Vision Transformer模型解读
由于工作需要,博主从原来的NLP转向了MLLM,因此开始从0学习一些计算机视觉和多模态的内容。通过将自己的理解转化为博客,更有利于巩固加深并帮助更多从0基础开始学习的同行。
文章目录
- 1.模型提出背景
- 2.模型架构
- 2.1 embedding层
- 2.2 编码层
- 2.3 MLP层
- 3.模型执行过程
- 4.总结
1.模型提出背景
在2017年谷歌提出了Transformer架构用于自然语言处理领域之后,就不断有人提出将Transformer用于计算机视觉领域。将图片的每个像素点进行排列后,经过嵌入层后输入到Transformer中,其原理相当于句子中的每个token。但是,这个方法面对的首要问题是计算量过大,在self-attention中计算复杂度是O(n*n),然而面对一张分辨率较低的图片224×224,它的像素点为50176,这个计算量已经到达十亿的数量级,面对更大分辨率图像的计算量可想而知。
于是,Vision Transformer被提出了:该模型不再对每个像素点单独进行处理,而是将图像分为一个一个的块(patch),将这些图像块进行嵌入后作为输入,这个操作用卷积神经网络就可以轻松的实现。
2.模型架构
Vision Transformer包括以下三层:embedding层、Transformer编码层、MLP层。
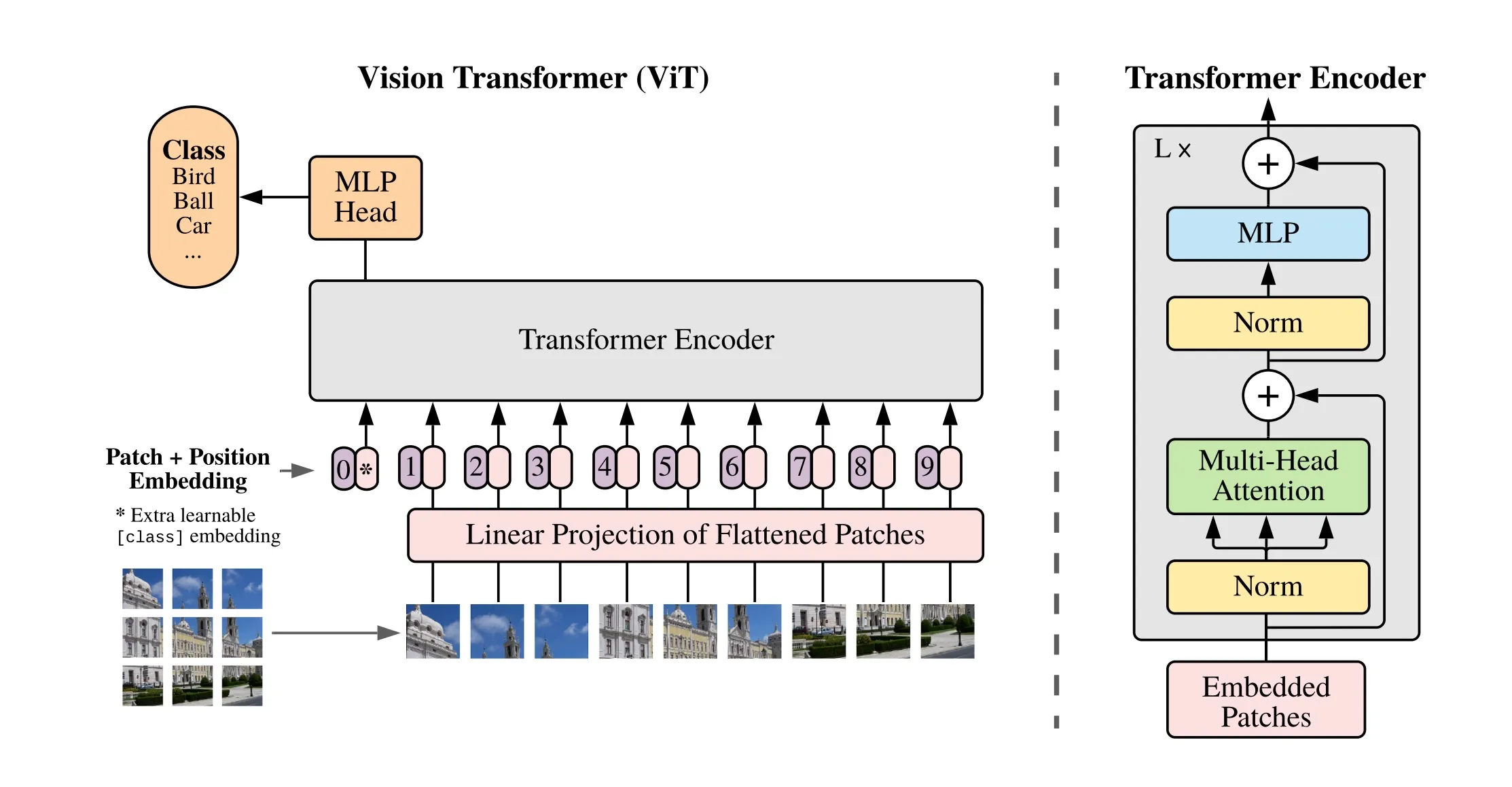
2.1 embedding层
在传统Transformer的embedding后,输入的是三维矩阵[batch_size, seq_length, embedding_dim]。而对于图像而言,其数据格式[height, width, channel],首先需要通过平坦层将其转化为序列数据。以ViT-B/16为例,将输入图片(224x224)按照16x16大小的patch进行划分,划分后得到(224/16)*(224/16)=196个patch;再通过线性映射将每个patch映射到一维向量中,每个patch数据shape为[16, 16, 3]通过映射得到一个长度为768的向量,得到一个[14, 14, 768]的三维矩阵;最后再将高度和宽度两个维度进行展平,得到一个[196, 768]的二维矩阵;至此终于对齐了文本输入的格式。
在代码实现中,可以采取一个卷积层来实现,输入通道数为3(若为灰度图像则为1),输出通道数为768,卷积核的大小为16×16,步长也为16。
Conv2d(in_c=3, embed_dim=768, kernel_size=16, stride=16)
为了做最后的分类,模型在所有patch最前面加一个可以通过学习得到的 [class] token作为这些patch的全局输出,相当于BERT中的分类字符CLS (这里的加是concat拼接),这个[class] token也会有与其他所有token交互的信息,最终得到的输入矩阵为{[1, 768] concat [196, 768]} = [197, 768]。
最后方便对位置信息进行建模,与传统Transformer一样,Vision Transformer同样需要对每个patch的嵌入向量中加入相应的位置信息,通过引入一个可学习的位置矩阵参数,在每个token中加入这样的位置信息。注:这里的加是sum,而不是concat。
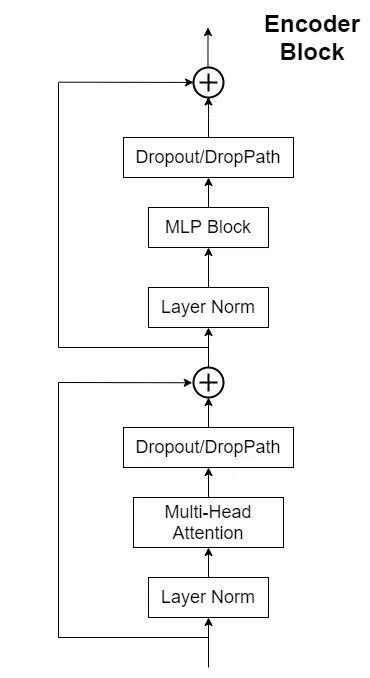
2.2 编码层
在上一层embedding层中,图片的输入格式[batch_size, patches, embed_dim]已经和文本输入格式[batch_size, seq_length, embed_dim]对齐,因此在编码层中,算法执行过程与传统Transformer一致,关于传统Transformer中Encoder结构,在这里就不再赘述。
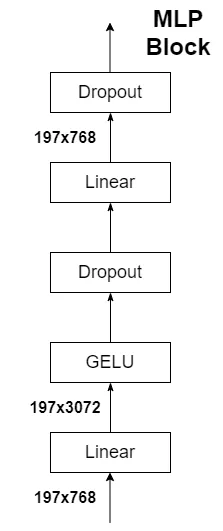
2.3 MLP层
经过编码层后输出维度和输入维度一致,仍然为[197, 768],这里我们只是需要分类的信息,所以我们只需要提取出[class]token生成的对应结果就行,即[197, 768]中抽取出[class] token对应的[1, 768]。接着我们通过MLP层得到我们最终的分类结果,下图展示的是Vision Transformer中的结构,实际训练任务中可以根据分类类别数来自行调整。
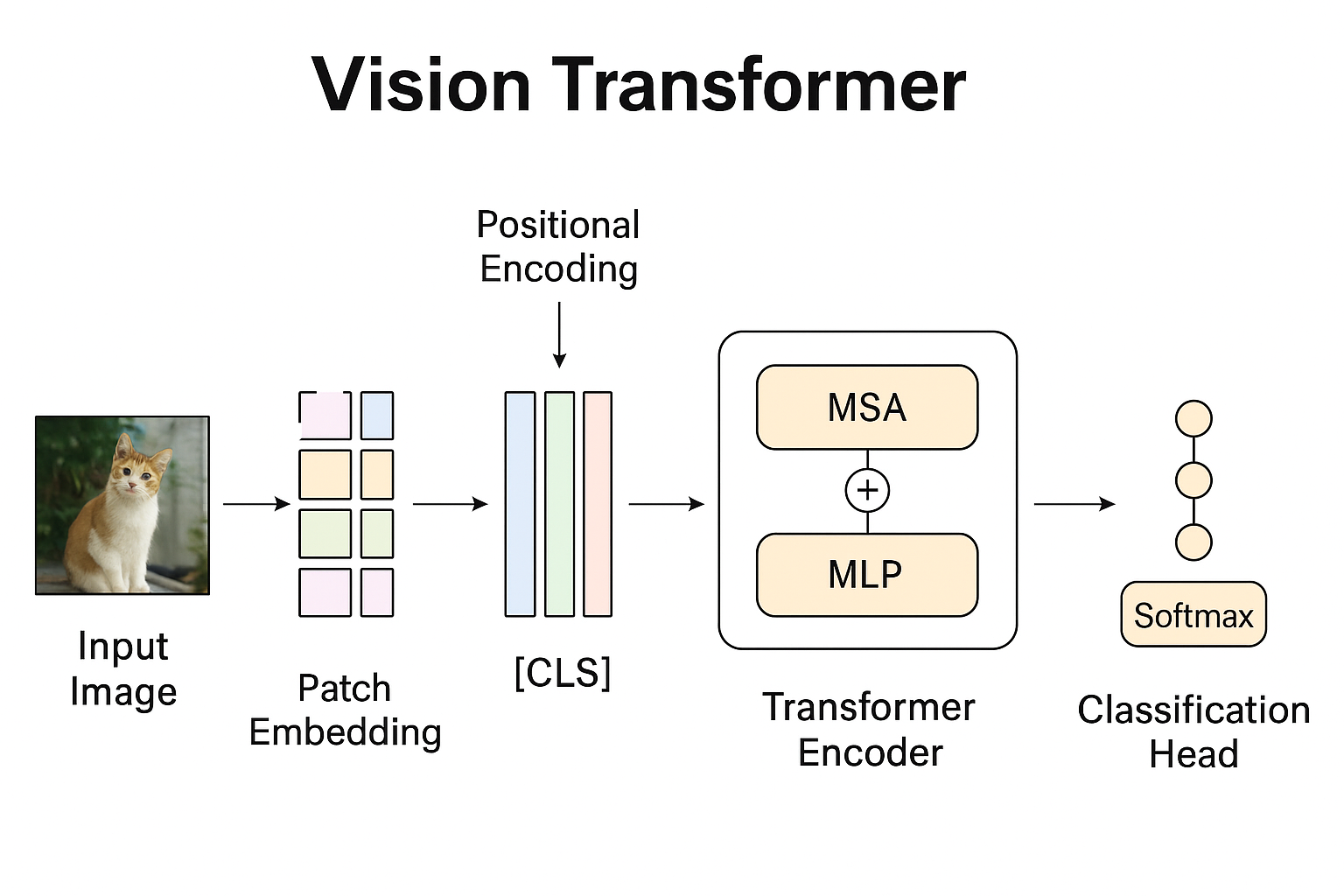
3.模型执行过程
其执行过程总共可以分为4步:
1.图片拆分成patch,获取每个patch的embedding。
2.加入位置信息,并加入全局向量[Class]。
3.用编码器进行编码。
4.通过多层感知机进行映射分类。
4.总结
Vision Transformer就是把图像当作词序列来处理,用Transformer取代 CNN,其在大规模数据上能超越CNN,但在小数据或有限算力场景下不如CNN高效。