Wend看源码-marker(RAG工程-PDF文件解析)
前言
在 RAG(检索增强生成)工程中,文件解析是连接原始文档与智能交互的关键环节。原始文档的解析质量直接影响后续检索的准确性和生成内容的相关性,而 PDF 作为学术研究、商业报告、技术文档等场景的主流格式,因其布局复杂性(包含文本、表格、公式、图片等混合元素),始终是解析环节的难点。
传统工具往往面临三大痛点:
-
一是格式丢失严重,表格错乱、公式失真等问题频发;
-
二是处理速度慢,大规模文档批量解析时效率低下;
-
三是多语言支持不足,难以应对跨语言场景。
经过多方向调研,我们最终选择 Marker 作为 PDF 解析工具 —— 这款开源项目在准确性、效率和扩展性上的综合表现,能够很好地解决 RAG 工程中的实际需求。
项目简介
Marker 是由 datalab-to 团队开发的开源文档转换工具,项目地址为:GitHub - datalab-to/marker: Convert PDF to markdown + JSON quickly with high accuracy。它专注于将各类文档高效、准确地转换为结构化格式,尤其在 PDF 解析场景中表现突出。
核心能力
Marker 的核心优势体现在对复杂文档的 “理解” 与 “转化” 能力上,具体包括:
-
多格式与多语言支持:不仅支持 PDF,还能处理图片、PPTX、DOCX、XLSX、HTML、EPUB 等文件,且对所有语言均有良好兼容性,覆盖多语种 RAG 场景。
-
精细格式保留:能精准处理表格、表单、公式(含内联数学表达式)、链接、参考文献、代码块等复杂元素,避免传统工具中常见的格式错乱问题。例如,学术论文中的多列布局、嵌套表格,均可被正确识别并转换。
-
冗余内容净化:自动去除页眉、页脚、水印等冗余信息,聚焦核心内容,减少后续检索时的噪音干扰。
-
增强功能扩展
-
支持图片提取与保存,便于后续多模态 RAG 应用;
-
提供结构化提取能力(beta 版),可基于 JSON schema 定制提取规则;
-
可选 LLM 增强模式,通过自定义提示词进一步提升转换准确性,适配复杂场景。
-
-
跨硬件适配:可在 GPU、CPU 或 MPS(Apple 芯片)上运行,灵活应对不同部署环境,从个人开发者的本地设备到企业级服务器均能适配。
性能表现
Marker 在速度与准确性上的平衡尤为亮眼,其基准测试数据显示:
-
速度优势:单页 PDF 串行处理平均耗时仅 2.84 秒,远快于 Llamaparse(23.35 秒)和 Mathpix(6.36 秒);批量模式下,在 H100 显卡上吞吐量可达 25 页 / 秒,适合大规模文档处理。
-
准确性领先:在包含科学论文、法律文档、报纸页面等多类型文档的测试集中,Marker 的 heuristic 评分(文本对齐 heuristic)达 95.67 分,显著高于同类工具(Llamaparse 为 84.24 分,Docling 为 86.71 分);LLM 评分(由大模型作为裁判)达 4.24 分(5 分制),在复杂格式处理上表现更优。
细分场景中,Marker 在科学论文解析(heuristic 评分 96.67 分)、报纸页面(98.87 分)、法律文档(96.69 分)等场景中优势明显,尤其适合学术 RAG、法律智能等专业领域。
项目架构
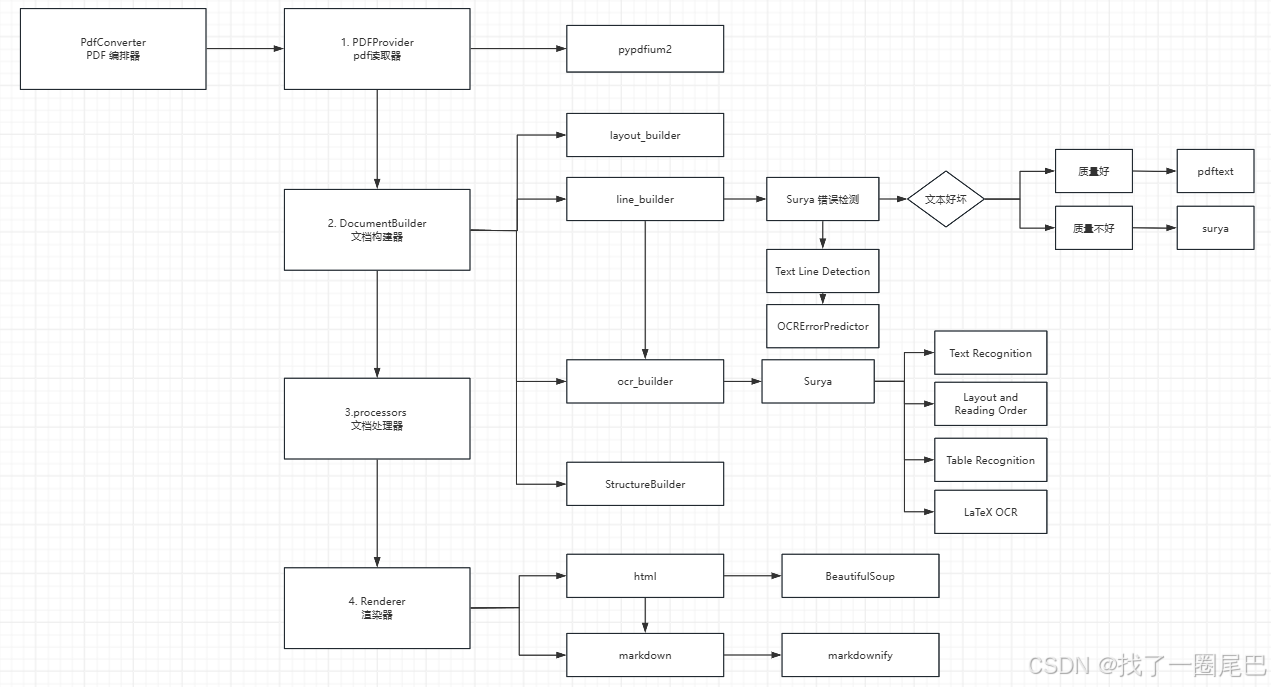
marker-pdf 处理流程图
如上图marker-pdf 处理流程图所述,在 Marker 处理 PDF 文件的流程中,核心逻辑由PdfConverter(PDF 转换器) 统筹调度,通过 “提取 - 构建 - 渲染” 三个核心阶段完成从原始 PDF 到目标格式(默认 Markdown)的转换。每个阶段由特定组件分工协作,具体流程如下:
一、PDF 提取阶段:原始内容解析与采集
该阶段由PdfConverter触发PdfProvider(PDF 提取器) 完成,核心目标是从 PDF 中提取原始文本、图像、布局坐标等基础信息,为后续处理提供数据基础。
-
PdfProvider 的核心操作:
-
基于
pypdfium2工具加载 PDF 文件,解析文件元数据(如页数、页面尺寸、字体信息等),并根据配置的page_range确定需要处理的页面范围。 -
针对可复制文本的 PDF:直接提取文本内容及对应坐标(通过
pdftext库实现),同时记录文本的字体属性(如粗体、斜体、字号)、行间距等格式信息,以及超链接、注释等附加数据。 -
针对扫描件或文本模糊的 PDF:若配置
force_ocr=True,则触发图像提取逻辑,将页面渲染为高分辨率图像(默认 192 DPI),为后续 OCR 做准备。 -
输出:生成包含 “页面 ID - 文本块 - 坐标 - 格式” 映射关系的原始数据,传递给文档构建阶段。
-
二、文档构建阶段:结构化解析与内容优化
DocumentBuilder(文档构建器) 接收 PdfProvider 的原始数据后,协调多个子构建器完成从 “原始内容” 到 “结构化文档” 的转换,核心是解决 “布局理解”“文本准确性”“内容关联性” 三大问题。
1. 布局构建(layout_builder)
-
基于Surya深度学习模型(专注文档布局分析),对页面图像进行布局检测,识别出段落、表格、公式、图片、页眉页脚等核心元素的边界框(BBox),并标记其类型(如
BlockTypes.TableBlockTypes.Equation)。 -
同时确定元素的空间位置关系(如 “表格位于段落下方”“公式嵌入文本中”),为后续阅读顺序排序提供依据。
2. 文本行构建(line_builder)
-
针对 PdfProvider 提取的文本块,按布局坐标拆分出独立的文本行(
BlockTypes.Line),并整合同一段落内的连续文本行。 -
触发Surya 错误检测流程:
-
先通过
Text Line Detection模型校验文本行的完整性(如是否存在断裂、重叠); -
再通过
OCRErrorPredictor预测文本质量(基于字符清晰度、语言连贯性等指标),生成 “文本质量评分”。
-
-
分支处理逻辑:
-
若文本质量良好(评分高于阈值):直接采用
pdftext提取的文本,保留原始格式(如字体、超链接); -
若文本质量较差(如模糊、残缺):标记为 “待 OCR 修复”,传递给
ocr_builder处理。
-
3. OCR 构建(ocr_builder)
-
针对
line_builder标记的低质量文本或扫描件图像,调用Surya模型完成精细化 OCR 处理,核心任务包括:-
Text Recognition:识别模糊文本或图像中的字符,生成可编辑文本;
-
Layout and Reading Order:校正文本行的顺序(如多列布局中从左到右、从上到下的阅读逻辑);
-
Table Recognition:识别表格的单元格边界、合并单元格关系,生成结构化表格数据;
-
LaTeX OCR:对公式(尤其是手写或复杂公式)进行识别,转换为 LaTeX 格式(如将 “x²+y²=1” 识别为
$x^2 + y^2 = 1$)。
-
-
输出:将 OCR 修复后的文本与原始布局坐标关联,更新到文本行数据中。
4. 结构构建(StructureBuilder)
-
整合上述构建器的输出,按 “文档 - 页面 - 块 - 行 - 跨度” 层级(
Document -> PageGroup -> Block -> Line -> Span)组织内容:-
确定块级元素的阅读顺序(如先标题、再段落、后表格);
-
关联跨页元素(如页眉页脚的统一去除、分页表格的合并);
-
标记冗余内容(如重复的页眉页脚),为后续处理器(如
PageHeaderProcessor)提供清理依据。
-
三、处理器阶段:结构化内容优化与修正
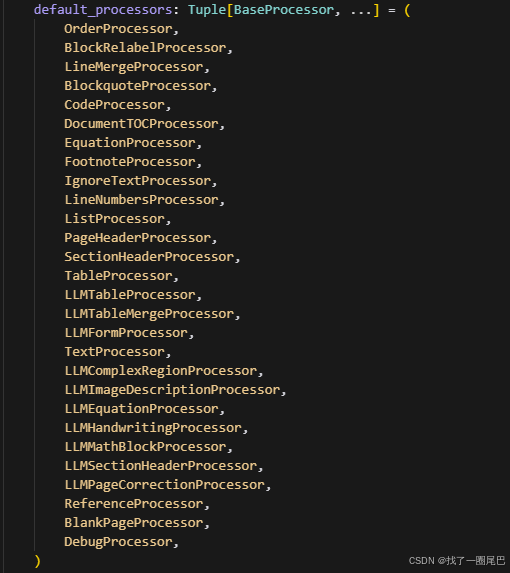
文档构建完成后,渲染器开始遍历执行文档处理器,大量的文档处理器会对结构化文档再进行精细化处理,解决格式细节、跨元素关联等问题,提升内容准确性。
核心处理器及功能:
-
基础格式处理器:如
LineMergeProcessor(合并连续文本行)、ListProcessor(识别有序 / 无序列表)、CodeProcessor(标记代码块),修复基础格式错误。 -
专项内容处理器:如
TableProcessor(优化表格结构)、EquationProcessor(校正公式格式)、FootnoteProcessor(提取脚注并关联正文)。 -
LLM 增强处理器:如
LLMTableMergeProcessor(合并跨页表格)、LLMEquationProcessor(优化复杂公式)、LLMPageCorrectionProcessor(修正页面级格式错误),通过 LLM 提升复杂内容处理精度。 -
冗余清理处理器:如
PageHeaderProcessor(去除重复页眉页脚)、BlankPageProcessor(删除空白页),精简内容。
输出:经过格式优化、冗余清理、跨元素关联的结构化文档,为渲染阶段做准备。
四、渲染输出阶段:结构化内容转目标格式
经过文档构建后,Renderer(渲染器) 将结构化文档转换为用户指定的格式(默认 Markdown,支持 JSON、HTML 等),核心是保证格式还原的准确性。
-
Markdown 渲染流程:
-
调用
MarkdownRenderer遍历结构化文档的块级元素,按类型适配 Markdown 语法:-
表格:转换为 Markdown 表格格式(支持合并单元格标注);
-
公式:保留 LaTeX 格式(包裹
$或$$); -
代码块:添加 ``` 标记;
-
图片:提取图像文件路径,生成
语法。
-
-
对于复杂格式(如嵌套列表、引用块),先通过
BeautifulSoup转换为中间 HTML 格式,再借助markdownify工具转换为标准 Markdown,确保层级关系正确。 -
最终输出:包含完整文本、格式标记、图像路径的 Markdown 文件,同时附带元数据(如处理时间、页面数量)。
-
整个流程通过 “按需调用模型”(如仅对低质量文本启用 OCR)平衡效率与准确性,且各阶段组件(如Processors Renderers)支持自定义扩展,可适配不同场景的格式需求。
核心模块详解
providers
尽管 Marker 宣称支持多种文件格式,但其核心解析引擎是针对 PDF 格式深度优化的。对于其他格式(如 DOCX, PPTX, XLSX, HTML, EPUB),Marker 均采用统一的预处理策略:先将其转换为 PDF,再交由核心的 PDF 处理管道进行解析。
以下是各类文件的核心处理流程概览:
| 文件格式 | 核心处理流程 |
|---|---|
| PDF (核心) | 直接处理。使用 |
| DOCX | DOCX → ( |
| PPTX | PPTX → ( |
| XLSX | XLSX → ( |
| HTML/EPUB | HTML/EPUB → (提取样式和图片) → HTML → ( |
| 图片 (JPG等) | 被视为单页PDF进行处理。 |
Marker 是处理 PDF 文件的顶级工具。但对于其他格式,如果您需要速度更快,精度更高的解析,建议优先考虑使用其原生库或更专业的转换工具进行处理,而非依赖 Marker 的间接转换流程。
processors
| 处理器类型 | 处理器名称 | 核心功能描述 |
|---|---|---|
| 基础文本与结构处理 | blank_page | 检测并过滤空白页面或无实质内容的文本块。 |
line_merge | 合并因PDF解析错误而断裂的文本行(尤其在启用LLM时生效)。 | |
line_numbers | 识别并移除文档页边或段落中的行号噪声。 | |
text | 处理跨页、跨栏的文本连续性,合并被断开的单词和段落。 | |
order | 调整页面内文本块的顺序,使其更符合人类的自然阅读流。 | |
| 语义块识别与标注 | block_relabel | 根据上下文启发式规则,为文本块重新分配更准确的类型标签(如正文、标题)。 |
sectionheader | 识别章节标题并规范化其层级结构(如H1, H2)。 | |
list | 识别列表项,并根据缩进等信息构建嵌套的层级化列表结构。 | |
blockquote | 识别并整理引用块的范围和格式。 | |
code | 识别并格式化代码块和行内代码片段。 | |
footnote | 识别脚注,并将其与正文中的引用关联起来。 | |
reference | 识别和规范化参考文献条目及其链接。 | |
| 复杂元素处理 | table | 核心处理器:解析表格布局,重建单元格结构(处理合并单元格、修正边框)。 |
equation | 识别并合并数学公式(块级与行内),并将其规范化为标准格式(如LaTeX)。 | |
| 内容清理与过滤 | ignoretext | 根据预定义规则过滤掉无用的文本,如水印、页眉页脚重复内容、噪声等。 |
page_header | 专门识别页眉区域,并将其与正文内容分离。 | |
| 文档级结构处理 | document_toc | 生成或整理整个文档的目录(Table of Contents)结构。 |
| AI增强处理 (LLM) | llm_meta | 调度器:将多个简单的处理任务打包,并发调用LLM服务进行处理。 |
llm_page_correction | 以整页图像和文本为上下文,进行页面级的全面纠错与内容重写。 | |
llm_table | 增强表格处理:将表格截图发送给LLM进行校对和重建,输出更精确的HTML表格。 | |
llm_table_merge | 处理复杂表格的合并与单元格跨度修正。 | |
llm_sectionheader | 使用LLM识别和校正章节标题及其层级,提高准确性。 | |
llm_equation | 使用LLM清洗和规范化数学公式的文本与标记。 | |
llm_mathblock | 多模态处理,识别和转写数学公式块。 | |
llm_image_description | 为图片区域生成描述性文本(alt text或caption)。 | |
llm_handwriting | 多模态识别和转写手写体文字。 | |
llm_form | 识别并结构化表单字段及其内容。 | |
llm_complex | 处理其他复杂区域的解析与重写。 | |
| 辅助与工具 | debug | 输出调试信息或可视化标记,用于开发和分析中间结果。 |
util | 为所有处理器提供共享的工具函数和辅助逻辑。 |
-
模块化设计:Marker 的处理流程由大量高度专业化的处理器组成,每个处理器负责一个具体的任务(如处理表格、列表、公式等),这种设计使得代码清晰且易于扩展。
-
处理阶段:处理器按顺序执行,先进行基于规则的基础处理(如合并文本行、过滤噪声),再进行复杂的结构识别(如表格、公式),最后可选地调用LLM进行增强校正。
-
AI增强可选性:所有以
llm_开头的处理器都是可选的。用户可以根据对质量和成本的需求,选择是否启用LLM来提升处理难度较高内容的准确性。 -
核心优势:这种处理器流水线式的架构是 Marker 能够高质量、高保真地从PDF中提取结构化信息的关键原因。
参数配置
一、全局设置(Global Settings)
| 参数名称 | 默认值 | 说明 |
|---|---|---|
| OUTPUT_DIR | BASE_DIR/conversion_results | 转换结果的输出目录,默认位于项目根目录下。 |
| FONT_PATH | .../static/fonts/GoNotoCurrent-Regular.ttf | 用于 OCR 和文本处理的字体路径,影响文本渲染和识别精度。 |
| LOGLEVEL | INFO | 日志输出级别(可选DEBUG/INFO/WARNING等),DEBUG可开启详细日志。 |
| GOOGLE_API_KEY | 空字符串 | 启用 LLM 功能(如 Gemini)必需的 API 密钥,未设置则 LLM 功能不可用。 |
| TORCH_DEVICE | None(自动选择) | 强制指定计算设备(cuda/mps/cpu),默认自动根据硬件适配。 |
二、转换流程核心控制(Converter - converters/pdf.py)
| 参数名称 | 默认值 | 说明 |
|---|---|---|
| use_llm | False | 总开关:是否启用 LLM 增强处理器提升质量(会增加耗时和成本)。 |
| renderer | MarkdownRenderer | 输出渲染器类型,可选HTMLRenderer/JSONRenderer等。 |
| processor_list | 内置列表 | 后处理处理器链,可自定义指定需运行的处理器(如表格 / 公式处理)。 |
三、PDF 解析配置(Provider - providers/pdf.py)
| 参数名称 | 默认值 | 说明 |
|---|---|---|
| page_range | None | 处理的页码范围(如[0,5]处理前 5 页),默认处理全部页面。 |
| force_ocr | False | 忽略 PDF 内置文本,强制对所有页面进行 OCR(适合乱码或低质量文本)。 |
| flatten_pdf | True | 将表单等动态元素 “扁平化” 为静态内容,推荐开启以保证解析完整性。 |
| ocr_space_threshold | 0.7 | 空白字符占比阈值,超过则触发 OCR(判定为低质量文本)。 |
| ocr_newline_threshold | 0.6 | 换行符占比阈值,超过则触发 OCR(判定为低质量文本)。 |
| image_threshold | 0.65 | 页面被图片覆盖的面积阈值,超过则标记为 “可能无文本”。 |
四、文档构建与 OCR 配置(Builder)
| 参数名称 | 默认值(按设备) | 说明 |
|---|---|---|
| lowres_image_dpi | 96 | 用于布局分析和行检测的图像 DPI,值越低处理越快,精度可能下降。 |
| highres_image_dpi | 192 | 用于 OCR 识别的图像 DPI,值越高 OCR 精度越高,处理越慢。 |
| disable_ocr | False | 完全禁用 OCR,仅使用 PDF 中嵌入的文本(适合高质量数字 PDF)。 |
| layout_batch_size | cpu:6, cuda:12(默认自动) | 布局分析模型的批次大小,影响 GPU 内存使用和处理速度。 |
| detection_batch_size | cpu:4, cuda:10(默认自动) | 行检测模型的批次大小,影响处理效率和内存占用。 |
| recognition_batch_size | cpu:32, mps:16, cuda:64(默认自动) | OCR 识别模型的批次大小,平衡识别速度和内存使用。 |
| table_rec_batch_size | cpu:8, cuda:32(默认自动) | 表格识别模型的批次大小,影响表格提取效率。 |
| ocr_error_batch_size | cpu:4, cuda:14(默认自动) | OCR 质量检测模型的批次大小,用于判定文本是否需要重新 OCR。 |
五、LLM 服务配置(Service - services/google.py)
| 参数名称 | 默认值 | 说明(仅在use_llm=True时生效) |
|---|---|---|
| gemini_model_name | gemini-2.0-flash | 指定使用的 Google Gemini 模型,可改为gemini-2.0-pro提升质量(成本更高)。 |
| timeout | 30 | LLM API 调用超时时间(秒)。 |
| max_retries | 2 | API 调用失败后的重试次数。 |
六、CLI 默认配置(marker-convert-cli)
| 参数名称 | 默认值 | 说明 |
|---|---|---|
| detector_postprocessing_cpu_workers | 2 | 行检测后处理的 CPU 线程数。 |
| NUM_DEVICES | 1 | 使用的设备数量(多 GPU 场景)。 |
| NUM_WORKERS | 1 | 并发处理的工作进程数。 |
-
性能调优:优先调整
*_batch_size(批次大小)、*_dpi(图像分辨率)和TORCH_DEVICE(计算设备),平衡速度与内存占用。 -
质量调优:学术文献可开启
use_llm=True并提高highres_image_dpi(如 300),提升公式和表格识别质量。 -
成本控制:
use_llm是主要成本因素,非必要时保持False;启用时需确保GOOGLE_API_KEY有效。 -
问题排查:设置
LOGLEVEL=DEBUG,查看DEBUG_DATA_FOLDER中的中间结果图分析解析问题。
性能调优
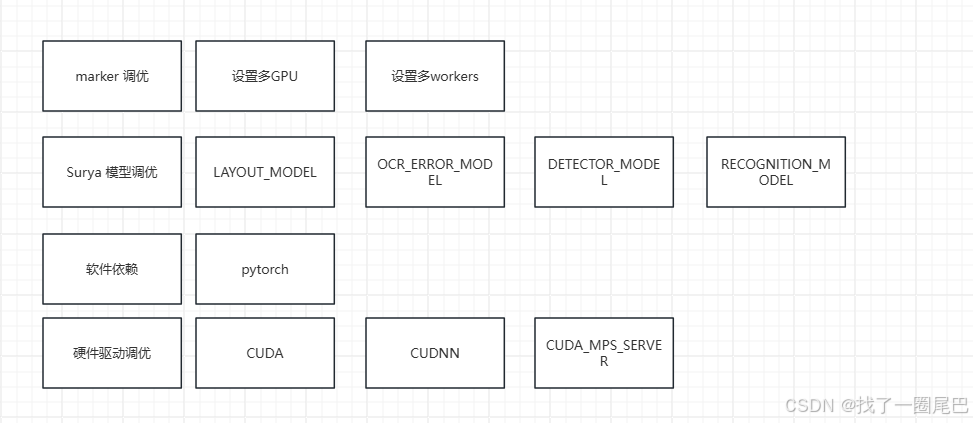
1. 计算资源配置优化
-
多 GPU 利用:通过 “设置多 GPU” 模块,采用数据并行或模型并行的方式,将 marker 的计算任务分配到多个 GPU 上,利用并行计算能力提升处理速度(尤其适用于大规模数据或复杂任务场景)。
-
workers 参数调优:合理设置 “workers”(数据加载工作进程数),平衡 CPU 数据预处理与 GPU 计算的效率。过多的 workers 可能导致内存占用过高,过少则可能使 GPU 处于等待数据的空闲状态,需根据硬件配置(CPU 核心数、内存大小)调整至最优值。
-
具体多并发处理方式可以参考marker 中chunk_convert.sh 的配置。
2. 关联模型调优
marker 的性能依赖于多个下游模型的协同工作,需针对图片中提及的关键模型进行优化:
-
基础模型调优:对 “Surya 模型”“LAYOUT_MODEL”“DETECTOR_MODEL”“RECOGNITION_MODEL” 等核心模型,可通过调整网络结构(如轻量化 backbone)、优化训练策略(如学习率调度、正则化参数)、采用知识蒸馏等方式,在保证精度的前提下提升推理速度。
-
专项模型优化:针对 “OCR_ERROR_MODEL”(OCR 错误处理模型)和 “TABLE_REC_MODEL”(表格识别模型),可优化其错误修正逻辑和特征提取流程,减少冗余计算,提升特定任务的处理效率。
-
关于模型的调优,我们可以做的更多的是关于模型参数的调优,具体模型的参数配置可以参考:GitHub - datalab-to/surya: OCR, layout analysis, reading order, table recognition in 90+ languages
3. 软件依赖配置优化
-
PyTorch 框架调优:作为核心 “软件依赖”,可通过启用 PyTorch 的混合精度训练(AMP)、调整批处理大小(batch size)、启用 cuDNN 加速等方式,减少计算开销并提升内存利用率。
-
依赖版本适配:确保 PyTorch 与其他依赖库(如 torchvision、numpy)的版本兼容性,避免因版本冲突导致的性能损耗或功能异常。
-
在实际的POC 的过程中,我将torch 版本换成了与我的cuda相匹配的版本,而linux 环境中,如果您使用docker 去配置marker ,也需要注意torch 版本与cuda,surya 版本的适配问题。
-

4. 硬件驱动与底层优化
-
GPU 驱动与库适配:通过 “硬件驱动调优” 模块,确保 CUDA(GPU 计算框架)、cuDNN(深度神经网络加速库)的版本与 PyTorch 及 GPU 型号匹配,充分发挥硬件算力。
-
CUDA MPS 配置:利用 “CUDA_MPS_SERVER”(多进程服务),在多任务共享 GPU 时优化资源分配,减少进程间的调度开销,提升 marker 在多实例场景下的整体性能。
参考文献
GitHub - datalab-to/surya: OCR, layout analysis, reading order, table recognition in 90+ languages