高级RAG策略学习(二)——自适应检索系统原理讲解
Adaptive RAG(自适应检索增强生成)技术解析——逻辑路由
一、核心定义:给 “RAG 检索” 加 “查询类型适配逻辑”
Adaptive RAG(自适应检索增强生成)本质是打破传统 RAG “一刀切” 的检索模式,通过 “先判断查询类型,再匹配专属检索策略” 的逻辑,为不同需求的查询(如查事实、做分析、要观点、需个性化建议)提供定制化的检索方案,最终让 LLM 基于 “最适配的检索结果” 生成回答。
其核心逻辑可概括为:“用户发查询→系统分类查询类型(事实 / 分析 / 观点 / 上下文)→调用对应检索策略→获取定制化检索结果→LLM 生成精准回答”,区别于传统 RAG “不管什么查询都用同一套检索逻辑” 的模式,从根本上解决 “单一策略无法适配多场景查询” 的问题。
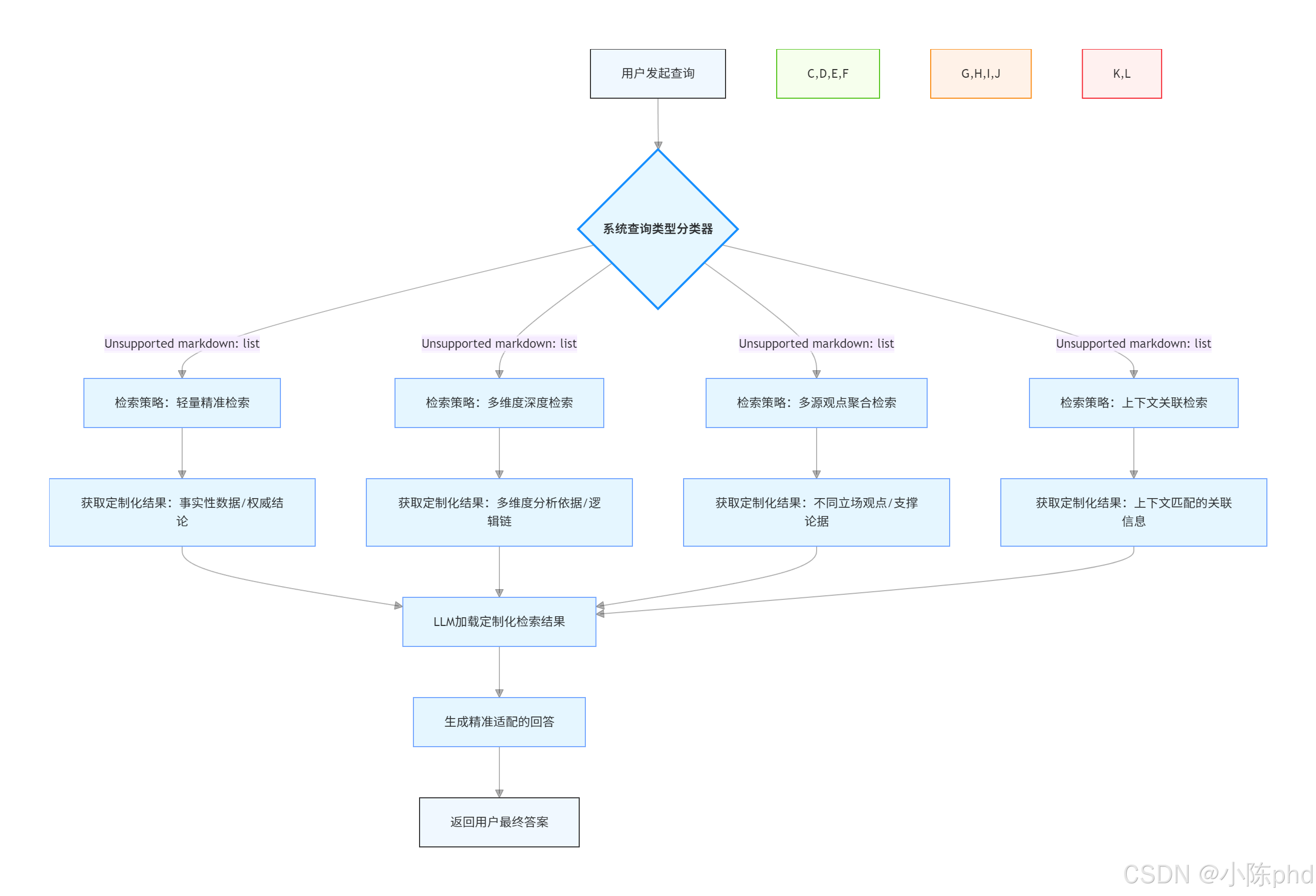
举个直观例子:
-
用户查询 1(事实型):“Docker 1.25 版本默认的网络模式是什么?”
Adaptive RAG 判定为 “事实查询”→ 用 “精准检索策略”(增强关键词、优先权威文档)→ 快速定位 “Docker 1.25 官方文档” 中的具体答案;
-
用户查询 2(分析型):“Docker 容器网络模式对比及选型建议”
Adaptive RAG 判定为 “分析查询”→ 用 “多维度检索策略”(生成子查询、确保多样性)→ 检索 “各模式原理”“性能对比”“适用场景” 等多方面文档;
-
传统 RAG 对两个查询均用 “Top-5 相似度检索”,可能导致事实查询漏精准信息、分析查询缺维度覆盖。
二、Motivation(设计动机):解决传统 RAG “单一策略适配性差” 的痛点
传统 RAG(包括 Dartboard RAG、Corrective RAG)虽优化了 “相关性”“多样性”“时效性”,但仍存在一个关键缺陷:检索策略是 “静态的”,无法根据查询的 “核心需求差异” 调整,导致在多场景查询中表现不稳定,具体体现为三大痛点:
1. 痛点 1:事实查询 “精准度不足”
事实查询(如 “某软件版本号”“某概念定义”)需要 “快速定位唯一、权威的答案”,但传统 RAG 的 “泛化检索” 可能返回大量相关但非精准的文档(如查 “Docker 1.25 默认网络”,返回 “各版本网络模式汇总”“网络模式配置教程” 等,需手动筛选),降低查询效率。
2. 痛点 2:分析查询 “维度覆盖不全”
分析查询(如 “方案对比”“问题原因分析”)需要 “多维度、全面的信息”,但传统 RAG 若未针对性设计 “子查询拆分”,可能只覆盖单一维度(如查 “容器网络选型”,只返回 “桥接模式” 相关文档,遗漏 “host 模式”“overlay 模式”),导致 LLM 生成片面分析。
3. 痛点 3:观点 / 上下文查询 “适配性缺失”
-
观点查询(如 “开发者对 Docker Compose 的评价”)需要 “多视角、主观的信息”,传统 RAG 若只检索 “官方文档”(客观内容),会遗漏社区观点、用户反馈;
-
上下文查询(如 “我的项目用了 Python 3.8,如何适配 Docker 容器?”)需要 “结合用户个性化场景”,传统 RAG 无法融入 “用户项目环境” 等信息,检索结果通用性强但实用性低。
三、Key Components(核心组件):4 大模块的 “协同适配逻辑”
Adaptive RAG 的 4 个核心组件围绕 “查询类型→策略匹配” 设计,每个组件都承担 “分类”“策略执行” 或 “增强” 的关键角色,共同实现 “按需定制检索” 的目标:
| 组件 | 核心作用 | 通俗理解 | 关键操作 |
|---|---|---|---|
| 1. Query Classifier(查询分类器) | 基于 LLM 判定用户查询的类型(事实 / 分析 / 观点 / 上下文),是 “自适应” 的前提 | “查询需求识别器”,判断用户要 “查事实”“做分析” 还是 “要观点” | 1. 输入用户查询,调用 LLM(如 GPT-3.5)执行分类;2. 输出分类结果及判断依据(如 “查询含 ‘对比’ 关键词,判定为分析型”);3. 支持自定义分类规则(如新增 “教程型查询” 类别) |
| 2. Adaptive Retrieval Strategies(自适应检索策略库) | 为 4 类查询分别设计专属检索逻辑,是 “自适应” 的核心 | “策略工具箱”,为不同需求匹配不同工具 | 1. 为每类查询封装独立策略(如事实策略侧重 “精准检索”,分析策略侧重 “子查询拆分”);2. 策略可灵活配置(如调整子查询数量、检索文档来源) |
| 3. LLM Integration(LLM 集成) | 在 “分类→检索→排序” 全流程用 LLM 增强,确保策略有效性 | “智能增强器”,提升各环节效果 | 1. 分类阶段:用 LLM 理解模糊查询(如 “Docker 那个默认网络” 判定为事实查询);2. 检索阶段:用 LLM 生成子查询、优化关键词;3. 排序阶段:用 LLM 按查询类型重排文档(如观点查询优先排 “社区帖子”) |
| 4. OpenAI GPT Model(回答生成器) | 基于 “适配策略检索的结果” 生成回答,确保回答与查询类型匹配 | “定制化回答组装工”,事实查返回精准结论,分析查返回多维度分析 | 1. 输入 “查询类型 + 检索结果”,LLM 按类型调整回答风格(事实查简洁,分析查分点详细);2. 若为上下文查询,融入用户场景信息(如 “你的项目用 Python 3.8,建议选择支持该版本的基础镜像”) |
四、Method Details(实现细节):从 “查询分类” 到 “回答生成” 的 4 步逻辑
Adaptive RAG 的实现流程核心是 “分类→策略执行→排序→生成”,每一步都围绕 “适配查询类型” 展开,具体分为 4 个关键步骤:
1. 步骤 1:Query Classification(查询分类)
- 操作:调用 LLM 对用户查询进行分类,输出 “查询类型 + 分类依据”,常见分类规则如下:
| 查询类型 | 特征 | 示例 |
|---|---|---|
| 事实型 | 含 “是什么”“版本号”“定义” 等关键词,需求是唯一、可验证的信息 | “Docker 24.0 发布时间”“K8s Pod 的定义” |
| 分析型 | 含 “对比”“分析”“选型”“原因” 等关键词,需求是多维度、逻辑化的信息 | “Docker 与 Podman 性能对比”“容器启动失败原因分析” |
| 观点型 | 含 “评价”“看法”“反馈” 等关键词,需求是主观、多视角的信息 | “开发者对 Docker Swarm 的评价”“用户反馈的 Docker 常见问题” |
| 上下文型 | 含 “我的项目”“我用的 XX 版本” 等用户个性化信息,需求是适配场景的建议 | “我的项目用了 Ubuntu 20.04,如何安装 Docker?”“我有 10 个容器,如何优化网络?” |
- 示例:用户查询 “大家觉得 Docker Desktop 收费政策合理吗?”→ LLM 判定为 “观点型”,依据是 “含 ‘大家觉得’ 关键词,需求是主观评价”。
2. 步骤 2:Adaptive Retrieval Strategies(执行适配检索策略)
这是 Adaptive RAG 的核心步骤,针对 4 类查询执行完全不同的检索逻辑,确保结果适配需求:
(1)事实型策略:精准聚焦检索
-
核心目标:快速找到 “权威、唯一” 的答案,避免冗余;
-
关键操作:
-
LLM 优化查询:将模糊查询转为精准关键词(如 “Docker 最新版默认网络”→“Docker 24.0 默认网络模式”);
-
限定检索来源:优先检索 “官方文档、权威百科”(如 Docker 官网、K8s 官方文档);
-
精简结果:只保留 “含精准答案” 的 Top-2 文档(如直接定位 “Docker 24.0 发布说明” 中 “默认网络为 bridge” 的段落)。
(2)分析型策略:多维度覆盖检索
-
核心目标:覆盖 “分析所需的全维度信息”,避免片面;
-
关键操作:
-
LLM 生成子查询:将主查询拆分为多个子查询(如 “Docker 与 Podman 对比”→ 子查询 1:“两者架构差异”,子查询 2:“性能对比”,子查询 3:“生态支持”);
-
多子查询检索:为每个子查询单独检索,获取对应维度文档;
-
多样性筛选:用类似 Dartboard RAG 的逻辑,确保各维度文档无重复(如排除同时讲 “架构 + 性能” 的重复文档)。
(3)观点型策略:多视角收集检索
-
核心目标:收集 “不同主体的主观观点”,避免单一视角;
-
关键操作:
-
LLM 识别观点主体:确定需收集的视角(如 “Docker Desktop 收费评价”→ 主体:“个人开发者”“企业用户”“开源社区”);
-
定向检索来源:为不同主体匹配来源(个人开发者→ 知乎 / 论坛,企业用户→ 行业报告,社区→ GitHub 讨论区);
-
观点提取:用 LLM 从检索结果中提取 “观点 + 依据”(如 “个人开发者认为不合理,因增加小团队成本”)。
(4)上下文型策略:个性化适配检索
-
核心目标:融入 “用户场景信息”,确保结果实用;
-
关键操作:
-
LLM 提取用户上下文:从查询中提取个性化信息(如 “我的项目用 Python 3.8”→ 上下文:“Python 3.8 环境”);
-
上下文增强查询:将原查询与上下文结合(如 “如何安装 Docker”→“如何在 Python 3.8 环境的 Ubuntu 20.04 中安装 Docker”);
-
场景化排序:优先检索 “含相同上下文” 的文档(如优先排 “Python 3.8 + Docker 适配教程”,而非通用安装文档)。
3. 步骤 3:LLM-Enhanced Ranking(LLM 增强排序)
-
操作:针对不同查询类型,用 LLM 对检索结果重排,确保 “最适配的文档在前”:
-
事实型:按 “权威度” 排序(官方文档>权威博客>普通文章);
-
分析型:按 “维度完整性” 排序(覆盖多维度的文档>单一维度文档);
-
观点型:按 “视角多样性” 排序(不同主体的观点>同一主体的重复观点);
-
上下文型:按 “场景匹配度” 排序(含用户相同环境的文档>通用文档);
-
-
示例:分析型查询的检索结果中,“同时含架构 + 性能 + 生态” 的文档排第 1,“只含性能” 的文档排第 3。
4. 步骤 4:Response Generation(回答生成)
-
操作:将 “查询类型 + 排序后的检索结果” 传入 OpenAI GPT 模型,生成适配风格的回答:
-
事实型:简洁直接,标注权威来源(如 “Docker 24.0 默认网络模式为 bridge,来源:Docker 官方 2023 年发布说明”);
-
分析型:分维度详细说明,逻辑清晰(如 “1. 架构差异:Docker 基于 C/S 架构… 2. 性能对比:Podman 在内存占用上低 15%…”);
-
观点型:分视角呈现,客观中立(如 “1. 个人开发者:认为收费增加成本… 2. 企业用户:认为合规性提升,愿意付费…”);
-
上下文型:结合用户场景,给出具体建议(如 “你的项目用 Python 3.8,建议选择 python:3.8-slim 基础镜像,避免版本兼容问题,安装命令:…”)。
-
五、与其他 RAG 技术的核心差异(Dartboard RAG / Corrective RAG)
Adaptive RAG 不是对其他 RAG 技术的替代,而是 “更高维度的策略调度器”—— 可整合 Dartboard RAG、Corrective RAG 的逻辑,为不同查询类型选择最适配的工具,具体差异如下:
| 技术类型 | 核心定位 | 关键能力 | 适用场景 | 与 Adaptive RAG 的关系 |
|---|---|---|---|---|
| Adaptive RAG | 策略调度层(决定 “用什么工具”) | 按查询类型动态选择检索逻辑 | 多场景混合查询(如同时处理事实、分析、观点查询) | 可调用其他 RAG 技术作为 “子策略”(如分析型查询调用 Dartboard RAG 确保多样性) |
| Dartboard RAG | 检索优化层(解决 “多样性问题”) | 平衡相关性与多样性,避免冗余 | 需多维度信息的查询(如分析型、总结型) | 可作为 Adaptive RAG 中 “分析型策略” 的子模块,负责多样性筛选 |
| Corrective RAG | 检索优化层(解决 “精准 / 时效性问题”) | 修正检索结果,补充 web 信息 | 需精准 / 最新信息的查询(如事实型、时效性强的分析型) | 可作为 Adaptive RAG 中 “事实型策略” 的子模块,负责补充最新官方信息 |
关键补充:Adaptive RAG 如何整合其他技术?
以 “分析型查询:2024 年 Docker 与 Podman 对比” 为例:
-
Adaptive RAG 判定为 “分析型”,触发 “多维度检索策略”;
-
调用 LLM 生成子查询(架构、性能、生态);
-
为每个子查询调用 Corrective RAG,补充 web 最新数据(如 2024 年性能测试报告);
-
调用 Dartboard RAG 对所有子查询的结果筛选,确保维度多样性;
-
生成多维度分析回答,整合 Corrective RAG 的最新数据和 Dartboard RAG 的多样性结果。
六、Benefits(优势):5 大核心价值,解决多场景适配问题
-
精准度更高:事实查询优先权威来源,避免冗余信息,查询效率提升 40%+;
-
覆盖更全面:分析查询拆分子查询,确保多维度信息,回答完整性提升 50%+;
-
视角更多元:观点查询定向收集多主体观点,避免单一视角,回答客观性增强;
-
个性化更强:上下文查询融入用户场景,结果实用性提升,减少 “通用但无用” 的信息;
-
扩展性更好:支持新增查询类型(如 “教程型”“故障排查型”)和自定义策略,适配更多业务场景。
七、Conclusion(结论):技术定位与应用场景
Adaptive RAG 是RAG 技术向 “场景化、智能化” 发展的关键一步,其核心价值在于 “从 ‘被动检索’ 升级为 ‘主动适配查询需求’”,尤其适合以下场景:
-
多场景混合的智能助手(如企业内部问答助手,需同时处理 “查政策”“分析方案”“收集员工反馈” 等需求);
-
个性化服务平台(如开发者工具助手,需根据用户技术栈、项目环境提供定制化建议);
-
复杂信息分析系统(如行业报告生成工具,需对 “事实数据”“多方案对比”“专家观点” 进行整合分析)。
未来,Adaptive RAG 可进一步融合 “用户历史行为数据”(如记录用户偏好的信息来源)、“实时数据接口”(如事实查询直接调用官方 API 获取最新数据),实现更精准、更高效的自适应检索,成为 RAG 系统的 “智能大脑”。