计算机体系结构之流水线与指令级并行
文章目录
- 前言
- 一、流水线定义和分类
- 1.1 流水线相关定义
- 1.2 流水线分类
- 1.3 流水线时空图以及性能分析
- 二、经典5段流水线RISC处理器
- 三、流水线中的冒险问题
- 3.1 结构冒险
- 3.2 数据冒险
- 3.3 控制冒险
- 四、流水线处理机及其设计
- 4.1 流水线模型扩展
- 4.2 数据冒险的解决
- 4.3 控制冒险的解决
- 4.4流水线中异常事件的处理
- 4.5 精确异常和非精确异常
- 五、指令级并行
- 1.1 静态多发射处理器
- 1.2 动态多发射处理器
- 结束语
- 💂 个人主页:风间琉璃
- 🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有
帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
前言
提示:这里可以添加本文要记录的大概内容:
一、流水线定义和分类
1.1 流水线相关定义
流水线是利用执行指令操作之间的并行性,实现多条指令重叠执行的技术。流水线是实现更快CPU的基本和关键技术。
机器周期(流水线周期):指令沿流水线移动一个流水段的时间。长度取决于最慢的流水段,一般是一个时钟周期(有时是两个时钟周期)。每个流水线周期从指令流水线流出一条指令。CPI还是为1。
吞吐量:单位时间从流水线流出的指令数。
一个流水线有多个段(级),段间有流水线寄存器。每个流水段执行指令或操作的不同部分
流水段之间采用同步时钟控制,一条指令或操作从流水线一端进入,经过各段,从另一端流出。流水线是开发串行指令流中并行性的一种实现技术
为了实现并行需要解决下面三个问题:
(1)为了实现取指、分析指令、执行指令同时进行,需要有对应的独立部件。需使用流水线锁存器暂存中间结果。
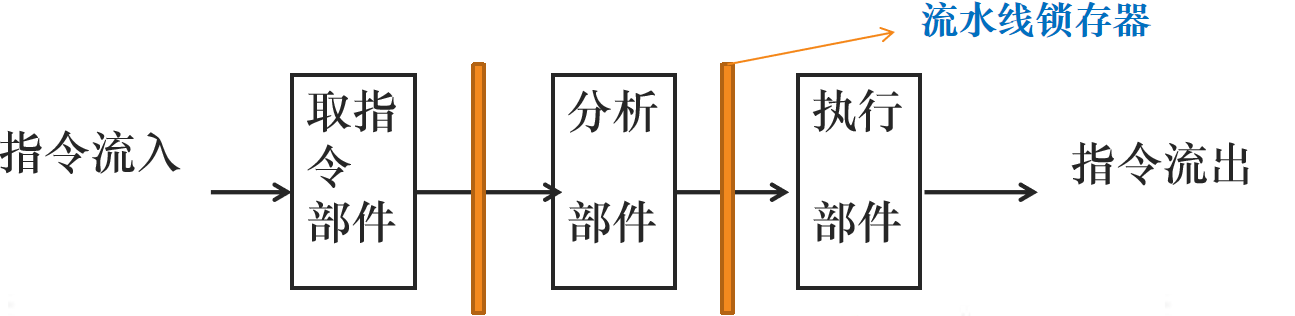
(2)尽量缩短各个功能部件的运行速度,使得大致相等,避免在重叠中相互等待。
(3)主存访问冲突。例如,取指令k+1时需访存,分析指令k时可能也需要取操作数访存。
解决访存冲突,主要有3种解决办法:
- 将主存分为两个独立编址的存储器:指令存储器和数据存储器,CPU可分别独立访问。
- 低位交叉存取方式:可并行访问不在同一个存储体中的指令或数据。
- 指令预取:在重叠操作中,当前一条指令在执行过程中就需要提前取出后面的指令进行相应处理,这种提前取出后继指令进行相应处理,称为先行(预取)。
1.2 流水线分类
(1)按各过程段用时是否相等分类
- 均匀流水线指的是各过程段用时全相等的流水线。
- 非均匀流水线指的是各过程段用时不全相等的流水线。
(2)按处理的数据类型
- 标量流水线用于对标量数据进行流水处理。
- 向量流水线:用于对向量数据进行流水处理。(向量很适合流水处理)
(3)按流水线的规模
- 操作流水线是把处理机的算术逻辑部件分段,使得各种数据类型的操作能够进行流水,规模最小。
- 指令流水线则是把执行指令的过程按照流水方式处理。
- 宏流水线它是指由两个以上的处理机串行地对同一数据流进行处理,每个处理机完成一项任务。
(4)按功能分类(流水线完成的功能是否单一)
- 单功能流水线:只能完成一种固定功能的流水线。例如,浮点加法器流水线专门完成浮点加法运算,浮点乘法器流水线专门完成浮点乘法运算。
- 多功能流水线:流水线的各段可以进行不同的连接,以实现不同的功能。
(5)按工作方式分类(在多功能流水线上)
-
静态流水线:在同一时间内,多功能流水线中的各段只能按同一种功能的连接方式工作。区别单功能流水线。对于静态流水线来说,只有当输入的是一串相同的运算任务时,流水的效率才能得到充分的发挥。
-
动态流水线:在同一时间内,**多功能流水线中的各段可以按照不同的方式连接,同时执行多种功能。**优点:灵活,能够提高流水线各段的使用率,从而提高处理速度。缺点:控制复杂。
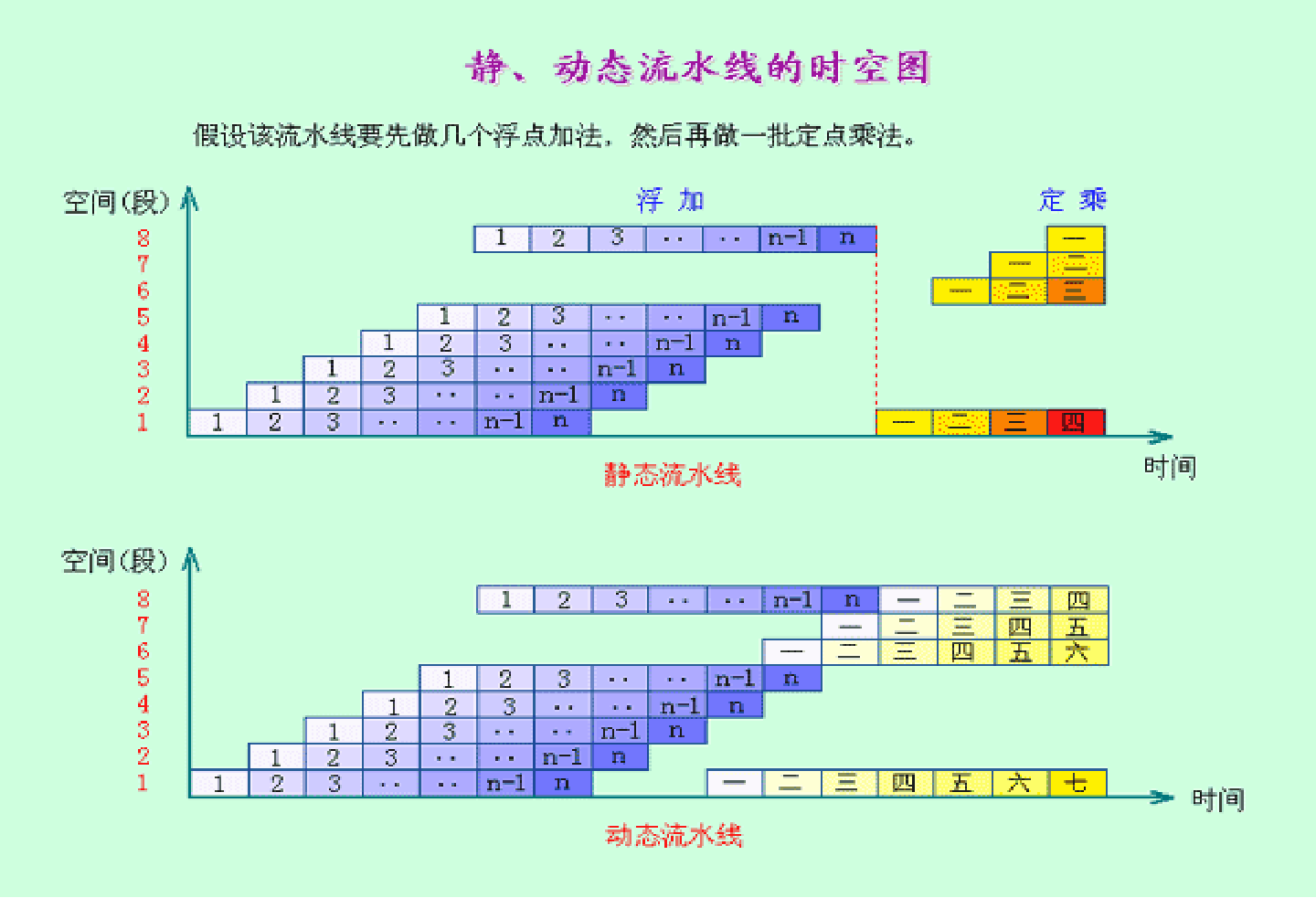
(6)按连接方式分类(流水线的各个功能段之间是否有反馈信号)
- 线性流水线:流水线的各段串行连接,没有反馈回路。数据通过流水线中的各段时,每一个段最多只流过一次。
- 非线性流水线:流水线中除了有串行的连接外,还有反馈回路。
根据控制方式分成顺序流水线和乱序流水线。在线性流水线中,根据控制方式还可以分成同步流水线和异步流水线。
流水线的特点
1.流水线处理的最好是连续任务,只有连续不断的任务才能充分发挥流水线的效率。
2.流水线依靠多个功能部件并行工作缩短程序的执行时间,实际上是把一个大的功能部件分解为多个子过程,如前述将浮点数加法器分解为4个子过程。
3.流水线中的每一功能部件后面都要有一个缓冲寄存器,即所谓的锁存器,以便平滑各个功能段延时时间的不一致。
4.流水线中各段时间应尽量相等,避免段延时过长引起的相互等待。
5.流水线需要有“装入时间”和“排空时间”。
1.3 流水线时空图以及性能分析
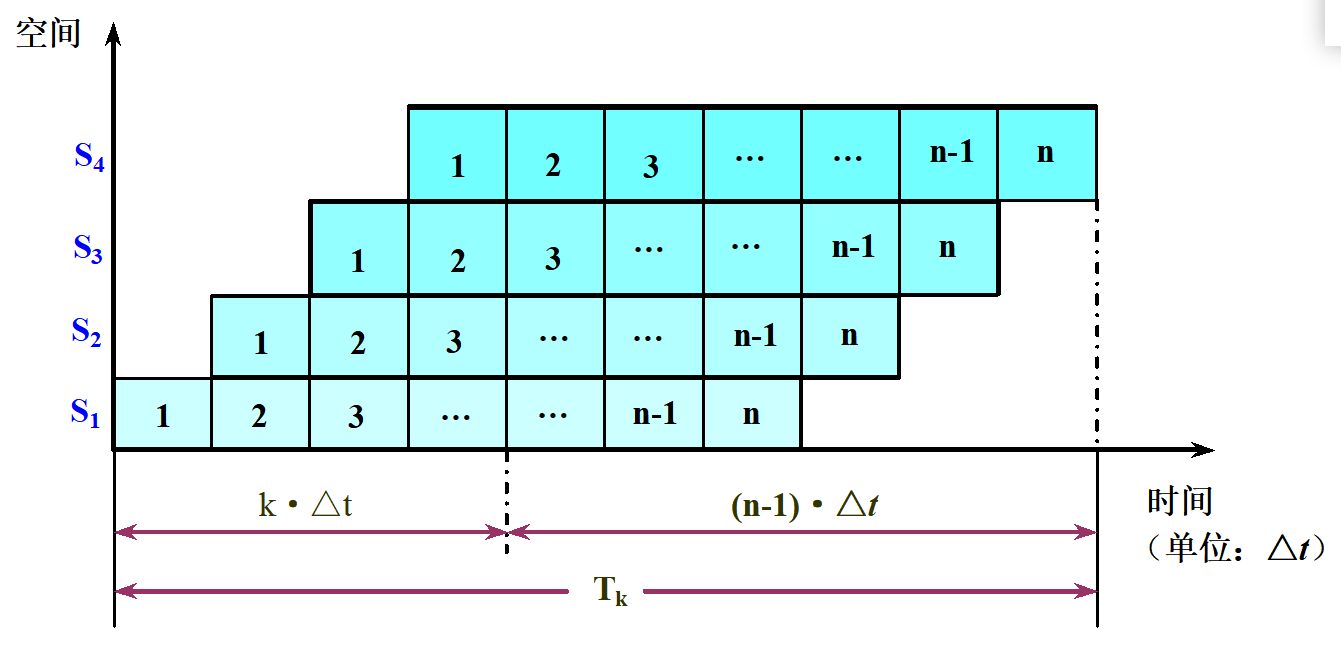
时空图从时间和空间两个方面描述了流水线的工作过程。时空图中,横坐标代表时间,纵坐标代表流水线的各个段。 4段指令流水线的时空图如下所示:
(1)吞吐率:在单位时间内流水线所完成的任务数量或输出结果的数量。
TP=nTKTP = \frac{n}{T_K} TP=TKn
n:任务数。Tk:处理完成n个任务所用的时间。k是流水线段数。
如上图所示,假设一条k段线性流水线,流水线完成n个连续任务所需要的总时间为
Tk=kΔt+(n−1)Δt=(k+n−1)ΔtT_k=kΔt+(n-1)Δt=(k+n-1)Δt Tk=kΔt+(n−1)Δt=(k+n−1)Δt
所以最大吞吐率为1Δt\frac{1}{\Delta t}Δt1:
TPmax=limn→∞n(k+n−1)Δt=1ΔtT P_{\max }=\lim _{n \rightarrow \infty} \frac{n}{(k+n-1) \Delta t}=\frac{1}{\Delta t} TPmax=n→∞lim(k+n−1)Δtn=Δt1
流水线的实际吞吐率小于最大吞吐率,它除了与每个段的时间有关外,还与流水线的段数k以及输入到流水线中的任务数n有关。
各段时间不完全相等的流水线,一条4段的流水线,S1,S3,S4各段的时间:Δt。S2的时间:3Δt (瓶颈段)。流水线中这种时间最长的段称为流水线的瓶颈段。
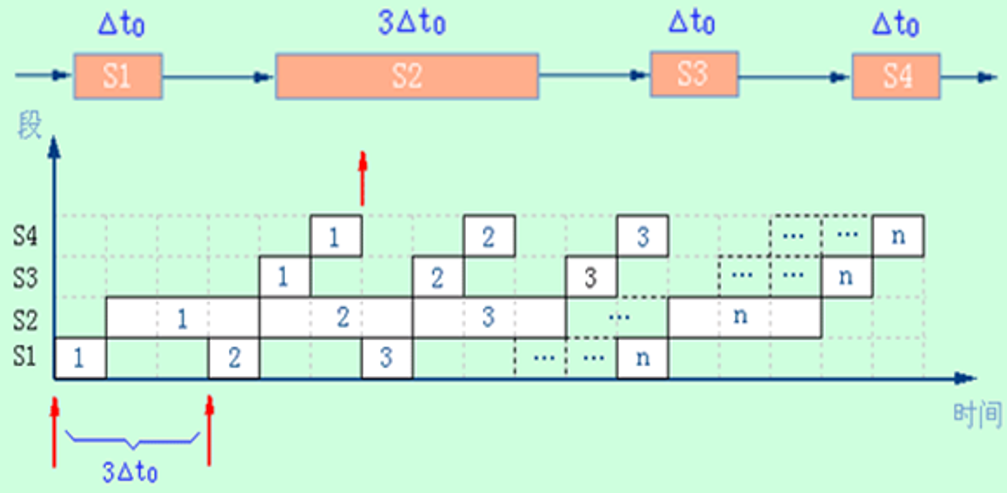
解决流水线瓶颈问题的常用方法:细分瓶颈段和重复设置瓶颈段。
(2)流水线的加速比是完成某个任务顺序执行所用时间与流水线执行所用时间之比。 假设不使用流水线(即顺序执行)所用的时间为Ts,使用流水线后所用的时间为Tk,则该流水线的加速比为
S=TSTkS=\frac{T_S}{T_k} S=TkTS
流水线各段时间相等(都是△t),一条k段流水线完成n个连续任务所需要的时间:Tk = (k+n-1)Δt
顺序执行n个任务所需要的时间: Ts = nk△t。流水线的最大加速比为为流水线段数k:
Smax=limn→∞nkk+n−1=kS_{\max }=\lim _{n \rightarrow \infty} \frac{n k}{k+n-1}=k Smax=n→∞limk+n−1nk=k
(3)流水线效率E是指流水线的设备利用率。在时空图上,流水线的效率定义为n个任务占用的时空区与k个功能段总的时空区之比(面积比),因此流水线的效率包含时间和空间两个方面的因素。
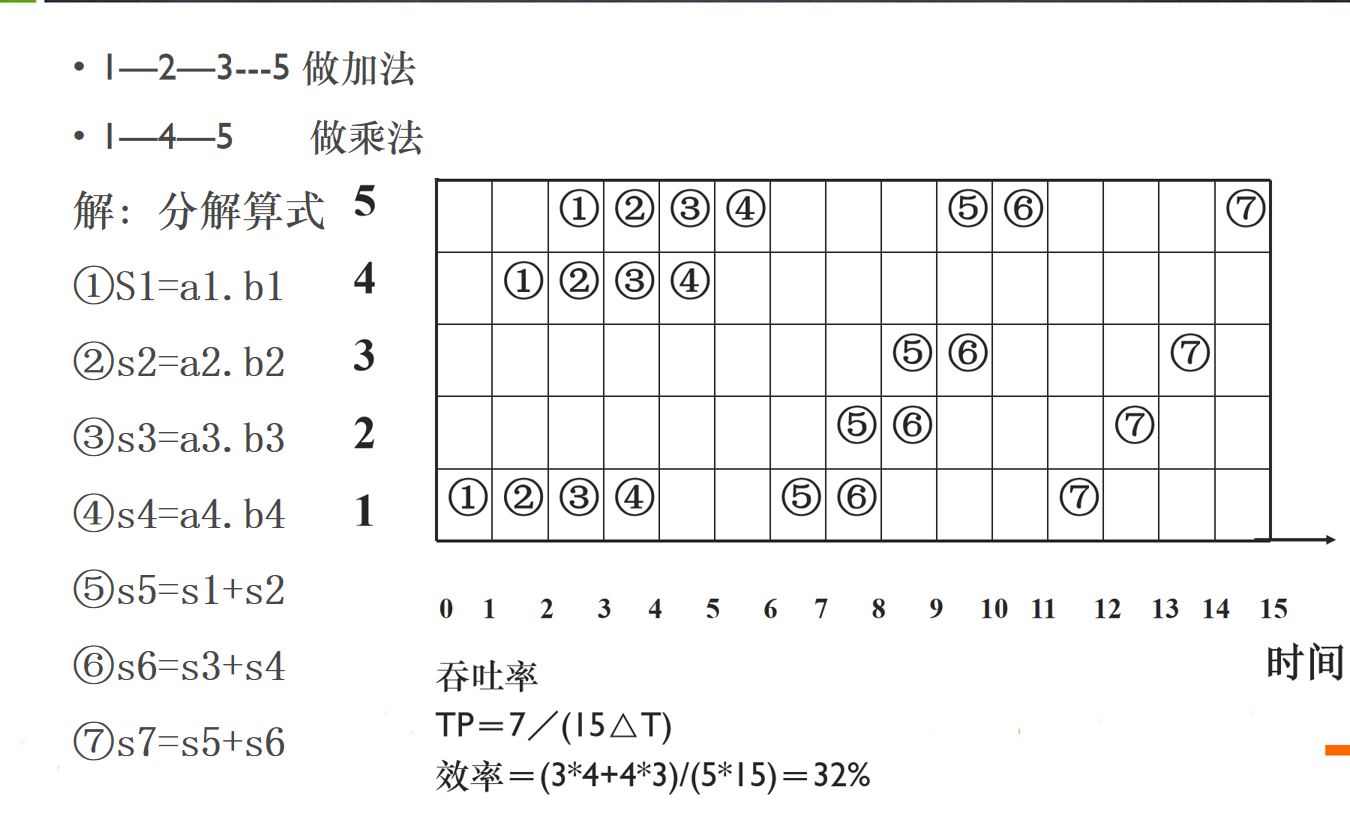
例题:假设加法由5个流水线实现,计算:S=a0+a1+a2+a3+a4+a5+a6+a7

例题:由静态多功能流水线实现如下计算:
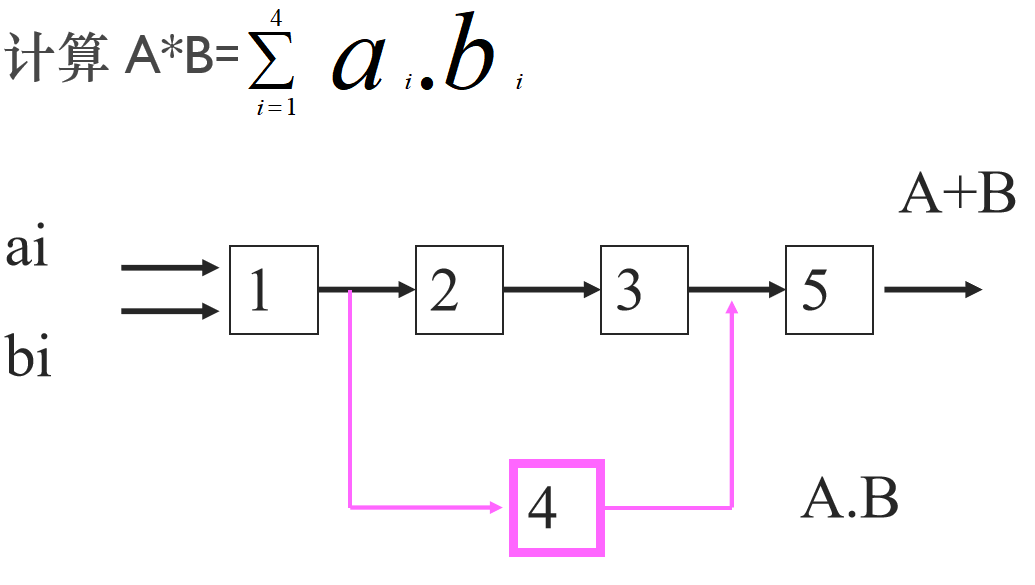
在上例中,将“静态”多功能流水线改为“动态”多功能流水线,又该如何分解?
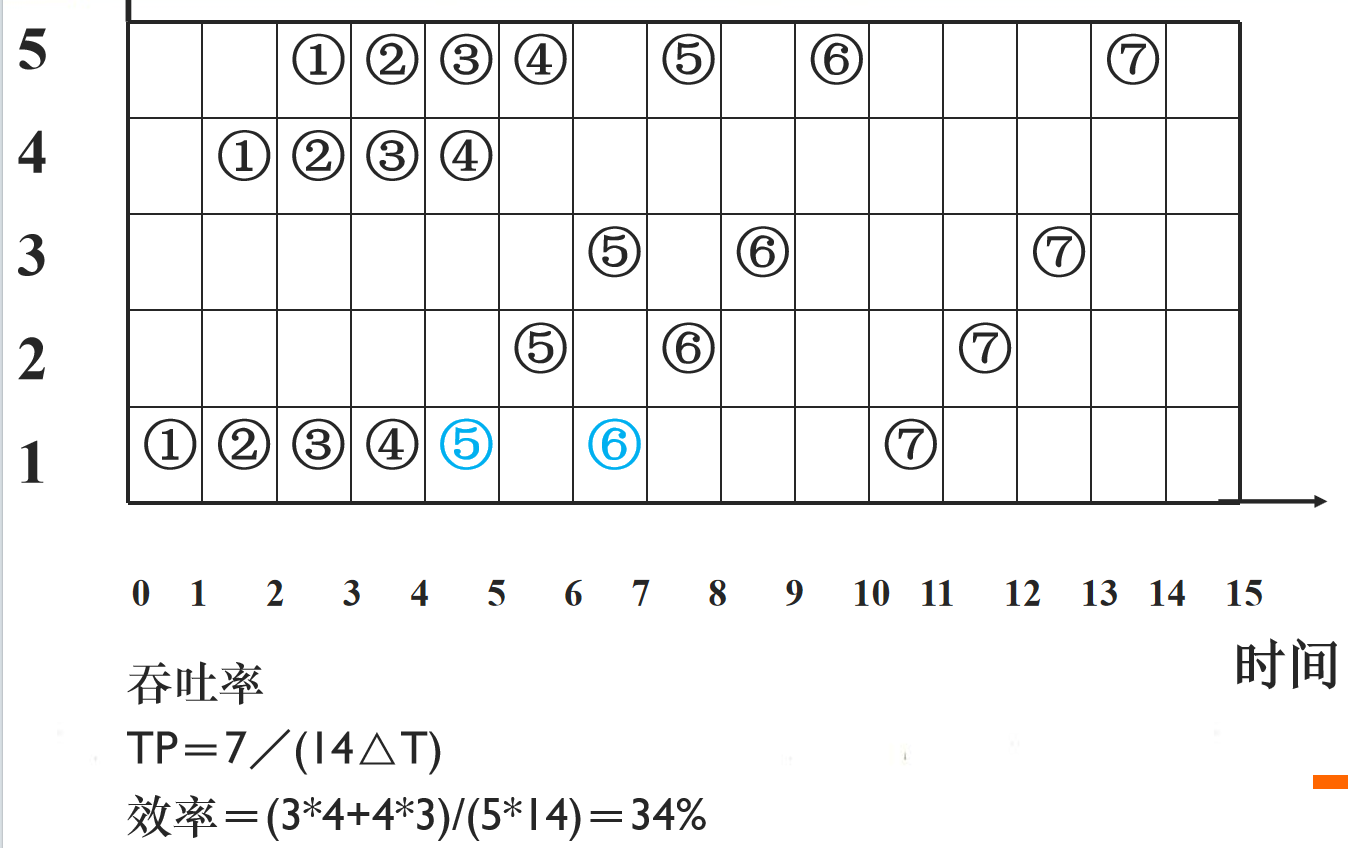
例题:动态流水线画法
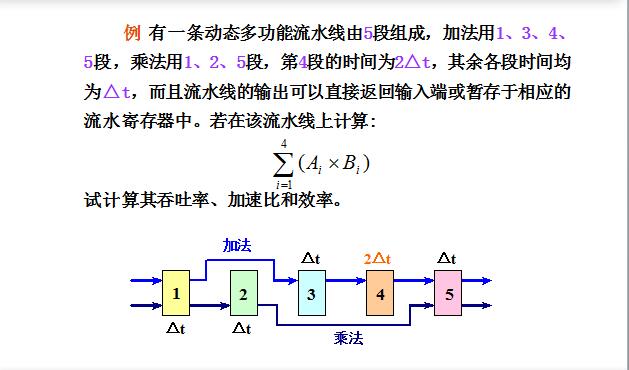
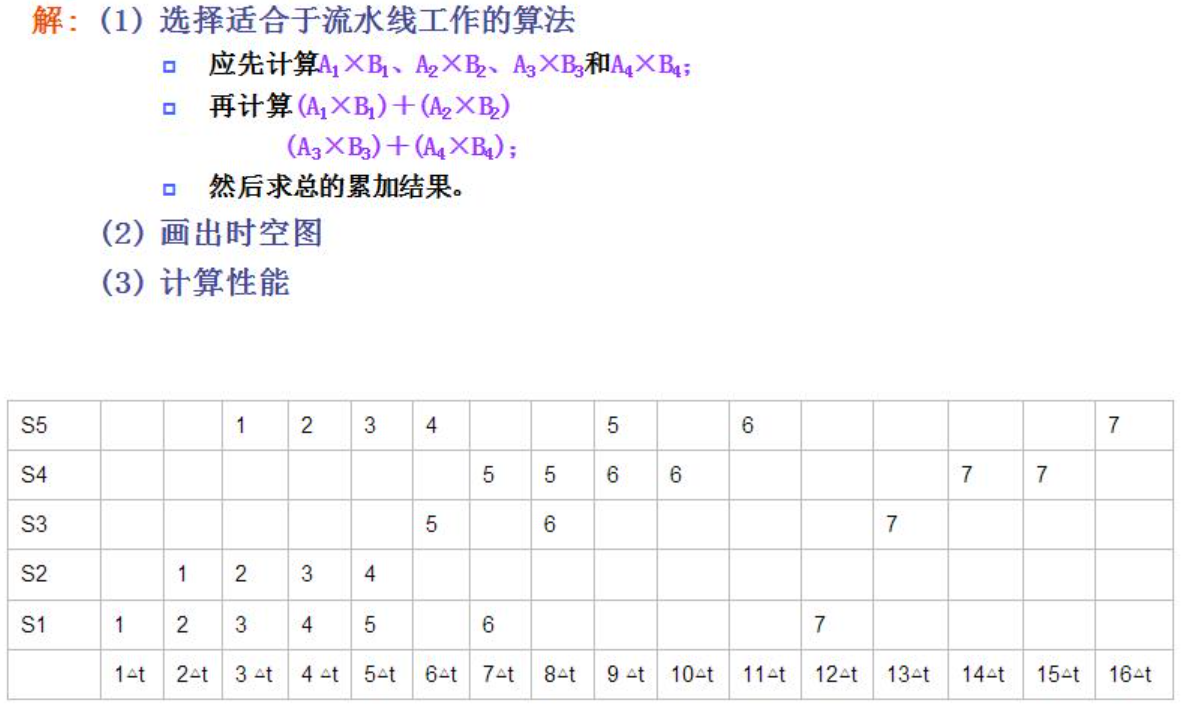
对应动态流水线,在第4个时钟周期计算出A1B1和A2B2,因此可以在第5个时钟周期进行两者和的计算,即可以开始5的流水。
二、经典5段流水线RISC处理器
指令级并行(Instruction-Level Parallelism, ILP),两个主要方法来进行ILP:
- 采用依靠硬件来发现和实现ILP(动态)。
- 依赖软件编译器来发现和实现ILP(静态)。
流水线级数并不是越多越好,流水线锁存器不是免费的,要占据面积,且有延迟。理想情况下,流水线的加速比等于流水线机器的段数。
- 流水线减少了指令执行的平均时间(减少了CPI或时钟周期),但并不减少指令的执行时间。
- 流水线技术(硬件实现)对编程者透明
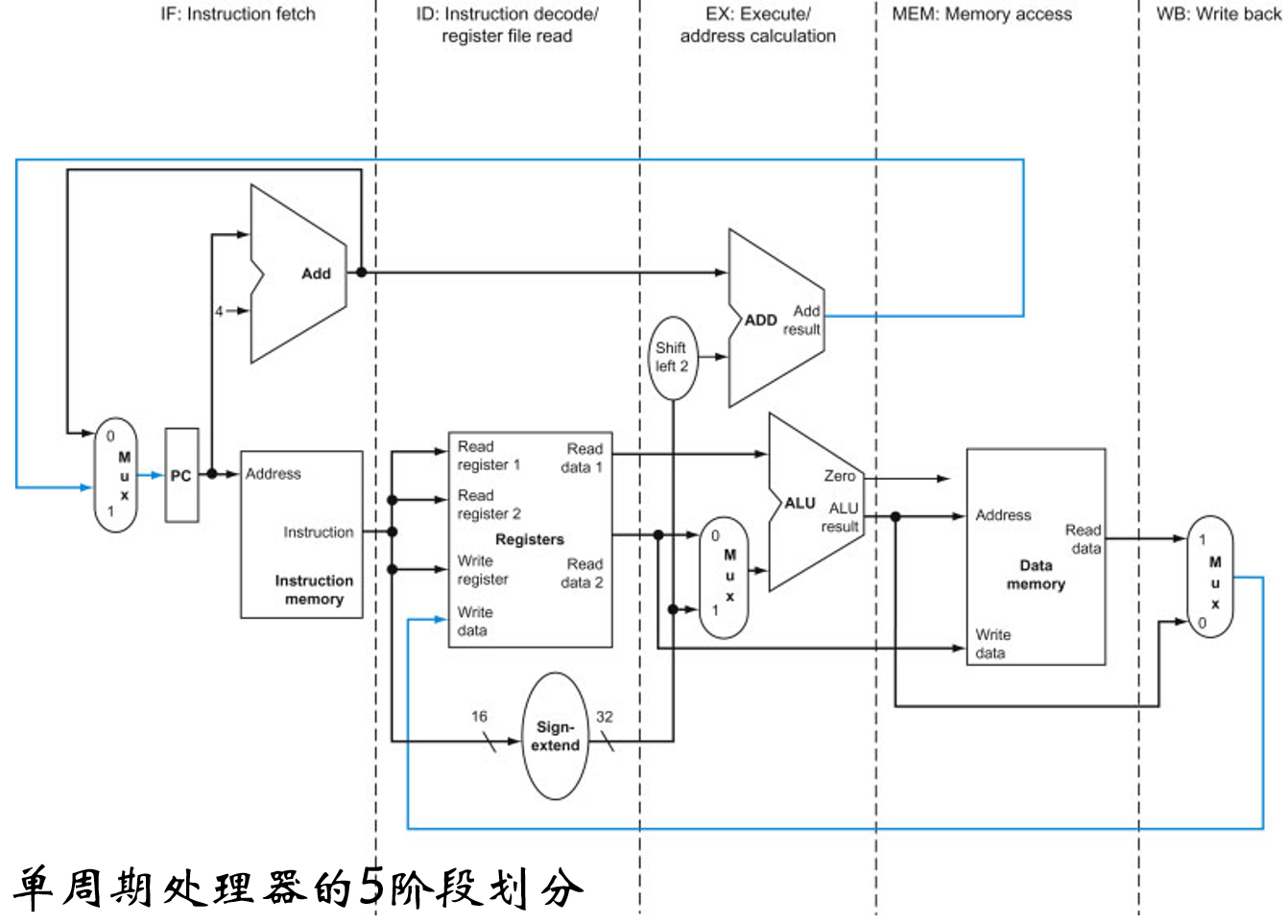
RISC指令系统特点:5个阶段前面都讲过,再简单重复一下
(1)IF: Instruction fetch cycle
- 按照PC内容访问指令存储器,取出指令
- PC+4→NPC,以获取下一条指令地址
(2)ID: Instruction decode/ register fetch cycle
- 指令译码
- 读寄存器
- 如果需要,符号扩展指令中的位移量
(3)EX: Execution/ effective address cycle
- Load/Store: 计算数据存储器有效地址
- R-R/ R-I ALU: 执行运算操作
- Branch: 做“=0?”测试,并置条件,计算目标地址
(4)MEM: Memory access
- Load: 送有效地址到数据存储器,取数据
- Store: 写ID读出数据到有效地址单元中
- Branch: 如果条件满足计算目标地址送PC;否则NPC送PC
(5)WB: Write-back cycle
- Load or ALU: 写结果到寄存器堆
对于经典5段流水线RISC处理器,5个段构成了一个指令流水线,一条指令经过每个段,每段在不同时钟,处理不同指令。 CPI与单周期一样还是为1,因为平均每个时钟周期发射或完成一条指令。在任意时钟周期,在每个流水段正执行一条指令的部分。理想情况下,性能增加了5倍!
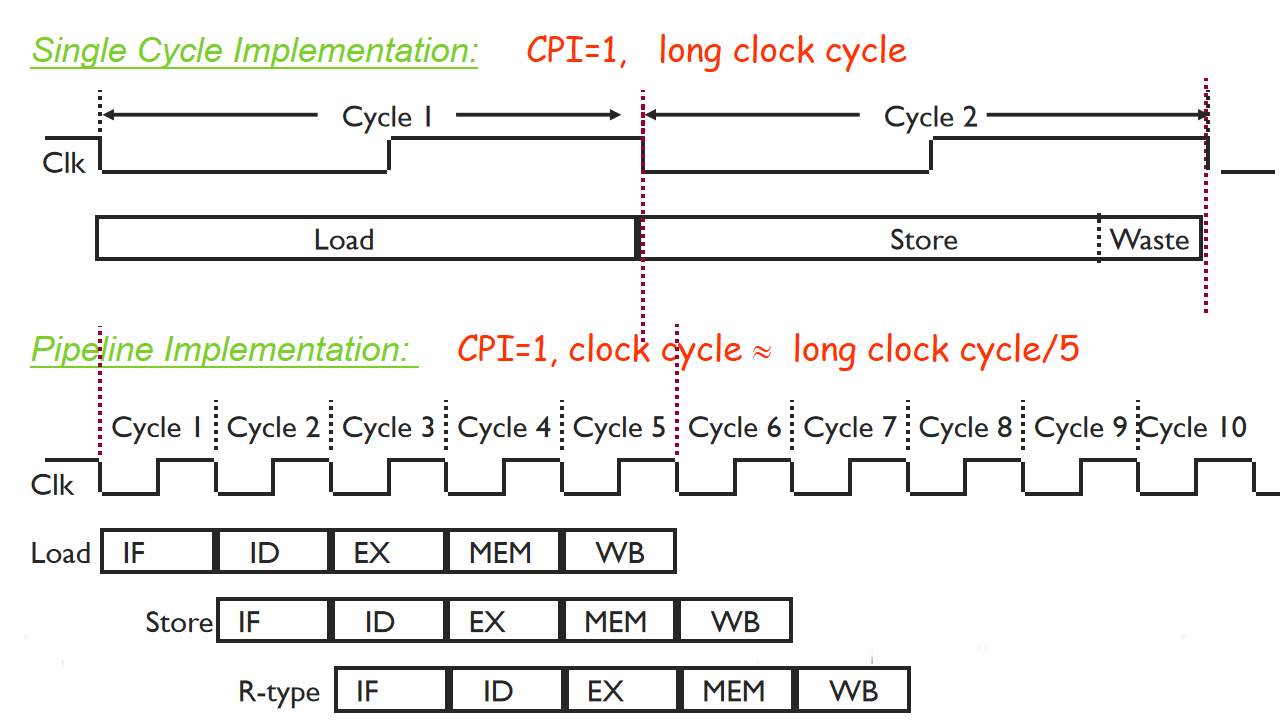
单周期和流水线实现方式其CPI都是1,但是流水线周期是单周期的1/5,指令数IC保持不变,根据CPU时间=IC×CPI×时钟周期CPU时间 = IC \times CPI \times 时钟周期CPU时间=IC×CPI×时钟周期公式,流水线大大缩短了CPU时间。流水线没有停顿时,加速比等于流水线段数。
三、流水线中的冒险问题
流水线中的冒险主要分为以下3种类型:
-
结构冒险
-
数据冒险
-
控制冒险
冒险总是可以用停顿解决,解决冒险最简单的方式就是停顿流水线。停顿意味着为某些指令暂停流水线一个或多个时钟周期。 一条指令被停顿后,其后的所有指令被停顿;该指令之前的指令必须继续执行。一个流水线停顿也称为流水线气泡或气泡。 停顿时,没有任何新的指令被取到流水线。
3.1 结构冒险
如果某些指令组合在流水线中重叠执行时产生了资源冲突,那么我们称该流水线有结构冒险。比如由于访问同一个存储器而引起的结构冲突。
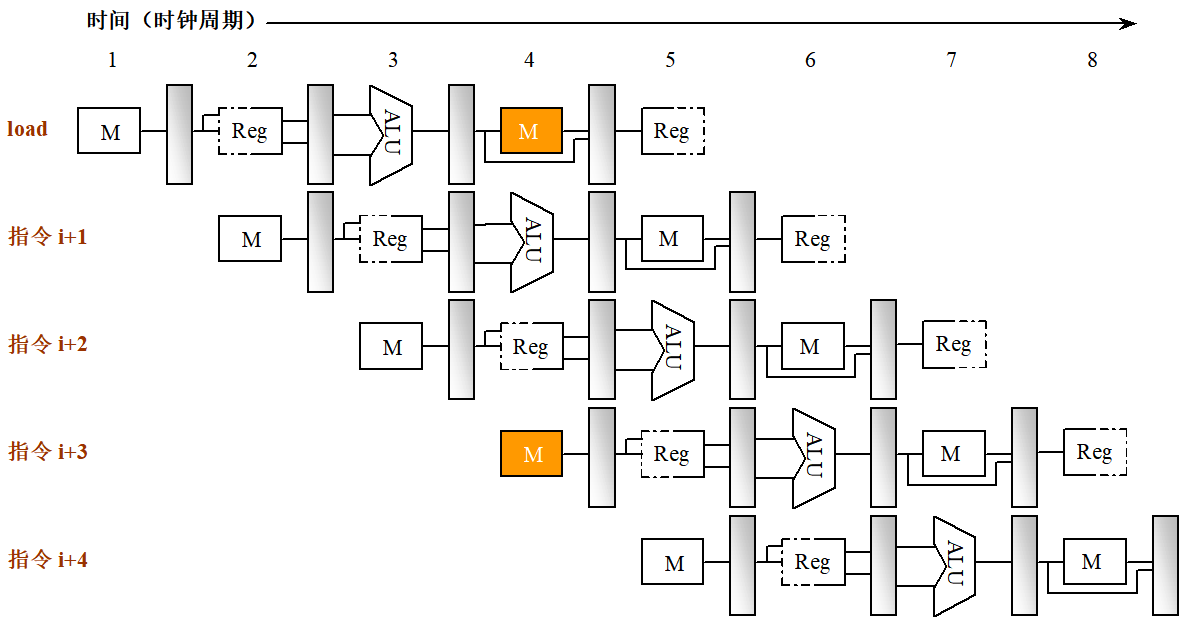
解决:
(1)插入暂停周期,即让流水线在完成前一条指令对数据的存储器访问时,暂停取后一条指令(指令存储器)的操作。
(2)设置相互独立的指令存储器和数据存储器或设置相互独立的指令Cache和数据Cache。
(3)预取指令技术(在重叠操作中,当前一条指令在执行过程中就需要提前取出后面的指令进行相应处理,这种提前取出后继指令进行相应处理,称为先行(预取)。)
3.2 数据冒险
如果下面的条件之一成立,则指令j与指令i数据冒险:
(1)指令j使用指令i产生的结果
(2)指令j与指令k数据冒险,指令k与指令i数据冒险,则指令j与指令i数据冒险。
指令想要的数据值还没有完成,或者值没有在正确的地方。
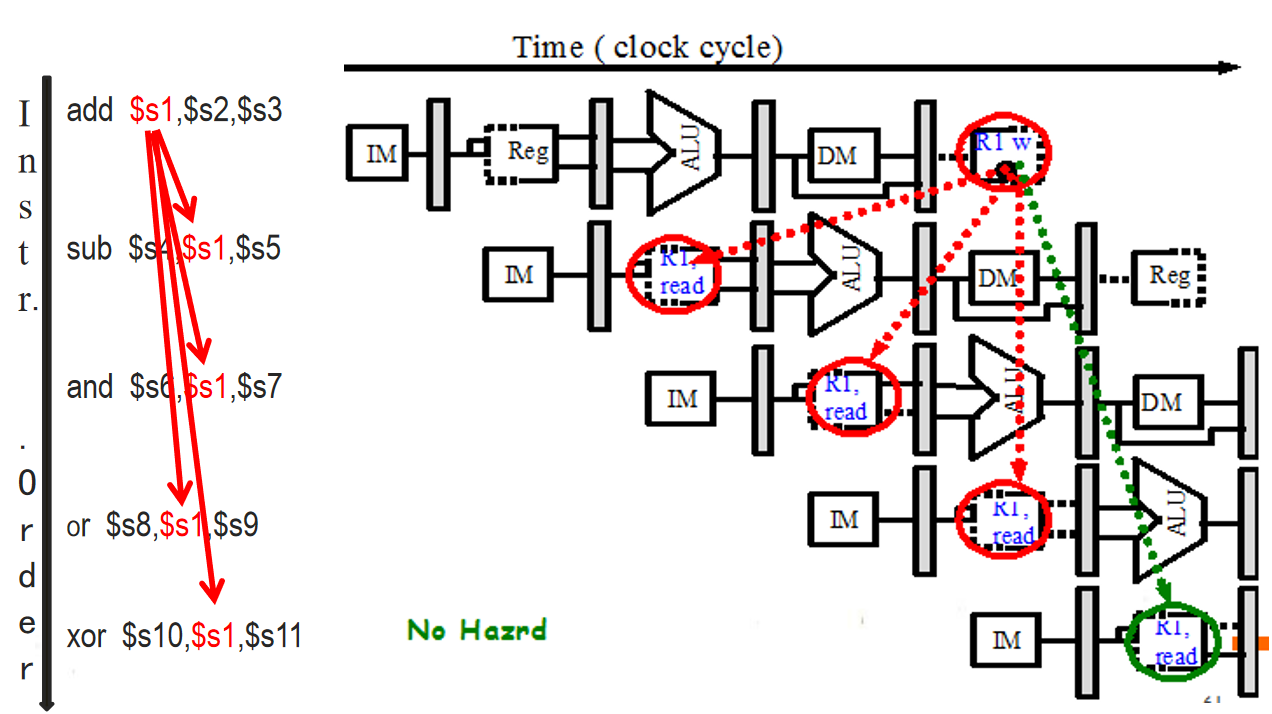
由于数据可以在寄存器和存储器之间流动。当数据在寄存器中出现时,检测相关很容易,因为寄存器名字在指令中是固定的。对于存储器之间的数据相关的检测会更难,因为多个看起来不同地址可能指的是同一个地址,例如100(s4)和20(s4)和20(s4)和20(s6)可能是相同的地址。
解决数据冒险的一般技术:
-
暂停流水线;
-
使用相关专用数据通路;
-
编译优化调度(静态调度);
-
动态调度。
3.3 控制冒险
控制冒险是指因为程序的执行方向可能被改变而引起的相关。可能改变程序执行方向的指令通常有无条件转移、条件转移、子程序调用、中断、异常等。控制冒险会引起MIPS流水线的性能损失比数据冒险大得多。

从相关的角度看,转移指令与后续指令之存在着一种冒险,==使后续指令不能同时进入流水线执行,==故称为控制冒险。
解决:
(1)转移Stalls就是插入停顿,但会造成大的性能损失
(2)总是预测分支不发生(即假设分支不发生,属于静态预测机制)(成功率在50%左右)
改进分支预测技术:预测一些分支发生而预测另外一些分支不发生。 即可以根据分支的方向来 预测分支是否命中,向后转移的分支预测为选中,向前转移的分支预测为不选中。这种分支预测的方法依赖于始终不变的行为,没有考虑特定分支指令的特点。
动态分支预测技术:通过硬件技术,在程序执行时根据近期转移是否成功的历史记录来预测下一次转移的方向。提前对分支操作做出反应,减少或消除控制相关导致的流水线停顿。其预测取决于每一条指令的行为,并且在整个程序生命周期内可能改变分支的预测结果。其实现方法是保存每次分支的历史记录,然后利用这个历史记录来预测。
动态分支预测技术主要有转移预测缓存和转移目标缓存。
-
转移预测缓存是一小块由转移指令低位地址索引的存储单元,用来记录转移指令在最近的一次执行中是否被选中。可能有几条转移指令都映射到了同一个预测缓存表项。
当每项为一位预测位时,记录该指令最近一次分支是否成功,每一条指令的“转移历史表”只需要一个二进制位。每个圆圈表示一种状态,圆圈中的T或N表示最近一次执行这条转移指令时,实际转移成功或不成功的信息,这个信息就是“转移历史表”中所记录的内容。带有箭头的线表示状态转换的方向,线旁边的T表示指令实际执行结果为转移成功,而N表示指令实际执行结果为转移不成功。
预测行为:假设表中原来记录的是T,如果本次转移成功,则表中的内容继续保存T;如果本次转移不成功,则表中的内容修改为N;
考虑一个循环,进行9次循环分支(分支发生)后退出(分支不发生),使用单预测位(初始化为表示不分支的0)会产生两次预测错误:
进入第1次循环后,要继续循环分支,然而预测位为0,预测不分支,产生一次预测错误。
进入第9次循环后,不再循环分支,然而预测位为1,预测分支,产生第二一次预测错误。
为了提高分支预测的准确率,后面采用
2位预测位。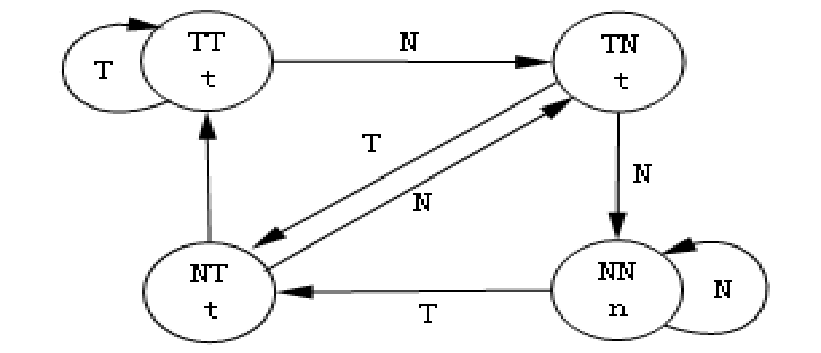
-
转移目标缓存如果转移指令知道下一条指令的地址,那么就可以将转移代价降为0。把为转移的后继指令保存预测地址的转移预测Cache称为转移目标缓存或转移目标Cache。
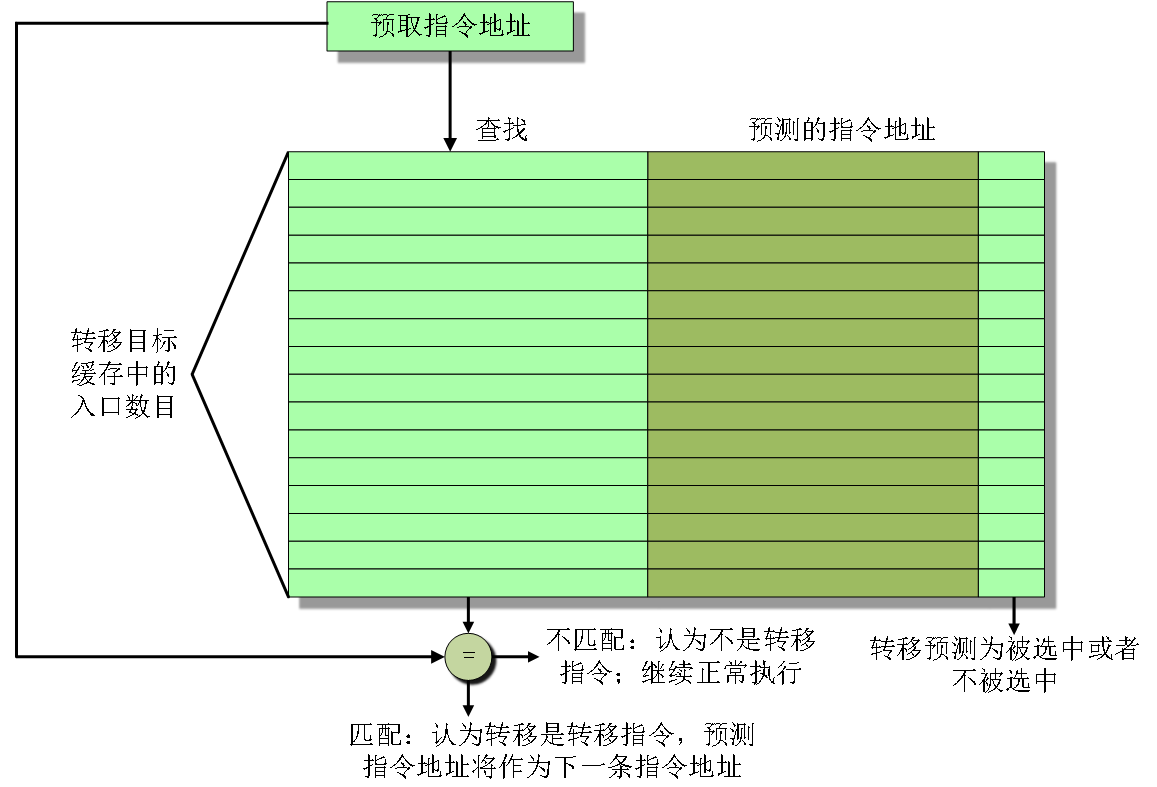
(3)延迟转移和缩小延迟槽
小结:
控制冒险出现的频率比数据冒险要小得多,而且采用转发就能有效解决数据冒险,但没有有效的方法能够解决控制冒险,而且控制冒险比数据冒险会引起更大的性能损失。
通常,流水线越深,在时钟周期上转移损失越大。 CPI更高的处理器,会付出更高的转移代价。解决控制冒险的有效性取决于转移预测的准确性。
四、流水线处理机及其设计
4.1 流水线模型扩展
在单周期处理机中,如果一条指令还没有执行完毕,PC的内容不会改变。这就使得在一条指令的整个执行过程中,IM始终输出当前指令。
任一时刻,每个流水级只被一条指令占用。用一条数据通路执行5条MIPS指令不会造成结构冒险,但每条指令使用和生成的数据各不相同,为了保留指令各自的数据,保存当前时钟周期运算出的结果,以便为下个周期使用,需要在两个流水级之间插入流水线寄存器以左右两个流水级命名分别叫做IF/ID、ID/EX、EX/MEM、MEM/WB。
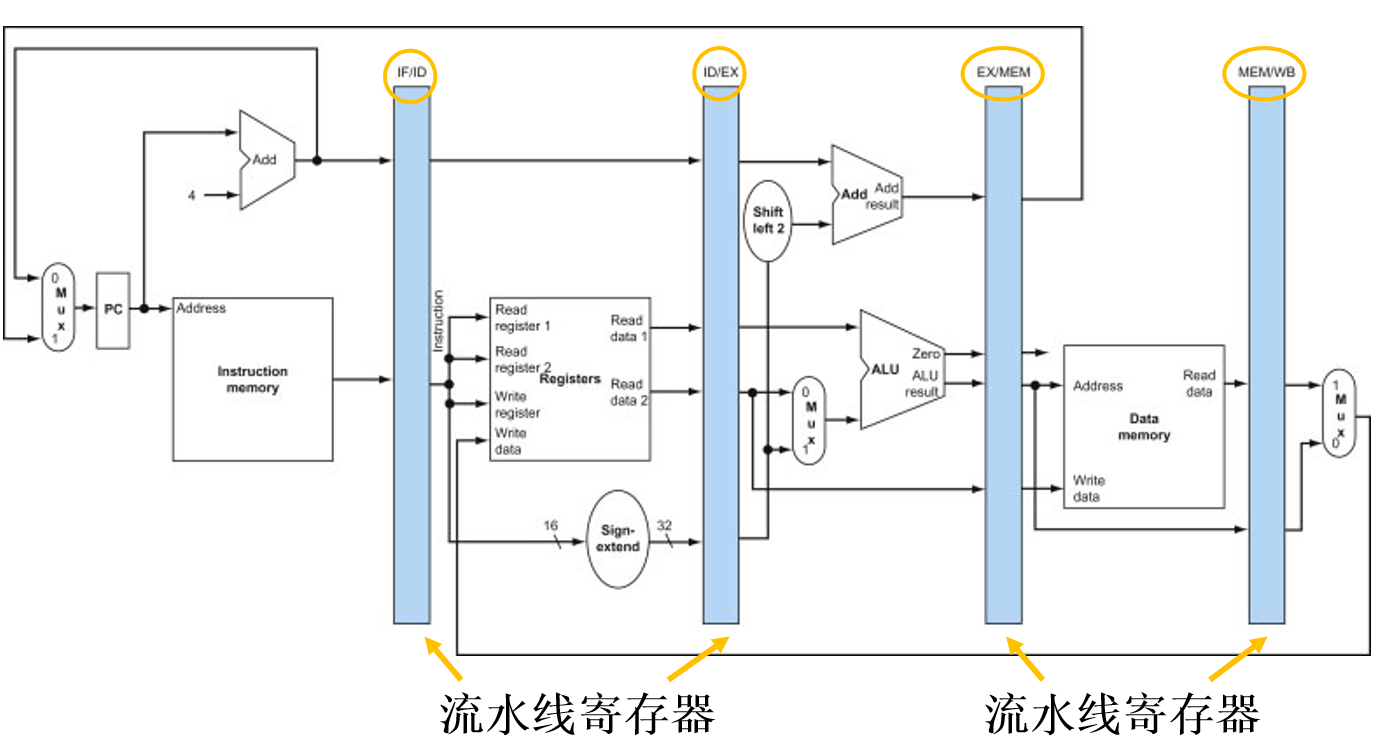
注意:只能使用触发器寄存器(触发器对边沿敏感),它把时钟上升沿时数据输入端的信息打入寄存器中;而不能使用锁存器(锁存器对电平敏感),因为锁存器的输出在时钟高电平时跟随输入的变化而变化。
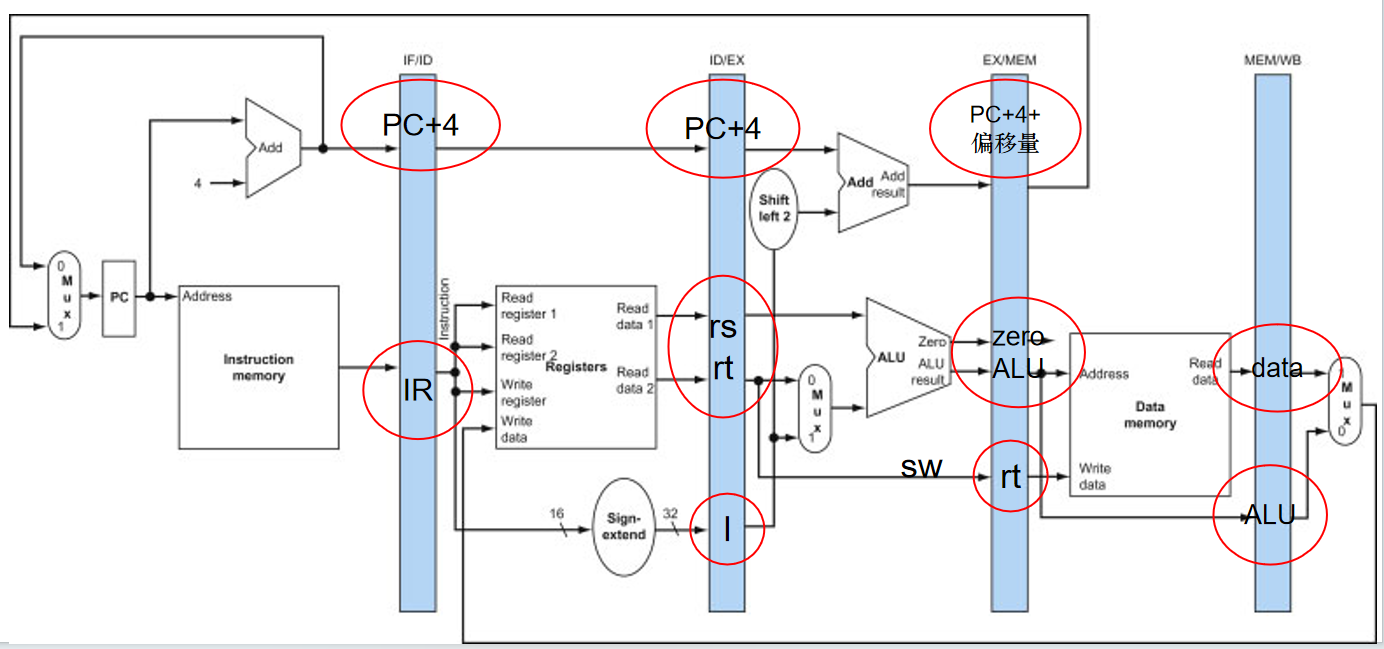
(1)对于PC寄存器,把它作为一个特殊的流水线寄存器来看待,因为在非流水线处理机中PC也是需要的。由于流水线处理机每个时钟周期都从指令存储器取出一条指令,它的值在每次周期结束时都将被改变。
(2)IF/ID流水线寄存器中必须包括一个指令寄存器IR(instruction register),IR有32位,用来存放一条指令。同时也要传递PC+4。
(3)ID/EXE中需保存:从寄存器堆中读出的两个32位数据必须要保存。经符号扩展后的32位立即数I也要保存。继续保存PC+4。
(4)EX/MEM中需保存:PC+4+偏移量的值(分支目的地址)。ALU的计算结果。ZERO标志位的值。要写入存储器中的数据rt(sw指令)。
(5)MEM/WB中需保存:ALU的计算结果。从存储器中读出的数据。
除了保存上面的数据之外,对于R型指令(add,sub)和lw指令,每级都需保存目的寄存器的值(rd/rt)。
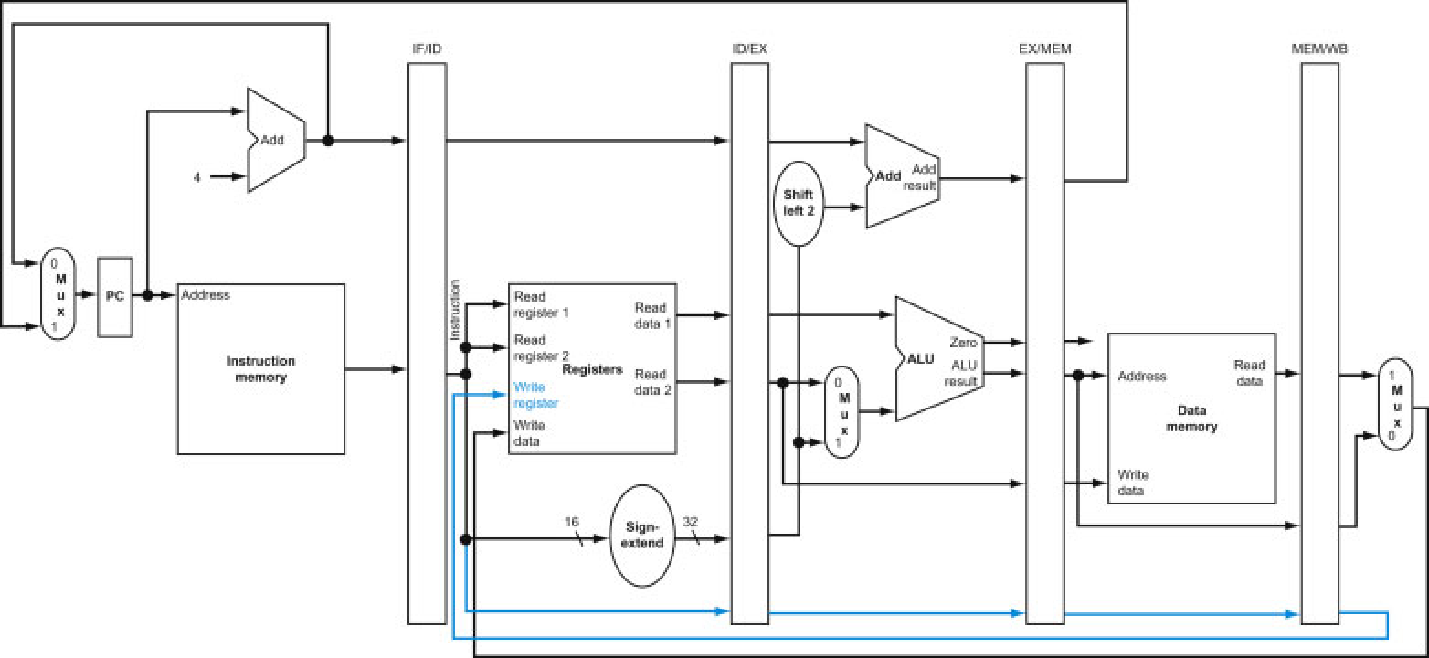
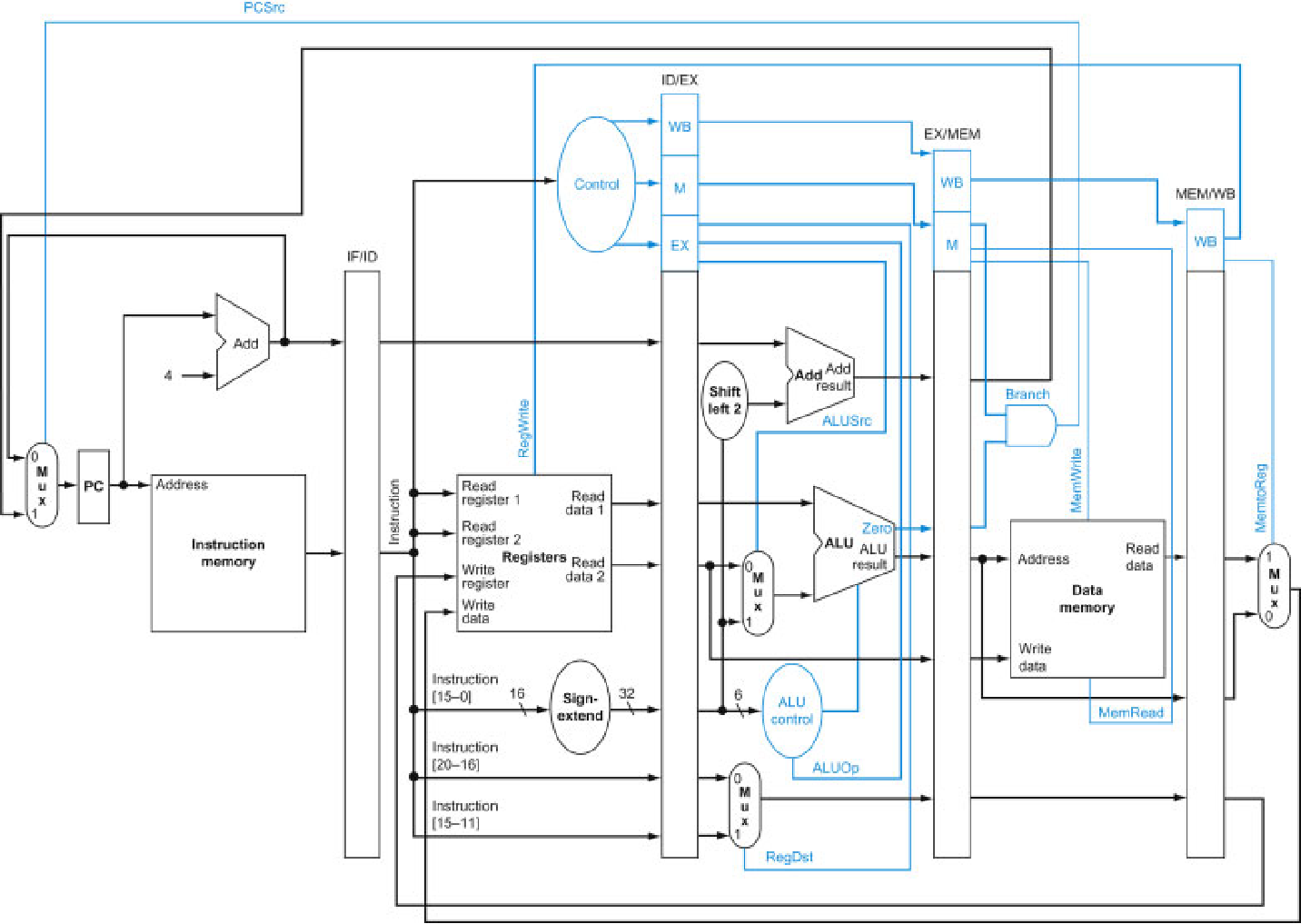
同样的单周期的控制信号在流水线周期中同样适用,并且含义一样。如下图所示。
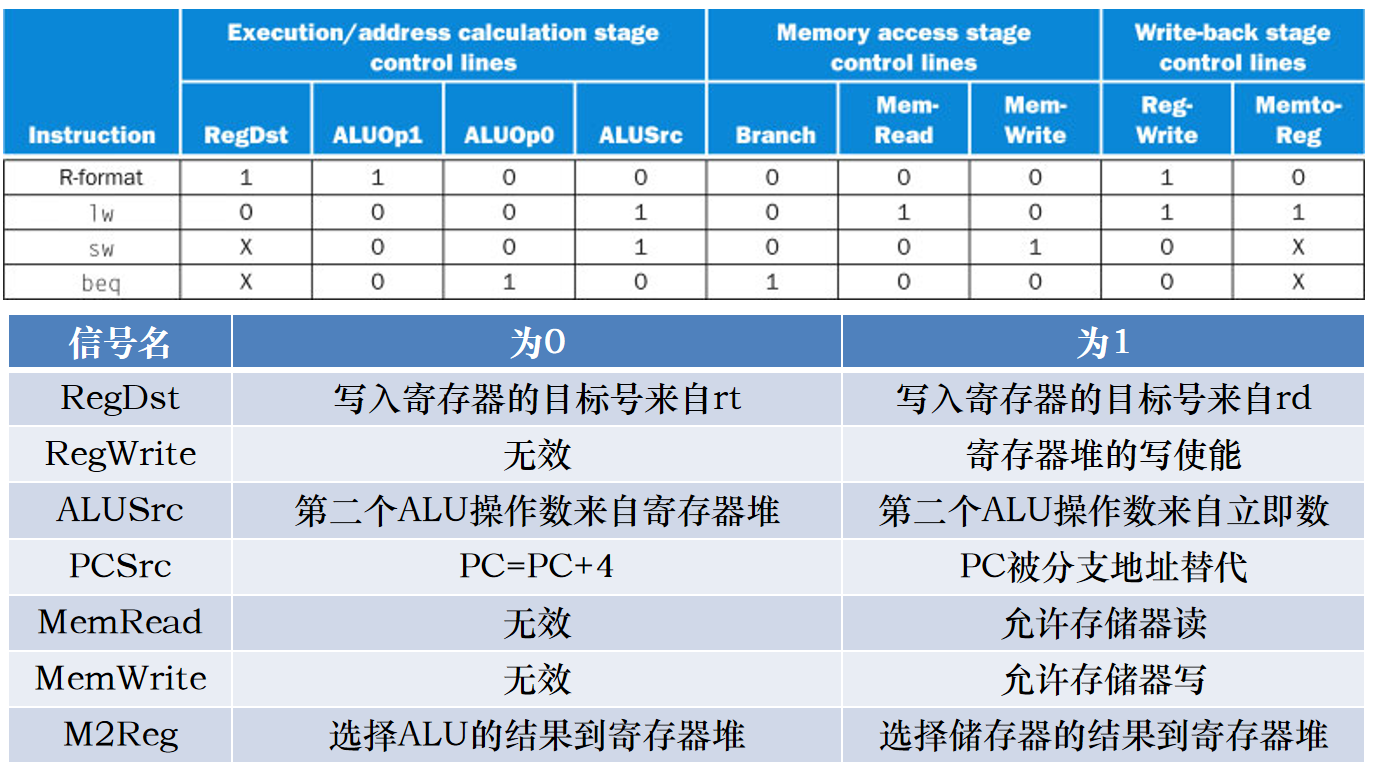
但是要区分单周期,在单周期中控制信号一般由一条指令决定,但是在流水线中不同阶段的控制信号可能由对应指令下的控制也可能由其它指令控制,比如ID的寄存器写使能可能由WB级的指令lw控制,如下图所示。
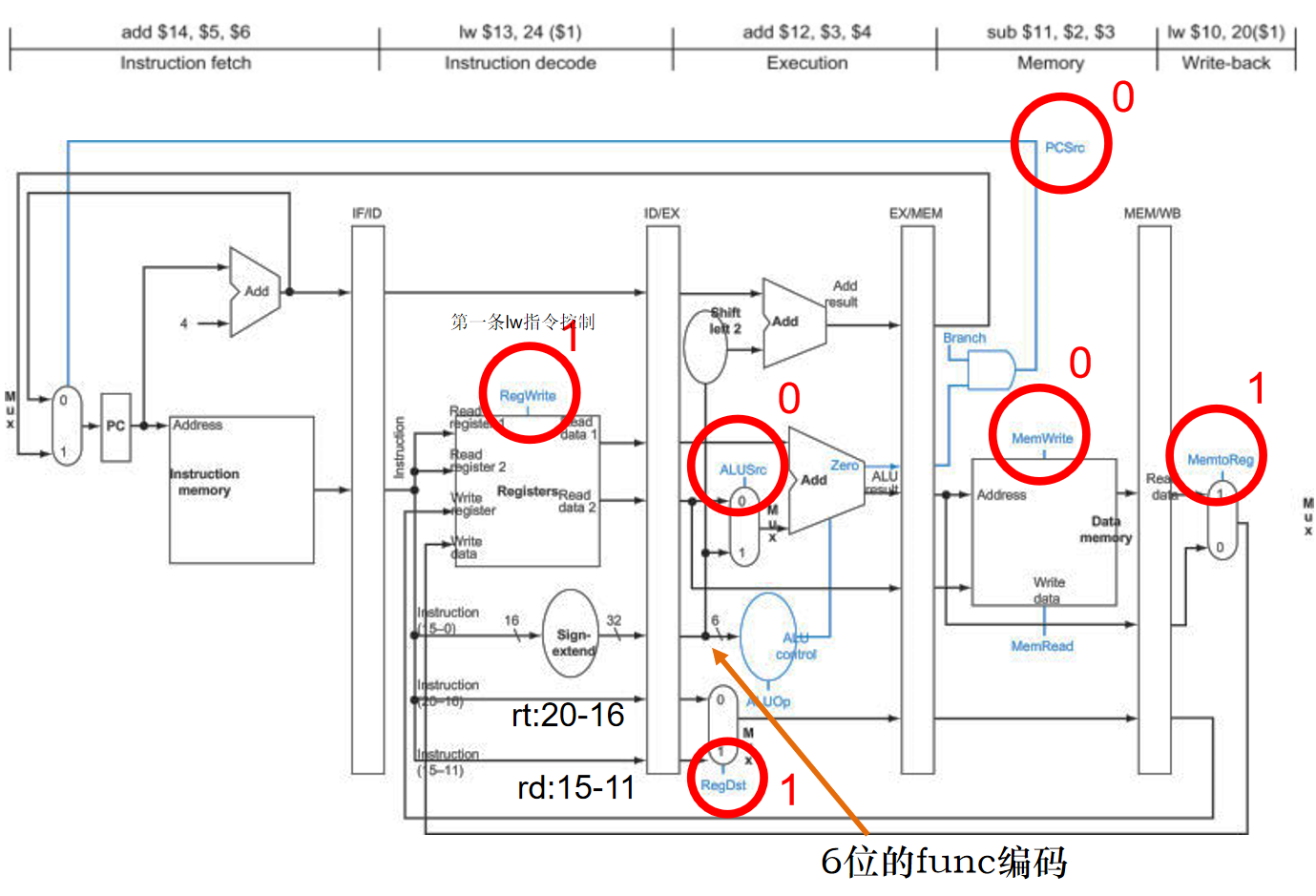
因此,在ID级创建控制信号,然后逐级传递,进行跨流水级的数据传送。
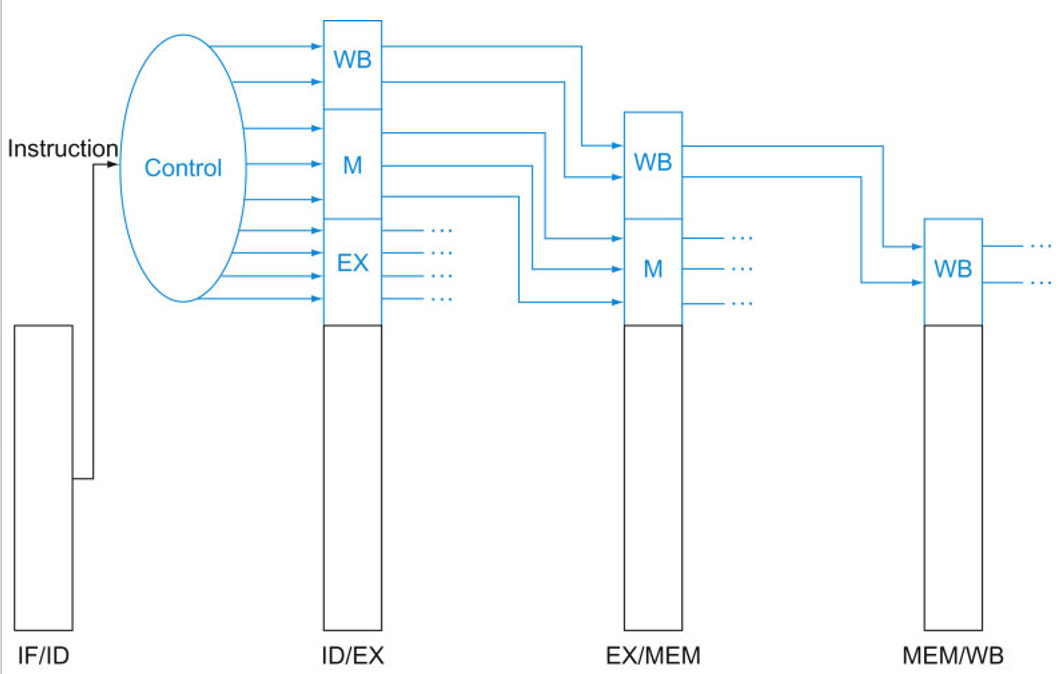
改进后的流水线数据通路如下图,流水线控制信号和单周期控制信号的种类、数量、功能完全相同,但是每条指令在ID级产生控制信号后,下一周期会被后续指令覆盖,因此,控制信号也需要从ID级依次传到EX级、MEM级、WB级。EX级使用该级的信号(ALUSrc和ALUOp)后不再使用,可以丢弃,MEM级同理。这就是跨流水级的控制信号传送。
4.2 数据冒险的解决
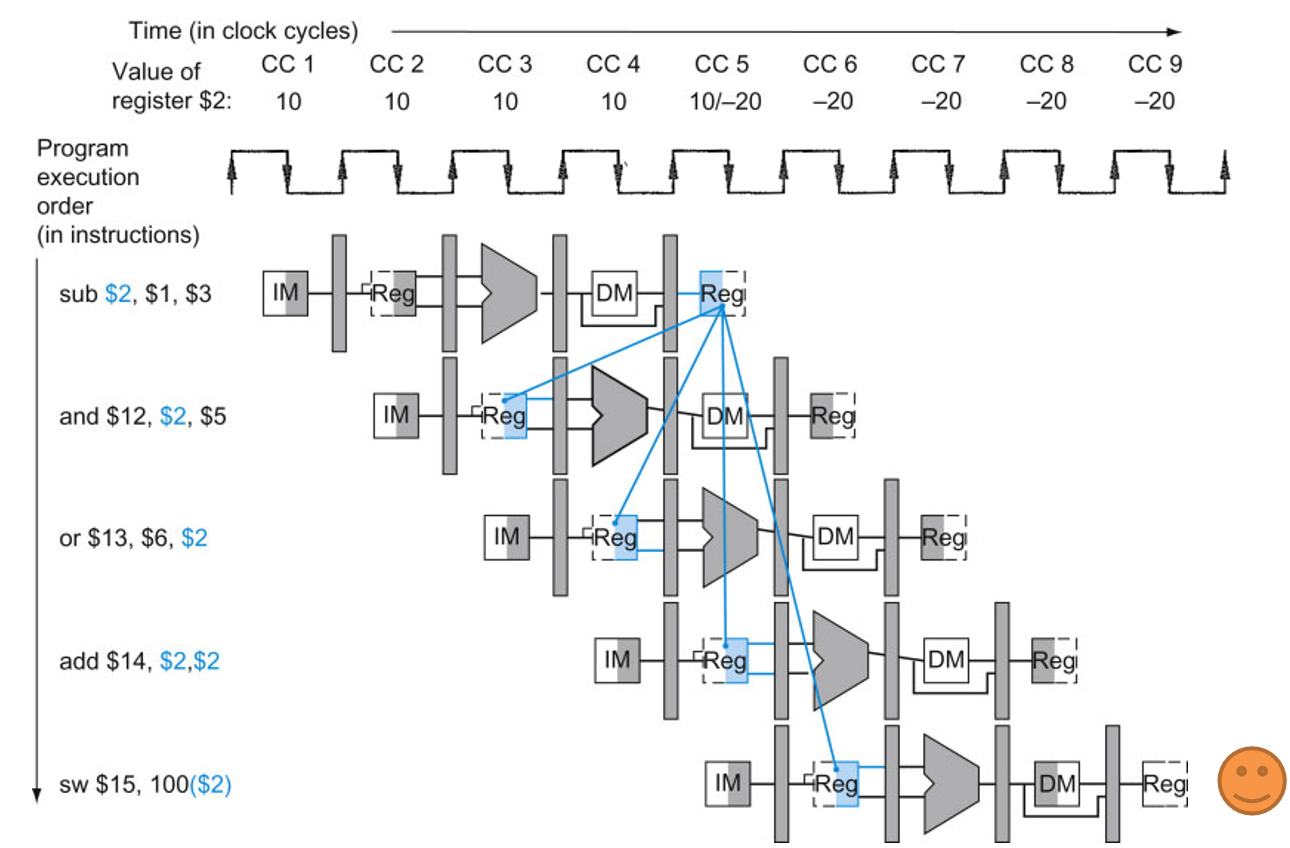
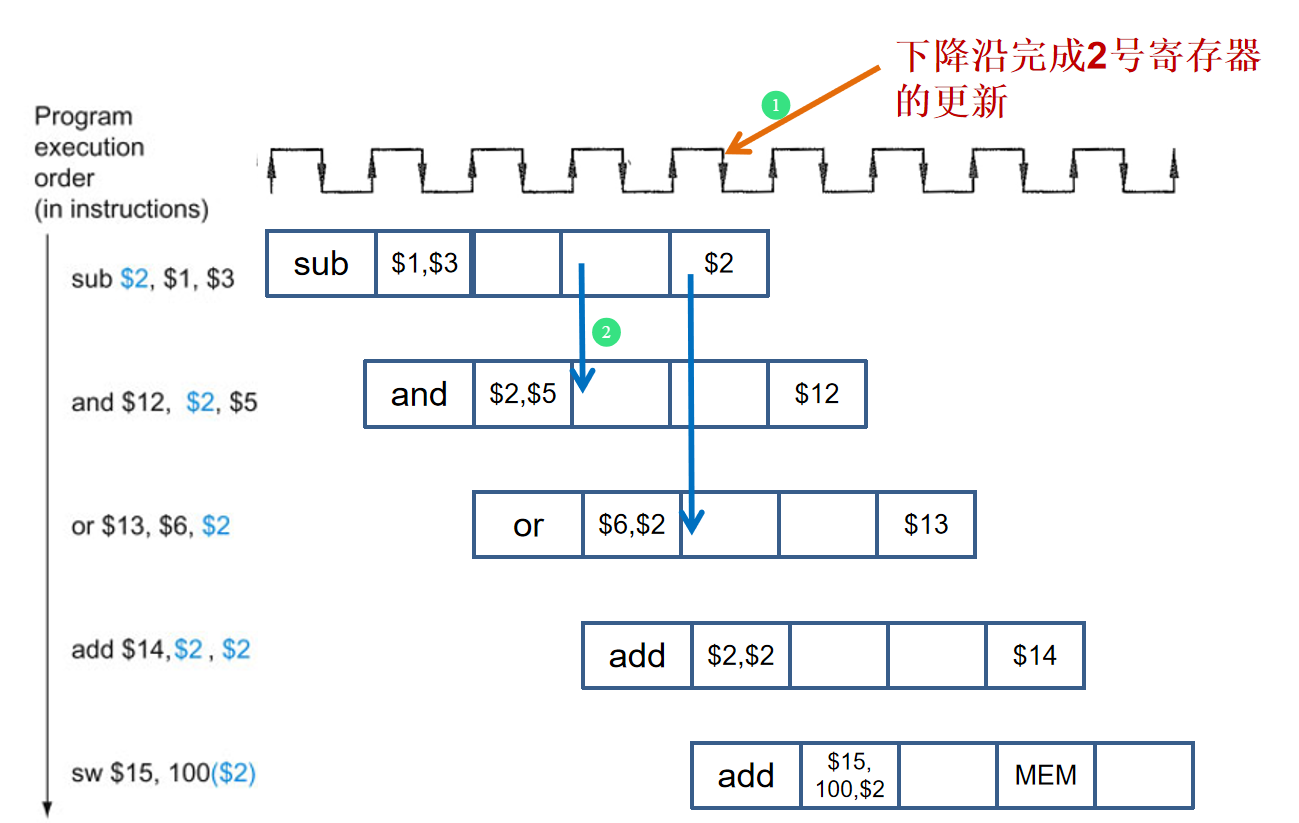
2号寄存器的值是否是正确的值?如何解决?显然只有最后一条指令会拿到正确的2号寄存器的值,2号寄存器值更新在wb周期结束的上升沿,后面三条指令拿到的都是旧值。
(1)WB提前半个周期
如果将wb周期进行提前半个周期进行写回,即第5个周期CC5的下降沿完成2号寄存器的更新,约定寄存器前半拍写,后半拍读,则第四条指令在后半周期读取,可避免一次冒险。
(2)ALU-ALU旁路 MEM-ALU旁路
实际上,and和or要使用的数据-20在CC3就已经由ALU计算生成,可以从EX/MEM寄存器将数据直接传给and指令的ALU,从MEM/WB寄存器将数据传给or指令的ALU。这种跳过寄存器写回、直接从流水线寄存器取得数据的方法称为转发(forward)或旁路(bypass)。
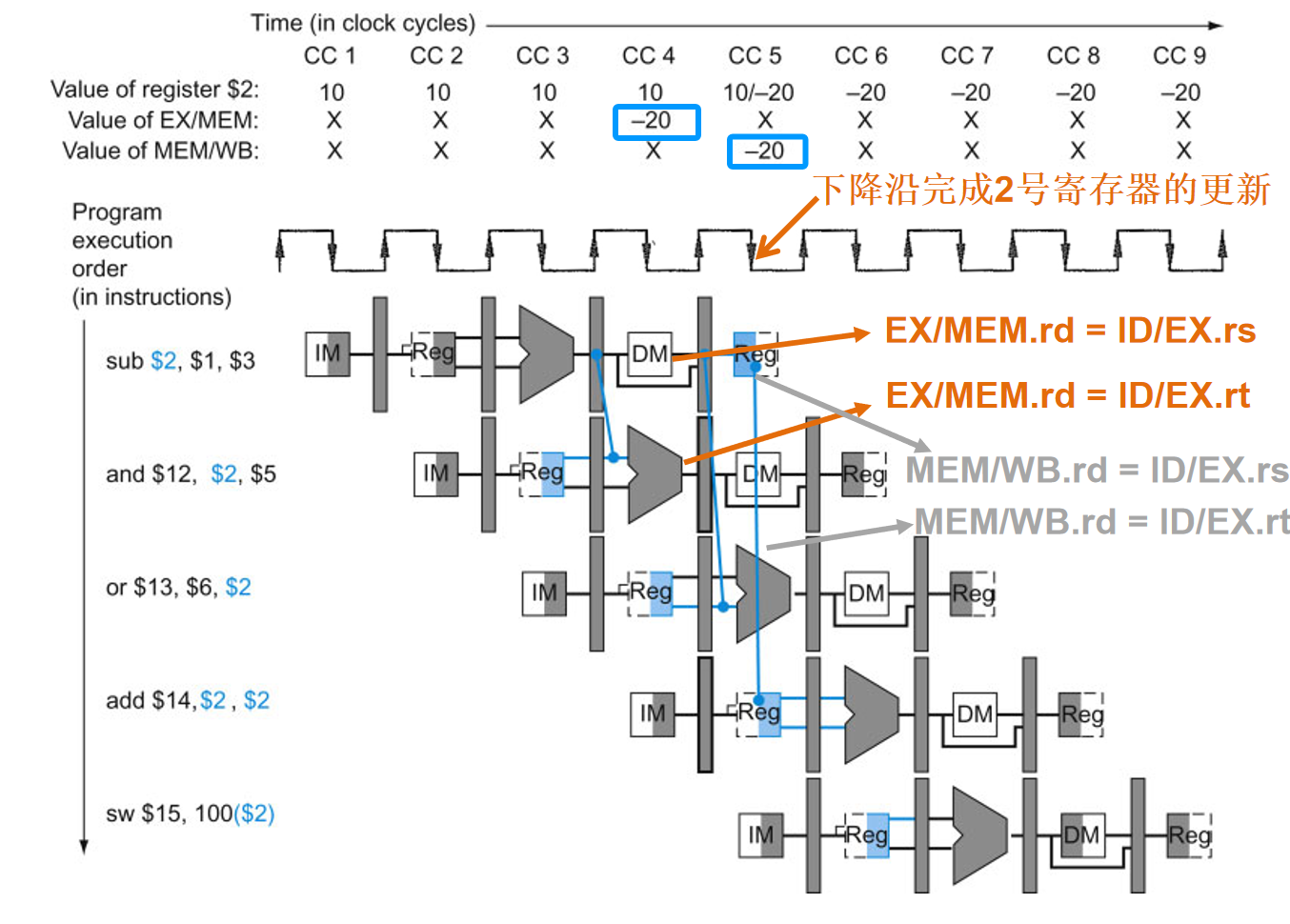
增加转发/前推通路如下图所示:
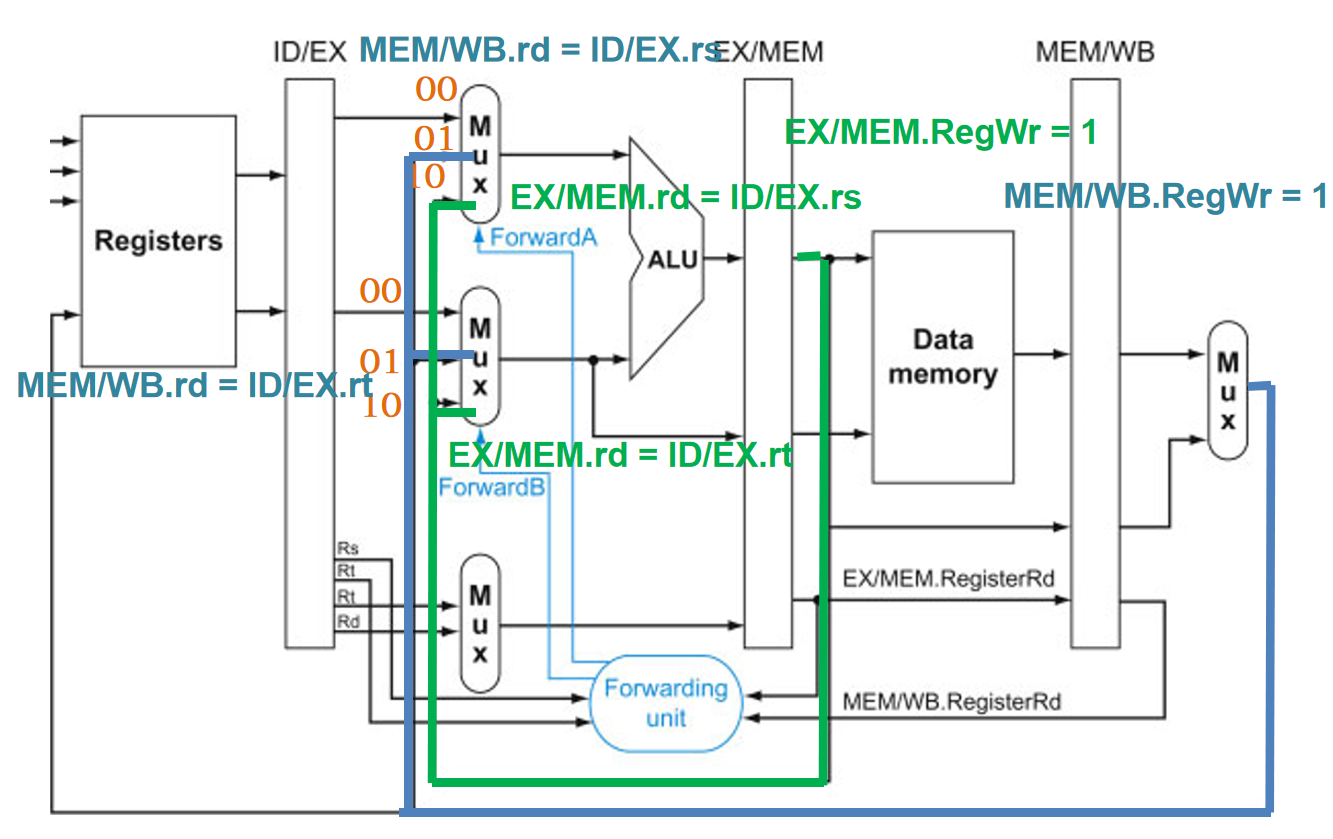
检测冒险的条件以及控制信号的选择:
- EX冒险:目的寄存器rd的值传递给其它指令的源操作数rs和rt
- if (EX/MEM.RegWrite and (EX/MEM.Rd = ID/EX.Rs)) ForwardA = 10;
- if (EX/MEM.RegWrite and (EX/MEM.Rd = ID/EX.Rt)) ForwardB = 10;
- MEM冒险:目的寄存器rd的值传递给其它指令的源操作数rs和rt
- if (MEM/WB.RegWrite and (MEM/WB.Rd = ID/EX.Rs)) ForwardA = 01;
- if (MEM/WB.RegWrite and (MEM/WB.Rd = ID/EX.Rt)) ForwardB = 01;
只有写回寄存器的指令(R型和lw)才能向后续指令发出旁路,所以需要RegWrite = 1。
同时增加立即数通道,在ALU之前增加一个多路选择器即可。
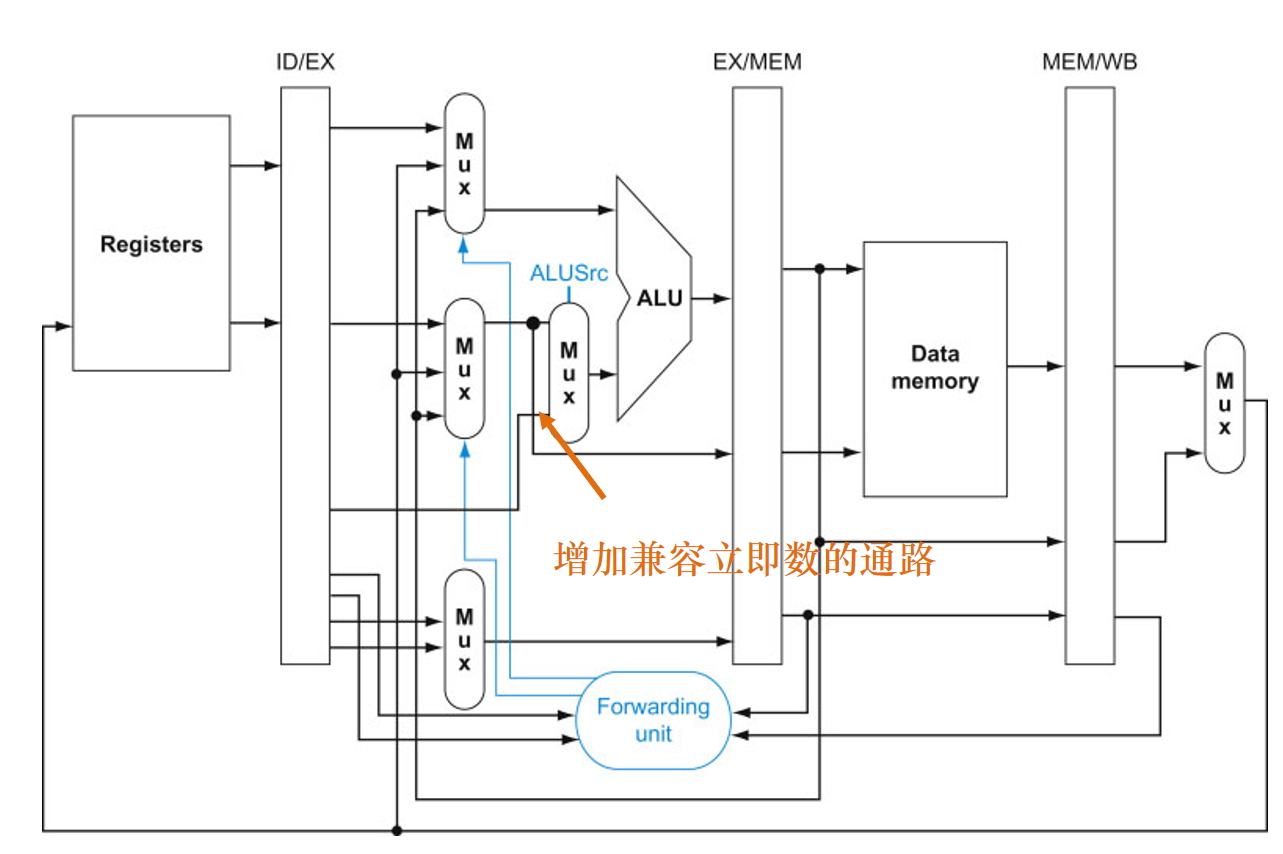
因此结合WB提前半个周期和增加转发/前推通路可以解决上述简单的数据冒险,转发/前推通路的时序图如下,要求会画!!!
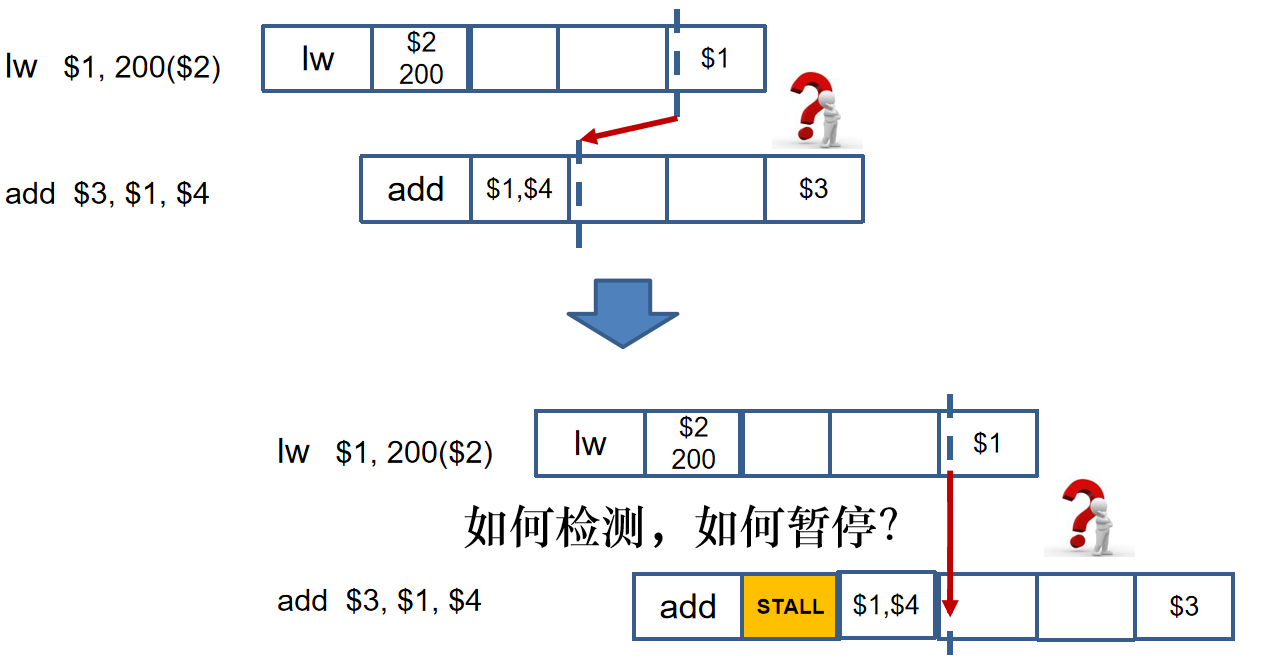
但是上述的指令前推技术并不能解决所有的数据冒险,比如取数-使用型数据冒险,如下所示。
 | 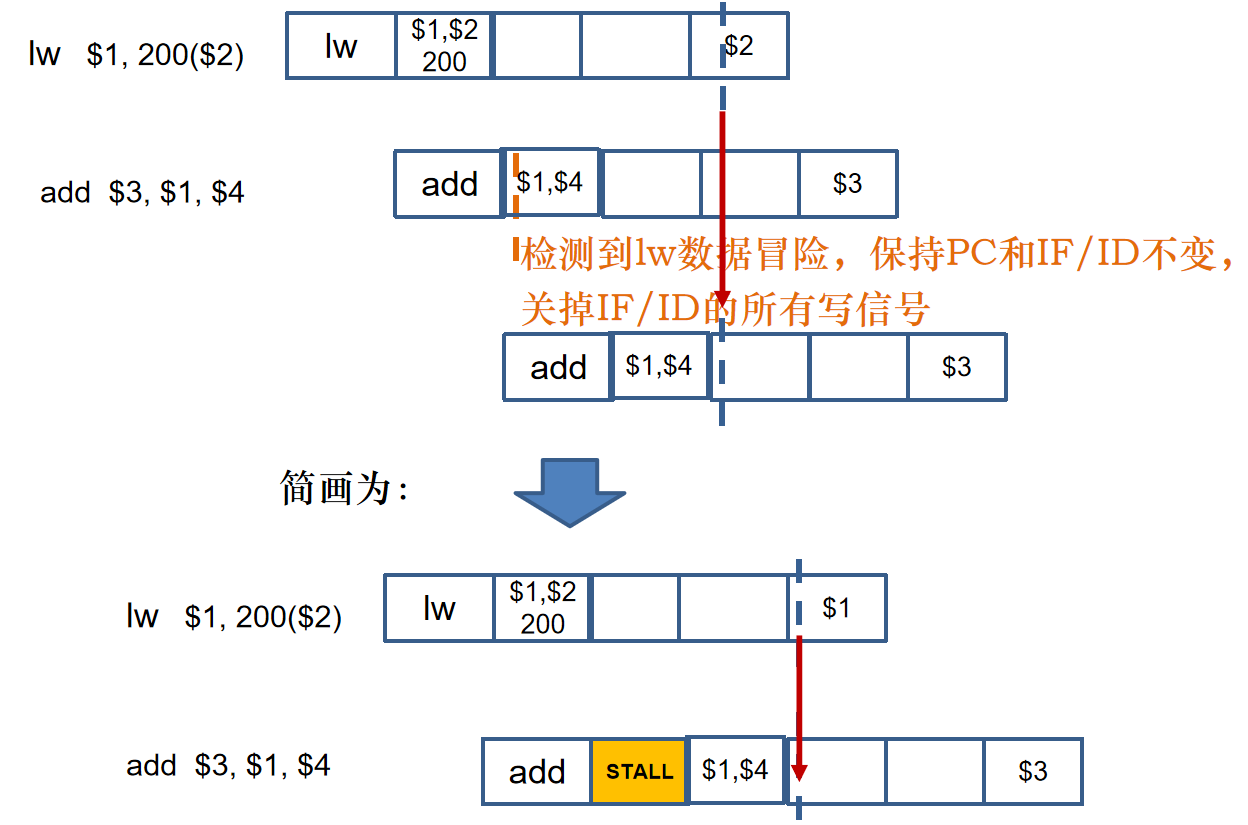 |
|---|---|
对于lw指令访存读出的数据在MEM级才产生,尝试添加旁路,发现数据流向和时间相反。对这种取数-使用型数据冒险,必须在lw指令后添加一个气泡/阻塞周期。
检测lw数据冒险的检测条件:
if (ID/EX.MemRead and ((ID/EX.Rt = IF/ID.Rs) or (ID/EX.Rt = IF/ID.Rt)))Stall the pipeline;暂停流水线:保持PC寄存器和IF/ID寄存器不变,关掉IF/ID的所有写信号。
add指令已经执行IF和ID周期,我们并不是真的塞入一条空指令nop,而是==把add的控制信号全部清零、使其不改变任何状态单元,将其变为空指令,同时将add指令的地址(PC+4-4)重新写回PC,在lw的EX周期重新执行add指令,==阻塞由冒险检测单元控制实现。
增加了暂停流水线的机制:封锁PC寄存器和IF/ID寄存器的更新以及冒险检测单元控制,如下图所示。
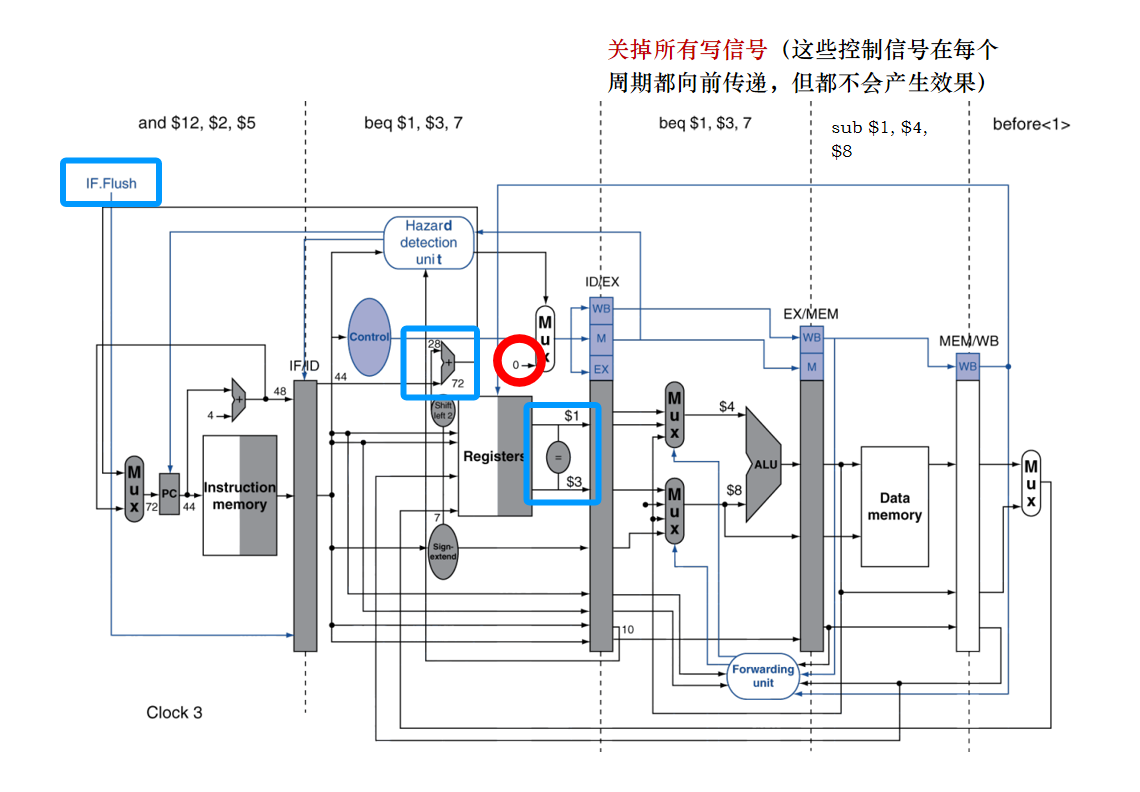
所以,如果beq的上一条指令是R型指令,且需要比较R型指令的运算结果,则在将R型ALU结果旁路到IF/ID寄存器的基础上还要将beq指令阻塞1个周期。如果beq比较上一条lw指令取得的数据,需要阻塞2个周期。
4.3 控制冒险的解决
分支指令beq在MEM级才能决定是否分支,此前beq后的三条指令都已被取到流水线,分支成功却执行了。分支失败才应该执行的指令(或反过来),就产生了分支冒险,是一种典型的控制冒险(control hazard)。
前面详细介绍了解决控制冒险的分支预测技术,这里结合图来分析如何通过缩短分支延迟解决控制冒险。在此前的分析中,beq在MEM级才能决定是否分支,如果能将整个分支过程提前到EX级,就能将分支错误时的开销从3条指令(3个周期)缩短到2条指令(2个周期);提前到ID级,就能将分支错误开销进一步降低到1条指令。
分支决策提前的条件:
-
提前计算分支目标地址在ID级中已形成了PC值和地址偏移量,因此将分支地址计算从EX级前移到ID级即可。
-
提前判断分支条件需要在ID级判断两个寄存器的值是否相等。由于可能存在数据冒险,需要把数据转发至ID级进行相等检测。
但是,如果分支预测错误时,必须清空IF/ID寄存器,确保错误路径的指令不会进入后续阶段。
IF.Flush冲掉IF/ID寄存器的实现方式
- 指令编码变全0:流水线定义编码为全0的指令为nop指令,语义:什么工作都不做。 IF.Flush有效,则将该指令在打入IF/ID寄存器时变为nop指令。
- 指令编码不变:将该指令的所有写信号全部关闭。
分支指令beq的前1条指令sub与分支指令有关于$1的数据冒险, 假定流水线对分支不发生进行了优化,并且分支的执行提前到流水线的ID级。试说明下面的指令序列在分支发生时的执行情况:

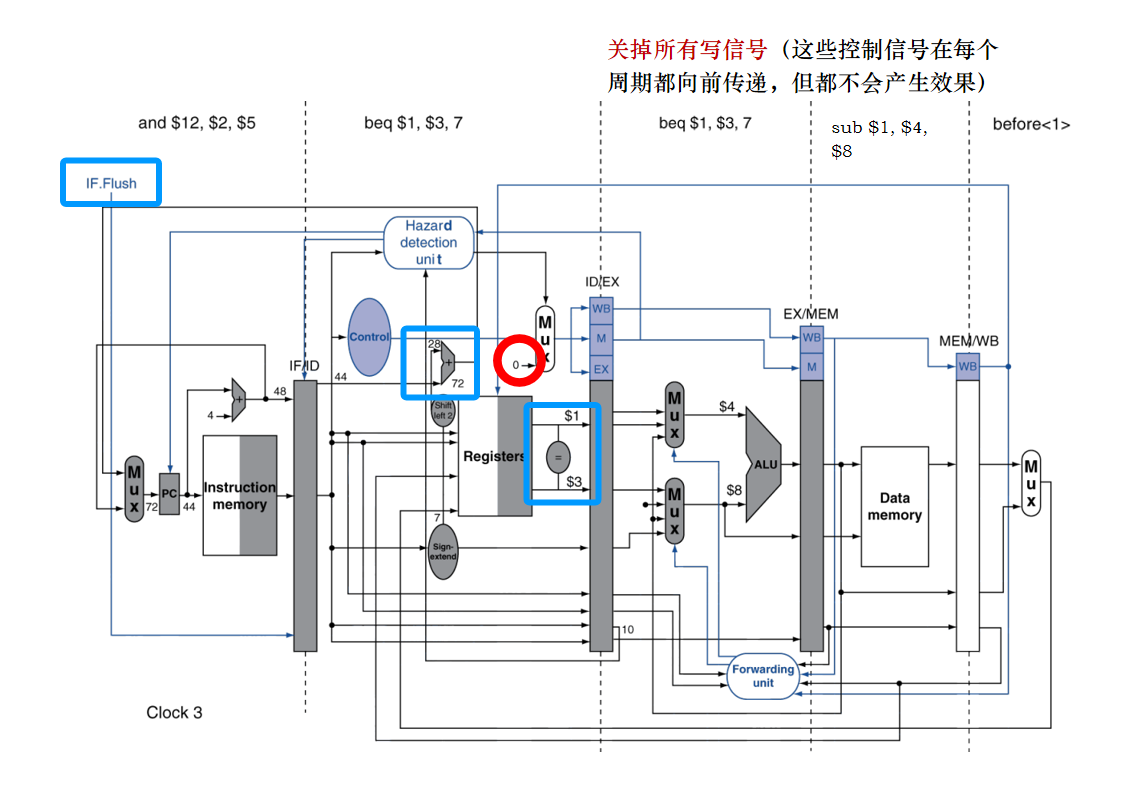
4.4流水线中异常事件的处理
异常(Exception)事件是指在程序执行过程中,由于操作非法,例如除数为0,结果上溢等,或者用户程序试图执行去处理异特权指令等。这时处理机应该转向特定的程序常事件。
处理的方法一般是先向用户报告哪条指令引起了异常事件以及引起了何种异常事件,然后继续用户程序的执行,或者结束用户程序的执行,返回到操作系统。
本节所指的异常是广义异常,包括了中断和狭义上的异常。
异常能在流水线的哪些阶段中产生?

非流水线处理机是在一条指令执行的过程中检测异常事件,当异常事件发生时处理机在该指令结束时转向异常事件处理程序,处理完毕后再返回到用户程序。当这些事件发生时,处理机应该适当地保存当前处理机的状态,比如当前程序计数器PC的内容,处理机状态寄存器的内容,等等。然后,处理机由硬件向PC写入特殊的值,即异常事件处理程序的入口地址,以实现程序的转移。
在流水线上出现异常的情况又是怎样的?
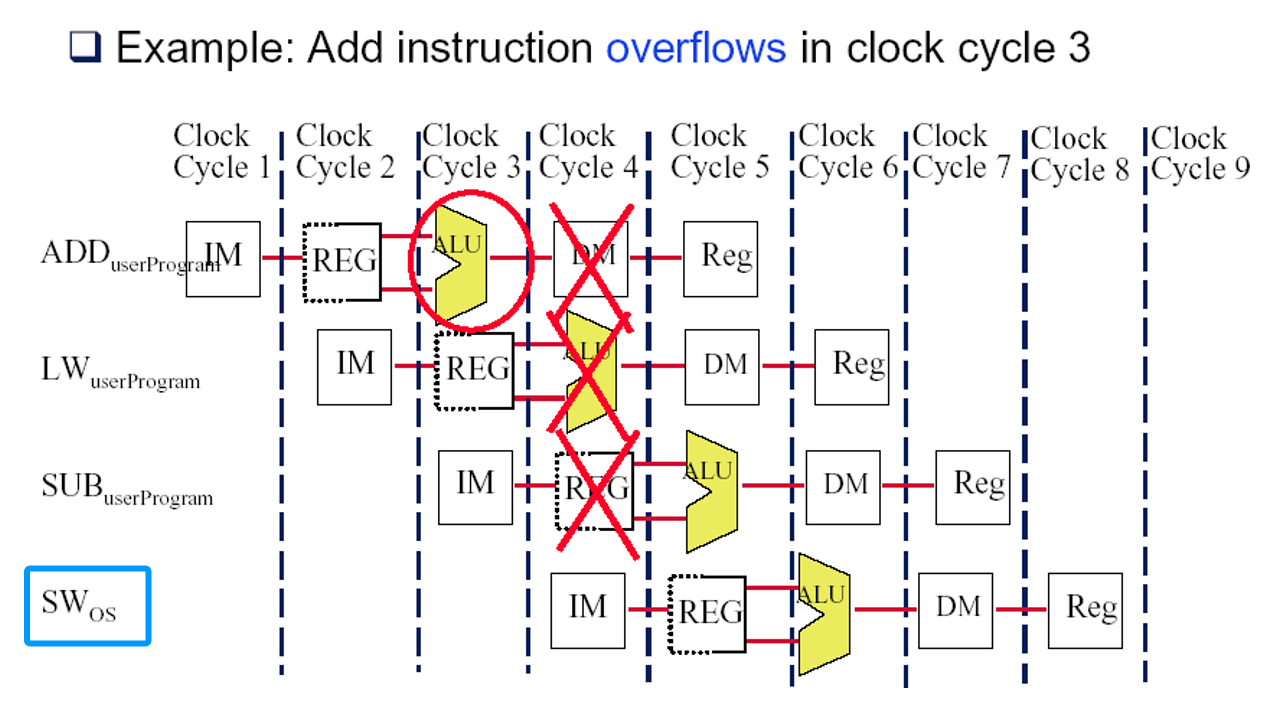
加法指令在第3个时钟周期中产生了溢出。解决办法:停止和重新开始执行。
- 强制一个trap指令进入流水线
- 关掉出错指令及后面指令的所有写操作,直到trap指令开始执行,这避免了后续指令改变机器出错时的状态。
- 当trap指令开始执行,唤醒OS ,OS保存出错指令的PC值,OS试图修复异常,然后重新执行出错指令,重新取出错指令的地址送给PC,重新执行出错指令。
在MIPS中:
- 由System Control Coprocessor (CP0)进行异常管理
- 出错指令的地址保存在:Exception Program Counter (EPC)
- 出错原因保存在:Cause register,We’ll assume 1-bit,0 for undefined opcode, 1 for overflow
- 统一异常向量入口地址:8000 0180
这里以add $1, $2, $1作为算术溢出类型异常的例子,假设该指令产生了一个算术溢出,则必须清除流水线中该指令后续进入流水线的指令,并开始在新异常地址取指。可使用之前的重置机制,异常可被视为另一种形式的控制冒险。
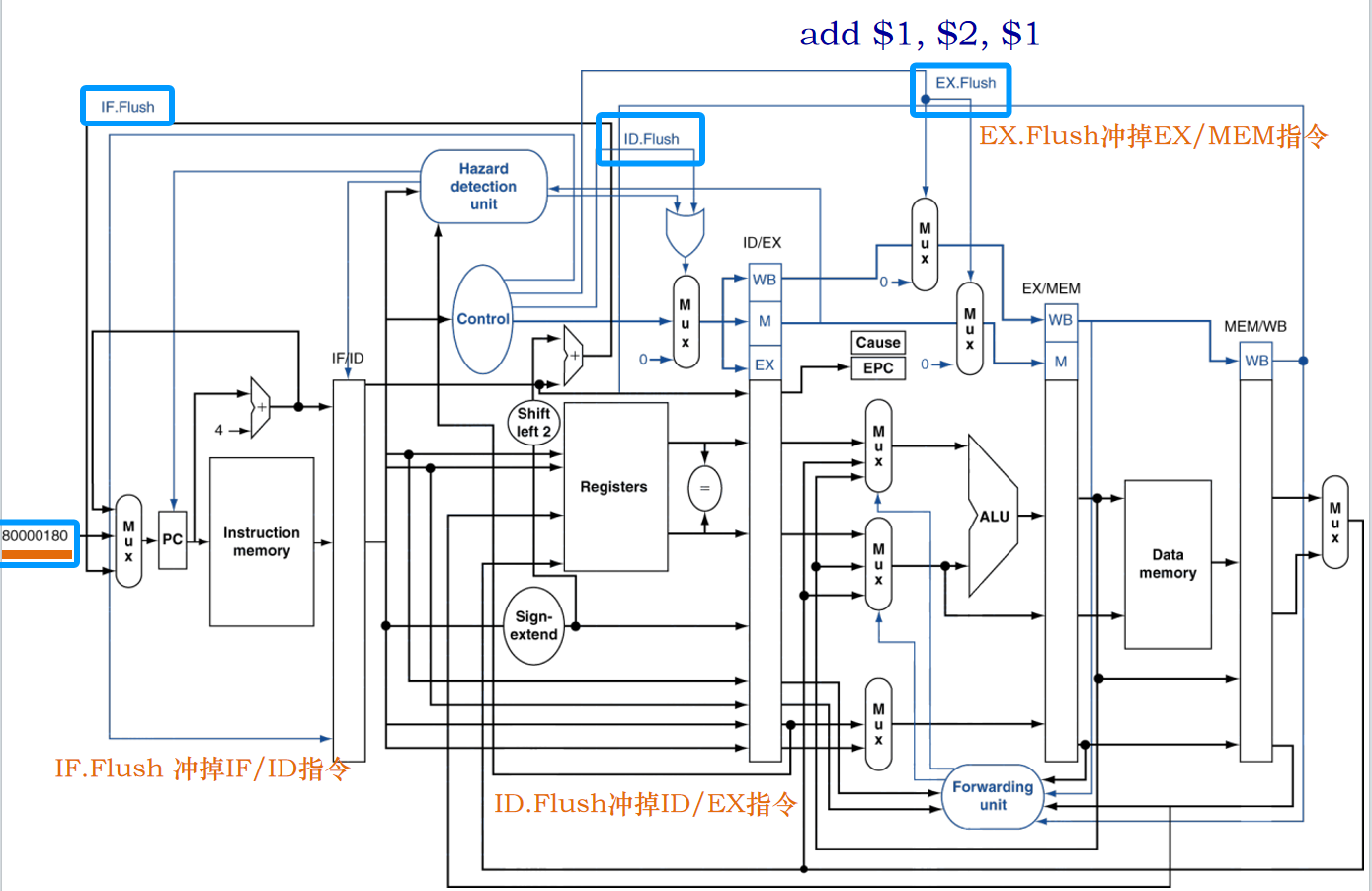
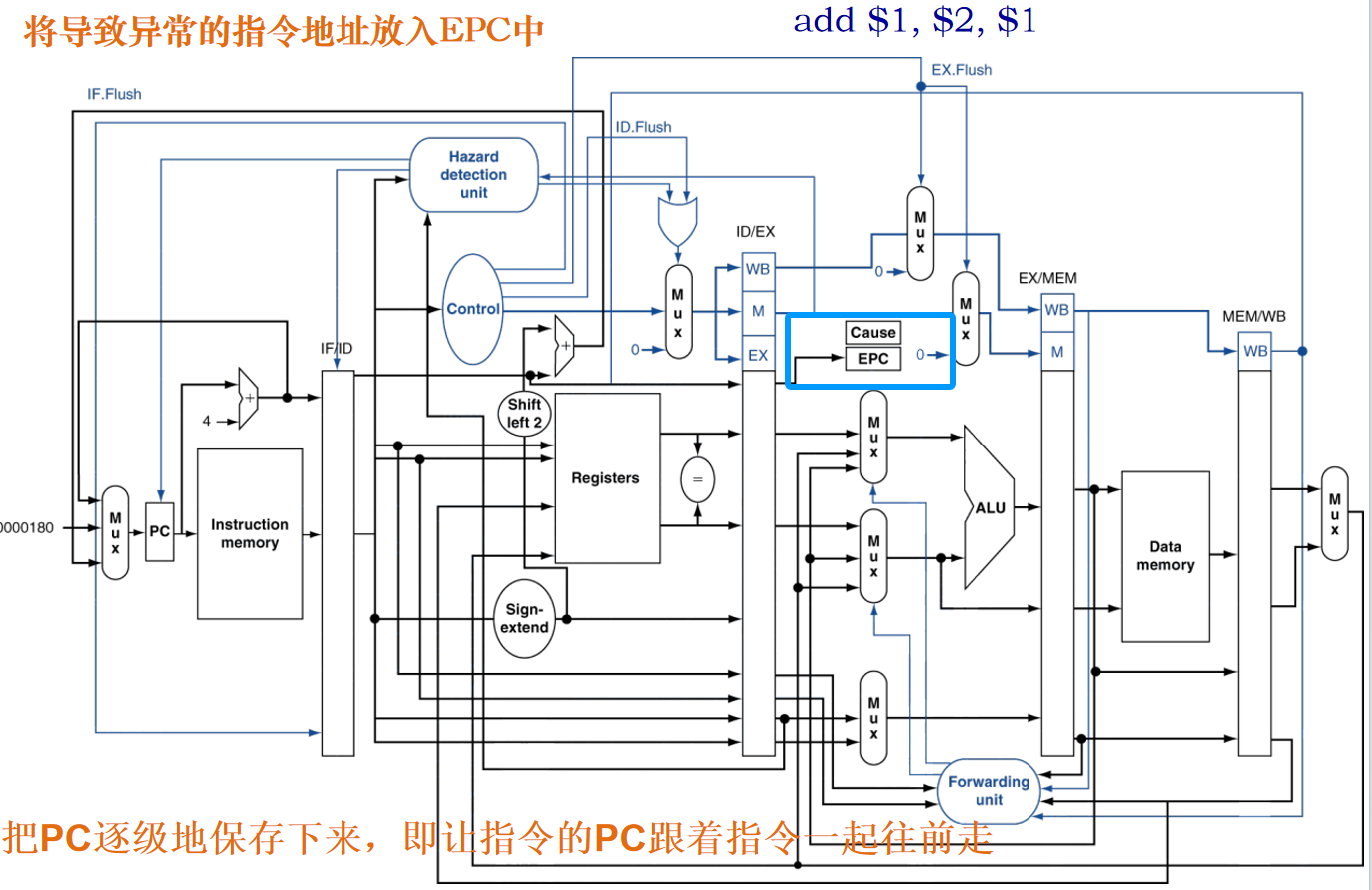
如何实现中断或异常时PC的保存?流水线处理机在每个周期都取来一条指令,假如当处在执行(EXE)级的指令(假设该指令的字地址为n)的操作结果上溢时,PC已经不再是n了。PC=n+8。把PC逐级地保存下来,即让指令的PC跟着指令一起往前走,同时将导致异常的指令地址放入EPC中。这样是为了保存发生异常的地址和原因。
4.5 精确异常和非精确异常
精确异常 Precise Exceptions:当异常出现时,如果出错指令之前的指令能正常完成,出错指令及其后的指令能够重新正常执行,则称该流水线是精确异常。
- 出错指令之前的指令正常完成
- 出错指令及其后的指令能重新正常执行的条件:出错指令及其后的指令没有改变机器的状态。
在这个模型下,重新执行就很简单了,简单地重新恢复执行出错指令,如果它不是一个可恢复执行的指令,则执行下一条指令。
非精确异常:当不同指令需要不同时钟周期才能完成的时候难以实现精确异常。在某条指令产生异常之前,后面的指令可能已经执行完毕。例如下面两条指令:
Multiply r1, r2, r3 ; 需 10 cycles
Add r10,r11,r12 ; 需 5 cycles
Add在Multiply完成之间执行完毕。如果在Add执行完之后且Multiply完成之前,Multiply发生溢出,此时R10的值已经被更新过了。异常发生后,要先恢复Multiply执行前的状态然后再重新执行Multiply很困难,此为非精确异常
某些处理器实现了两种工作模式:精确异常和非精确异常。
- 特殊的软件指令保证精确异常
- 处理器若工作在精确异常模式下,运行速度更慢。
- 一般来说,整数操作所产生的异常是精确的,浮点异常一般不是精确的。
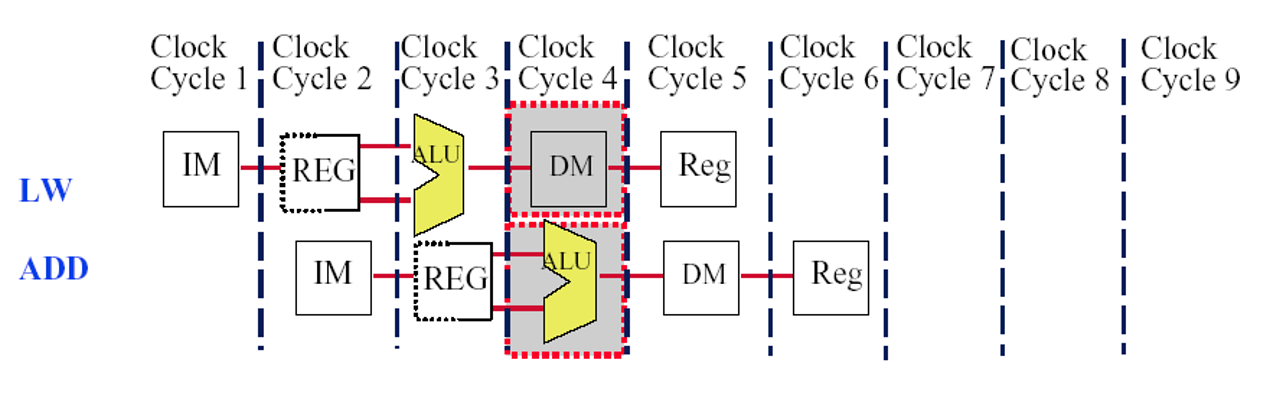
MIPS一个时钟周期中的多个异常,在Clock Cycle 4, LW指令可能出现数据缺页异常,且ADD指令 可能出现算术异常。CPU应该先响应哪个异常?
应该先响应前一条指令,即LW指令的缺页异常,然后==重新开始LW指令的执行。==当LW指令执行完毕后,ADD’s 算术异常会再次发生。
多个异常的乱序产生,ADD指令在取指阶段导致了一个指令预取异常,LW指令在访存阶段导致了一个异常。如果我们要实现精确异常,LW 异常必须先被处理。实现精确异常的方式:设置一个按指令顺序推迟异常响应的机制。
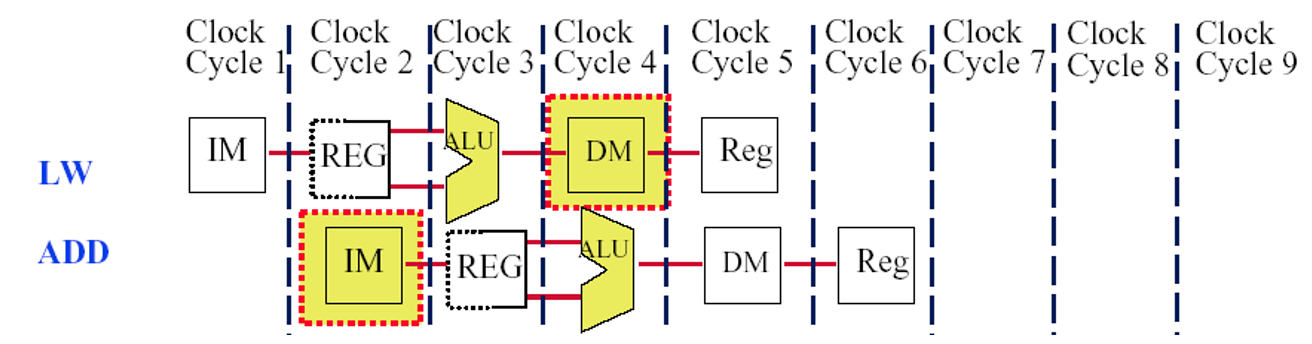
精确异常的实现方式:当一条指令即将离开流水线(MEM/WB), 检查是否有挂起未响应的异常。 如果一条指令产生过了多个异常,应先响应最早出现的异常。
可行的办法是:在流水线中的每条指令有一个异常状态向量表: 如果一个异常被推迟了,它就被添加到对应的向量表,并禁止所有会影响系统状态的写操作。
五、指令级并行
流水线挖掘了指令间潜在的并行性:
- 增加流水线的深度以重叠更多的指令
- 复制处理器内部部件的数量
每个流水级可以启动多条指令,称为多发射;CPI<1,例如四路多发射处理器的CPI可达0.25,如果是5级流水线,可有20条指令在流水线中;实现的方式:
- 编译器完成(静态多发射)
- 硬件完成(动态多发射)
1.1 静态多发射处理器
静态多发射处理器,使用编译器来帮助封装多条指令并处理冒险。在给定时钟周期内发射的多条指令称为发射包(超长指令字)。
静态多发射处理器的不同:
- 某些设计中,编译器负责避免所有的冒险,通过调度指令和插入nop等方法使代码在执行时完全不需要冒险检测。
- 某些设计中,由硬件检测数据冒险并在两个发射包间产生阻塞,而编译器只负责避免同一个发射包中两条指令的依赖。
一个简单的双发射MIPS处理器,前一条指令是ALU操作或分支;后一条指令是lw或sw;实在没有配对指令,就用nop指令代替;
对处理器的要求:每个时钟周期要取回和译码64位指令;两条指令成对放在64位对齐的内存区域;
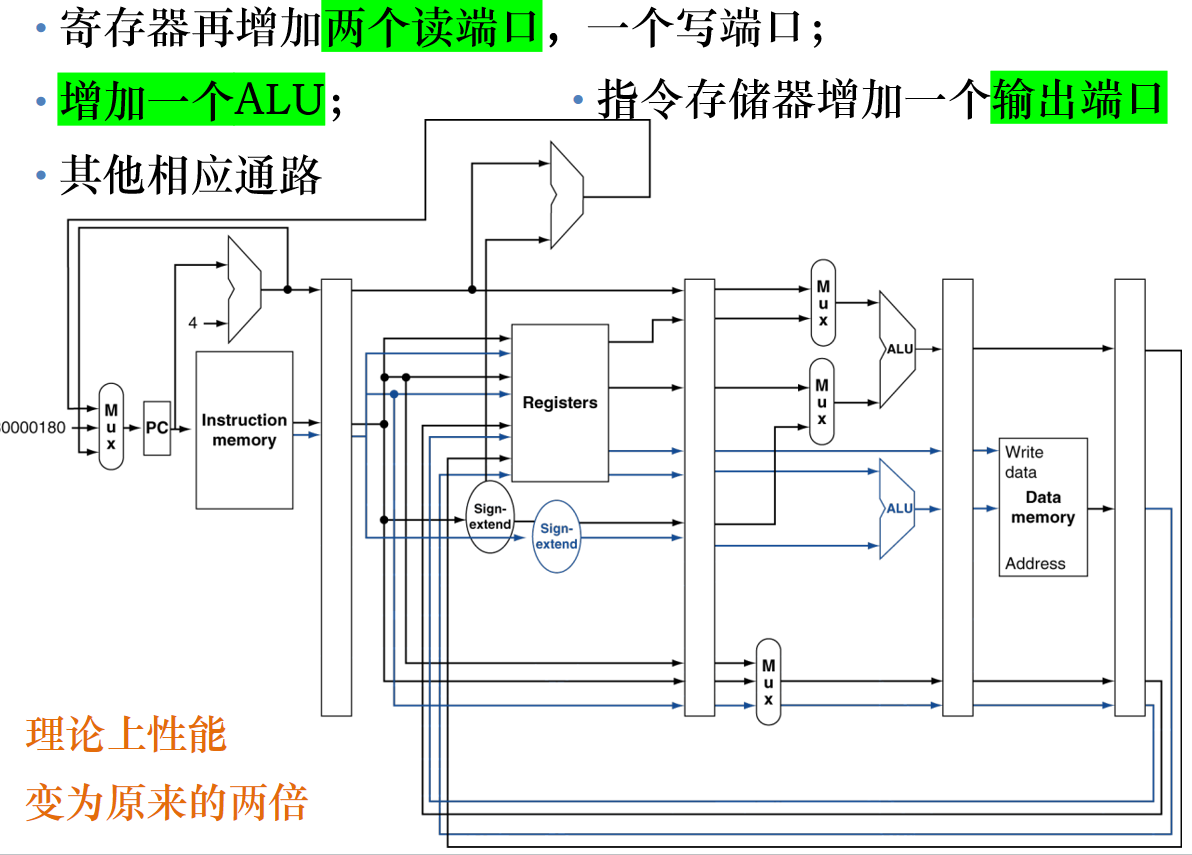
理论上性能,变为原来的两倍,但是额外的重叠使数据冒险和控制冒险带来的性能损失也增加了。lw指令的结果不能再下个时钟周期使用,意味着下一个发射包的两条指令都不能使用。
一种重要的从循环中获得更多性能的编译技术叫循环展开。
- 循环体被复制多份;
- 重叠不同循环体的指令可以获得更多的ILP;
- 消除不必要的循环开销指令;
1.2 动态多发射处理器
动态多发射处理器,也称为超标量处理器。指令顺序发射,在每个周期由硬件决定是发射0条,1条还是多条指令。
与静态多发射的异同:
同:动态多发射仍然依赖编译器对指令的调度,错开依赖指令
异:由硬件保证执行的正确性和速度,尽量不产生冒险和阻塞(采用了动态流水线调度技术)
动态流水线调度,动态选择下一条要执行的指令,甚至重排避免阻塞。流水线被划分为3个主要单元:取值与发射单元,多个功能单元,一个提交单元。
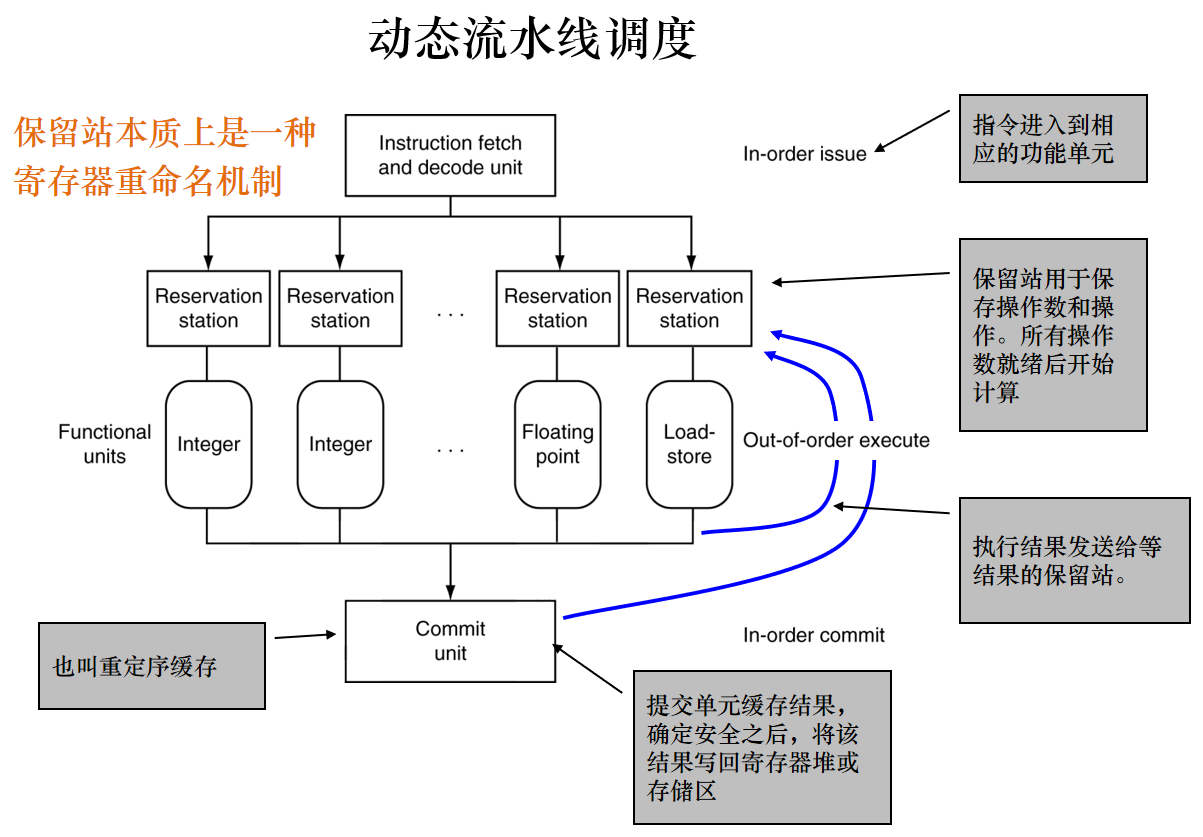
动态调度处理器的优势:
- 并不是所有阻塞都是可以事先知道的,尤其是Cache缺失可能导致不可预测的阻塞。动态调度可以调度其他无关指令避免性能损失;
- 编译器无法预知的信息,如分支结果,可由动态推测解决;
- 流水线延时和发射宽度在不同处理器上实现不同,最佳编译也不固定。如:调度一个互相依赖的指令序列的具体方式和发射宽度密切相关,流水线的结构也影响循环展开的效果。动态调度通过硬件将这些细节对用户透明,代码具有更好的通用性。
有空在补充…
结束语
感谢阅读吾之文章,今已至此次旅程之终站 🛬。
吾望斯文献能供尔以宝贵之信息与知识也 🎉。
学习者之途,若藏于天际之星辰🍥,吾等皆当努力熠熠生辉,持续前行。
然而,如若斯文献有益于尔,何不以三连为礼?点赞、留言、收藏 - 此等皆以证尔对作者之支持与鼓励也 💞。