Linux之shell-awk命令详解
1. AWK 概述
1.1 定义与核心定位
AWK 是一种专为文本处理设计的编程语言,同时也是功能强大的文本分析工具。它以 “行处理” 为核心,能高效完成文本的扫描、过滤、统计汇总等工作,处理的数据来源灵活,可来自标准输入(如键盘输入)、管道(通过|传递的数据流)或本地文件。
1.2 起源与版本演进
- 起源:20 世纪 70 年代诞生于贝尔实验室,名称取自三位创始人 Alfred Aho、Peter Weinberger、Brian Kernighan 的姓氏首字母。
- 主要版本
- 基础 AWK:最初由 AT&T 实验室开发的原始版本,功能较为基础。
- NAWK(New AWK):AT&T 实验室对基础 AWK 的升级版,扩展了更多功能,兼容性更强。
- GAWK(GNU AWK):由自由软件基金会(FSF)维护的版本,是所有 GNU/Linux 发行版(如 CentOS、Ubuntu)的默认 AWK 工具,完全兼容基础 AWK 和 NAWK。在 Linux 系统中,
awk命令本质是gawk的软链接,可通过以下命令验证:bash
[root@benet22 opt]# which awk # 查看awk命令路径 /usr/bin/awk [root@benet22 opt]# ll `which awk` # 查看软链接指向 lrwxrwxrwx. 1 root root 4 8月 19 2022 /usr/bin/awk -> gawk
2. 工作原理与流程
2.1 核心工作原理
- 逐行读取与字段拆分:AWK 按 “行” 为单位读取文本,默认以空格或 Tab 键为分隔符,将每行拆分为多个 “字段”(类似表格的列),并将拆分后的字段存入内建变量(如
$1表示第一列、$2表示第二列)。 - 模式匹配与动作执行:对每一行数据,先判断是否匹配预设的 “模式”(如包含特定字符串、满足数值条件),若匹配则执行对应的 “动作”(如打印字段、计算数值)。若未定义模式,默认匹配所有行;若未定义动作,默认打印整行内容。
- 与 sed 的核心区别:
sed更侧重 “整行处理”(如替换整行、删除整行),而 AWK 更擅长 “字段级处理”—— 先拆分每行的字段,再针对字段进行精准操作(如提取某几列、按列统计)。 - 支持的运算与逻辑:可直接使用数学运算符(
+加、-减、*乘、/除、%取余、^或**乘方)和逻辑运算符(&&与、||或、!非),满足复杂的条件判断与数值计算需求。
2.2 完整工作流程
2.2.1 结构组成
AWK 脚本的基本结构由 “模式(Pattern) ” 和 “动作(Process) ” 组成,一个脚本可包含多个 “模式 - 动作” 对,核心语法框架如下:
awk [选项] 'BEGIN{ 初始化动作 } 模式1{ 动作1 } 模式2{ 动作2 } ... END{ 汇总动作 }' 目标文件
- 模式:决定动作的触发条件,常见类型包括正则表达式(如
/root/匹配含 “root” 的行)、关系表达式(如$3>10匹配第三列大于 10 的行)、行号条件(如NR==5匹配第五行)。 - 动作:触发后执行的操作,可包含变量赋值、字段打印、内置函数调用(如
print)、流控制语句(如if、for)。
2.2.2 三阶段执行流程
AWK 的执行过程严格分为三个阶段,按顺序依次执行:
- BEGIN 阶段:在读取任何文本数据前执行,仅执行1 次。常用于初始化变量(如
x=0)、打印表头(如print "列1 列2"),属于可选模块(若无需初始化,可省略 BEGIN 块)。 - 主体阶段:逐行读取目标文件,对每一行依次匹配所有 “模式 - 动作” 对,满足条件则执行对应动作,重复此过程直至所有行处理完毕。此阶段是 AWK 的核心,若未定义任何模式,默认对每一行执行动作;若未定义任何动作,默认打印匹配行的整行内容。
- END 阶段:在所有文本行处理完成后执行,仅执行1 次。常用于输出统计结果(如
print "总行数:"NR)、汇总计算结果,属于可选模块(若无需汇总,可省略 END 块)。
2.2.3 简化执行逻辑
可概括为 “读(Read)→ 执(Execute)→ 重(Repeat) ” 三步循环:
- 读(Read):从标准输入、管道或文件中读取 1 行文本,存入内存。
- 执(Execute):对当前行,按脚本中的 “模式 - 动作” 对依次判断并执行操作。
- 重(Repeat):重复 “读→执” 步骤,直至所有输入数据读取完毕,最后执行 END 块(若有)。
3. 基本语法与关键变量
3.1 常用命令格式
AWK 的命令调用主要有两种方式,根据使用场景选择:
方式 1:直接在命令行写脚本(适合简单需求
awk [选项] '模式{动作}' 目标文件1 目标文件2 ...
- 示例:提取
/etc/passwd中含 “root” 的行,并打印第一列(用户名):awk -F: '/root/{print $1}' /etc/passwd
方式 2:通过脚本文件执行(适合复杂需求)
当脚本包含多个模式 - 动作对或逻辑较复杂时,可将脚本写入文件,通过-f选项调用:
awk -f 脚本文件路径 目标文件1 目标文件2 ...
- 示例:创建脚本文件
awk_script.awk,内容如下:BEGIN{FS=":"; print "用户名 家目录"} # 初始化:冒号为分隔符,打印表头 $3==0{print $1, $6} # 匹配第三列(UID)为0的行,打印用户名和家目录 END{print "处理完成"} # 汇总:打印结束提示awk -f awk_script.awk /etc/passwd
3.1.2 常用选项
-F 分隔符:指定输入字段的分隔符,替代默认的 “空格 / Tab”,如-F:表示以冒号为分隔符(常用于处理/etc/passwd、/etc/group等系统文件)。-v 变量=值:在执行前定义自定义变量,如awk -v x=10 '{print $1+x}' file,将第一列与 10 相加后打印。
3.2 关键变量(内建变量 + 自定义变量)
3.2.1 核心内建变量(无需定义,直接使用)
内建变量是 AWK 预定义的、与文本处理相关的变量,涵盖字段、行号、文件名等关键信息,常用变量如下:
| 变量名 | 含义 | 示例 |
|---|---|---|
FS | 输入字段分隔符(Field Separator),默认空格 / Tab | BEGIN{FS=":"}:指定冒号为输入分隔符 |
NF | 当前行的字段总数(Number of Fields),即 “列数” | {print "当前行有"NF"列"}:打印每行的列数 |
NR | 当前处理的行号(Number of Records),所有文件统一计数 | {print NR, $0}:打印行号和整行内容 |
$0 | 当前行的完整内容(整行文本) | /root/{print $0}:打印含 “root” 的整行 |
$n | 当前行的第 n 个字段(n 为正整数),如$1第一列、$2第二列 | -F:{print $1, $6}:打印第一列(用户名)和第六列(家目录) |
FILENAME | 当前处理的文件名 | {print FILENAME, $1}:打印文件名和第一列 |
FNR | 当前处理的行号(按单个文件计数,新文件重新从 1 开始) | awk '{print FNR, $0}' file1 file2:file1 和 file2 的行号分别从 1 开始 |
OFS | 输出字段分隔符(Output Field Separator),默认空格 | BEGIN{OFS="---"}{print $1, $2}:用 “---” 分隔输出第一列和第二列 |
ORS | 输出记录分隔符(Output Record Separator),默认换行符 | BEGIN{ORS=" "}{print $0}:将所有行合并为一行,用空格分隔 |
RS | 输入记录分隔符(Record Separator),默认换行符 | BEGIN{RS=":"}{print $0}:以冒号为分隔符,将文本拆分为 “行” 处理 |
3.2.2 自定义变量
用户可根据需求自行定义变量,无需声明类型,直接赋值即可:
- 赋值方式:在 BEGIN 块、主体块或命令行中赋值,如
BEGIN{x=0}(初始化计数器 x 为 0)、{x=$3+10}(将第三列加 10 赋值给 x)。 - 使用示例:统计
/etc/passwd中以/bin/bash结尾的行数:bash
awk -F: 'BEGIN{x=0} /\/bin\/bash$/{x++} END{print "bash用户数:"x}' /etc/passwd
4. 实战案例
4.1 案例文本测试
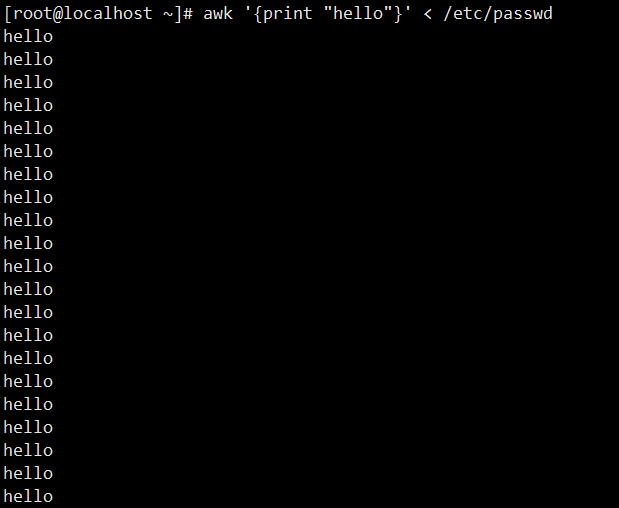
1. 固定输出指定内容:读取/etc/passwd文件,对每一行都输出 “hello”(awk隐含逐行循环,无匹配条件时默认处理所有行)。
[root@localhost ~]# awk '{print "hello"}' < /etc/passwd
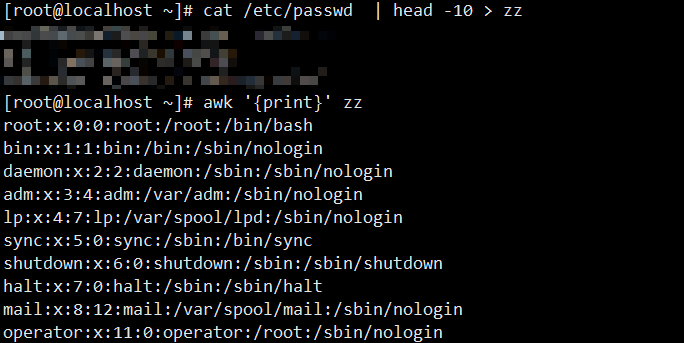
2. 生成测试文件:将/etc/passwd的前 10 行内容写入zz文件,用于后续测试。
[root@localhost ~]# cat /etc/passwd | head -10 > zz
3. 打印文件所有内容:输出zz文件的完整内容(无自定义动作时,默认打印整行,等同于cat zz)。
[root@localhost ~]# awk '{print}' zz
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
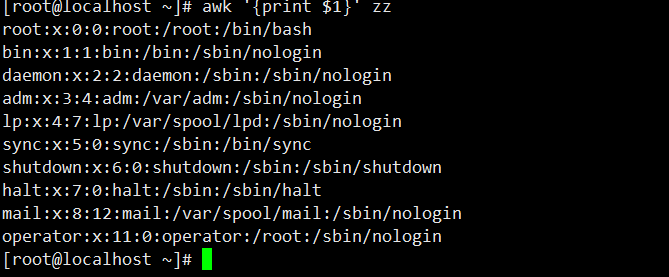
4. 默认分隔符提取字段(无效果演示):awk默认以空格或 Tab 为分隔符,zz文件每行内容以冒号分隔(无空格),因此$1代表整行,无法拆分字段。
[root@localhost ~]# awk '{print $1}' zz
root:x:0:0:root:/root:/bin/bash # 整行被视为第一列
bin:x:1:1:bin:/bin:/sbin/nologin
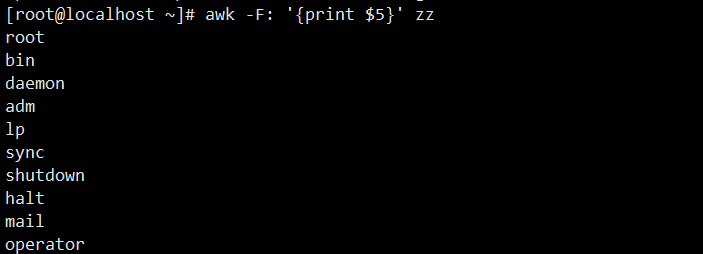
5. 自定义单分隔符(冒号):通过-F:指定冒号为分隔符,提取zz文件中每行的第五列(用户注释信息)。
[root@localhost ~]# awk -F: '{print $5}' zz
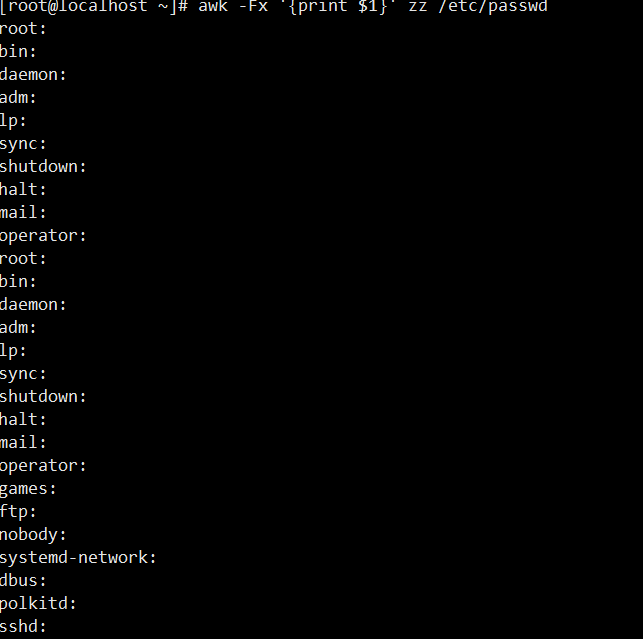
6. 自定义单分隔符(x):以 “x” 为分隔符,提取/etc/passwd文件中每行的第一列。
[root@localhost ~]# awk -Fx '{print $1}' /etc/passwd
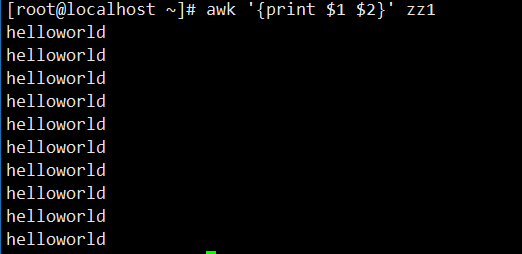
7. 提取多列(无显式分隔):读取zz1文件(含hello world等以空格分隔的内容),提取第一列($1)和第二列($2),输出时两列无明显分隔(直接拼接)。
[root@localhost ~]# awk '{print $1 $2}' zz1
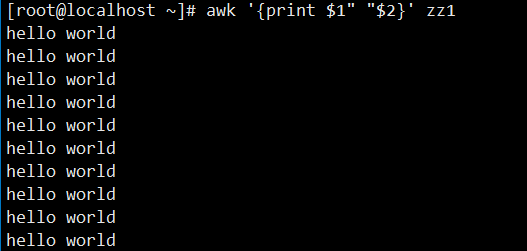
8. 自定义输出分隔(空格):通过双引号包裹空格(""),使zz1文件的第一列和第二列以空格分隔输出;若不加双引号,空格会被视为变量(无意义),需用双引号明确为常量空格。
[root@localhost ~]# awk '{print $1""$2}' zz1 # 显式添加空格分隔
hello world # 输出结果
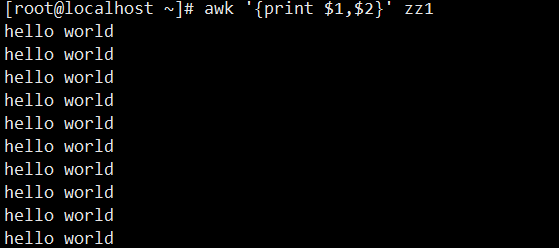
9. 逗号的空格效果:awk中逗号(,)默认映射为输出字段分隔符(OFS,默认值为空格),因此用逗号分隔$1和$2,输出时两列自动以空格分隔。
[root@localhost ~]# awk '{print $1,$2}' zz1
hello world # 输出结果(与上一条命令效果一致)
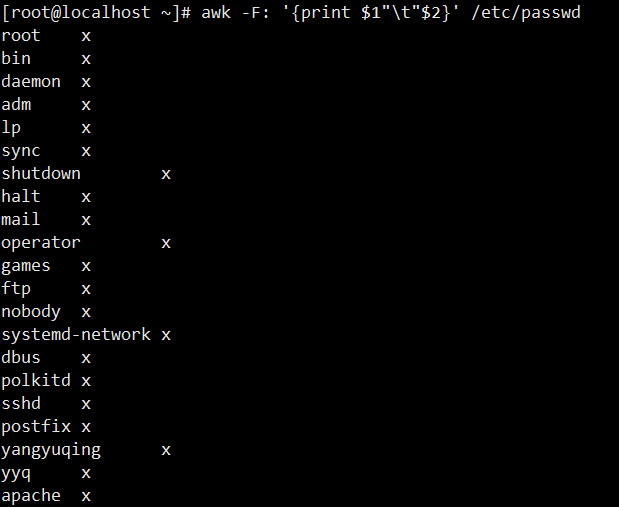
10. 自定义输出分隔(制表符):通过\t表示制表符,以冒号为输入分隔符,提取/etc/passwd的第一列和第二列,输出时用制表符分隔两列。
[root@localhost ~]# awk -F: '{print $1"\t"$2}' /etc/passwd
11. 自定义多分隔符(冒号 / 斜杠):通过-F[:/]指定 “冒号” 或 “斜杠” 为分隔符(只要遇到其中一个字符,均视为分隔符),提取zz文件的第九列。
[root@localhost ~]# awk -F[:/] '{print $9}' zz
bin # 输出结果
sbin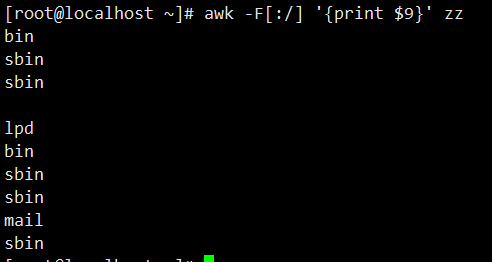
4.2 内建变量实战
awk 常用内置变量包括$1、$2、NF、NR、$0,以下通过实际命令案例演示各变量的用法,操作对象涉及pass.txt(含用户信息的文本文件,格式同/etc/passwd)、zz(自定义文本文件)、/etc/passwd(系统用户配置文件)。
核心变量说明
$1:代表当前行的第一列(第一个字段)$2:代表当前行的第二列(第二个字段),以此类推$0:代表当前行的整行内容NF:代表当前行的字段个数(列数)NR:代表当前行的行号(序数)
具体操作案例
打印包含 “root” 的整行内容:以冒号为分隔符(
-F:),匹配含 “root” 的行,通过$0输出整行。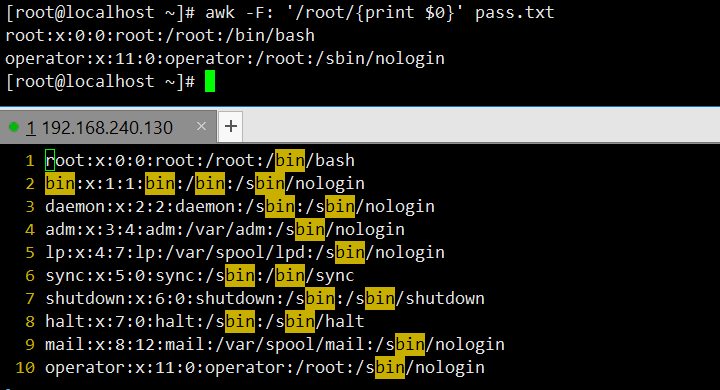
打印包含 “root” 的行的第一列:匹配含 “root” 的行,通过
$1输出第一列(用户名)。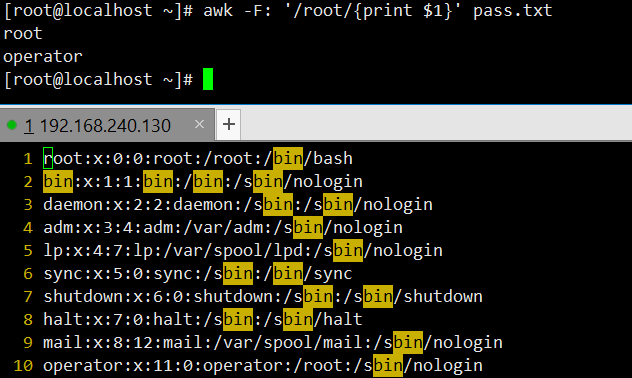
打印包含 “root” 的行的第一列和第六列:匹配含 “root” 的行,输出第一列(用户名)和第六列(家目录)。
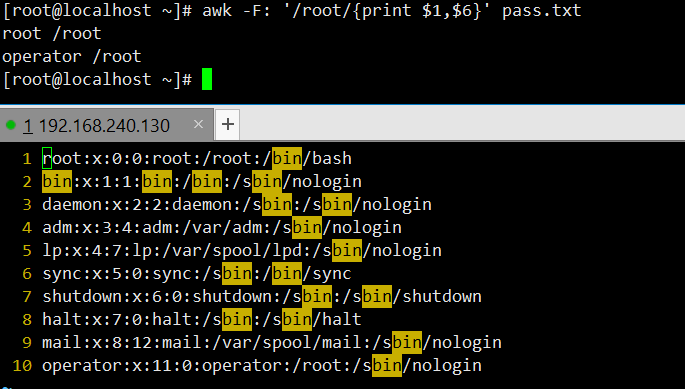
默认打印包含 “root” 的行:未指定动作时,awk 默认打印匹配到的行(等同于
print $0)。[root@localhost ~]# awk '/root/' /etc/passwd root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin打印每行的列数:以 “冒号” 或 “斜杠” 为分隔符(
-F[:/]),通过NF输出zz文件每行的字段总数。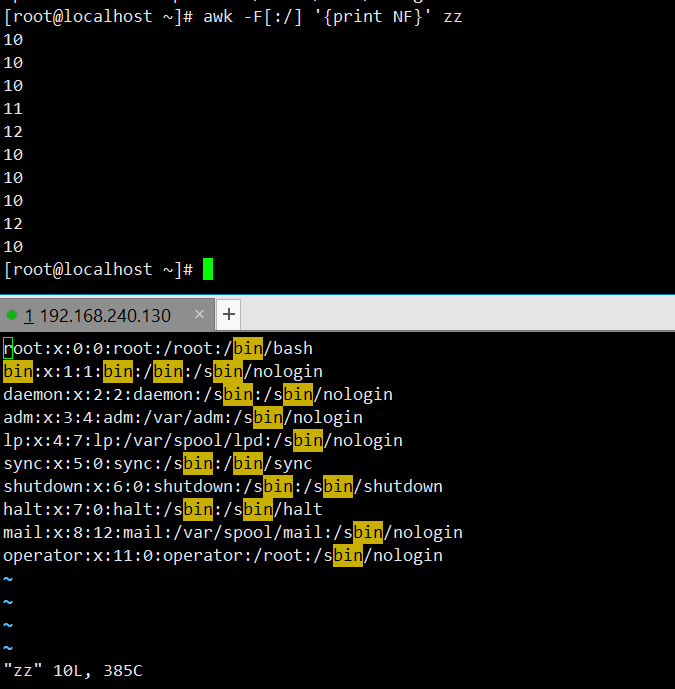
显示行号(按单个文件计数):通过
NR输出zz文件每行的行号。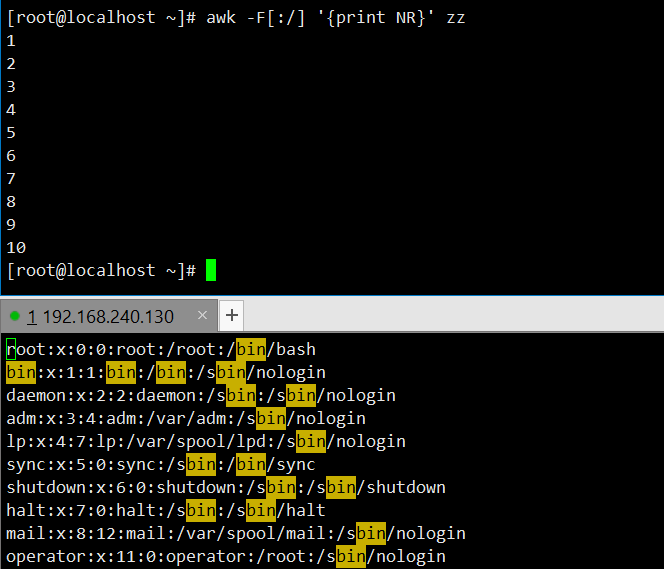
显示文件的行号:输出
pass.txt文件每行的行号。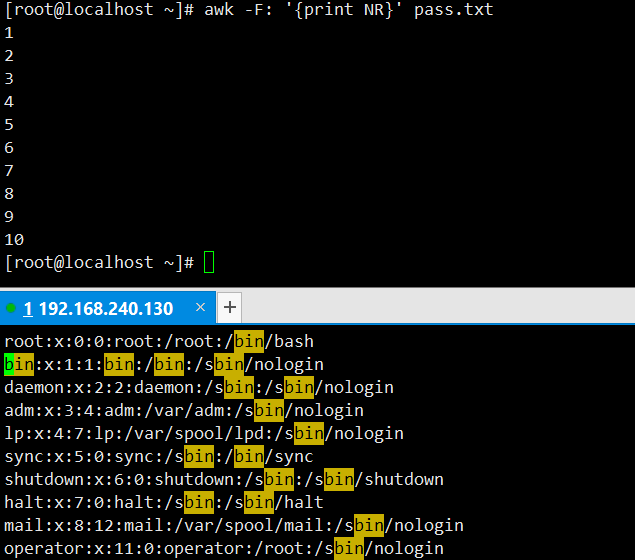
显示行号与整行内容:输出
pass.txt文件每行的行号(NR)和整行内容($0)。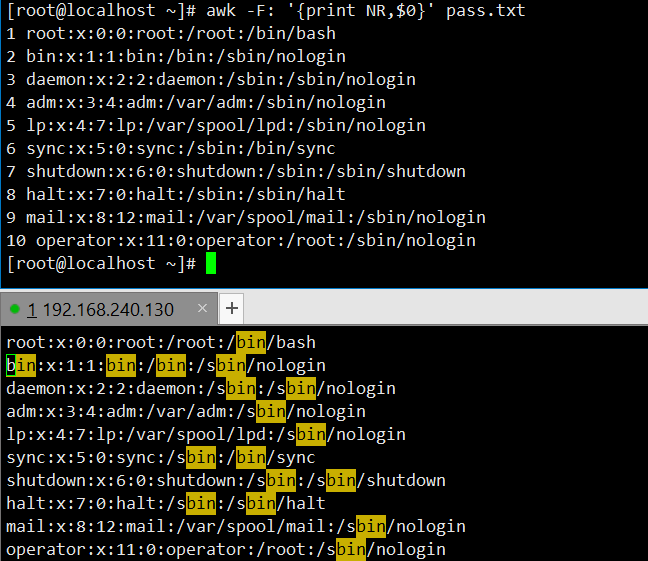
打印指定行(第二行):通过
NR==2匹配第二行,未指定动作时默认打印整行。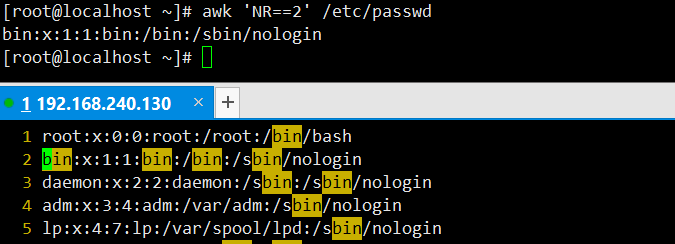
打印指定行(第二行)的显式写法:通过
NR==2匹配第二行,显式用print输出整行,与上一条命令效果一致。[root@localhost ~]# awk 'NR==2{print}' /etc/passwd bin:x:1:1:bin:/bin:/sbin/nologin打印指定行的指定列:匹配第二行,以冒号为分隔符,输出第二行的第一列。
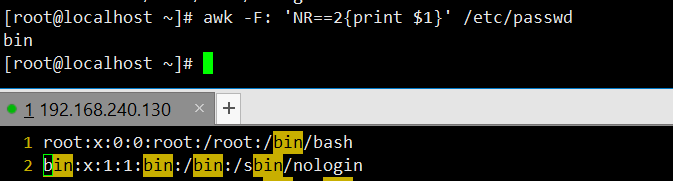
打印最后一列:以冒号为分隔符,通过
$NF(NF为列数,$NF即最后一列)输出/etc/passwd每行的最后一列(登录 Shell)。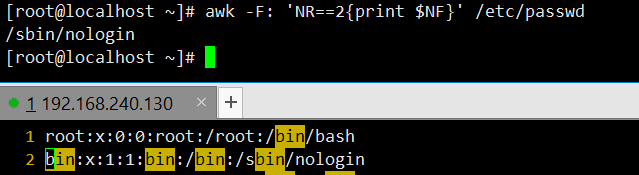
打印文件总行数:在
END模块中通过NR输出/etc/passwd的总行数(NR在文件处理结束后等于总行数)。[root@localhost ~]# awk 'END{print NR}' /etc/passwd 65打印文件最后一行:在
END模块中通过$0输出/etc/passwd的最后一行(文件处理结束前,$0为最后一行内容)。[root@localhost ~]# awk 'END{print $0}' /etc/passwd stu10:x:1020:1020::/home/stu10:/bin/bash显示每行的列数(带描述):以冒号为分隔符,输出
zz文件每行的列数,搭配文字描述提升可读性。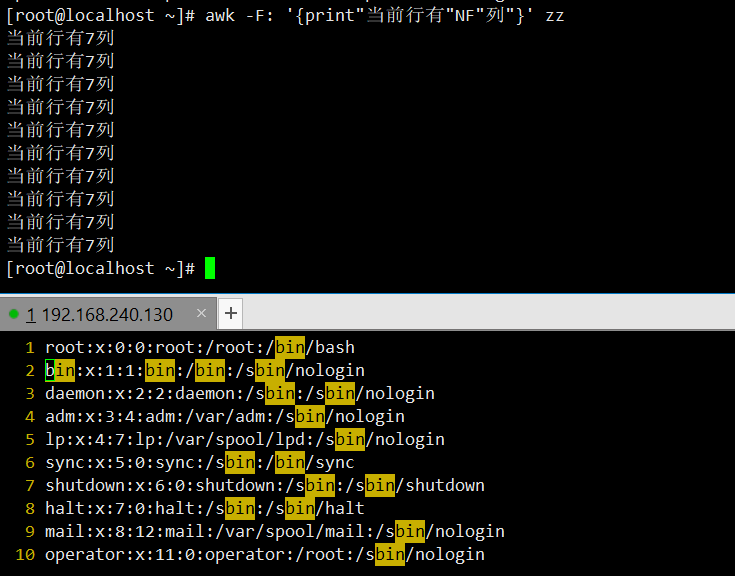
显示行号与对应列数(带描述):以冒号为分隔符,输出
/etc/passwd每行的行号和列数,搭配文字描述。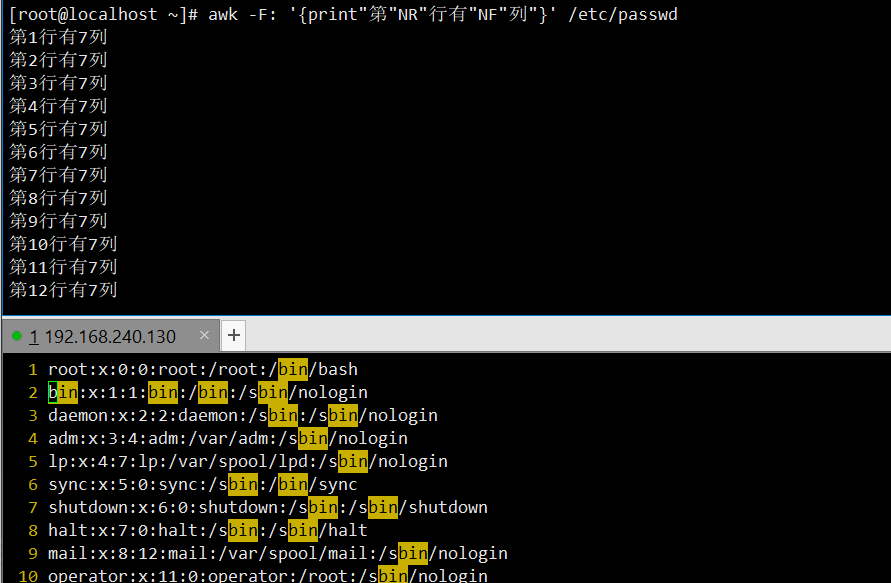
扩展生产案例
提取网卡 IP 地址:通过
ifconfig ens33获取网卡信息,匹配含 “netmask” 的行,输出第二列(IP 地址)并添加描述。[root@localhost ~]# ifconfig ens33 | awk '/netmask/{print "本机的ip地址是"$2}' 本机的ip地址是192.168.245.211提取网卡接收流量:匹配
ifconfig ens33输出中含 “RX p” 的行,输出第五列(流量数值)并添加 “字节” 单位。[root@localhost ~]# ifconfig ens33 | awk '/RX p/{print $5"字节"}' 8341053字节提取根分区可用量:通过
df -h查看磁盘信息,匹配第二行(根分区对应行),输出第四列(可用空间)。[root@localhost ~]# df -h | awk 'NR==2{print $4}' 45G
4.3 BEGIN END 运算
4.3.1 核心概念
- BEGIN 模块:在读取文本数据前执行,且仅执行一次,常用于初始化变量(比如赋值、定义分隔符)、设置输出格式头部等操作,后续即使不跟文件名也能独立运行。
- END 模块:在读取完所有文本数据后执行,同样仅执行一次,主要用于汇总结果,例如统计总行数、计算最终数值、打印汇总信息等。
- 运算特性:AWK 支持整数与小数运算,涵盖加(+)、减(-)、乘(*)、除(/)、取余(%)、乘方(^ 或 **)等运算;未初始化的变量,在数值运算中默认值为 0,在字符串运算中默认值为空。
4.3.2 关键功能与实战案例
1. 基础运算(BEGIN 模块实现)
通过BEGIN初始化变量并执行运算,无需依赖外部文本,可直接输出结果。
awk 'BEGIN{x=10;print x}':初始化变量 x 并赋值为 10,然后打印 x,输出结果为 10。awk 'BEGIN{x=10;print x+1}':对初始化的变量 x 进行加 1 运算后打印,输出结果为 11。awk 'BEGIN{x=10;x++;print x}':将变量 x 自增 1 后打印,输出结果为 11。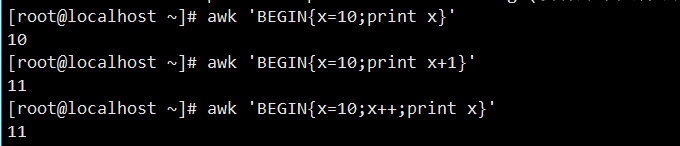
awk 'BEGIN{print 2.5+3.5}':直接进行小数加法运算,输出结果为 6。awk 'BEGIN{print 3**2}':进行乘方运算(计算 3 的 2 次方),输出结果为 9。awk 'BEGIN{print 1/2}':执行除法运算,输出结果为 0.5。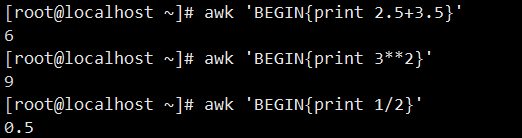
2. 模糊匹配(结合文本处理)
使用~(表示包含)和!~(表示不包含)实现模糊匹配,筛选符合条件的行,该操作常与字段分隔符(-F)搭配使用。
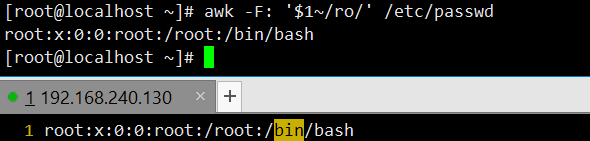
awk -F: '/root/' /etc/passwd:以冒号为分隔符,筛选包含 “root” 的行,未指定打印字段时,默认打印整行。
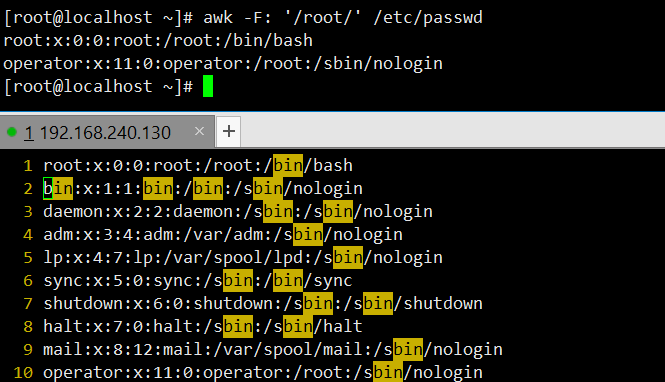
awk -F: '$1~/ro/' /etc/passwd:以冒号为分隔符,筛选第一列包含 “ro” 的行,能匹配到 “root”“chrony” 等相关行。
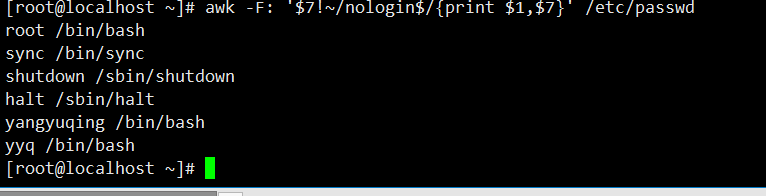
awk -F: '$7!~/nologin$/{print $1,$7}' /etc/passwd:以冒号为分隔符,筛选第七列不以 “nologin” 结尾的行,输出非系统用户的账号与对应的 shell 路径。
3. 数值与字符串比较
通过比较符号(==、!=、<、>、<=、>=)筛选符合条件的行,需要注意的是,进行字符串比较时需给字符串加双引号。
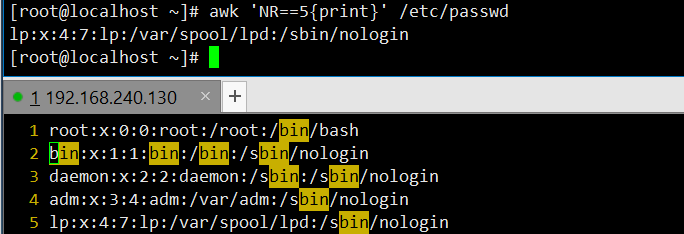
awk 'NR==5{print}' /etc/passwd:打印文件的第 5 行,输出内容为 “lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin”。
awk -F: '$3==0' /etc/passwd:以冒号为分隔符,筛选第三列(即 UID)为 0 的行,输出结果为 “root:x:0:0:root:/root:/bin/bash”。
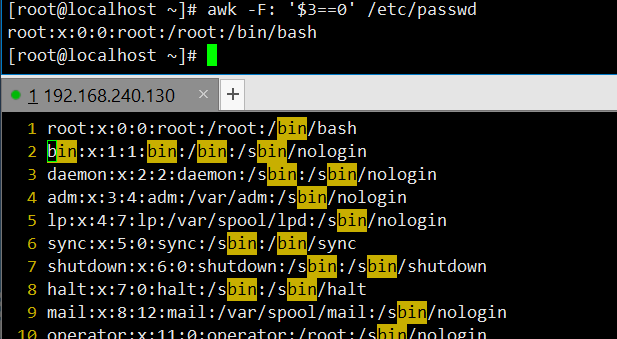
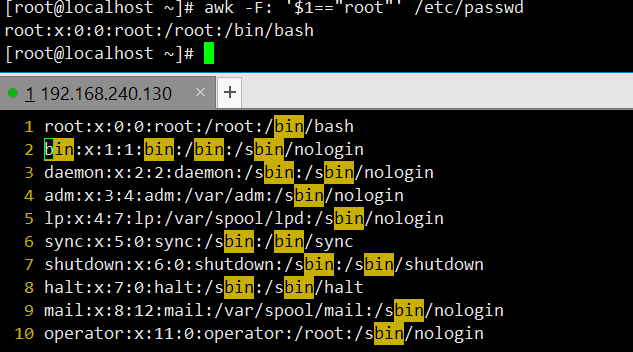
awk -F: '$1=="root"' /etc/passwd:以冒号为分隔符,精确匹配第一列为 “root” 的行,该方式可避免因变量误解导致匹配失败,输出结果同上。
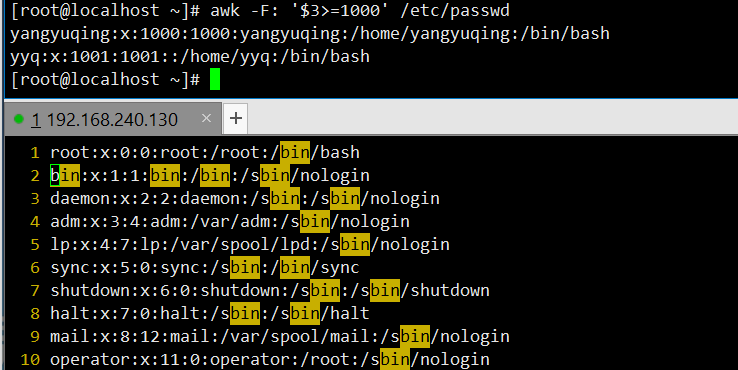
awk -F: '$3>=1000' /etc/passwd:以冒号为分隔符,筛选 UID≥1000 的行,输出普通用户(如 shengjie)的相关信息。
4. 逻辑运算(多条件组合)
使用&&(表示 “与”,需所有条件都为真)、||(表示 “或”,任一条件为真即可)组合多个条件,实现更精准的筛选。
awk -F: '$3<10 || $3>=1000' /etc/passwd:以冒号为分隔符,筛选 UID<10(系统账号)或 UID≥1000(普通用户)的行,排除了 UID 在 10-999 之间的系统账号。
awk -F: '$3>10 && $3<1000' /etc/passwd:以冒号为分隔符,筛选 UID 在 10-999 之间的行,输出中间段系统账号(如 chrony)的信息。
awk -F: '($1~"root") && (NF==7)' /etc/passwd:以冒号为分隔符,筛选第一列含 “root” 且字段数为 7 的行,确保行格式正确,输出 root 相关行。
其他内置变量的用法FS(输入)、OFS、NR、FNR、RS、ORS
- FS:输入字段的分隔符 默认是空格
- OFS:输出字段的分隔符 默认也是空格
- FNR:读取文件的记录数(行号),从1开始,新的文件重新重1开始计数
- RS:输入行分隔符 默认为换行符
- ORS:输出行分隔符 默认也是为换行符
[root@localhost ~]# awk 'BEGIN{FS=":"}{print $1}' pass.txt //在打印之前定义字段
分隔符为冒号
root
bin
daemon
adm
lp
[root@localhost ~]# awk '{print FNR,$0}' /etc/resolv.conf /etc/hosts
FNR的行号在追加当有多个文件时//可以看出
1
2 nameserver 114.114.114.114
3 search localdomain
1 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
2 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
[root@localhost ~]# awk '{print NR,$0}' /etc/resolv.conf /etc/hosts
1
2 nameserver 114.114.114.114
3 search localdomain
4 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
5 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6同时读取 /etc/resolv.conf 和 /etc/hosts 两个文件,为文件内容的每一行添加行号(从 1 开始连续计数),并输出“行号 + 该行内容”的格式。
[root@localhost ~]# awk 'BEGIN{RS=":"}{print $0}' /etc/passwd
#RS:指定以什么为换行符,这里指定是冒号,你指定的肯定是原文里存在的字符
root
x
0
0
root
[root@localhost ~]# awk 'BEGIN{ORS=" "}{print $0}' /etc/passwd //把多行合并成一行
输出,输出的时候自定义以空格分隔每行,本来默认的是回车键5. 总结
- 定位:强大的文本处理工具,擅长拆分“字段”处理(区别于sed的整行处理),用于过滤、统计、格式化文本。Linux中常用gawk,awk是其链接。
- 核心流程:BEGIN(读文本前初始化)→ 逐行执行Body(按条件处理)→ END(读后统计输出)。
- 关键语法:awk [选项] '模式{操作}' 文件名,如awk -F: '{print $1}' /etc/passwd(按冒号拆分,打印第一列)。
- 常用变量:$0(整行)、$n(第n列)、NR(行号)、NF(列数)、FS(输入分隔符)。
- 核心场景:字段提取、内容匹配(如/root/找含root的行)、统计计算(如END{print NR}算总行数)、日志分析(如统计IP访问次数)。
- 工具对比:grep(查文本)、sed(编文本)、awk(格式化/复杂处理)。