第2.5节:中文大模型(文心一言、通义千问、讯飞星火)

🏆作者简介,黑夜开发者,CSDN领军人物,全栈领域优质创作者✌,CSDN博客专家,阿里云社区专家博主,2023年6月CSDN上海赛道top4。
🏆数年电商行业从业经验,历任核心研发工程师,项目技术负责人。
🏆本文已收录于专栏:智能时代:人人都要知道的AI课
🎉欢迎 👍点赞✍评论⭐收藏
本篇聚焦主流中文大模型:百度文心一言、阿里通义千问、科大讯飞星火。对比其版本谱系、中文能力、工具生态、API使用、RAG实践与企业落地策略,帮助读者做出选型与集成。
文章目录
- 🚀一、引言
- 🚀二、版本谱系与定位
- 🚀三、架构特点与中文能力
- 🔎3.1 中文语料与分词
- 🔎3.2 对齐与拒绝策略
- 🔎3.3 多模态与工具生态
- 🚀四、API 快速上手
- 🔎4.1 文心一言(Python 伪代码)
- 🔎4.2 通义千问(Python 伪代码)
- 🔎4.3 讯飞星火(Python 伪代码)
- 🔎4.4 结构化JSON输出模板
- 🚀五、RAG 与中文检索实务
- 🔎5.1 中文分词与检索
- 🔎5.2 拼接策略与模板
- 🔎5.3 简易代码(伪)
- 🚀六、提示工程与中文表达
- 🔎6.1 常用模板
- 🔎6.2 场景化示例
- 🚀七、成本、安全与合规
- 🔎7.1 成本优化
- 🔎7.2 安全与合规
- 🚀八、应用案例
- 🚀九、FAQ 与最佳实践
- 🔗参考资料
🚀一、引言
中文大模型在中文语料、行业数据与中文指令对齐方面具有先天优势,适用于中文写作、政务/金融/制造业知识问答、客服与办公自动化等场景。不同厂商在对话风格、工具生态、计费与SLA 上存在差异,需结合业务选择。
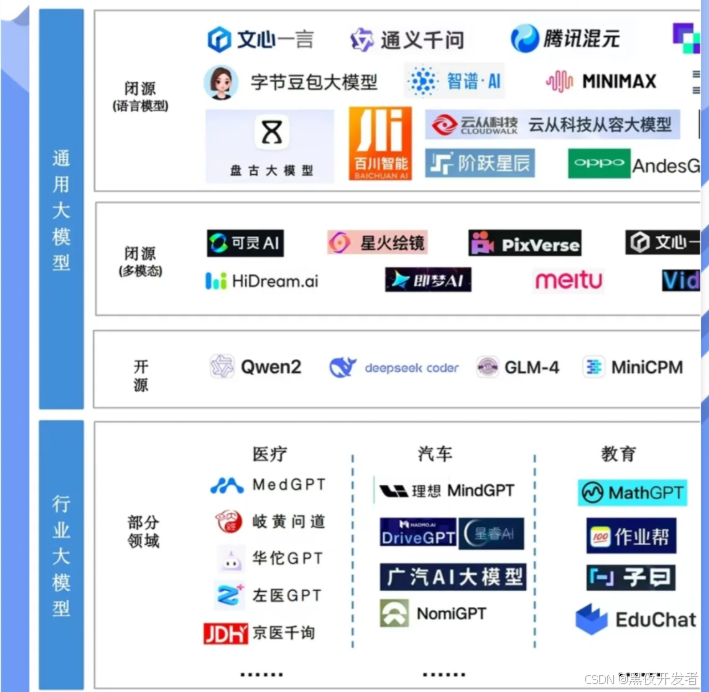
🚀二、版本谱系与定位
- 文心一言(ERNIE Bot/ERNIE 3.x/4.x):擅长中文知识问答、检索增强与行业方案
- 通义千问(Qwen/Qwen-Plus/Qwen-Max/Qwen-VL/Qwen2系列):覆盖多模态、工具调用与代码
- 讯飞星火(Spark/Spark Pro等):中文对话稳健,语音与办公生态结合紧密
定位建议:
- 泛中文内容与知识问答:文心/通义/星火均可,小样本评测为准
- 多模态/工具调用/代码:通义系列生态活跃、开源衍生多
- 语音场景:星火与讯飞生态整合便捷
🚀三、架构特点与中文能力
🔎3.1 中文语料与分词
- 大规模中文语料与高质量指令数据
- 更适配中文断句、诗词与成语、文化常识等
🔎3.2 对齐与拒绝策略
- 中文场景下的安全对齐与内容合规
- 对不当内容的拒绝与替代性建议
🔎3.3 多模态与工具生态
- 图片理解、OCR、表格解析(视具体版本)
- 搜索、数据库、办公套件与企业知识库集成
🚀四、API 快速上手
以下示例为典型调用思路(不同厂商SDK/接口参数略有差异),以伪代码/通用风格呈现,便于迁移。
🔎4.1 文心一言(Python 伪代码)
from ernie import ErnieClientclient = ErnieClient(api_key="<ERNIE_KEY>")
resp = client.chat(model="ernie-4.0", messages=[{"role":"user","content":"写一段100字中文营销文案"}])
print(resp.text)
🔎4.2 通义千问(Python 伪代码)
from qwen import QwenClientclient = QwenClient(api_key="<QWEN_KEY>")
resp = client.chat(model="qwen-max", messages=[{"role":"user","content":"将下文整理为要点列表:..."}])
print(resp.text)
🔎4.3 讯飞星火(Python 伪代码)
from spark import SparkClientclient = SparkClient(app_id="<APP>", api_key="<KEY>", api_secret="<SECRET>")
resp = client.chat(model="spark-pro", messages=[{"role":"user","content":"根据标题生成文章大纲:..."}])
print(resp.text)
🔎4.4 结构化JSON输出模板
prompt = ("请以JSON输出,字段: title, summary, bullets[string[]],中文回答。\n""主题: 制造业数字化转型的三大要点"
)
resp = client.chat(model=model_id, messages=[{"role":"user","content":prompt}])
data = json.loads(resp.text)
🚀五、RAG 与中文检索实务
🔎5.1 中文分词与检索
- 使用中文适配的分词器/向量模型(如 bge-zh 等)
- 保留文档层级结构与标题,避免语义切断
🔎5.2 拼接策略与模板
只基于下方材料回答;若材料无信息请回答“不知道”。
[文档1] ...
[文档2] ...
问题:...
请以要点列表回答,并标注来源文档编号。
🔎5.3 简易代码(伪)
index = build_zh_index(chunks) # 中文向量或BM25
top = index.search(q, k=5)
ctx = "\n".join([f"[DOC{i}] {t}" for i, t in enumerate(top)])
prompt = f"仅根据文档回答,必要时引用文档编号:\n{ctx}\n问题: {q}"
resp = client.chat(model=model_id, messages=[{"role":"user","content":prompt}])
🚀六、提示工程与中文表达

🔎6.1 常用模板
- 角色+任务+约束格式(中文输出、列点、字数上限)
- 引用来源要求(如[DOC1]、[DOC2])
- 允许“不知道”,降低幻觉
🔎6.2 场景化示例
- 政务/规范:要求引用条款并给出出处
- 金融/医疗:给出风险提示与免责声明
- 办公/写作:给出标题、摘要、提纲、段落与收尾
🚀七、成本、安全与合规
🔎7.1 成本优化
- Prompt模板化与上下文裁剪;缓存高频问答
- 批处理与流式输出结合;分层路由不同型号
🔎7.2 安全与合规
- 内容合规审查(涉政/涉医/金融等高敏领域)
- 审计日志与可追溯;数据最小化与脱敏
🚀八、应用案例
- 中文知识助手与客服、会议纪要与公文写作
- 政务/行业问答、表格/合同解析与审校
- 中文RAG检索+生成:政策/制度/标准库
🚀九、FAQ 与最佳实践
Q1:中文生成质量如何提升?
高质量中文语料的RAG增强;模板化输出;样本回放评测。
Q2:不同厂商如何切换?
使用统一网关与SDK抽象,路由到文心/通义/星火,按延迟/成本/效果动态选择。
Q3:合规如何保障?
引入敏感词/领域审查,保留审计日志,权限最小化与加密。
🔗参考资料
- 百度文心、阿里通义、讯飞星火官方文档
- 中文向量模型与检索工具(bge-zh、Elasticsearch、FAISS)
- 中文RAG与企业知识工程最佳实践
写在最后:中文大模型在本地化语料与行业实践上优势明显。结合RAG、提示工程与企业治理,可快速落地高质量中文智能应用。