基于深度学习的餐盘清洁状态分类
1.任务描述
要求完成一个图像分类任务,问题输入为图像,目标输出为C:干净的,D:脏的。

C:干净的

D:脏的
2.评价标准
本任务以分类准确率作为排序依据,测试集中所有样本中预测正确的数量除以测试集总数即为准确率。
3.数据集
3.1 数据集来源与分类
本研究所使用的数据集来自某网站,主要聚焦 于餐盘在使用后的清洁状态判别。所有图像均为实 拍图像,并按照餐盘清洁情况分为两类:cleaned(干 净)类指的是表面无明显残渣、油渍或液体痕迹的 空餐盘;dirty(脏的)类则包含具有明显食物残留、 汤汁油渍或其它污染物的图像样本。该标签设置贴 合现实清洁标准,具备良好的实际适用性。
数据集整体结构组织清晰,采用标准的文件夹 层级划分。训练集目录(train/)下设有两个子文件 夹,分别存放“cleaned”和“dirty”类别图像,而 测试集(test/)则单独存放未标注的图像,用于最 终模型的预测评估与部署效果测试。具体的目录结构如下所示:
plates/
├── train/
│ ├── cleaned/ (干净餐盘图像)
│ └── dirty/ (脏餐盘图像)
└── test/(仅图像,无标签,用于最终预测)
在样本数量方面,训练集共包含 40 张图像,其中“cleaned”和“dirty”两个类别各占 20 张, 样本数量基本平衡,有利于模型学习到均衡的特征 表达。验证集则通过从训练集中按照 8:2 的比例随 机划分而得,主要用于模型的超参数调优、过拟合监控与早停机制(Early Stopping)判断。测试集共 计 744 张图像,不包含标签信息,专用于评估模型部署后的真实推理表现,模拟实际应用中的“未标 注输入”场景。
3.2 数据预处理流程
为了保证模型在训练阶段的稳定性和在推理 阶段的效率,本文统一将所有输入图像缩放至 224 ×224 像素,以匹配主流预训练骨干网络(如 ResNet 和 EfficientNet)所需的标准输入尺寸。在此基础上,图像预处理过程主要包括三个基本步 骤:首先通过 transforms.Resize((224, 224)) 对图像 进行尺寸缩放,使其保持结构完整的同时适配网络 输入;随后使用 transforms.ToTensor() 将图像从 PIL 或 NumPy 格式转换为 [C, H, W] 格式的张量,并将像素值线性归一化到 [0, 1] 区间;最后应 用 transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) 对图像三个通道分别执行标准化处理,以对齐 ImageNet 预训练模型所采 用的数据分布,从而最大限度地继承预训练参数的 有效性。
在训练集中,为增强模型对实际场景变化的鲁棒性,本文引入了多种数据增强策略,以模拟不同光照条件、拍摄角度、餐盘摆放方式等变化情形。 具体而言,采用概率为 0.5 的随机水平翻转增强模型对左右对称结构的识别能力,同时引入概率为 0.3 的随机垂直翻转以考虑摄像头在顶部或侧面装 时可能出现的角度差异。此外,通过在 ±15° 范 围内执行的随机旋转操作,模拟现实中因餐盘放置 或摄像头安装角度引起的图像倾斜问题。为了适应不同的照明环境,进一步加入了色彩抖动处理 (brightness、contrast、saturation、hue 分别设置为 0.3、0.3、0.3 和 0.1),以模拟光照和白平衡条件 的差异,提高模型在多样照明条件下的稳定性。
为了增强模型对空间扰动的感知能力,本文还引入了仿射变换和透视变换。其中,随机仿射操作 通过设定 10% 的平移范围与 90%–110% 的缩 放系数,模拟摄像头与餐盘之间距离变化和位置偏 移 的 实 际 情 境 ; 而 随机透视变换(distortion_scale=0.2,p=0.3)则用于增强模型对 由于斜视拍摄导致的几何畸变的适应能力。在图像 质量方面,为模拟图像在实际采集中可能受到的模糊影响,进一步引入了高斯模糊处理,采用 3×3 核并设置 σ 范围为 [0.1, 2.0],以提升模型对轻度 模糊图像的鲁棒性。
与训练集不同,验证集和测试集在预处理流程 中仅保留了 Resize、ToTensor 和 Normalize 三个操作,确保输入数据保持“干净”状态,用于客观评估模型的泛化能力与真实性能表现,避免因增强策略带来的评估偏差。
4.实验
4.1实验环境
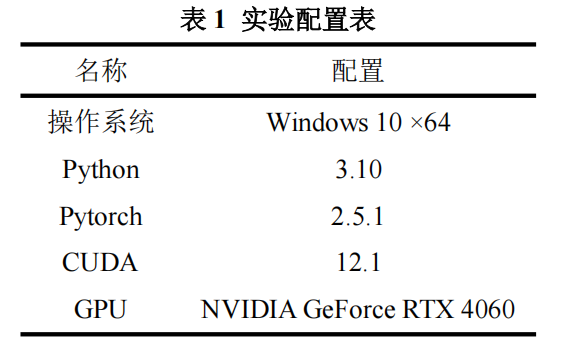
4.2超参数设置
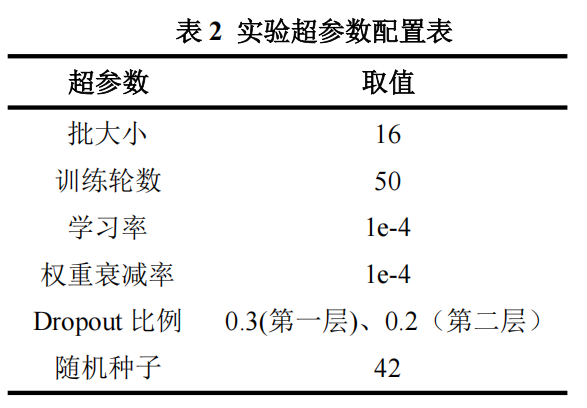
4.3超参数设置
4.3.1 训练过程结果图
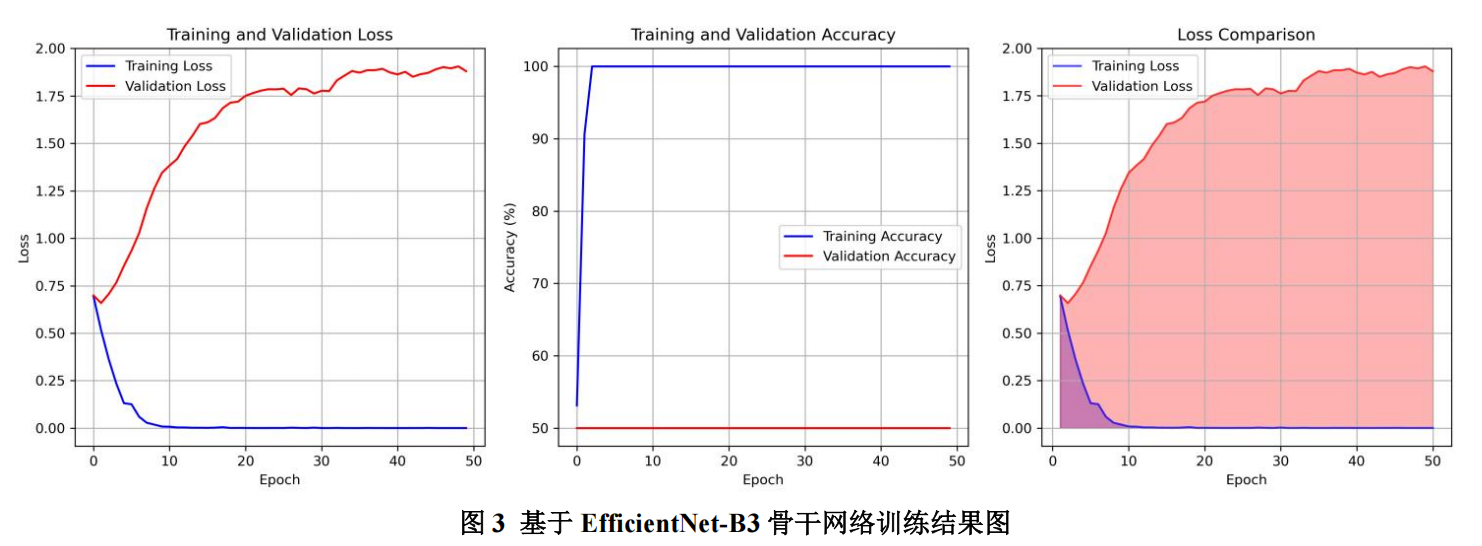
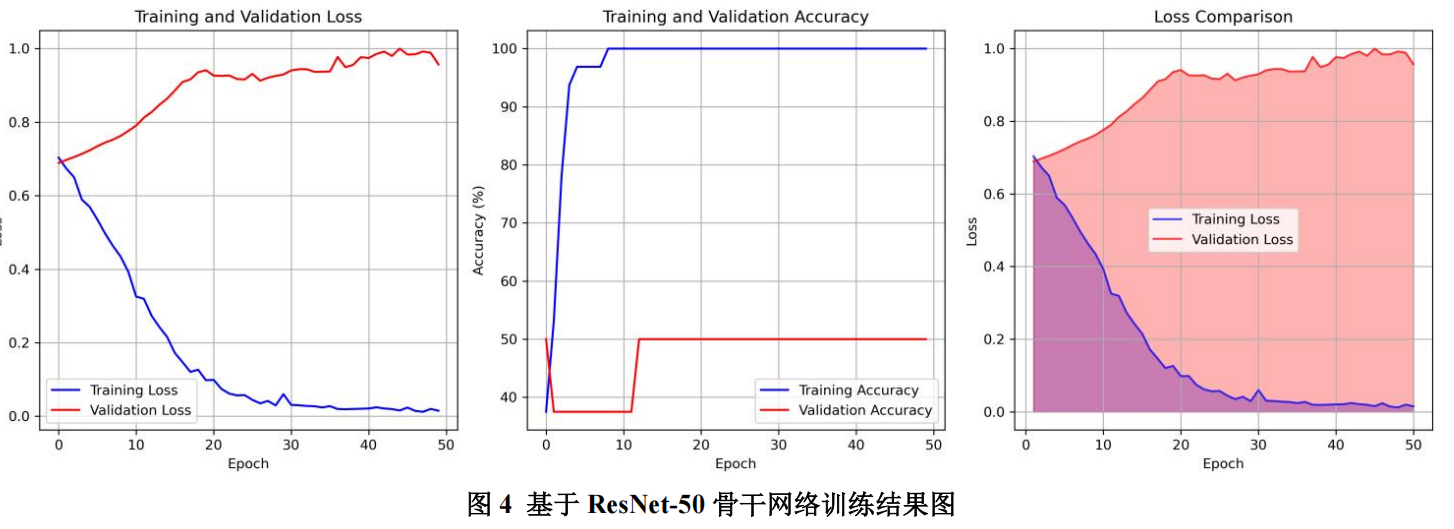
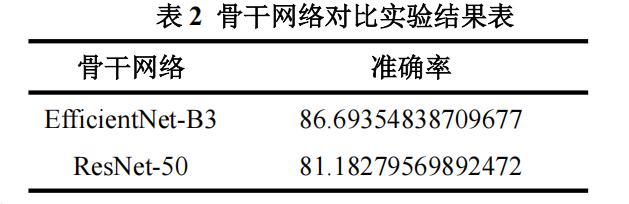
4.3.2 骨干网络对比实验结果
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import torchvision.transforms as transforms
import torchvision.models as models
from PIL import Image
import os
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import accuracy_score, confusion_matrix
import seaborn as sns
import requests
from tqdm import tqdm
import random# 设置随机种子
def set_seed(seed=42):random.seed(seed)np.random.seed(seed)torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed)torch.backends.cudnn.deterministic = Truetorch.backends.cudnn.benchmark = Falseset_seed(42)class PlateDataset(Dataset):def __init__(self, root_dir, transform=None, is_train=True):self.root_dir = root_dirself.transform = transformself.is_train = is_trainself.images = []self.labels = []if is_train:# 训练集:从cleaned和dirty文件夹加载cleaned_dir = os.path.join(root_dir, 'train', 'cleaned')dirty_dir = os.path.join(root_dir, 'train', 'dirty')# 加载干净的图片 (标签为0)if os.path.exists(cleaned_dir):for img_name in os.listdir(cleaned_dir):if img_name.lower().endswith(('.png', '.jpg', '.jpeg')):self.images.append(os.path.join(cleaned_dir, img_name))self.labels.append(0) # 干净的# 加载脏的图片 (标签为1)if os.path.exists(dirty_dir):for img_name in os.listdir(dirty_dir):if img_name.lower().endswith(('.png', '.jpg', '.jpeg')):self.images.append(os.path.join(dirty_dir, img_name))self.labels.append(1) # 脏的else:# 测试集:从test文件夹加载test_dir = os.path.join(root_dir, 'test')if os.path.exists(test_dir):for img_name in os.listdir(test_dir):if img_name.lower().endswith(('.png', '.jpg', '.jpeg')):self.images.append(os.path.join(test_dir, img_name))self.labels.append(-1) # 测试集没有标签def __len__(self):return len(self.images)def __getitem__(self, idx):img_path = self.images[idx]image = Image.open(img_path).convert('RGB')if self.transform:image = self.transform(image)if self.is_train:return image, self.labels[idx]else:# 测试集返回图片和文件名img_name = os.path.basename(img_path)return image, img_name# 数据增强和预处理
def get_transforms():# 训练时的数据增强train_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.RandomHorizontalFlip(p=0.5),transforms.RandomVerticalFlip(p=0.3),transforms.RandomRotation(degrees=15),transforms.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.3, hue=0.1),transforms.RandomAffine(degrees=0, translate=(0.1, 0.1), scale=(0.9, 1.1)),transforms.RandomPerspective(distortion_scale=0.2, p=0.3),transforms.GaussianBlur(kernel_size=3, sigma=(0.1, 2.0)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])# 验证/测试时的预处理val_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])return train_transform, val_transform# 构建先进的深度学习模型
class PlateClassifier(nn.Module):def __init__(self, num_classes=2, model_name='efficientnet_b3'):super(PlateClassifier, self).__init__()if model_name == 'efficientnet_b3':# 使用EfficientNet-B3作为backboneself.backbone = models.efficientnet_b3(pretrained=True)num_features = self.backbone.classifier[1].in_features# 替换分类头self.backbone.classifier = nn.Sequential(nn.Dropout(0.3),nn.Linear(num_features, 512),nn.ReLU(),nn.Dropout(0.2),nn.Linear(512, num_classes))elif model_name == 'resnet50':# 使用ResNet50作为backboneself.backbone = models.resnet50(pretrained=True)num_features = self.backbone.fc.in_features# 替换分类头self.backbone.fc = nn.Sequential(nn.Dropout(0.3),nn.Linear(num_features, 512),nn.ReLU(),nn.Dropout(0.2),nn.Linear(512, num_classes))def forward(self, x):return self.backbone(x)# 训练函数
def train_model(model, train_loader, val_loader, num_epochs=50, device='cuda'):model = model.to(device)criterion = nn.CrossEntropyLoss()optimizer = optim.AdamW(model.parameters(), lr=1e-4, weight_decay=1e-4)scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=num_epochs)train_losses = []train_accs = []val_losses = []val_accs = []best_val_acc = 0.0best_model_state = Nonefor epoch in range(num_epochs):# 训练阶段model.train()train_loss = 0.0train_correct = 0train_total = 0train_pbar = tqdm(train_loader, desc=f'Epoch {epoch + 1}/{num_epochs} [Train]')for images, labels in train_pbar:images, labels = images.to(device), labels.to(device)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()train_loss += loss.item()_, predicted = torch.max(outputs.data, 1)train_total += labels.size(0)train_correct += (predicted == labels).sum().item()train_pbar.set_postfix({'Loss': f'{loss.item():.4f}','Acc': f'{100 * train_correct / train_total:.2f}%'})# 验证阶段model.eval()val_loss = 0.0val_correct = 0val_total = 0with torch.no_grad():for images, labels in val_loader:images, labels = images.to(device), labels.to(device)outputs = model(images)loss = criterion(outputs, labels)val_loss += loss.item()_, predicted = torch.max(outputs.data, 1)val_total += labels.size(0)val_correct += (predicted == labels).sum().item()# 计算平均损失和准确率train_loss_avg = train_loss / len(train_loader)train_acc = 100 * train_correct / train_totalval_loss_avg = val_loss / len(val_loader)val_acc = 100 * val_correct / val_totaltrain_losses.append(train_loss_avg)train_accs.append(train_acc)val_losses.append(val_loss_avg)val_accs.append(val_acc)# 保存最佳模型if val_acc > best_val_acc:best_val_acc = val_accbest_model_state = model.state_dict().copy()scheduler.step()print(f'Epoch {epoch + 1}/{num_epochs}:')print(f'Train Loss: {train_loss_avg:.4f}, Train Acc: {train_acc:.2f}%')print(f'Val Loss: {val_loss_avg:.4f}, Val Acc: {val_acc:.2f}%')print(f'Best Val Acc: {best_val_acc:.2f}%')print('-' * 50)# 加载最佳模型if best_model_state is not None:model.load_state_dict(best_model_state)return model, train_losses, train_accs, val_losses, val_accs# 绘制训练曲线
def plot_training_curves(train_losses, train_accs, val_losses, val_accs):plt.figure(figsize=(15, 5))# 绘制损失曲线plt.subplot(1, 3, 1)plt.plot(train_losses, label='Training Loss', color='blue')plt.plot(val_losses, label='Validation Loss', color='red')plt.title('Training and Validation Loss')plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()plt.grid(True)# 绘制准确率曲线plt.subplot(1, 3, 2)plt.plot(train_accs, label='Training Accuracy', color='blue')plt.plot(val_accs, label='Validation Accuracy', color='red')plt.title('Training and Validation Accuracy')plt.xlabel('Epoch')plt.ylabel('Accuracy (%)')plt.legend()plt.grid(True)# 绘制学习率曲线(如果需要)plt.subplot(1, 3, 3)epochs = range(1, len(train_losses) + 1)plt.plot(epochs, train_losses, 'b-', alpha=0.7, label='Training Loss')plt.plot(epochs, val_losses, 'r-', alpha=0.7, label='Validation Loss')plt.fill_between(epochs, train_losses, alpha=0.3, color='blue')plt.fill_between(epochs, val_losses, alpha=0.3, color='red')plt.title('Loss Comparison')plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()plt.grid(True)plt.tight_layout()plt.savefig('training_curves.png', dpi=300, bbox_inches='tight')plt.show()# 测试和预测函数
def predict_test_set(model, test_loader, device='cuda'):model.eval()predictions = {}with torch.no_grad():for images, img_names in tqdm(test_loader, desc='Predicting'):images = images.to(device)outputs = model(images)_, predicted = torch.max(outputs, 1)for i, img_name in enumerate(img_names):# 提取图片ID(去除扩展名)img_id = os.path.splitext(img_name)[0]# 去除可能的前导零以外的前缀if img_id.isdigit():img_id = str(int(img_id)) # 去除前导零predictions[img_id] = predicted[i].item()return predictions# 生成提交结果
def generate_submission(predictions):cleaned_ids = []for img_id, prediction in predictions.items():if prediction == 0: # 0表示干净的cleaned_ids.append(img_id)# 排序确保结果一致cleaned_ids.sort(key=lambda x: int(x))cleaned_ids_str = ','.join(cleaned_ids)print(f"预测为cleaned的图片ID: {cleaned_ids_str}")print(f"提交URL: http://202.207.12.156:20000/calculate_accuracy?cleaned_ids={cleaned_ids_str}")return cleaned_ids_str# 主函数
def main():# 设置路径data_root = r"D:\作业\Plate_classification\plates"# 检查CUDAdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')print(f"Using device: {device}")# 获取数据变换train_transform, val_transform = get_transforms()# 创建数据集full_train_dataset = PlateDataset(data_root, transform=train_transform, is_train=True)# 划分训练集和验证集train_size = int(0.8 * len(full_train_dataset))val_size = len(full_train_dataset) - train_sizetrain_dataset, val_dataset = torch.utils.data.random_split(full_train_dataset, [train_size, val_size])# 为验证集设置不同的变换val_dataset.dataset.transform = val_transform# 创建测试集test_dataset = PlateDataset(data_root, transform=val_transform, is_train=False)# 创建数据加载器train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True, num_workers=4)val_loader = DataLoader(val_dataset, batch_size=16, shuffle=False, num_workers=4)test_loader = DataLoader(test_dataset, batch_size=16, shuffle=False, num_workers=4)print(f"训练集大小: {len(train_dataset)}")print(f"验证集大小: {len(val_dataset)}")print(f"测试集大小: {len(test_dataset)}")# 创建模型model = PlateClassifier(num_classes=2, model_name='resnet50')# 训练模型model, train_losses, train_accs, val_losses, val_accs = train_model(model, train_loader, val_loader, num_epochs=50, device=device)# 绘制训练曲线plot_training_curves(train_losses, train_accs, val_losses, val_accs)# 保存模型torch.save(model.state_dict(), 'best_plate_classifier.pth')print("模型已保存为 'best_plate_classifier.pth'")# 预测测试集predictions = predict_test_set(model, test_loader, device)# 生成提交结果submission_string = generate_submission(predictions)# 保存预测结果到文件with open('predictions.txt', 'w') as f:f.write(f"cleaned_ids={submission_string}\n")f.write(f"提交URL: http://202.207.12.156:20000/calculate_accuracy?cleaned_ids={submission_string}\n")print("预测结果已保存到 'predictions.txt'")if __name__ == "__main__":main()