AWK命令完全指南:从理论到实战的文本处理利器
AWK命令完全指南:从理论到实战的文本处理利器
文章目录
- AWK命令完全指南:从理论到实战的文本处理利器
- 一、AWK概述:起源与版本
- 1.1 常见版本
- 二、AWK工作原理与流程
- 2.1 核心工作原理
- 2.2 完整工作流程:BEGIN → 主体 → END
- 三、AWK基础语法:选项与内置变量
- 3.1 常用命令选项
- 3.2 核心内置变量
- 四、AWK实战案例:从基础到进阶
- 4.1 基础操作:字段提取与输出
- 案例1:提取`/etc/passwd`中的用户名和家目录
- 案例2:打印指定行的内容
- 案例3:打印最后一列和总行数
- 4.2 模式匹配:按内容过滤行
- 案例4:过滤包含“root”的行
- 案例5:按数值条件过滤(如UID判断)
- 4.3 内置变量进阶:FS、OFS、FNR的使用
- 案例6:自定义输入/输出分隔符
- 案例7:处理多个文件时保持独立行号
- 4.4 数值运算与统计
- 案例8:计算1-10的和
- 案例9:统计系统用户和普通用户数量
- 4.5 条件判断:if语句的使用
- 案例10:按UID分类输出用户
- 4.6 生产环境实战:提取系统信息
- 案例11:提取网卡IP地址
- 案例12:提取根分区可用空间
- 五、AWK高级技巧:脚本与函数
- 5.1 编写AWK脚本:统计日志中不同状态码的数量
- 六、AWK与其他工具的结合
- 案例13:提取内存使用情况并排序
- 七、总结
在Linux/Unix系统的文本处理工具中,AWK绝对是“瑞士军刀”般的存在。它不仅是一个命令行工具,更是一门专门为文本分析设计的编程语言,擅长扫描、过滤、统计和格式化文本数据。本文将从AWK的基础理论出发,结合大量实战案例,带你全面掌握这一强大工具。
一、AWK概述:起源与版本
AWK诞生于20世纪70年代的贝尔实验室,其命名源自三位创始人Alfred Aho、Peter Weinberger和Brian Kernighan的姓氏首字母。作为行处理工具,它能从标准输入、管道或文件中读取数据,按规则进行处理后输出结果。
1.1 常见版本
目前Linux系统中最常用的是GNU AWK(简称gawk),各大发行版(如CentOS、Ubuntu)均默认预装,且与原始AWK、New AWK(nawk)完全兼容。可以通过以下命令验证:
# 查看awk的实际指向
ll `which awk`
# 输出示例:lrwxrwxrwx. 1 root root 4 8月 19 2022 /usr/bin/awk -> gawk
二、AWK工作原理与流程
AWK的核心优势在于**“分字段处理”** —— 与sed侧重整行处理不同,AWK会先将每行文本按分隔符拆分为“字段”,再按规则处理指定字段。
2.1 核心工作原理
- 逐行读取:从输入源(文件/管道/标准输入)逐行读取文本,存入内存;
- 字段拆分:默认以空格或Tab为分隔符,将当前行拆分为多个字段,用
$1(第1列)、$2(第2列)…$NF(最后一列)表示,$0代表整行; - 规则匹配:根据用户定义的“模式(Pattern)”判断是否处理当前行;
- 执行动作:若匹配成功,执行对应的“动作(Action)”;
- 循环重复:重复步骤1-4,直到所有行处理完毕。
2.2 完整工作流程:BEGIN → 主体 → END
AWK脚本由开始块(BEGIN)、主体块(Body)、结束块(END) 三部分组成,执行顺序严格固定:
| 模块 | 执行时机 | 作用 | 必须大写? |
|---|---|---|---|
| BEGIN块 | 读取输入数据前仅执行一次 | 初始化变量、打印表头 | 是 |
| 主体块 | 每读一行数据执行一次 | 核心处理逻辑(模式+动作) | 无关键字 |
| END块 | 所有数据处理完仅执行一次 | 汇总结果(如统计行数、求和) | 是 |
语法结构:
awk [选项] 'BEGIN{ 初始化命令 }模式{ 处理动作 }END{ 汇总命令 }
' 输入文件
三、AWK基础语法:选项与内置变量
掌握选项和内置变量是使用AWK的基础,它们能极大简化文本处理逻辑。
3.1 常用命令选项
| 选项 | 说明 | 示例 |
|---|---|---|
| -F | 指定输入字段分隔符(替代默认空格/Tab) | awk -F: '{print $1}' /etc/passwd |
| -f | 从脚本文件中读取AWK命令(适合复杂逻辑) | awk -f script.awk data.txt |
| -v | 定义自定义变量并赋值 | awk -v num=10 '{print $1+num}' data.txt |
3.2 核心内置变量
AWK预定义了一系列变量,无需声明即可直接使用,最常用的如下:
| 变量名 | 说明 | 示例场景 |
|---|---|---|
| $0 | 当前处理的整行文本 | 打印整行:awk '{print $0}' data.txt |
| $n | 当前行的第n个字段(n为正整数) | 打印第2列:awk '{print $2}' data.txt |
| NF | 当前行的字段总数(Number of Fields) | 打印最后一列:awk '{print $NF}' data.txt |
| NR | 已处理的总行数(Number of Records) | 打印行号+内容:awk '{print NR,$0}' data.txt |
| FNR | 每个文件独立计数的行号(多文件时用) | 处理两个文件:awk '{print FNR,$0}' a.txt b.txt |
| FS | 输入字段分隔符(同-F选项) | BEGIN{FS=":"}{print $1} |
| OFS | 输出字段分隔符(默认空格) | BEGIN{FS=":";OFS="---"}{print $1,$2} |
| FILENAME | 当前处理的文件名 | awk '{print FILENAME,$1}' data.txt |
四、AWK实战案例:从基础到进阶
理论结合实践才是掌握AWK的关键。以下案例基于Linux系统常见文件(如/etc/passwd、ifconfig输出等),覆盖日常工作中90%的使用场景。
4.1 基础操作:字段提取与输出
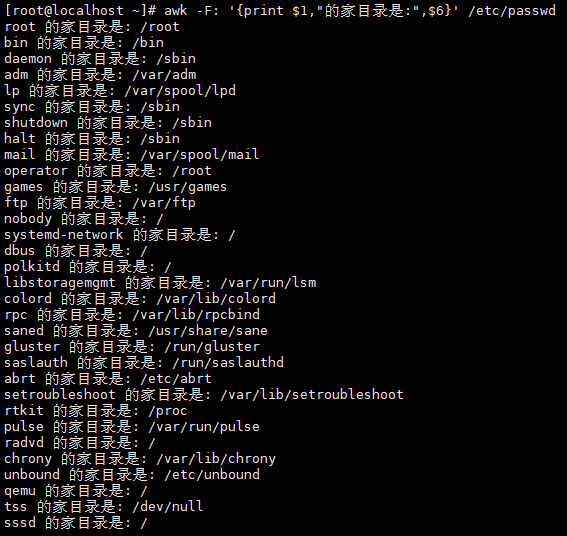
案例1:提取/etc/passwd中的用户名和家目录
/etc/passwd以冒号(:)分隔,第1列为用户名,第6列为家目录:
# 用-F指定分隔符,打印第1和第6列
awk -F: '{print $1,"的家目录是:",$6}' /etc/passwd
# 输出示例:root 的家目录是: /root
案例2:打印指定行的内容
# 打印第3行(NR==3)
awk 'NR==3{print}' /etc/passwd
# 打印第2-5行(NR>=2 && NR<=5)
awk 'NR>=2 && NR<=5{print $1}' /etc/passwd
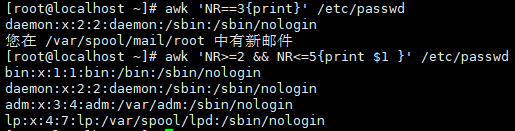
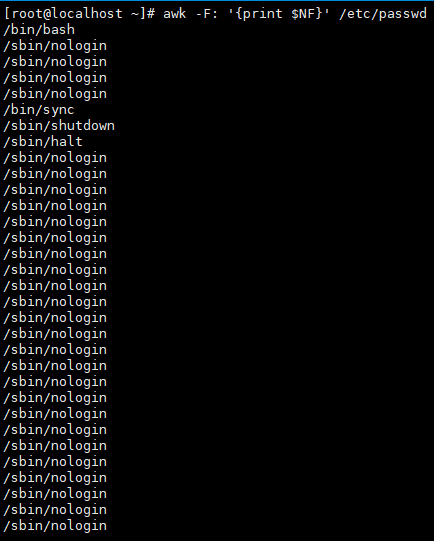
案例3:打印最后一列和总行数
# 打印/etc/passwd每行的最后一列($NF)
awk -F: '{print $NF}' /etc/passwd
# 用END块统计总行数
awk 'END{print "总行数:",NR}' /etc/passwd

4.2 模式匹配:按内容过滤行
AWK支持正则表达式匹配和关系运算匹配,用~表示“包含”,!~表示“不包含”。
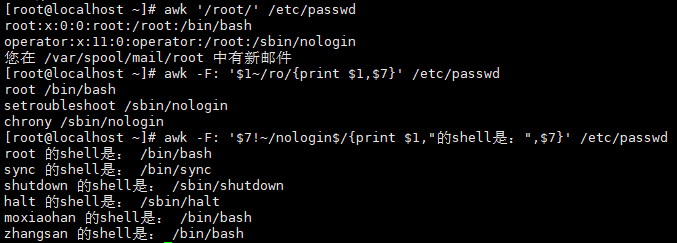
案例4:过滤包含“root”的行
# 打印包含root的整行
awk '/root/' /etc/passwd
# 打印用户名(第1列)包含“ro”的行
awk -F: '$1~/ro/{print $1,$7}' /etc/passwd
# 打印shell(第7列)不是nologin的用户名
awk -F: '$7!~/nologin$/{print $1,"的shell是:",$7}' /etc/passwd
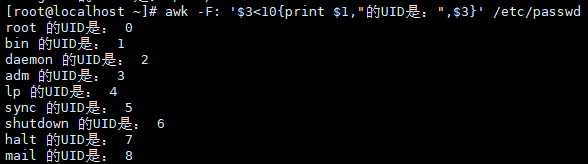
案例5:按数值条件过滤(如UID判断)
/etc/passwd第3列为UID,过滤UID<10的系统用户:
# UID<10的用户($3<10)
awk -F: '$3<10{print $1,"的UID是:",$3}' /etc/passwd
# 输出示例:root 的UID是: 0
4.3 内置变量进阶:FS、OFS、FNR的使用
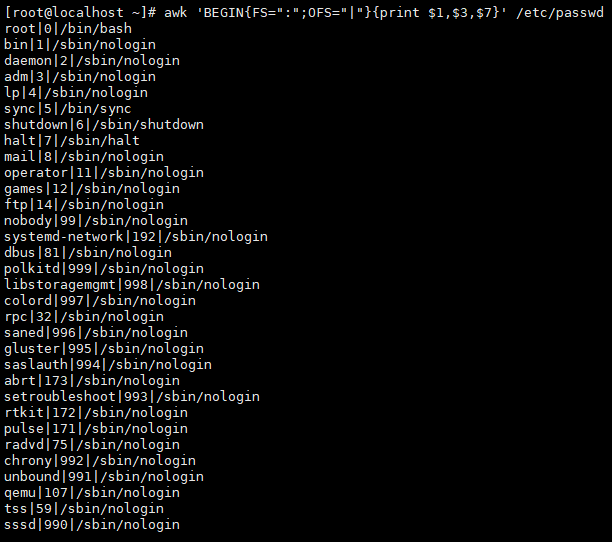
案例6:自定义输入/输出分隔符
# 输入用:分隔,输出用“|”分隔
awk 'BEGIN{FS=":";OFS="|"}{print $1,$3,$7}' /etc/passwd
# 输出示例:root|0|/bin/bash
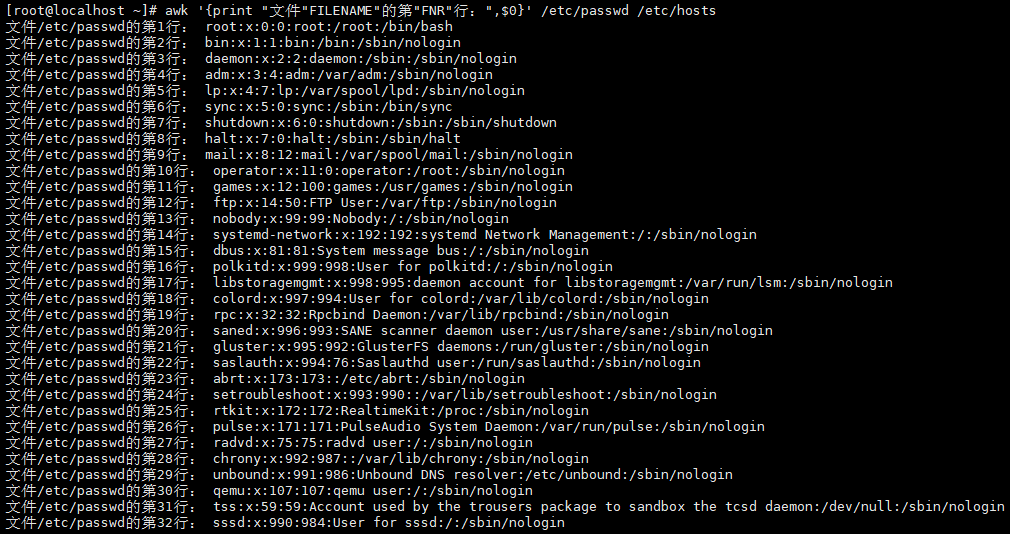
案例7:处理多个文件时保持独立行号
当处理多个文件时,NR会累计行数,FNR会为每个文件重新计数:
# 同时处理/etc/passwd和/etc/hosts,打印行号和内容
awk '{print "文件"FILENAME"的第"FNR"行:",$0}' /etc/passwd /etc/hosts
4.4 数值运算与统计
AWK支持常见的数学运算(+、-、*、/、%、^),可在BEGIN块初始化变量,在主体块累计计算。
案例8:计算1-10的和
awk 'BEGIN{sum=0;for(i=1;i<=10;i++)sum+=i;print "1-10的和:",sum}'
# 输出:1-10的和: 55

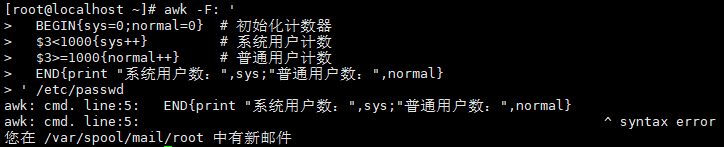
案例9:统计系统用户和普通用户数量
UID<1000为系统用户,UID>=1000为普通用户:
awk -F: 'BEGIN{sys=0;normal=0} # 初始化计数器$3<1000{sys++} # 系统用户计数$3>=1000{normal++} # 普通用户计数END{print "系统用户数:",sys;"普通用户数:",normal}
' /etc/passwd
4.5 条件判断:if语句的使用
AWK的if语句支持单分支、双分支(if-else)和多分支(if-else if-else),适合复杂逻辑判断。
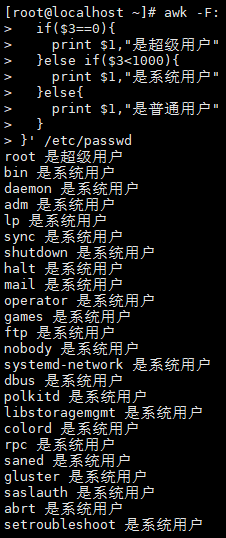
案例10:按UID分类输出用户
awk -F: '{if($3==0){print $1,"是超级用户"}else if($3<1000){print $1,"是系统用户"}else{print $1,"是普通用户"}
}' /etc/passwd
4.6 生产环境实战:提取系统信息
案例11:提取网卡IP地址
# 过滤包含netmask的行,打印第2列(IP地址)
ifconfig ens33 | awk '/netmask/{print "本机IP:",$2}'
# 输出示例:本机IP: 192.168.1.100

案例12:提取根分区可用空间
# df -h的第2行为根分区,第4列为可用空间
df -h | awk 'NR==2{print "根分区可用空间:",$4}'
# 输出示例:根分区可用空间: 45G
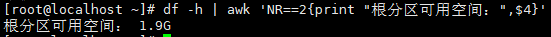
五、AWK高级技巧:脚本与函数
对于复杂逻辑,可将AWK命令写入脚本文件(.awk),再用-f选项执行。
5.1 编写AWK脚本:统计日志中不同状态码的数量
假设有nginx访问日志access.log,格式如下:
192.168.1.1 - - [01/Jan/2024:12:00:00 +0800] "GET /index.html HTTP/1.1" 200 1024
192.168.1.2 - - [01/Jan/2024:12:01:00 +0800] "POST /login HTTP/1.1" 404 512
创建脚本count_status.awk:
# 初始化数组(关联数组,键为状态码,值为次数)
BEGIN{print "=== 日志状态码统计 ==="}
# 第9列为状态码,累计计数
{status[$9]++}
# 结束时打印结果
END{for(code in status){print "状态码"code":"status[code]"次"}
}
执行脚本:
awk -f count_status.awk access.log
# 输出示例:
# === 日志状态码统计 ===
# 状态码200:1次
# 状态码404:1次
六、AWK与其他工具的结合
AWK常与grep、sed、sort等工具配合,形成强大的文本处理流水线。
案例13:提取内存使用情况并排序
# 用free命令获取内存,awk提取第2列(总量、已用、空闲),sort排序
free -m | awk 'NR==2{print "总内存:"$2"MB";print "已用内存:"$3"MB";print "空闲内存:"$4"MB"}' | sort -n -k2

七、总结
AWK作为一款“文本处理编程语言”,其核心价值在于**“按字段处理+规则驱动”**。掌握它的关键在于:
- 理解
BEGIN→主体→END的执行流程; - 熟练使用内置变量(尤其是
$0、$n、NF、NR); - 灵活结合正则匹配、条件判断和数值运算;
- 复杂逻辑用脚本文件管理,提高可维护性。
从简单的字段提取到复杂的日志统计,AWK都能胜任。多加练习,你会发现它能极大提升Linux文本处理的效率。