【完整源码+数据集+部署教程】控制台缺陷检测系统源码和数据集:改进yolo11-repvit
背景意义
研究背景与意义
随着电子产品的快速发展,控制台作为一种重要的消费电子设备,其生产和质量控制变得愈发重要。控制台在使用过程中可能会出现多种缺陷,如碰撞、污垢、缝隙和划痕等,这些缺陷不仅影响产品的外观,还可能影响其功能和用户体验。因此,建立一个高效、准确的缺陷检测系统显得尤为重要。传统的人工检测方法不仅耗时耗力,而且容易受到人为因素的影响,导致检测结果的不一致性和准确性不足。为了解决这一问题,基于计算机视觉的自动缺陷检测技术逐渐成为研究的热点。
在众多计算机视觉算法中,YOLO(You Only Look Once)系列模型因其高效的实时检测能力而受到广泛关注。YOLOv11作为该系列的最新版本,具备更强的特征提取能力和更快的处理速度,适合于复杂环境下的缺陷检测任务。本研究旨在基于改进的YOLOv11模型,构建一个针对控制台缺陷的检测系统,以实现对碰撞、污垢、缝隙和划痕等四类缺陷的精准识别。
本项目使用的数据集“Consolesliced2”包含3500张经过精确标注的图像,涵盖了四种缺陷类型。这一数据集为模型的训练和评估提供了丰富的样本,有助于提高模型的泛化能力和检测精度。通过对该数据集的深入分析和应用,研究将探索如何优化YOLOv11模型的结构和参数设置,以提高其在控制台缺陷检测中的表现。
综上所述,本研究不仅具有重要的理论意义,也为实际生产中的质量控制提供了新的思路和方法。通过实现高效的缺陷检测系统,能够有效降低人工成本,提高产品质量,进而提升消费者的满意度和企业的市场竞争力。
图片效果
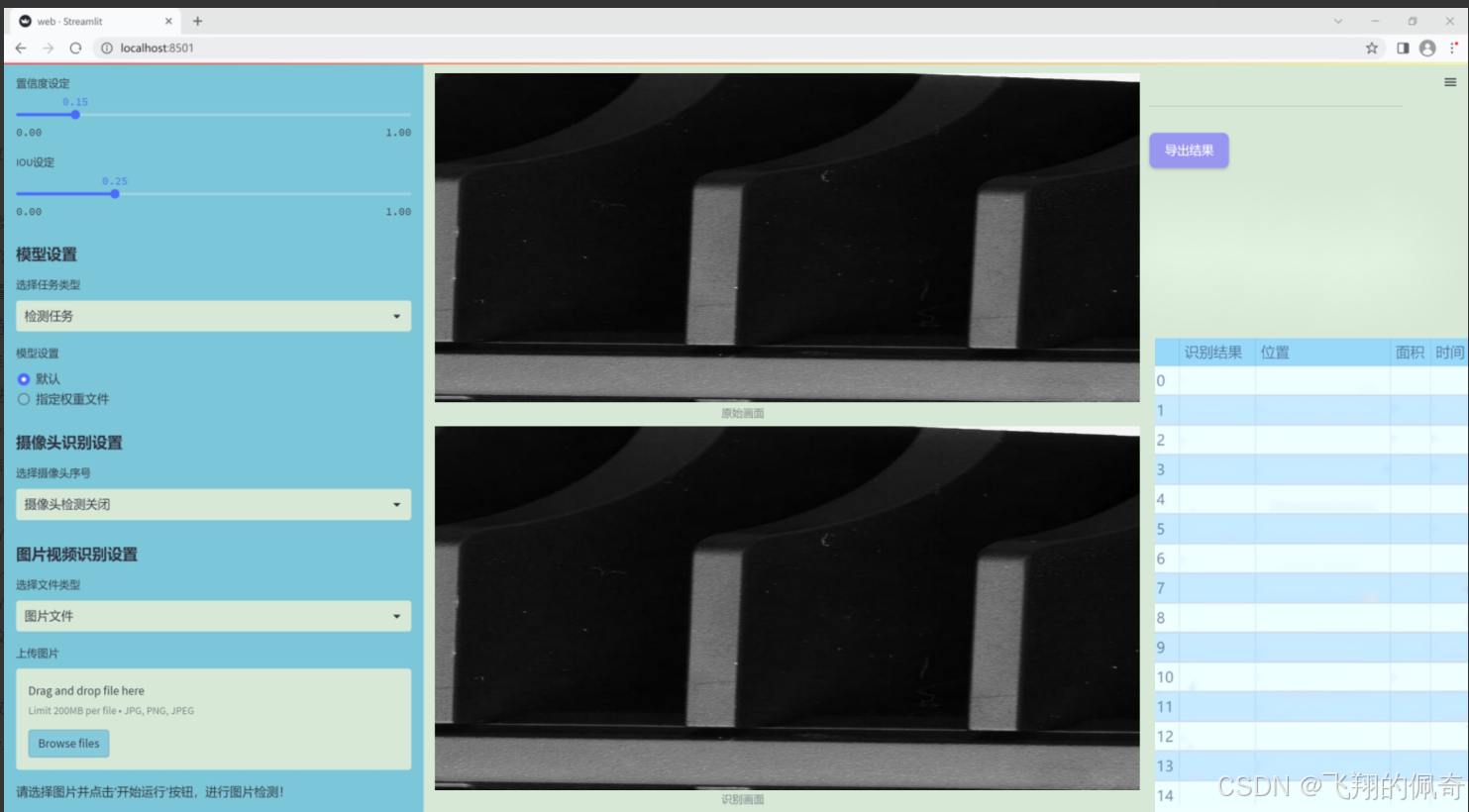
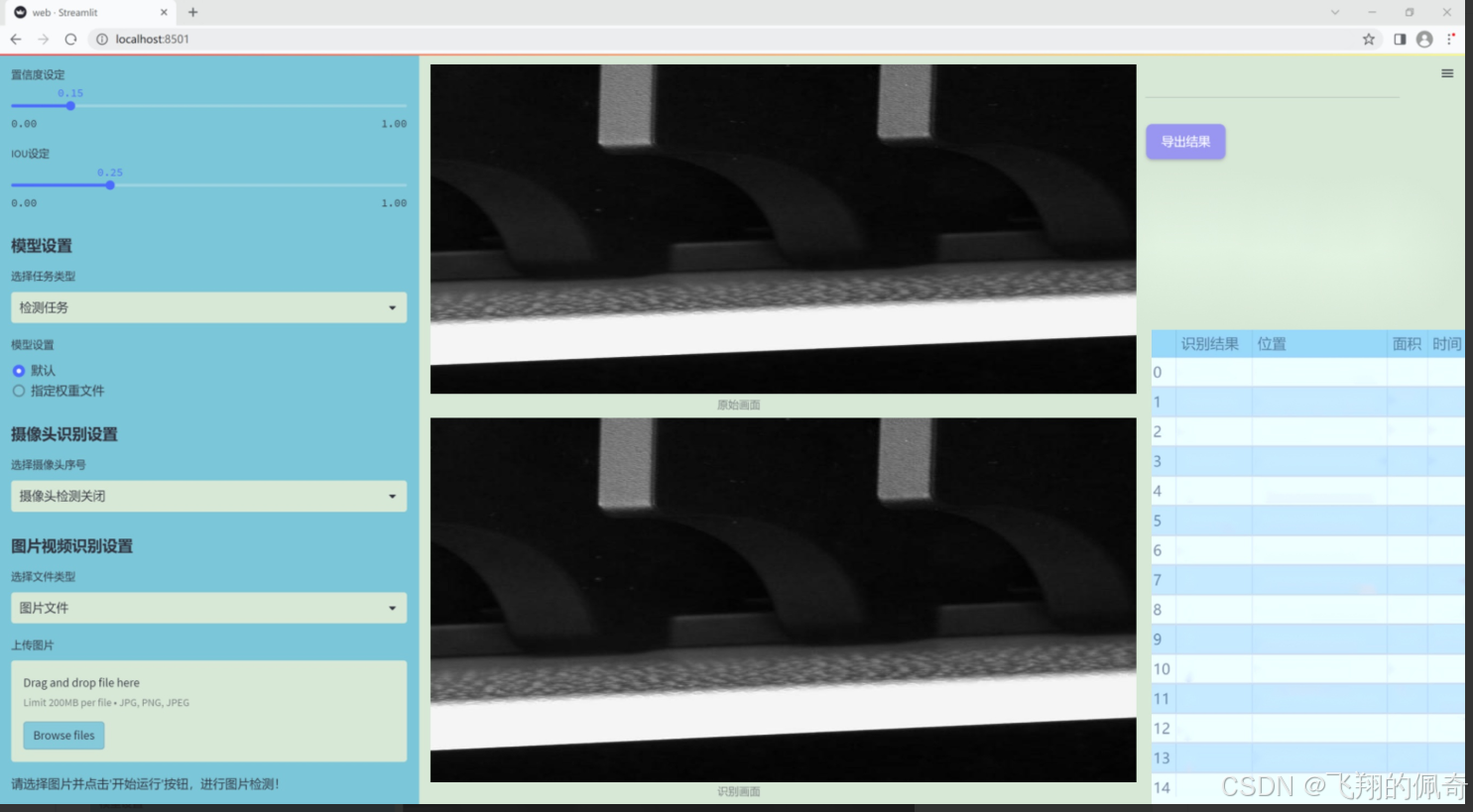
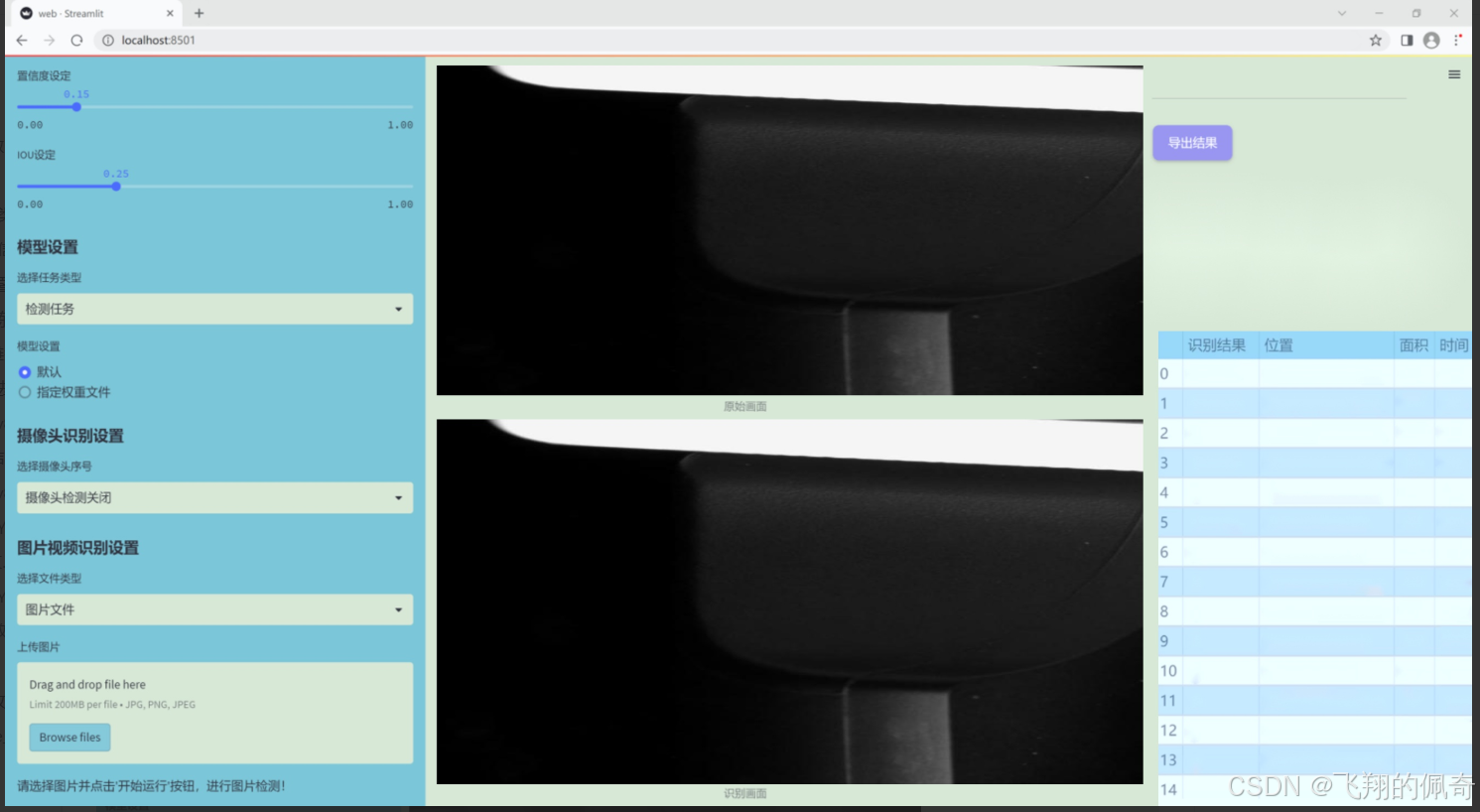
数据集信息
本项目数据集信息介绍
本项目所使用的数据集名为“Consolesliced2”,旨在为改进YOLOv11的控制台缺陷检测系统提供强有力的支持。该数据集专注于控制台表面的各种缺陷,涵盖了四个主要类别,分别为“Collision”(碰撞)、“Dirty”(脏污)、“Gap”(缝隙)和“Scratch”(划痕)。这些类别的选择是基于对控制台在实际使用中可能出现的常见问题的深入分析,确保模型能够有效识别并分类不同类型的缺陷。
在数据集的构建过程中,收集了大量高质量的图像,确保每个类别都有足够的样本量,以便于训练和验证模型的性能。每张图像都经过精心标注,标注信息不仅包括缺陷的类别,还涵盖了缺陷的具体位置和范围,这为后续的模型训练提供了丰富的上下文信息。通过这种方式,数据集能够帮助YOLOv11在特征提取和缺陷识别方面实现更高的准确率。
此外,数据集中的图像来源多样,涵盖了不同光照条件、角度和背景的控制台,旨在提高模型的鲁棒性和泛化能力。通过这种多样化的训练数据,改进后的YOLOv11能够在实际应用中更好地适应各种环境和条件,提升缺陷检测的效率和准确性。
综上所述,“Consolesliced2”数据集不仅为改进YOLOv11提供了坚实的基础,也为后续的缺陷检测研究奠定了重要的理论和实践依据。通过对该数据集的深入挖掘




核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
class KACNConvNDLayer(nn.Module):
def init(self, conv_class, norm_class, input_dim, output_dim, degree, kernel_size,
groups=1, padding=0, stride=1, dilation=1,
ndim: int = 2, dropout=0.0):
super(KACNConvNDLayer, self).init()
# 初始化参数self.inputdim = input_dim # 输入维度self.outdim = output_dim # 输出维度self.degree = degree # 多项式的度数self.kernel_size = kernel_size # 卷积核大小self.padding = padding # 填充self.stride = stride # 步幅self.dilation = dilation # 膨胀self.groups = groups # 分组卷积的组数self.ndim = ndim # 数据的维度(1D, 2D, 3D)self.dropout = None # Dropout层初始化为None# 如果dropout大于0,则根据维度选择相应的Dropout层if dropout > 0:if ndim == 1:self.dropout = nn.Dropout1d(p=dropout)elif ndim == 2:self.dropout = nn.Dropout2d(p=dropout)elif ndim == 3:self.dropout = nn.Dropout3d(p=dropout)# 检查groups参数的有效性if groups <= 0:raise ValueError('groups must be a positive integer')if input_dim % groups != 0:raise ValueError('input_dim must be divisible by groups')if output_dim % groups != 0:raise ValueError('output_dim must be divisible by groups')# 创建分组归一化层self.layer_norm = nn.ModuleList([norm_class(output_dim // groups) for _ in range(groups)])# 创建多项式卷积层self.poly_conv = nn.ModuleList([conv_class((degree + 1) * input_dim // groups,output_dim // groups,kernel_size,stride,padding,dilation,groups=1,bias=False) for _ in range(groups)])# 注册一个缓冲区,用于存储多项式的系数arange_buffer_size = (1, 1, -1,) + tuple(1 for _ in range(ndim))self.register_buffer("arange", torch.arange(0, degree + 1, 1).view(*arange_buffer_size))# 使用Kaiming均匀分布初始化卷积层的权重for conv_layer in self.poly_conv:nn.init.normal_(conv_layer.weight, mean=0.0, std=1 / (input_dim * (degree + 1) * kernel_size ** ndim))def forward_kacn(self, x, group_index):# 前向传播,应用激活函数和线性变换x = torch.tanh(x) # 应用tanh激活函数x = x.acos().unsqueeze(2) # 计算反余弦并增加一个维度x = (x * self.arange).flatten(1, 2) # 乘以多项式系数并展平x = x.cos() # 计算余弦值x = self.poly_conv[group_index](x) # 通过对应的卷积层x = self.layer_norm[group_index](x) # 通过对应的归一化层if self.dropout is not None:x = self.dropout(x) # 如果有dropout,则应用dropoutreturn xdef forward(self, x):# 前向传播,处理输入数据split_x = torch.split(x, self.inputdim // self.groups, dim=1) # 按组分割输入output = []for group_ind, _x in enumerate(split_x):y = self.forward_kacn(_x.clone(), group_ind) # 对每个组进行前向传播output.append(y.clone()) # 将结果添加到输出列表y = torch.cat(output, dim=1) # 将所有组的输出拼接在一起return y
代码说明:
KACNConvNDLayer: 这是一个自定义的卷积层类,支持任意维度的卷积操作。它的构造函数接受卷积类型、归一化类型、输入输出维度、卷积核大小等参数,并进行初始化。
forward_kacn: 这是该类的核心前向传播方法,应用了多项式卷积和归一化,并可以选择性地应用dropout。
forward: 该方法处理输入数据,将其分割成多个组,并对每个组调用forward_kacn进行处理,最后将结果拼接在一起返回。
这个程序文件定义了一个名为 kacn_conv.py 的模块,主要实现了一个自定义的卷积层,称为 KACNConvNDLayer 及其一维、二维和三维的特化版本。该模块使用 PyTorch 框架,包含了卷积操作、归一化、激活函数等功能,适用于多维数据的处理。
首先,KACNConvNDLayer 类是一个通用的卷积层,接受多个参数以配置卷积操作,包括输入和输出维度、卷积核大小、分组数、填充、步幅、扩张率、丢弃率等。构造函数中,首先进行了一些参数的验证,确保分组数为正整数,并且输入和输出维度能够被分组数整除。接着,初始化了归一化层和多项式卷积层。多项式卷积层的数量与分组数相同,每个卷积层的输入通道数是输入维度与分组数的比值乘以多项式的度数加一。
在前向传播过程中,forward 方法将输入张量按组进行拆分,并对每个组调用 forward_kacn 方法进行处理。forward_kacn 方法中,首先对输入进行激活,然后进行线性变换,接着应用多项式卷积和归一化,最后根据需要应用丢弃层。
接下来的三个类 KACNConv3DLayer、KACNConv2DLayer 和 KACNConv1DLayer 是对 KACNConvNDLayer 的特化,分别实现了三维、二维和一维的卷积操作。它们在构造函数中调用了父类的构造函数,并传入相应的卷积和归一化类。
整体来看,这个模块提供了一种灵活的方式来实现多维卷积操作,结合了多项式卷积和归一化的特点,适用于需要复杂特征提取的深度学习任务。
10.4 efficientViT.py
以下是简化后的代码,保留了核心部分,并添加了详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
import itertools
定义卷积层和批归一化的组合
class Conv2d_BN(torch.nn.Sequential):
def init(self, in_channels, out_channels, kernel_size=1, stride=1, padding=0, dilation=1, groups=1, bn_weight_init=1):
super().init()
# 添加卷积层
self.add_module(‘conv’, torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias=False))
# 添加批归一化层
self.add_module(‘bn’, torch.nn.BatchNorm2d(out_channels))
# 初始化批归一化的权重
torch.nn.init.constant_(self.bn.weight, bn_weight_init)
torch.nn.init.constant_(self.bn.bias, 0)
@torch.no_grad()
def switch_to_deploy(self):# 将训练模式下的卷积和批归一化合并为一个卷积层conv, bn = self._modules.values()w = bn.weight / (bn.running_var + bn.eps)**0.5w = conv.weight * w[:, None, None, None]b = bn.bias - bn.running_mean * bn.weight / (bn.running_var + bn.eps)**0.5m = torch.nn.Conv2d(w.size(1) * conv.groups, w.size(0), w.shape[2:], stride=conv.stride, padding=conv.padding, dilation=conv.dilation, groups=conv.groups)m.weight.data.copy_(w)m.bias.data.copy_(b)return m
定义一个简单的前馈神经网络
class FFN(torch.nn.Module):
def init(self, in_dim, hidden_dim):
super().init()
self.pw1 = Conv2d_BN(in_dim, hidden_dim) # 第一层卷积
self.act = torch.nn.ReLU() # 激活函数
self.pw2 = Conv2d_BN(hidden_dim, in_dim, bn_weight_init=0) # 第二层卷积
def forward(self, x):# 前向传播x = self.pw2(self.act(self.pw1(x)))return x
定义EfficientViT的基本模块
class EfficientViTBlock(torch.nn.Module):
def init(self, in_dim, key_dim, num_heads=8):
super().init()
self.dw0 = Conv2d_BN(in_dim, in_dim, kernel_size=3, stride=1, padding=1, groups=in_dim) # 深度卷积
self.ffn0 = FFN(in_dim, in_dim * 2) # 前馈网络
self.mixer = FFN(in_dim, in_dim) # 注意力机制
self.dw1 = Conv2d_BN(in_dim, in_dim, kernel_size=3, stride=1, padding=1, groups=in_dim) # 深度卷积
self.ffn1 = FFN(in_dim, in_dim * 2) # 前馈网络
def forward(self, x):# 前向传播x = self.ffn1(self.dw1(self.mixer(self.ffn0(self.dw0(x)))))return x
定义EfficientViT模型
class EfficientViT(torch.nn.Module):
def init(self, img_size=224, embed_dim=[64, 128, 192], depth=[1, 2, 3]):
super().init()
self.patch_embed = Conv2d_BN(3, embed_dim[0] // 8, kernel_size=3, stride=2, padding=1) # 图像嵌入
self.blocks = nn.ModuleList() # 存储多个EfficientViTBlock
for i in range(len(depth)):
for _ in range(depth[i]):
self.blocks.append(EfficientViTBlock(embed_dim[i], key_dim=16, num_heads=4)) # 添加块
def forward(self, x):x = self.patch_embed(x) # 图像嵌入for block in self.blocks:x = block(x) # 通过每个块return x
测试模型
if name == ‘main’:
model = EfficientViT() # 创建模型实例
inputs = torch.randn((1, 3, 224, 224)) # 创建随机输入
res = model(inputs) # 前向传播
print(res.size()) # 输出结果的尺寸
代码说明:
Conv2d_BN: 这是一个自定义的卷积层,包含卷积操作和批归一化,支持在推理时将两者合并以提高效率。
FFN: 定义了一个简单的前馈神经网络,包含两个卷积层和一个ReLU激活函数。
EfficientViTBlock: 这是EfficientViT的基本构建块,包含深度卷积和前馈网络。
EfficientViT: 整个模型的定义,包含图像嵌入和多个EfficientViTBlock的堆叠。
主函数: 创建模型实例并进行一次前向传播,输出结果的尺寸。
这个程序文件实现了一个高效的视觉变换器(EfficientViT)模型架构,主要用于图像分类等下游任务。文件中包含了多个类和函数,构成了整个模型的结构。
首先,程序导入了必要的库,包括PyTorch及其相关模块,以及一些辅助函数和类。然后定义了一个名为Conv2d_BN的类,它继承自torch.nn.Sequential,用于创建一个包含卷积层和批归一化层的模块。这个类还提供了一个switch_to_deploy方法,用于在推理阶段将批归一化层融合到卷积层中,以提高推理效率。
接下来,replace_batchnorm函数用于遍历网络中的所有子模块,将批归一化层替换为恒等映射,从而在推理时提高效率。
PatchMerging类用于将输入特征图进行合并,生成更高层次的特征表示。它包含多个卷积层和激活函数,并使用了Squeeze-and-Excitation模块来增强特征。
Residual类实现了残差连接的功能,允许在训练过程中引入随机丢弃,以增强模型的鲁棒性。
FFN类定义了一个前馈神经网络,包含两个线性层和一个ReLU激活函数。
CascadedGroupAttention类实现了级联组注意力机制,通过多个卷积层对输入进行处理,计算注意力权重,并将其应用于输入特征图。
LocalWindowAttention类实现了局部窗口注意力机制,允许模型在局部范围内进行注意力计算,从而提高计算效率。
EfficientViTBlock类是EfficientViT的基本构建块,结合了卷积、前馈网络和注意力机制,形成一个完整的模块。
EfficientViT类是整个模型的核心,负责构建网络的各个阶段。它包含了多个EfficientViTBlock,并通过patch_embed模块将输入图像分割成补丁进行处理。模型的各个阶段可以根据配置参数进行调整,包括嵌入维度、深度、注意力头数等。
最后,文件定义了一些不同配置的EfficientViT模型(如EfficientViT_m0到EfficientViT_m5),并提供了加载预训练权重和替换批归一化层的功能。update_weight函数用于更新模型权重,并打印加载的权重数量。
在__main__部分,代码实例化了一个EfficientViT_M0模型,并对随机生成的输入进行前向传播,输出每个阶段的特征图大小。
总体而言,这个程序实现了一个灵活且高效的视觉变换器模型,适用于各种计算机视觉任务。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式