Spark内存管理
文章目录
- 1.Spark内存消耗来源
- 2.Spark内存管理模型
- 2.1 数据缓存空间、框架执行空间以及用户代码空间
- 2.2 Executor空间划分
- 2.2.1 JVM堆内内存
- 2.2.2 JVM堆外内存
- 3.Spark框架执行内存消耗
- 3.1 内存共享与竞争
- 3.2 Shuffle Write
- 3.2.1 ShuffleWrite分类
- 3.2.2 无聚合,无排序,且分区数<=200
- 3.2.3 无聚合,无排序,分区数>200
- 3.2.3.1 分页的策略和优点
- 3.2.3.2 Serialized Shuffle使用条件
- 3.2.3.3 实现细节
- 3.2.3.4 内存消耗
- 3.2.4 不需要聚合,需要排序
- 3.2.5 需要聚合,需要/不需要排序
- 3.3 Shuffle Read
- 3.3.1 ShuffleRead分类
- 3.3.2 无聚合,无排序
- 3.3.3 无聚合,需要排序
- 3.3.4 有聚合
- 4.数据缓存空间
- 4.1 RDD缓存
- 4.1.1 MEMORY_ONLY/MEMROY_AND_DISK
- 4.1.2 MEMORY_ONLY_SER/MEMORY_AND_DISK_SER
- 4.1.3 off-heap
- 4.2 广播数据
- 4.3 task计算结果
1.Spark内存消耗来源
- 用户代码:比如在map操作中定义数组,字典等。
- 框架:比如Shuffle阶段进行聚合排序的时候需要用到的数据结构。再比如不同rdd传输时产生的临时存储,比如record1->record1’之后将record1删除。
- 缓存数据
2.Spark内存管理模型
2.1 数据缓存空间、框架执行空间以及用户代码空间
为了能够平衡用户代码、Shuffle机制中的中间数据,以及数据缓存的内存空间需求,最理想的方法是为三者分配一定的内存配额,并且在运行时根据三者的实际内存用量,动态调整配额比例。Spark将内存划分为三个区域:数据缓存空间、框架执行空间以及用户代码空间。
Framework memory:数据缓存空间和框架执行空间共享了一个大空间,称为Framework memory。Framework memory大小固定,且为数据缓存空间和框架执行空间设置了初始比例,但这个比例可以在应用执行过程中动态调整。
2.2 Executor空间划分
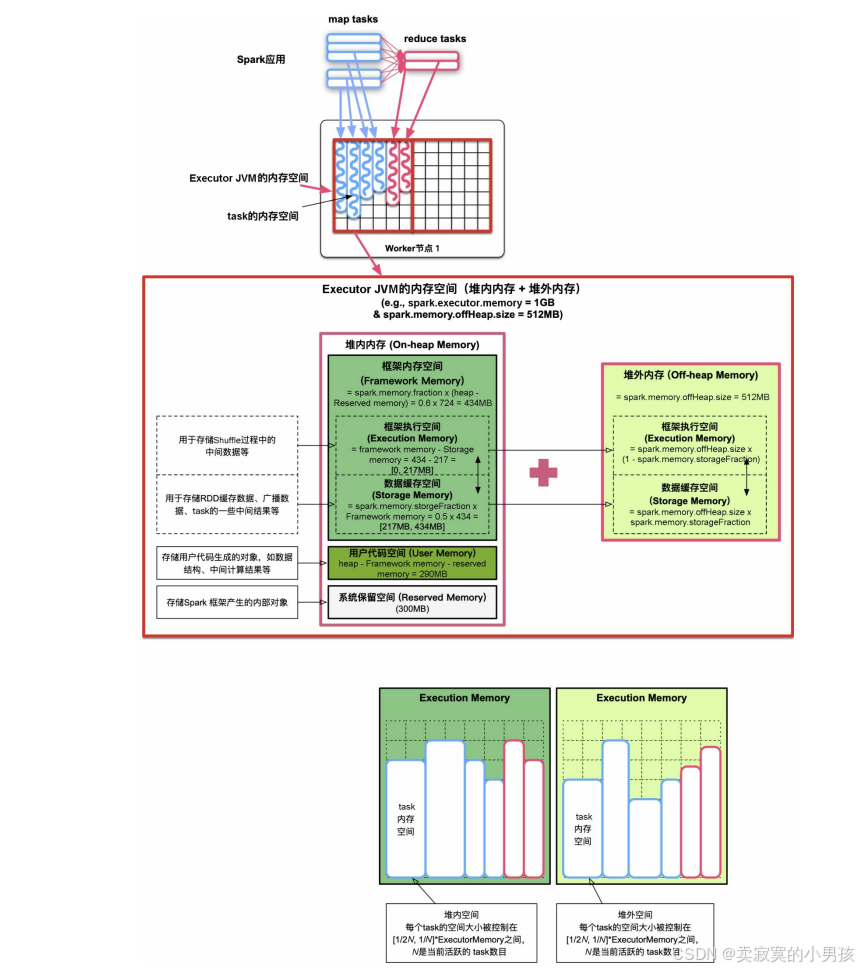
2.2.1 JVM堆内内存
Reserved Memory:spark.testing.ReservedMemory默认设置为300MB。系统保留内存使用较小的空间存储Spark框架产生的内部对象(如Spark Executor对象,TaskMemoryManager对象等Spark内部对象)。
UserMemory:默认约为40%的内存空间,用于存储用户代码生成的对象。
Framework Memory:包括框架执行空间(Execution Memory)和数据缓存空间(Storage Memory)。spark.memory.fraction总大小默认设为60%的内存空间。当数据缓存空间不足时,可以借用框架执行空间,后续框架执行空间不足时,需要归还该空间。当框架执行空间不足时,可以向数据缓存空间借用空间,但至少要保证数据缓存空间(spark.memory.storageFraction)具有Framework Memory的50%左右,在框架执行时借走的空间不会归还给数据缓存空间,原因是难以代码实现。
2.2.2 JVM堆外内存
- 为了减少垃圾回收(GC)开销,Spark的统一内存管理机制也允许使用堆外内存。堆外内存类似使用C/C++语言分配的malloc空间,该空间不受JVM垃圾回收机制管理,在结束使用时需要手动释放空间。
- 因为堆外内存主要存储序列化对象数据,而用户代码处理的是普通Java对象,因此堆外内存只用于框架执行空间和数据缓存空间,而不用于用户代码空间。
- 如图,堆外内存大小使用过spark.memory.offHeap.size设置,Spark仍然会按照堆内内存使用的spark.memory.storageFraction比例将堆外内存分为框架执行空间和数据缓存空间,而且堆外内存的管理方式和功能与堆内内存的Framework Memory一样。
- 在运行应用时,Spark会根据应用的Shuffle方式及用户设定的数据缓存级别来决定使用堆内内存还是堆外内存,如后面介绍SerializedShuffle方式可以利用堆外内存来进行Shuffle Write,再如用户使用rdd.persist(OFF_HEAP)后可以将rdd存储到堆外内存。
3.Spark框架执行内存消耗
3.1 内存共享与竞争
- 一个Executor中存在多个task,假设一个Executor申请了cpu_nums个cpu,那么Executor中活跃的task数目就在[0, cpu_nums]之间。
- 为了公平性,每个task所使用的空间被均分,一个task的空间大小被控制在[1/2N, 1/N]内,N为当前活跃的task数。
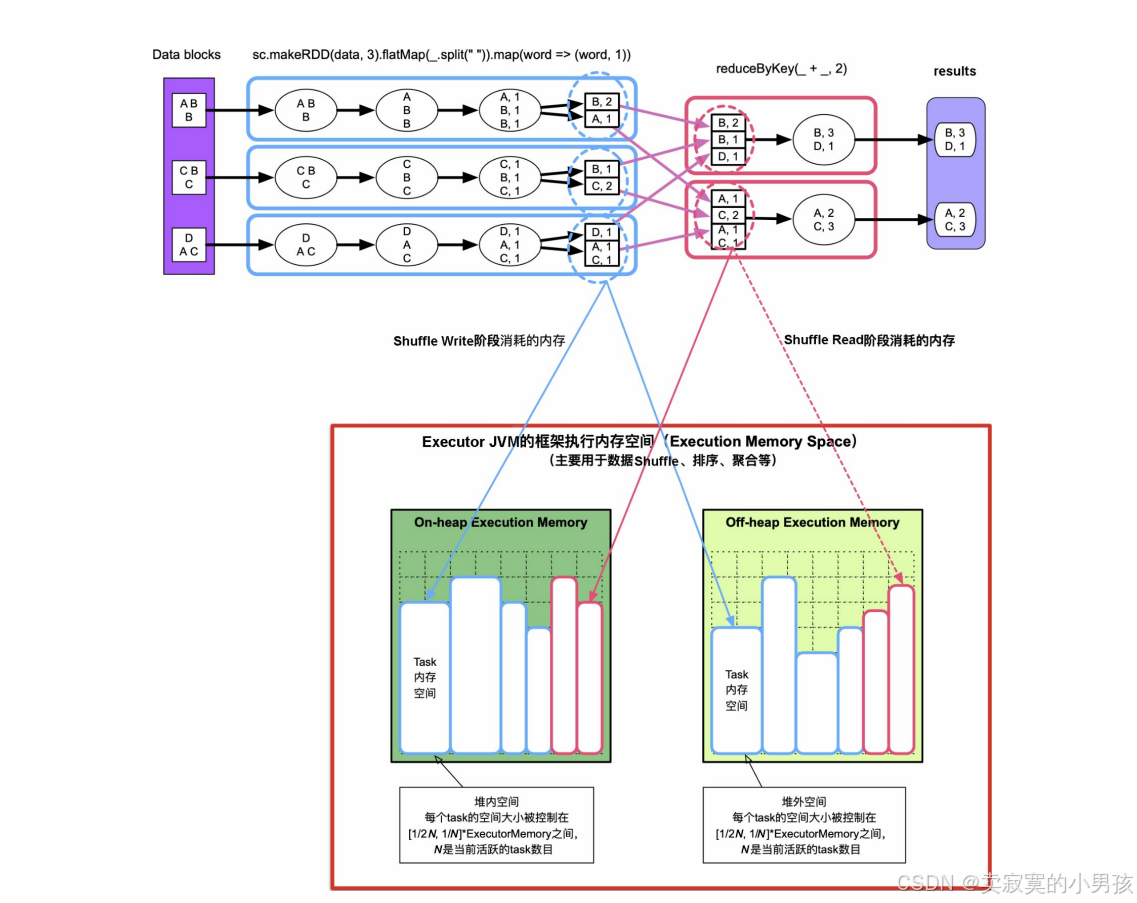
3.2 Shuffle Write
3.2.1 ShuffleWrite分类
- BypassMergeSortShuffle-Writer:无聚合,无排序,partition数不超过200。
- Serialized ShuffleWriter:无聚合,无排序,partition数大于200。
- SortShuffleWriter(KeyOrdering=true):无聚合,要排序。基于数组。
- SortShuffleWriter(mapSideCombine=true):有聚合。基于哈希表。
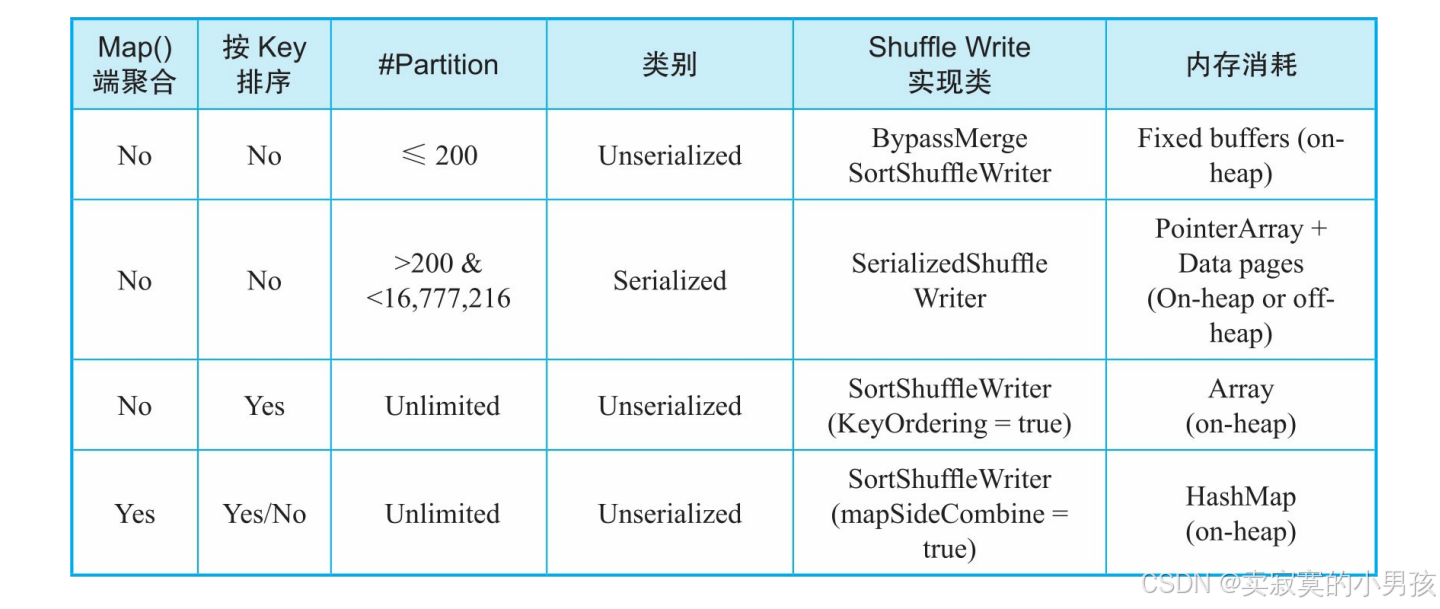
其中1,3,4都是使用堆内内存来聚合,排序record对象的,属于Unserialized Shuffle方式。这种方式处理的record为普通的Java对象,有较大的内存开销,也会造成较大的JVM垃圾回收开销。
Seriralized Shuffle处理序列化之后的数据,原理是直接在内存中操作序列化之后的对象,在ShuffleWrite中只用于无map端聚合,无排序,partition大于200的情况中。
3.2.2 无聚合,无排序,且分区数<=200
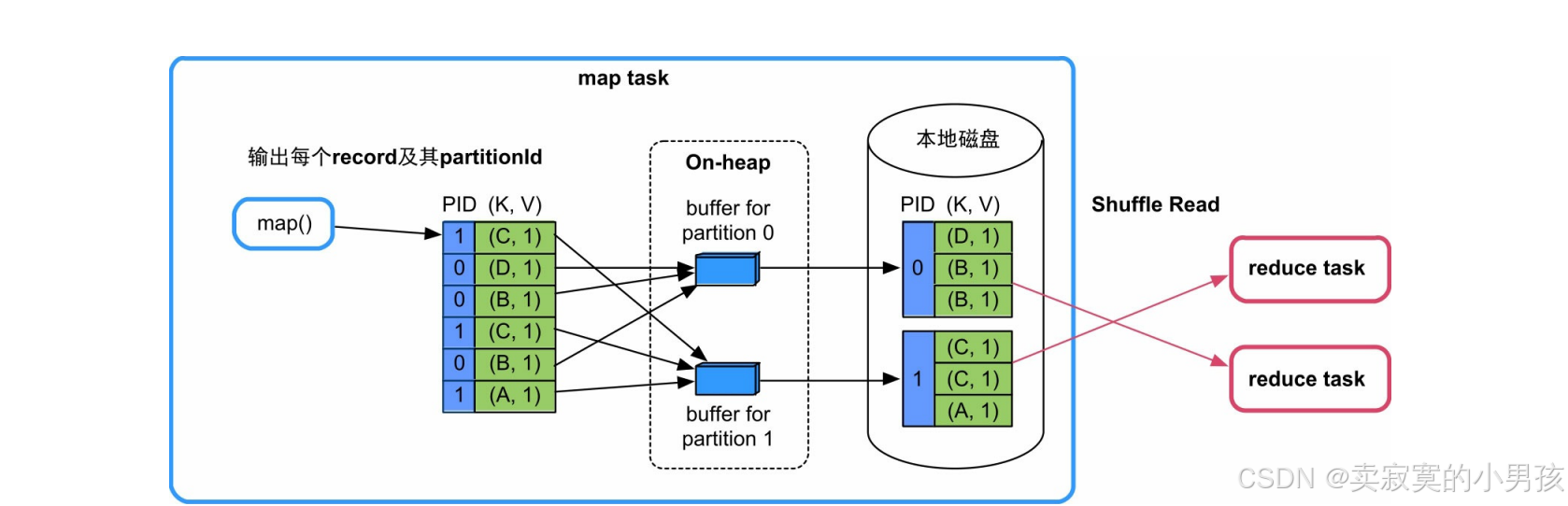
每个task内存消耗为,BufferSize(默认32KB)*partition number。
3.2.3 无聚合,无排序,分区数>200
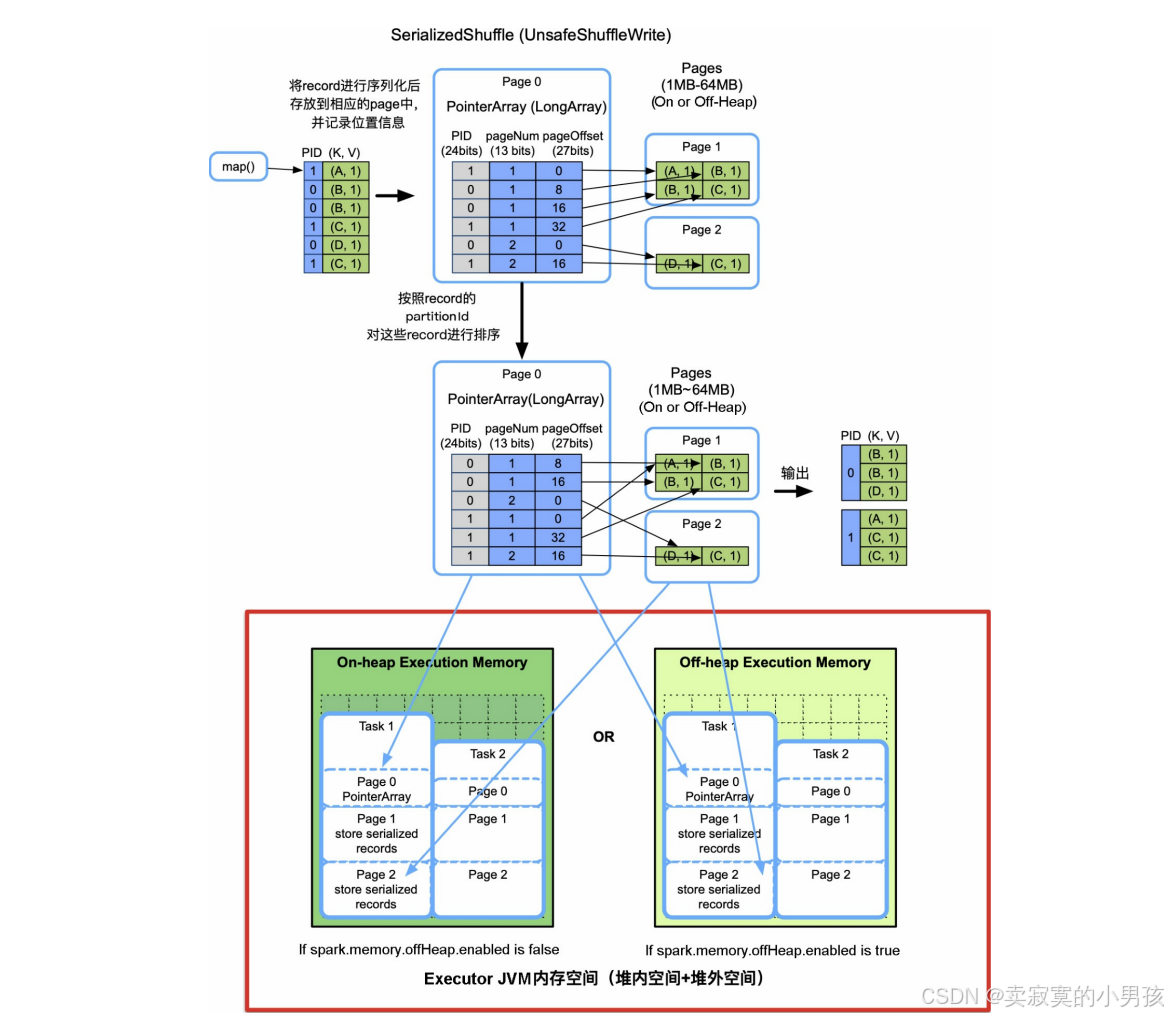
当分区数量大于200时,不再为每个分区分配一个buffer,而是将计算出的KV放到一个大数组中,将数组中的record根据partitionId进行排序,然后输出即可。然后record是一个java对象,占用空间较大,并且会频繁GC。SerializedShuffle将对象序列化后放到可分页存储的数组中,序列化可以减少存储开销,分页可以利用碎片内存。
3.2.3.1 分页的策略和优点
分页的策略和优点包括:
- 序列化后的record占用的内存空间小。
- 不需要连续的内存空间。
- 排序效率高。对序列化后的record按partitionId进行排序时,排序的不是record本身,而是record序列化后字节数组的指针(元数据)。由于直接基于二进制数据进行操作,所以在这里面没有序列化和反序列化的过程,内存和GC开销降低。
- 可以使用cache-efficient sort等优化技术,提高排序性能。
- 可以使用堆外内存,分页也可以方便统一管理堆内内存和堆外内存。
3.2.3.2 Serialized Shuffle使用条件
- 无聚合和排序操作。
- 使用的序列化类(serializer)支持序列化Value的位置互换功能(relocation of serialized Value),目前KryoSerializer和Spark SQL的custom serializers都支持该功能。
- 分区个数小于16 777 216。
- 单个Serialized record小于128MB。
3.2.3.3 实现细节
过Serliazed Shuffle采用了分页技术,像操作系统一样将内存空间划分为Page,每个Page大小在1MB~64MB,既可以在堆内内存上分配,也可以在堆外内存上分配。Page由Executor中的TaskMemoryManager对象来管理,TaskMemoryManager包含一个PageTable,可以最多寻址8192个Page。
如上图:
spark将输出的每个record进行序列化并放在申请的某一个page中,然后将该record的partitionId,所在的PageNum,以及Page中的offset放到PointerArray中,然后通过partitionId进行排序。当所有page的总大小超过了task的内存界限时,会将Page中的record按partition进行排序并spill到磁盘上。最后进行归并即可。
更具体的细节:
- 对于新来的一个record,首先将其序列化后存到一个serBuffer中(1MB),然后将serBuffer中序列化的record放到ShuffleExternalSorter的Page中进行排序。
- 插入和排序方法是,首先分配一个LongArray来保存record的指针,指针为64位,前24位存储record的partitionId,中间13位存储record所在的Page Num,后27位存储record在该Page中的偏移量。也就是说LongArray最多可以管理2 (13+27)=8192×128MB=1TB的内存。
- 随着record不断地插入Page中,如果LongArray不够用或Page不够用,则会通过allocatePage()向TaskMemoryManager申请,如果申请不到,就启动spill()程序,将中间结果spill到磁盘上。
- 最后再由UnsafeShuffleWriter进行统一的merge。Page由TaskMemoryManager管理和分配,可以存放在堆内内存或者堆外内存。
3.2.3.4 内存消耗
PointerArray、存储record的Page、sort算法所需的额外空间,总大小不超过task的内存限制。需要注意的是,单个数据结构(如PointerArray、serialized record)不能同时使用堆内内存和堆外内存,因此Serialized Shuffle使用堆外内存最大的问题是,在Shuffle Write时不能同时利用堆内内存和堆外内存,可能会造成更多的spill次数。
3.2.4 不需要聚合,需要排序
建立一个Array,根据partition+key进行排序。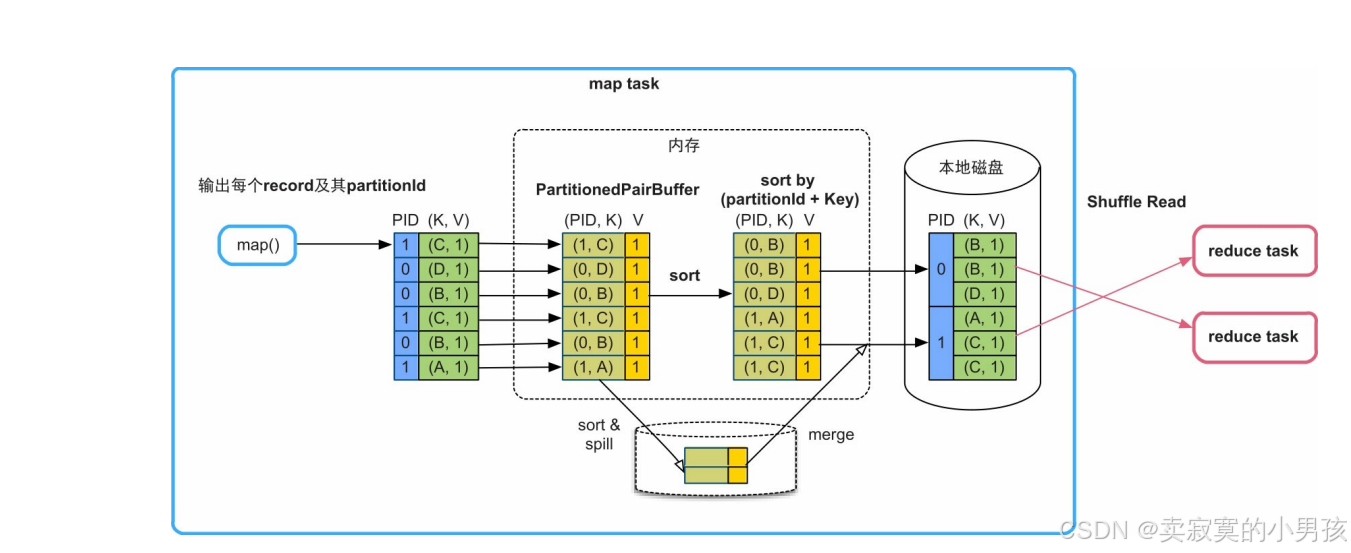
最大的内存消耗是存储record的数组PartitionedPairBuffer,占用堆内内存,具有扩容能力,但大小不超过task的内存限制。
3.2.5 需要聚合,需要/不需要排序
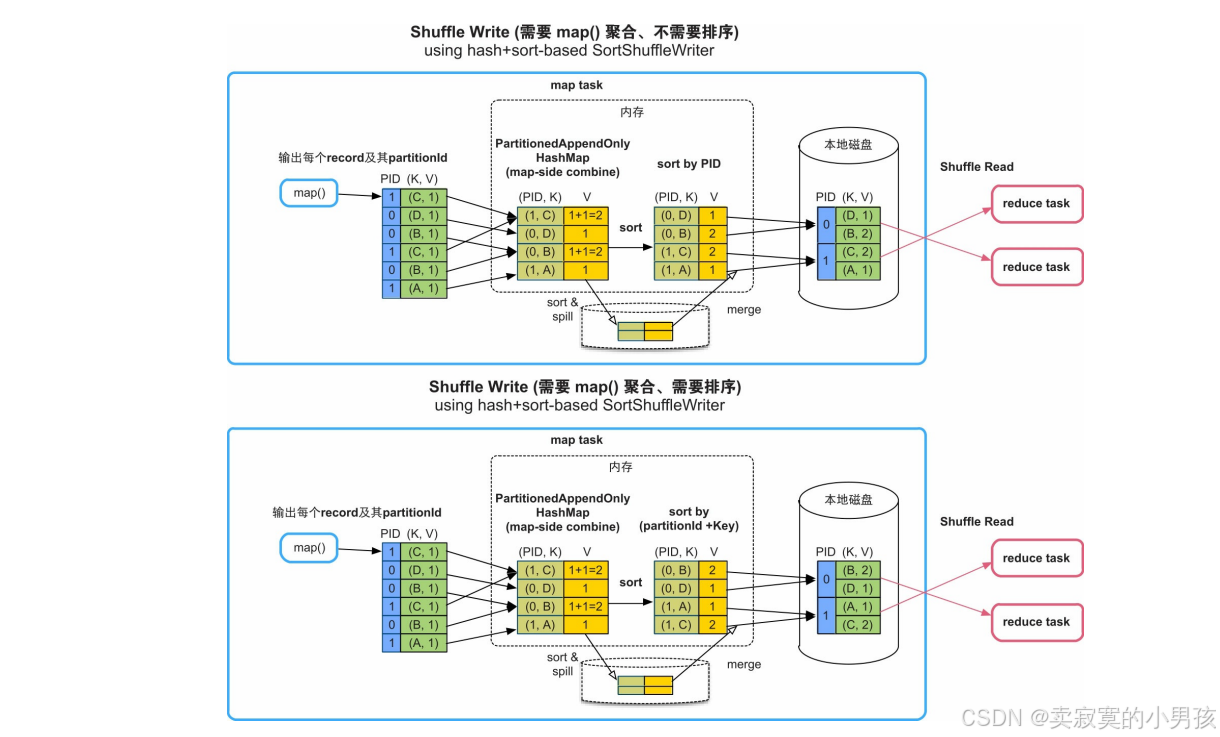
HashMap在堆内分配,需要消耗大量内存。如果HashMap存放不下,则会先扩容为两倍大小,如果还存放不下,就将HashMap中的record排序后spill到磁盘上。放入堆内HashMap或buffer中的record大小,如果超过task的内存限制,那么会spill到磁盘上。该Shuffle方式的优点是通用性强、对分区个数也无限制,缺点是内存消耗高(record是普通Java对象)、不能使用堆外内存。
3.3 Shuffle Read
3.3.1 ShuffleRead分类
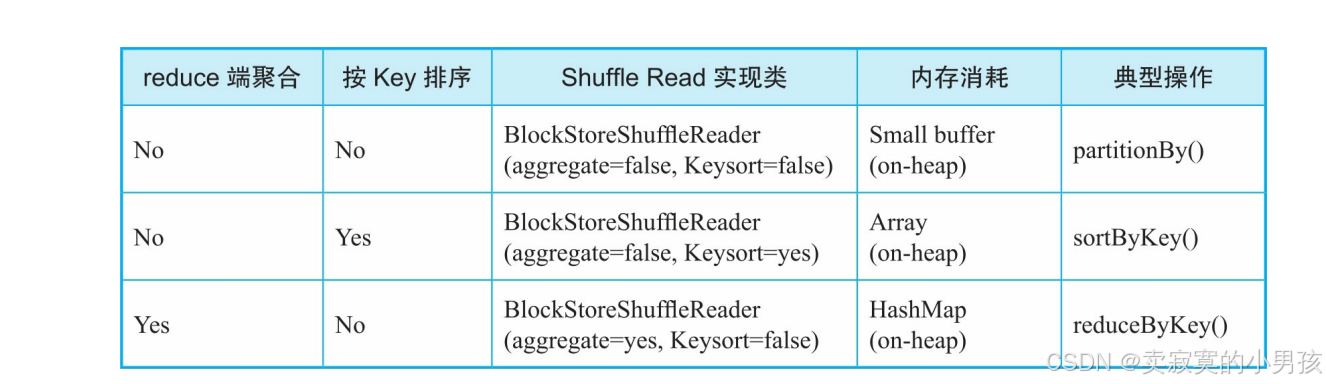
- 无聚合且无排序的情况:采用基于buffer获取数据并直接处理的方式,适用的典型操作如partitionBy()。
- 无聚合但需要排序的情况:采用基于数组排序的方式,适用的典型操作如sortByKey()。
- 有聚合的情况:采用基于HashMap聚合的方式,适用的典型操作如reduceByKey()。
这3种方式都是利用堆内内存来完成数据处理的,属于UnSerialized Shuffle方式。
3.3.2 无聚合,无排序
只包含一个大小为spark.reducer.maxSizeInFlight=48MB的缓冲区。
3.3.3 无聚合,需要排序
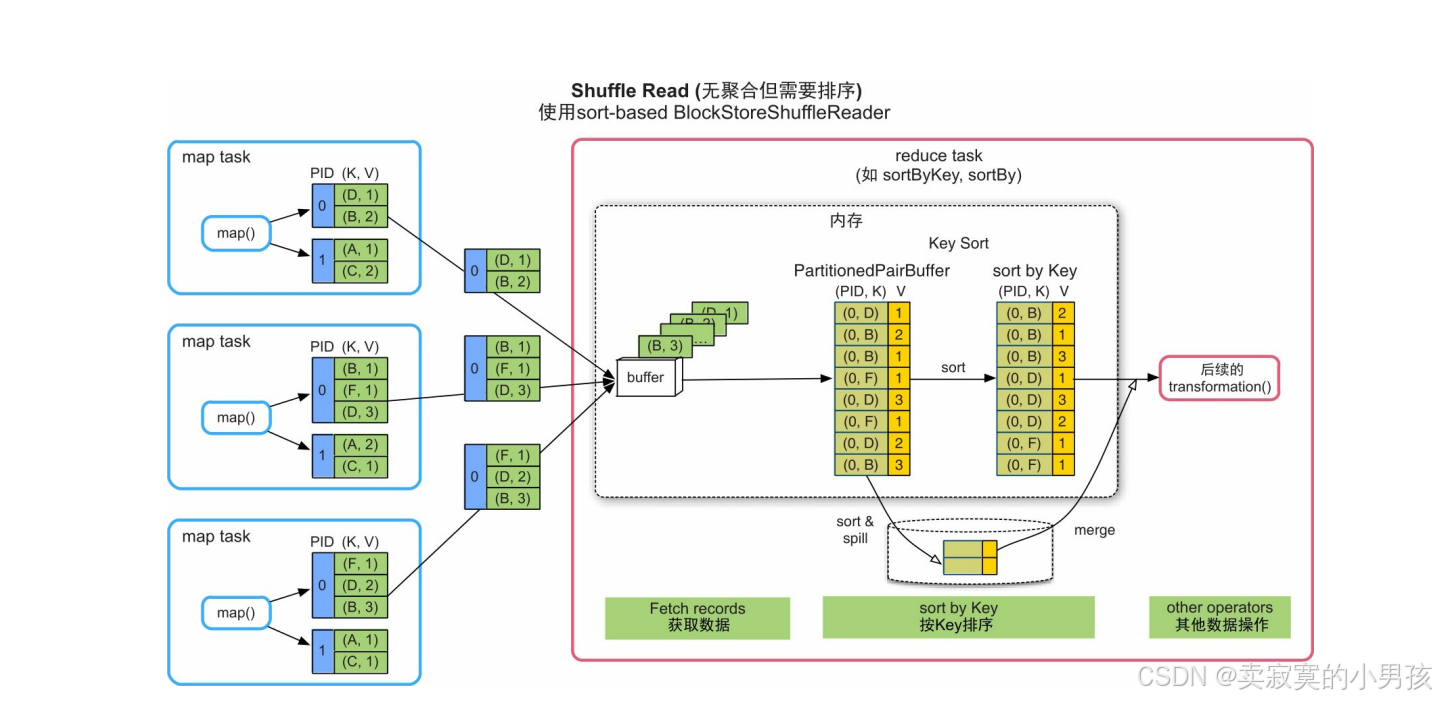
下游的task不断获取上游task输出的record,经过缓冲后,将record依次输出到一个Array结构(PartitionedPairBuffer)中。然后,对Array中的record按照Key进行排序,并将排序结果输出或者传递给下一步操作。
3.3.4 有聚合
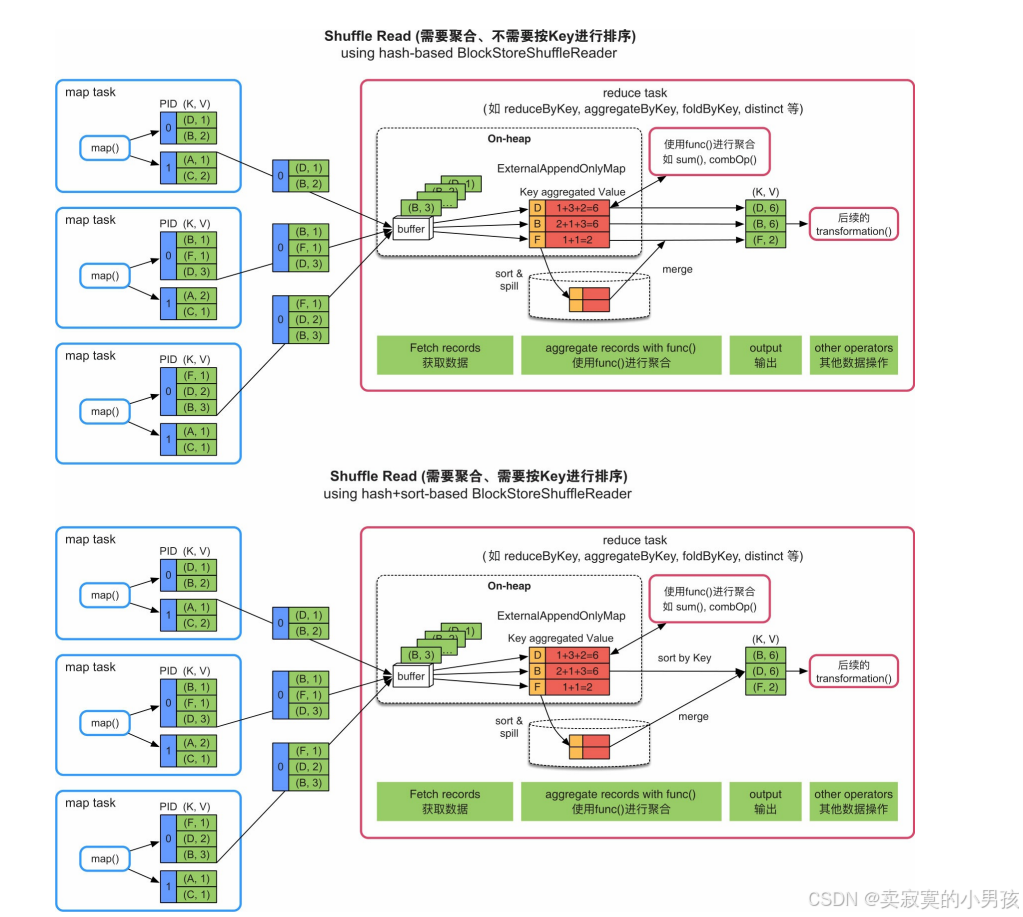
由于Shuffle Read端获取的是各个上游task的输出数据,用于数据聚合的HashMap结构会消耗大量内存,而且只能使用堆内内存。当然,HashMap的内存消耗量也与record中不同Key的个数及聚合函数的复杂度相关。HashMap 具有扩容和spill到磁盘上的功能,支持小规模到大规模数据的聚合。
4.数据缓存空间
数据缓存空间只存放三种数据:rdd缓存数据,广播数据,以及task的计算结果。
另外,还有几种临时空间,如用于反序列化(展开iterator为Array[])的临时空间、用于存放Netty网络数据传输的临时空间等。
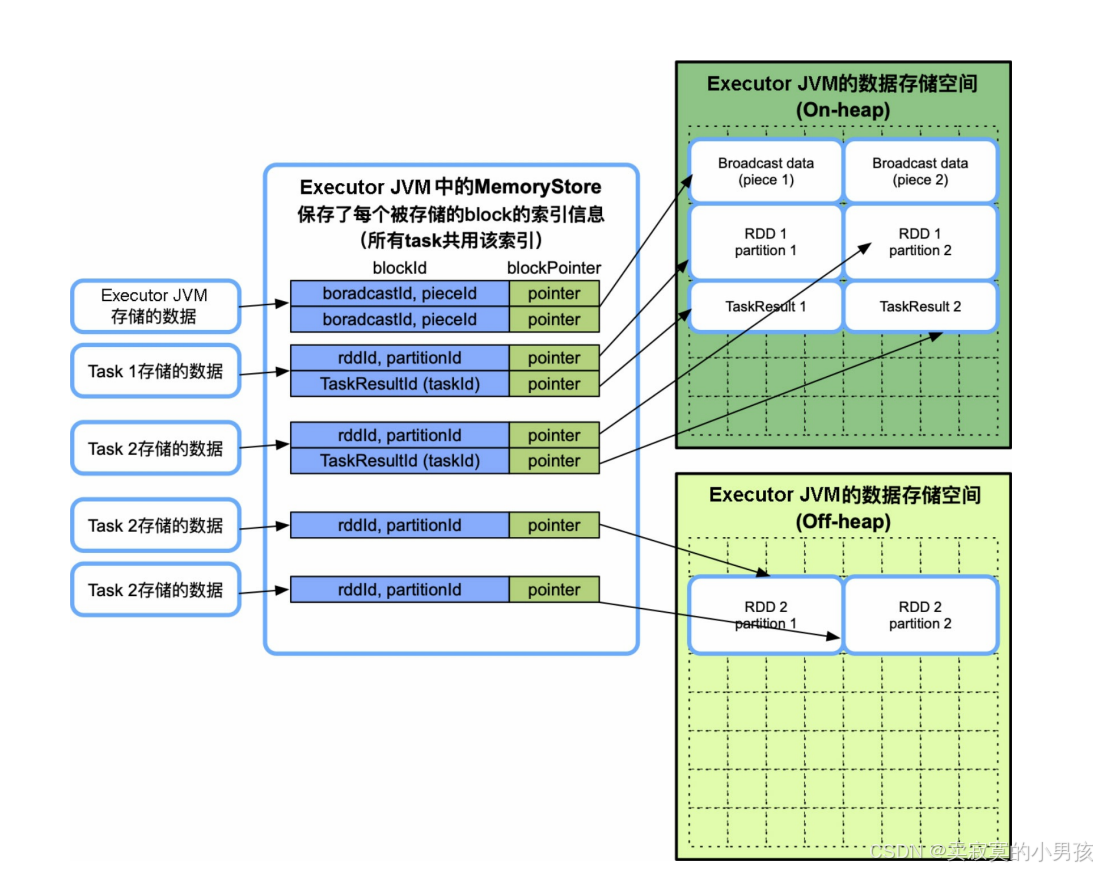
数据缓存空间也可以同时存放在堆内和堆外,而且由task共享。不同的是,每个task的存储空间并没有被限制为1/ N 。
4.1 RDD缓存
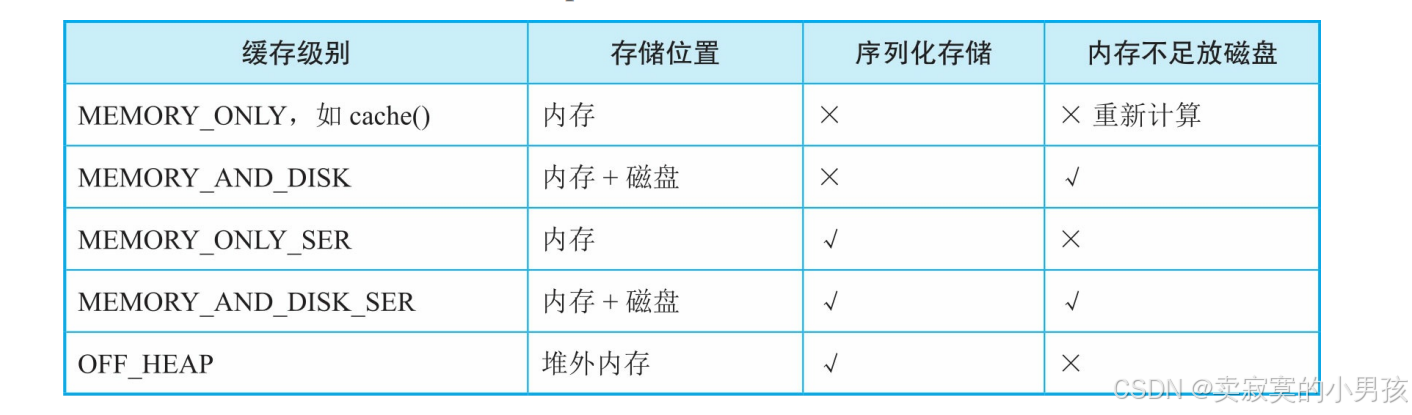
4.1.1 MEMORY_ONLY/MEMROY_AND_DISK
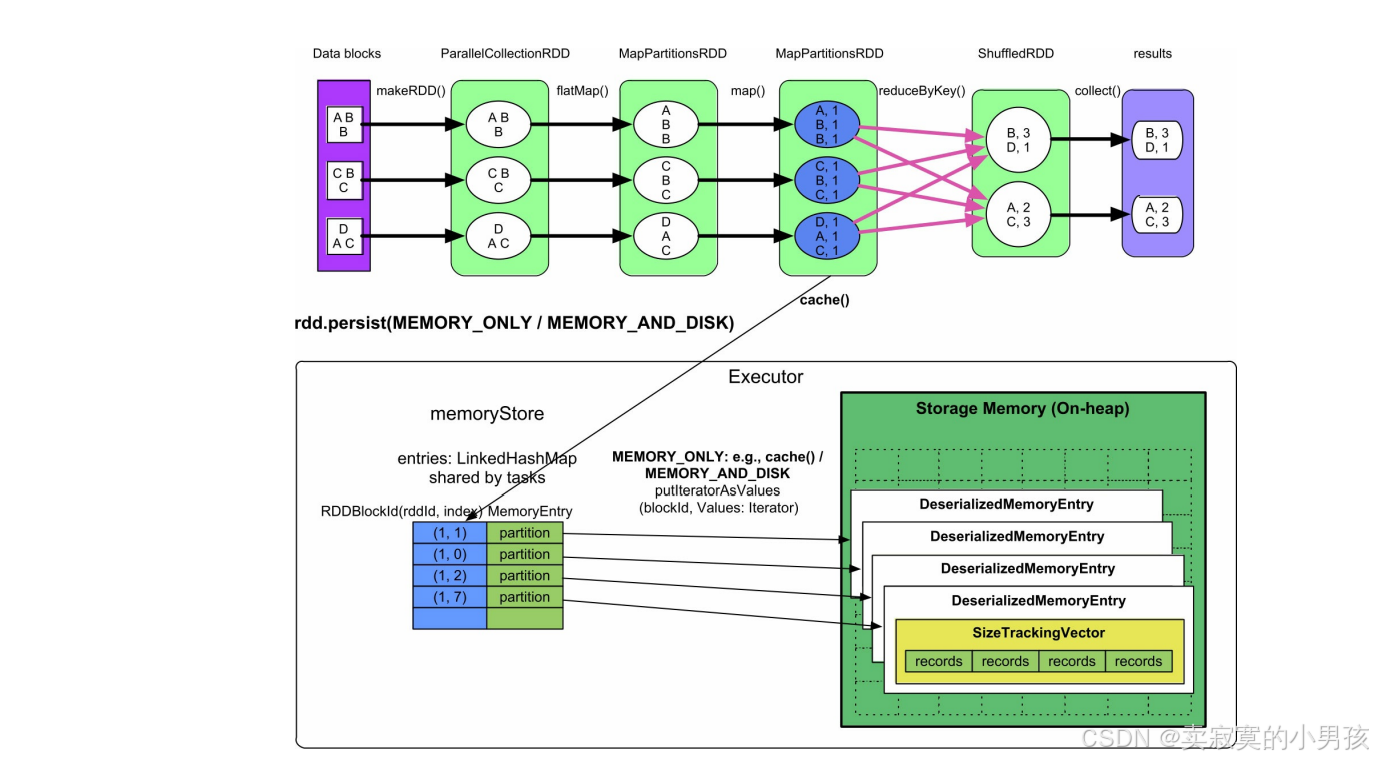
- memoryStore持有一个链表(LinkedHashMap)来存储和管理缓存的RDD partition。在链表中,Key的形式是(rddId= m ,partitionId= n ),表示其Value存储的数据来自RDD m 的第 n 个分区。
- Value是该partition的引用,引用指向一个名为DeserializedMemoryEntry的对象。该对象包含一个Vector,里面存放了partition中的record。
- 由于缓存级别没有被设置为序列化存储,这些record以普通Java对象的方式存放在Vector中。一个Executor中可能同时运行多个task,因此,链表被多个task共用,即数据缓存空间由多个task共享。
数据缓存空间的内存消耗由存放到其中的RDD record大小决定,即等于所有task缓存的RDD partition的record总大小。
4.1.2 MEMORY_ONLY_SER/MEMORY_AND_DISK_SER
与MEMORY_ONLY的实现方式基本相同,唯一不同是,这里的partition中的record以序列化的方式存储在一个ChunkedByteBuffer(不连续的ByteBuffer数组)中。使用不连续的ByteBuffer数组的目的是方便分配和回收。因为如果record非常多,序列化后就需要一个非常大的数组来存储,而此时的内存空间如果没有连续的一大块空间,就无法存储。在之前的MEMORY_ONLY模式中不存在这个问题,因为单个普通Java对象可以存放在内存中的任意位置。
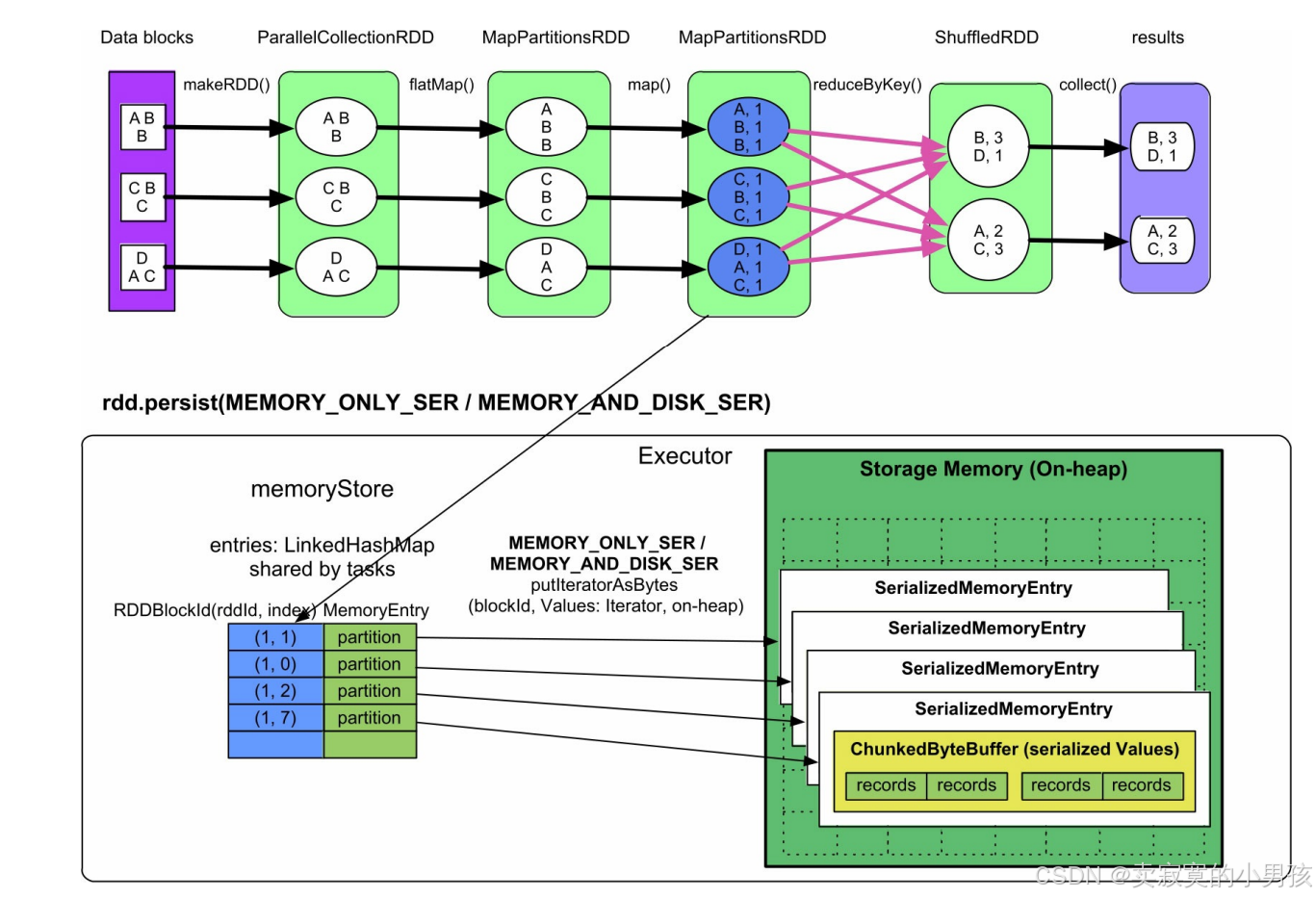
内存消耗:由存储的record总大小决定,即等于所有task缓存的RDD partition的record序列化后的总大小。
4.1.3 off-heap
该缓存模式的存储方式与MEMORY_ONLY_SER/MEMORY_AND_DISK_SER模式基本相同,需要缓存的partition中的record也是以序列化的方式存储在一个ChunkedByteBuffer(不连续的ByteBuffer数组)中的,只是存放位置是堆外内存。
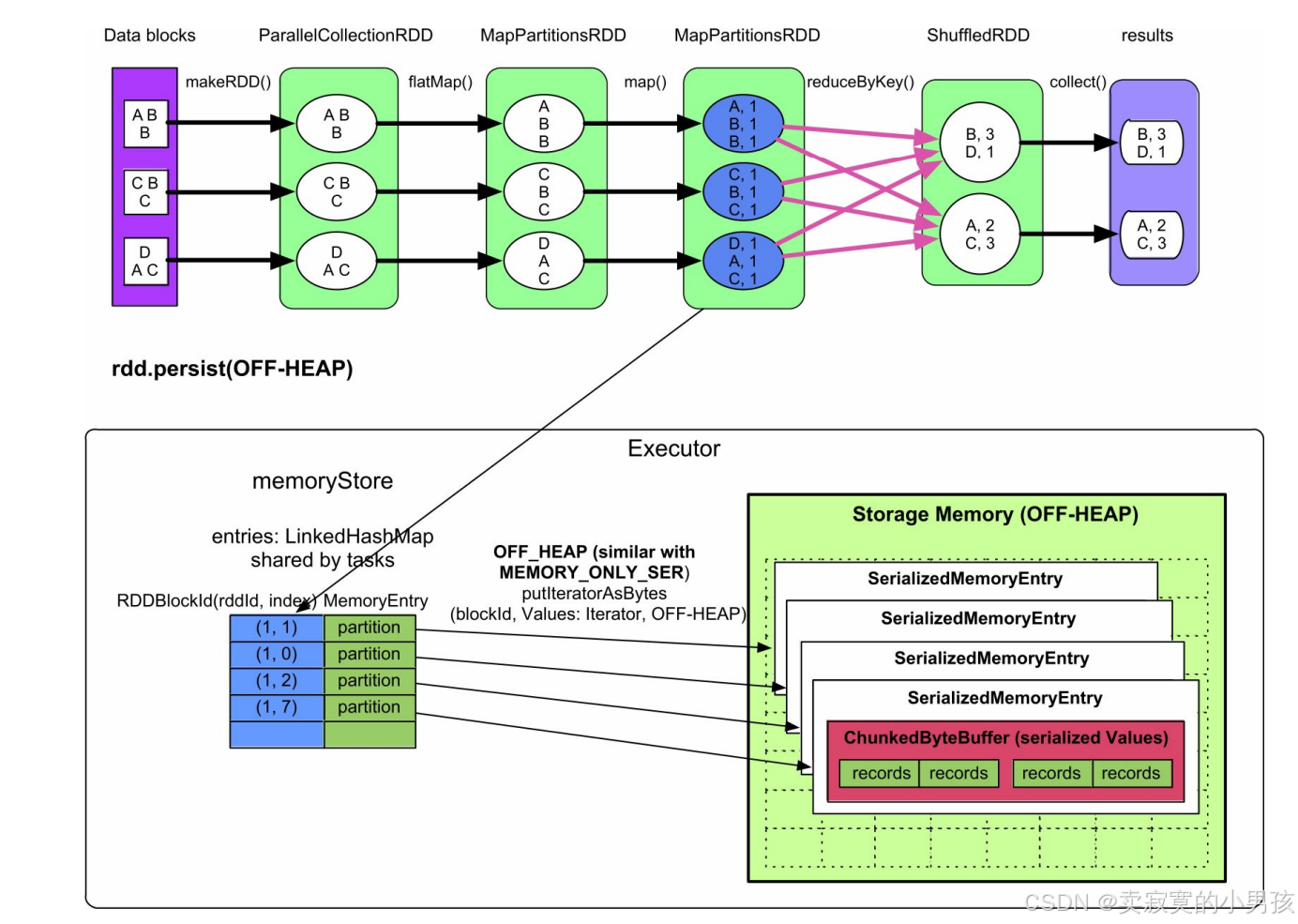
内存消耗:存放到OFF-HEAP中的partition的原始大小。
4.2 广播数据
Broadcast默认使用类似BT下载的TorrentBroadcast方式。
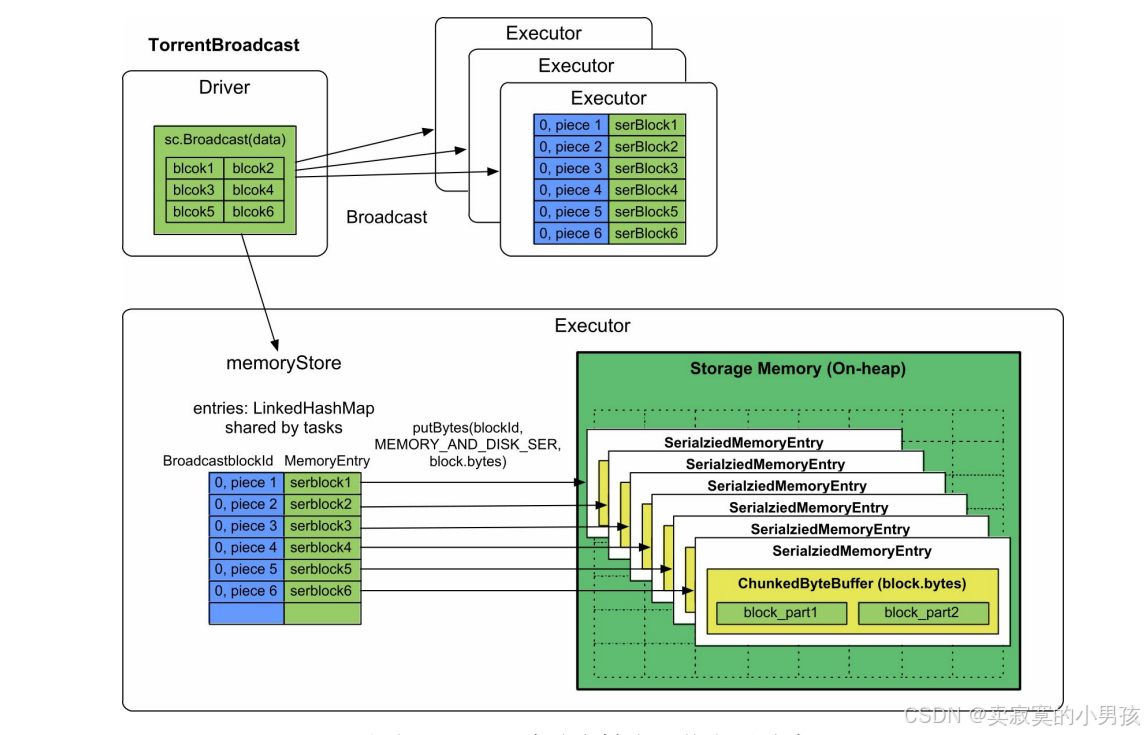
- 需要广播的数据一般预先存储在Driver端,Spark在Driver端将要广播的数据划分大小为spark.Broadcast.blockSize=4MB的数
据块(block)。 - 然后赋予每个数据块一个blockId为BroadcastblockId(id,“piece”+ i ),id表示block的编号,piece表示被划分后的第几个block。
- 之后,使用类似BT的方式将每个block广播到每个Executor中。Executor接收到每个block数据块后,将其放到堆内的数据缓存空间的ChunkedByteBuffer里面,缓存模式为MEMORY_AND_DISK_SER。
内存消耗:序列化后的Broadcast block总大小。
内存不足:Broadcast data的存放方式是内存+磁盘,内存不足时放入磁盘。
4.3 task计算结果
许多应用需要在Driver端收集task的计算结果并进行处理,如调用了rdd.collect()的应用。当task的输出结果大小超过spark.task.maxDirectResultSize=1MB且小于1GB时,需要先将每个task的输出结果缓存到执行该task的Executor中,存放模式是MEMORY_AND_DISK_SER,然后Executor将task的输出结果发送到Driver端进一步处理。
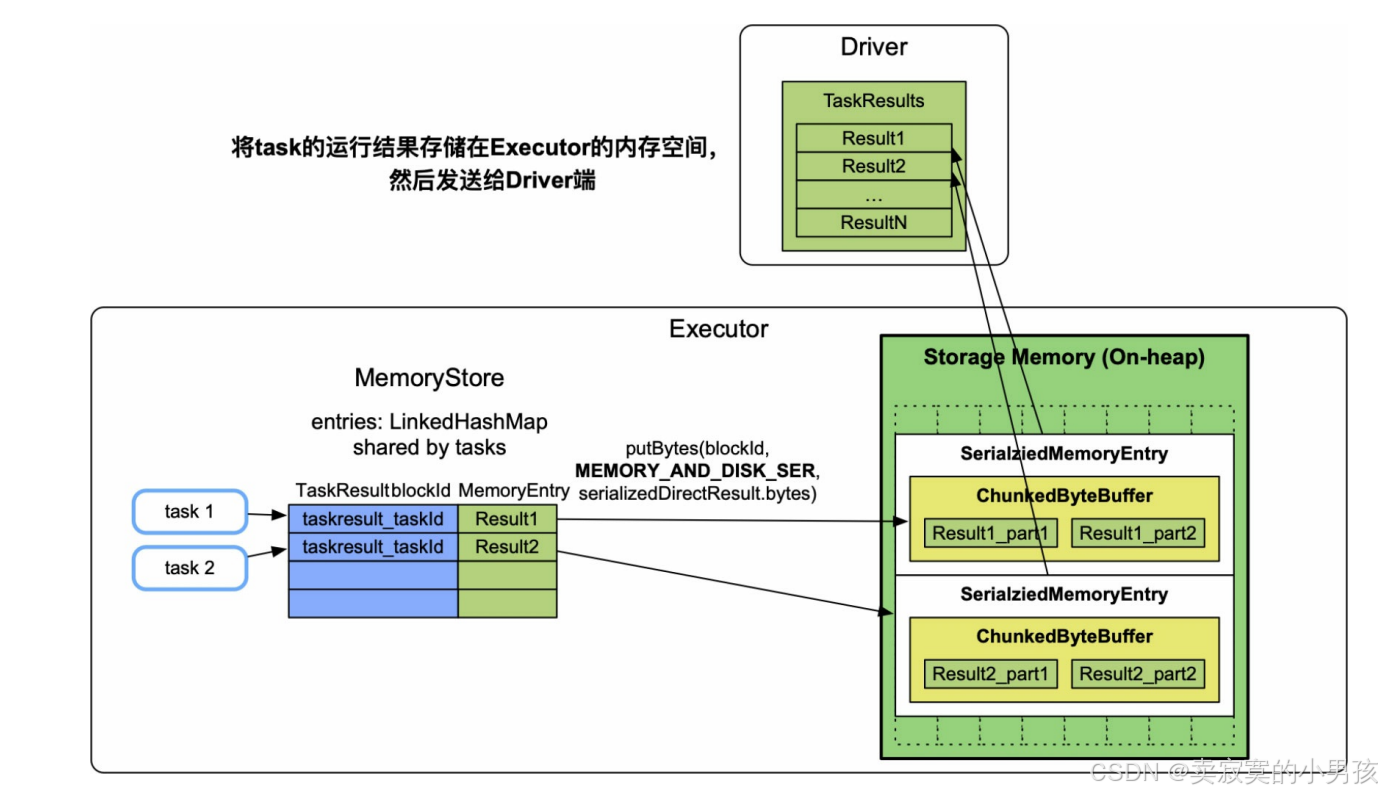
内存消耗:序列化后的task输出结果大小,不超过1GB。在Executor中一般运行多个task,如果每个task都占用了1GB以上的话,则会引起Executor的数据缓存空间不足。
内存不足:因为缓存方式是内存+磁盘,所以在内存不足时放入磁盘。