【大数据技术实战】流式计算 Flink~生产错误实战解析
前言:流处理时代 Flink与生产痛点
实时数据处理已成为企业构建竞争优势的核心能力。从电商平台的实时库存同步、金融系统的实时风控预警,到物联网设备的实时状态监控,流处理技术支撑着越来越多的关键业务场景。Apache Flink 作为当前流处理领域的 “事实标准”,凭借其低延迟(毫秒级)、高吞吐(百万级 / 秒)、 Exactly-Once 语义保障以及丰富的 API 生态(DataStream/Table API/SQL),成为企业级实时数据平台的首选框架。
“从实验室到生产环境” 的落地过程中,开发者和运维人员常常面临各类 “疑难杂症”:作业从保存点恢复时突然失败、部分 TaskManager CPU 持续满负荷而 others 空闲、高负载下吞吐量骤降却找不到明显瓶颈…… 这些问题看似 “神秘”,实则多源于对 Flink 核心机制(状态管理、资源调度、序列化)的理解不足,或对版本升级、配置优化的细节疏忽。
基于生产环境调试经验,结合数十个行业(金融、电商、物联网、电信)的真实案例,提炼出 Flink 生产落地中最易踩坑的 “三大核心问题”——Kafka 连接器迁移的状态管理问题、任务槽负载分配不均问题、Kryo 序列化性能陷阱。每个问题均从 “症状表现→技术原理→根因分析→解决方案→最佳实践” 五个维度展开,配套完整的代码示例、图表解析与工具配置,旨在帮助读者穿透问题表象,掌握从 “被动排查” 到 “主动预防” 的实战能力。
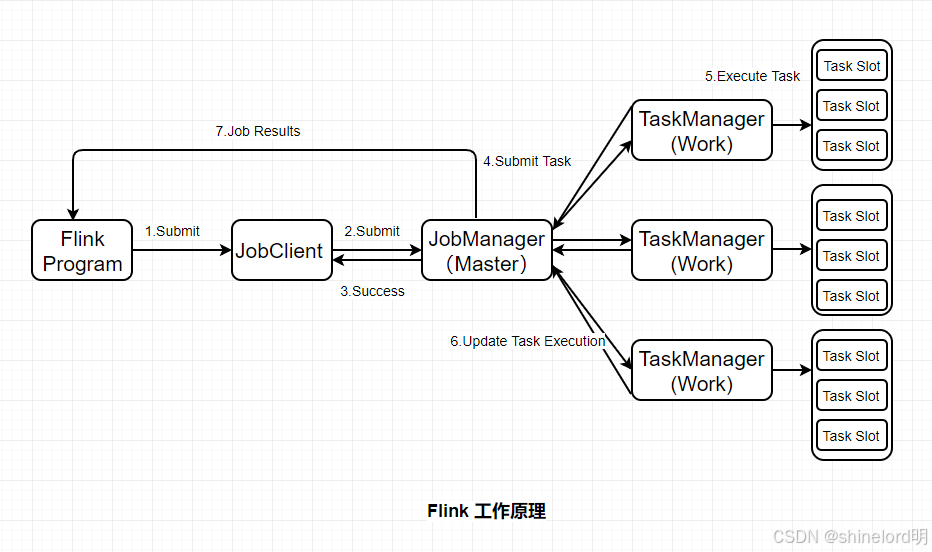
一、背景与故障排查方法论

1.1 实战经验来源:生产环境的多样性挑战
本文的经验积累源自对不同行业 Flink 部署案例的深度支持:
- 金融行业:日均处理 10 亿 + 交易流水,要求 99.99% 可用性与 Exactly-Once 语义,常见问题为状态一致性与作业恢复效率;
- 电商行业:大促期间(如双 11)峰值 QPS 达百万级,核心痛点是数据倾斜与资源弹性调度;
- 物联网行业:百万级设备实时上报数据,面临序列化性能与状态存储优化问题;
- 电信行业:跨地域集群部署,需解决连接器兼容性与跨集群状态迁移问题。
这些场景的共性是 “业务不可中断、数据不可丢失”,而问题的共性则是 “对 Flink 核心机制的理解不深入”—— 例如将 UID 视为 “无关紧要的标识”、忽略数据分布对资源调度的影响、未关注序列化方式对性能的决定性作用。
1.2 故障排查通用方法论
生产环境的 Flink 问题排查需遵循 “先现象、后日志、再原理、终验证” 的流程,避免盲目调参或重启作业(可能导致状态丢失或数据重复)。具体步骤如下:
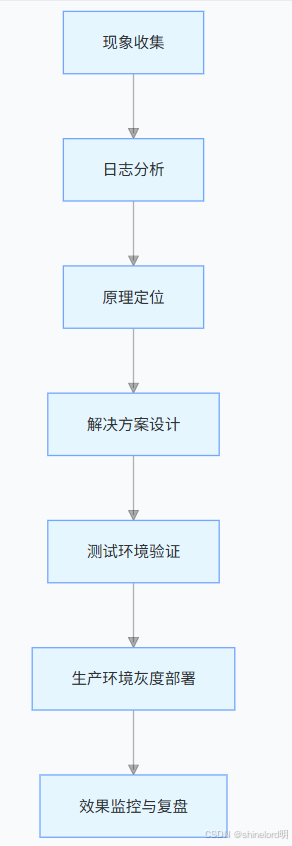
图 1:Flink 故障排查流程图
1.2.1 步骤 1:现象收集 —— 精准定位问题边界
首先明确 “问题发生的场景、范围与特征”,需收集以下信息:
- 触发条件:作业启动时 / 运行中 / 从保存点恢复时?是否与数据量、时间窗口、外部系统(如 Kafka)变更相关?
- 影响范围:单个 Task 失败 / 整个作业崩溃 / 集群级故障?是否伴随数据丢失、重复或延迟增长?
- 关键指标:通过 Flink UI 或监控工具(Prometheus+Grafana)收集核心指标:
作业层面:Checkpoint 成功率、恢复时间、总吞吐量;
Task 层面:CPU 利用率、堆内存使用、输入 / 输出记录数、背压状态;
状态层面:保存点大小、状态读写延迟、Checkpoint 对齐时间。
例如:“作业从保存点恢复时失败,日志显示 RPC 消息超限(64MB),保存点大小在近一周从 100MB 增长至 2GB”—— 这些信息可快速缩小排查范围至 “状态管理问题”。
1.2.2 步骤 2:日志分析 —— 找到问题的 “直接证据”
Flink 的日志是故障排查的核心依据,关键日志位置与分析重点如下:
- JobManager 日志(jobmanager.log):关注作业启动、Checkpoint 协调、保存点读取 / 写入、RPC 通信相关错误(如akka framesize exceeded、OutOfMemory);
- TaskManager 日志(taskmanager.log):聚焦 Task 执行错误(如序列化异常、状态访问失败)、背压根源(如BufferPool is full);
- Checkpoint 日志(checkpointing.log):分析 Checkpoint 失败原因(如状态存储超时、Task 端 Checkpoint 未完成)。
常用日志过滤命令(以 Linux 为例):
# 查找RPC消息超限错误grep "akka framesize" /path/to/flink/log/jobmanager.log# 查找POJO序列化相关日志grep "TypeExtractor" /path/to/flink/log/taskmanager.log | grep "POJO"# 查找Checkpoint失败记录grep "Checkpoint failed" /path/to/flink/log/checkpointing.log1.2.3 步骤 3:原理定位 —— 穿透问题表象
日志仅能提供 “直接错误”,需结合 Flink 核心原理(状态管理、资源调度、序列化)分析 “根本原因”:
- 若为 “保存点恢复失败”,需关联 Flink 状态与 UID 的绑定机制;
- 若为 “负载不均”,需思考数据分区策略与 Key 分布特征;
- 若为 “性能骤降”,需排查序列化方式、状态后端选择、背压传播路径。
1.2.4 步骤 4:解决方案与验证 —— 从测试到生产的闭环
解决方案需满足 “安全性、可复现性、可监控性”:
- 安全性:对涉及状态变更的操作(如 UID 修改),需先在测试环境验证,避免生产数据丢失;
- 可复现性:在测试环境模拟生产数据量与场景,确认解决方案有效;
- 可监控性:部署后新增监控指标(如保存点大小增长率、序列化类型占比),预防问题复发。
二、问题一:Kafka 连接器迁移引发的状态管理问题
2.1 问题背景:从旧版到新版的必然迁移
Apache Flink 的 Kafka 连接器经历了从 “FlinkKafkaConsumer”(旧版,Flink 1.x 时代)到 “KafkaSource”(新版,Flink 1.14 + 引入,2.x 时代默认)的重大迭代。这一迁移并非 “可选优化”,而是生态演进的必然 —— 旧版连接器已停止维护,且无法支持 Flink 新特性(如动态分区发现、增量 Checkpoint 优化)。
表 1:旧版 FlinkKafkaConsumer 与新版 KafkaSource 对比
| 对比维度 | 旧版 FlinkKafkaConsumer | 新版 KafkaSource |
| API 类型 | 继承 SourceFunction,需通过addSource添加 | 实现 Source 接口,通过fromSource添加 |
| 状态存储类型 | TopicPartitionOffsetState(偏移量存储) | SourceReaderState(读取器状态 + 偏移量) |
| 动态分区发现 | 需手动配置flink.partition-discovery.interval-millis | 内置支持,自动感知新增分区 |
| Checkpoint 机制 | 依赖 Flink 通用 Checkpoint,需手动保障一致性 | 内置 Checkpoint 优化,减少状态写入开销 |
| Exactly-Once 语义 | 需配合事务或幂等写入,配置复杂 | 原生支持,通过 Kafka 事务与 Checkpoint 联动 |
| API 易用性 | 配置分散,需手动设置 DeserializationSchema | 流式构建器(Fluent Builder),配置更直观 |
| 维护状态 | 已停止维护(Flink 1.17 后标记为 Deprecated) | 持续迭代,支持新 Kafka 版本(如 Kafka 3.x) |
新版 KafkaSource 的优势显而易见,但迁移过程中,大量团队因忽视 “状态兼容性”,导致作业从保存点恢复失败,甚至状态文件急剧膨胀。
2.2 症状表现:保存点恢复失败的两种典型错误
迁移后尝试从现有保存点恢复作业时,最常见的两种错误如下:
2.2.1 错误 1:RPC 调用超限(Akka Frame Size Exceeded)
org.apache.flink.runtime.JobException: Recovery failed from checkpoint/savepoint hdfs:///flink/savepoints/savepoint-xxxCaused by: java.io.IOException: The rpc invocation size 67158903 exceeds the maximum akka framesize (67108864 bytes).at org.apache.flink.runtime.rpc.akka.AkkaRpcUtils$.createRpcInvocationException(AkkaRpcUtils.scala:425)at org.apache.flink.runtime.rpc.akka.AkkaRpcUtils$.askRpcServer(AkkaRpcUtils.scala:326)错误中的67158903 bytes(约 64MB)是 Flink Akka RPC 的默认帧大小限制(由akka.framesize配置,默认 64MB)。当 JobManager 尝试将保存点中的状态通过 RPC 分发给 TaskManager 时,若状态数据超出此限制,将触发该错误。
2.2.2 错误 2:JobManager 内存溢出(OutOfMemoryError)
java.lang.OutOfMemoryError: Java heap spaceat org.apache.flink.runtime.checkpoint.savepoint.Savepoint.load(Savepoint.java:115)at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.restoreSavepoint(CheckpointCoordinator.java:1789)at org.apache.flink.runtime.jobmaster.JobMaster.restoreExecutionGraphFromSavepoint(JobMaster.java:1188)若 JobManager 堆内存配置较低(如默认 1GB),而保存点中的_metadata文件过大(如超过 500MB),JobManager 加载该文件时会直接触发 OOM。
关键观察:两种错误的共性
表面上,RPC 超限与内存溢出是两类问题,但根源完全一致—— 保存点的_metadata文件异常膨胀,远超正常大小(正常场景下,10 个 Kafka 分区的保存点_metadata文件通常在 10KB 以内,而异常场景下可能达到数百 MB 甚至 GB 级)。
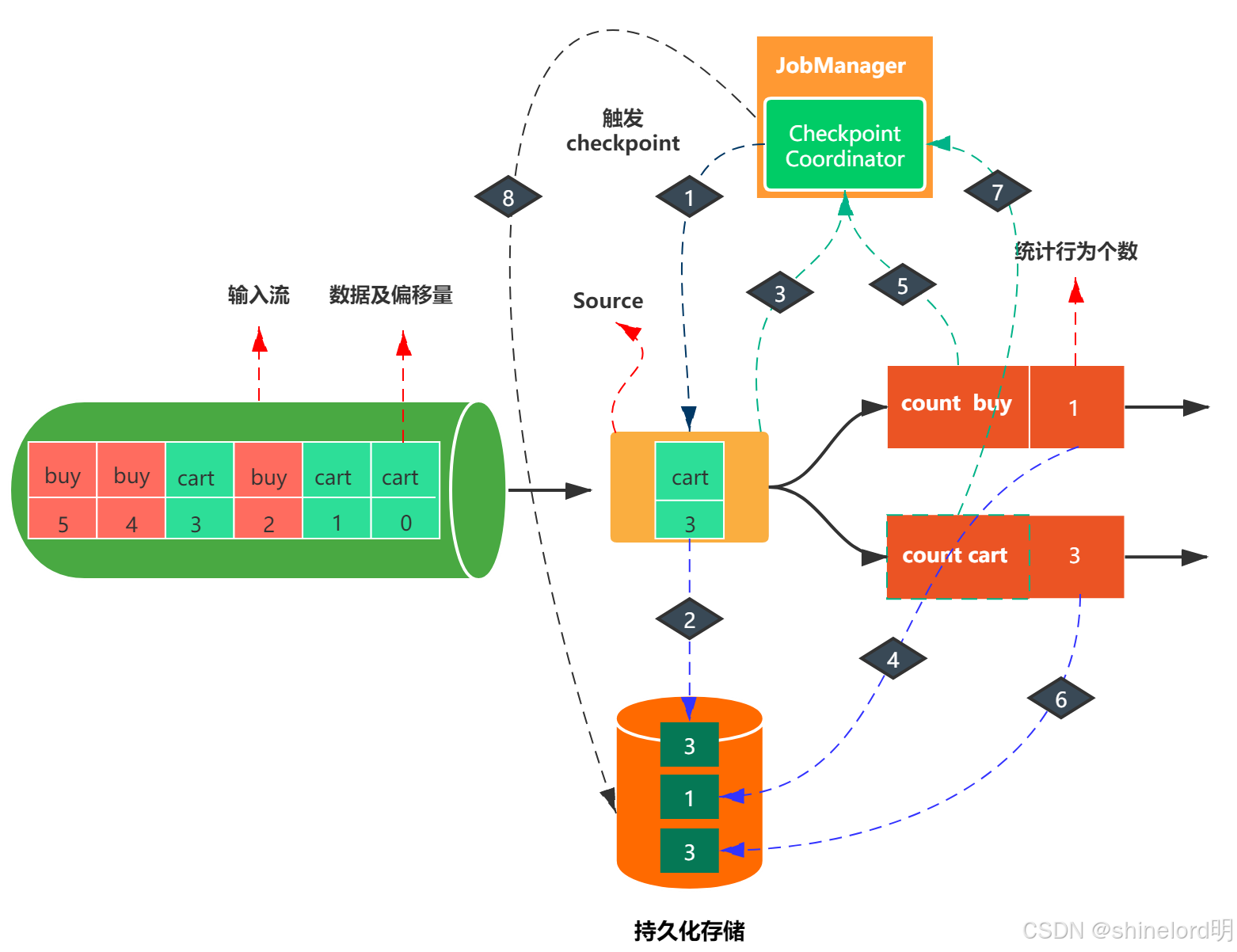
2.3 技术原理:Flink 保存点与状态管理机制
要理解问题根源,需先掌握 Flink 保存点(Savepoint)的核心结构与状态分发流程。
2.3.1 保存点的核心组成
Flink 保存点是一个 “目录结构”,存储在分布式文件系统(如 HDFS、S3)中,主要包含两部分:
- _metadata 文件:保存点的 “索引文件”,记录状态的元信息(如算子 UID、状态类型、状态存储路径),部分小状态(如 Kafka 分区偏移量)会直接内联存储在该文件中;
- 状态数据文件:大状态(如 Keyed State 中的 MapState)会存储在独立文件中,_metadata文件仅记录其路径引用。
/flink/savepoints/savepoint-xxx/├─ _metadata # 核心索引文件,内联小状态├─ 7f8a9b0c1d2e3f4g/ # 算子A的状态数据文件(大状态)│ └─ 0000000000000000000.state└─ a1b2c3d4e5f6g7h8/ # 算子B的状态数据文件(大状态)└─ 0000000000000000000.state图 2:Flink 保存点目录结构与_metadata 文件作用
2.3.2 保存点恢复的核心流程
当作业从保存点恢复时,JobManager 会执行以下步骤:
- 读取_metadata 文件:从分布式存储加载_metadata,解析其中的算子 UID 与状态映射关系;
- 匹配算子与状态:根据当前作业的算子 UID,从_metadata中找到对应的状态数据(内联状态直接读取,大状态读取引用的文件);
- RPC 分发状态:将匹配到的状态通过 Akka RPC 分发给对应的 TaskManager(每个 Task 仅接收其负责的状态分片);
- Task 恢复状态:TaskManager 接收状态后,初始化算子并加载状态,完成作业恢复。
关键结论:_metadata 文件的大小决定恢复成败
若_metadata文件过大(如内联状态过多),会导致两个问题:
- JobManager 加载时内存不足(OOM);
- 分发状态时 RPC 消息超出帧大小限制。
2.4 根因分析:UID 复用与状态累积的 “致命组合”
Kafka 连接器迁移后_metadata文件膨胀的核心原因,是算子 UID 复用与状态类型变更的冲突,具体可拆解为三层逻辑:
2.4.1 第一层:新旧连接器的状态类型不兼容
旧版FlinkKafkaConsumer与新版KafkaSource使用完全不同的状态对象存储偏移量:
- 旧版:使用TopicPartitionOffsetState,仅存储TopicPartition(主题 + 分区)与offset(偏移量)两个字段;
- 新版:使用SourceReaderState,包含readerId(读取器 ID)、splitState(分片状态)、offset(偏移量)等更复杂的结构。
两种状态对象的类结构、字段含义完全不同,属于 “不可兼容状态”。
2.4.2 第二层:UID 复用导致 Flink 错误关联状态
Flink 通过算子 UID(Unique ID)关联 “算子” 与 “状态”—— 只要 UID 不变,Flink 就认为 “算子未变”,会尝试将旧状态恢复到新算子。
生产中常见的 “误操作” 是:迁移时认为 “只是换个 API,功能没变”,因此保留原有 UID,例如:
// 旧代码(FlinkKafkaConsumer)Properties props = new Properties();props.setProperty("bootstrap.servers", "kafka:9092");FlinkKafkaConsumer<String> source = new FlinkKafkaConsumer<>("topic", new SimpleStringSchema(), props);DataStream<String> stream = env.addSource(source).uid("kafka-source") // 旧UID.name("Old Kafka Source");// 错误的新代码(KafkaSource):复用旧UIDKafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("kafka:9092").setTopics("topic").setValueOnlyDeserializer(new SimpleStringSchema()).build();DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "New Kafka Source").uid("kafka-source") // 复用旧UID,致命错误!.name("New Kafka Source");此时 Flink 的行为是:
- 发现新算子 UID(kafka-source)与保存点中旧算子的 UID 一致;
- 尝试将旧状态(TopicPartitionOffsetState)恢复到新算子(KafkaSource);
- 由于状态类型不兼容,恢复失败,但 Flink 不会丢弃旧状态,而是将其 “保留” 在_metadata文件中;
- 每次 Checkpoint 时,Flink 会同时写入 “旧状态(废弃)” 和 “新状态(正常)”,导致_metadata文件持续膨胀。
2.4.3 第三层:状态文件的指数级膨胀
以 “10 个 Kafka 分区” 为例,正常与异常场景下的状态累积对比如下:
表 2:UID 复用导致的状态累积示例
| Checkpoint 次数 | 正常场景(新 UID) | 异常场景(复用旧 UID) | _metadata 文件大小趋势 |
| 初始(迁移前) | 10 条旧状态记录 | 10 条旧状态记录 | 10KB |
| 第 1 次 Checkpoint | 10 条新状态记录 | 10 条旧状态 + 10 条新状态 | 20KB |
| 第 2 次 Checkpoint | 10 条新状态记录(覆盖) | 20 条旧状态(累积) + 10 条新状态 | 40KB |
| 第 3 次 Checkpoint | 10 条新状态记录 | 40 条旧状态(累积) + 10 条新状态 | 80KB |
| 第 n 次 Checkpoint | 10 条新状态记录 | 10×2^(n-1) 条旧状态 + 10 条新状态 | 10×2^(n-1) KB |
可见,异常场景下,旧状态会以 “指数级” 累积,最终导致_metadata文件超出 RPC 限制或 JobManager 内存上限。
2.5 解决方案:断开状态关联,启用非恢复模式
解决该问题的核心是 “明确告诉 Flink:新算子与旧状态无关,无需恢复旧状态”,需通过 “修改 UID + 启用非恢复参数” 两步实现。
2.5.1 第一步:为新 KafkaSource 设置全新 UID
将新版KafkaSource的 UID 修改为与旧版完全不同的名称(如加入版本号),让 Flink 识别为 “全新算子”,不再关联旧状态:
// 正确的新代码(KafkaSource):使用新UIDKafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("kafka:9092").setTopics("topic").setValueOnlyDeserializer(new SimpleStringSchema()).setGroupId("flink-consumer-group") // 新版需显式设置消费组.build();// 关键:使用新UID,如“kafka-source-v2”DataStream<String> stream = env.fromSource(source,WatermarkStrategy.noWatermarks(), // 根据业务需求调整Watermark策略"New Kafka Source").uid("kafka-source-v2") // 新UID,与旧版“kafka-source”区分.name("New Kafka Source");2.5.2 第二步:启动作业时启用 --allow-non-restored-state
若直接从旧保存点恢复,Flink 会因 “旧 UID 对应的状态无法匹配新算子” 而报错。需通过--allow-non-restored-state参数告诉 Flink “忽略无法匹配的旧状态”:
# 从保存点恢复,允许忽略无法匹配的旧状态flink run \--class com.example.MyFlinkJob \--fromSavepoint hdfs:///flink/savepoints/savepoint-xxx \--allow-non-restored-state \ # 核心参数,安全丢弃旧状态--executor-memory 2g \ # 根据JobManager内存需求调整--akka.framesize 128mb \ # 可选:临时增大RPC帧大小,避免恢复时超限
my-flink-job.jar2.5.3 效果验证
启用上述配置后:
- 第一次恢复时,Flink 会丢弃旧 UID(kafka-source)对应的状态,仅为新 UID(kafka-source-v2)初始化新状态;
- 从下一次 Checkpoint 开始,_metadata文件仅包含新算子的状态,大小迅速恢复正常(如 10 个分区对应 10KB 左右);
- 作业恢复后,KafkaSource 会从 “消费组的最新偏移量” 或 “指定的起始偏移量” 开始消费(需根据业务需求配置setStartingOffsets)。
特殊场景:需保留部分状态的迁移
若业务要求 “保留旧连接器的偏移量,避免重复消费”,可通过以下方案实现:
- 提前导出旧偏移量:从旧保存点中提取FlinkKafkaConsumer的偏移量(可通过 Flink 的SavepointReader工具);
- 设置新连接器起始偏移量:在KafkaSource中通过setStartingOffsets指定导出的偏移量:
// 从旧保存点导出的偏移量示例:topic-0 → 1000,topic-1 → 2000Map<TopicPartition, Long> oldOffsets = new HashMap<>();oldOffsets.put(new TopicPartition("topic", 0), 1000L);oldOffsets.put(new TopicPartition("topic", 1), 2000L);// 配置KafkaSource从旧偏移量开始消费KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("kafka:9092").setTopics("topic").setValueOnlyDeserializer(new SimpleStringSchema()).setGroupId("flink-consumer-group").setStartingOffsets(OffsetsInitializer.manual(oldOffsets)) // 手动指定起始偏移量.build();2.6 最佳实践:从 “被动修复” 到 “主动预防”
2.6.1 建立 UID 命名规范,避免随意复用
UID 是 Flink 状态生命周期的 “唯一标识”,需在项目初期定义规范,建议格式:[组件类型]-[功能描述]-[版本号],例如:
- Kafka Source:kafka-source-order-v1、kafka-source-user-v2;
- Keyed Process Function:kpf-agg-order-amount-v1;
- Sink:kafka-sink-order-result-v1。
版本号的作用是 “明确区分算子变更”—— 当算子逻辑(如状态类型、业务逻辑)变更时,同步升级版本号,避免状态关联错误。
2.6.2 制定 API 升级检查清单
每次进行连接器(如 Kafka、HBase)或 Flink 版本升级前,需执行以下检查:
| 检查项 | 检查内容 | 结果(√/×) |
| 状态兼容性 | 新旧算子的状态类型是否一致?是否需自定义状态迁移器(State Migrator)? | |
| UID 规划 | 是否需为新算子设置新 UID?旧 UID 对应的状态是否需保留或清理? | |
| 保存点测试 | 在测试环境从旧保存点恢复,验证是否成功?保存点大小是否正常? | |
| 数据一致性验证 | 升级后是否存在数据重复 / 丢失?通过对比源端与 Sink 端数据量验证? | |
| 回滚方案 | 若升级失败,是否有回滚到旧版本的预案?(如保留旧作业 JAR 与保存点) |
2.6.3 实施状态监控,提前发现异常
通过 Prometheus+Grafana 监控以下状态相关指标,设置告警阈值:
| 指标名称 | 含义 | 告警阈值示例 |
| flink_jobmanager_savepoint_size | 保存点总大小 | 超过 1GB 触发告警 |
| flink_jobmanager_savepoint_metadata_size | _metadata 文件大小 | 超过 100MB 触发告警 |
| flink_jobmanager_checkpoint_duration | Checkpoint 执行时间 | 超过 30 秒触发告警 |
| flink_jobmanager_checkpoint_failure_rate | Checkpoint 失败率 | 超过 10% 触发告警 |
2.6.4 测试环境完整复现生产场景
测试环境需模拟生产的关键参数:
- 数据量:使用生产数据的子集(如 10%),避免因数据量过小无法暴露问题;
- 并行度:与生产保持一致(如生产并行度 10,测试也设为 10);
- 状态大小:通过循环写入测试数据,使状态大小接近生产水平;
- 恢复流程:每次测试需包含 “从保存点恢复” 的步骤,验证恢复成功率。
三、问题二:任务槽负载分配不均问题
3.1 症状表现:资源利用的 “冰火两重天”
在 Flink 生产环境中,“任务槽(Task Slot)负载不均” 是仅次于状态问题的高频痛点。典型表现为:
- 资源倾斜:部分 TaskManager 的 CPU 利用率持续 100%(甚至超负载),而其他 TaskManager CPU 利用率低于 20%;
- 吞吐量受限:作业总吞吐量无法提升,瓶颈始终在 “最忙的 Task”(通过 Flink UI 的 “Records Sent/Received” 指标可观察);
- 背压传播:忙 Task 的背压(Backpressure)状态从 “OK” 变为 “LOW” 甚至 “HIGH”,并向上游算子传播,导致整个作业延迟增长;
- ** checkpoint 超时 **:忙 Task 因处理数据压力大,无法及时完成 Checkpoint 快照,导致 Checkpoint 失败率上升。
TaskManager列表(并行度=10):┌───────────────┬───────────┬────────────┬─────────────┐│ TaskManager │ CPU利用率 │ 输入记录数 │ 背压状态 │├───────────────┼───────────┼────────────┼─────────────┤│ tm-1 │ 100% │ 1,000,000 │ HIGH ││ tm-2 │ 98% │ 950,000 │ HIGH ││ tm-3 │ 15% │ 50,000 │ OK ││ tm-4 │ 12% │ 45,000 │ OK ││ ...(共10个) │ <20% │ <50,000 │ OK │└───────────────┴───────────┴────────────┴─────────────┘图 3:Task 负载不均的 Flink UI 指标示意
例如:某电商平台的 “商品销量实时统计” 作业,并行度设为 10,但两个 TaskManager 处理了 95% 的商品数据(主要是热门商品),其余 8 个 TaskManager 几乎空闲,导致大促期间作业延迟从 100ms 飙升至 5s。
3.2 根本原因:数据分布倾斜与默认策略的局限性
负载不均的本质是 “数据分布不均”,而 Flink 的默认资源调度策略无法应对这种不均。具体可拆解为三个层面:
3.2.1 核心根源:键控流(Keyed Stream)的数据倾斜
Flink 的keyBy算子是负载不均的 “重灾区”—— 它根据 Key 的哈希值将数据分发到不同的 Task Slot,若 Key 的分布本身不均(即 “数据倾斜”),则负载必然倾斜。
典型场景:
- 电商:热门商品(如爆款手机)的订单量占总订单量的 80%,若按 “商品 ID”keyBy,处理该商品 ID 的 Task 将承受绝大部分负载;
- 社交:头部主播的直播间消息量远超普通主播,按 “主播 ID”keyBy会导致负载集中;
- 金融:少数大客户的交易笔数占比高,按 “客户 ID”keyBy会引发倾斜。
Key分布(共10个Key):Key A: 800条数据(80%)Key B: 100条数据(10%)Key C-I: 各10条数据(共9%)Key J: 10条数据(1%)Flink默认哈希分区(并行度=3):Task 1: 处理Key A → 800条数据(负载80%)Task 2: 处理Key B、C、D → 120条数据(负载12%)Task 3: 处理Key E-J → 60条数据(负载8%)图 4:数据倾斜下的 Key 分布与 Task 负载关系
3.2.2 次要根源 1:默认哈希分区的局限性
Flink 对keyBy后的分区默认使用 “MurmurHash 2” 哈希函数,将 Key 映射到对应的 KeyGroup(Flink 用于状态分区的逻辑单元),再分配到 Task Slot。这种策略的前提是 “Key 的哈希值均匀分布”,但实际场景中:
- 若 Key 本身存在 “热点”(如固定前缀的 Key:prod_001、prod_002…),哈希后可能集中在少数 KeyGroup;
- 若 Key 的取值范围过小(如仅 10 个 Key),即使分布均匀,并行度设为 20 也会导致部分 Task 空闲。
3.2.3 次要根源 2:并行度设置缺乏数据感知
许多团队设置并行度时 “凭经验”(如默认设为 10、20),未结合数据分布特征计算合理值。例如:
- 若数据中存在 1 个热点 Key,即使并行度设为 100,该 Key 的负载仍会集中在 1 个 Task(哈希分区无法拆分单个 Key 的负载);
- 若总数据量仅 1000 条 / 秒,并行度设为 100,每个 Task 平均仅处理 10 条 / 秒,资源严重浪费。
3.3 数据倾斜的检测方法:从指标到数据验证
解决负载不均的前提是 “精准检测倾斜根源”,需结合 Flink UI 指标与数据分布分析。
3.3.1 步骤 1:通过 Flink UI 定位倾斜 Task
- 进入 Flink 作业的 “Task Managers” 页面,查看各 TaskManager 的 “CPU Usage”“Records In/Out” 指标,找到负载最高的 TaskManager;
- 点击该 TaskManager,进入 “Tasks” 页面,查看其负责的 Task,记录对应的 “Subtask Index”;
- 进入作业的 “Job Graph” 页面,点击keyBy后的算子(如ProcessWindowFunction),查看 “Subtask Metrics”,对比各 Subtask 的 “Records In”—— 若某 Subtask 的记录数是其他的 10 倍以上,可确认存在倾斜。
3.3.2 步骤 2:分析 Key 分布,找到热点 Key
通过以下两种方式定位具体的热点 Key:
日志打印:在keyBy前添加日志,打印 Key 的频次(仅测试环境或低负载生产环境使用):
// 打印Key的频次,定位热点Key(生产环境需控制日志量)dataStream.map(new MapFunction<Order, Order>() {private final Map<String, AtomicLong> keyCount = new ConcurrentHashMap<>();@Overridepublic Order map(Order value) throws Exception {String productId = value.getProductId();keyCount.computeIfAbsent(productId, k -> new AtomicLong(0)).incrementAndGet();// 每1000条记录打印一次Key频次if (keyCount.get(productId) % 1000 == 0) {LOG.info("Product ID: {}, Count: {}", productId, keyCount.get(productId));}return value;}}).keyBy(Order::getProductId).window(TumblingProcessingTimeWindow.of(Time.minutes(1))).sum("amount");- SQL 查询验证:若数据源自 Kafka/Hive,可通过 SQL 直接统计 Key 的分布:
-- 统计Kafka主题中各商品ID的订单数(Top 10)SELECT product_id, COUNT(*) AS order_countFROM kafka_order_topicWHERE event_time >= CURRENT_TIMESTAMP - INTERVAL '10' MINUTEGROUP BY product_idORDER BY order_count DESCLIMIT 10;3.3.3 步骤 3:量化倾斜程度
通过以下指标量化倾斜程度,为解决方案提供依据:
- 倾斜率:热点 Key 的记录数 / 平均每个 Key 的记录数;
- 负载占比:热点 Task 的处理记录数 / 总记录数;
- 延迟差异:热点 Task 的处理延迟 / 非热点 Task 的处理延迟。
例如:“倾斜率 = 80,负载占比 = 80%,延迟差异 = 50 倍”,说明倾斜已严重影响作业性能。
3.4 解决方案:分层优化策略
针对数据倾斜的不同场景,需采用 “分层优化” 策略 —— 从简单的 “数据打散” 到复杂的 “动态重平衡”,逐步提升负载均衡效果。
3.4.1 第一层优化:数据预处理 —— 盐值打散(适用于热点 Key 集中场景)
“盐值打散” 是解决热点 Key 的 “快速方案”,核心思路是:
- 加盐:对热点 Key 添加随机前缀(如 0~N-1 的随机数,N 为打散后的并行度),将 1 个热点 Key 拆分为 N 个 “虚拟 Key”;
- 分片聚合:按 “虚拟 Key”keyBy后进行局部聚合,分散负载;
- 去盐聚合:去掉虚拟 Key 前缀,按原 KeykeyBy后进行全局聚合,得到最终结果。
代码示例(Java):
// 原始数据:Order{productId: String, amount: Double}DataStream<Order> orderStream = ...;// 步骤1:识别热点Key(假设已知热点Key为"hot_prod_001")DataStream<Tuple2<String, Double>> saltedStream = orderStream.map(order -> {String productId = order.getProductId();String saltedKey;// 对热点Key添加随机盐值(0~4,打散为5个虚拟Key)if ("hot_prod_001".equals(productId)) {int salt = new Random().nextInt(5); // 盐值范围:0-4saltedKey = salt + "_" + productId; // 虚拟Key:如"0_hot_prod_001"} else {saltedKey = productId; // 非热点Key保持不变}return Tuple2.of(saltedKey, order.getAmount());});// 步骤2:按虚拟Key分片聚合(分散热点负载)DataStream<Tuple2<String, Double>> partialAggStream = saltedStream.keyBy(t -> t.f0) // 按虚拟Key分组.window(TumblingProcessingTimeWindow.of(Time.minutes(1))).sum(1); // 局部求和// 步骤3:去盐,按原Key全局聚合(得到最终结果)DataStream<Tuple2<String, Double>> finalAggStream = partialAggStream.map(t -> {String saltedKey = t.f0;String originalKey;// 去掉盐值前缀,恢复原Keyif (saltedKey.contains("_hot_prod_001")) {originalKey = saltedKey.split("_")[1]; // 提取原Key:"hot_prod_001"} else {originalKey = saltedKey;}return Tuple2.of(originalKey, t.f1);}).keyBy(t -> t.f0) // 按原Key分组.window(TumblingProcessingTimeWindow.of(Time.minutes(1))).sum(1); // 全局求和finalAggStream.addSink(...);效果:将原本集中在 1 个 Task 的热点 Key 负载,分散到 5 个 Task,每个 Task 处理 20% 的热点数据,负载均衡度显著提升。
注意事项:
- 盐值范围(N)需根据热点 Key 的负载程度调整,通常设为 “热点 Task 当前负载 / 目标负载”(如当前负载 80%,目标负载 20%,则 N=4);
- 需提前识别热点 Key(可通过历史数据统计或实时监控),若热点 Key 动态变化,需结合 “动态热点检测”(如实时计算 Key 的频次,超过阈值则自动加盐)。
3.4.2 第二层优化:自定义分区策略(适用于已知数据分布场景)
若已知 Key 的分布特征(如 Key 按业务类型分类),可通过实现Partitioner接口自定义分区逻辑,避免默认哈希的局限性。
场景示例:某物流平台的 “订单区域分布” 中,“华东区” 订单占比 40%,“华北区” 30%,其他区域 30%。默认哈希可能将 “华东区” 订单集中到 1 个 Task,可自定义分区将 “华东区” 拆分为 2 个 Task。
代码示例(自定义 Partitioner):
// 自定义分区器:按区域分配Taskpublic class RegionPartitioner implements Partitioner<String> {// 分区逻辑:华东区→0/1,华北区→2,其他→3@Overridepublic int partition(String region, int numPartitions) {switch (region) {case "华东区":// 华东区分到2个Task(0或1),分散负载return new Random().nextInt(2);case "华北区":return 2;default:return 3;}}}// 应用自定义分区器DataStream<Order> orderStream = ...;orderStream.partitionCustom(new RegionPartitioner(), Order::getRegion) // 按区域分区.keyBy(Order::getOrderId) // 再按订单ID分组.process(new OrderProcessFunction()).addSink(...);优势:可根据业务逻辑精准控制数据流向,比默认哈希更灵活;
局限:需提前掌握数据分布特征,不适用于动态变化的 Key 分布。
3.4.3 第三层优化:动态重平衡机制(适用于动态负载场景)
Flink 1.13 + 引入 “动态资源管理”(Dynamic Resource Allocation),支持根据作业负载自动调整 Task Slot 数量;结合 “动态重平衡”(Dynamic Rebalancing),可在运行时调整数据分区,应对动态变化的负载。
3.4.3.1 1. 启用动态资源管理
在flink-conf.yaml中配置:
# 启用动态资源管理jobmanager.resource.dynamic-resource-allocation.enabled: true# 最小/最大Slot数量jobmanager.resource.dynamic-resource-allocation.min-slots-per-taskmanager: 1jobmanager.resource.dynamic-resource-allocation.max-slots-per-taskmanager: 10# 资源调整触发阈值(空闲/繁忙时间)jobmanager.resource.dynamic-resource-allocation.resource-idle-timeout: 5minjobmanager.resource.dynamic-resource-allocation.load-balancing-interval: 30s3.4.3.2 2. 使用动态重平衡算子
Flink 提供rebalance()和rescale()算子,可在运行时重新分配数据:
- rebalance():全局重平衡,将数据均匀分发到所有 Task(适用于跨 TaskManager 的负载调整);
- rescale():局部重平衡,仅在当前 TaskManager 内分发数据(适用于单 TaskManager 内的负载调整)。
代码示例:
// 在keyBy前添加rebalance,避免上游数据倾斜DataStream<Order> orderStream = ...;orderStream.rebalance() // 全局重平衡,均匀分发数据.keyBy(Order::getProductId).window(TumblingProcessingTimeWindow.of(Time.minutes(1))).sum("amount").addSink(...);3.4.3.3 3. 基于负载的动态重平衡(进阶)
对于更复杂的场景,可结合 Flink 的 Metrics API 实时监控 Task 负载,当负载超过阈值时触发重平衡:
// 自定义ProcessFunction,监控负载并触发重平衡public class LoadAwareRebalanceFunction extends ProcessFunction<Order, Order> {private transient Gauge<Double> cpuGauge;private static final double CPU_THRESHOLD = 0.8; // CPU阈值:80%@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);// 获取当前Task的CPU利用率GaugecpuGauge = getRuntimeContext().getMetricGroup().getIOMetricGroup().getCpuUtilizationGauge();}@Overridepublic void processElement(Order value, Context ctx, Collector<Order> out) throws Exception {// 若CPU利用率超过阈值,输出重平衡信号(可结合侧输出流)if (cpuGauge.getValue() > CPU_THRESHOLD) {ctx.output(new OutputTag<String>("rebalance-signal") {}, "rebalance");}out.collect(value);}}// 应用负载感知重平衡OutputTag<String> rebalanceTag = new OutputTag<String>("rebalance-signal") {};SingleOutputStreamOperator<Order> mainStream = orderStream.process(new LoadAwareRebalanceFunction());// 监听重平衡信号,触发作业重配置(需结合Flink REST API)mainStream.getSideOutput(rebalanceTag).addSink(new SinkFunction<String>() {@Overridepublic void invoke(String value, Context context) throws Exception {if ("rebalance".equals(value)) {// 调用Flink REST API触发重平衡(示例:使用HttpClient)triggerJobRebalance();}}});优势:可应对动态变化的负载,无需人工干预;
局限:需开发额外的监控与触发逻辑,对集群稳定性要求较高。
3.4.4 第四层优化:KeyGroup 与状态分区调整(适用于状态倾斜场景)
若倾斜不仅导致负载不均,还引发 “状态倾斜”(如热点 Key 的状态大小远超其他 Key),需调整 Flink 的 KeyGroup 配置:
- 增大 KeyGroup 数量:KeyGroup 是 Flink 状态分区的最小单元,默认数量等于并行度。增大 KeyGroup 数量(通过state.backend.key-group-range.max-parallelism配置),可使状态分片更细,为后续并行度调整预留空间:
# flink-conf.yaml中配置state.backend.key-group-range.max-parallelism: 1024 # 默认等于并行度,建议设为2的幂- 调整并行度与 KeyGroup 映射:通过setParallelism()设置并行度时,Flink 会将 KeyGroup 均匀分配到 Task,若 KeyGroup 数量足够大,可减少单个 Task 的状态负载。
3.5 最佳实践:从设计到监控的全流程优化
3.5.1 设计阶段:避免先天倾斜
- Key 选择优化:尽量选择分布均匀的 Key,如 “订单 ID”(UUID)而非 “商品 ID”(易有热点);若必须用热点 Key,提前规划打散策略;
- 无状态优先:能通过process()而非keyBy().process()实现的逻辑,优先使用无状态算子,避免数据倾斜;
- 窗口拆分:对大窗口(如 1 小时),可拆分为多个小窗口(如 10 分钟),再通过allowedLateness处理迟到数据,分散窗口计算压力。
3.5.2 部署阶段:合理配置并行度
并行度的设置需结合 “数据量、Key 分布、单 Task 处理能力”,计算公式参考:
合理并行度 = 峰值QPS / 单Task最大处理能力
- 峰值 QPS:业务高峰期的每秒数据量(如 10 万条 / 秒);
- 单 Task 最大处理能力:通过测试环境压测得到(如 1 万条 / 秒 / Task);
- 实际配置时需预留 20%~30% 冗余,避免突发流量。
3.5.3 监控阶段:实时感知倾斜
通过 Prometheus+Grafana 监控以下指标,设置告警:
| 指标名称 | 含义 | 告警阈值示例 |
| flink_taskmanager_job_task_cpu_usage | Task 的 CPU 利用率 | 持续 5 分钟 > 90% |
| flink_taskmanager_job_task_records_in_rate | Task 的输入记录速率 | 某 Task 是均值的 10 倍 |
| flink_taskmanager_job_task_backpressure | Task 的背压状态 | 持续 1 分钟 > HIGH |
| flink_taskmanager_job_task_state_size | Task 的状态大小 | 超过 1GB |
3.5.4 复盘阶段:沉淀倾斜处理经验
每次处理完负载不均问题后,需记录以下信息,形成团队知识库:
- 倾斜场景:业务场景、Key 类型、数据量;
- 倾斜原因:Key 分布特征、默认策略的局限性;
- 解决方案:采用的优化方法、代码变更、配置调整;
- 效果验证:优化前后的负载、延迟、吞吐量对比。
四、问题三:Kryo 序列化后备机制的性能陷阱
4.1 症状表现:隐藏的 “性能悬崖”
Flink 作业在运行中突然出现 “高 CPU 占用但低吞吐量”,是 Kryo 序列化陷阱的典型特征。具体症状包括:
- 延迟尖峰:处理特定类型数据(如自定义 POJO)时,延迟从毫秒级飙升至秒级;
- 吞吐量骤降:高负载下(如 QPS>10 万),吞吐量仅为预期的 25%~50%;
- CPU 异常:TaskManager CPU 利用率持续 80% 以上,但大部分 CPU 消耗在 “序列化 / 反序列化” 操作(通过jstack可观察到com.esotericsoftware.kryo.Kryo.writeClassAndObject线程占比高);
- 日志线索:Flink 启动日志中存在TypeExtractor的 INFO 级日志,提示 “类无法作为 POJO,将使用 Kryo 序列化”。
案例:某物联网平台的 Flink 作业,处理设备上报的DeviceData POJO(包含 10 个字段),测试环境吞吐量可达 20 万条 / 秒,生产环境却仅 5 万条 / 秒,CPU 利用率达 90%。查看日志发现 “DeviceData缺少默认构造函数,使用 Kryo 序列化”,修复 POJO 后吞吐量恢复至 18 万条 / 秒。
4.2 技术原理:Flink 序列化机制的优先级与性能差异
Flink 的序列化机制直接决定作业性能 —— 不同序列化器的性能差异可达4 倍以上。Flink 按以下优先级选择序列化器,性能逐层递减:
表 3:Flink 序列化器优先级与性能对比
| 优先级 | 序列化器类型 | 适用场景 | 性能(相对值) | 优点 | 缺点 |
| 1 | 内置基础类型序列化器 | String、Long、Integer、Double 等基础类型 | 100%(基准) | 无反射开销,速度最快 | 仅支持基础类型 |
| 2 | 数组序列化器 | 基础类型数组(如 String []、int []) | 95% | 序列化逻辑简单,速度接近基础类型 | 仅支持基础类型数组 |
| 3 | 复合类型序列化器 | Tuple(Tuple1~Tuple25)、Case Class(Scala) | 90% | 预编译序列化逻辑,无反射 | 仅支持 Flink 内置复合类型 |
| 4 | POJO 序列化器 | 符合 POJO 规范的自定义类 | 85% | 支持自定义类型,性能接近内置类型 | 需满足 POJO 规范 |
| 5 | 专用格式序列化器 | Avro、Protobuf、JSON Schema | 70%~80% | 跨语言兼容, schema 演进支持好 | 需定义 schema,序列化逻辑稍复杂 |
| 6 | Kryo 序列化器(回退) | 不符合上述规范的自定义类 | 25%~50% | 兼容性强,支持几乎所有 Java 类 | 反射开销大,性能低 |
| 7 | Java 序列化器(兜底) | 实现 Serializable 接口但不支持 Kryo 的类 | 10%~20% | 兼容性最强 | 性能极差,不建议生产使用 |
关键结论:Kryo 是 “最后的选择”
Flink 仅在无法使用前 5 类序列化器时,才会自动回退到 Kryo。而 Kryo 的性能仅为 POJO 序列化器的1/3~1/2,一旦触发,将直接导致作业性能 “断崖式下跌”。
4.3 性能影响:实测数据揭示差距
为量化不同序列化器的性能差异,我们在相同环境(4 核 8GB 虚拟机、Flink 1.17)下进行压测:测试数据为自定义User类(包含 id: Long、name: String、age: Int、address: String 4 个字段),每条数据大小约 100 字节,并行度设为 4。
表 4:不同序列化器性能压测结果
| 序列化器类型 | 吞吐量(条 / 秒) | 平均延迟(ms) | CPU 利用率(%) | 相对性能(POJO 为 100%) |
| POJO 序列化器 | 180,000 | 12 | 45 | 100% |
| Avro 序列化器 | 150,000 | 15 | 55 | 83% |
| Protobuf 序列化器 | 140,000 | 16 | 58 | 78% |
| Kryo 序列化器 | 50,000 | 45 | 90 | 28% |
| Java 序列化器 | 20,000 | 110 | 95 | 11% |
可见,Kryo 序列化器的吞吐量仅为 POJO 的 28%,延迟是 POJO 的 3.75 倍,CPU 利用率接近饱和 —— 这意味着,若生产作业无意中触发 Kryo,即使硬件资源充足,吞吐量也无法提升。
4.4 根本原因识别:从日志到代码的排查路径
触发 Kryo 序列化的根本原因是 “自定义类不符合 POJO 规范”,Flink 会在日志中明确提示,关键是要能识别这些 “线索日志”。
4.4.1 步骤 1:查找 TypeExtractor 日志
Flink 的TypeExtractor类负责判断类是否符合 POJO 规范,若不符合,会输出 INFO 级日志。需在 TaskManager 日志中过滤以下关键字:
# 查找POJO相关日志grep "TypeExtractor" /path/to/flink/log/taskmanager.log | grep -i "pojo"4.4.2 步骤 2:识别常见不符合 POJO 的日志类型
以下是三类最常见的 “不符合 POJO 规范” 日志,对应不同的根因:
类型 1:类非公共(non-public)
INFO org.apache.flink.api.java.typeutils.TypeExtractor - Class com.example.User is not public, so it cannot be used as a POJO type. Falling back to Kryo.根因:自定义类的访问修饰符不是public,Flink 无法通过反射访问其字段。
类型 2:缺少无参构造函数
INFO org.apache.flink.api.java.typeutils.TypeExtractor - Class com.example.User is missing a default (no-arg) constructor, so it cannot be used as a POJO type. Falling back to Kryo.根因:自定义类仅定义了有参构造函数,未显式定义无参构造函数(Java 默认会生成无参构造函数,但显式定义有参后会覆盖默认)。
类型 3:字段不可访问或存在特殊修饰符
INFO org.apache.flink.api.java.typeutils.TypeExtractor - Class com.example.User has fields with non-public access modifiers (e.g., private) and no getter/setter methods. Falling back to Kryo.根因:类的字段是private,但未提供getter/setter方法,Flink 无法读写字段值;或字段使用transient/static/final修饰(这些字段不会被序列化)。
类型 4:泛型类型信息缺失
INFO org.apache.flink.api.java.typeutils.TypeExtractor - Class com.example.User contains generic type parameters, but no type information is provided. Falling back to Kryo.根因:类包含泛型字段(如List<String>),但未通过注解(如@TypeInfo)提供显式类型信息,Flink 无法推断泛型类型。
4.4.3 步骤 3:代码层面验证 POJO 规范
根据日志提示,检查自定义类的代码,确认是否违反 POJO 规范。例如,以下User类存在两处问题:
// 错误示例:不符合POJO规范的User类class User { // 问题1:非public类private Long id;private String name;private int age;private List<String> tags; // 问题2:泛型字段无显式类型信息// 问题3:仅定义有参构造函数,无无参构造函数public User(Long id, String name, int age, List<String> tags) {this.id = id;this.name = name;this.age = age;this.tags = tags;}// 问题4:缺少id的getter方法public String getName() { return name; }public void setName(String name) { this.name = name; }public int getAge() { return age; }public void setAge(int age) { this.age = age; }public List<String> getTags() { return tags; }public void setTags(List<String> tags) { this.tags = tags; }}4.5 解决方案:构建 “完美 POJO” 与序列化优化
解决 Kryo 性能陷阱的核心是 “让 Flink 使用 POJO 序列化器”,需严格遵循 POJO 规范,并针对复杂场景(如泛型、嵌套类)进行优化。
4.5.1 完美 POJO 设计检查清单
以下是 Flink POJO 的 “黄金规范”,需逐条满足:
表 5:Flink POJO 设计检查清单
| 检查项 | 要求 | 正确示例 | 常见错误示例 |
| 类访问修饰符 | 必须为public | public class User { ... } | class User { ... }(默认包访问权限) |
| 构造函数 | 必须包含无参构造函数(可显式定义,即使为空) | public User() {} public User(Long id, String name) { ... } | 仅定义有参构造函数:public User(Long id, String name) { ... } |
| 字段访问 | 字段为private时,必须提供对应的getter(public)和setter(public);或字段直接为public | 字段private Long id + public Long getId() + public void setId(Long id) | 字段private Long id但无getter,或getter为private |
| 字段修饰符 | 不使用transient/static/final(这些字段不会被序列化) | private String name; | private transient String name; private static int count; |
| 泛型类型 | 泛型字段需通过@TypeInfo或@TypeHint提供显式类型信息 | @TypeInfo(ListTypeInfo.class) private List<String> tags; | private List<String> tags;(无类型注解) |
| 嵌套类 | 嵌套类必须为static(静态内部类),非静态内部类会包含外部类引用 | public static class Address { ... } | public class Address { ... }(非静态内部类) |
| 继承关系 | 若继承自其他类,父类也需满足 POJO 规范 | public class VipUser extends User { ... }(User 满足 POJO 规范) | 父类缺少无参构造函数 |
4.5.2 正确 POJO 示例(修复后)
根据上述清单,修复后的User类如下:
import org.apache.flink.api.common.typeinfo.TypeInfo;import org.apache.flink.api.common.typeinfo.Types;import org.apache.flink.api.java.typeutils.ListTypeInfo;// 正确示例:符合POJO规范的User类public class User { // 1. public类private Long id;private String name;private int age;// 2. 泛型字段添加@TypeInfo,指定List<String>类型@TypeInfo(ListTypeInfo.class)private List<String> tags;// 3. 静态内部类(嵌套类需static)private Address address;// 4. 显式无参构造函数public User() {}// 5. 有参构造函数(可选)public User(Long id, String name, int age, List<String> tags, Address address) {this.id = id;this.name = name;this.age = age;this.tags = tags;this.address = address;}// 6. 所有private字段提供getter/setterpublic Long getId() { return id; }public void setId(Long id) { this.id = id; }public String getName() { return name; }public void setName(String name) { this.name = name; }public int getAge() { return age; }public void setAge(int age) { this.age = age; }public List<String> getTags() { return tags; }public void setTags(List<String> tags) { this.tags = tags; }public Address getAddress() { return address; }public void setAddress(Address address) { this.address = address; }// 7. 嵌套类为static,且符合POJO规范public static class Address {private String province;private String city;public Address() {} // 无参构造函数public Address(String province, String city) {this.province = province;this.city = city;}public String getProvince() { return province; }public void setProvince(String province) { this.province = province; }public String getCity() { return city; }public void setCity(String city) { this.city = city; }}}4.5.3 泛型类型的高级处理
对于复杂泛型(如Map<String, List<User>>),需使用TypeHint或TypeInformation显式指定类型:
import org.apache.flink.api.common.typeinfo.TypeHint;import org.apache.flink.api.common.typeinfo.TypeInformation;// 场景:处理Map<String, List<User>>类型的数据DataStream<Map<String, List<User>>> mapStream = ...;// 方式1:使用TypeHint指定泛型类型TypeInformation<Map<String, List<User>>> typeInfo = TypeInformation.of(new TypeHint<Map<String, List<User>>>() {});// 方式2:手动构建TypeInformationTypeInformation<List<User>> listType = new ListTypeInfo<>(User.class);TypeInformation<Map<String, List<User>>> mapType = new MapTypeInfo<>(Types.STRING, // Key类型listType // Value类型);// 应用类型信息(如在map算子中)DataStream<String> resultStream = mapStream.map(new MapFunction<Map<String, List<User>>, String>() {@Overridepublic String map(Map<String, List<User>> value) throws Exception {return "Key count: " + value.size();}}).returns(typeInfo); // 显式指定返回类型4.5.4 启用 fail-fast 模式:提前暴露问题
为避免 “生产环境才发现 Kryo 序列化”,可在作业启动时启用 “泛型禁用”(fail-fast)模式 —— 若存在无法使用高效序列化器的类型,作业会直接启动失败,强制在开发阶段修复:
// 启用fail-fast模式:禁用泛型类型(触发Kryo的类型会导致启动失败)StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.getConfig().disableGenericTypes(); // 核心配置// 若存在不符合POJO规范的类,启动时会抛出以下异常:// org.apache.flink.api.common.functions.InvalidTypesException:// The generic type parameters of 'User' are not properly specified.// Please use a TypeHint or provide a TypeInformation explicitly.4.5.5 专用格式序列化:Avro/Protobuf 优化
对于跨语言场景(如 Flink 与 Spark、Java 与 Python 交互),建议使用 Avro 或 Protobuf 序列化,它们兼具 “高性能” 与 “跨语言兼容性”,且支持 Schema 演进(Schema Evolution),比 POJO 更适合复杂业务场景。
4.5.5.1 Avro 序列化实践
Avro 是 Apache 基金会的开源数据序列化框架,基于 JSON 定义 Schema,支持动态类型和 Schema 演进。
步骤 1:定义 Avro Schema
创建user.avsc文件,定义User类型的 Schema
{"type": "record","name": "User","namespace": "com.example.avro","fields": [{"name": "id", "type": "long"},{"name": "name", "type": "string"},{"name": "age", "type": "int"},{"name": "tags", "type": {"type": "array", "items": "string"}},{"name": "address", "type": {"type": "record","name": "Address","fields": [{"name": "province", "type": "string"},{"name": "city", "type": "string"}]}}]}步骤 2:生成 Java 实体类
使用 Avro Maven 插件自动生成 Java 类(需在pom.xml中配置):
<plugin><groupId>org.apache.avro</groupId><artifactId>avro-maven-plugin</artifactId><version>1.11.1</version><executions><execution><phase>generate-sources</phase><goals><goal>schema</goal></goals><configuration><sourceDirectory>${project.basedir}/src/main/avro</sourceDirectory><outputDirectory>${project.basedir}/src/main/java</outputDirectory></configuration></execution></executions></plugin>执行mvn generate-sources后,会在com.example.avro包下生成User.java和Address.java。
步骤 3:Flink 中使用 Avro 序列化
Flink 提供AvroInputFormat和AvroOutputFormat,支持直接读写 Avro 格式数据:
// 1. 从Kafka读取Avro格式数据(需Kafka主题存储Avro二进制数据)KafkaSource<User> avroKafkaSource = KafkaSource.<User>builder().setBootstrapServers("kafka:9092").setTopics("user-avro-topic").setValueOnlyDeserializer(new AvroDeserializationSchema<>(User.class)) // Avro反序列化器.setGroupId("avro-consumer-group").build();DataStream<User> avroStream = env.fromSource(avroKafkaSource,WatermarkStrategy.noWatermarks(),"Avro Kafka Source");// 2. 处理后写入Avro文件(或Kafka)avroStream.addSink(AvroOutputFormat.buildAvroOutputFormat().setOutputPath(new Path("hdfs:///flink/output/user-avro")).setSchema(User.getClassSchema()) // 指定Avro Schema.finish());优势:Schema 与数据分离,支持新增字段、删除可选字段等演进操作;跨语言兼容性好,Python/Scala 可直接解析 Avro 数据。
4.5.5.2 Protobuf 序列化实践
Protobuf(Protocol Buffers)是 Google 开源的序列化框架,基于二进制格式,比 Avro 更紧凑,性能更高,适合高性能场景。
步骤 1:定义 Protobuf Schema
创建user.proto文件:syntax = "proto3";package com.example.protobuf;message Address {string province = 1;string city = 2;}message User {int64 id = 1;string name = 2;int32 age = 3;repeated string tags = 4; // 对应Java的List<String>Address address = 5;}步骤 2:生成 Java 实体类
使用 Protobuf Maven 插件生成 Java 类:
<plugin><groupId>org.xolstice.maven.plugins</groupId><artifactId>protobuf-maven-plugin</artifactId><version>0.6.1</version><configuration><protoSourceRoot>${project.basedir}/src/main/proto</protoSourceRoot><outputDirectory>${project.basedir}/src/main/java</outputDirectory><clearOutputDirectory>false</clearOutputDirectory></configuration><executions><execution><goals><goal>compile</goal></goals></execution></executions></plugin>执行mvn protobuf:compile后,生成User.java和Address.java。
步骤 3:Flink 中使用 Protobuf 序列化
Flink 1.14 + 提供ProtobufDeserializationSchema和ProtobufSerializationSchema:
// 1. 从Kafka读取Protobuf格式数据KafkaSource<User> protobufKafkaSource = KafkaSource.<User>builder().setBootstrapServers("kafka:9092").setTopics("user-protobuf-topic").setValueOnlyDeserializer(ProtobufDeserializationSchema.of(User.class)) // Protobuf反序列化器.setGroupId("protobuf-consumer-group").build();DataStream<User> protobufStream = env.fromSource(protobufKafkaSource,WatermarkStrategy.noWatermarks(),"Protobuf Kafka Source");// 2. 处理后写入Kafka(Protobuf格式)protobufStream.addSink(KafkaSink.<User>builder().setBootstrapServers("kafka:9092").setRecordSerializer(KafkaRecordSerializationSchema.<User>builder().setTopic("user-protobuf-output").setValueSerializationSchema(ProtobufSerializationSchema.of(User.class)) // Protobuf序列化器.build()).build());性能对比:在相同测试环境下,Protobuf 的吞吐量比 Avro 高约 10%~15%,数据压缩率更高(相同User数据,Protobuf 约 80 字节,Avro 约 100 字节),适合对性能和存储要求严格的场景。
4.5.6 Kryo 优化:无法避免时的性能提升
若因业务场景限制(如使用第三方库的非 POJO 类)无法避免 Kryo,可通过以下配置提升性能:
4.5.6.1 注册自定义类到 Kryo
提前注册自定义类,避免 Kryo 在序列化时动态生成类信息,减少反射开销
// 注册自定义类到KryoStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.getConfig().registerKryoType(com.example.ThirdPartyClass.class);env.getConfig().registerKryoType(com.example.AnotherThirdPartyClass.class);4.5.6.2 使用 Kryo 优化器(如 Objenesis)
Kryo 默认通过无参构造函数创建对象,若类无无参构造函数,可启用 Objenesis 优化:
// 启用Objenesis,支持无无参构造函数的类env.getConfig().setUseObjenesis(true);4.5.6.3 配置 Kryo 序列化缓存
启用 Kryo 序列化缓存,避免重复序列化相同对象:
# flink-conf.yaml中配置state.backend.kryo.cache-enabled: truestate.backend.kryo.cache-size: 10000 # 缓存大小,根据对象数量调整效果:通过上述优化,Kryo 的性能可提升 30%~50%,但仍无法达到 POJO 的性能水平,仅作为 “无法避免时的折中方案”。
4.6 最佳实践:序列化性能的全周期保障
4.6.1 开发阶段:提前验证序列化类型
在开发初期,通过 Flink 的TypeInformation工具验证类的序列化类型,避免生产环境踩坑:
// 验证User类的序列化类型TypeInformation<User> typeInfo = TypeInformation.of(User.class);System.out.println("Serialization Type: " + typeInfo.getTypeClass());System.out.println("Is POJO: " + typeInfo.isPojoType());若输出Is POJO: true,说明使用 POJO 序列化器;若为false,需检查是否符合 POJO 规范。
4.6.2 测试阶段:量化序列化性能
通过压测工具(如 Flink 的Benchmark模块)对比不同序列化器的性能,选择最优方案:
// 简单压测:对比POJO与Kryo的序列化耗时public class SerializationBenchmark {public static void main(String[] args) throws Exception {User user = new User(1L, "Alice", 25, Arrays.asList("tag1", "tag2"), new Address("Shanghai", "Shanghai"));// POJO序列化耗时TypeSerializer<User> pojoSerializer = TypeInformation.of(User.class).createSerializer(new ExecutionConfig());long pojoTime = benchmark(pojoSerializer, user, 100000);// Kryo序列化耗时(强制使用Kryo)ExecutionConfig config = new ExecutionConfig();config.disableGenericTypes();config.registerKryoType(User.class);TypeSerializer<User> kryoSerializer = new KryoSerializer<>(User.class, config);long kryoTime = benchmark(kryoSerializer, user, 100000);System.out.println("POJO Serialization Time: " + pojoTime + "ms");System.out.println("Kryo Serialization Time: " + kryoTime + "ms");}private static <T> long benchmark(TypeSerializer<T> serializer, T obj, int times) throws IOException {long start = System.currentTimeMillis();for (int i = 0; i < times; i++) {DataOutputView dov = new DataOutputViewStreamWrapper(new ByteArrayOutputStream());serializer.serialize(obj, dov);}return System.currentTimeMillis() - start;}}4.6.3 生产阶段:监控序列化指标
通过 Flink Metrics 监控序列化相关指标,及时发现异常:
| 指标名称 | 含义 | 告警阈值示例 |
| flink_taskmanager_job_task_serialization_time | 单个 Task 的序列化总耗时 | 每分钟超过 10 秒 |
| flink_taskmanager_job_task_deserialization_time | 单个 Task 的反序列化总耗时 | 每分钟超过 10 秒 |
| flink_taskmanager_job_task_kryo_usage_rate | Kryo 序列化的记录占比 | 超过 10% 触发告警 |
4.6.4 演进阶段:兼容 Schema 变更
当业务需要修改数据结构时,需遵循 Schema 演进规则:
- Avro:新增字段需设为可选("default": null),删除字段需确保下游已不依赖;
- Protobuf:新增字段使用新的标签号(tag),不修改现有标签号,删除字段标记为reserved;
- POJO:新增字段需提供默认值,避免反序列化旧数据时抛出NullPointerException。
五、总结:从实战到体系化的 Flink 错误处理能力
5.1 核心洞察:三大问题的共性与本质
通过对 Flink 生产环境 “三大核心问题” 的深度分析,可提炼出以下共性规律:
5.1.1 状态管理是 Flink 稳定性的 “基石”
Kafka 连接器迁移的核心矛盾是 “状态与算子的绑定关系”——UID 不仅是算子的标识,更是状态生命周期的 “控制开关”。忽视 UID 的作用,会导致状态累积、恢复失败等连锁问题。本质上,状态管理需纳入 “架构设计范畴”,而非 “开发细节”。
5.1.2 数据分布决定资源调度的 “效率上限”
任务槽负载不均的根源是 “数据倾斜”,而数据倾斜是现实业务的常态(如热门商品、头部主播)。Flink 的默认哈希分区仅适用于 “理想均匀数据”,生产环境需结合业务特征设计分层优化策略(盐值打散、自定义分区、动态重平衡),让资源调度 “适配数据分布” 而非 “依赖理想假设”。
5.1.3 序列化是性能优化的 “隐形杠杆”
Kryo 序列化陷阱揭示了 “细节决定性能”—— 一个不符合 POJO 规范的类(如缺少无参构造函数),可能导致吞吐量下降 75%。序列化优化的本质是 “让 Flink 使用最适合的序列化器”,优先选择 POJO、Avro 或 Protobuf,避免无意中触发低性能的 Kryo。
5.2 体系化错误处理能力构建路径
从 “被动排查问题” 到 “主动预防风险”,需构建 “监控 - 分析 - 解决 - 沉淀” 的闭环能力:

图 5:Flink 错误处理能力体系
5.2.1 第一步:构建全维度监控体系
覆盖 “作业 - 任务 - 状态 - 序列化” 四个层级,核心监控指标如下:
| 监控维度 | 核心指标 | 工具推荐 |
| 作业层面 | Checkpoint 成功率、恢复时间、总吞吐量 | Prometheus+Grafana |
| 任务层面 | CPU 利用率、背压状态、输入 / 输出速率 | Flink UI+Grafana |
| 状态层面 | 保存点大小、状态读写延迟、Checkpoint 对齐时间 | Prometheus+AlertManager |
| 序列化层面 | 序列化 / 反序列化耗时、Kryo 使用占比 | 自定义 Metrics+Grafana |
5.2.2 第二步:标准化根因分析流程
针对不同类型的问题,制定标准化分析路径:
- 状态相关问题:日志查找akka framesize/OutOfMemory → 检查保存点_metadata大小 → 验证 UID 是否复用 → 确认状态类型兼容性;
- 负载不均问题:Flink UI 查看 Task 负载分布 → 统计 Key 频次定位热点 Key → 分析数据倾斜率 → 选择分层优化策略;
- 性能问题:查看TypeExtractor日志确认序列化类型 → 压测对比不同序列化器性能 → 修复 POJO 规范或切换至 Avro/Protobuf。
5.2.3 第三步:沉淀解决方案库与最佳实践
将实战经验转化为可复用的 “解决方案模板” 和 “检查清单”:
- 解决方案模板:如 “Kafka 连接器迁移模板”(包含 UID 修改、保存点恢复参数、偏移量导出步骤);
- 检查清单:如 “Flink 作业上线前检查清单”(包含 POJO 规范验证、并行度合理性检查、状态监控配置)。
5.2.4 第四步:开发自动化工具提升效率
基于沉淀的经验,开发自动化工具:
- 状态分析工具:解析保存点_metadata文件,自动检测状态累积问题;
- POJO 验证工具:扫描项目中的自定义类,自动检查是否符合 POJO 规范;
- 数据倾斜检测工具:实时统计 Key 分布,自动识别热点 Key 并触发告警。
5.3 未来趋势与应对建议
随着 Flink 生态的持续演进(如 Flink 2.0 的状态后端优化、动态资源管理增强),错误处理的方式也将不断升级。未来需重点关注以下趋势:
5.3.1 趋势 1:状态管理智能化
Flink 社区正推进 “状态自动迁移” 功能,未来版本可能支持 “算子 UID 变更时的状态平滑迁移”,减少人工干预。建议:
- 关注 Flink 2.x 版本的状态管理新特性;
- 提前规范 UID 命名,为未来智能化迁移预留空间。
5.3.2 趋势 2:资源调度自适应
动态资源管理将支持 “基于数据分布的自动并行度调整”,可根据 Key 分布实时优化 Task 数量。建议:
- 生产环境启用动态资源管理(Flink 1.13+);
- 结合自定义负载感知逻辑,实现更精细的资源调度。
5.3.3 趋势 3:序列化优化自动化
未来 Flink 可能提供 “POJO 自动修复” 功能(如编译期生成无参构造函数),或增强 Avro/Protobuf 的原生支持。建议:
- 优先使用 Flink 原生支持的序列化格式;
- 避免过度依赖第三方库的非标准类。
5.4 最后的思考:技术问题背后的能力沉淀
Flink 生产环境的错误处理,不仅是 “解决技术问题”,更是 “沉淀工程能力”。一个团队的 Flink 水平,体现在:
- 是否能在 10 分钟内定位到 “保存点恢复失败” 的根因;
- 是否能通过标准化流程避免 “数据倾斜” 导致的大促故障;
- 是否能将 “序列化优化” 的经验转化为团队的 POJO 设计规范。
技术的本质是 “服务业务”,Flink 错误处理的最终目标,是确保实时数据处理系统 “稳定、高效、可靠”,为业务提供持续的实时价值。