Spring二级缓存为什么不行(详细)
概述
对于spring为什么二级缓存不行,一定要用三级缓存,网上的说法很多,好多都是说了个大概,自己整理查阅了一下,终于弄透彻了。(主要讲解一级缓存加二级缓存为什么不行)
开讲
为什么要有spring三级缓存?
这个问题大家应该都明白,为了解决循环依赖问题呗,对吧,怎么解决循环依赖的呢?
噢大家都知道,例如我现在又一个Class A, 一个Class B,并且Bean A依赖Bean B,Bean B依赖Bean A
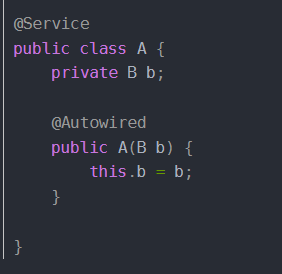
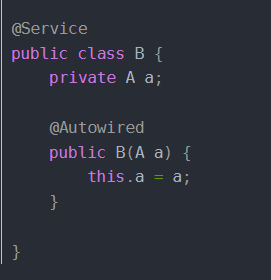
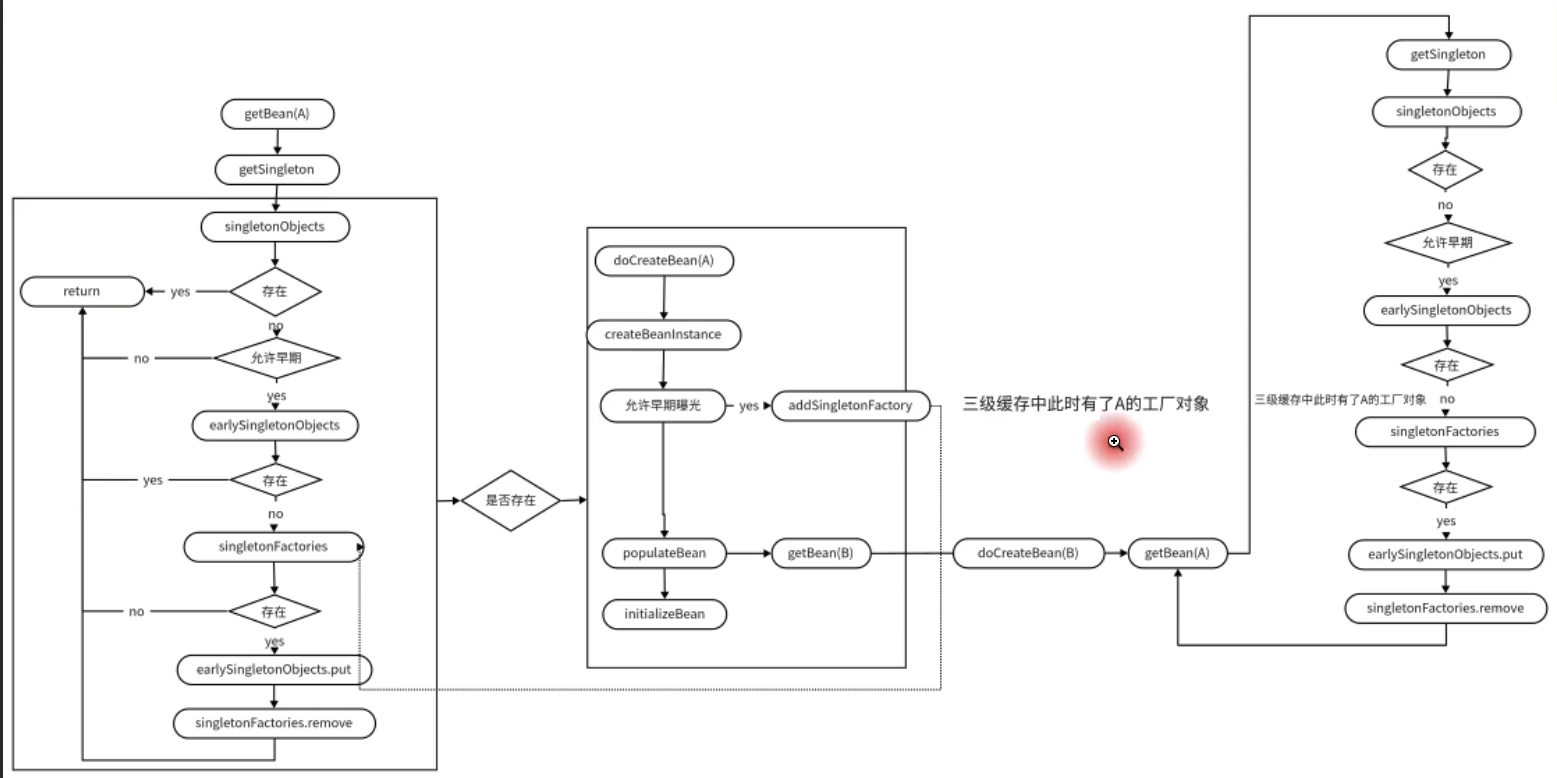
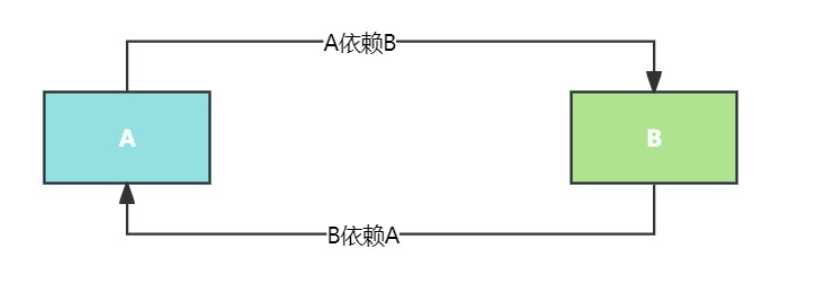 那么在注入的时候是什么样子的,首先创建A的时候实例化之后,需要属性注入B,这时候将A的ObjectFactory放到三级缓存当中,然后去创建B,实例化之后,注入A的时候就能够到三级缓存中获取到A的早期对象注入给B,完成B的创建,进而回去完成A(如果A要创建代理对象则返回的是代理对象,不用代理就是未初始化的原始对象)的创建,解决了循环依赖的问题。
那么在注入的时候是什么样子的,首先创建A的时候实例化之后,需要属性注入B,这时候将A的ObjectFactory放到三级缓存当中,然后去创建B,实例化之后,注入A的时候就能够到三级缓存中获取到A的早期对象注入给B,完成B的创建,进而回去完成A(如果A要创建代理对象则返回的是代理对象,不用代理就是未初始化的原始对象)的创建,解决了循环依赖的问题。
那我如果只有二级缓存行不行呢?
删掉三级缓存
这个样子,我去掉三级缓存,我在实例化A之后,判断A是否需要创建代理对象,如果需要代理对象则创建代理对象并加入二级缓存,不需要就把原始的对象加入二级缓存,可以吗?
先说结论:如果A不需要代理,那么二级缓存是可以解决循环依赖问题的,但是如果A需要代理,那么三级缓存时不能删掉的?
如果A不需要代理,那么就很简单生成一个半成品原始对象,放到二级缓存中,B需要时直接注入,最后把A完全初始化后(执行初始化方法和Bean后置处理器的后置方法),将A放入一级缓存,没有什么问题。
那么为什么需要代理的时候就会产生问题呢?
因为三级缓存不仅仅是做了创建返回代理对象或者原始对象这件事情,他其实还做了其他事情。
注:B 实例化后需要注入 A,从三级缓存取 ObjectFactory,执行 getObject() → 调用 getEarlyBeanReference。getEarlyBeanReference 会遍历 BeanPostProcessor,最终执行到 AbstractAutoProxyCreator 的 getEarlyBeanReference 方法
来看代码:
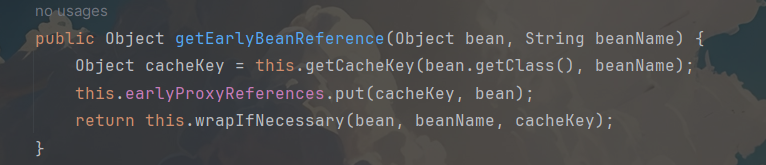
bean传的是原始半成品的A对象,最后决定是返回代理对象还是原始对象的是最下面这行代码,我们的例子经过这个方法最终生成了A的代理对象,假设为(0x333),此时B中的A属性就被赋值成了(0x333),但是在这行代码上面还做了一件事情,将这个bean保存到earlyProxyReferences当中,这个map是用来标识当前bean是否生成过代理对象的,因为A如果需要代理,肯定会被加到这个里面。
那如果我们是取掉三级缓存,自己在二级缓存中存储了A的代理对象,而没有在这个map中保存这个bean已经被代理过了,会发生什么?来看看Bean后置处理器的逻辑
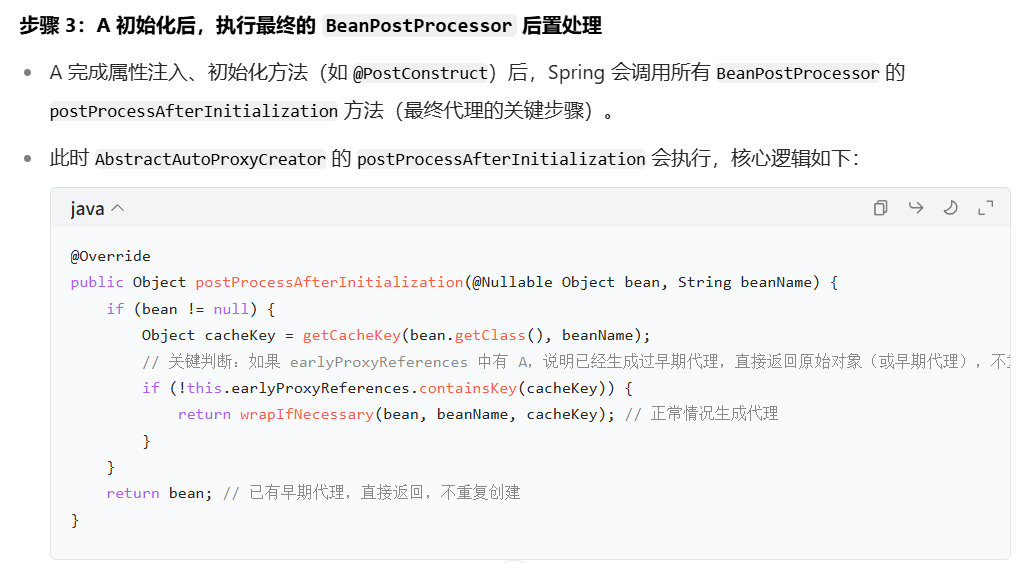
可以看到A初始化之后,执行后置处理器逻辑的时候会判断当前的Bean是否已经被代理过,如果没有并且需要生成代理对象的话,那么就会为A再创建一个代理对象(0x444)
执行
Object finalExposedObject = exposeObject; // exposeObject 此时是 A代理对象(0x444)
if (earlySingletonExposure) {// 从二级缓存获取早期代理 0x333Object earlySingletonReference = getSingleton(beanName, false);if (earlySingletonReference != null) {// 因为 exposeObject(0x444)!= bean(0x111,原始对象),所以将最终对象是 0x444if (exposeObject == bean) {finalExposedObject = earlySingletonReference;}}
}
// 将最终对象 0x444 存入一级缓存
addSingleton(beanName, finalExposedObject);这样B中存的是代理对象0x333,而实际上最终保存的是0x444,就出现了不一致问题,并且三级缓存时延迟加载的,只有循环依赖出现的时候我们才会用到它,不需要每次都去调用三级缓存。