comfyUI背后的一些技术——CLIP
CLIP 全称 Contrastive Language-Image Pre-Training(对比性语言-图像预训练模型),是 OpenAI 在 2021 年初开源的一个用文本作为监督信号来做预训练的模型
整体认识
CLIP是Text Encoder算法的一种,是把文字转化为编码的一种算法。他的主要功能是把自然语义prompt 转变为77x768维度的词特征向量Embedding——77个等长的token词向量,其中每个词向量包含768个维度。
在comfUI工作流中,往往会有两个文本编码器CLIP,分别用来编码正向提示词和反向提示词,也就是画面中希望出现的内容和不希望出现的内容。
看论文
主页链接https://github.com/OpenAI/CLIP?tab=readme-ov-file

| Alec Radford | Ilya Sutskever | Aditya Ramesh | Amanda Askell |
 |  |  |  |
| 于 2016 年加入 OpenAI,并于 2017 年发表了划时代的论文《Attention Is All You Need》以第一作者身份发表过 GPT、GPT-2、CLIP 等多项重要研究的相关论文,论文被引用超过 18 万次,并且参与了语音模型 Whisper 以及 Dall-E 的开发(同样是一作),2024离职 | 2012年,在多伦多大学获得计算机博士学位,同年,苏茨克弗和他的老师杰弗里·辛顿以及辛顿的另一位研究生( Alex Krizhevsky)建立了一个名为 AlexNet 的神经网络。 2015年,加入OpenAI,成为该公司的联合创始人兼首席科学家 2024年6月,成立新公司SSI(safe superintelligence,安全超级智能) | 毕业于纽约大学,曾在 杨立昆实验室, Sora和DALL-E负责人 | Anthropic研究方向是对齐微调 |
在以往的CNN监督训练中,图像对都是高质量的和低质量的构成,或者是图像-label的方式,但是在CLIP (Contrastive Language-Image Pre-Training)中,训练对是(image, text)。其实在CLIP之前就有很多人致力于使用从自然语言中学习supervision,不过方法各有差异,并且取的名称也是叫什么的都有:unsupervised, self-supervised, weakly supervised。并且之前的条件有限,而CLIP这时已经可以借助更先进的从复杂文本中提取信息的能力。
那么为什么要执着于自然语言呢?一方面是自然语言获取容易,不需要机器学习时代那种复杂的,标准化的标注,更重要的是迁移学习的能力。以图像分类和检测为例,ImageNet提供了1.28M的图片,对应1000个类别,可用于目标检测和分割任务的COCO数据集共有33万张图片80个目标类别,但是训练之后很难zero-shot泛化到新的类别中。
zero shot
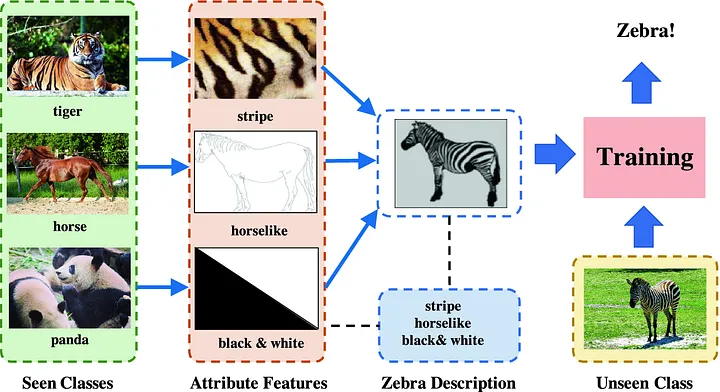
ZERO-SHOT LEARNING解决的就是训练阶段没有见过的类型。虽然没有见过斑马这一类型,但是从训练样本中学习到了颜色特征,形体特征,还有花纹特征,而这些特征组合起来,就是斑马!
更详细的解释可以看论文Unsupervised Domain Adaptation for Zero-Shot Learning。
这是整体流程图:
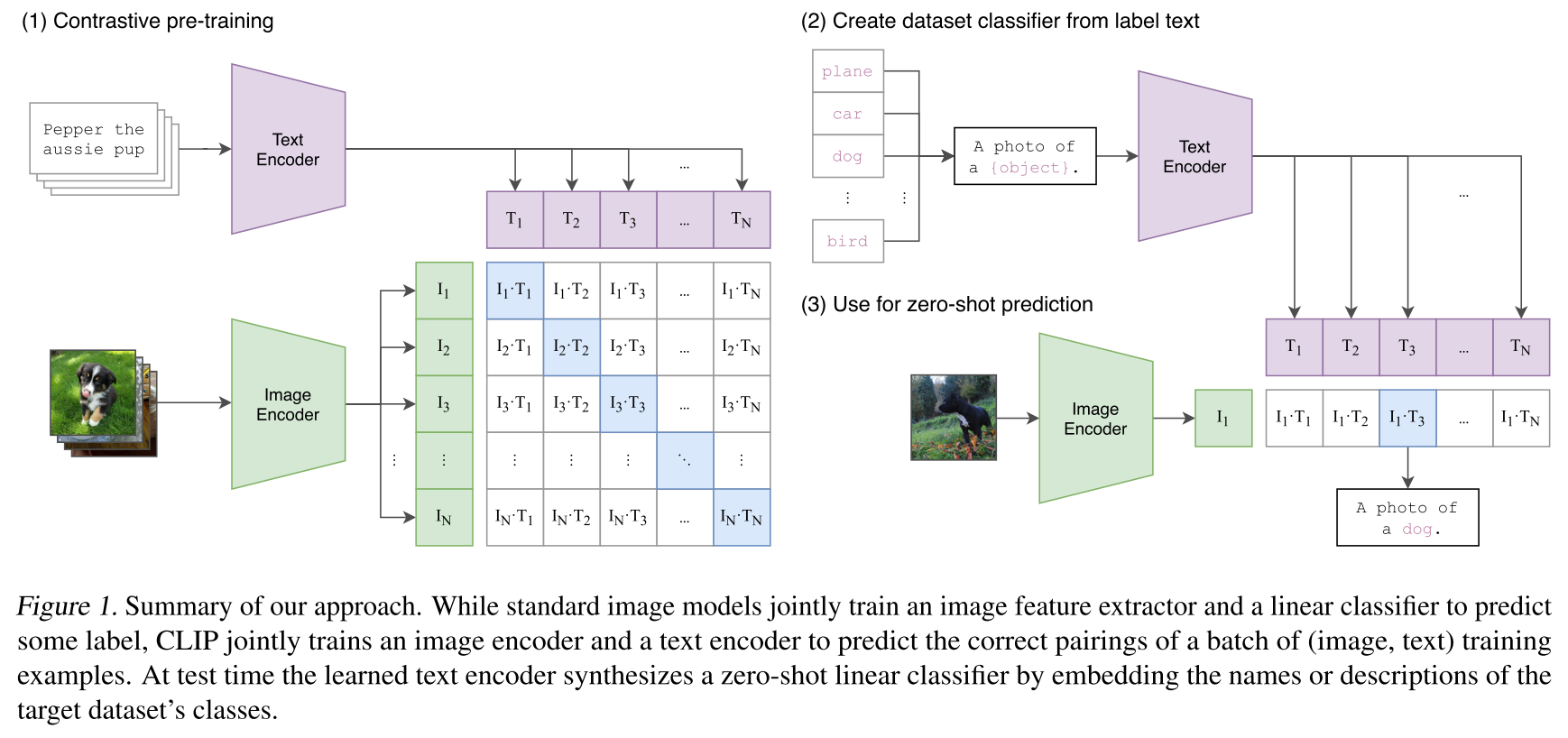
左右两幅图表示的分别是训练和推理阶段。训练的时候把text和image分别提取得到多维向量,然后两两计算相似度,训练的过程就是匹配的文本和图像贴近的过程。推理阶段也是类似的,不过是提前把所有可能的标签文本构建好dataset,对单个图像encoder之后从dataset中寻找最相似的。
接下来针对上图的三部分分别研究一下:
Contrastive pre-training
说是要学习自然语言,但真的一字一句去严格预测是效率很低的,因为同一个意思有太多种不同的表达,所以一个思想就是去学习和预测word的特征,这就是bag-of-words。但是这样效率还是不够高,所以使用了对比学习的思想,这样可以进一步提高4倍的效率。
具体而言,对于N个image,N个text,分别训练图像和文本的encoder,这就就能得到NxN种对应关系。训练目标是最大化具有真正对应关系的pair的余弦相似度cosine similarity,最小化其余NxN-N组不对应的pair的余弦相似度。
# image_encoder 图像编码器:ResNet或者ViT
# text_encoder 文本编码器:CBOW或者Text Transformer
# I[n,h,w,c] 图像输入大小: 比如 [16, 224, 224, 3]
# T[n,l] 文本输入大小:n表示batch size,l表示序列长度
# W_i[d_i, d_e] 图像的投射层,学习如何从单模态到多模态
# W_t[d_t, d_e] 文本的投射层,学习如何从单模态到多模态
# t 可学习的温度系数# 分别提取每个模态的特征
I_f = image_encoder(I) # 输出大小 [n, d_i]
T_f = text_encoder(T) # 输出大小 [n, d_t]# 合并多模态特征
I_e = l2_normalize(np.dot(I_f, W_i), axis=1) # 输出大小 [n, d_e]
T_e = l2_normalize(np.dot(T_f, W_t), axis=1) # 输出大小 [n, d_e]# 计算cos相似度,I_e 与 T_e 转置矩阵的点积,np.exp(t) 表示可学习的温度系数的指数。
# 这里实际是在对点积的结果进行加权,通过指数函数引入温度系数的影响,以调整余弦相似度的分数。
# 这样的加权余弦相似度通常用于度量多模态特征之间的相似性。
logits = np.dot(I_e, T_e.T) * np.exp(t) # 输出大小 [n, n]# 计算损失函数
labels = np.arange(n) # ground truth,因为交叉熵计算时使用的是索引,
loss_i = cross_entropy_loss(logits, labels, axis=0) # 针对图像的交叉熵损失
loss_t = cross_entropy_loss(logits, labels, axis=1) # 针对文本的交叉熵损失
loss = (loss_i + loss_t) / 2 # 综合图像和文本的损失
和ConVIRT相比,这里进行了简化。因为数据量足够大,所以不担心过拟合的问题;对encoder没有进行权重的预加载;没有使用非线性映射non-linear projection;没有使用text transformation function对文本进行数据增广,对图像的增广image transformation function也只进行了resize和crop。
图像的encoder是ResNet(如ResNet-50)或Vision Transformer(ViT),文本的encoder是Transformer类型的bert。
Create dataset classifier from label text
CLIP 经过预训练后只能得到视觉上和文本上的特征,并没有在任何分类的任务上去做继续的训练或微调,所以它没有分类头,那么 CLIP 是如何做推理的呢?
CLIP(Contrastive Language–Image Pretraining)的推理过程基于其预训练阶段学到的多模态嵌入对齐能力,通过将分类任务转化为图像-文本相似度匹配问题,无需传统意义上的分类头(Classifier Head)。
因为训练的时候是句子的形式,所以需要将类别名嵌入自然语言描述的模板中。那为什么训练的时候就不能是单一个单词呢?因为单词的含义往往需要在句子中才能知道它确切的含义,比如crane可能是鹤,也可以是起重机,remote可以是遥远的,也可以是遥控器。
这里展示的比较简单,是a photo of xxx这样的固定句式,实际中openAI有专门对此的优化,叫做prompt engineering和prompt ensemble。比如可以增加一些描述,这是一种动物/食物,描述材质,大小,这样就能缩小解空间,提高zero shot的效果。
输入文本的话,会利用文本编码器得到一系列权重。本质上这一步是把类别名称映射到了高维空间。
Use for zero-shot prediction
前面已经对可能存在的类别都通过encoder得到对应的编码。同样,把待分类的图片也送入encoder,图像编码和文本编码进行相似度计算,得到预测的分类结果。
所以说,CLIP之所以可以做到zero-shot,就是它的预训练过程不是直接服务于任务的,而是真正的建立起了图像和文本的关联,所以就像是它真正理解了图像内容一样,而不是简单地死记硬背。
夸张的细节
400 million个(image,text) pairs,minibatch size 达到了 32,768,使用RN50x64,在 592张 V100 GPUs训练了18天,如果使用largest Vision Transformer,256块 V100 GPUs 需要训练12天。
reference:
1.https://zhuanlan.zhihu.com/p/639379490
2.Stable Diffusion概要讲解_emaonly 模型-CSDN博客
3.音视频开发之旅(92)-多模态Clip论文解读与源码分析-腾讯云开发者社区-腾讯云
4.ICML 2021 | CLIP论文解读-CSDN博客