使用DCGAN实现动漫图像生成
DCGAN是GAN的一种具体架构实现,它引入了卷积神经网络来极大地提升了GAN在图像生成任务上的稳定性和效果。
一、DCGAN与GAN之间关系
GAN 是由Ian Goodfellow等人在2014年提出的一个思想框架。它定义了一个“生成器”和一个“判别器”互相博弈的抽象概念,但没有规定这两个网络具体应该用什么模型(比如全连接层、CNN、RNN等)来构建。
DCGAN 是2015年提出的一种具体架构。它首次成功地将卷积神经网络的结构融入GAN的框架中,为如何构建稳定、高效的GAN模型提供了一套经验性的设计指南。可以说,DCGAN是GAN思想在图像领域的一次非常成功的“工程实践”。
1、区别对比
属性 GAN DCGAN 网络结构 通常使用全连接层 使用转置卷积作为生成器,卷积层作为判别器 输入 随机噪声向量 随机噪声向量 输出(图像) 可以生成图像,但质量通常较差、分辨率低、且模糊 能生成更清晰、更高质量、更逼真的图像 稳定性 训练过程非常不稳定,容易模式崩溃(生成器只生成一种结果) 通过特定的架构设计,显著提高了训练稳定性 适用领域 更通用、更理论化的框架,可应用于多种数据类型(图像、文本等) 主要针对图像生成任务进行优化 层次结构 缺乏明确的层次结构,网络是“黑箱” 生成器有明显的层次结构,能从噪声中逐步“画”出图像 特征表示 隐空间的特征含义不明确 隐空间(输入噪声)的插值变化平滑,具有语义含义(如角度、表情)
2、GAN
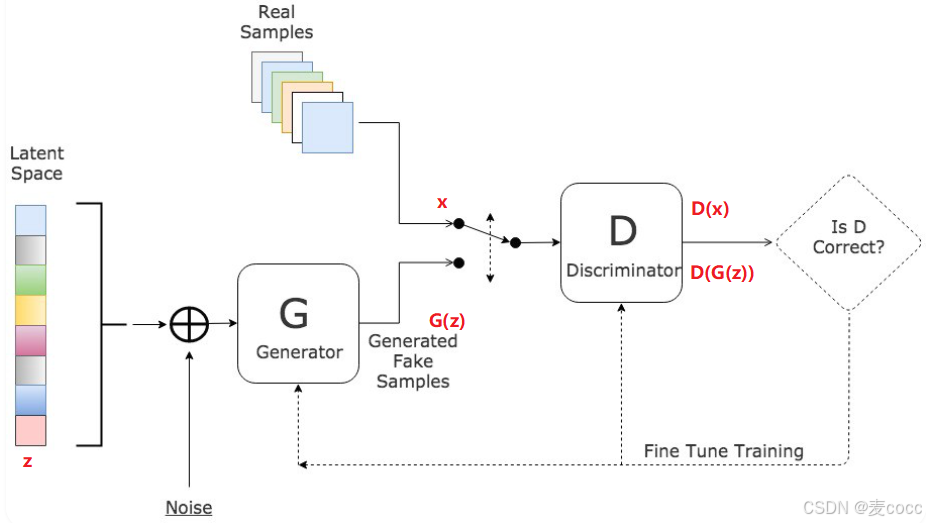
生成器(Generator):接收随机噪声作为输入,通过其内部的神经网络(通常是转置卷积网络)生成假数据(如图片)
判别器(Discriminator):判断输入的数据是真实数据(Real Sample)还是假数据(G(z))
训练原理:生成器生成越来越逼真的数据,使得判别器无法区分真假。判别器则不断优化自身,以更准确地区分真假数据。两者交替训练,最终达到纳什均衡。
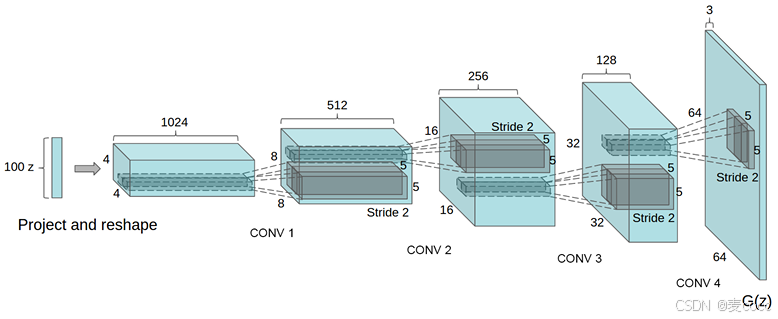
3、DCGAN
生成器:一个100维均匀分布的z被投影到一个小空间范围的卷积中,包含多个特征映射。随后通过一系列分步卷积操作将这一高级表示转换为64x64像素的图像
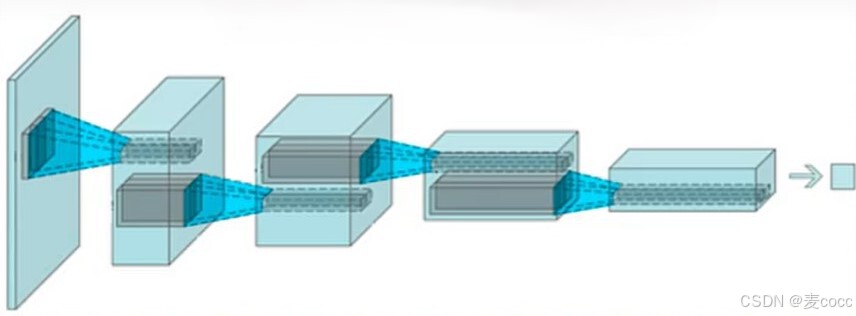
判别器:一个图片输入样本,判断这个样本是来自真实数据还是来自生成器,输出是一个概率值(0到1之间)
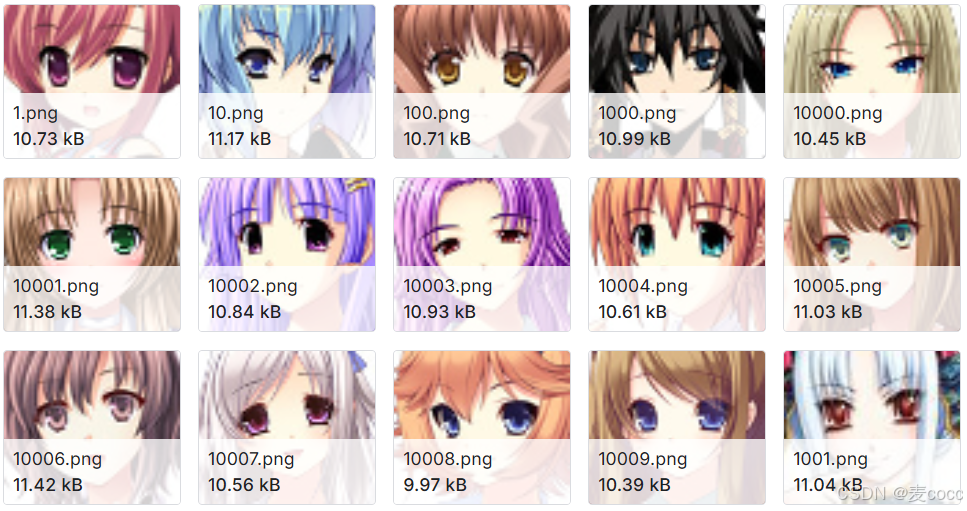
二、动漫图像数据集
Anime Faces数据集,包含从www.getchu.com上抓取的21551张动漫面孔,然后使用https://github.com/nagadomi/lbpcascadeanimeface中的动漫面孔检测算法进行裁剪。所有图像均调整为64*64以方便使用。在使用此数据集时,请务必引用两个来源。
三、动漫图像生成代码实现
1、生成器和判别器:model.py
#初始化网络中的权重
def apply_weights(model):classname = model.__class__.__name__if classname.find('Conv') != -1:nn.init.normal_(model.weight.data, 0.0, 0.02)elif classname.find('BatchNorm') != -1:nn.init.normal_(model.weight.data, 1.0, 0.02)nn.init.constant_(model.bias.data, 0)
#判别器由多个卷积层(Conv2d)和批量归一化层(BatchNorm2d)组成
class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()self.model = nn.Sequential(nn.Conv2d(3, 64, kernel_size=4, stride=2, padding=1),nn.BatchNorm2d(64),nn.LeakyReLU(0.2),nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1),nn.BatchNorm2d(128),nn.LeakyReLU(0.2),nn.Conv2d(128, 256, kernel_size=4, stride=2, padding=1),nn.BatchNorm2d(256),nn.LeakyReLU(0.2),nn.Conv2d(256, 512, kernel_size=4, stride=2, padding=1),nn.BatchNorm2d(512),nn.LeakyReLU(0.2),#激活函数nn.Conv2d(512, 1, kernel_size=4, stride=2, padding=0),nn.Sigmoid()#输出概率值)def forward(self, x):return self.model(x)#生成器由多个转置卷积层(ConvTranspose2d)组成
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()self.model = nn.Sequential(nn.ConvTranspose2d(100, 1024, kernel_size=4, stride=1, padding=0),nn.BatchNorm2d(1024),nn.ReLU(),nn.ConvTranspose2d(1024, 512, kernel_size=4, stride=2, padding=1),nn.BatchNorm2d(512),nn.ReLU(),nn.ConvTranspose2d(512, 256, kernel_size=4, stride=2, padding=1),nn.BatchNorm2d(256),nn.ReLU(),nn.ConvTranspose2d(256, 128, kernel_size=4, stride=2, padding=1),nn.BatchNorm2d(128),nn.ReLU(),nn.ConvTranspose2d(128, 3, kernel_size=4, stride=2, padding=1),nn.Tanh(),#输出)def forward(self, x):return self.model(x)
#生成器的损失函数
def modified_g_loss(fake_output, eps=1e-6):loss = (fake_output + eps).log().mean()return loss.neg()2、训练train.py
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, datasets
import argparse
import random
import os
from model import Discriminator, Generator, apply_weights, modified_g_lossdef get_arguments():parser = argparse.ArgumentParser()parser.add_argument('--dataset', dest='dataset', help='Path of the dataset', default=r'Anime_Generation/data')parser.add_argument('--epoch', dest='epoch', help='Number of training epochs', default=200,type=int)parser.add_argument('--device', dest='device', help='Specify the training device (default: GPU)', default='cuda' if torch.cuda.is_available() else 'cpu')parser.add_argument('--continue', dest='cont_train', help='Continue training?', default=False)parser.add_argument('--seed', dest='seed', help='Specify Random Seed', default=None)options = parser.parse_args()print(f'Training on {options.device}')if not options.seed:options.seed = random.randint(1, 1000)random.seed(int(options.seed))torch.manual_seed(int(options.seed))return options# 自定义数据集类
class ImageDataset(Dataset):def __init__(self, data_dir, transform=None):self.data_dir = data_dirself.transform = transformself.image_paths = []# 收集所有图片文件路径for root, _, files in os.walk(data_dir):for file in files:if file.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.tiff')):self.image_paths.append(os.path.join(root, file))if len(self.image_paths) == 0:raise FileNotFoundError(f"No images found in {data_dir}")print(f"Found {len(self.image_paths)} images in {data_dir}")def __len__(self):return len(self.image_paths)def __getitem__(self, idx):img_path = self.image_paths[idx]image = Image.open(img_path).convert('RGB')if self.transform:image = self.transform(image)# 返回图像和伪标签(因为GAN不需要真实的标签)return image, 0def load_data(data_dir):transform = transforms.Compose([transforms.Resize(64),transforms.CenterCrop(64),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])dataset = ImageDataset(data_dir, transform=transform)dataloader = DataLoader(dataset, batch_size=128, shuffle=True, num_workers=4)return dataloaderdef models_init():netD = Discriminator()netG = Generator()apply_weights(netD)apply_weights(netG)return netD, netGdef train(netD, netG, dataloader, num_epochs, device, check=False):if check:netD.load_state_dict(torch.load('./Discriminator.pth'))netG.load_state_dict(torch.load('./Generator.pth'))print('\nContinuing Training...\n')else:print('Starting Training...\n')netD.to(device)netG.to(device)criterion = nn.BCELoss()optimizerD = optim.Adam(netD.parameters(), lr=0.0002, betas=(0.5, 0.999))optimizerG = optim.Adam(netG.parameters(), lr=0.0002, betas=(0.5, 0.999))lossD_list = [] # To store lossD values for plottinglossG_list = [] # To store lossG values for plottingfor epoch in range(num_epochs):torch.save(netD.state_dict(), f'Discriminator.pth')torch.save(netG.state_dict(), f'Generator.pth')for idx, (images, _) in enumerate(dataloader):images = images.to(device)optimizerD.zero_grad()output = netD(images).reshape(-1)# 解决 smooth_real > 1.0 的问题smooth_real = round(random.uniform(0.7, 1.0), 2)labels = (smooth_real * torch.ones(images.shape[0])).to(device)labels = labels.clamp(0, 1) # 确保 labels 在 [0,1] 之间lossD_real = criterion(output, labels)fake = netG(torch.randn(images.shape[0], 100, 1, 1).to(device))output = netD(fake.detach()).reshape(-1)smooth_fake = round(random.uniform(0.0, 0.3), 2)labels = (smooth_fake * torch.ones(images.shape[0])).to(device)labels = labels.clamp(0, 1) # 确保 labels 在 [0,1] 之间lossD_fake = criterion(output, labels)lossD = lossD_real + lossD_fakelossD.backward()optimizerD.step()optimizerG.zero_grad()output = netD(fake).reshape(-1)lossG = modified_g_loss(output)lossG.backward()optimizerG.step()if idx % 50 == 0 and idx != 0:print(f'epoch[{epoch+1:3d}/{num_epochs}]=> lossD: {lossD.item():.4f}\tlossG: {lossG.item():.4f}')# Save loss values for each epochlossD_list.append(lossD.item())lossG_list.append(lossG.item())# Plot the loss curves after trainingplot_losses(lossD_list, lossG_list)def plot_losses(lossD_list, lossG_list):# Create "loss" directory if it doesn't existif not os.path.exists('loss'):os.makedirs('loss')plt.figure(figsize=(10, 5))plt.plot(range(len(lossD_list)), lossD_list, label='Discriminator Loss (lossD)', color='blue')plt.plot(range(len(lossG_list)), lossG_list, label='Generator Loss (lossG)', color='red')plt.xlabel('Epoch')plt.ylabel('Loss')plt.title('LossD and LossG Over Epochs')plt.legend()plt.grid(True)plt.savefig('loss/training_loss.png') # Save the loss plot to a file in the "loss" folderplt.show()if __name__ == '__main__':arguments = get_arguments()dataloader = load_data(arguments.dataset)netD, netG = models_init()train(netD, netG, dataloader, int(arguments.epoch), arguments.device, arguments.cont_train)3、使用训练好的Generator.pth生成图像,这里为200轮训练结果,生成效果还有很大的提升空间。后期我会进行更多训练轮数,尝试提升生成效果。

小白刚入门,如有错误请批评指正O(∩_∩)O