深度学习:ResNet 残差神经网络详解
一、ResNet 残差神经网络的起源与核心地位
ResNet(Residual Neural Network,残差神经网络)是 2015 年由微软亚洲研究院的何凯明、张祥雨等研究者提出的深度神经网络架构。在当年的 ImageNet 大规模视觉识别挑战赛(ILSVRC)中,ResNet 凭借革命性的设计一举斩获分类任务、目标检测任务双料冠军;同时在 COCO 数据集(Common Objects in Context)的评测中,也包揽了目标检测与图像分割任务的第一名,成为计算机视觉领域的里程碑模型。
与传统卷积神经网络(如 AlexNet、VGGNet)相比,ResNet 的核心突破在于两点:独创的残差结构和内置的批次归一化机制。这两个设计不仅让网络能够突破 “深度瓶颈”,实现数百层的有效训练,更奠定了后续深度学习架构(如 DenseNet、EfficientNet)的设计基础,至今仍是图像分类、目标检测、图像分割等任务的基础骨干网络之一。
二、残差结构的原理与实现细节
残差结构(Residual Block)是 ResNet 的 “灵魂”,其核心目标是解决深层网络训练中的 “退化问题”,让网络在增加深度的同时,性能不下降甚至提升。
1. 核心思想:从 “直接映射” 到 “残差学习”
传统神经网络的每一层都试图学习 “输入到输出的直接映射”(即学习函数 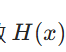 ),而残差结构则将目标改为学习 “输入与输出的差异”(即学习残差函数
),而残差结构则将目标改为学习 “输入与输出的差异”(即学习残差函数 ![]() )。最终网络的输出则变为:
)。最终网络的输出则变为:![]() ) 其中,x 是残差块的输入,
) 其中,x 是残差块的输入,![]() 是经过若干卷积层、激活函数后的特征(残差部分),“+” 代表元素级加法(即特征矩阵相同位置的数值相加)。
是经过若干卷积层、激活函数后的特征(残差部分),“+” 代表元素级加法(即特征矩阵相同位置的数值相加)。
这种设计的优势在于:当网络需要学习 “恒等映射”(即输入等于输出,![]() )时,只需让残差部分
)时,只需让残差部分 ![]() ) 即可,无需让卷积层费力学习复杂的直接映射 —— 这大大降低了深层网络的训练难度。
) 即可,无需让卷积层费力学习复杂的直接映射 —— 这大大降低了深层网络的训练难度。
2. 实现关键:保证输入与残差的 “形状匹配”
元素级加法要求输入 x 和残差 ![]() 的特征矩阵形状(高度、宽度、通道数)完全一致,否则无法直接相加。为满足这一要求,ResNet 设计了两种残差块:
的特征矩阵形状(高度、宽度、通道数)完全一致,否则无法直接相加。为满足这一要求,ResNet 设计了两种残差块:
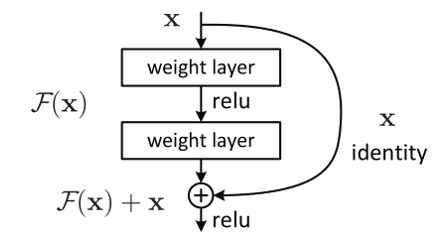
(1)恒等映射残差块(Identity Block)
适用于 “输入与输出特征形状一致” 的场景(通常是同一组残差块内部的连接)。结构如下:
- 输入 x 先经过 1 个卷积层(卷积核大小 3×3,步长 1,填充 1),激活函数为 ReLU;
- 再经过 1 个卷积层(同样 3×3,步长 1,填充 1),此时得到残差
 ;
; - 将
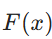 与原始输入 x 直接相加(元素级加法);
与原始输入 x 直接相加(元素级加法); - 最后经过 ReLU 激活函数,得到残差块的输出。
- 由于卷积层使用 “步长 1 + 填充 1”,残差 的高度、宽度与输入 x 完全一致;若通道数需调整,会在卷积层中通过调整卷积核数量来匹配输入通道数。
(2)1×1 卷积调整残差块(Conv Block)
适用于 “输入与输出特征形状不一致” 的场景(通常是不同组残差块之间的连接,需要降维或调整通道数)。结构与恒等映射块类似,但增加了 “1×1 卷积调整输入” 的步骤:
- 输入 x 先经过 1 个 1×1 卷积层(步长 2,无填充),目的是将输入的高度、宽度减半(降维),同时调整通道数;
- 后续卷积层操作与恒等映射块一致,得到残差 \(F(x)\);
- 跳跃连接(Skip Connection)部分的输入 x 也需经过 1 个 1×1 卷积层(步长 2),确保其形状与 \(F(x)\) 匹配;
- 两者相加后经过 ReLU 激活,得到输出。
1×1 卷积的引入是 ResNet 的巧妙设计 —— 它既能高效调整特征通道数,又能控制计算量,避免因形状匹配导致的复杂度飙升。
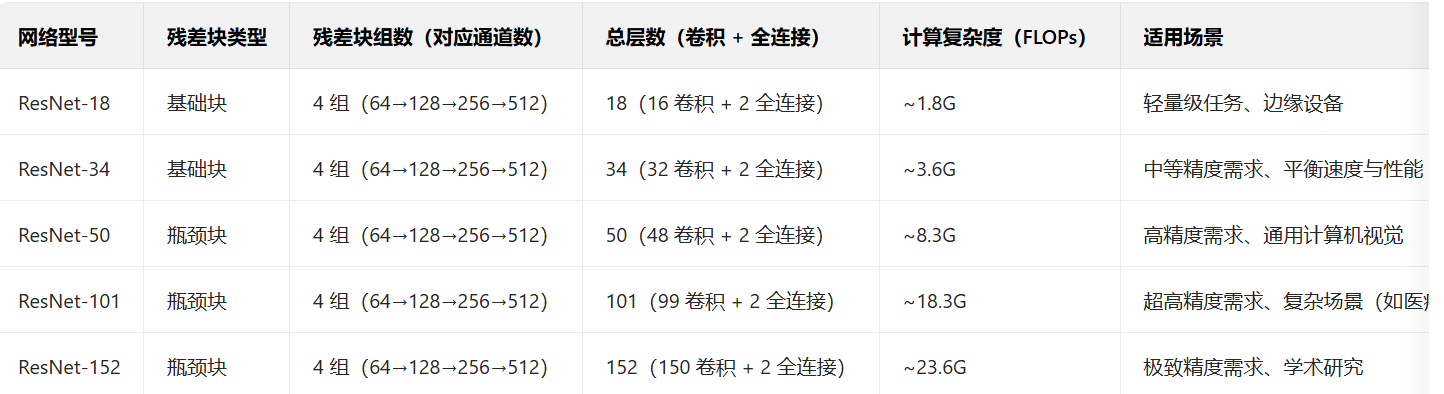
三、ResNet 经典变体:从 18 层到 152 层的架构解析
ResNet 并非单一架构,而是一系列不同深度的变体集合。通常所说的 “层数” 指的是卷积层与全连接层的总数量(不含池化层、激活层)。常见变体包括 ResNet-18、ResNet-34、ResNet-50、ResNet-101、ResNet-152,其核心差异在于 “残差块的类型” 和 “每组残差块的数量”。
1. 架构分类:基础块与瓶颈块
- 基础块(Basic Block):用于 ResNet-18 和 ResNet-34,由 2 个 3×3 卷积层组成(即上述恒等映射 / Conv Block 结构),适合层数较少的网络。
- 瓶颈块(Bottleneck Block):用于 ResNet-50、ResNet-101 和 ResNet-152,由 “1×1 卷积(降维)→3×3 卷积(特征提取)→1×1 卷积(升维)” 组成。这种结构在保证特征提取能力的同时,大幅减少了计算量(FLOPs),让数百层网络的训练成为可能。
2. ResNet 各变体架构对比表
下表清晰展示了不同 ResNet 变体的层数分布、残差块类型及计算复杂度(以 ImageNet 数据集为基准):
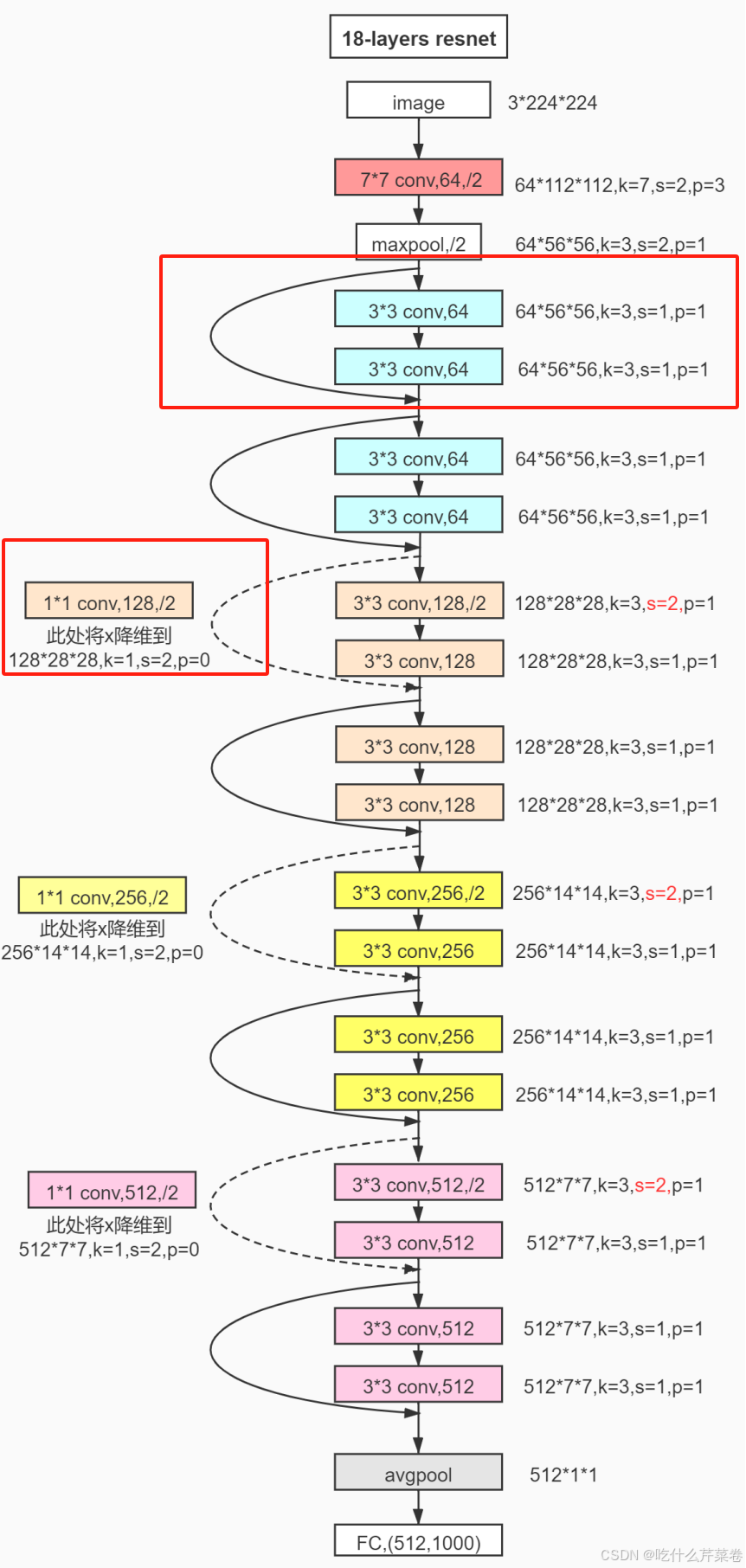
3. ResNet-18 架构示例(以 ImageNet 分类任务为例)
ResNet-18 是最基础的变体,其架构流程可分为 5 个阶段,清晰体现了 ResNet 的设计逻辑:
- 输入层与初始卷积:输入 224×224×3 的 RGB 图像,经过 1 个 7×7 卷积层(步长 2,填充 3)和 1 个最大池化层(3×3,步长 2),得到 56×56×64 的特征图;
- 第一组残差块:包含 2 个基础块(恒等映射块),输入输出均为 56×56×64,无降维;
- 第二组残差块:包含 2 个基础块,第一个块为 Conv Block(步长 2),将特征图降为 28×28×128,第二个块为恒等映射块;
- 第三组残差块:包含 2 个基础块,第一个块为 Conv Block(步长 2),将特征图降为 14×14×256,第二个块为恒等映射块;
- 第四组残差块:包含 2 个基础块,第一个块为 Conv Block(步长 2),将特征图降为 7×7×512,第二个块为恒等映射块;
- 全局平均池化与全连接:对 7×7×512 的特征图进行全局平均池化,得到 1×1×512 的向量,再经过 1 个全连接层输出 1000 个类别(对应 ImageNet 的 1000 类分类任务)。
实际应用中,若需适配自定义分类任务(如 10 类分类),只需将最后全连接层的输出维度修改为 10 即可。
4.表格示例
- 18层,34层,50层,101层,152层,及其结构
- FLOPs行是每个网络的计算性能和模型复杂度

四、批次归一化(Batch Normalization)与 ResNet 的协同作用
批次归一化(Batch Normalization,简称 BN)并非 ResNet 首创(2015 年由 Ioffe 和 Szegedy 提出),但 ResNet 将其与残差结构深度结合,成为解决深层网络训练问题的 “双核心” 之一。
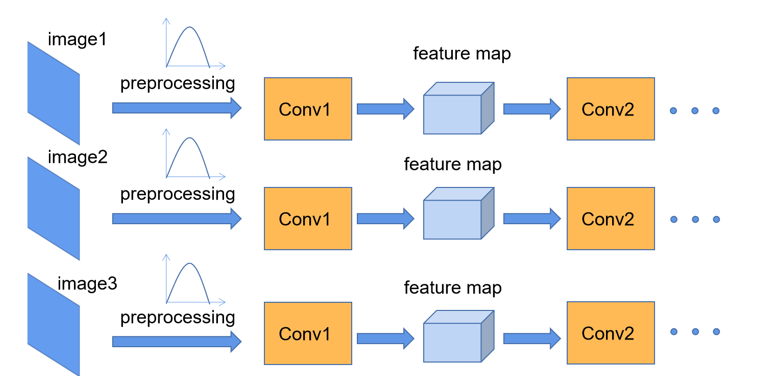
1.工作过程
- 对输入图像进行预处理
- 对每一个特征图进行归一化处理之后再输入下一个卷积层
2.主要作用
减轻内部协变量偏移:通过标准化每一层的输入,使得其均值接近0,方差接近1,从而减少了层间输入的变化,帮助模型更快地收敛。
提高训练速度:批次归一化能够使得更大的学习率得以使用,从而加速训练。
缓解梯度消失:通过规范化输入,有助于保持激活值的稳定性,从而在一定程度上减轻了梯度消失现象。
具有正则化效果:批次归一化可以在某种程度上减少对其他正则化技术(如Dropout)的依赖,因为它引入了一定的噪声。
提高模型泛化能力:通过使训练过程更加稳定,批次归一化有助于提高模型在未见数据上的表现。
五、ResNet 对传统神经网络痛点的突破性解决
在 ResNet 出现之前,传统深层卷积神经网络(如 VGGNet-19、GoogleNet)面临两大核心痛点:梯度消失 / 爆炸和退化问题。ResNet 通过残差结构和 BN 的组合,从根本上解决了这些问题。
1. 解决梯度消失与梯度爆炸问题
梯度消失和梯度爆炸是深层网络反向传播过程中的经典问题,其本质是 “梯度在多层传递中被不断放大或缩小”。
(1)梯度消失
- 问题表现:反向传播时,梯度通过链式法则逐层传递,若每一层的梯度绝对值小于 1(如激活函数为 Sigmoid 时,导数最大值仅 0.25),经过数十层传递后,梯度会趋近于 0,导致浅层权重几乎无法更新,模型训练停滞。
- ResNet 的解决方案:
- 残差结构的跳跃连接:残差块的输出为
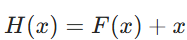 ,反向传播时,梯度
,反向传播时,梯度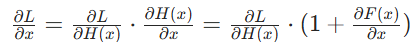 其中 “1” 直接来自跳跃连接,确保梯度至少为
其中 “1” 直接来自跳跃连接,确保梯度至少为 ,不会因
,不会因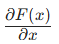 趋近于 0 而消失。
趋近于 0 而消失。 - BN 的稳定作用:BN 通过标准化输入,避免激活函数进入梯度趋近于 0 的区域(如 ReLU 的死亡区、Sigmoid 的饱和区),进一步保证梯度的有效传递。
- 残差结构的跳跃连接:残差块的输出为
(2)梯度爆炸
- 问题表现:若每一层的梯度绝对值大于 1,经过多层传递后,梯度会呈指数级增长,导致权重更新过大,模型损失函数发散,甚至出现数值溢出(如权重变为 NaN)。
- ResNet 的解决方案:
- BN 的梯度缩放:BN 的标准化操作会将输入特征的方差控制在 1 附近,间接限制了梯度的量级,避免梯度在传递过程中过度放大。
- 残差结构的梯度分流:残差块中的卷积层多采用 3×3 小卷积核,且瓶颈块通过 1×1 卷积降维,减少了参数数量和计算量,间接降低了梯度的波动范围,避免梯度爆炸
2. 解决深层网络的退化问题
退化问题是 ResNet 要解决的核心痛点,也是区别于 “梯度问题” 的全新挑战。
(1)退化问题的定义
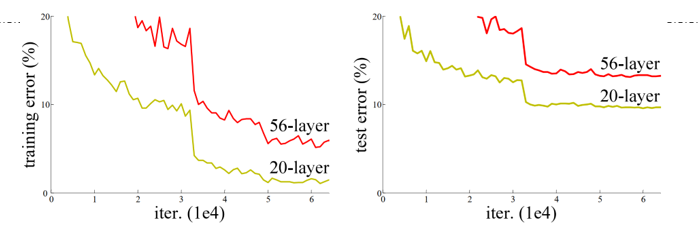
当网络深度增加到一定程度后,模型在训练集上的误差会随着深度增加而上升(而非下降),同时测试集误差也随之上升 —— 这并非过拟合(过拟合是训练集误差下降、测试集误差上升),而是模型 “能力退化”,无法有效利用深层结构提取特征。
例如,在 ImageNet 数据集上,传统 56 层网络的训练误差(约 10%)反而高于 20 层网络(约 8%),说明深层网络不仅没有带来性能提升,反而出现了 “越学越差” 的情况。
(2)ResNet 的解决方案:残差结构
退化问题的本质是 “深层网络难以学习恒等映射”—— 当浅层网络已能提取足够特征时,深层网络需要学习 “输入等于输出” 的恒等映射,但传统网络的直接映射学习难度极高,导致权重更新方向偏离最优解,性能退化。