当 LLM 遇上真实世界:MCP-Universe 如何撕开大模型 “工具能力” 的伪装?
本次文章基于:
论文MCP-Universe: Benchmarking Large Language Models with Real-World Model Context Protocol Servers的作者来自 Salesforce AI Research,发布时间为 2025 年 8 月 20 日 。
- 作者:Ziyang Luo、Zhiqi Shen、Wenzhuo Yang、Zirui Zhao、Prathyusha Jwalapuram、Amrita Saha、Doyen Sahoo、Silvio Savarese、Caiming Xiong、Junnan Li。
- 时间:arXiv 平台上显示的版本时间为 2025 年 8 月 20 日(“2025-08-20” ),文中提及的相关实验和研究成果也是基于这一时期 。此外,相关的 github 项目和网页介绍,也基本围绕 2025 年 8 月左右的时间进行发布和讨论,进一步印证了论文的时间线 。
在 AI 圈,“大模型能调用工具” 早已不是新鲜事 —— 从查天气到写代码,仿佛只要给个 API,LLM 就能无所不能。但如果你仔细观察就会发现,多数所谓的 “工具调用评测”,要么是用简化的模拟环境,要么是重复老掉牙的数学题、代码题,根本没触及真实世界的复杂场景。直到 Salesforce AI Research 推出 MCP-Universe benchmark,才算真正把 LLM 扔进了 “工具使用的修罗场” 🥷。
一、先搞懂:为什么需要 MCP-Universe?
要理解这个 benchmark 的价值,得先从一个核心问题入手:现在的 LLM 工具评测,到底差在哪儿?
论文里直接点出了现有方案的三大 “痛点”:
- 场景太假:比如 MCP-RADAR 只是把 HumanEval(代码题)、GSM8k(数学题)套上 MCP 壳子,和真实工作里 “查实时股价 + 分析财报”“规划跨城路线 + 找高评分餐厅” 完全不是一回事;
- 缺实时性:MCPEval、LiveMCPBench 用 “LLM 当裁判” 的方式打分,但像 “明天的航班价格”“实时 GitHub issue 数量” 这类动态数据,静态的 LLM 知识根本评不准;
- 工具太浅:MCPWorld 依赖图形界面(GUI),却没覆盖 MCP 协议最核心的 “多工具协同”—— 真实场景里,你不可能只用一个工具完成任务。
而 MCP(Model Context Protocol)本身是个好东西,被业内称为 “AI 界的 USB-C” 🔌—— 它能让 LLM 统一对接各种外部工具(地图、代码仓库、财务系统等),不用再为每个工具写专属接口。可偏偏没有一个像样的评测,能检验 LLM 在真实 MCP 环境下的能力。
于是,MCP-Universe 来了:它直接对接 11 个真实的 MCP 服务器,覆盖 6 大核心领域,231 个任务全是 “打工人天天碰的活”,比如用 GitHub 管理代码分支、用 Yahoo Finance 算股票收益、用 Blender 做 3D 建模。这一下,就把 LLM 从 “模拟题考场” 拉到了 “真实工作现场”。
二、MCP-Universe 的 “狠活”:真实世界的三大考验
这个 benchmark 最绝的地方,是它精准命中了 LLM 在真实工具使用中的三大核心难题,每一个都戳中了现有大模型的 “软肋”。
1. 考验 1:“长上下文” 压垮 LLM—— 对话越长,脑子越乱 🧠
你有没有遇到过:和 AI 聊多了,它会忘记前面说的关键信息?这在工具调用里更致命。
论文里做了个实验:在 “路线规划”“浏览器自动化” 这类任务中,每多一步工具交互,输入 token 数就会暴涨。比如用 Google Maps 查餐厅,返回的地址、评分、路线信息一堆,聊到第 10 步,上下文长度可能就超出很多模型的承载极限。
更扎心的是,论文尝试用 “总结 agent” 压缩上下文 —— 结果呢?GPT-4.1 在路线规划任务里表现好了点,但在财务分析、浏览器自动化里反而更差了。这说明:简单的 “剪枝” 解决不了长上下文问题,LLM 需要的是 “记住关键信息 + 忽略噪音” 的真本事,而不是单纯的 “压缩文本”。
2. 考验 2:“陌生工具” 难倒英雄汉 —— 参数错了,全白搭 ⚠️
别以为 LLM “见过世面”,面对真实 MCP 工具的细节,它们经常犯 “低级错误”。
论文里举了个典型例子:用 Yahoo Finance 查股票历史价格时,工具要求 “开始日期和结束日期必须不同”,但 GPT-4.1、Claude-4.0 这类顶级模型,经常把两个日期设成同一天,直接触发报错(左图)。这不是 “不会”,而是 “不熟”——LLM 没摸透每个 MCP 工具的参数规则、格式要求,就像刚拿到新手机,连充电口在哪都找不到。
为了验证这点,论文加了个 “探索阶段”:让 LLM 先自由试用工具,熟悉用法再做题。结果发现,Claude-4.0 在财务分析任务里成功率涨了 7.5%,但在浏览器自动化里反而降了 —— 说明工具熟悉度是 “domain-specific” 的,不是靠 “多试几次” 就能万能解决,LLM 需要更系统的 “工具学习能力”。
3. 考验 3:“工具太多” 选择困难 —— 噪音一多,就迷路 🧩
真实工作中,你不会只面对一个工具:比如做 “跨城出差计划”,要同时用到地图(查路线)、浏览器(订酒店)、财务工具(算差旅预算)。MCP-Universe 故意加了这个变量 —— 在原有任务基础上,多接 7 个无关的 MCP 服务器(共 94 个工具)。
结果很明显:Claude-4.0 在路线规划任务里的成功率从 22.22% 跌到 11.11%,GPT-4.1 在浏览器自动化里从 23.08% 降到 15.38%。这说明:LLM 还没学会 “在一堆工具里挑对的”,就像你打开手机 20 个 APP,反而不知道该点哪个 —— 真实场景里的 “工具选择成本”,远比想象中高。
三、实测结果:顶级 LLM 集体 “露怯”,43.72% 已是天花板?
论文用 MCP-Universe 测了 15 个顶级模型(包括 GPT-5、Grok-4、Claude-4.0 这些 “明星选手”),结果让人大跌眼镜 ——没有一个模型能拿下 50% 以上的成功率。
看几个关键数据:
- 最强者 GPT-5,整体成功率 43.72%,在财务分析(67.5%)、3D 设计(52.63%)里表现不错,但在路线规划(33.33%)、代码仓库管理(30.3%)里照样拉胯;
- 企业级工具如 Cursor(主打代码 + 工具协同),整体成功率 26.41%,居然比简单的 ReAct 框架(29.44%)还低,尤其在网页搜索里,成功率从 21.82% 暴跌到 7.27%;
- 开源模型里最好的 GLM-4.5,成功率 24.68%,虽然比部分闭源模型(如 Claude-3.7)强,但和 GPT-5 差了近 20 个百分点。
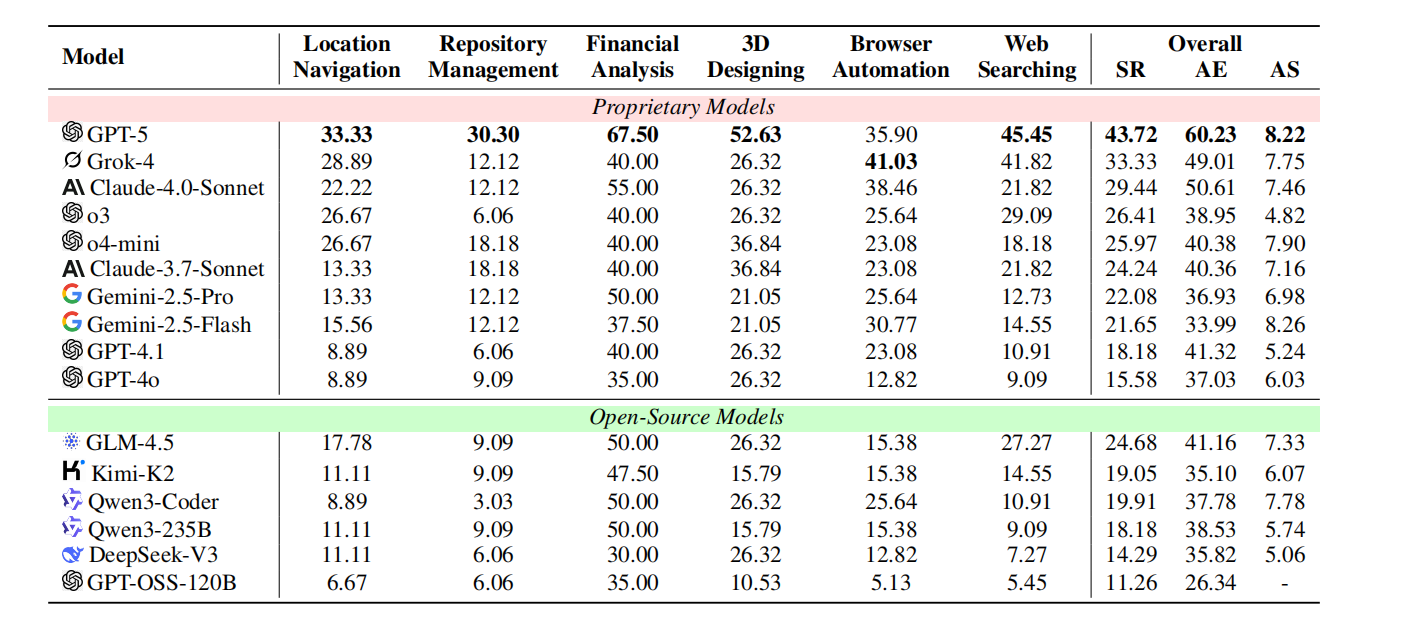
更值得关注的是 “evaluator 表现”:多数模型在 “格式合规”(比如按要求输出 JSON)上能拿 80% 以上分数,但在 “内容正确性”(比如算对股票收益、找对餐厅 ID)上只有 40-60%—— 这说明:LLM 不是 “不会用工具”,而是 “用不对工具”,就像你会点外卖 APP,但总是填错地址、选错餐品。
四、MCP-Universe 的价值:不止是 “测分”,更是 “指路”
这篇论文最棒的地方,不是 “把 LLM 骂一顿”,而是通过 MCP-Universe 给出了明确的 “改进方向” 🧭。
1. 对研究者:明确三大攻坚点
论文直接指出未来 LLM 工具能力的核心突破方向:
- 长上下文不是 “堆长度”:要优化 “动态上下文管理”,比如自动识别 “路线坐标”“股票代码” 这类关键信息,而非无脑保留所有对话;
- 工具学习不是 “死记硬背”:需要让 LLM 学会 “试错 - 总结”,比如调用 Yahoo Finance 报错后,能自动调整日期参数,而不是反复踩同一个坑;
- 跨领域能力要 “因材施教”:模型在财务、3D 设计里强,在路线规划里弱,说明不能用一套方法优化所有领域,需要 domain-specific 的微调。
2. 对开发者:提供可复用的框架
MCP-Universe 不是一个 “一次性评测”,而是开源了完整的框架 —— 支持接入新的 MCP 服务器、新的 LLM agent,还有可视化 UI。比如你想测自家模型在 “飞书文档 MCP 服务器” 上的表现,直接按框架接入就行,不用从零造轮子。
五、最后:LLM 的 “工具能力”,还在 “发展阶段”
MCP-Universe 就像一面镜子,照出了当前 LLM 工具能力的 “真相”:我们以为的 “会用工具”,只是 “会按按钮”,但真实世界需要的是 “会选工具、会调参数、会处理意外” 的综合能力。
论文结尾那句其实很扎心:“即使是 GPT-5 这样的顶级模型,在真实 MCP 环境下的表现,也远没达到实用要求。” 但这不是坏事 —— 只有明确了差距,才能找到前进的方向。毕竟,AI 要帮人类干活,先得在 “真实工具的修罗场” 里活下去,再谈 “干得好” ✊。