wav2vec2.0模型代码分析
首先给出代码:
import math
from dataclasses import dataclass, field
from typing import List, Tupleimport numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as Ffrom fairseq import utils
from fairseq.data.data_utils import compute_mask_indices
from fairseq.dataclass import ChoiceEnum, FairseqDataclass
from fairseq.distributed import fsdp_wrap
from fairseq.models import BaseFairseqModel, register_model
from fairseq.distributed.fully_sharded_data_parallel import FullyShardedDataParallel
from fairseq.modules import (Fp32GroupNorm,Fp32LayerNorm,GradMultiply,GumbelVectorQuantizer,LayerNorm,MultiheadAttention,RelPositionalEncoding,SamePad,TransposeLast,
)
from fairseq.modules.checkpoint_activations import checkpoint_wrapper
from fairseq.modules.conformer_layer import ConformerWav2Vec2EncoderLayer
from fairseq.modules.transformer_sentence_encoder import init_bert_params
from fairseq.utils import buffered_arange, index_put, is_xla_tensorfrom .utils import pad_to_multipleEXTRACTOR_MODE_CHOICES = ChoiceEnum(["default", "layer_norm"])
MASKING_DISTRIBUTION_CHOICES = ChoiceEnum(["static", "uniform", "normal", "poisson"])
LAYER_TYPE_CHOICES = ChoiceEnum(["transformer", "conformer", "trf_adp"])@dataclass
class Wav2Vec2Config(FairseqDataclass):extractor_mode: EXTRACTOR_MODE_CHOICES = field(default="default",metadata={"help": "mode for feature extractor. default has a single group norm with d ""groups in the first conv block, whereas layer_norm has layer norms in ""every block (meant to use with normalize=True)"},)encoder_layers: int = field(default=12, metadata={"help": "num encoder layers in the transformer"})encoder_embed_dim: int = field(default=768, metadata={"help": "encoder embedding dimension"})encoder_ffn_embed_dim: int = field(default=3072, metadata={"help": "encoder embedding dimension for FFN"})encoder_attention_heads: int = field(default=12, metadata={"help": "num encoder attention heads"})activation_fn: ChoiceEnum(utils.get_available_activation_fns()) = field(default="gelu", metadata={"help": "activation function to use"})layer_type: LAYER_TYPE_CHOICES = field(default="transformer", metadata={"help": "layer type in encoder"})# dropoutsdropout: float = field(default=0.1, metadata={"help": "dropout probability for the transformer"})attention_dropout: float = field(default=0.1, metadata={"help": "dropout probability for attention weights"})activation_dropout: float = field(default=0.0, metadata={"help": "dropout probability after activation in FFN"})encoder_layerdrop: float = field(default=0.0, metadata={"help": "probability of dropping a tarnsformer layer"})dropout_input: float = field(default=0.0,metadata={"help": "dropout to apply to the input (after feat extr)"},)dropout_features: float = field(default=0.0,metadata={"help": "dropout to apply to the features (after feat extr)"},)final_dim: int = field(default=0,metadata={"help": "project final representations and targets to this many dimensions.""set to encoder_embed_dim is <= 0"},)layer_norm_first: bool = field(default=False, metadata={"help": "apply layernorm first in the transformer"})conv_feature_layers: str = field(default="[(512, 10, 5)] + [(512, 3, 2)] * 4 + [(512,2,2)] + [(512,2,2)]",metadata={"help": "string describing convolutional feature extraction layers in form of a python list that contains ""[(dim, kernel_size, stride), ...]"},)conv_bias: bool = field(default=False, metadata={"help": "include bias in conv encoder"})logit_temp: float = field(default=0.1, metadata={"help": "temperature to divide logits by"})quantize_targets: bool = field(default=False, metadata={"help": "use quantized targets"})quantize_input: bool = field(default=False, metadata={"help": "use quantized inputs"})same_quantizer: bool = field(default=False, metadata={"help": "use same quantizer for inputs and targets"})target_glu: bool = field(default=False, metadata={"help": "adds projection + glu to targets"})feature_grad_mult: float = field(default=1.0, metadata={"help": "multiply feature extractor var grads by this"})quantizer_depth: int = field(default=1,metadata={"help": "number of quantizer layers"},)quantizer_factor: int = field(default=3,metadata={"help": "dimensionality increase for inner quantizer layers (if depth > 1)"},)latent_vars: int = field(default=320,metadata={"help": "number of latent variables V in each group of the codebook"},)latent_groups: int = field(default=2,metadata={"help": "number of groups G of latent variables in the codebook"},)latent_dim: int = field(default=0,metadata={"help": "if > 0, uses this dimensionality for latent variables. ""otherwise uses final_dim / latent_groups"},)# maskingmask_length: int = field(default=10, metadata={"help": "mask length"})mask_prob: float = field(default=0.65, metadata={"help": "probability of replacing a token with mask"})mask_selection: MASKING_DISTRIBUTION_CHOICES = field(default="static", metadata={"help": "how to choose mask length"})mask_other: float = field(default=0,metadata={"help": "secondary mask argument (used for more complex distributions), ""see help in compute_mask_indices"},)no_mask_overlap: bool = field(default=False, metadata={"help": "whether to allow masks to overlap"})mask_min_space: int = field(default=1,metadata={"help": "min space between spans (if no overlap is enabled)"},)require_same_masks: bool = field(default=True,metadata={"help": "whether to number of masked timesteps must be the same across all ""examples in a batch"},)mask_dropout: float = field(default=0.0,metadata={"help": "percent of masks to unmask for each sample"},)# channel maskingmask_channel_length: int = field(default=10, metadata={"help": "length of the mask for features (channels)"})mask_channel_prob: float = field(default=0.0, metadata={"help": "probability of replacing a feature with 0"})mask_channel_before: bool = Falsemask_channel_selection: MASKING_DISTRIBUTION_CHOICES = field(default="static",metadata={"help": "how to choose mask length for channel masking"},)mask_channel_other: float = field(default=0,metadata={"help": "secondary mask argument (used for more complex distributions), ""see help in compute_mask_indicesh"},)no_mask_channel_overlap: bool = field(default=False, metadata={"help": "whether to allow channel masks to overlap"})mask_channel_min_space: int = field(default=1,metadata={"help": "min space between spans (if no overlap is enabled)"},)# negative selectionnum_negatives: int = field(default=100,metadata={"help": "number of negative examples from the same sample"},)negatives_from_everywhere: bool = field(default=False,metadata={"help": "sample negatives from everywhere, not just masked states"},)cross_sample_negatives: int = field(default=0, metadata={"help": "number of negative examples from the any sample"})codebook_negatives: int = field(default=0, metadata={"help": "number of negative examples codebook"})# positional embeddingsconv_pos: int = field(default=128,metadata={"help": "number of filters for convolutional positional embeddings"},)conv_pos_groups: int = field(default=16,metadata={"help": "number of groups for convolutional positional embedding"},)pos_conv_depth: int = field(default=1,metadata={"help": "depth of positional encoder network"},)latent_temp: Tuple[float, float, float] = field(default=(2, 0.5, 0.999995),metadata={"help": "temperature for latent variable sampling. ""can be tuple of 3 values (start, end, decay)"},)max_positions: int = field(default=100000, metadata={"help": "Max positions"})checkpoint_activations: bool = field(default=False,metadata={"help": "recompute activations and save memory for extra compute"},)# FP16 optimizationrequired_seq_len_multiple: int = field(default=2,metadata={"help": "pad the input to encoder such that the sequence length is divisible by multiple"},)crop_seq_to_multiple: int = field(default=1,metadata={"help": "crop convolutional feature extractor output such that the sequence length is divisible by multiple"},)# Conformerdepthwise_conv_kernel_size: int = field(default=31,metadata={"help": "depthwise-conv-kernel-size for convolution in conformer layer"},)attn_type: str = field(default="",metadata={"help": "if espnet use ESPNET MHA"},)pos_enc_type: str = field(default="abs",metadata={"help": "Positional encoding type to use in conformer"},)fp16: bool = field(default=False, metadata={"help": "If fp16 is being used"})# Adapter numadp_num: int = field(default=-1)adp_dim: int = field(default=64)adp_act_fn: str = field(default="relu")adp_trf_idx: str = field(default="all",)@register_model("wav2vec2", dataclass=Wav2Vec2Config)
class Wav2Vec2Model(BaseFairseqModel):def __init__(self, cfg: Wav2Vec2Config):super().__init__()self.cfg = cfgfeature_enc_layers = eval(cfg.conv_feature_layers)self.embed = feature_enc_layers[-1][0]self.feature_extractor = ConvFeatureExtractionModel(conv_layers=feature_enc_layers,dropout=0.0,mode=cfg.extractor_mode,conv_bias=cfg.conv_bias,)self.post_extract_proj = (nn.Linear(self.embed, cfg.encoder_embed_dim)if self.embed != cfg.encoder_embed_dim and not cfg.quantize_inputelse None)self.crop_seq_to_multiple = cfg.crop_seq_to_multipleself.mask_prob = cfg.mask_probself.mask_selection = cfg.mask_selectionself.mask_other = cfg.mask_otherself.mask_length = cfg.mask_lengthself.no_mask_overlap = cfg.no_mask_overlapself.mask_min_space = cfg.mask_min_spaceself.mask_channel_prob = cfg.mask_channel_probself.mask_channel_before = cfg.mask_channel_beforeself.mask_channel_selection = cfg.mask_channel_selectionself.mask_channel_other = cfg.mask_channel_otherself.mask_channel_length = cfg.mask_channel_lengthself.no_mask_channel_overlap = cfg.no_mask_channel_overlapself.mask_channel_min_space = cfg.mask_channel_min_spaceself.dropout_input = nn.Dropout(cfg.dropout_input)self.dropout_features = nn.Dropout(cfg.dropout_features)self.feature_grad_mult = cfg.feature_grad_multself.quantizer = Noneself.input_quantizer = Noneself.n_negatives = cfg.num_negativesself.cross_sample_negatives = cfg.cross_sample_negativesself.codebook_negatives = cfg.codebook_negativesself.negatives_from_everywhere = cfg.negatives_from_everywhereself.logit_temp = cfg.logit_tempfinal_dim = cfg.final_dim if cfg.final_dim > 0 else cfg.encoder_embed_dimif cfg.quantize_targets:vq_dim = cfg.latent_dim if cfg.latent_dim > 0 else final_dimself.quantizer = GumbelVectorQuantizer(dim=self.embed,num_vars=cfg.latent_vars,temp=cfg.latent_temp,groups=cfg.latent_groups,combine_groups=False,vq_dim=vq_dim,time_first=True,weight_proj_depth=cfg.quantizer_depth,weight_proj_factor=cfg.quantizer_factor,)self.project_q = nn.Linear(vq_dim, final_dim)else:self.project_q = nn.Linear(self.embed, final_dim)if cfg.quantize_input:if cfg.same_quantizer and self.quantizer is not None:vq_dim = final_dimself.input_quantizer = self.quantizerelse:vq_dim = cfg.latent_dim if cfg.latent_dim > 0 else cfg.encoder_embed_dimself.input_quantizer = GumbelVectorQuantizer(dim=self.embed,num_vars=cfg.latent_vars,temp=cfg.latent_temp,groups=cfg.latent_groups,combine_groups=False,vq_dim=vq_dim,time_first=True,weight_proj_depth=cfg.quantizer_depth,weight_proj_factor=cfg.quantizer_factor,)self.project_inp = nn.Linear(vq_dim, cfg.encoder_embed_dim)self.mask_emb = nn.Parameter(torch.FloatTensor(cfg.encoder_embed_dim).uniform_())encoder_cls = TransformerEncoderif cfg.layer_type == "conformer" and cfg.pos_enc_type in ["rel_pos", "rope"]:encoder_cls = ConformerEncoderself.encoder = encoder_cls(cfg)self.layer_norm = LayerNorm(self.embed)self.target_glu = Noneif cfg.target_glu:self.target_glu = nn.Sequential(nn.Linear(final_dim, final_dim * 2), nn.GLU())self.final_proj = nn.Linear(cfg.encoder_embed_dim, final_dim)def upgrade_state_dict_named(self, state_dict, name):super().upgrade_state_dict_named(state_dict, name)"""Upgrade a (possibly old) state dict for new versions of fairseq."""return state_dict@classmethoddef build_model(cls, cfg: Wav2Vec2Config, task=None):"""Build a new model instance."""return cls(cfg)def apply_mask(self,x,padding_mask,mask_indices=None,mask_channel_indices=None,):B, T, C = x.shapeif self.mask_channel_prob > 0 and self.mask_channel_before:mask_channel_indices = compute_mask_indices((B, C),None,self.mask_channel_prob,self.mask_channel_length,self.mask_channel_selection,self.mask_channel_other,no_overlap=self.no_mask_channel_overlap,min_space=self.mask_channel_min_space,)mask_channel_indices = (torch.from_numpy(mask_channel_indices).to(x.device).unsqueeze(1).expand(-1, T, -1))x[mask_channel_indices] = 0if self.mask_prob > 0:if mask_indices is None:mask_indices = compute_mask_indices((B, T),padding_mask,self.mask_prob,self.mask_length,self.mask_selection,self.mask_other,min_masks=2,no_overlap=self.no_mask_overlap,min_space=self.mask_min_space,require_same_masks=self.cfg.require_same_masks,mask_dropout=self.cfg.mask_dropout,)mask_indices = torch.from_numpy(mask_indices).to(x.device)x = index_put(x, mask_indices, self.mask_emb)else:mask_indices = Noneif self.mask_channel_prob > 0 and not self.mask_channel_before:if mask_channel_indices is None:mask_channel_indices = compute_mask_indices((B, C),None,self.mask_channel_prob,self.mask_channel_length,self.mask_channel_selection,self.mask_channel_other,no_overlap=self.no_mask_channel_overlap,min_space=self.mask_channel_min_space,)mask_channel_indices = (torch.from_numpy(mask_channel_indices).to(x.device).unsqueeze(1).expand(-1, T, -1))x = index_put(x, mask_channel_indices, 0)return x, mask_indicesdef sample_negatives(self, y, num, padding_count=None):if self.n_negatives == 0 and self.cross_sample_negatives == 0:return y.new(0)bsz, tsz, fsz = y.shapey = y.view(-1, fsz) # BTC => (BxT)C# FIXME: what happens if padding_count is specified?cross_high = tsz * bszhigh = tsz - (padding_count or 0)with torch.no_grad():assert high > 1, f"{bsz,tsz,fsz}"if self.n_negatives > 0:tszs = (buffered_arange(num).unsqueeze(-1).expand(-1, self.n_negatives).flatten())neg_idxs = torch.randint(low=0, high=high - 1, size=(bsz, self.n_negatives * num))neg_idxs[neg_idxs >= tszs] += 1if self.cross_sample_negatives > 0:tszs = (buffered_arange(num).unsqueeze(-1).expand(-1, self.cross_sample_negatives).flatten())cross_neg_idxs = torch.randint(low=0,high=cross_high - 1,size=(bsz, self.cross_sample_negatives * num),)cross_neg_idxs[cross_neg_idxs >= tszs] += 1if self.n_negatives > 0:neg_idxs = neg_idxs + (torch.arange(bsz).unsqueeze(1) * high)else:neg_idxs = cross_neg_idxsif self.cross_sample_negatives > 0 and self.n_negatives > 0:neg_idxs = torch.cat([neg_idxs, cross_neg_idxs], dim=1)negs = y[neg_idxs.view(-1)]negs = negs.view(bsz, num, self.n_negatives + self.cross_sample_negatives, fsz).permute(2, 0, 1, 3) # to NxBxTxCreturn negs, neg_idxsdef compute_preds(self, x, y, negatives):neg_is_pos = (y == negatives).all(-1)y = y.unsqueeze(0)targets = torch.cat([y, negatives], dim=0)logits = torch.cosine_similarity(x.float(), targets.float(), dim=-1)logits = logits / self.logit_templogits = logits.type_as(x)if is_xla_tensor(logits) or neg_is_pos.any():if not hasattr(self, "_inftensor"):fillval = -float(2**30)self._inftensor = (torch.tensor(fillval).to(x.device)if is_xla_tensor(logits)else float("-inf"))logits[1:] = index_put(logits[1:], neg_is_pos, self._inftensor)return logitsdef _get_feat_extract_output_lengths(self, input_lengths: torch.LongTensor):"""Computes the output length of the convolutional layers"""def _conv_out_length(input_length, kernel_size, stride):return torch.floor((input_length - kernel_size) / stride + 1)conv_cfg_list = eval(self.cfg.conv_feature_layers)for i in range(len(conv_cfg_list)):input_lengths = _conv_out_length(input_lengths, conv_cfg_list[i][1], conv_cfg_list[i][2])return input_lengths.to(torch.long)def forward(self,source,padding_mask=None,mask=True,features_only=False,layer=None,mask_indices=None,mask_channel_indices=None,padding_count=None,corpus_key=None,):if self.feature_grad_mult > 0:features = self.feature_extractor(source)if self.feature_grad_mult != 1.0:features = GradMultiply.apply(features, self.feature_grad_mult)else:with torch.no_grad():features = self.feature_extractor(source)features_pen = features.float().pow(2).mean()features = features.transpose(1, 2)features = self.layer_norm(features)unmasked_features = features.clone()if padding_mask is not None and padding_mask.any():input_lengths = (1 - padding_mask.long()).sum(-1)# apply conv formula to get real output_lengthsoutput_lengths = self._get_feat_extract_output_lengths(input_lengths)padding_mask = torch.zeros(features.shape[:2], dtype=features.dtype, device=features.device)# these two operations makes sure that all values# before the output lengths indices are attended topadding_mask[(torch.arange(padding_mask.shape[0], device=padding_mask.device),output_lengths - 1,)] = 1padding_mask = (1 - padding_mask.flip([-1]).cumsum(-1).flip([-1])).bool()else:padding_mask = Nonetime_steps_to_drop = features.size(1) % self.crop_seq_to_multipleif time_steps_to_drop != 0:features = features[:, :-time_steps_to_drop]unmasked_features = unmasked_features[:, :-time_steps_to_drop]if padding_mask is not None:padding_mask = padding_mask[:, :-time_steps_to_drop]if self.post_extract_proj is not None:features = self.post_extract_proj(features)features = self.dropout_input(features)unmasked_features = self.dropout_features(unmasked_features)num_vars = Nonecode_ppl = Noneprob_ppl = Nonecurr_temp = Noneif self.input_quantizer:q = self.input_quantizer(features, produce_targets=False)features = q["x"]num_vars = q["num_vars"]code_ppl = q["code_perplexity"]prob_ppl = q["prob_perplexity"]curr_temp = q["temp"]features = self.project_inp(features)if mask:x, mask_indices = self.apply_mask(features,padding_mask,mask_indices=mask_indices,mask_channel_indices=mask_channel_indices,)if not is_xla_tensor(x) and mask_indices is not None:# tpu-comment: reducing the size in a dynamic way causes# too many recompilations on xla.y = unmasked_features[mask_indices].view(unmasked_features.size(0), -1, unmasked_features.size(-1))else:y = unmasked_featureselse:x = featuresy = unmasked_featuresmask_indices = Nonex, layer_results = self.encoder(x, padding_mask=padding_mask, layer=layer, corpus_key=corpus_key)if features_only:return {"x": x,"padding_mask": padding_mask,"features": unmasked_features,"layer_results": layer_results,}if self.quantizer:if self.negatives_from_everywhere:q = self.quantizer(unmasked_features, produce_targets=False)y = q["x"]num_vars = q["num_vars"]code_ppl = q["code_perplexity"]prob_ppl = q["prob_perplexity"]curr_temp = q["temp"]y = self.project_q(y)negs, _ = self.sample_negatives(y,mask_indices[0].sum(),padding_count=padding_count,)y = y[mask_indices].view(y.size(0), -1, y.size(-1))else:q = self.quantizer(y, produce_targets=False)y = q["x"]num_vars = q["num_vars"]code_ppl = q["code_perplexity"]prob_ppl = q["prob_perplexity"]curr_temp = q["temp"]y = self.project_q(y)negs, _ = self.sample_negatives(y,y.size(1),padding_count=padding_count,)if self.codebook_negatives > 0:cb_negs = self.quantizer.sample_from_codebook(y.size(0) * y.size(1), self.codebook_negatives)cb_negs = cb_negs.view(self.codebook_negatives, y.size(0), y.size(1), -1) # order doesnt mattercb_negs = self.project_q(cb_negs)negs = torch.cat([negs, cb_negs], dim=0)else:y = self.project_q(y)if self.negatives_from_everywhere:negs, _ = self.sample_negatives(unmasked_features,y.size(1),padding_count=padding_count,)negs = self.project_q(negs)else:negs, _ = self.sample_negatives(y,y.size(1),padding_count=padding_count,)if not is_xla_tensor(x):# tpu-comment: reducing the size in a dynamic way causes# too many recompilations on xla.x = x[mask_indices].view(x.size(0), -1, x.size(-1))if self.target_glu:y = self.target_glu(y)negs = self.target_glu(negs)x = self.final_proj(x)x = self.compute_preds(x, y, negs)result = {"x": x,"padding_mask": padding_mask,"features_pen": features_pen,}if prob_ppl is not None:result["prob_perplexity"] = prob_pplresult["code_perplexity"] = code_pplresult["num_vars"] = num_varsresult["temp"] = curr_tempreturn resultdef quantize(self, x):assert self.quantizer is not Nonex = self.feature_extractor(x)x = x.transpose(1, 2)x = self.layer_norm(x)return self.quantizer.forward_idx(x)def extract_features(self, source, padding_mask, mask=False, layer=None, corpus_key=None):res = self.forward(source,padding_mask,mask=mask,features_only=True,layer=layer,corpus_key=corpus_key,)return resdef get_logits(self, net_output):logits = net_output["x"]logits = logits.transpose(0, 2)logits = logits.reshape(-1, logits.size(-1))return logitsdef get_targets(self, sample, net_output, expand_steps=True):x = net_output["x"]return x.new_zeros(x.size(1) * x.size(2), dtype=torch.long)def get_extra_losses(self, net_output):pen = []if "prob_perplexity" in net_output:pen.append((net_output["num_vars"] - net_output["prob_perplexity"])/ net_output["num_vars"])if "features_pen" in net_output:pen.append(net_output["features_pen"])return pendef remove_pretraining_modules(self, last_layer=None):self.quantizer = Noneself.project_q = Noneself.target_glu = Noneself.final_proj = Noneif last_layer is not None:self.encoder.layers = nn.ModuleList(l for i, l in enumerate(self.encoder.layers) if i <= last_layer)class ConvFeatureExtractionModel(nn.Module):def __init__(self,conv_layers: List[Tuple[int, int, int]],dropout: float = 0.0,mode: str = "default",conv_bias: bool = False,):super().__init__()assert mode in {"default", "layer_norm"}def block(n_in,n_out,k,stride,is_layer_norm=False,is_group_norm=False,conv_bias=False,):def make_conv():conv = nn.Conv1d(n_in, n_out, k, stride=stride, bias=conv_bias)nn.init.kaiming_normal_(conv.weight)return convassert (is_layer_norm and is_group_norm) == False, "layer norm and group norm are exclusive"if is_layer_norm:return nn.Sequential(make_conv(),nn.Dropout(p=dropout),nn.Sequential(TransposeLast(),Fp32LayerNorm(dim, elementwise_affine=True),TransposeLast(),),nn.GELU(),)elif is_group_norm:return nn.Sequential(make_conv(),nn.Dropout(p=dropout),Fp32GroupNorm(dim, dim, affine=True),nn.GELU(),)else:return nn.Sequential(make_conv(), nn.Dropout(p=dropout), nn.GELU())in_d = 1self.conv_layers = nn.ModuleList()for i, cl in enumerate(conv_layers):assert len(cl) == 3, "invalid conv definition: " + str(cl)(dim, k, stride) = clself.conv_layers.append(block(in_d,dim,k,stride,is_layer_norm=mode == "layer_norm",is_group_norm=mode == "default" and i == 0,conv_bias=conv_bias,))in_d = dimdef forward(self, x):# BxT -> BxCxTx = x.unsqueeze(1)for conv in self.conv_layers:x = conv(x)return xdef make_conv_pos(e, k, g, is_batch_norm=False):pos_conv = nn.Conv1d(e,e,kernel_size=k,padding=k // 2,groups=g,)dropout = 0std = math.sqrt((4 * (1.0 - dropout)) / (k * e))nn.init.normal_(pos_conv.weight, mean=0, std=std)nn.init.constant_(pos_conv.bias, 0)if not is_batch_norm:pos_conv = nn.utils.weight_norm(pos_conv, name="weight", dim=2)pos_conv = nn.Sequential(pos_conv, SamePad(k), nn.GELU())else:batch_norm = nn.BatchNorm1d(e)pos_conv = nn.Sequential(batch_norm, pos_conv, SamePad(k), nn.GELU())return pos_convclass TransformerEncoder(nn.Module):def build_encoder_layer(self, args: Wav2Vec2Config, **kwargs):if args.layer_type == "transformer":layer = TransformerSentenceEncoderLayer(embedding_dim=self.embedding_dim,ffn_embedding_dim=args.encoder_ffn_embed_dim,num_attention_heads=args.encoder_attention_heads,dropout=self.dropout,attention_dropout=args.attention_dropout,activation_dropout=args.activation_dropout,activation_fn=args.activation_fn,layer_norm_first=args.layer_norm_first,)elif args.layer_type == "conformer":layer = ConformerWav2Vec2EncoderLayer(embed_dim=self.embedding_dim,ffn_embed_dim=args.encoder_ffn_embed_dim,attention_heads=args.encoder_attention_heads,dropout=args.dropout,depthwise_conv_kernel_size=args.depthwise_conv_kernel_size,activation_fn="swish",attn_type=args.attn_type,use_fp16=args.fp16,pos_enc_type="abs",)elif args.layer_type == "trf_adp":use_adp = Falseif args.adp_trf_idx == "all":use_adp = Trueelse:adp_trf_idx = list(range(*[int(g) for g in args.adp_trf_idx.split(":")]))if kwargs.get("layer_idx", None) in adp_trf_idx:use_adp = Trueif use_adp:layer = TransformerSentenceEncoderWithAdapterLayer(embedding_dim=self.embedding_dim,ffn_embedding_dim=args.encoder_ffn_embed_dim,num_attention_heads=args.encoder_attention_heads,dropout=self.dropout,attention_dropout=args.attention_dropout,activation_dropout=args.activation_dropout,activation_fn=args.activation_fn,layer_norm_first=args.layer_norm_first,adapter_num=args.adp_num,adapter_dim=args.adp_dim,adapter_act_fn=args.adp_act_fn,)else:layer = TransformerSentenceEncoderLayer(embedding_dim=self.embedding_dim,ffn_embedding_dim=args.encoder_ffn_embed_dim,num_attention_heads=args.encoder_attention_heads,dropout=self.dropout,attention_dropout=args.attention_dropout,activation_dropout=args.activation_dropout,activation_fn=args.activation_fn,layer_norm_first=args.layer_norm_first,)layer = fsdp_wrap(layer)if args.checkpoint_activations:layer = checkpoint_wrapper(layer)return layerdef __init__(self, args: Wav2Vec2Config, skip_pos_conv: bool = False, override_encoder_layer: int = None):super().__init__()self.dropout = args.dropoutself.embedding_dim = args.encoder_embed_dimself.required_seq_len_multiple = args.required_seq_len_multiplepos_conv_depth = getattr(args, "pos_conv_depth", 1)if pos_conv_depth > 1:num_layers = args.pos_conv_depthk = max(3, args.conv_pos // num_layers)def make_conv_block(e, k, g, l):return nn.Sequential(*[nn.Sequential(nn.Conv1d(e,e,kernel_size=k,padding=k // 2,groups=g,),SamePad(k),TransposeLast(),LayerNorm(e, elementwise_affine=False),TransposeLast(),nn.GELU(),)for _ in range(l)])self.pos_conv = make_conv_block(self.embedding_dim, k, args.conv_pos_groups, num_layers)elif skip_pos_conv:self.pos_conv = Noneelse:self.pos_conv = make_conv_pos(self.embedding_dim,args.conv_pos,args.conv_pos_groups,is_batch_norm=args.conv_pos_batch_normif hasattr(args, "conv_pos_batch_norm")else False,)if override_encoder_layer is None:encoder_layers = args.encoder_layerselse:encoder_layers = override_encoder_layerself.layers = nn.ModuleList([self.build_encoder_layer(args, layer_idx=ii) for ii in range(encoder_layers)])self.layer_norm_first = args.layer_norm_firstself.layer_norm = LayerNorm(self.embedding_dim)self.layerdrop = args.encoder_layerdropself.apply(init_bert_params)def forward(self, x, padding_mask=None, layer=None, corpus_key=None):x, layer_results = self.extract_features(x, padding_mask, layer, corpus_key=corpus_key)if self.layer_norm_first and layer is None:x = self.layer_norm(x)return x, layer_resultsdef extract_features(self,x,padding_mask=None,tgt_layer=None,min_layer=0,corpus_key=None,):if padding_mask is not None:x = index_put(x, padding_mask, 0)if self.pos_conv is not None:x_conv = self.pos_conv(x.transpose(1, 2))x_conv = x_conv.transpose(1, 2)x = x + x_convif not self.layer_norm_first:x = self.layer_norm(x)# pad to the sequence length dimensionx, pad_length = pad_to_multiple(x, self.required_seq_len_multiple, dim=-2, value=0)if pad_length > 0 and padding_mask is None:padding_mask = x.new_zeros((x.size(0), x.size(1)), dtype=torch.bool)padding_mask[:, -pad_length:] = Trueelse:padding_mask, _ = pad_to_multiple(padding_mask, self.required_seq_len_multiple, dim=-1, value=True)x = F.dropout(x, p=self.dropout, training=self.training)# B x T x C -> T x B x Cx = x.transpose(0, 1)layer_results = []r = Nonefor i, layer in enumerate(self.layers):dropout_probability = np.random.random() if self.layerdrop > 0 else 1if not self.training or (dropout_probability > self.layerdrop):layer_check = layerif isinstance(layer, FullyShardedDataParallel):layer_check = layer.unwrapped_moduleif (corpus_key is None) or (not isinstance(layer_check, (TransformerSentenceEncoderWithAdapterLayer,))):x, (z, lr) = layer(x, self_attn_padding_mask=padding_mask, need_weights=False)else:x, (z, lr) = layer(x,self_attn_padding_mask=padding_mask,need_weights=False,corpus_key=corpus_key,)if i >= min_layer:layer_results.append((x, z, lr))if i == tgt_layer:r = xbreakif r is not None:x = r# T x B x C -> B x T x Cx = x.transpose(0, 1)# undo padddingif pad_length > 0:x = x[:, :-pad_length]def undo_pad(a, b, c):return (a[:-pad_length],b[:-pad_length] if b is not None else b,c[:-pad_length],)layer_results = [undo_pad(*u) for u in layer_results]return x, layer_resultsdef max_positions(self):"""Maximum output length supported by the encoder."""return self.args.max_positionsdef upgrade_state_dict_named(self, state_dict, name):"""Upgrade a (possibly old) state dict for new versions of fairseq."""return state_dictclass ConformerEncoder(TransformerEncoder):def build_encoder_layer(self, args):layer = ConformerWav2Vec2EncoderLayer(embed_dim=self.embedding_dim,ffn_embed_dim=args.encoder_ffn_embed_dim,attention_heads=args.encoder_attention_heads,dropout=args.dropout,depthwise_conv_kernel_size=args.depthwise_conv_kernel_size,activation_fn="swish",attn_type=args.attn_type,pos_enc_type=args.pos_enc_type,use_fp16=args.fp16, # only used for rope)layer = fsdp_wrap(layer)if args.checkpoint_activations:layer = checkpoint_wrapper(layer)return layerdef __init__(self, args):super().__init__(args)self.args = argsself.dropout = args.dropoutself.embedding_dim = args.encoder_embed_dimself.pos_enc_type = args.pos_enc_typemax_source_positions = self.max_positions()if self.pos_enc_type == "rel_pos":self.embed_positions = RelPositionalEncoding(max_source_positions, self.embedding_dim)elif self.pos_enc_type == "rope":self.embed_positions = Noneelse:raise Exception("Unsupported positional encoding type")self.layers = nn.ModuleList([self.build_encoder_layer(args) for _ in range(args.encoder_layers)])self.layer_norm_first = args.layer_norm_firstself.layer_norm = LayerNorm(self.embedding_dim)self.layerdrop = args.encoder_layerdropself.apply(init_bert_params)def extract_features(self, x, padding_mask=None, tgt_layer=None):if padding_mask is not None:x = index_put(x, padding_mask, 0)# B x T x C -> T x B x Cx = x.transpose(0, 1)# B X T X C hereposition_emb = Noneif self.pos_enc_type == "rel_pos":position_emb = self.embed_positions(x)if not self.layer_norm_first:x = self.layer_norm(x)x = F.dropout(x, p=self.dropout, training=self.training)layer_results = []r = Nonefor i, layer in enumerate(self.layers):dropout_probability = np.random.random()if not self.training or (dropout_probability > self.layerdrop):x, z = layer(x,self_attn_padding_mask=padding_mask,need_weights=False,position_emb=position_emb,)if tgt_layer is not None:layer_results.append((x, z))if i == tgt_layer:r = xbreakif r is not None:x = r# T x B x C -> B x T x Cx = x.transpose(0, 1)return x, layer_resultsclass TransformerSentenceEncoderLayer(nn.Module):"""Implements a Transformer Encoder Layer used in BERT/XLM style pre-trainedmodels."""def __init__(self,embedding_dim: float = 768,ffn_embedding_dim: float = 3072,num_attention_heads: int = 8,dropout: float = 0.1,attention_dropout: float = 0.1,activation_dropout: float = 0.1,activation_fn: str = "relu",layer_norm_first: bool = False,) -> None:super().__init__()# Initialize parametersself.embedding_dim = embedding_dimself.dropout = dropoutself.activation_dropout = activation_dropout# Initialize blocksself.activation_fn = utils.get_activation_fn(activation_fn)self.self_attn = MultiheadAttention(self.embedding_dim,num_attention_heads,dropout=attention_dropout,self_attention=True,)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(self.activation_dropout)self.dropout3 = nn.Dropout(dropout)self.layer_norm_first = layer_norm_first# layer norm associated with the self attention layerself.self_attn_layer_norm = LayerNorm(self.embedding_dim)self.fc1 = nn.Linear(self.embedding_dim, ffn_embedding_dim)self.fc2 = nn.Linear(ffn_embedding_dim, self.embedding_dim)# layer norm associated with the position wise feed-forward NNself.final_layer_norm = LayerNorm(self.embedding_dim)def forward(self,x: torch.Tensor,self_attn_mask: torch.Tensor = None,self_attn_padding_mask: torch.Tensor = None,need_weights: bool = False,att_args=None,):"""LayerNorm is applied either before or after the self-attention/ffnmodules similar to the original Transformer imlementation."""residual = xif self.layer_norm_first:x = self.self_attn_layer_norm(x)x, attn = self.self_attn(query=x,key=x,value=x,key_padding_mask=self_attn_padding_mask,attn_mask=self_attn_mask,need_weights=False,)x = self.dropout1(x)x = residual + xresidual = xx = self.final_layer_norm(x)x = self.activation_fn(self.fc1(x))x = self.dropout2(x)x = self.fc2(x)layer_result = xx = self.dropout3(x)x = residual + xelse:x, attn = self.self_attn(query=x,key=x,value=x,key_padding_mask=self_attn_padding_mask,need_weights=False,)x = self.dropout1(x)x = residual + xx = self.self_attn_layer_norm(x)residual = xx = self.activation_fn(self.fc1(x))x = self.dropout2(x)x = self.fc2(x)layer_result = xx = self.dropout3(x)x = residual + xx = self.final_layer_norm(x)return x, (attn, layer_result)class AdapterFast(nn.Module):def __init__(self, adapter_num, input_dim, hidden_dim, act_fn):"""Implements adapter modules directly with 3D tensor weight as parametersand without using ModuleList orto speed up training throughput."""super().__init__()self.adapter_num = adapter_numself.input_dim = input_dimself.hidden_dim = hidden_dimself.W_a = nn.Parameter(torch.empty(adapter_num, hidden_dim, input_dim))self.W_b = nn.Parameter(torch.empty(adapter_num, input_dim, hidden_dim))self.b_a = nn.Parameter(torch.empty(adapter_num, hidden_dim))self.b_b = nn.Parameter(torch.empty(adapter_num, input_dim))self.ln_W = nn.Parameter(torch.empty(adapter_num, input_dim))self.ln_b = nn.Parameter(torch.empty(adapter_num, input_dim))self.act_fn = nn.Identity()if act_fn == "relu":self.act_fn = nn.ReLU()elif act_fn == "gelu":self.act_fn = nn.GELU()elif act_fn == "selu":self.act_fn = nn.SELU()else:raise ValueError(f"unsupported {act_fn}")self.input_dim = input_dimself.reset_parameters()def reset_parameters(self):for ii in range(self.adapter_num):nn.init.kaiming_uniform_(self.W_a[ii], a=math.sqrt(5))nn.init.kaiming_uniform_(self.W_b[ii], a=math.sqrt(5))fan_in, _ = nn.init._calculate_fan_in_and_fan_out(self.W_a[ii])bound = 1 / math.sqrt(fan_in) if fan_in > 0 else 0nn.init.uniform_(self.b_a[ii], -bound, bound)fan_in, _ = nn.init._calculate_fan_in_and_fan_out(self.W_b[ii])bound = 1 / math.sqrt(fan_in) if fan_in > 0 else 0nn.init.uniform_(self.b_b[ii], -bound, bound)nn.init.ones_(self.ln_W)nn.init.zeros_(self.ln_b)def forward(self, x, adapter_id):ii = adapter_idh = xh = F.layer_norm(h, (self.input_dim, ), self.ln_W[ii], self.ln_b[ii])h = F.linear(h, self.W_a[ii], self.b_a[ii])h = self.act_fn(h)h = F.linear(h, self.W_b[ii], self.b_b[ii])outputs = hreturn outputsdef extra_repr(self):return ('adapter={}, input_dim={}, hidden_dim={}'.format(self.adapter_num, self.input_dim, self.hidden_dim))class TransformerSentenceEncoderWithAdapterLayer(TransformerSentenceEncoderLayer):"""Implements a Transformer Encoder Layer with adapters used in BERT/XLM style pre-trainedmodels. An adapter module is added along with vanilla Transformer module."""def __init__(self,embedding_dim: float = 768,ffn_embedding_dim: float = 3072,num_attention_heads: int = 8,dropout: float = 0.1,attention_dropout: float = 0.1,activation_dropout: float = 0.1,activation_fn: str = "relu",layer_norm_first: bool = False,adapter_num=201,adapter_dim=64,adapter_act_fn="relu",) -> None:super().__init__(embedding_dim=embedding_dim,ffn_embedding_dim=ffn_embedding_dim,num_attention_heads=num_attention_heads,dropout=dropout,attention_dropout=attention_dropout,activation_dropout=activation_dropout,activation_fn=activation_fn,layer_norm_first=layer_norm_first,)self.adapter_num = adapter_numself.adapter_dim = adapter_dimself.adapter_layer = AdapterFast(adapter_num, self.embedding_dim, self.adapter_dim, adapter_act_fn)def forward(self,x: torch.Tensor,self_attn_mask: torch.Tensor = None,self_attn_padding_mask: torch.Tensor = None,need_weights: bool = False,att_args=None,corpus_key=None,):x, (attn, layer_result) = super().forward(x=x,self_attn_mask=self_attn_mask,self_attn_padding_mask=self_attn_padding_mask,need_weights=need_weights,att_args=att_args,)assert corpus_key is not Noneassert len(set(corpus_key)) == 1, f"corpus_key items are not same {corpus_key}"y = self.adapter_layer(x, corpus_key[0])x = x + yreturn x, (attn, layer_result)
然后给出模型图:
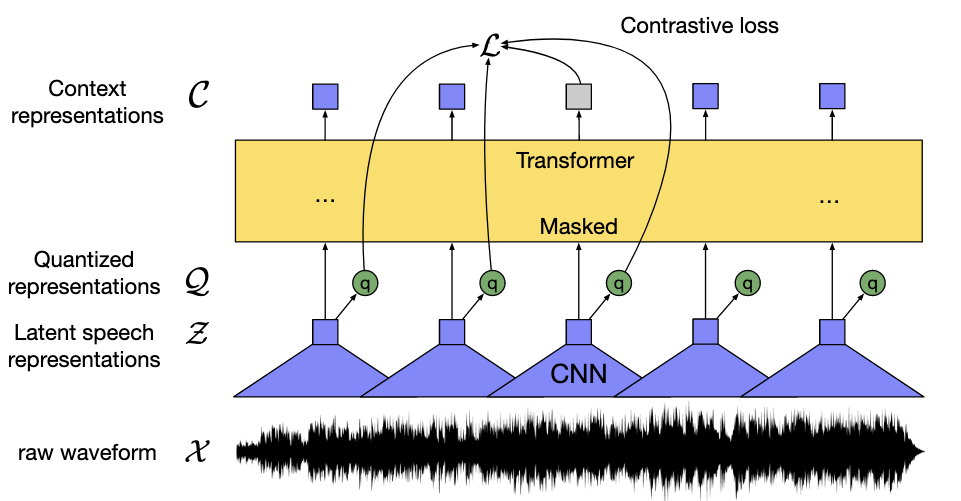
这段代码实现了Wav2Vec 2.0模型的核心结构,是一个基于自监督学习的语音表示模型,主要用于从原始语音信号中学习通用的语音特征。该模型在语音识别、语音翻译等任务中表现优异,其核心思想是通过掩盖语音特征并让模型预测被掩盖的部分,从而学习到鲁棒的语音表示。以下是对代码的详细解析:
导入的库
这部分代码主要包含了基础库导入、Fairseq框架组件导入以及核心配置枚举定义,为后续Wav2Vec 2.0模型的实现奠定了基础。以下是详细解释:
一、基础库导入
import math
from dataclasses import dataclass, field
from typing import List, Tupleimport numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
math:提供数学运算工具(如平方根、三角函数等),用于模型初始化、激活函数等计算。dataclasses:Python标准库中的数据类工具,dataclass用于定义配置类(如模型超参数),field用于指定配置项的默认值和元数据。typing:提供类型提示工具(如List、Tuple),增强代码可读性和类型检查。numpy:用于数值计算,尤其在数据预处理(如掩码索引生成)中常用。torch及torch.nn/torch.nn.functional:PyTorch深度学习框架的核心库,用于构建神经网络层(如nn.Linear)、激活函数(如F.relu)等。
二、Fairseq框架组件导入
from fairseq import utils
from fairseq.data.data_utils import compute_mask_indices
from fairseq.dataclass import ChoiceEnum, FairseqDataclass
from fairseq.distributed import fsdp_wrap
from fairseq.models import BaseFairseqModel, register_model
from fairseq.distributed.fully_sharded_data_parallel import FullyShardedDataParallel
from fairseq.modules import (Fp32GroupNorm,Fp32LayerNorm,GradMultiply,GumbelVectorQuantizer,LayerNorm,MultiheadAttention,RelPositionalEncoding,SamePad,TransposeLast,
)
from fairseq.modules.checkpoint_activations import checkpoint_wrapper
from fairseq.modules.conformer_layer import ConformerWav2Vec2EncoderLayer
from fairseq.modules.transformer_sentence_encoder import init_bert_params
from fairseq.utils import buffered_arange, index_put, is_xla_tensorfrom .utils import pad_to_multiple
Fairseq是Facebook推出的序列建模工具包,专为NLP和语音任务设计,这里导入的组件是Wav2Vec 2.0模型的核心依赖:
-
工具函数与数据处理
fairseq.utils:Fairseq的通用工具函数(如激活函数选择、张量操作等)。compute_mask_indices:用于生成掩码的索引(自监督学习中关键步骤,决定哪些位置需要被掩盖)。buffered_arange:高效生成.arange张量,避免重复计算;index_put:安全地对张量指定位置赋值(如掩码替换);is_xla_tensor:判断张量是否为XLA设备(如TPU)上的张量。pad_to_multiple:将序列长度补齐到指定倍数(用于满足模型对输入长度的要求,如Transformer的并行计算)。
-
配置相关
ChoiceEnum:Fairseq自定义的枚举类,用于限制配置参数的可选值(避免无效输入)。FairseqDataclass:Fairseq的基础配置类,所有模型配置类需继承它,支持参数解析和验证。
-
分布式训练
fsdp_wrap:用于包装模型层,支持Fully Sharded Data Parallel(FSDP)分布式训练(节省内存,适用于大模型)。FullyShardedDataParallel:FSDP分布式训练的核心类,将模型参数分片到多个GPU。
-
神经网络模块
- 归一化层:
Fp32GroupNorm(FP32精度的组归一化)、Fp32LayerNorm(FP32精度的层归一化)、LayerNorm(标准层归一化),用于稳定训练。 GradMultiply:梯度缩放工具(如在Wav2Vec 2.0中对特征提取器的梯度进行缩放,平衡不同模块的更新)。GumbelVectorQuantizer:Gumbel-softmax向量量化器(Wav2Vec 2.0的核心组件,将连续特征转换为离散码本,用于自监督目标)。MultiheadAttention:多头自注意力机制(Transformer的核心组件,捕捉序列上下文依赖)。RelPositionalEncoding:相对位置编码(用于Conformer等结构,建模序列中位置的相对关系)。SamePad:同阶填充(卷积层中保持输出长度与输入一致的填充方式)。TransposeLast:交换张量的最后两个维度(如将卷积输出的(B, C, T)转换为(B, T, C),适配Transformer输入格式)。
- 归一化层:
-
模型训练优化
checkpoint_wrapper:激活检查点(Checkpointing)工具,通过牺牲少量计算换取内存节省(在大模型训练中常用)。init_bert_params:BERT风格的参数初始化方法(如对线性层使用正态分布初始化,偏置置0)。
-
编码器层
ConformerWav2Vec2EncoderLayer:Conformer编码器层(结合Transformer注意力和卷积,在语音任务中性能优于纯Transformer)。
三、核心配置枚举定义
EXTRACTOR_MODE_CHOICES = ChoiceEnum(["default", "layer_norm"])
MASKING_DISTRIBUTION_CHOICES = ChoiceEnum(["static", "uniform", "normal", "poisson"])
LAYER_TYPE_CHOICES = ChoiceEnum(["transformer", "conformer", "trf_adp"])
这些是基于ChoiceEnum定义的枚举类型,用于限制模型配置参数的可选值,确保配置有效性:
-
EXTRACTOR_MODE_CHOICES
定义特征提取器的归一化模式:default:第一层使用组归一化(GroupNorm),其余层无(Wav2Vec 2.0原始配置)。layer_norm:每一层都使用层归一化(LayerNorm),适用于需要更强归一化的场景。
-
MASKING_DISTRIBUTION_CHOICES
定义掩码长度的分布类型(自监督学习中,决定掩盖区域的长度如何采样):static:固定掩码长度(如始终掩盖10个时间步)。uniform:掩码长度从均匀分布中采样。normal:掩码长度从正态分布中采样。poisson:掩码长度从泊松分布中采样。
-
LAYER_TYPE_CHOICES
定义编码器层的类型:transformer:使用标准Transformer编码器层。conformer:使用Conformer编码器层(语音任务更优)。trf_adp:带适配器(Adapter)的Transformer层(用于迁移学习,仅微调适配器参数)。
总结
这部分代码是Wav2Vec 2.0模型的“基础设施”:
- 导入了必要的数学工具、深度学习框架和Fairseq组件,为模型构建提供了基础模块;
- 定义的枚举类型限制了核心配置的可选值,确保模型参数的合法性;
- 后续的模型类(如
Wav2Vec2Model)将基于这些组件和配置展开实现。
1. 核心配置类(Wav2Vec2Config)
Wav2Vec2Config 是 Wav2Vec 2.0 模型的核心配置类,基于 dataclass 和 FairseqDataclass 实现,用于集中管理模型的所有超参数和训练策略。它定义了模型从特征提取、编码器结构到自监督学习策略的全部细节,是模型初始化和训练的“蓝图”。以下是对其每个字段的详细解释:
基础结构与继承
@dataclass
class Wav2Vec2Config(FairseqDataclass):
- 由
@dataclass装饰,自动生成构造函数、__repr__等方法,简化配置参数的管理。 - 继承
FairseqDataclass,这是 Fairseq 框架的基础配置类,支持参数解析、验证和与命令行参数的映射。
1. 特征提取器配置(语音→特征序列)
控制将原始语音波形转换为初始特征序列的卷积层参数。
| 字段 | 类型 | 默认值 | 作用 |
|---|---|---|---|
extractor_mode | EXTRACTOR_MODE_CHOICES | "default" | 特征提取器的归一化模式: - "default":第一层用组归一化(GroupNorm),其余层无;- "layer_norm":每层都用层归一化(LayerNorm)。 |
conv_feature_layers | str | "[(512, 10, 5)] + [(512, 3, 2)] * 4 + [(512,2,2)] + [(512,2,2)]" | 卷积特征提取层的定义,格式为 [(维度, kernel_size, 步长), ...]:默认配置是 7 层卷积,逐步将原始语音(1D 波形)降采样为高维特征序列(时间维度压缩,特征维度提升至 512)。 |
conv_bias | bool | False | 卷积层是否使用偏置参数。默认不使用,减少参数数量并稳定训练。 |
crop_seq_to_multiple | int | 1 | 对卷积提取的特征序列进行裁剪,使其长度为该值的倍数(用于适配后续编码器的并行计算需求)。 |
2. 编码器配置(特征序列→上下文表示)
控制 Transformer/Conformer 编码器的结构,负责将特征序列转换为上下文相关表示。
| 字段 | 类型 | 默认值 | 作用 |
|---|---|---|---|
encoder_layers | int | 12 | 编码器的层数(Transformer/Conformer 块的数量)。 |
encoder_embed_dim | int | 768 | 编码器的嵌入维度(所有层的输入/输出维度)。 |
encoder_ffn_embed_dim | int | 3072 | 编码器前馈网络(FFN)的中间维度(通常为 encoder_embed_dim 的 4 倍)。 |
encoder_attention_heads | int | 12 | 多头自注意力的头数(encoder_embed_dim 需能被头数整除,如 768/12=64,即每个头的维度为 64)。 |
activation_fn | ChoiceEnum | "gelu" | 激活函数类型,支持 relu、gelu 等(默认 gelu,在 Transformer 中更常用)。 |
layer_type | LAYER_TYPE_CHOICES | "transformer" | 编码器层的类型: - "transformer":标准 Transformer 层;- "conformer":Conformer 层(结合注意力和卷积,适合语音);- "trf_adp":带适配器(Adapter)的 Transformer 层(用于迁移学习)。 |
layer_norm_first | bool | False | 层归一化(LayerNorm)的位置: - True:归一化在注意力/FFN 之前;- False:归一化在残差连接之后(默认,更稳定)。 |
depthwise_conv_kernel_size | int | 31 | Conformer 层中深度可分离卷积的 kernel 大小(语音任务常用大 kernel 捕捉局部特征)。 |
pos_enc_type | str | "abs" | 位置编码类型(仅 Conformer 用): - "rel_pos":相对位置编码;- "rope":旋转位置编码。 |
3. 正则化配置(防止过拟合)
通过 dropout 等机制增强模型泛化能力。
| 字段 | 类型 | 默认值 | 作用 |
|---|---|---|---|
dropout | float | 0.1 | 编码器整体的 dropout 概率(如残差连接后的 dropout)。 |
attention_dropout | float | 0.1 | 注意力权重的 dropout 概率(减少注意力权重的过拟合)。 |
activation_dropout | float | 0.0 | 激活函数后的 dropout 概率(如 FFN 中激活后的 dropout)。 |
encoder_layerdrop | float | 0.0 | 随机丢弃整个编码器层的概率(增强模型鲁棒性)。 |
dropout_input | float | 0.0 | 特征提取器输出后的 dropout 概率(对输入特征正则化)。 |
dropout_features | float | 0.0 | 未被掩码的特征的 dropout 概率(进一步正则化特征)。 |
4. 量化配置(自监督目标生成)
Wav2Vec 2.0 的核心机制之一:将连续特征量化为离散“码本”,作为自监督学习的目标。
| 字段 | 类型 | 默认值 | 作用 |
|---|---|---|---|
quantize_targets | bool | False | 是否将目标特征量化为离散值(开启后使用 GumbelVectorQuantizer)。 |
quantize_input | bool | False | 是否将输入特征量化(通常用于特殊训练策略,如输入-目标量化对齐)。 |
same_quantizer | bool | False | 输入量化器与目标量化器是否共享参数(quantize_input 和 quantize_targets 均为 True 时有效)。 |
latent_vars | int | 320 | 每个量化组中的潜在变量数量(码本大小,如 320 表示每个组有 320 个可选离散值)。 |
latent_groups | int | 2 | 量化的分组数量(将特征维度拆分到多个组,并行量化,减少计算量)。 |
latent_dim | int | 0 | 量化后潜在变量的维度: - 若 >0,直接使用该值;- 若 =0,则为 final_dim / latent_groups(默认)。 |
quantizer_depth | int | 1 | 量化器中投影层的深度(>1 时增加中间层提升量化能力)。 |
quantizer_factor | int | 3 | 量化器中间层的维度放大倍数(如深度>1 时,中间层维度 = 输入维度 × 该值)。 |
latent_temp | Tuple[float, float, float] | (2, 0.5, 0.999995) | Gumbel 量化的温度参数((起始值, 结束值, 衰减率)):温度控制离散化的“硬度”,逐渐从软分配(高温度)过渡到硬分配(低温度)。 |
5. 掩码策略配置(自监督学习核心)
通过随机掩盖部分特征,迫使模型学习上下文依赖以预测被掩盖部分。
时间掩码(掩盖时间步)
| 字段 | 类型 | 默认值 | 作用 |
|---|---|---|---|
mask_length | int | 10 | 单个掩码片段的长度(默认掩盖 10 个时间步)。 |
mask_prob | float | 0.65 | 特征序列中被掩码覆盖的比例(默认 65% 的时间步被掩盖)。 |
mask_selection | MASKING_DISTRIBUTION_CHOICES | "static" | 掩码长度的分布: - "static":固定长度;- "uniform"/"normal"/"poisson":从对应分布采样长度。 |
mask_other | float | 0 | 辅助掩码参数(如对 uniform 分布,控制长度范围)。 |
no_mask_overlap | bool | False | 是否禁止掩码片段重叠(True 时掩码不重叠,更严格)。 |
mask_min_space | int | 1 | 掩码片段间的最小间隔(仅 no_mask_overlap=True 时有效)。 |
require_same_masks | bool | True | 批次中所有样本是否使用相同数量的掩码(便于并行计算)。 |
mask_dropout | float | 0.0 | 对已生成的掩码随机“解掩盖”的比例(增加随机性)。 |
通道掩码(掩盖特征通道)
| 字段 | 类型 | 默认值 | 作用 |
|---|---|---|---|
mask_channel_length | int | 10 | 单个通道掩码的长度(掩盖连续的特征通道)。 |
mask_channel_prob | float | 0.0 | 特征通道被掩码覆盖的比例(默认不使用通道掩码)。 |
mask_channel_before | bool | False | 通道掩码应用时机: - True:在时间掩码之前;- False:在时间掩码之后。 |
mask_channel_selection | MASKING_DISTRIBUTION_CHOICES | "static" | 通道掩码长度的分布(同时间掩码)。 |
| (其他通道掩码参数) | - | - | 与时间掩码类似(mask_channel_other/no_mask_channel_overlap 等)。 |
6. 对比学习配置(损失计算)
通过正例(被掩盖位置的真实特征)和负例(干扰项)的对比,优化模型对特征的判别能力。
| 字段 | 类型 | 默认值 | 作用 |
|---|---|---|---|
num_negatives | int | 100 | 从同一样本中采样的负例数量(每个正例对应 100 个负例)。 |
cross_sample_negatives | int | 0 | 从其他样本中采样的负例数量(增加负例多样性)。 |
codebook_negatives | int | 0 | 从量化码本中采样的负例数量(增强对码本的学习)。 |
negatives_from_everywhere | bool | False | 负例是否可从整个特征序列采样(True 时不仅限于被掩码位置)。 |
logit_temp | float | 0.1 | 计算相似度时的温度系数(缩小 logits 范围,使 softmax 更“陡峭”)。 |
7. 位置编码配置(建模序列顺序)
| 字段 | 类型 | 默认值 | 作用 |
|---|---|---|---|
conv_pos | int | 128 | 卷积位置编码的滤波器数量(用卷积捕捉局部位置信息)。 |
conv_pos_groups | int | 16 | 卷积位置编码的分组数量(分组卷积减少参数)。 |
pos_conv_depth | int | 1 | 位置编码卷积网络的深度(>1 时堆叠多层卷积)。 |
8. 训练与优化配置
| 字段 | 类型 | 默认值 | 作用 |
|---|---|---|---|
final_dim | int | 0 | 最终输出的特征维度: - 若 >0,使用该值;- 若 =0,等于 encoder_embed_dim(默认)。 |
target_glu | bool | False | 是否对目标特征应用 GLU(门控线性单元):通过 Linear+GLU 增强目标特征的表达能力。 |
feature_grad_mult | float | 1.0 | 特征提取器梯度的缩放因子(如设为 0.1 可减弱特征提取器的更新,适合预训练后微调)。 |
max_positions | int | 100000 | 模型支持的最大序列长度(防止输入过长导致内存溢出)。 |
checkpoint_activations | bool | False | 是否启用激活检查点(Checkpointing):牺牲计算量换取内存节省(大模型训练常用)。 |
required_seq_len_multiple | int | 2 | 编码器输入序列长度需满足的倍数(用于对齐并行计算的块大小)。 |
fp16 | bool | False | 是否使用 FP16 混合精度训练(加速训练并节省内存)。 |
9. 适配器(Adapter)配置(迁移学习)
| 字段 | 类型 | 默认值 | 作用 |
|---|---|---|---|
adp_num | int | -1 | 适配器的数量(用于多任务/多语料迁移,-1 表示不使用)。 |
adp_dim | int | 64 | 适配器中间层的维度(通常小于 encoder_embed_dim,减少参数)。 |
adp_act_fn | str | "relu" | 适配器的激活函数。 |
adp_trf_idx | str | "all" | 启用适配器的 Transformer 层索引: - "all":所有层;- 如 "0:5":第 0 到 4 层。 |
总结
Wav2Vec2Config 全面定义了 Wav2Vec 2.0 模型的“基因”:从原始语音到特征序列的转换(特征提取器)、序列的上下文编码(Transformer/Conformer)、自监督学习的核心机制(掩码与量化),到训练优化策略(正则化、对比学习)。每个参数都直接影响模型的结构、性能和训练效率,是理解和修改 Wav2Vec 2.0 模型的关键入口。
2. 主模型类(Wav2Vec2Model)
Wav2Vec2Model 是 Wav2Vec 2.0 模型的核心实现类,继承自 BaseFairseqModel,整合了特征提取、掩码策略、上下文编码、量化目标生成和对比学习等核心逻辑。它是连接模型配置(Wav2Vec2Config)与实际功能的桥梁,负责将原始语音信号转换为有意义的特征表示,并通过自监督学习优化模型参数。以下是对其结构和核心功能的详细解析:
1. 类定义与初始化(init)
@register_model("wav2vec2", dataclass=Wav2Vec2Config)
class Wav2Vec2Model(BaseFairseqModel):def __init__(self, cfg: Wav2Vec2Config):super().__init__()self.cfg = cfg# ... 组件初始化 ...
@register_model("wav2vec2"):Fairseq 的注册机制,将该类标记为名为"wav2vec2"的模型,允许通过配置文件自动加载。- 初始化方法接收
Wav2Vec2Config实例cfg,并基于配置初始化模型的所有核心组件。
核心组件初始化
初始化方法中构建了模型的关键模块,这些模块协同完成从语音输入到损失计算的全过程:
| 组件 | 作用 | 初始化逻辑 |
|---|---|---|
| 特征提取器(feature_extractor) | 将原始语音波形(1D 信号)转换为高维特征序列。 | 通过 ConvFeatureExtractionModel 实现,参数由 cfg.conv_feature_layers(卷积层配置)、cfg.extractor_mode(归一化模式)等决定。 |
| 投影层(post_extract_proj) | 将特征提取器的输出维度映射到编码器的嵌入维度(encoder_embed_dim)。 | 若特征提取器输出维度(self.embed)与 encoder_embed_dim 不一致且不启用输入量化,则初始化线性层;否则为 None。 |
| 量化器(quantizer/input_quantizer) | 将连续特征转换为离散潜在变量(码本),用于自监督学习的目标或输入处理。 | - quantizer:当 cfg.quantize_targets=True 时,通过 GumbelVectorQuantizer 初始化,用于生成目标特征的离散表示。- input_quantizer:当 cfg.quantize_input=True 时初始化,用于量化输入特征(可选与 quantizer 共享参数)。 |
| 掩码嵌入(mask_emb) | 可学习的向量,用于替换被掩码的特征位置(自监督学习中“掩盖”操作的核心)。 | 随机初始化一个维度为 encoder_embed_dim 的向量。 |
| 编码器(encoder) | 将特征序列编码为上下文相关表示,支持 Transformer 或 Conformer 结构。 | 根据 cfg.layer_type 选择编码器类(TransformerEncoder 或 ConformerEncoder),并传入配置参数初始化。 |
| 归一化与 Dropout 层 | 稳定训练过程,防止过拟合。 | - layer_norm:对特征提取器的输出进行层归一化。- dropout_input/dropout_features:对输入特征和未掩码特征应用 Dropout。 |
| 目标与投影层 | 处理量化目标和最终输出。 | - project_q:将量化器输出映射到 final_dim(最终特征维度)。- target_glu:可选的门控线性单元(GLU),增强目标特征的表达能力。- final_proj:将编码器输出映射到 final_dim,用于对比学习的预测。 |
2. 核心方法解析
Wav2Vec2Model 的方法实现了自监督学习的完整流程:从语音输入到特征提取、掩码、编码、目标生成,最终计算预测结果。
2.1 forward 方法(核心前向传播)
def forward(self,source, # 原始语音波形 (batch_size, seq_len)padding_mask=None, # 标记语音序列中的填充位置 (batch_size, seq_len)mask=True, # 是否启用掩码features_only=False, # 是否仅输出特征(用于下游任务)layer=None, # 指定输出某一层的特征# ... 其他参数 ...
):# ... 前向传播逻辑 ...
forward 是模型的主入口,实现了从原始语音到预测结果的完整流程,可分为以下步骤:
-
特征提取
使用feature_extractor处理原始语音波形,得到初始特征序列。若feature_grad_mult不等于 1.0,则通过GradMultiply缩放特征提取器的梯度(平衡不同模块的更新强度)。if self.feature_grad_mult > 0:features = self.feature_extractor(source)if self.feature_grad_mult != 1.0:features = GradMultiply.apply(features, self.feature_grad_mult) else:with torch.no_grad(): # 冻结特征提取器features = self.feature_extractor(source) -
特征预处理
- 对特征进行转置(
(batch, dim, time) → (batch, time, dim))和层归一化。 - 处理填充掩码(
padding_mask):根据语音序列长度计算特征序列的有效长度,生成特征级别的填充掩码。 - 裁剪特征序列长度至
crop_seq_to_multiple的倍数(适配后续编码器的并行计算)。
- 对特征进行转置(
-
特征投影与量化(可选)
- 若
post_extract_proj存在,将特征映射到编码器维度。 - 若启用输入量化(
input_quantizer),对特征进行量化并投影到编码器维度。
- 若
-
掩码应用
若mask=True,调用apply_mask方法对特征序列应用时间掩码或通道掩码,替换被掩盖位置为mask_emb或 0。 -
编码器处理
将掩码后的特征输入编码器(self.encoder),得到上下文相关表示。若features_only=True,直接返回特征(用于下游任务,如语音识别)。 -
目标生成与负例采样
- 若启用目标量化(
quantizer),将未掩码特征量化为离散目标(正例)。 - 调用
sample_negatives采样负例(同一样本内、跨样本或码本中的干扰项)。
- 若启用目标量化(
-
预测计算
通过compute_preds计算编码器输出(预测)与正例/负例的相似度(logits),用于后续对比损失计算。
2.2 apply_mask 方法(掩码策略实现)
掩码是 Wav2Vec 2.0 自监督学习的核心机制,通过随机掩盖部分特征,迫使模型学习上下文依赖以预测被掩盖的内容。
def apply_mask(self,x, # 特征序列 (batch, time, dim)padding_mask, # 填充掩码mask_indices=None, # 预定义的时间掩码索引mask_channel_indices=None, # 预定义的通道掩码索引
):# ... 掩码逻辑 ...return x, mask_indices # 掩码后的特征和掩码索引
- 时间掩码:随机选择时间步,用
mask_emb替换其特征值。掩码索引通过compute_mask_indices生成,参数由mask_prob(掩码概率)、mask_length(掩码长度)等控制。 - 通道掩码:随机选择特征通道(维度),将其值设为 0。可配置在时间掩码之前或之后应用(
mask_channel_before)。
2.3 sample_negatives 方法(负例采样)
对比学习需要正负例来优化模型对目标的判别能力。该方法为每个正例采样多个负例。
def sample_negatives(self, y, num, padding_count=None):# ... 负例采样逻辑 ...return negs, neg_idxs # 采样的负例和其索引
- 负例来源:
- 同一样本内的非目标位置(
num_negatives); - 其他样本的位置(
cross_sample_negatives); - 量化码本中的随机离散值(
codebook_negatives)。
- 同一样本内的非目标位置(
- 采样逻辑:通过随机索引生成负例,确保负例与正例不同(后续在
compute_preds中进一步过滤)。
2.4 compute_preds 方法(预测计算)
计算编码器输出(预测)与正例/负例的相似度,用于对比损失。
def compute_preds(self, x, y, negatives):# ... 相似度计算逻辑 ...return logits # 预测的logits(包含正例和负例的相似度)
- 采用余弦相似度衡量
x(编码器对掩码位置的预测)与y(正例)、negatives(负例)的相似性。 - 除以
logit_temp(温度系数)缩放相似度,使 softmax 分布更陡峭,增强判别性。 - 过滤与正例相同的负例(避免标签污染)。
2.5 其他关键方法
- _get_feat_extract_output_lengths:根据原始语音长度计算特征提取器输出的特征序列长度(用于对齐填充掩码)。
- quantize:仅使用量化器对输入语音进行量化(用于生成离散特征)。
- extract_features:提取编码器特征(用于下游任务微调,如语音识别中替换预训练特征)。
- remove_pretraining_modules:移除预训练相关模块(如量化器、目标投影层),用于下游任务微调(减少冗余参数)。
3. 模型核心逻辑总结
Wav2Vec2Model 实现了 Wav2Vec 2.0 的核心自监督学习范式,其工作流程可概括为:
- 特征提取:通过卷积层将原始语音转换为高维特征序列。
- 掩码干扰:随机掩盖部分特征(时间或通道维度),模拟“缺失信息”。
- 上下文编码:使用 Transformer/Conformer 编码器处理掩码后的特征,生成上下文相关表示。
- 目标生成:将未掩码特征量化为离散目标(正例),并采样负例。
- 对比学习:通过预测掩码位置的特征(与正例/负例对比),优化模型学习语音的鲁棒表示。
该类的设计体现了模块化和灵活性:通过配置参数可切换编码器类型(Transformer/Conformer)、掩码策略、量化方式等,既能支持自监督预训练,也能通过 extract_features 或 remove_pretraining_modules 适配下游任务(如语音识别、语音分类)。
3. 特征提取器(ConvFeatureExtractionModel)
ConvFeatureExtractionModel 是 Wav2Vec 2.0 模型中负责将原始语音波形转换为高维特征序列的核心组件,通过多层卷积操作实现从原始信号到抽象特征的提取。它是连接原始语音输入与后续编码器(Transformer/Conformer)的关键桥梁,其设计直接影响模型对语音特征的捕捉能力。以下是对该类的详细解析:
1. 类定义与初始化(init)
class ConvFeatureExtractionModel(nn.Module):def __init__(self,conv_layers: List[Tuple[int, int, int]], # 卷积层配置:[(输出维度, kernel大小, 步长), ...]dropout: float = 0.0, # dropout概率mode: str = "default", # 归一化模式:"default"或"layer_norm"conv_bias: bool = False, # 卷积层是否使用偏置):super().__init__()# ... 初始化逻辑 ...
- 继承自
nn.Module,是 PyTorch 中所有神经网络模块的基类。 - 核心参数
conv_layers定义了卷积层的结构,每个元素为(输出维度, kernel_size, stride)的元组,控制特征提取的层次和降采样率。
核心初始化逻辑
-
校验归一化模式:确保
mode为"default"或"layer_norm",两种模式对应不同的归一化策略。 -
定义卷积块生成函数(block):
内部嵌套函数block用于生成单个卷积块(包含卷积层、归一化、激活等),其参数包括:n_in:输入特征维度;n_out:输出特征维度;k:卷积核大小;stride:步长;- 归一化相关参数(
is_layer_norm/is_group_norm)。
每个卷积块的结构为:
卷积层 → Dropout → 归一化(可选) → GELU激活- 卷积层:使用
nn.Conv1d(1D卷积,适合处理语音等时序信号),通过kaiming_normal_初始化权重(适合ReLU/GELU等激活函数)。 - 归一化:
- 若
mode="default"且是第一层:使用组归一化(Fp32GroupNorm),组数等于输出维度(每个通道单独归一化)。 - 若
mode="layer_norm":使用层归一化(Fp32LayerNorm),需先通过TransposeLast交换维度(适应层归一化的输入格式)。
- 若
- 激活函数:固定使用 GELU(高斯误差线性单元,在Transformer等模型中表现优于ReLU)。
-
构建卷积层序列:
通过循环conv_layers配置,依次创建卷积块,存入self.conv_layers(nn.ModuleList)。初始输入维度为 1(原始语音波形是单通道信号),后续每层的输入维度为前一层的输出维度。
2. forward 方法(前向传播)
def forward(self, x):# BxT -> BxCxT(添加通道维度,C=1)x = x.unsqueeze(1)# 依次通过每个卷积块for conv in self.conv_layers:x = conv(x)return x
- 输入:原始语音波形,形状为
(batch_size, seq_len)(batch_size为批次大小,seq_len为语音时间步)。 - 步骤:
- 扩展维度:通过
unsqueeze(1)将输入从(B, T)转换为(B, 1, T),添加通道维度(语音为单通道信号)。 - 逐层处理:将信号依次输入每个卷积块,每一层的卷积操作会同时:
- 提升特征维度:输出维度由
conv_layers中定义的n_out决定(默认从 1 提升至 512)。 - 降低时间维度:通过步长(
stride)实现降采样,时间维度计算公式为:
output_len = floor((input_len - kernel_size) / stride + 1)
例如,默认配置中,7 层卷积会将原始语音的时间步压缩约 100 倍(适合后续编码器处理)。
- 提升特征维度:输出维度由
- 输出:最终特征形状为
(batch_size, final_dim, final_seq_len),其中final_dim是最后一层的输出维度(默认 512),final_seq_len是降采样后的时间步。
- 扩展维度:通过
3. 关键设计细节
3.1 卷积层配置(默认参数解析)
默认 conv_layers 为:
[(512, 10, 5)] + [(512, 3, 2)] * 4 + [(512, 2, 2)] + [(512, 2, 2)]
共 7 层卷积,逐步实现特征提取和降采样:
- 第 1 层:
(512, 10, 5)→ 输出维度 512,kernel=10,步长 5(时间维度压缩 5 倍)。 - 中间 4 层:
(512, 3, 2)→ 每层步长 2(时间维度压缩 2 倍/层,共压缩 2⁴=16 倍)。 - 最后 2 层:
(512, 2, 2)→ 每层步长 2(共压缩 2²=4 倍)。 - 总降采样率:5×16×4=320 → 原始语音(如 16kHz 采样率)经处理后,时间步对应约 50Hz(16000/320)的帧率,符合语音特征的时间分辨率需求。
3.2 归一化策略
- “default” 模式:仅第一层使用组归一化(
Fp32GroupNorm),组数=512(与输出维度相同,即每个通道单独归一化),后续层无归一化。这种设计保留了早期特征的局部多样性,适合捕捉语音的细粒度信息。 - “layer_norm” 模式:每层均使用层归一化(
Fp32LayerNorm),通过跨通道归一化稳定训练,适合需要更强正则化的场景。
3.3 与后续模块的衔接
特征提取器的输出形状为 (B, C, T),而后续编码器(Transformer/Conformer)需要 (B, T, C) 格式的输入。因此,在 Wav2Vec2Model 的 forward 方法中,会通过 features = features.transpose(1, 2) 将维度转换为 (B, T, C),再传入编码器。
4. 功能总结
ConvFeatureExtractionModel 的核心作用是将原始语音波形转换为高维、低时间分辨率的特征序列,具体表现为:
- 特征抽象:通过多层卷积逐步提取语音的层次化特征(从低级的频谱特征到高级的声学特征)。
- 降采样:通过大步长卷积显著减少时间维度,降低后续编码器的计算压力,同时保留关键时序信息。
- 归一化:通过组归一化或层归一化稳定训练,增强模型对输入变化的鲁棒性。
该组件是 Wav2Vec 2.0 从原始信号到语义特征的“第一道加工工序”,其设计直接影响模型对语音细节的捕捉能力,是后续自监督学习(掩码、量化、对比学习)的基础。
4. 编码器(TransformerEncoder / ConformerEncoder)
在 Wav2Vec 2.0 模型中,编码器(TransformerEncoder 和 ConformerEncoder)是将特征提取器输出的局部特征转换为上下文相关表示的核心组件。它们负责捕捉语音序列中的长距离依赖关系,为后续的自监督学习(掩码预测、对比学习)提供高-level 特征。其中,TransformerEncoder 基于标准 Transformer 结构,ConformerEncoder 则结合了 Transformer 注意力和卷积模块,更适合语音等时序信号。以下是详细解析:
1. TransformerEncoder:基于 Transformer 的编码器
TransformerEncoder 是通用编码器基类,支持多种层类型(纯 Transformer、带适配器的 Transformer 等),核心是通过多层自注意力和前馈网络捕捉序列上下文。
1.1 类定义与初始化(init)
class TransformerEncoder(nn.Module):def __init__(self, args: Wav2Vec2Config, skip_pos_conv: bool = False, override_encoder_layer: int = None):super().__init__()self.dropout = args.dropoutself.embedding_dim = args.encoder_embed_dim # 编码器输入/输出维度self.required_seq_len_multiple = args.required_seq_len_multiple # 序列长度需满足的倍数(并行计算用)# 初始化位置卷积(用于添加位置信息)pos_conv_depth = getattr(args, "pos_conv_depth", 1)if pos_conv_depth > 1:# 多层位置卷积self.pos_conv = make_conv_block(...) # 堆叠多层卷积捕捉位置信息elif skip_pos_conv:self.pos_conv = None # 不使用位置卷积else:# 单层位置卷积self.pos_conv = make_conv_pos(...) # 用卷积生成位置编码# 初始化编码器层encoder_layers = args.encoder_layers if override_encoder_layer is None else override_encoder_layerself.layers = nn.ModuleList([self.build_encoder_layer(args, layer_idx=ii) for ii in range(encoder_layers)])self.layer_norm_first = args.layer_norm_first # 层归一化位置(前/后)self.layer_norm = LayerNorm(self.embedding_dim) # 最终层归一化self.layerdrop = args.encoder_layerdrop # 层丢弃概率(正则化)self.apply(init_bert_params) # BERT风格参数初始化
核心初始化逻辑:
- 位置卷积(pos_conv):通过 1D 卷积生成位置编码,捕捉序列中位置的局部依赖(替代传统的正弦余弦位置编码)。支持单层或多层卷积,参数由
conv_pos(滤波器数量)、conv_pos_groups(分组数)控制。 - 编码器层(layers):通过
build_encoder_layer方法构建多层编码器,层数由encoder_layers决定。 - 层归一化与正则化:包含层归一化(
layer_norm)和层丢弃(layerdrop,随机丢弃整个层以增强鲁棒性)。
1.2 核心方法:build_encoder_layer(构建编码器层)
该方法根据配置(layer_type)选择不同的编码器层类型,是灵活性的核心:
def build_encoder_layer(self, args: Wav2Vec2Config, **kwargs):if args.layer_type == "transformer":# 标准Transformer层layer = TransformerSentenceEncoderLayer(embedding_dim=self.embedding_dim,ffn_embedding_dim=args.encoder_ffn_embed_dim,num_attention_heads=args.encoder_attention_heads,dropout=self.dropout,attention_dropout=args.attention_dropout,activation_dropout=args.activation_dropout,activation_fn=args.activation_fn,layer_norm_first=args.layer_norm_first,)elif args.layer_type == "conformer":# Conformer层(结合注意力和卷积)layer = ConformerWav2Vec2EncoderLayer(...)elif args.layer_type == "trf_adp":# 带适配器(Adapter)的Transformer层(迁移学习用)use_adp = ... # 根据配置判断是否启用适配器if use_adp:layer = TransformerSentenceEncoderWithAdapterLayer(...) # 含适配器else:layer = TransformerSentenceEncoderLayer(...) # 标准层# 分布式训练与激活检查点包装layer = fsdp_wrap(layer) # FSDP分布式包装if args.checkpoint_activations:layer = checkpoint_wrapper(layer) # 激活检查点(节省内存)return layer
支持的层类型:
transformer:标准 Transformer 编码器层(TransformerSentenceEncoderLayer),包含多头自注意力和前馈网络(FFN)。conformer:Conformer 层(ConformerWav2Vec2EncoderLayer),在 Transformer 基础上增加深度可分离卷积,增强局部特征捕捉。trf_adp:带适配器的 Transformer 层(TransformerSentenceEncoderWithAdapterLayer),在标准层中插入适配器模块,用于迁移学习(微调时仅更新适配器参数)。
####** 1.3 核心方法:extract_features(特征提取与前向传播)**该方法是编码器的核心前向逻辑,将输入特征转换为上下文相关表示:
def extract_features(self,x, # 输入特征 (batch_size, seq_len, embed_dim)padding_mask=None, # 填充掩码 (batch_size, seq_len)tgt_layer=None, # 输出指定层的特征min_layer=0,corpus_key=None, # 适配器的语料/任务标识(trf_adp层用)
):# 填充位置置零if padding_mask is not None:x = index_put(x, padding_mask, 0)# 应用位置卷积(添加位置信息)if self.pos_conv is not None:x_conv = self.pos_conv(x.transpose(1, 2)) # (B, T, C) → (B, C, T) 适配卷积x_conv = x_conv.transpose(1, 2) # 转回 (B, T, C)x = x + x_conv # 残差连接添加位置信息# 层归一化(位置根据layer_norm_first决定)if not self.layer_norm_first:x = self.layer_norm(x)# 补齐序列长度至required_seq_len_multiple的倍数(并行计算需求)x, pad_length = pad_to_multiple(x, self.required_seq_len_multiple, dim=-2)# 同步调整填充掩码if pad_length > 0 and padding_mask is not None:padding_mask = ... # 扩展掩码以匹配补齐后的长度x = F.dropout(x, p=self.dropout, training=self.training) # 输入dropoutx = x.transpose(0, 1) # (B, T, C) → (T, B, C)(适配Transformer的时序优先格式)layer_results = [] # 存储各层输出r = None # 目标层输出for i, layer in enumerate(self.layers):# 层丢弃(随机跳过某些层,增强鲁棒性)if self.training and self.layerdrop > 0 and np.random.random() < self.layerdrop:continue# 前向传播通过当前层if isinstance(layer, FullyShardedDataParallel):layer_unwrapped = layer.unwrapped_module # 分布式包装的层需解包else:layer_unwrapped = layer# 带适配器的层需要传入corpus_key选择适配器if hasattr(layer_unwrapped, "adapter_layer") and corpus_key is not None:x, (z, lr) = layer(x, self_attn_padding_mask=padding_mask, need_weights=False, corpus_key=corpus_key)else:x, (z, lr) = layer(x, self_attn_padding_mask=padding_mask, need_weights=False)# 记录指定层的输出if i >= min_layer:layer_results.append((x, z, lr))if i == tgt_layer: # 若指定目标层,提前退出r = xbreakif r is not None:x = r # 输出目标层特征x = x.transpose(0, 1) # (T, B, C) → (B, T, C)(恢复批次优先格式)# 移除补齐的长度if pad_length > 0:x = x[:, :-pad_length]layer_results = [undo_pad(*u) for u in layer_results] # 同步调整层输出return x, layer_results
前向流程解析:
1.** 填充处理 :将填充位置的特征置零,避免其影响注意力计算。
2. 位置信息注入 :通过 pos_conv 生成位置编码,并与输入特征相加(残差连接)。
3. 归一化与补齐 :根据 layer_norm_first 应用层归一化,并补齐序列长度至指定倍数(适配并行计算)。
4. 层迭代 :依次通过各编码器层,支持层丢弃(layerdrop)正则化;若为带适配器的层,通过 corpus_key 选择对应适配器。
5. 输出处理**:恢复序列长度(移除补齐部分),返回最终特征或指定层的特征。
2. ConformerEncoder:基于 Conformer 的编码器
ConformerEncoder 继承自 TransformerEncoder,专为语音处理优化,结合了 Transformer 自注意力(捕捉长距离依赖)和卷积(捕捉局部结构),在语音任务中性能优于纯 Transformer。
2.1 类定义与初始化(init)
class ConformerEncoder(TransformerEncoder):def __init__(self, args):super().__init__(args)self.args = argsself.pos_enc_type = args.pos_enc_type # 位置编码类型max_source_positions = self.max_positions()# 初始化位置编码(Conformer专用)if self.pos_enc_type == "rel_pos":self.embed_positions = RelPositionalEncoding( # 相对位置编码max_source_positions, self.embedding_dim)elif self.pos_enc_type == "rope":self.embed_positions = None # 旋转位置编码(在注意力层内实现)else:raise Exception("Unsupported positional encoding type")# 构建Conformer层self.layers = nn.ModuleList([self.build_encoder_layer(args) for _ in range(args.encoder_layers)])# 其他初始化(层归一化、层丢弃等与父类一致)
核心差异:
- 位置编码:放弃
TransformerEncoder的卷积位置编码,改用更适合语音的相对位置编码(rel_pos)或旋转位置编码(rope)。 - 层类型固定:仅使用
ConformerWav2Vec2EncoderLayer作为编码器层。
2.2 重写的 build_encoder_layer 方法
def build_encoder_layer(self, args):layer = ConformerWav2Vec2EncoderLayer(embed_dim=self.embedding_dim,ffn_embedding_dim=args.encoder_ffn_embed_dim,attention_heads=args.encoder_attention_heads,dropout=args.dropout,depthwise_conv_kernel_size=args.depthwise_conv_kernel_size, # 深度卷积核大小activation_fn="swish", # Conformer常用swish激活attn_type=args.attn_type,pos_enc_type=args.pos_enc_type, # 位置编码类型use_fp16=args.fp16,)# 分布式与检查点包装(同父类)layer = fsdp_wrap(layer)if args.checkpoint_activations:layer = checkpoint_wrapper(layer)return layer
Conformer层特点:
ConformerWav2Vec2EncoderLayer 结构为:输入归一化 → 自注意力 → 残差连接 → 中间归一化 → 深度可分离卷积 → 残差连接 → 输出归一化 → 前馈网络 → 残差连接。其中,深度可分离卷积(大 kernel,如 31)专门用于捕捉语音的局部频谱-时序结构,弥补纯注意力对局部依赖建模的不足。
2.3 重写的 extract_features 方法
def extract_features(self, x, padding_mask=None, tgt_layer=None):if padding_mask is not None:x = index_put(x, padding_mask, 0) # 填充位置置零x = x.transpose(0, 1) # (B, T, C) → (T, B, C)(时序优先)# 生成位置嵌入(相对位置编码需提前计算)position_emb = Noneif self.pos_enc_type == "rel_pos":position_emb = self.embed_positions(x) # 相对位置编码# 层归一化(位置与父类相反,Conformer通常先归一化)if not self.layer_norm_first:x = self.layer_norm(x)x = F.dropout(x, p=self.dropout, training=self.training)layer_results = []r = Nonefor i, layer in enumerate(self.layers):# 层丢弃if self.training and self.layerdrop > 0 and np.random.random() < self.layerdrop:continue# Conformer层前向传播(需传入位置嵌入)x, z = layer(x,self_attn_padding_mask=padding_mask,need_weights=False,position_emb=position_emb, # 传入位置编码)if tgt_layer is not None:layer_results.append((x, z))if i == tgt_layer:r = xbreakif r is not None:x = rx = x.transpose(0, 1) # 恢复 (B, T, C)return x, layer_results
核心差异:
- 位置编码处理:相对位置编码(
rel_pos)需提前生成并传入每层;旋转位置编码(rope)则在注意力层内部动态计算。 - 适配 Conformer 层:前向传播时需将位置嵌入(
position_emb)传入每层,供 Conformer 层的注意力模块使用。
3. 编码器的核心作用与总结
编码器是 Wav2Vec 2.0 从“局部特征”到“上下文特征”的关键转换模块,其核心作用是:
- 捕捉上下文依赖:通过自注意力机制建模语音序列中的长距离依赖(如语音中的音素关联、韵律结构)。
- 增强特征表达:通过多层非线性变换,将特征提取器输出的低级声学特征转换为高级语义特征。
- 适配语音特性:Conformer 版本通过卷积模块增强局部特征捕捉,更适合语音这种具有强局部相关性的信号。
两者的选择取决于任务需求:纯 Transformer 适合需要强长距离依赖建模的场景,而 Conformer 在语音任务中通常表现更优。编码器的输出最终用于掩码位置的预测(自监督学习),或作为下游任务(如语音识别)的输入特征。
5. 适配器模块(AdapterFast)
适配器模块(AdapterFast)是 Wav2Vec 2.0 模型中用于迁移学习与多任务适配的轻量级组件,核心作用是在不显著增加模型参数总量的前提下,通过微调少量新增参数使预训练模型快速适配下游任务(如特定领域的语音识别、语音分类等)。其设计遵循“冻结预训练参数,仅更新适配器参数”的原则,既保留了预训练模型的通用知识,又能针对新任务进行定制化优化。
1. 类定义与核心设计思路
class AdapterFast(nn.Module):def __init__(self,input_dim: int, # 输入特征维度(需与编码器层输出维度匹配)adapter_dim: int = 64, # 适配器瓶颈维度(通常远小于input_dim,如64)activation: str = "relu", # 激活函数类型dropout: float = 0.0, # Dropout概率bias: bool = True, # 线性层是否使用偏置):super().__init__()self.input_dim = input_dimself.adapter_dim = adapter_dim# 瓶颈结构:降维 → 激活 → 升维self.down_proj = nn.Linear(input_dim, adapter_dim, bias=bias) # 降维线性层self.activation = utils.get_activation_fn(activation) # 激活函数(如ReLU、Swish)self.dropout = nn.Dropout(dropout) # Dropout层(正则化)self.up_proj = nn.Linear(adapter_dim, input_dim, bias=bias) # 升维线性层# 层归一化(稳定适配器输出)self.layer_norm = LayerNorm(input_dim)# 初始化参数(升维层初始化为0,避免初始时干扰原有特征)nn.init.zeros_(self.up_proj.weight)if bias:nn.init.zeros_(self.up_proj.bias)
核心设计思路:
采用“瓶颈(Bottleneck)”结构,通过“降维→非线性变换→升维”的流程,以极少的参数实现对特征的任务特异性调整:
- 降维(down_proj):将高维输入特征(如编码器输出的768维)压缩到低维瓶颈(如64维),大幅降低计算量。
- 非线性变换:通过激活函数(如ReLU)引入任务相关的非线性特征。
- 升维(up_proj):将瓶颈特征恢复到原始输入维度,确保能与原特征进行残差连接。
- 残差连接:适配器输出与输入特征相加,保留预训练模型的原始特征,仅叠加任务特异性调整。
2. forward 方法(前向传播)
def forward(self, x):# x: 输入特征,形状为 (batch_size, seq_len, input_dim)residual = x # 保存输入特征用于残差连接# 层归一化(稳定输入分布)x = self.layer_norm(x)# 瓶颈变换:降维 → 激活 → Dropout → 升维x = self.down_proj(x) # (B, T, input_dim) → (B, T, adapter_dim)x = self.activation(x)x = self.dropout(x)x = self.up_proj(x) # (B, T, adapter_dim) → (B, T, input_dim)# 残差连接:适配器输出 + 原始输入x = x + residualreturn x
前向流程解析:
- 残差保留:先保存输入特征
residual,用于后续残差连接,确保预训练特征不被完全覆盖。 - 层归一化:对输入特征进行归一化,稳定适配器的输入分布,避免因输入波动影响训练。
- 瓶颈变换:通过降维、激活、升维的组合,学习任务特异性的特征调整(如强调新任务中的关键声学特征)。
- 残差融合:适配器的输出与原始输入相加,既保留预训练模型的通用知识,又融入任务特异性信息。
3. 关键设计细节
3.1 参数效率
适配器的参数总量极少,以 input_dim=768、adapter_dim=64 为例:
- 降维层参数:
768×64 + 64 = 49216(含偏置) - 升维层参数:
64×768 + 768 = 49728(含偏置) - 总计约 9.8 万参数,仅为编码器单一层(约 1000 万参数)的 1%,大幅降低微调成本。
3.2 初始化策略
升维层(up_proj)的权重和偏置初始化为 0,确保适配器在初始状态下输出为 0(x = 0 + residual),完全保留原始特征,避免对预训练模型的初始性能造成干扰。随着训练进行,适配器逐渐学习到任务相关的调整。
3.3 与主模型的集成方式
AdapterFast 通常插入在编码器层(如 TransformerSentenceEncoderLayer 或 ConformerWav2Vec2EncoderLayer)的特定位置,形成带适配器的编码器层(TransformerSentenceEncoderWithAdapterLayer)。常见插入位置包括:
- 自注意力模块输出后
- 前馈网络(FFN)输出后
- 注意力与 FFN 之间
通过这种“即插即用”的设计,可灵活控制适配器对特征的调整时机。
4. 适配器的核心作用与优势
- 迁移学习效率:无需微调整个预训练模型,仅优化适配器的少量参数即可适配新任务,显著降低计算资源需求,尤其适合小数据集场景(避免过拟合)。
- 多任务兼容性:可为不同任务(或不同语料库)设计独立的适配器(通过
corpus_key区分),实现“一模型多任务”,且任务间参数隔离,避免相互干扰。 - 保留预训练知识:残差连接确保预训练模型学到的通用语音特征不被破坏,适配器仅在此基础上补充任务特异性信息,兼顾通用性与特异性。
5. 总结
AdapterFast 是 Wav2Vec 2.0 模型中针对迁移学习优化的轻量级模块,通过“瓶颈结构+残差连接”的设计,以极少参数实现预训练模型对下游任务的快速适配。其核心价值在于平衡了模型性能与微调成本,使预训练模型能高效应用于多样化的语音任务(如低资源语音识别、方言识别等),是工业界部署预训练模型的重要技术选择。
6. 自监督学习关键机制
Wav2Vec 2.0的自监督学习机制是其能从无标注语音数据中学习通用语音特征的核心,通过掩码干扰、离散量化和对比学习三大关键策略,构建了一个“从上下文预测被掩盖信息”的自监督任务。这些机制协同工作,迫使模型捕捉语音中的音素、韵律、时序依赖等关键结构,最终生成可迁移到下游任务(如语音识别、情感分析)的鲁棒特征。以下是具体解析:
1. 掩码策略(Masking):创造“预测任务”
掩码是自监督学习的“任务发生器”,通过随机掩盖语音特征序列中的部分内容,迫使模型利用上下文信息预测被掩盖的部分。Wav2Vec 2.0设计了时间掩码和通道掩码两种方式,模拟语音信号中可能缺失的信息。
1.1 时间掩码(Temporal Masking)
针对语音的时序特性,随机掩盖连续的时间步(即语音片段),让模型学习“根据前后语音推断中间缺失部分”的能力。
- 核心逻辑:
从特征序列(形状为(batch_size, seq_len, dim))中随机选择若干连续片段,用一个可学习的“掩码嵌入向量”(mask_emb)替换被掩盖位置的特征值。 - 关键参数(由
Wav2Vec2Config控制):mask_prob:被掩码覆盖的时间步比例(默认65%,确保足够的预测压力)。mask_length:单个掩码片段的长度(默认10,可通过mask_selection从均匀/正态/泊松分布中采样)。no_mask_overlap:是否禁止掩码片段重叠(默认不禁止,增加任务复杂度)。
- 示例:若原始特征序列为
[f1, f2, f3, f4, f5, f6],时间掩码可能将[f2, f3]替换为mask_emb,得到[f1, mask_emb, mask_emb, f4, f5, f6],模型需根据f1, f4, f5, f6预测f2, f3。
1.2 通道掩码(Channel Masking)
针对特征的维度(通道),随机掩盖连续的特征维度,让模型学习“跨通道互补信息”的利用能力(类似图像中的通道 dropout)。
- 核心逻辑:随机选择若干连续的特征维度(如从512维中掩盖第10-20维),将被掩盖通道的值设为0。
- 关键参数:
mask_channel_prob:被掩盖的通道比例(默认0,即不启用,可根据任务调整)。mask_channel_before:通道掩码在时间掩码之前还是之后应用(控制干扰顺序)。
- 作用:增强模型对特征通道冗余性的鲁棒性,避免过度依赖特定通道的特征。
2. 量化目标生成(Quantization):构建“可预测的离散目标”
原始语音特征是连续值,直接预测难度大。Wav2Vec 2.0通过Gumbel向量量化器(GumbelVectorQuantizer) 将连续特征转换为离散“码本”(codebook),作为自监督学习的预测目标,降低学习难度并增强特征的判别性。
2.1 量化器工作原理
量化器将编码器输出的连续特征(未被掩码的部分)映射到一组离散的“潜在变量”(latent variables),过程如下:
- 特征分组:将输入特征的维度(如512维)拆分为
latent_groups个组(默认2组,每组256维),并行量化以降低计算量。 - Gumbel-softmax离散化:对每组特征,通过线性层投影到
latent_vars个潜在变量(默认320个),再用Gumbel-softmax采样(一种“软离散化”方法)选择最可能的变量,既保留梯度可导性,又接近离散值。 - 码本输出:每个组的量化结果拼接后,通过投影层(
project_q)映射到最终维度(final_dim),作为预测目标(正例)。
2.2 量化的核心作用
- 简化预测任务:连续特征空间无限,而离散码本是有限集合(如320个选择),大幅降低预测难度。
- 增强特征判别性:量化过程强制模型学习“哪些特征属于同一离散类别”,使特征更具语义区分度(如不同音素对应不同码本)。
- 稳定性:离散目标受噪声影响更小,训练更稳定。
3. 对比学习(Contrastive Learning):优化“预测能力”
对比学习是模型参数更新的核心驱动力,通过让模型区分“正例”(被掩码位置的真实量化目标)和“负例”(干扰项),学习对语音特征的精确判别能力。
3.1 正负例定义
- 正例(Positive):被掩码位置对应的真实量化目标(即未掩码特征经量化器处理后的结果)。
- 负例(Negative):干扰项,用于与正例对比,包括:
- 同一样本内负例:从同一样本的非掩码位置采样(默认100个,
num_negatives控制)。 - 跨样本负例:从其他样本的任意位置采样(
cross_sample_negatives控制,增加负例多样性)。 - 码本负例:从量化器的码本中随机采样(
codebook_negatives控制,增强对码本的学习)。
- 同一样本内负例:从同一样本的非掩码位置采样(默认100个,
3.2 对比损失计算(InfoNCE Loss)
损失函数的核心是最大化正例与模型预测的相似度,同时最小化负例与预测的相似度,公式如下:
Loss=−log(exp(s(y^,y+)/τ)exp(s(y^,y+)/τ)+∑n=1Nexp(s(y^,yn−)/τ))
\text{Loss} = -\log\left(\frac{\exp(s(\hat{y}, y^+)/\tau)}{\exp(s(\hat{y}, y^+)/\tau) + \sum_{n=1}^N \exp(s(\hat{y}, y_n^-)/\tau)}\right)
Loss=−log(exp(s(y^,y+)/τ)+∑n=1Nexp(s(y^,yn−)/τ)exp(s(y^,y+)/τ))
其中:
- y^\hat{y}y^ 是模型对掩码位置的预测(编码器输出经
final_proj投影的结果)。 - y+y^+y+ 是正例(真实量化目标),yn−y_n^-yn− 是负例。
- s(a,b)s(a, b)s(a,b) 是余弦相似度(衡量特征相似性)。
- τ\tauτ 是温度系数(
logit_temp,默认0.1,缩小相似度范围,使softmax更“陡峭”,增强判别性)。
3.3 学习过程
模型通过编码器对掩码后的特征序列进行编码,得到掩码位置的预测 y^\hat{y}y^;将 y^\hat{y}y^ 与正例 y+y^+y+、负例 yn−y_n^-yn− 计算相似度后,通过InfoNCE损失优化参数。随着训练进行,模型逐渐学会从上下文准确推断被掩盖位置的特征,最终捕捉到语音的内在结构(如音素、音节的时序关系)。
4. 三大机制的协同作用
Wav2Vec 2.0的自监督学习是一个“三位一体”的闭环:
- 掩码策略制造信息缺失,创造“必须通过上下文推断”的任务;
- 量化器将连续特征转换为离散目标,提供可预测的“答案”;
- 对比学习通过正负例对比,驱动模型优化对“答案”的预测能力。
三者协同迫使模型学习语音的鲁棒上下文表示——既能捕捉局部声学特征(如音素),又能建模长距离时序依赖(如语句中的语法结构),这正是其在下游任务中表现优异的核心原因。
总结
自监督学习机制是Wav2Vec 2.0的“灵魂”,通过掩码、量化和对比学习的巧妙设计,实现了从无标注语音数据中学习通用特征的突破。这种设计既适应了语音信号的时序特性(时间掩码),又降低了自监督任务的难度(离散量化),同时通过对比学习保证了特征的判别性。最终,预训练模型能为语音识别、语音分类等下游任务提供高质量的初始化特征,大幅降低对标注数据的依赖。
总结
该代码实现了 Wav2Vec 2.0 模型的完整结构,涵盖特征提取、掩码、编码、量化、对比学习等核心组件,支持 Transformer/Conformer 编码器和适配器模块,适用于语音的自监督预训练及下游任务微调(如语音识别、语音分类)。配置参数丰富,可灵活调整模型结构和训练策略,是语音自监督学习的经典实现。