K8S网络组件Calico深度解析
目录
K8S-网络组件 Calico
一、calico 概述
1.1、calico 介绍
1.2、calico 的优点
1.3、calico的缺点
1.4、calico 优势
二、Calico结构组成
2.1 架构
2.2 名词解释
2.3 组网原理
2.4、Calico 工作原理
三、Calico 网络模式
3.1、BGP 概述
3.1.1 BGP两种模式
3.1.2 Calico BGP 概述
3.1.3 BGP 是怎么工作的?
3.1.4 为什么叫边界网关协议呢?
3.1.5 Pod 1 访问 Pod 2 流程如下
3.1.6 Route Reflector 模式(RR)(路由反射)
3.2、IPIP 模式概述(默认模式)
3.2.1 Pod1 访问 Pod2 流程如下:
3.3 Calico 优势 与 劣势
3.4 两种网络的对比
pod抓包
Calico管理工具
K8S-网络组件 Flannel
一、简介
二、flannel对网络要求提出的解决方法
互相不冲突的IP
pod之间互相访问
三、flannel架构原理
不同node上的Pod的通信流程
K8S-CoreDNS组件
一、概述
Kubernetes 中的域名是如何解析的?
二、pod DNS策略
三、CoreDns解析规则
四、pod之间通信
五、CoreDns Corefile 文件
配置文件分析
案例:添加外部解析
K8S-网络组件 Calico
一、calico 概述
1.1、calico 介绍
Calico 是一套开源的网络和网络安全方案,用于容器、虚拟机、宿主机之前的网络连接,可以用在kubernetes、OpenShift(红帽的容器编排工具)、DockerEE、OpenStack等PaaS或IaaS平台上。
1.2、calico 的优点
-
endpoints组成的网络是单纯的三层网络,报文的流向完全通过路由规则控制,没有overlay等额外开销;
-
calico的endpoint可以漂移,并且实现了acl。
1.3、calico的缺点
-
路由的数目与容器数目相同,非常容易超过路由器、三层交换、甚至node的处理能力,从而限制了整个网络的扩张;
-
calico的每个node上会设置大量(海量)的iptables规则、路由;运维、排障难度大;
-
calico的原理决定了它不可能支持VPC,容器只能从calico设置的网段中获取ip;
-
calico目前的实现没有流量控制的功能,会出现少数容器抢占node多数带宽的情况;
-
calico的网络规模受到BGP网络规模的限制。
1.4、calico 优势
-
更优的资源利用: 二层网络通讯需要依赖广播消息机制,广播消息的开销与host的数量成指数级增长,calico使用的三层路由方法,则完全抑制了二层广播,减少了资源开销。另外二层网络使用VLAN隔离技术,天生有4096个规格的限制,即便可以使用vxlan解决,单vxlan又带来了隧道开销的新问题,而calico不使用VLAN或者vxlan,资源利用率更高;
-
可扩展性:Calico使用与Internet类似的方案,Internet的网络比任何数据中心都大,Calico同样天然具有可扩展性;
-
更简单的容器调试:没有隧道,workloads之间的路径更短更简单,配置更少,在host上使用容器进行debug调试;
-
更少依赖:Calico仅依赖三层路由可达;
-
可适配性:较少的依赖使它能适配所有的VM、Container、白盒(程序源代码)或者混合环境场景;
二、Calico结构组成
Calico不使用重叠网络比如flannel和libnetwork重叠网络驱动,它是一个纯三层的方法,使用虚拟路由代替虚拟交换,每一台虚拟路由通过BGP协议传播可达信息(路由)到其他数据中心;Calico在每一个计算节点利用Linux Kernel实现了一个高效的vRouter来负责数据转发,而每个vRouter通过BGP协议负责把自己上运行的workload的路由信息向整个Calico网络内传播——小规模部署可以直接互联,大规模下可通过指定的BGP route reflector来完成。
2.1 架构
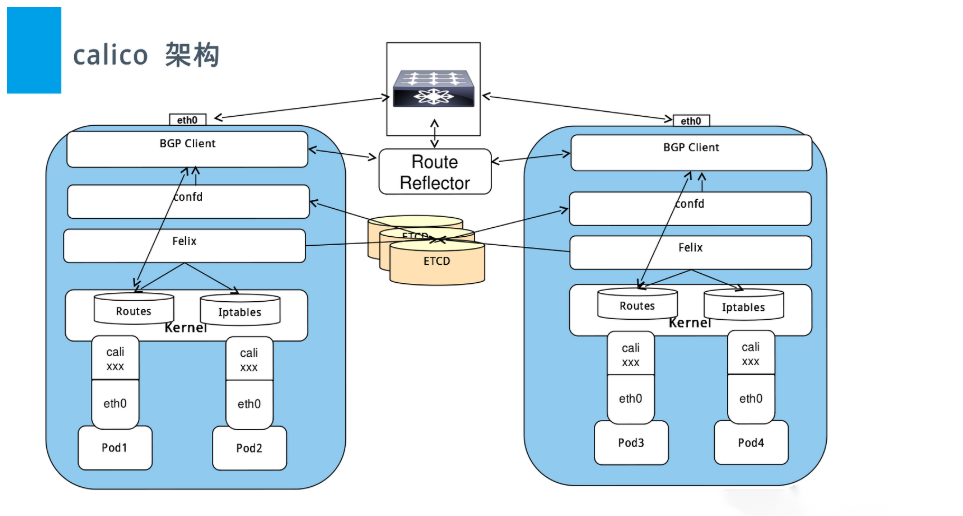
-
Felix:calico的核心组件,运行在每个节点上。主要的功能有接口管理、路由规则、ACL规则和状态报告
-
接口管理:Felix为内核编写一些接口信息,以便让内核能正确的处理主机endpoint的流量。特别是主机之间的ARP请求和处理ip转发。
-
路由规则:Felix负责主机之间路由信息写到linux内核的FIB(Forwarding Information Base)转发信息库,保证数据包可以在主机之间相互转发。
-
-
ACL规则:Felix负责将ACL策略写入到linux内核中,保证主机endpoint的为有效流量不能绕过calico的安全措施。
-
状态报告:Felix负责提供关于网络健康状况的数据。特别是,它报告配置主机时出现的错误和问题。这些数据被写入etcd,使其对网络的其他组件和操作人员可见。
-
Etcd:保证数据一致性的数据库,存储集群中节点的所有路由信息。为保证数据的可靠和容错建议至少三个以上etcd节点。
-
Orchestrator plugin:协调器插件负责允许kubernetes(容器)或OpenStack(虚拟机)等原生云平台方便管理Calico,可以通过各自的API来配置Calico网络实现无缝集成。如kubernetes的cni网络插件。
-
Bird:BGP客户端,Calico在每个节点上的都会部署一个BGP客户端,它的作用是将Felix的路由信息读入内核,并通过BGP协议在集群中分发。当Felix将路由插入到Linux内核FIB中时,BGP客户端将获取这些路由并将它们分发到部署中的其他节点。这可以确保在部署时有效地路由流量。
-
BGP Router Reflector:大型网络仅仅使用 BGP client 形成 mesh 全网互联的方案就会导致规模限制,所有节点需要 N^2 个连接,为了解决这个规模问题,可以采用 BGP 的 Router Reflector 的方法,使所有 BGP Client 仅与特定 RR 节点互联并做路由同步,从而大大减少连接数。
-
Calicoctl: calico 命令行管理工具。
2.2 名词解释
| 名词 | 作用 |
|---|---|
| endpoint | 接入到calico网络中的网卡称为endpoint |
| AS | 网络自治系统,通过BGP协议与其它AS网络交换路由信息 |
| ibgp | AS内部的BGP Speaker,与同一个AS内部的ibgp、ebgp交换路由信息。 |
| ebgp | AS边界的BGP Speaker,与同一个AS内部的ibgp、其它AS的ebgp交换路由信息。 |
| workloadEndpoint | 虚拟机、容器使用的endpoint |
| hostEndpoints | 物理机(node)的地址 |
实际上,Calico 项目提供的 BGP 网络解决方案,与 Flannel 的 host-gw 模式几乎一样。也就是说,Calico也是基于路由表实现容器数据包转发,但不同于Flannel使用flanneld进程来维护路由信息的做法,而Calico项目使用BGP协议来自动维护整个集群的路由信息。
2.3 组网原理
calico组网的核心原理就是IP路由,每个容器或者虚拟机会分配一个workload-endpoint(wl)。
从nodeA上的容器A内访问nodeB上的容器B时:
+--------------------+ +--------------------+
| +------------+ | | +------------+ |
| | | | | | | |
| | ConA | | | | ConB | |
| | | | | | | |
| +-----+------+ | | +-----+------+ |
| |veth | | |veth |
| wl-A | | wl-B |
| | | | | |
+-------node-A-------+ +-------node-B-------+ | | | || | type1. in the same lan | || +-------------------------------+ || || type2. in different network || +-------------+ || | | |+-------------+ Routers |-------------+| |+-------------+
#从ConA中发送给ConB的报文被nodeA的wl-A接收,根据nodeA上的路由规则,经过各种iptables规则后,转发到nodeB。
#如果nodeA和nodeB在同一个二层网段,下一条地址直接就是node-B,经过二层交换机即可到达。
#如果nodeA和nodeB在不同的网段,报文被路由到下一跳,经过三层交换或路由器,一步步跳转到node-B。核心问题是,nodeA怎样得知下一跳的地址?
答案是node之间通过BGP协议交换路由信息。
每个node上运行一个软路由软件bird,并且被设置成BGP Speaker,与其它node通过BGP协议交换路由信息。 可以简单理解为,每一个node都会向其它node通知这样的信息:
我是X.X.X.X,某个IP或者网段在我这里,它们的下一跳地址是我。
通过这种方式每个node知晓了每个workload-endpoint的下一跳地址。
2.4、Calico 工作原理
Calico把每个操作系统的协议栈认为是一个路由器,然后把所有的容器认为是连在这个路由器上的网络终端,在路由器之间跑标准的路由协议——BGP的协议,然后让它们自己去学习这个网络拓扑该如何转发。所以Calico方案其实是一个纯三层的方案,也就是说让每台机器的协议栈的三层去确保两个容器,跨主机容器之间的三层连通性。
对于控制平面,它每个节点上会运行两个主要的程序,一个是Felix,它会监听ECTD中心的存储,从它获取事件,比如说用户在这台机器上加了一个IP,或者是分配了一个容器等。接着会在这台机器上创建出一个容器,并将其网卡、IP、MAC都设置好,然后在内核的路由表里面写一条,注明这个IP应该到这张网卡。绿色部分是一个标准的路由程序,它会从内核里面获取哪一些IP的路由发生了变化,然后通过标准BGP的路由协议扩散到整个其他的宿主机上,让外界都知道这个IP在这里,你们路由的时候得到这里来。
由于Calico是一种纯三层的实现,因此可以避免与二层方案相关的数据包封装的操作,中间没有任何的NAT,没有任何的overlay,所以它的转发效率可能是所有方案中最高的,因为它的包直接走原生TCP/IP的协议栈,它的隔离也因为这个栈而变得好做。因为TCP/IP的协议栈提供了一整套的防火墙的规则,所以它可以通过IPTABLES的规则达到比较复杂的隔离逻辑。
三、Calico 网络模式
BGP 边界网关协议(Border Gateway Protocol, BGP):是互联网上一个核心的去中心化自治路由协议。BGP不使用传统的内部网关协议(IGP)的指标。
Route Reflector 模式(RR)(路由反射):Calico 维护的网络在默认是(Node-to-Node Mesh)全互联模式,Calico集群中的节点之间都会相互建立连接,用于路由交换。但是随着集群规模的扩大,mesh模式将形成一个巨大服务网格,连接数成倍增加。这时就需要使用 Route Reflector(路由器反射)模式解决这个问题。
IPIP模式:把 IP 层封装到 IP 层的一个 tunnel。作用其实基本上就相当于一个基于IP层的网桥!一般来说,普通的网桥是基于mac层的,根本不需 IP,而这个 ipip 则是通过两端的路由做一个 tunnel,把两个本来不通的网络通过点对点连接起来。
3.1、BGP 概述
BGP(border gateway protocol)是外部路由协议(边界网关路由协议),用来在AS之间传递路由信息是一种增强的距离矢量路由协议(应用场景),基本功能是在自治系统间自动交换无环路的路由信息,通过交换带有自治系统号序列属性的路径可达信息,来构造自治系统的拓扑图,从而消除路由环路并实施用户配置的路由策略。
(边界网关协议(BGP),提供自治系统之间无环路的路由信息交换(无环路保证主要通过其AS-PATH实现),BGP是基于策略的路由协议,其策略通过丰富的路径属性(attributes)进行控制。BGP工作在应用层,在传输层采用可靠的TCP作为传输协议(BGP传输路由的邻居关系建立在可靠的TCP会话的基础之上)。在路径传输方式上,BGP类似于距离矢量路由协议。而BGP路由的好坏不是基于距离(多数路由协议选路都是基于带宽的),它的选路基于丰富的路径属性,而这些属性在路由传输时携带,所以我们可以把BGP称为路径矢量路由协议。如果把自治系统浓缩成一个路由器来看待,BGP作为路径矢量路由协议这一特征便不难理解了。除此以外,BGP又具备很多链路状态(LS)路由协议的特征,比如触发式的增量更新机制,宣告路由时携带掩码等。)
实际上,Calico 项目提供的 BGP 网络解决方案,与 Flannel 的 host-gw 模式几乎一样。也就是说,Calico也是基于路由表实现容器数据包转发,但不同于Flannel使用flanneld进程来维护路由信息的做法,而Calico项目使用BGP协议来自动维护整个集群的路由信息。
3.1.1 BGP两种模式
全互联模式(node-to-node mesh)
全互联模式 每一个BGP Speaker都需要和其他BGP Speaker建立BGP连接,这样BGP连接总数就是2^N - 2,如果数量过大会消耗大量连接。如果集群数量超过100台官方不建议使用此种模式。
路由反射模式Router Reflection(RR)
RR模式 中会指定一个或多个BGP Speaker为RouterReflection,它与网络中其他Speaker建立连接,每个Speaker只要与Router Reflection建立BGP就可以获得全网的路由信息。在calico中可以通过Global Peer实现RR模式。
3.1.2 Calico BGP 概述
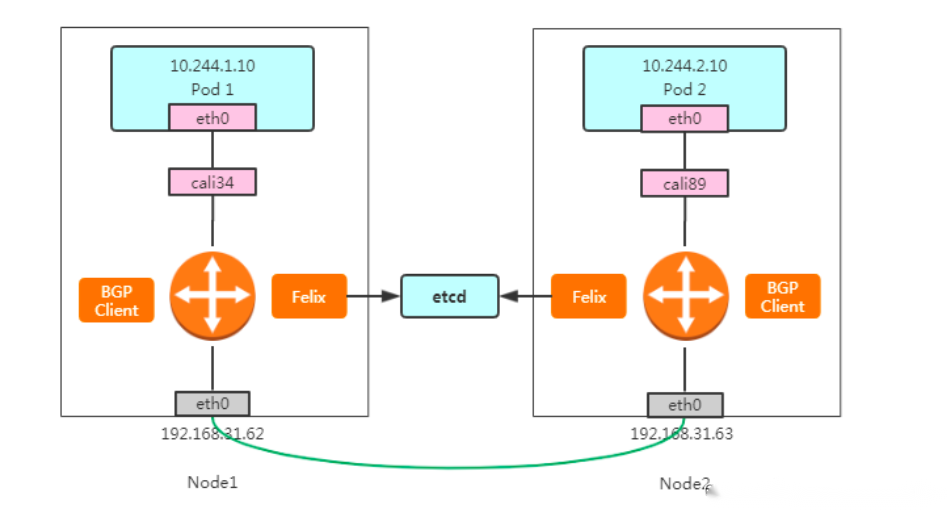
3.1.3 BGP 是怎么工作的?
这个也是跨节点之间的通信,与flannel类似,其实这张图相比于flannel,通过一个路由器来路由,flannel.1 就相比于vxlan模式去掉,所以会发现这里是没有网桥存在,完全就是通过路由来实现,这个数据包也是先从veth设备对另一口发出,到达宿主机上的cali开头的虚拟网卡上,到达这一头也就到达了宿主机上的网络协议栈,另外就是当创建一个pod时帮你先起一个infra containers的容器,调用calico的二进制帮你去配置容器的网络,然后会根据路由表决定这个数据包到底发送到哪里去,可以从ip route看到路由表信息,这里显示是目的cni分配的子网络和目的宿主机的网络,当进行跨主机通信的时候之间转发到下一跳地址走宿主机的eth0网卡出去,也就是一个直接的静态路由,这个下一跳就跟host-gw的形式一样,和host-gw最大的区别是calico使用BGP路由交换,而host-gw是使用自己的路由交换,BGP这个方案比较成熟,在大型网络中用的也比较多,所以要比flannel的方式好,而这些路由信息都是由BGP client传输。
3.1.4 为什么叫边界网关协议呢?
和 flannel host-gw 工作模式基本上一样,BGP是一个边界路由器,主要是在每个自治系统的最边界与其他自治系统的传输规则,而这些节点之间组成的BGP网络是一个全网通的网络,这个网络就称为一个 BGP Peer。
启动文件放在 /opt/cni/bin 目录下,/etc/cni/net.d 目录下记录子网的相关配置信息。
$ cat /etc/cni/net.d/10-calico.conflist{"name": "k8s-pod-network","cniVersion": "0.3.0","plugins": [{"type": "calico","log_level": "info","etcd_endpoints": "https://10.10.0.174:2379","etcd_key_file": "/etc/cni/net.d/calico-tls/etcd-key","etcd_cert_file": "/etc/cni/net.d/calico-tls/etcd-cert","etcd_ca_cert_file": "/etc/cni/net.d/calico-tls/etcd-ca","mtu": 1440,"ipam": {"type": "calico-ipam"},"policy": {"type": "k8s"},"kubernetes": {"kubeconfig": "/etc/cni/net.d/calico-kubeconfig"}},{"type": "portmap","snat": true,"capabilities": {"portMappings": true}}]
}3.1.5 Pod 1 访问 Pod 2 流程如下
1、数据包从 Pod1 出到达Veth Pair另一端(宿主机上,以cali前缀开头)
2、宿主机根据路由规则,将数据包转发给下一跳(网关)
3、到达 Node2,根据路由规则将数据包转发给 cali 设备,从而到达 Pod2。
其中,这里最核心的 下一跳 路由规则,就是由 Calico 的 Felix 进程负责维护的。这些路由规则信息,则是通过 BGP Client 中 BIRD 组件,使用 BGP 协议来传输。
不难发现,Calico 项目实际上将集群里的所有节点,都当作是边界路由器来处理,它们一起组成了一个全连通的网络,互相之间通过 BGP 协议交换路由规则。这些节点,我们称为 BGP Peer。
而 Flannel host-gw 和 Calico 的唯一不一样的地方就是当数据包下一跳到达node2节点容器时发生变化,并且出数据包也发生变化,知道它是从veth的设备流出,容器里面的数据包到达宿主机上,这个数据包到达node2之后,它又根据一个特殊的路由规则,这个会记录目的通信地址的cni网络,然后通过cali设备进去容器,这个就跟网线一样,数据包通过这个网线发到容器中,这也是一个二层的网络互通才能实现。
3.1.6 Route Reflector 模式(RR)(路由反射)
设置方法请参考官方链接 https://docs.projectcalico.org/master/networking/bgp
Calico 维护的网络在默认是 (Node-to-Node Mesh)全互联模式,Calico集群中的节点之间都会相互建立连接,用于路由交换。但是随着集群规模的扩大,mesh模式将形成一个巨大服务网格,连接数成倍增加。这时就需要使用 Route Reflector(路由器反射)模式解决这个问题。确定一个或多个Calico节点充当路由反射器,让其他节点从这个RR节点获取路由信息。
在BGP中可以通过calicoctl node status看到启动是 node-to-node mesh 网格的形式,这种形式是一个全互联的模式,默认的BGP在k8s的每个节点担任了一个BGP的一个喇叭,一直吆喝着扩散到其他节点,随着集群节点的数量的增加,那么上百台节点就要构建上百台链接,就是全互联的方式,都要来回建立连接来保证网络的互通性,那么增加一个节点就要成倍的增加这种链接保证网络的互通性,这样的话就会使用大量的网络消耗,所以这时就需要使用Route reflector,也就是找几个大的节点,让他们去这个大的节点建立连接,也叫RR,也就是公司的员工没有微信群的时候,找每个人沟通都很麻烦,那么建个群,里面的人都能收到,所以要找节点或着多个节点充当路由反射器,建议至少是2到3个,一个做备用,一个在维护的时候不影响其他的使用。
3.2、IPIP 模式概述(默认模式)
IPIP 是linux内核的驱动程序,可以对数据包进行隧道,上图可以看到两个不同的网络 vlan1 和 vlan2。基于现有的以太网将原始包中的原始IP进行一次封装,通过tunl0解包,这个tunl0类似于ipip模块,和Flannel vxlan的veth很类似。
3.2.1 Pod1 访问 Pod2 流程如下:
1、数据包从 Pod1 出到达Veth Pair另一端(宿主机上,以cali前缀开头)。
2、进入IP隧道设备(tunl0),由Linux内核IPIP驱动封装,把源容器ip换成源宿主机ip,目的容器ip换成目的主机ip,这样就封装成 Node1 到 Node2 的数据包。
此时包的类型:原始IP包:源IP:10.244.1.10目的IP:10.244.2.10
TCP:源IP: 192.168.31.62目的iP:192.168.32.633、数据包经过路由器三层转发到 Node2。
4、Node2 收到数据包后,网络协议栈会使用IPIP驱动进行解包,从中拿到原始IP包。
5、然后根据路由规则,将数据包转发给cali设备,从而到达 Pod2。
3.3 Calico 优势 与 劣势
优势
没有封包和解包过程,完全基于两端宿主机的路由表进行转发
可以配合使用 Network Policy 做 pod 和 pod 之前的访问控制劣势
要求宿主机处于同一个2层网络下,也就是连在一台交换机上
路由的数目与容器数目相同,非常容易超过路由器、三层交换、甚至node的处理能力,从而限制了整个网络的扩张。(可以使用大规模方式解决)
每个node上会设置大量(海量)的iptables规则、路由,运维、排障难度大。
原理决定了它不可能支持VPC,容器只能从calico设置的网段中获取ip。3.4 两种网络的对比
IPIP网络:
流量:tunl0 设备封装数据,形成隧道,承载流量。
适用网络类型:适用于互相访问的pod不在同一个网段中,跨网段访问的场景。外层封装的ip能够解决跨网段的路由问题。
效率:流量需要tunl0设备封装,效率略低BGP网络:
流量:使用路由信息导向流量
适用网络类型:适用于互相访问的pod在同一个网段,适用于大型网络。
效率:原生hostGW,效率高总结:
| 项目 | IPIP | BGP |
|---|---|---|
| 流量 | tunl0封装数据,形成隧道,承载流量 | 路由信息导向流量 |
| 适用场景 | Pod跨网段互访 | Pod同网段互访,适合大型网络 |
| 效率 | 需要tunl0设备封装,效率略低 | 原生hostGW, 效率高 |
| 类型 | overlay | underlay |
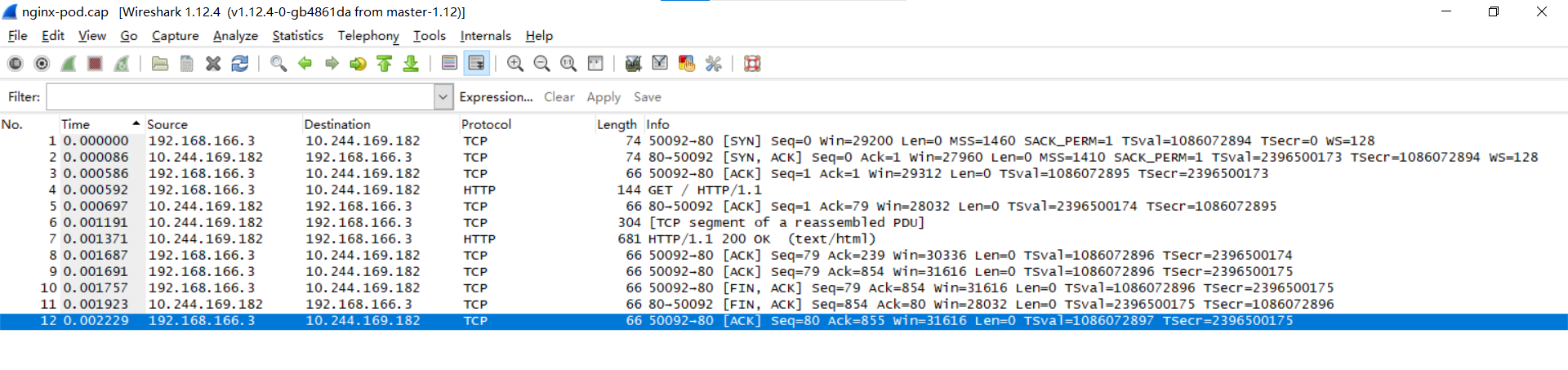
pod抓包
查看pod网络接口编号
[root@k8s-master ~]#kubectl exec pods/nginx-pod -- bash -c 'cat /sys/class/net/eth0/iflink'
18查看对应pod的运行node
[root@k8s-master ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-pod 1/1 Running 2 (59m ago) 2d22h 10.244.169.182 k8s-node2 <none> <none>登录到运行node
[root@k8s-node2 ~]# ip a | grep 18:
18: cali8b56182ddcf@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default qlen 1000
##抓取数据包并重定向到文件nginx-pod.cap中
[root@k8s-node2 ~]# tcpdump -i cali8b56182ddcf -w nginx-pod.cap使用wireshark进行数据分析
Calico管理工具
curl -L https://github.com/projectcalico/calico/releases/download/v3.24.6/calicoctl-linux-amd64 -o /usr/sbin/kubectl-calico
chmod +x /usr/sbin/kubectl-calico
# 验证插件是否有效
kubectl-calico node statusK8S-网络组件 Flannel
一、简介
-
flannel是coreos团队针对k8s设计的一个网络规划服务,简单来说,他的功能是让集群中的不同节点主机创建的docker容器具有全集群唯一的虚拟IP地址。
-
在默认的docker配置中,每个节点上的docker服务会分别负责所在节点容器的IP分配。这样导致的一个问题是,不同节点上容器可能获得相同的内外IP地址。并使这些容器之间能够通过IP地址相互找到,也就是互相ping通。
-
flannel的设计目的就是为集群中的所有节点重新规划IP地址的使用规则,从而使得不同节点上的容器能够获得“同属一个内网”且“不重复”的IP地址,并让属于不同节点上的容器能够直接通过内网IP通信。
-
flannel实际上是一种“覆盖网络(overlaynetwork)”,也就是将TCP数据包装在另一种网络包里面进行路由转发和通信,目前已经支持udp、vxlan、host-gw、aws-vpc、gce和alloc路由等数据转发方式,默认的节点间数据通信是UDP转发。
flannel的特点:
(1)是集群中的不同node主机创建的docker容器都具有全集群唯一的虚拟IP地址
(2)建立一个覆盖网络(overlay network),通过这个覆盖网络,将数据包原封不动的传递到目标容器。覆盖容器是建立在另一个网络之上并由其基础设施支持的虚拟网络。覆盖网络通过将一个分组封装在另一个分组内来将网络服务与底层基础实施分离。在将封装的数据包转发到端点后,将其解封。
(3)创建一个新的虚拟网卡flannel0接受docker网桥的数据,通过维护路由表,通过维护路由表,对接受到的数据进行封包和转发(vxlan)
(4)etcd保证了所有node上flannel所看到的配置是一致的。同时每个node上的flanned监控etcd上的数据变化,实时感知集群中node的变化。
二、flannel对网络要求提出的解决方法
互相不冲突的IP
(1)flannel利用k8s api通过etcd存储整个集群的网络配置,根据配置记录集群使用的网段。
(2)flannel在每个主机上建立flanneld作为agent,它会为所在主机从集群的网络地址空间中获取一个小网段subnet,本主机内所有容器IP将从中分配。
在flannel network中,每个pod都会分配一个唯一的IP地址,且每个k8s node的subent不重叠
pod之间互相访问
(1)flanneld将本机获取的subnet以及主机之间通信的public ip通过etcd存储起来,需要时发给相应模块
(2)flanneld通过各种 backend mechanism,如vxlan、udp等跨主机转发容器之间的网络流量,完成容器之间的跨主机通信。
三、flannel架构原理
(一)flannel架构图和各组件
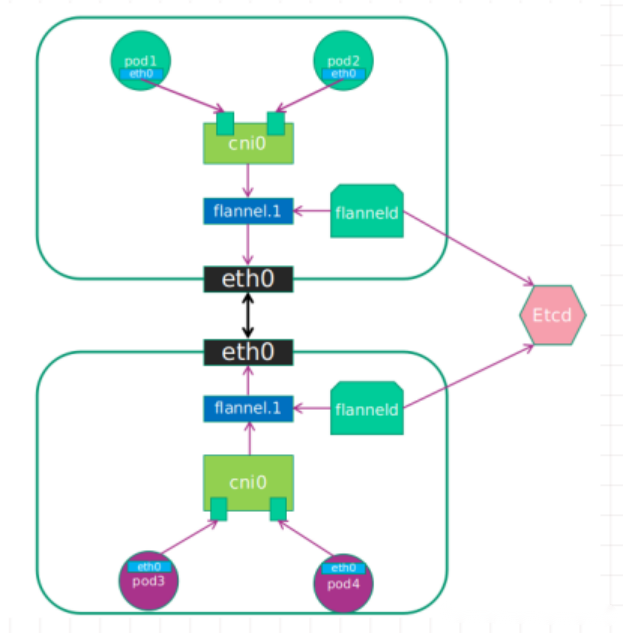
-
cni0:网桥设备,每创建一个pod都会创建一对veth pair。其中一端是pod中的eth0,另一端是cni0网桥的端口(网卡)。pod中从网卡eth0发出的流量都会发送到cni网桥设备的端口(网卡上)
-
cni0设备获得的IP地址是该节点分配到的网段的第一个地址。
-
flannel.1:overlay网络的设备,用来进行vxlan报文的处理(封包和解包)。不同node之间的pod数据流量都从overlya设备以隧道的形式发送到对端。
不同node上的Pod的通信流程
1)pod产生数据,根据pod的路由信息,将数据发送到cni0
2)cni0根据节点的路由表,将数据发送到隧道设备flannel.1
3)flannel.1查看数据包的目的IP,从flanneld获得对端隧道设备的必要信息,封装数据包。
4)flannel.1将数据包发送到对端设备。对端节点的网卡接收到数据包,发现数据包为overlay数据包,解开外层封装,并发送内层封装到flannel.1设备。
5)flannel.1设备查看数据包,根据路由表匹配,将数据发送给cni0设备。
6)cni0匹配路由表,发送数据给网桥上对应的端口。
K8S-CoreDNS组件
一、概述
在 Kubernetes 中,服务发现有几种方式:
-
基于环境变量的方式
-
基于内部域名的方式
基本上,使用环境变量的方式很少,主要还是使用内部域名这种服务发现的方式。
其中,基于内部域名的方式,涉及到 Kubernetes 内部域名的解析,而 kubedns,是 Kubernetes 官方的 DNS 解析组件。从 1.11 版本开始,kubeadm 已经使用第三方的 CoreDNS 替换官方的 kubedns 作为 Kubernetes 集群的内部域名解析组件。
Kubernetes 中的域名是如何解析的?
在 Kubernetes 中,比如服务 a 访问服务 b,对于同一个 Namespace下,可以直接在 pod 中,通过 curl b 来访问。对于跨 Namespace 的情况,服务名后边对应 Namespace即可。比如 curl b.default。那么,使用者这里边会有几个问题:
-
服务名是什么?
-
为什么同一个 Namespace 下,直接访问服务名即可?不同 Namespace 下,需要带上 Namespace 才行?
-
为什么内部的域名可以做解析,原理是什么?
DNS 如何解析,依赖容器内 resolv 文件的配置
cat /etc/resolv.conf
nameserver 10.10.0.3
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5这个文件中,配置的 DNS Server,一般就是 K8S 中,kubedns 的 Service 的 ClusterIP,这个IP是虚拟IP,无法ping,但可以访问。
service 是否可以ping取决于 svc使用iptables 以及ipvs的区别。
如果pod使用dns策略为clusterfirst的时候 ,要经过 kubedns 的虚拟IP 10.10.0.3 进行解析,不论是 Kubernetes 内部域名还是外部的域名。
二、pod DNS策略
Kubernetes 中 Pod 的 DNS 策略有四种类型。
-
Default:Pod 继承所在主机上的 DNS 配置;
-
ClusterFirst:K8s 的默认设置;先在 K8s 集群配置的 coreDNS 中查询,查不到的再去继承自主机的上游 nameserver 中查询;
dnsPolicy: ClusterFirst
-
ClusterFirstWithHostNet:对于网络配置为 hostNetwork 的 Pod 而言,其 DNS 配置规则与 ClusterFirst 一致;
-
None:忽略 K8s 环境的 DNS 配置,只认 Pod 的 dnsConfig 设置。
dnsPolicy: "None"dnsConfig:nameservers:- 114.114.114.114searches:- default.svc.cluster.localoptions:- name: ndotsvalue: "5" ###默认为5三、CoreDns解析规则
在部署 pod 的时候, kubelet 在起容器的时候,会将其 DNS 解析配置初始化成集群内的配置。因此在每个pod里面都会有/etc/resolv.conf文件,通过修改其中的配置可以更改DNS的查询规则
如下启动一个pod,查看/etc/resolv.conf配置
[root@mypod /]# cat etc/resolv.conf
search default.svc.test.com svc.test.com test.com
nameserver 169.254.25.10 ####我的环境中使用了nodelocaldns,这个地址是nodelocaldns的地址
options ndots:5
[root@mypod /]#
#在集群中 pod 之间互相用 svc name 访问的时候,会根据 resolv.conf 文件的 DNS 配置来解析域名-
nameserver:集群中的DNS服务器IP,一般来说就是CoreDNS的ClusterIP -
search:需要搜索的域,默认情况下会从该pod所属的namespace开始逐级补充
#解析域名的时候,将要访问的域名依次带入 search 域,进行 DNS 查询。
#例如在pod 中访问一个域名为 nginx 的服务,其进行的 DNS 域名查询的顺序是:
nginx.default.svc.test.com. -> nginx.svc.test.com. -> nginx.test.com.
#按照上述顺序直到查到为止-
options ndots:触发上面的search的域名点数’.',在K8S中默认为5,上限15;例如test.com这个域名的ndots是1,test.com.这个域名的ndots才是2(需要注意所有域名其实都有一个根域.,因此test.com的全称应该是test.com.)。如果dnots 指定查询的域名包含的点 “.” 小于 5,则先走 search 域,再用绝对域名;如果查询的域名包含点数大于或等于 5,则先用绝对域名,再走 search 域。
#例如当ndots大于等于5时访问的是 a.b.c.e.f.g ,那么域名查找的顺序如下:
a.b.c.e.f.g. -> a.b.c.e.f.g.default.svc.test.com. -> a.b.c.e.f.g.svc.test.com. -> a.b.c.e.f.g.test.com.
#例如当ndots小于5时访问的是 a.b.c.e. ,那么域名查找的顺序如下:
a.b.c.e.default.svc.test.com. -> a.b.c.e.svc.test.com. -> a.b.c.e.test.com. -> a.b.c.e.四、pod之间通信
-
通过svc的方式通信
在 K8s 中,Pod 之间通过 svc 访问的时候,会经过 DNS 域名解析,再拿到 ip 通信。而 K8s 的域名全称为 "<service-name>.<namespace>.svc.test.com",通常只需将 svc name 当成域名就能访问到 pod。
1:使用deploy启动一个nginx的pod,svc名称为nginx-svc,如下:
---
apiVersion: apps/v1
kind: Deployment
metadata:name: nginxlabels:app: nginx
spec:replicas: 1selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: docker.io/library/nginx:latestimagePullPolicy: IfNotPresentports:- containerPort: 80---
apiVersion: v1
kind: Service
metadata:name: nginx-svc
spec:selector:app: nginxports:- port: 80protocol: TCPtargetPort: 80type: ClusterIP查看pod中/etc/resolv.conf配置如下:
root@nginx-5977dc5756-lcmwq:/# cat etc/resolv.conf
search default.svc.test.com svc.test.com test.com
nameserver 169.254.25.10
options ndots:5
root@nginx-5977dc5756-lcmwq:/#
2:使用另外一个pod访问nginx-svc这个域名,如下:
[root@master yaml]# kubectl exec -it mypod bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
[root@mypod /]# ping nginx-svc
PING nginx-svc.default.svc.test.com (10.10.23.221) 56(84) bytes of data.
64 bytes from nginx-svc.default.svc.test.com (10.10.23.221): icmp_seq=1 ttl=64 time=0.152 ms
64 bytes from nginx-svc.default.svc.test.com (10.10.23.221): icmp_seq=2 ttl=64 time=0.143 ms
64 bytes from nginx-svc.default.svc.test.com (10.10.23.221): icmp_seq=3 ttl=64 time=0.114 ms
^C
--- nginx-svc.default.svc.test.com ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2002ms
rtt min/avg/max/mdev = 0.114/0.136/0.152/0.018 ms
[root@mypod /]#
#############################
返回的nginx-svc的地址为10.10.23.221,此地址为nginx-svc的地址,如下:
[root@master yaml]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-svc ClusterIP 10.10.23.221 <none> 80/TCP 2d17h
[root@master yaml]#
#############################
如果要访问其他ns的svc,需要带上ns name即可,如下:
[root@master yaml]# kubectl exec -it mypod bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
[root@mypod /]# ping harbor-core
ping: harbor-core: Name or service not known ###不添加ns的话,无法解析habor-core
[root@mypod /]# ping harbor-core.harbor
PING harbor-core.harbor.svc.test.com (10.10.30.184) 56(84) bytes of data.
64 bytes from harbor-core.harbor.svc.test.com (10.10.30.184): icmp_seq=1 ttl=64 time=0.095 ms
64 bytes from harbor-core.harbor.svc.test.com (10.10.30.184): icmp_seq=2 ttl=64 time=0.130 ms
64 bytes from harbor-core.harbor.svc.test.com (10.10.30.184): icmp_seq=3 ttl=64 time=0.165 ms
^C
--- harbor-core.harbor.svc.test.com ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2001ms
rtt min/avg/max/mdev = 0.095/0.130/0.165/0.028 ms
[root@mypod /]# -
通过hostname和subdomain通信
在 K8s 中,如果不指定 pod 的 hostname,其默认为 pod.metadata.name,通过 spec.hostname 字段可以自定义;另外还可以给 pod 设置 subdomain,通过 spec.subdomain 字段。如下:
#启动pod,如下:
---
apiVersion: v1
kind: Pod
metadata:name: nginxlabels:app: web
spec:hostname: nginx ####设置hostnam为nginxsubdomain: subdomain-test ####containers:- name: nginximage: docker.io/library/nginx:latestimagePullPolicy: IfNotPresentdnsPolicy: "None"dnsConfig:nameservers:- 114.114.114.114searches:- default.svc.test.comoptions:- name: ndotsvalue: "5" ###默认为5---
apiVersion: v1
kind: Service
metadata:name: subdomain-test
spec:selector:app: webports:- port: 80targetPort: 80protocol: TCP#启动pod,查看/etc/hosts文件
[root@master yaml]# kubectl get po -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 6s 10.10.92.25 node3 <none> <none>
[root@master yaml]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
subdomain-test ClusterIP 10.10.7.174 <none> 80/TCP 15s
[root@k8s-master ~]# dig @10.96.0.10 nginx.subdomain-test.default.svc.cluster.local
; <<>> DiG 9.11.36-RedHat-9.11.36-14.el8_10 <<>> @10.96.0.10 nginx.subdomain-test.default.svc.cluster.local
; (1 server found)
;; global options: +cmd
;; Got answer:
;; WARNING: .local is reserved for Multicast DNS
;; You are currently testing what happens when an mDNS query is leaked to DNS
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 50420
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
; COOKIE: 793a61ce1b4aae71 (echoed)
;; QUESTION SECTION:
;nginx.subdomain-test.default.svc.cluster.local. IN A
;; ANSWER SECTION:
nginx.subdomain-test.default.svc.cluster.local. 30 IN A 10.244.169.187
;; Query time: 1 msec
;; SERVER: 10.96.0.10#53(10.96.0.10)
;; WHEN: 五 11月 29 03:51:09 EST 2024
;; MSG SIZE rcvd: 149
#通过其他pod 访问nginx.subdomain,如下:
[root@master yaml]# kubectl exec -it mypod bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
[root@mypod /]#
[root@mypod /]#
[root@mypod /]# ping nginx.subdomain-test
PING nginx.subdomain-test.default.svc.test.com (10.10.92.25) 56(84) bytes of data.
64 bytes from nginx.subdomain-test.default.svc.test.com (10.10.92.25): icmp_seq=1 ttl=62 time=1.91 ms
64 bytes from nginx.subdomain-test.default.svc.test.com (10.10.92.25): icmp_seq=2 ttl=62 time=0.902 ms
64 bytes from nginx.subdomain-test.default.svc.test.com (10.10.92.25): icmp_seq=3 ttl=62 time=1.01 ms
^C
--- nginx.subdomain-test.default.svc.test.com ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2002ms
rtt min/avg/max/mdev = 0.902/1.278/1.914/0.452 ms
#如上返回的地址为pod本身的ip地址五、CoreDns Corefile 文件
CoreDNS 实现了应用的插件化,用户可以选择所需的插件编译到可执行文件中;CoreDNS 的配置文件是 Corefile 形式的,以下是CoreDns的configmap的配置:
[root@master yaml]# kubectl -n kube-system get cm coredns -o yaml
apiVersion: v1
data:Corefile: |.:53 {errorshealth {lameduck 5s}readykubernetes test.com in-addr.arpa ip6.arpa {pods insecurefallthrough in-addr.arpa ip6.arpattl 30}prometheus :9153forward . /etc/resolv.conf {max_concurrent 1000}cache 30loopreloadloadbalance}
kind: ConfigMap
metadata:creationTimestamp: "2023-12-08T17:18:27Z"name: corednsnamespace: kube-systemresourceVersion: "224"uid: ccf7598d-8b5c-48db-9230-7a539d6c7e98
[root@master yaml]# 配置文件分析
#第一部分errorshealth {lameduck 5s}coredns内部插件,错误日志以及健康监测等,其他插件可以参考https://coredns.io/plugins/kubernetes/
#第二部分kubernetes test.com in-addr.arpa ip6.arpa {pods insecurefallthrough in-addr.arpa ip6.arpattl 30}
#指明 test.com 后缀的域名,都是 kubernetes 内部域名,coredns 会监听 service 的变化来维护域名关系,test.com 相关域名都在这里解析。
#ttl 30:设置标准的DNS域名TTL,默认值为 5 秒。允许的最小 TTL 为 0 秒,最大值为 3600 秒。将 TTL 设置为 0 将防止记录被缓存。
#pods insecure:总是从请求中返回带有 IP 的 A 记录(不检查 k8s),即查询域名1-2-3-4.ns.pod.cluster.local.的时候,不论是否存在一个IP地址为1.2.3.4的pod,都返回这个结果给客户端。如果与通配符 SSL 证书一起被恶意使用,此选项很容易被滥用。提供此选项是为了向后兼容 kube-dns。
#fallthrough in-addr.arpa ip6.arpa:正常情况下一个客户端对CoreDNS发起了一个DNS查询,如果该记录不存在,那么就会直接返回一个NXDOMAIN的响应。
#第三部分
forward . /etc/resolv.conf {max_concurrent 1000}
#指 coredns 中没有找到记录,则去 /etc/resolv.conf 中的 nameserver 请求解析,而 coredns 容器中的 /etc/resolv.conf 是继承自宿主机的。实际是如果不是 k8s 内部域名,就会去默认的 dns 服务器请求解析,并返回给 coredns 的请求者。
#第四部分prometheus :9153cache 30loopreloadloadbalance
#prometheus:CoreDNS 的监控地址为: http://localhost:9153/metrics ,满足 Prometheus 的格式。
#cache:允许缓存
#loop:如果找到循环,则检测简单的转发循环并停止 CoreDNS 进程。
#reload:允许 Corefile 的配置自动更新。在更改 ConfigMap 后两分钟,修改生效
#loadbalance:这是一个循环 DNS 负载均衡器,可以在答案中随机化 A,AAAA 和 MX 记录的顺序。
#第五部分
#当某个域名服务不在集群内部时,为了让pod可以访问,可以在corefile中添加host选项如下:
hosts {192.168.10.10 edu.comfallthrough
}案例:添加外部解析
在 Kubernetes 1.28 版本中,如果您想要通过 CoreDNS 的 ConfigMap 添加外部指定主机名的解析,可以使用 CoreDNS 的 hosts 插件。以下是如何配置 CoreDNS 的 ConfigMap 以添加 hosts 字段的示例:
-
获取当前 CoreDNS ConfigMap: 您可以通过以下命令获取当前的 CoreDNS ConfigMap 配置:
kubectl get cm coredns -n kube-system -o yaml > coredns-configmap.yaml
-
编辑 CoreDNS ConfigMap: 使用编辑器打开
coredns-configmap.yaml文件,您将看到 CoreDNS 的配置文件Corefile。在这个文件中,您可以添加hosts插件的配置。 -
添加 hosts 插件配置: 在
Corefile中添加hosts部分,例如,如果您想要将域名git.k8s.local解析到 IP 地址10.151.30.11,可以添加如下配置:apiVersion: v1 kind: ConfigMap metadata:name: corednsnamespace: kube-system data:Corefile: |.:53 {errorshealth {lameduck 5s}readykubernetes cluster.local in-addr.arpa ip6.arpa {pods insecurefallthrough in-addr.arpa ip6.arpa}hosts {10.151.30.11 git.k8s.localfallthrough}prometheus :9153forward . /etc/resolv.conf {max_concurrent 1000}cache 30loopreloadloadbalance}在这个配置中,
hosts插件被用来指定特定的 IP 地址和主机名映射。fallthrough指令表示如果请求的域名不在hosts部分定义,则请求将被转发到下一个插件处理。 -
应用更改: 保存更改后的
coredns-configmap.yaml文件,并使用以下命令应用更改:kubectl apply -f coredns-configmap.yaml -
重启 CoreDNS Pod: 更改 ConfigMap 后,您需要重启 CoreDNS Pod 以使更改生效。可以通过以下命令删除现有的 CoreDNS Pod:
kubectl delete pod -n kube-system -l k8s-app=kube-dns这将触发 CoreDNS Pod 的重启,新的 Pod 将使用更新后的 ConfigMap 配置。
通过以上步骤,您可以在 Kubernetes 1.28 版本中通过 CoreDNS 的 ConfigMap 添加外部指定主机名的解析。这种方法允许您自定义 DNS 解析规则,以满足集群内外的域名解析需求。
-
验证
[root@k8s-master ~]# dig @10.96.0.10 git.k8s.local ; <<>> DiG 9.11.36-RedHat-9.11.36-14.el8_10 <<>> @10.96.0.10 git.k8s.local ; (1 server found) ;; global options: +cmd ;; Got answer: ;; WARNING: .local is reserved for Multicast DNS ;; You are currently testing what happens when an mDNS query is leaked to DNS ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 51965 ;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ; COOKIE: e37b3a494b869230 (echoed) ;; QUESTION SECTION: ;git.k8s.local. IN A ;; ANSWER SECTION: git.k8s.local. 30 IN A 10.151.30.11 ;; Query time: 1 msec ;; SERVER: 10.96.0.10#53(10.96.0.10) ;; WHEN: 五 11月 29 04:04:09 EST 2024 ;; MSG SIZE rcvd: 83