节点,独立管理本 cell 内的资源。
每个 cell 的 conductor 节点与 super conductor 不同,前者专注于处理本 cell 内部的任务,而后者则负责协调整个 OpenStack 环境中的操作,尤其是在多个 cell 之间的跨 cell 操作。
5. 总结:
在 多 cell 部署 中,为了有效地管理跨 cell 的服务和资源,必须将消息总线拆分为多个部分,每个 cell 拥有独立的消息队列。此外,还需要一个 super conductor,它与各个 cell 中的 conductor 节点不同,主要负责协调 API 级别的全局操作,确保整个系统的稳定性和一致性。
这种结构有助于大规模 OpenStack 环境的扩展,确保每个 cell 的负载得到合理分配,同时保证服务间的高效通信。
2.2.2 服务调用关系
在多 cell 部署 中,以创建一个虚拟机(VM)场景为例,涉及到的服务及其相互调用关系如下:
1. 用户通过 nova-api 创建虚拟机请求
-
用户通过
nova-api提交创建虚拟机的请求。 -
nova-api是接收外部请求的接口,它提供 RESTful API 供用户进行虚拟机的创建、删除等操作。
2. nova-api 通过 API MQ 与 super conductor 通信
-
当
nova-api接收到虚拟机创建请求后,它会通过 API MQ 向 super conductor 发送消息。 -
API MQ 是一个 全局消息队列,用于跨 cell 服务之间的通信。它确保 API 服务(如
nova-api)能够与 super conductor 和其他服务进行通信。
3. super conductor 访问 API 数据库
-
super conductor 是一个特殊的 conductor 实例,它主要负责处理 API 级别的操作,例如跨 cell 的调度任务。与每个 cell 的独立 conductor 节点不同,super conductor 负责协调 API 请求和管理跨 cell 操作。
-
super conductor 通过访问 API 数据库 来获取有关实例调度、资源分配等的全局信息。它还会在 API 数据库中更新虚拟机的状态。
4. super conductor 向相应的 Cell MQ 发送调度请求
-
super conductor 根据 API 请求将调度任务传递给相应的 cell,并通过 Cell MQ 与目标 cell conductor 进行通信。每个 cell 都有自己的 消息队列(Cell MQ),用于该 cell 内部服务的通信。
-
super conductor 会通过 Cell MQ 向 cell conductor 发送虚拟机创建的指令,告知该 cell 执行具体的虚拟机创建操作。
5. cell conductor 选择计算节点并与 nova-compute 交互
-
cell conductor 负责与 cell 数据库 和 nova-compute 进行交互,执行虚拟机的实际创建操作。
-
cell conductor 会根据资源需求选择一个适合的计算节点(
nova-compute)。它会与目标计算节点的nova-compute节点进行通信,指示计算节点启动虚拟机。 -
cell conductor 还会更新 cell 数据库,记录实例的状态。
6. nova-compute 启动虚拟机
-
nova-compute 在目标计算节点上启动虚拟机。它与 Hypervisor(如 KVM、Xen)进行交互,分配虚拟机的资源(如 CPU、内存、存储等)并启动虚拟机实例。
-
一旦虚拟机启动成功,
nova-compute会将结果返回给 cell conductor,并通过消息队列通知 super conductor 虚拟机创建成功。
7. super conductor 更新数据库
-
super conductor 会更新数据库中的虚拟机状态,将其标记为“已创建”或“已启动”,并将这些信息同步到 API 数据库。
-
最后,super conductor 将虚拟机创建的成功信息通过 API MQ 返回给 nova-api,通知用户虚拟机创建完成。
具体的调用流程:
-
nova-api接收用户请求,发送虚拟机创建任务到 super conductor。 -
super conductor 通过 API MQ 获取请求并访问 API 数据库,根据调度需要向 cell conductor 发送请求。
-
cell conductor 根据资源选择目标计算节点,并与 nova-compute 进行交互,启动虚拟机。
-
nova-compute 在计算节点上启动虚拟机,并将结果返回给 cell conductor。
-
super conductor 更新数据库中的虚拟机状态,并将成功信息返回给 nova-api。
各个服务角色解释:
API MQ:用于 nova-api 与 super conductor 之间的通信,确保 API 请求能够传递给处理虚拟机创建的高层服务。
Cell MQ:用于 super conductor 与各个 cell conductor 之间的通信。每个 cell 都有自己的消息队列,用于处理该 cell 内部的服务调用。
super conductor:跨 cell 的 conductor,处理 API 级别的任务,协调不同 cell 的服务操作。
cell conductor:每个 cell 中的 conductor 节点,负责与本 cell 内部的 nova-compute 和数据库进行交互,执行实例创建等任务。
nova-compute:在计算节点上执行虚拟机的创建操作,启动虚拟机并管理其生命周期。
这种设计使得 OpenStack 在多 cell 部署下能够高效地调度资源、隔离各 cell 的服务、并且确保跨 cell 的操作协调和一致性。
3、Nova数据库布局
所有的 Nova 部署都是Cell v2的部署方式,必须拥有并配置以下数据库:
-
API 数据库
-
一个特殊的 cell 数据库,称为 cell0
-
一个(或将来更多的)cell 数据库
因此,一个小型的 Nova 部署(Single cell)将有一个 API 数据库,一个 cell0 数据库,以及我们在此称之为 cell1 的数据库。高层次的跟踪信息存储在 API 数据库中。那些从未调度成功的实例会被放到 cell0 数据库中,实际上它是一个存放调度失败实例的“墓地”。所有成功运行的实例则存储在 cell1 中。
详细讲解:
这段话讲述了 cells v2 架构在 Nova 部署中的应用和数据库配置要求。根据 OpenStack Nova 的 cells v2 架构,即使是 单一 cell 部署,也需要进行相关的 cells 配置,并确保一定的数据库配置。
1. 所有部署都是 cells v2 部署
现在,OpenStack Nova 的所有部署都基于 cells v2 架构。这意味着,不管是 单一 cell 部署 还是 多 cell 部署,都需要使用 cells v2 的配置和数据库结构。
cells v2 架构让 Nova 支持将计算节点分割成多个 cell,每个 cell 具有独立的数据库和资源池。这样可以提高部署的可扩展性、资源隔离性和容错性。
2. 配置要求
由于所有部署都需要支持 cells v2,即使是单个 cell 部署,也需要进行一定的 cells 配置。
配置内容不仅仅是在 nova.conf 配置文件中设置,还包括在数据库中添加相关记录。特别是,数据库中需要有用于 cell 的标识、实例状态等信息。
3. 所需数据库
在 cells v2 架构中,所有 Nova 部署都需要以下数据库:
API 数据库:这是一个全局数据库,用于存储 Nova API 和 Nova 调度器 需要的高层次信息(如虚拟机的调度状态、位置等)。所有实例的高层次元数据和调度状态都存储在这个数据库中。
cell0 数据库:这是一个特殊的 cell 数据库。它存储那些没有成功调度的实例,即那些由于某些原因无法启动的实例。可以把它看作是一个“墓地”数据库,用来存放那些在调度过程中失败的虚拟机实例。通常,调度失败的实例(如由于计算节点资源不足或其他错误而无法启动的实例)会被暂时存储在 cell0 数据库中,直到它们能够被重新调度。
cell 数据库(如 cell1):每个实际使用的 cell 都会有自己的数据库(例如 cell1)。在这个数据库中,会存储 所有成功启动的实例 的数据。每个 cell 都有自己的数据库,用于存储该 cell 内部的虚拟机实例的状态和资源信息。
4. 单一 cell 部署的数据库
在 单一 cell 部署 中,会有以下三种数据库:
API 数据库:存储全局的调度信息和实例状态。
cell0 数据库:存储调度失败的实例。
cell1 数据库:存储所有成功调度并正在运行的虚拟机实例。
这种配置对于 小型部署 非常适用,因为它通过将所有实例数据存储在一个 cell1 数据库中,实现了较为简单的管理。
5. 虚拟机的存储和调度
API 数据库 主要存储的是关于虚拟机和实例的高层信息,例如实例的调度状态、位置等。
cell0 数据库 仅包含那些未能成功调度的虚拟机。即,如果 Nova 无法将一个实例调度到一个合适的计算节点,实例信息就会被存放在 cell0 中,等待重新调度。
cell1 数据库 存储的是所有已经成功调度和正在运行的虚拟机的信息。这些实例可以跨多个计算节点,
nova-compute服务会定期与 cell1 数据库同步虚拟机状态。6. 总结
cells v2 架构不仅在 多 cell 部署 中有应用,在 单一 cell 部署 中也必须进行一些基本的配置,尤其是数据库配置。
在 单一 cell 部署 中,Nova 部署会涉及 API 数据库、cell0 数据库 和 cell1 数据库,它们分别用于存储全局的调度信息、失败的实例信息和正在运行的实例信息。
这些数据库的设计确保了 OpenStack 在 单一 cell 和 多 cell 部署中都能够高效地进行资源管理和调度,同时处理失败的实例并保证系统的高可用性。
通过这种架构,即使是小规模的部署,也能保证高效的资源管理,并为未来扩展到多 cell 部署做好准备。
4、Nova安装笔记回顾
在《OpenStack Yoga版安装笔记(十二)nova(下)》中,OpenStack Nova 采用 Cells v2 架构,配置为单一cell(Single cell)部署模式。
1、创建nova_api,nova,nova_cell0数据库:
MariaDB [(none)]> CREATE DATABASE nova_api;
Query OK, 1 row affected (0.001 sec)MariaDB [(none)]> CREATE DATABASE nova;
Query OK, 1 row affected (0.000 sec)MariaDB [(none)]> CREATE DATABASE nova_cell0;
Query OK, 1 row affected (0.000 sec)2、编辑/etc/nova/nova.conf,配置数据库和MQ连接信息
[api_database]
# ...
connection = mysql+pymysql://nova:NOVA_DBPASS@controller/nova_api[database]
# ...
connection = mysql+pymysql://nova:NOVA_DBPASS@controller/nova[DEFAULT]
transport_url = rabbit://openstack:openstack@controller:5672/3、同步 Nova API 数据库架构:
root@controller:~# su -s /bin/sh -c "nova-manage api_db sync" nova
- api_db sync 是同步 Nova API 数据库架构的子命令。它应用任何待处理的数据库迁移(架构更改),以确保 API 数据库与当前版本的 Nova 所需的结构匹配。
4、在 Nova cell_v2 架构中注册特殊的 cell0:
root@controller:~# su -s /bin/sh -c "nova-manage cell_v2 map_cell0" nova
- cell_v2 map_cell0 是一个子命令,用于在 Nova API 数据库中为 cell0 创建映射 ,将其注册为用于处理调度失败的实例的特殊 cell。
5、在 Nova cell_v2 架构中创建一个名为 cell1 的新单元:
root@controller:~# su -s /bin/sh -c "nova-manage cell_v2 create_cell --name=cell1 --verbose" nova
Modules with known eventlet monkey patching issues were imported prior to eventlet monkey patching: urllib3. This warning can usually be ignored if the caller is only importing and not executing nova code.
--transport-url not provided in the command line, using the value [DEFAULT]/transport_url from the configuration file
--database_connection not provided in the command line, using the value [database]/connection from the configuration file
8b1967df-7901-42b3-8b03-fc4e884f490d
root@controller:~#
- cell_v2 create_cell 是在 Nova cell_v2 体系结构中创建新单元的子命令。
6、将 Nova 主数据库架构与已安装的 Nova 软件定义的最新版本同步:
root@controller:~# su -s /bin/sh -c "nova-manage db sync" nova
- db sync 是同步 Nova 主数据库架构的子命令。它会应用任何待处理的数据库迁移(架构更改),以确保数据库与当前版本的 Nova 所需的结构匹配。
7、发现和注册 Nova cell_v2 架构中的计算节点(nova-compute):
root@controller:~# su -s /bin/sh -c "nova-manage cell_v2 discover_hosts --verbose" nova
Modules with known eventlet monkey patching issues were imported prior to eventlet monkey patching: urllib3. This warning can usually be ignored if the caller is only importing and not executing nova code.
Found 2 cell mappings.
Skipping cell0 since it does not contain hosts.
Getting computes from cell 'cell1': 8b1967df-7901-42b3-8b03-fc4e884f490d
Checking host mapping for compute host 'compute1': 205c89e0-fb82-4def-a0f6-bfe4b120ab79
Creating host mapping for compute host 'compute1': 205c89e0-fb82-4def-a0f6-bfe4b120ab79
Found 1 unmapped computes in cell: 8b1967df-7901-42b3-8b03-fc4e884f490d
root@controller:~# root@controller:~# nova-manage cell_v2 list_hosts --cell_uuid 8b1967df-7901-42b3-8b03-fc4e884f490d
Modules with known eventlet monkey patching issues were imported prior to eventlet monkey patching: urllib3. This warning can usually be ignored if the caller is only importing and not executing nova code.
+-----------+--------------------------------------+----------+
| Cell Name | Cell UUID | Hostname |
+-----------+--------------------------------------+----------+
| cell1 | 8b1967df-7901-42b3-8b03-fc4e884f490d | compute1 |
+-----------+--------------------------------------+----------+
root@controller:~#
root@controller:~# su -s /bin/sh -c "nova-manage cell_v2 discover_hosts --verbose" nova
Modules with known eventlet monkey patching issues were imported prior to eventlet monkey patching: urllib3. This warning can usually be ignored if the caller is only importing and not executing nova code.
Found 2 cell mappings.
Skipping cell0 since it does not contain hosts.
Getting computes from cell 'cell1': 8b1967df-7901-42b3-8b03-fc4e884f490d
Found 0 unmapped computes in cell: 8b1967df-7901-42b3-8b03-fc4e884f490d
root@controller:~#
root@controller:~# nova-manage cell_v2 list_hosts --cell_uuid 8b1967df-7901-42b3-8b03-fc4e884f490d
Modules with known eventlet monkey patching issues were imported prior to eventlet monkey patching: urllib3. This warning can usually be ignored if the caller is only importing and not executing nova code.
+-----------+--------------------------------------+----------+
| Cell Name | Cell UUID | Hostname |
+-----------+--------------------------------------+----------+
| cell1 | 8b1967df-7901-42b3-8b03-fc4e884f490d | compute1 |
+-----------+--------------------------------------+----------+
- cell_v2 discover_hosts 是一个子命令,用于扫描尚未在 Cell 数据库中注册的计算主机(运行 nova-compute 的服务器 ),并将它们映射到相应的 Cell。