NVIDIA Jetson 开发板使用
1、nvidia jetson 是什么

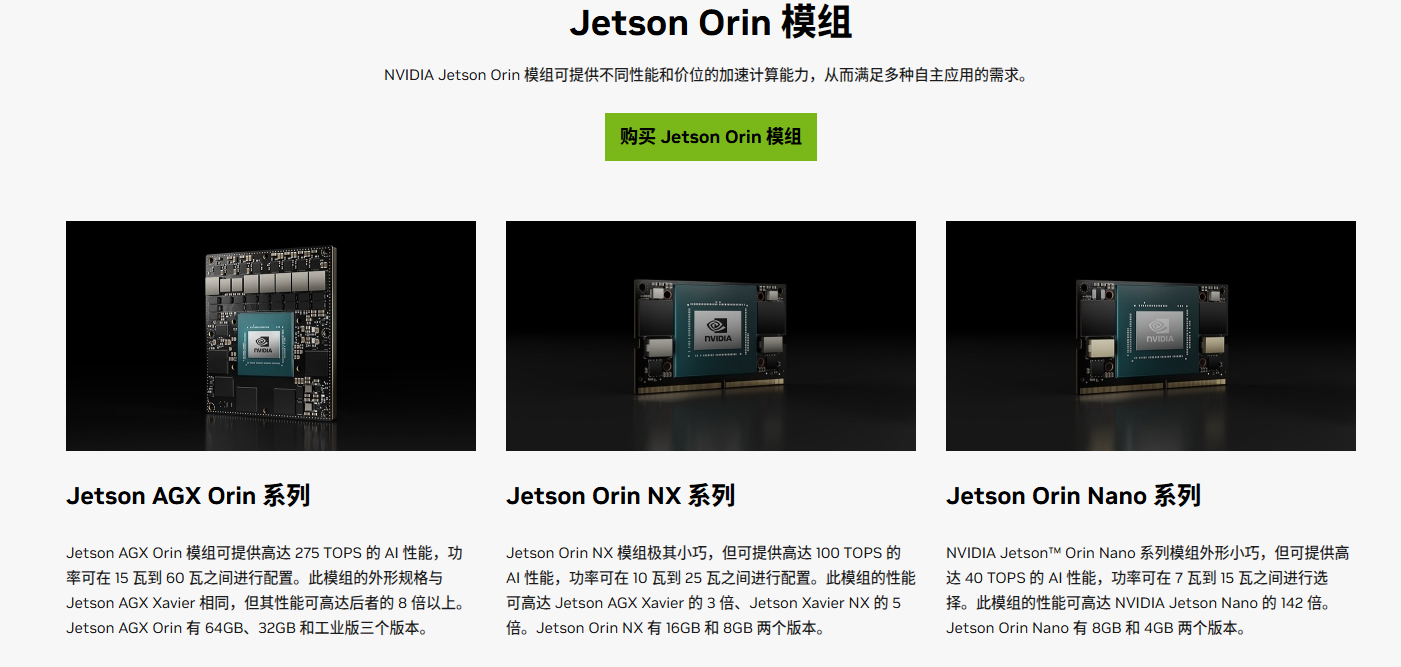
Jetson 是NVIDIA嵌入式系列开发板,见上图
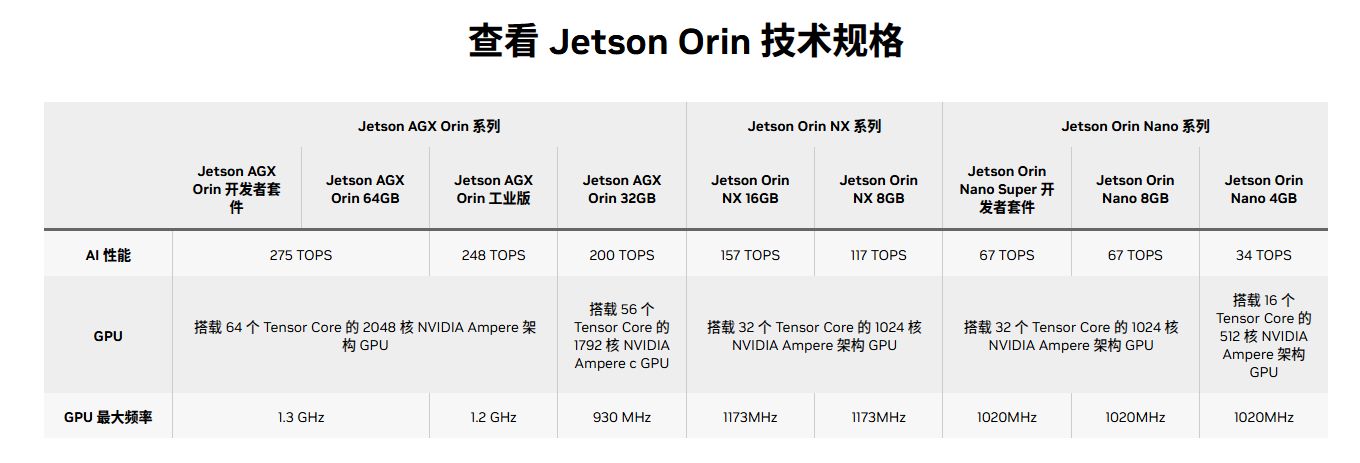
技术规格:
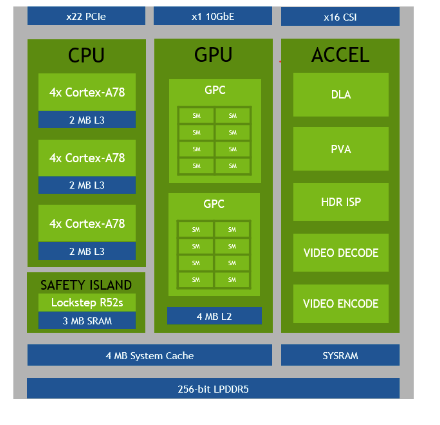
2、硬件架构
架构图
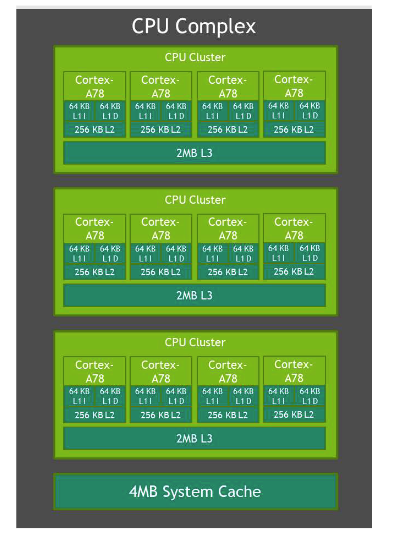
ARM CPU
Arm Cortex-A78AE
12 CPU cores
64KB Instruction L1 Cache
64KB Data Cache
256 KB L2 Cache
最大主频 2.2 GHz
Ampere 架构 GPU
2 Graphic Processing Clusters (GPCs)
8 Texture Processing Clusters (TPCs),
16 Streaming Multiprocessors (SM’s)
192 KB of L1-cache per SM
4 MB of L2 Cache
128 CUDA cores per SM

3、benchmark
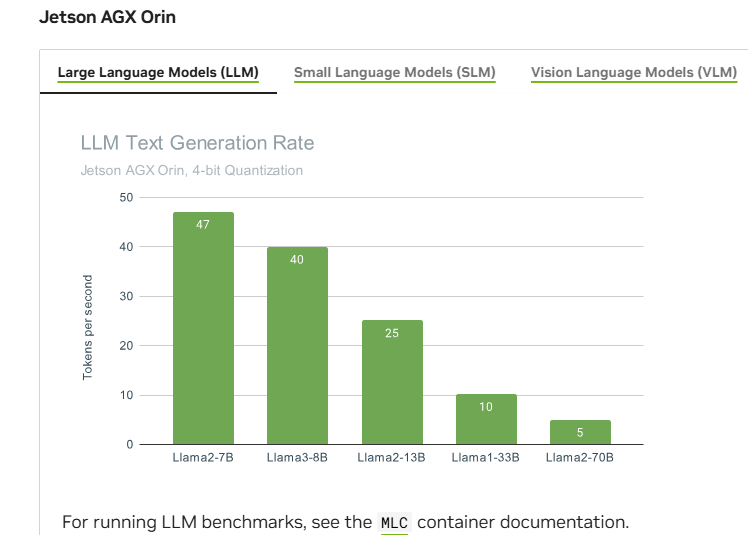
4、查看自己设备的型号
root@ubuntu:~# jtop显示如下:
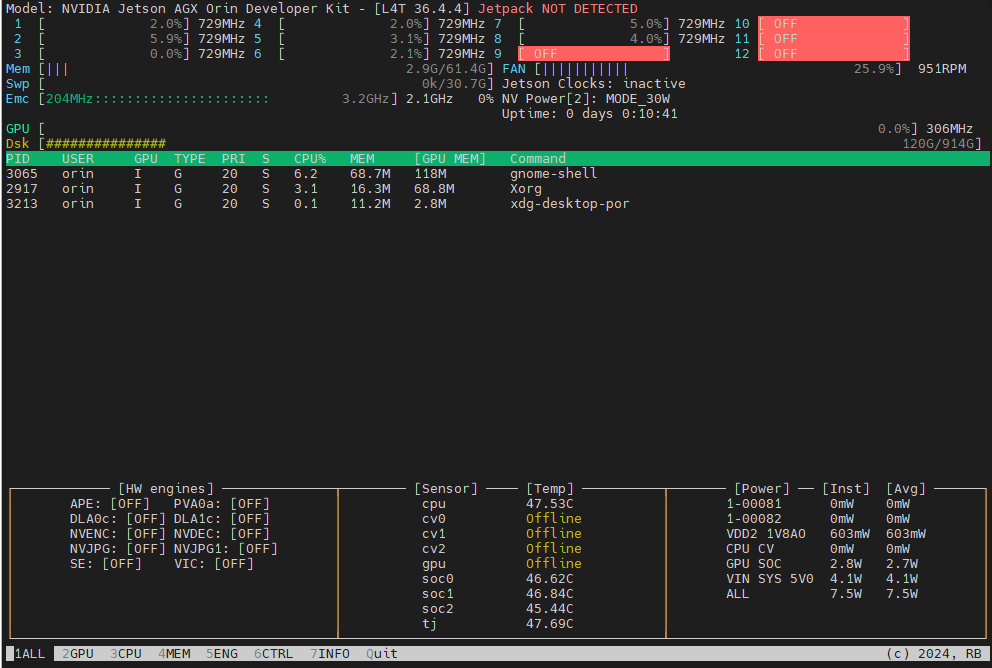
监控GPU状态
root@ubuntu:~# tegrastatsRAM 3216/16384MB (lfb 1234x4MB) SWAP 0/0MB
GPU 25%@1122 EMC 12%@1600 APE 150 MTS fg 0%
GR3D 22% CV 0% NVENC 0% NVDEC 0% 其中 GR3D 代表GPU利用率;
5、使用
安装jetson-container
git clone https://github.com/dusty-nv/jetson-containers
bash jetson-containers/install.sh如果要编译镜像,需要修改/etc/docker/daemon.json,添加 "default-runtime": "nvidia"
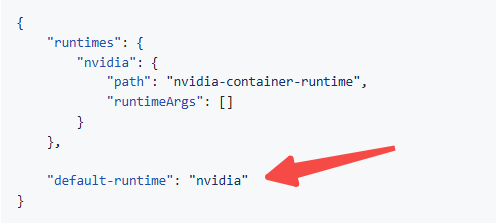
添加后重启docker并检查
$ sudo systemctl restart docker
$ sudo docker info | grep 'Default Runtime'
Default Runtime: nvidia修改文件 ".env" (环境变量INDEX_HOST必须设置,否则编译镜像报错)

激活环境变量:
# activate it
source .env5.1 benchmark
将jetson设置为高功率模式:
# check the current power mode
$ sudo nvpmodel -q
NV Power Mode: MODE_30W
2# set it to mode 0 (typically the highest)
$ sudo nvpmodel -m 0# reboot if necessary, and confirm the changes
$ sudo nvpmodel -q
NV Power Mode: MAXN
0bash jetson-containers/packages/llm/mlc/benchmarks.sh结果:
| model | prefill_rate | decode_rate |
| Llama-2-7b | 536.70 | 36.29 |
| Qwen2.5-0.5B | 2269.55 | 81.71 |
| Qwen2.5-1.5B | 413.98 | 45.27 |
| Qwen2.5-7B | 506.35 | 32.82 |
实测在高功率(60W)的条件下,Llama-2-7B的decode_rate的最大约36与上图官方给的47有一点差距;
5.2 llamaspeech
llamaspeech 是级联的结构 ASR+LLM+TTS,启动下面的服务之前,需要先启动ASR(riva)服务(否则ASR无法使用);
下载 riva_quickstart_arm64_2.19.0
下载后解压riva_quickstart_arm64_2.19.0.zip
启动 riva服务(需要NGC key):
bash riva_init.sh
bash riva_start.sh启动llamaspeaker
jetson-containers run $(autotag nano_llm) \python3 -m nano_llm.agents.web_chat --api=mlc \--model /models/Meta-Llama-3-8B-Instruct \--asr=riva --tts=piper如果无法从huggingface下载llama模型,可以从ModelScope 魔搭社区下载llama模型;
服务启动后,打开浏览器 https://IP_ADDRESS:8050
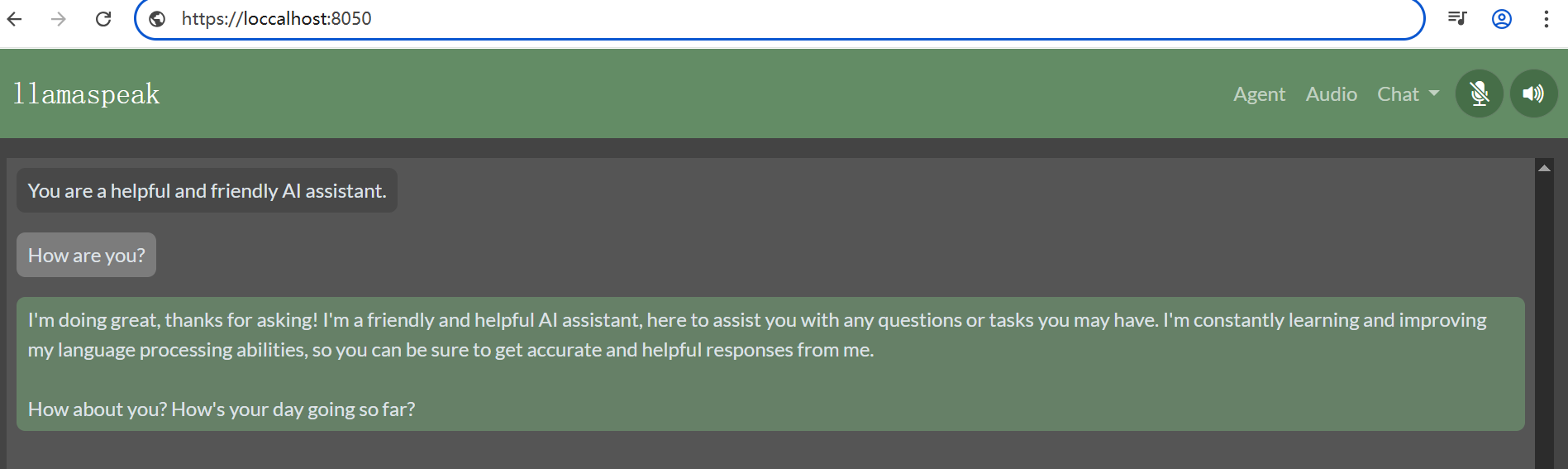
6、docker镜像编译说明
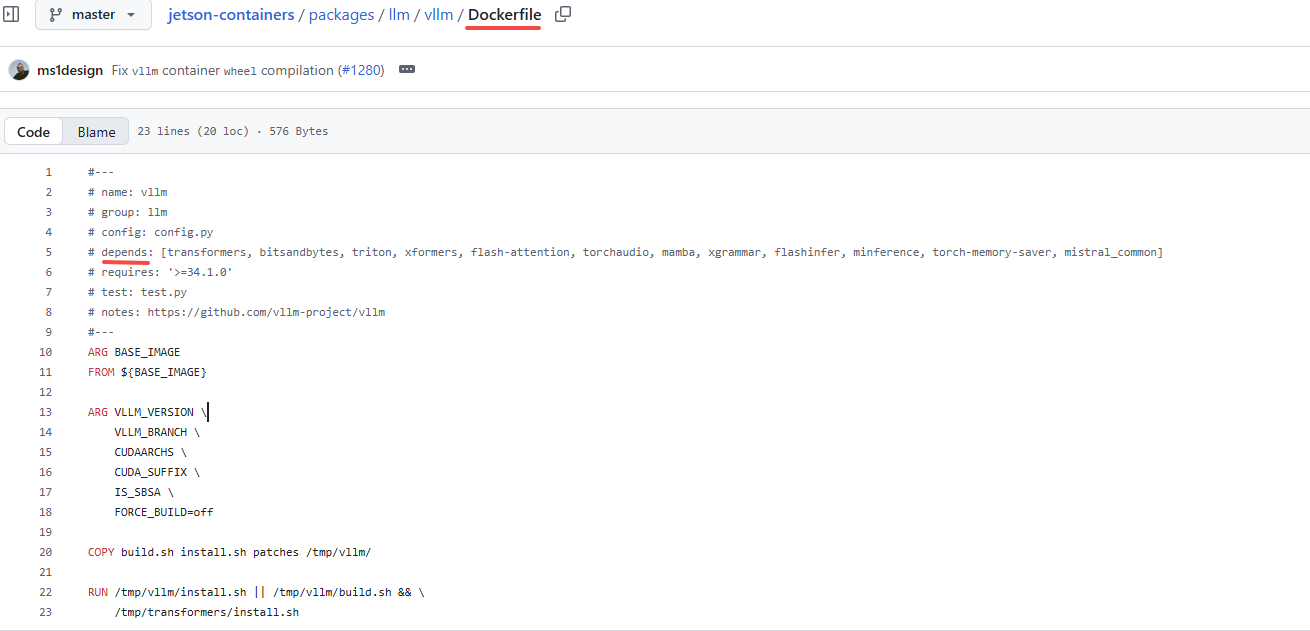
jetson-containers run $(autotag vllm)举例,如上图编译vllm如何有合适的镜像直接拉取,如果没有则需要编译镜像;
编译镜像过程:
查找package目录下packages/llm/vllm/Dockerfile
解析文件头,获取镜像依赖模块;
每个模块都要单独编译为一个镜像;
每个模块使用前一个依赖的模块镜像为基础镜像进行编译;
初始的基础镜像是:ubuntu:22.04
编译镜像很不完善,可能会遇到很多问题:
1、https://forums.developer.nvidia.com/t/pypi-jetson-ai-lab-dev-is-down/338695/6
2、https://forums.developer.nvidia.com/t/failed-building-nccl/342580/5
3、编译中断,需要删除之前已经编译好的镜像,重新开始编译;(可自行修改代码,文件jetson_containers/container.py:build_container(),从中断的镜像开始继续编译,节约时间)
7、参考:
1、nvidia 开发板 jetson 主页:Home - NVIDIA Jetson AI Lab
2、github:https://github.com/dusty-nv/jetson-containers/
另,新一代 balckwell架构的jetson AGX Thor已经发布,性能是orin的7.5倍;;
(完)