动态环境下的人员感知具身导航!HA-VLN:具备动态多人互动的视觉语言导航基准与排行榜

- 作者:Yifei Dong1^{1}1, Fengyi Wu1^{1}1, Qi He1^{1}1, Heng Li1^{1}1, Minghan Li2^{2}2, Zebang Cheng1^{1}1, Yuxuan Zhou3^{3}3, Jingdong Sun4^{4}4, Zhi-Qi Cheng1^{1}1, Qi Dai5^{5}5, Alexander G Hauptmann4^{4}4
- 单位:1^{1}1华盛顿大学,2^{2}2Galbot,3^{3}3曼海姆大学,4^{4}4卡内基梅隆大学,5^{5}5微软研究院
- 论文标题:HA-VLN: ABenchmark for Human-Aware Navigation in Discrete–Continuous Environments with Dynamic Multi-Human Interactions, Real-World Validation, and an Open Leaderboard
- 论文链接:https://arxiv.org/pdf/2503.14229
- 项目主页:https://ha-vln-project.vercel.app/
- 代码链接:https://github.com/F1y1113/HA-VLN
主要贡献

- 提出了HA-VLN基准测试,将离散和连续导航范式统一起来,并在明确的社会意识约束下进行。它包括标准化的任务定义、升级的数据集和模拟器、广泛的基准测试、真实世界的机器人测试以及公开的排行榜。
- 标准化任务与指标:将离散和连续导航在社会意识约束下统一起来,确保目标和评估的一致性。
- 升级数据与HA-VLN模拟器:在HAPS 1.0的基础上,提出了HAPS 2.0(包含486个SMPL序列),并开发了两个先进的模拟器(HA-VLN-DE和HA-VLN-CE),它们结合了多视角人类标注、双线程渲染和严格的碰撞检查,能够容纳多达910个活跃个体。
- 全面的基准测试:在R2R-CE的基础上增加了16,844条以人为中心的指令,并在统一的指标下对多个智能体进行基准测试,揭示了多个人类动态和部分可观测性给领先的VLN智能体带来的巨大挑战。
- 真实世界验证与排行榜:通过物理机器人在拥挤的室内空间中成功导航,有力地证明了从模拟到现实的转移,并提供了一个公共排行榜,用于在多个人类场景中对离散和连续任务进行全面评估。
研究背景
- 视觉语言导航(VLN)系统:使机器人能够理解多模态指令并在真实或模拟空间中导航。然而,现有的VLN系统大多只关注离散(全景)或连续(自由运动)范式之一,忽略了人类动态和部分可观测性的复杂性,这限制了它们在现实世界中的适用性。
- 存在的挑战:社会意识未被充分探索,人类参与者常被忽视或简化为静态障碍;指令复杂性未被现有语料库很好地捕捉;静态环境假设占主导,忽视了实时重规划的需求。
人类感知的视觉语言导航任务
任务动机与概述
- 动机:传统VLN系统大多忽视了人类动态和部分可观测性,而现实世界中的导航场景往往涉及动态的人类活动,如人群移动、个人空间需求等。因此,提出了人类感知的视觉语言导航(HA-VLN)任务,要求智能体在遵循自然语言指令的同时,能够应对动态的人类活动,预测人类运动,尊重个人空间,并调整路径以避免碰撞。
- 概述:HA-VLN任务要求智能体在动态环境中导航,同时遵循自然语言指令。与标准VLN不同,HA-VLN中的智能体需要考虑人类的动态行为,如“去楼上,那里有人边走边打电话……”,并据此调整路径。
状态与动作空间
- 状态空间:在每个时间步ttt,智能体的状态st=⟨pt,ot,ΘFOVt⟩s_t = \langle p_t, o_t, \Theta_{FOV}^t \ranglest=⟨pt,ot,ΘFOVt⟩,其中ptp_tpt是智能体的3D位置,oto_tot是其朝向,ΘFOVt\Theta_{FOV}^tΘFOVt是其以自我为中心的视图。在离散环境(DE)中,智能体在预定义的视点之间跳跃,每个视点提供一个RGB观测。在连续环境(CE)中,智能体看到一个90°视场的RGB+D(深度)馈送,并可以进行小增量移动(例如,向前移动0.25米,转动15°)。
- 动作空间:在两种环境中,动作空间均为A={aforward,aleft,aright,aup,adown,astop}A = \{a_{forward}, a_{left}, a_{right}, a_{up}, a_{down}, a_{stop}\}A={aforward,aleft,aright,aup,adown,astop}。
人类感知约束
- 动态人类模型:人类根据HAPS 2.0中的3D运动轨迹自然移动,这些运动轨迹会实时更新。
- 个人空间:智能体必须避免过于接近人类(在DE中距离小于3米,在CE中距离小于半径之和)。
- 以人为中心的指令:语言通常描述人及其活动(例如,“绕过正在打电话的人”),需要文本提示与实时视觉输入之间的一致性。这些详细的人类位置和运动是通过多阶段管道标注的,涉及广泛的标记和验证以确保真实性。
动态与部分可观测性
- 由于人类可能不可预测地移动,每个时间步是一个部分可观测马尔可夫决策过程(POMDP)。新状态st+1s_{t+1}st+1取决于智能体的动作和同时发生的人类运动(例如,有人让开或从走廊中出现)。
- 智能体必须推断未观测到的因素——例如,一个人是否会让出空间——并在探索(寻找替代路线)和利用(继续已知路径)之间取得平衡,以高效地到达目标。
挑战与DE-CE协同作用
- 挑战:
- 社交导航:无碰撞运动,尊重个人空间。
- 人类对齐指令:语言可能涉及短暂的活动或互动。
- 自适应重规划:人类可以不可预测地阻塞或解阻通道。
- DE与CE协同作用:DE允许通过离散视点跳跃快速原型设计,而CE近似于现实世界的动态和运动保真度。通过整合这两种方法,HA-VLN涵盖了从大规模模拟到实际机器人部署的整个范围,显著扩展了社会意识、以人为中心的导航研究。
HA-VLN模拟器
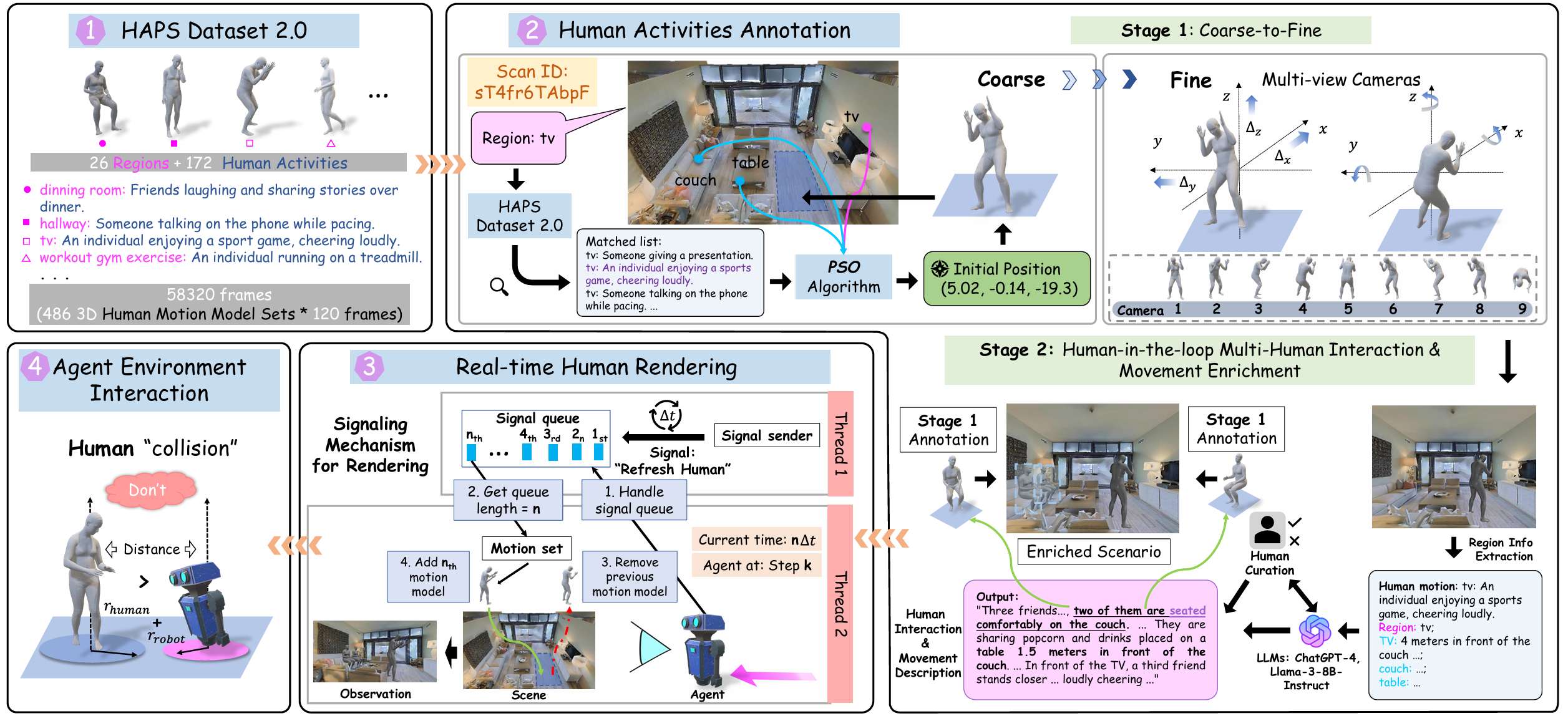
动机与概述
- 动机:现有的模拟器要么忽视人类行为,要么将人类建模为静态障碍。HA-VLN模拟器通过在离散和连续的3D环境中放置多个动态移动的人类,解决了社会意识导航中的长期挑战。它具有高保真度的运动、多人互动和现实世界的复杂性,如群体聚会、自发运动和个人空间限制。
- 概述:HA-VLN模拟器基于HAPS 2.0数据集,利用486个运动序列,涵盖了室内和室外活动。它提供了两个互补模块:HA-VLN-CE用于连续导航,HA-VLN-DE用于离散导航。这两个模块共享一个统一的API,提供一致的人类状态查询、动态场景更新和碰撞检查。
HAPS 2.0数据集
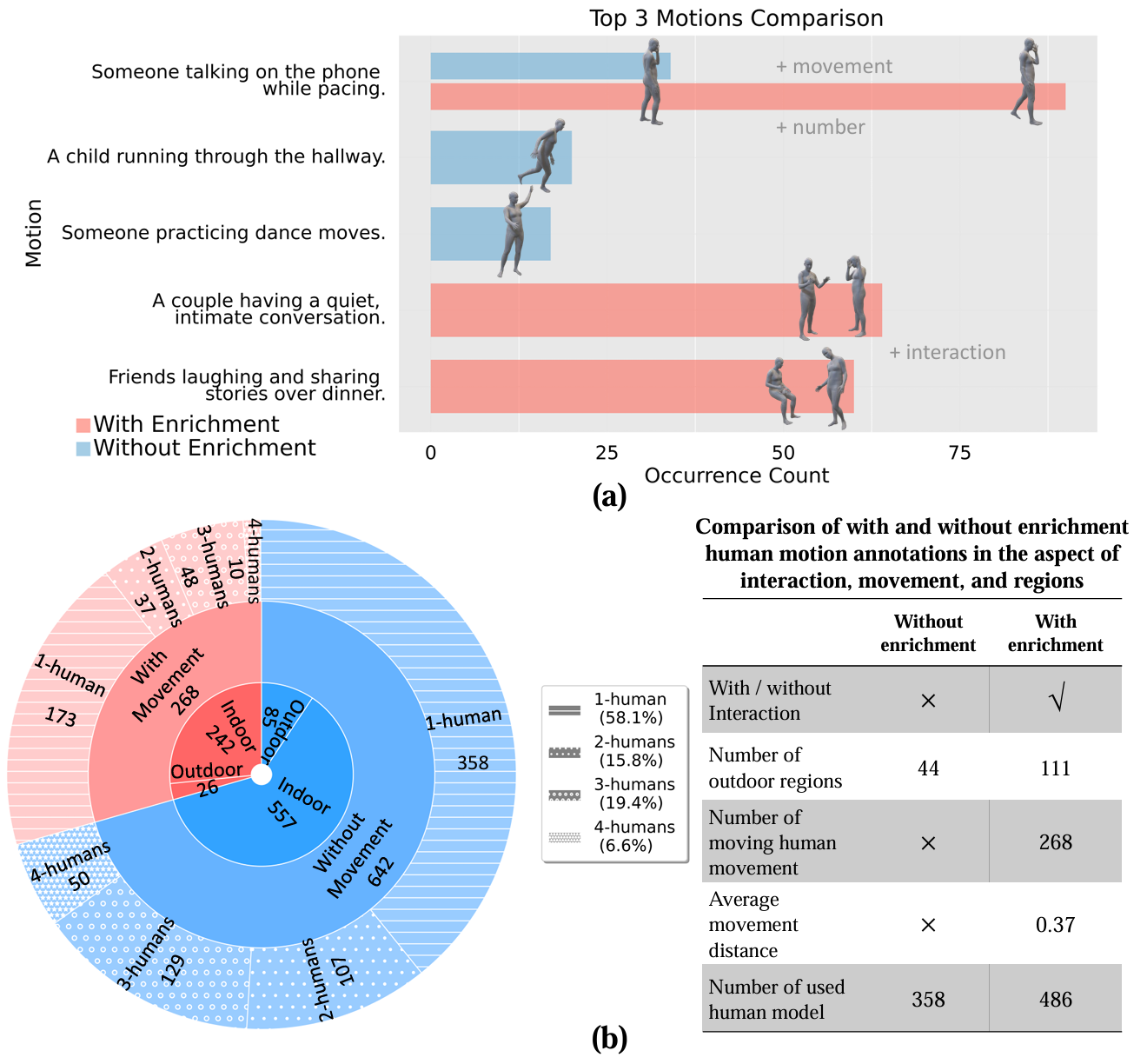
- 运动描述对齐:HAPS 2.0数据集通过两轮人工验证来对齐文本描述和运动数据,消除了HAPS 1.0中超过一半的不准确配对,最终得到172个精确对齐的运动。
- 多样化区域-运动关系:重新组织区域-运动关联,使同一运动能够适应各种环境,包括室内外场景,从而更真实地反映人类行为,减少环境偏差,提高现实世界适用性。
- 与HAPS 1.0的对比:HAPS 2.0在运动准确性、环境兼容性、失败案例数量和标注工作量等方面均优于HAPS 1.0。它包含26个不同区域,覆盖90个建筑场景,涵盖486个人类活动。
标注流程:粗粒度到细粒度
粗粒度标注
- 区域定义与对象列表:定义每个区域的边界坐标和对象列表。
- 安全距离约束:设置人类与对象之间的最小安全距离为1米,确保布局真实,同时为智能体通行留出空间。
- 自适应惩罚:适应性地对违反约束的布局(如与墙壁相交或人类重叠)施加惩罚,以阻止不可行的姿势并促进场景几何对齐。
细粒度标注
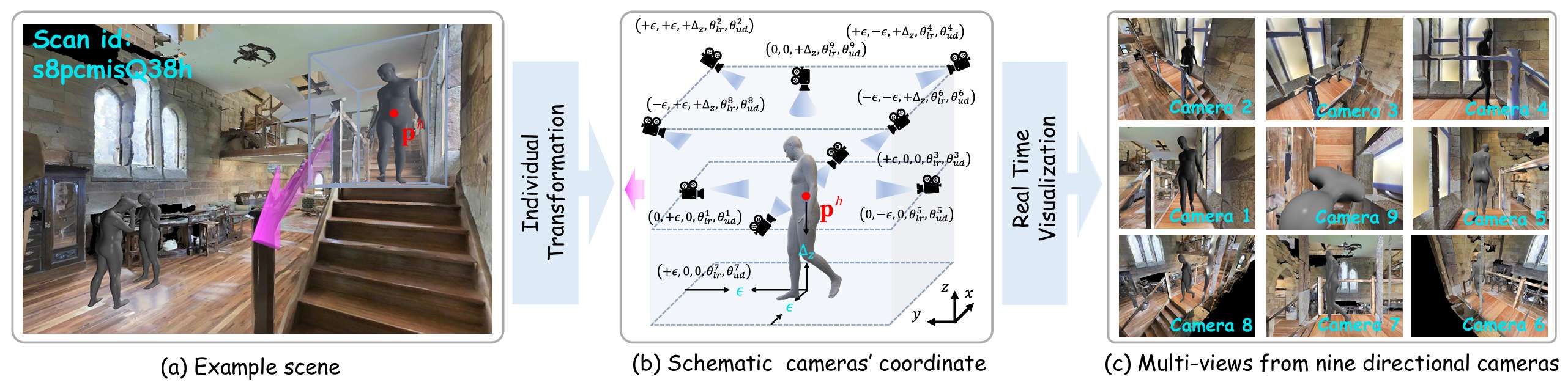
- 相机位置与角度:设置九个RGB相机的位置和角度,以提供全面的多视角视图,用于检测人类与周围物体之间的潜在碰撞或对齐问题。
- 细标注协议:通过六步程序来微调人类的位置和朝向,包括初始视图、多相机观察、垂直碰撞检查、水平平移、侧相机审查和最终输出。
多人类互动与运动丰富
- 人类在环方法:使用大模型(如ChatGPT-4和LLaMA-3-8B-Instruct)提出合理的多人类场景。每个提示都整合了有关现有人类运动、对象位置和区域上下文的详细信息,引导语言模型生成丰富的多角色互动。
- 迭代标注工作流:对语言模型产生的候选互动进行四轮手动细化和验证,以纠正不一致之处并确保上下文对齐。
- 丰富互动的例子:展示了如何通过添加额外的人类来丰富场景,例如在客厅中,两个人坐在沙发上分享爆米花,而第三个人在电视前欢呼。

实时渲染与智能体交互
- 多线程管道:通过受生产者-消费者原则和Java风格信号启发的多线程管道,将动态人类模型集成到模拟中。智能体可以实时观察和响应人类运动,从而促进适应性导航策略。
- 系统初始化:加载环境、人类运动数据和对象模板管理器,以高效处理3D模型模板。
- 信号发送线程(线程1):以固定频率将“刷新”信号放入队列,模拟人类运动的连续更新。
- 主线程(线程2):在智能体即将行动时,检查队列中的刷新信号,计算当前帧索引,并更新人类模型的位置和朝向。
API设计
- 离散环境(DE):通过实时导航图跟踪所有智能体和人类的位置,以2D顶视图显示。每个人类的活动都存储为一个元组,包含人类的2D坐标、与智能体的距离、相对朝向和活动状态。
- 连续环境(CE):API主要关注三个组件:人类活动监控、环境感知和导航支持。实时跟踪和分析人类活动,维护动态场景图,并使用基于A*的规划器计算候选轨迹,同时考虑动态人类和静态障碍物。
HA-VLN智能体
HA-R2R数据集
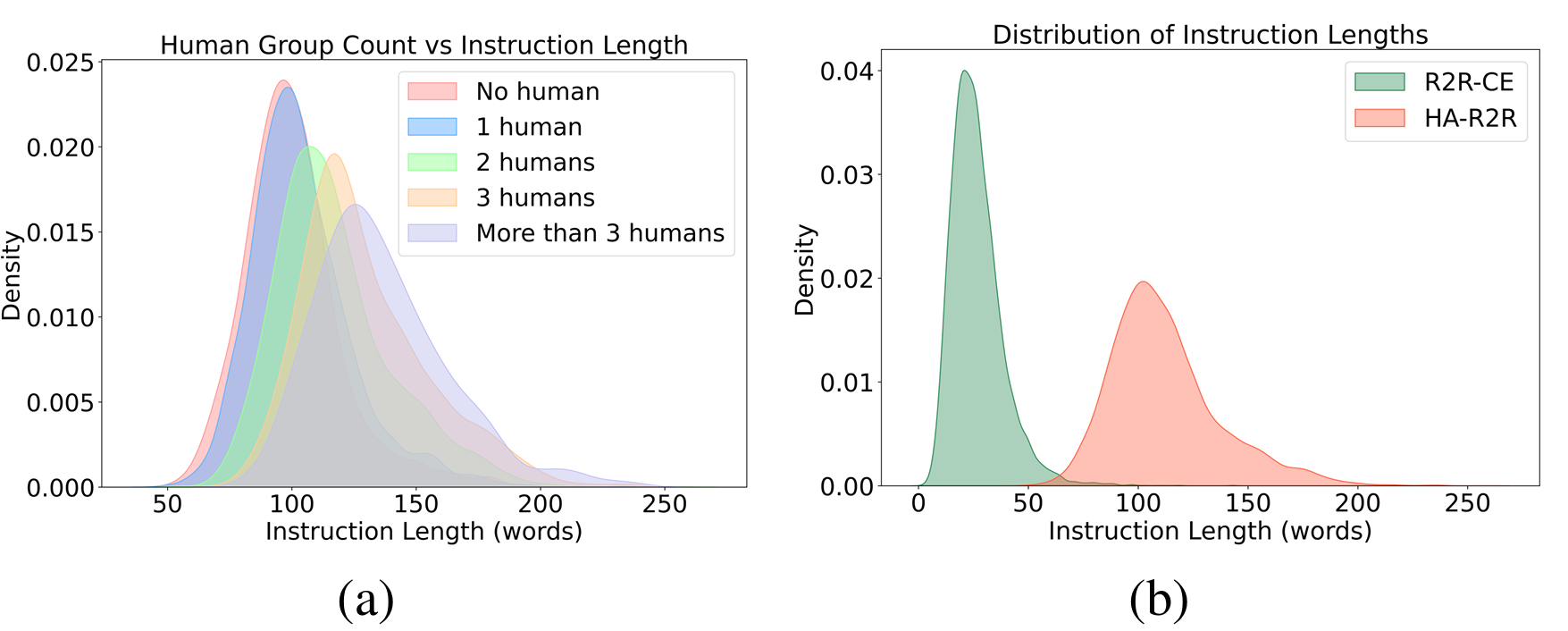
现有的Room-to-Room in Continuous Environment(R2R-CE)数据集缺乏对人类互动的明确关注。因此,研究者开发了HA-R2R数据集,扩展了R2R-CE,增加了16,844条精心策划的指令,强调社交细微差别,如对话、走廊交叉和近碰撞事件。
- 通过设计针对大型语言模型(LLM)的目标提示来生成这些丰富的指令,捕捉多样化的现实世界社交场景。
- 这些指令从静态路径转变为需要智能体解释如“避开在酒吧附近聊天的情侣”或“让出正在穿过走廊的人”的指令。
HA-VLN-VL智能体
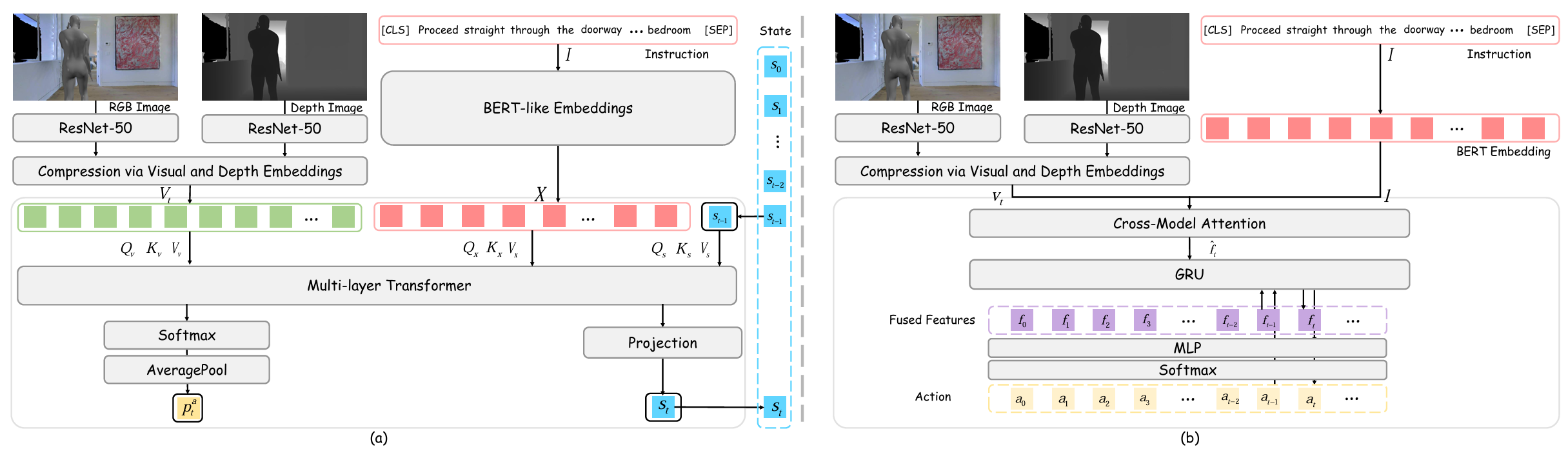
基于Recurrent VLNBERT,采用模仿学习方法,强调在复杂设置中仅通过更强的多模态基础就能提升性能。
- 在每个时间步ttt,智能体更新其隐藏状态sts_tst并预测动作分布patp_a^tpat。
- 使用多层Transformer处理输入,使用专门的状态标记来关注语言和视觉标记。最终动作概率是注意力权重的平均值。
HA-VLN-CMA智能体
基于交叉模态注意力(CMA),在每个时间步融合文本嵌入和视觉特征,通过多头注意力机制产生联合表示,然后通过MLP映射到动作概率。
- 利用环境Dropout(Envdrop)和数据集聚合(DAgger)来解决部分可观测性和不可预测运动的挑战。
- Envdrop随机掩盖视觉语言流中的特征,模拟人群或遮挡物体造成的遮挡。
- DAgger维护智能体状态的重放缓冲区,使智能体能够迭代纠正先前的错误。
真实世界验证与排行榜
真实世界验证与设置
- 实验设置:在四种室内空间(办公室、客厅、走廊、大厅)中部署训练有素的智能体,每个空间都有2-4名自由移动的志愿者。实验在适度拥挤的条件下进行,但面临在狭窄走廊或人群突然聚集时的挑战,突出了在部分可观测性下稳健重新规划的需求。
- 硬件平台:使用Unitree Go2-EDU四足机器人,配备Intel Realsense D435i RGB-D相机、MID360 3D LiDAR和IMU,用于机载感知和控制。
HA-R2R测试数据集与排行榜
- 数据集构成:HA-R2R包含16,844条指令,涵盖90栋建筑扫描中的910个标注人类模型。测试分区包含3,408条指令,分布在18栋保留的建筑中,强调多人路线。数据集分为训练(10,819)、已见验证(778)、未见验证(1,839)和测试(3,408)。
- 排行榜:为主机提供HA-R2R-DE(离散)和HA-R2R-CE(连续)的排行榜,关注碰撞相关(TCR、CR)和导航(NE、SR)指标。提交可能包括智能体代码或轨迹,提供可复制的服务器端评估,并为以人为中心、动态的VLN研究设定新的基准。
实验
HA-VLN-CE:连续导航
- 任务定义:HA-VLN-CE通过在逼真的3D环境中填充多个独立移动的人类,扩展了VLN-CE。智能体基于自然语言指令通过连续低级动作进行导航,目标是提高成功率(SR),同时限制碰撞(TCR、CR)。这种设置反映了现实世界条件,旁观者可能会意外改变路径,要求反应性策略和复杂的感官整合。
- 基线模型:系统地对两个显著的连续导航模型BEVBert和ETPNav进行基准测试,以及HA-VLN-CMA和HA-VLN-VL智能体。每个方法都在两种配置下进行训练/评估:重新训练(仅在HA-VLN任务上训练/评估)和零样本(仅在VLN-CE任务上训练并在HA-VLN任务上评估)。

- 结果:
- 在HA-VLN任务中整合模型时的显著增益。例如,BEVBert的成功率在已见分割中从0.19提高到0.27,在未见分割中从0.15提高到0.21。
- 相比之下,BEVBert在HA-VLN任务上训练的性能与在VLN-CE任务上训练的相当(成功率:0.54对比0.58)。这种双向评估表明,明确引用动态人群行为可以增强现实世界的导航准备,并确认HA-VLN任务的稳健性。
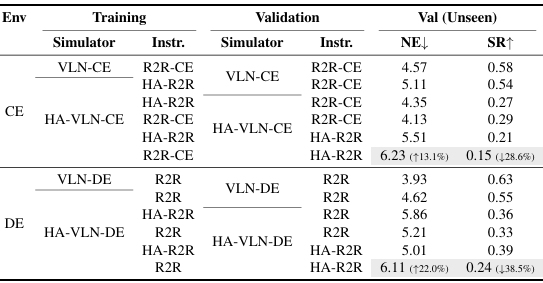
HA-VLN-DE:离散导航
- 任务定义:HA-VLN-DE通过在基于视点的环境中放置多个移动个体,扩展了全景VLN。尽管离散控制将可能的移动限制在预定义的位置,但它并不能消除碰撞,因为旁观者可能会占据选定的视点或在狭窄走廊中阻塞关键转换。
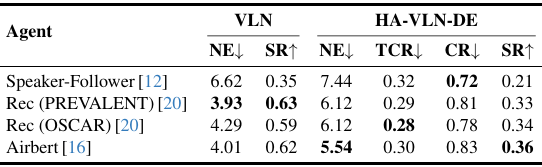
- 结果:尽管Airbert实现了中等的成功率(0.36),但它可能会遭受高达0.83的碰撞率,这表明持续的碰撞风险。忽视人类动态或个人空间的方法往往会在多个旁观者汇聚时失败,特别是在狭窄的路口或门口。因此,仅靠基于视点的导航是不足以实现稳健的社会导航的——即使在离散设置中,适应性碰撞避免策略也是必不可少的。
真实世界实验
- 实验设置:在四种类型的日常室内环境中(每种有三个实例)——办公室、客厅、走廊和大厅——分别在有无人类存在(无旁观者和2-4名自由移动的志愿者)的条件下评估智能体。这种设置模拟了现实的室内交通模式和部分可观测性。

- 观察结果:机器人经常暂停或让路以避开迎面而来的行人。在没有旁观者的情况下,它能顺利导航,但在狭窄走廊或人群突然聚集时会出现碰撞。尽管人类存在总是会降低NSR,但HA-VLN-VL始终优于HA-VLN-CMA-Base,显示出对动态运动的更强适应性。此外,在HA-VLN上训练的智能体比VLN-CE的NSR更高(0.18对比0.12),证明了HA-R2R在现实条件下从模拟到现实的增益。然而,部分可观测性和突然的群体形成仍然是一个挑战,特别是在狭窄通道或拥挤的路口。
- 见解:这些实验证实,经过模拟训练的多人群导航策略确实可以转移到物理机器人上。然而,为了处理室内狭窄环境中的不可预测人类行为,还需要进一步改进碰撞预测和反应控制。
结论与未来工作
- 结论:
- 该研究提出了HA-VLN框架,将离散和连续导航统一在现实的多人群条件下。通过整合动态人类运动、精细标注和高保真模拟器,HA-R2R数据集强调以人为中心的指令。
- 实验表明,社会意识、多人互动和部分可观测性大大增加了复杂性,降低了先进智能体的性能。然而,该方法在平衡安全性、效率和个人空间方面取得了平衡。真实世界的测试证实了从模拟到现实的转移。
- 未来工作:
- 尽管该研究在模拟和真实世界环境中都取得了进展,但在处理不可预测的人类行为方面仍有改进空间。
- 未来的工作可以集中在进一步提高智能体对人类行为的预测能力,以及在更复杂和动态的环境中进行测试。此外,还可以探索如何将这种技术应用于其他领域,如服务机器人或自动驾驶汽车。
