【机器学习深度学习】多模态学习
目录
前言
一、什么是多模态学习?
二、从语义感知角度理解多模态
三、从数据层面理解多模态
四、多模态学习的关键挑战
五、多模态学习的商业落地
六、核心学习范式: alignment(对齐)
七、学习过程分解(以“图文模型”为例)
八、多模态学习的训练基础:多源数据的“感官输入”
九、训练过程的三大阶段:编码、对齐与融合
9.1 模态独立编码(Unimodal Encoding)
9.2 模态对齐与融合(Alignment & Fusion)
9.3 微调与优化(Fine-Tuning)
十、实际例子:模型“学”会的过程
总结

前言
在人工智能的快速发展中,“多模态学习”成为了最热门的研究方向之一。与传统单一模态算法不同,多模态学习强调从多种信息来源中进行联合建模和学习,让机器能够像人类一样,通过 视觉、听觉、语言 等多种通道来理解和感知世界。
一、什么是多模态学习?
多模态学习并不是某一个固定的算法,而是 一类方法的集合。其核心思想是:
输入端:来自不同模态的信息(如图像、语音、文本)。
表示层:对不同模态进行建模,提取特征。
融合层:将这些信息进行组合(如加权、对齐、交互建模)。
输出端:基于融合后的表征完成预测或生成任务。
换句话说,多模态学习就是 对多源异构数据进行联合理解和推理。
二、从语义感知角度理解多模态
人类的感知是天然的多模态:
-
视觉:看到别人的表情。
-
听觉:听到对方的语调。
-
语言:理解对方所说的话。
-
触觉/嗅觉:辅助我们更完整地认知环境。
在机器学习中,多模态学习试图模拟这一过程。比如,情感分析任务中:
-
图像模态捕捉面部表情;
-
音频模态分析语音声调;
-
文本模态理解语义内容;
三者结合才能更准确地识别人类的情绪。
三、从数据层面理解多模态
在数据科学层面,多模态数据远不止图像和文本,它可以包括:
媒体数据:图片、视频、音频、文本。
数值数据:传感器读数、金融指标。
符号数据:知识图谱、逻辑符号。
复杂结构数据:时间序列、集合、树、图等。
这些不同来源的数据,组合后构成了 复合型输入,对其进行高效建模,就是多模态学习的关键。
四、多模态学习的关键挑战
1.模态对齐(Alignment)
不同模态在时间和空间上的差异如何对应?
例如:一句话的语音波形如何对齐对应的文字?
2.模态融合(Fusion)
不同模态信息如何组合?
是早期融合(输入层面)、中期融合(表示层面)还是后期融合(决策层面)?
3.模态缺失(Missing Modality)
当某一模态缺失时,如何保证模型依旧稳定?
4.模态噪声(Noisy Modality)
当某模态数据质量差时,如何抑制其对整体结果的负面影响?
五、多模态学习的商业落地
多模态学习正在渗透进多个领域:
-
智能客服与搜索:用户可通过语音提问,结合图像识别和知识库检索得到更精准答案。
-
智慧医疗:医生可以综合医学影像(CT、MRI)、病理报告(文本)、生理信号(时间序列)进行辅助诊断。
-
自动驾驶:车辆需要融合摄像头视觉、激光雷达点云、GPS 数据来感知环境。
-
情感计算:通过语音语调、面部表情、对话文本来判断用户情绪,提升人机交互体验。
-
内容生成:AI 可以根据文字描述生成图片或视频,也能为图片自动生成文字说明。
六、核心学习范式: alignment(对齐)
多模态学习最关键的秘诀就是寻找不同模态数据之间的对应关系(Alignment),并让模型学会这种关系。
文本:“一只可爱的柯基犬在草地上奔跑。”
图像:一张对应的柯基犬奔跑的图片。
对于人类来说,我们一眼就能看出这段文字描述的就是这张图片。但对机器来说,文字只是一串数字编码,图像只是一个巨大的像素矩阵,它们之间毫无关联。多模态学习的核心任务,就是在海量的(图像,文本)配对数据中,让模型自己发现并建立“柯基”这个词与图像中那个毛茸茸的生物、“奔跑”这个词与四条腿伸展的姿态、“草地”与绿色像素块之间的内在联系。
七、学习过程分解(以“图文模型”为例)
整个学习过程可以大致分为三个核心阶段,如下图所示:
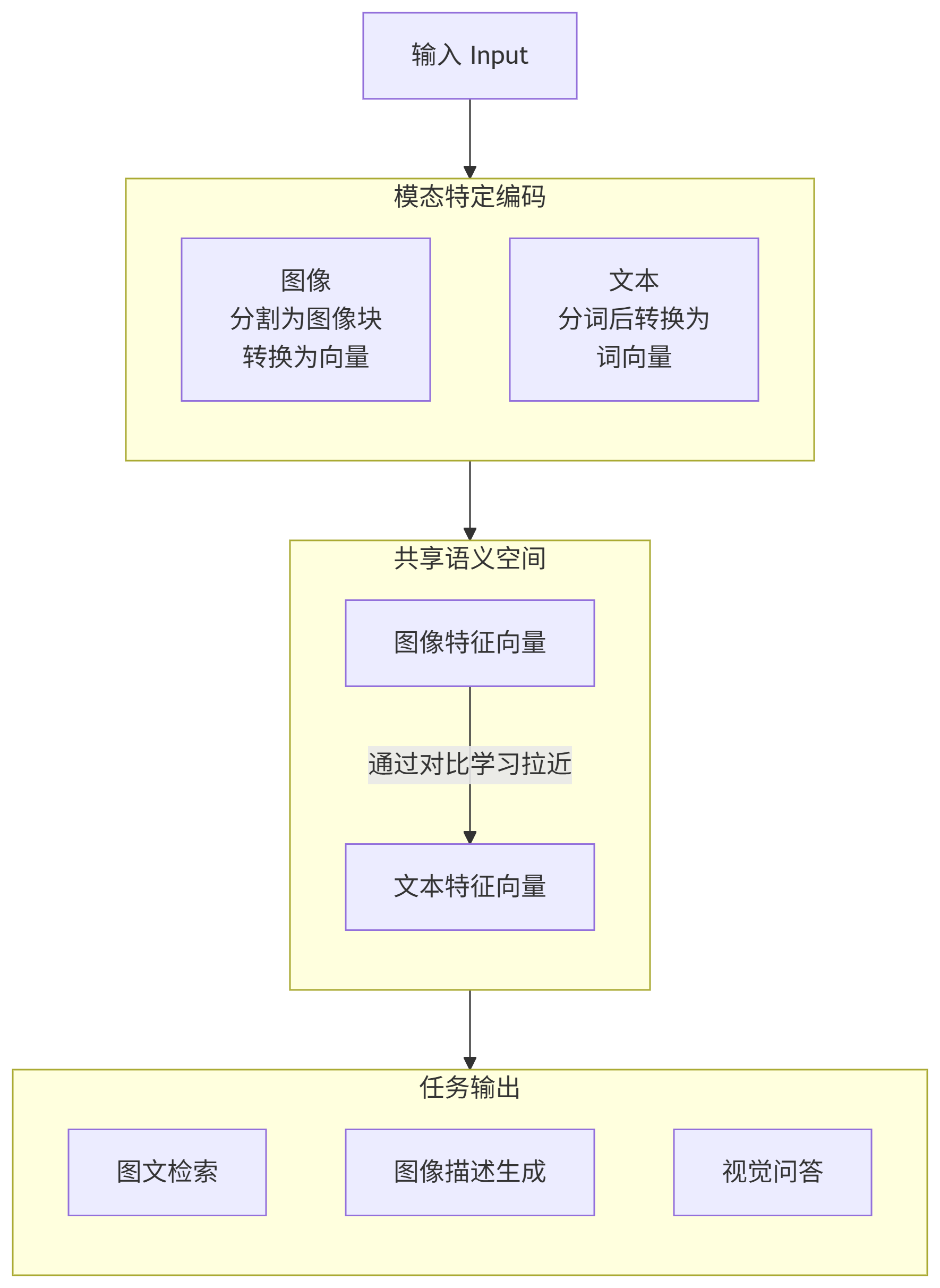
八、多模态学习的训练基础:多源数据的“感官输入”
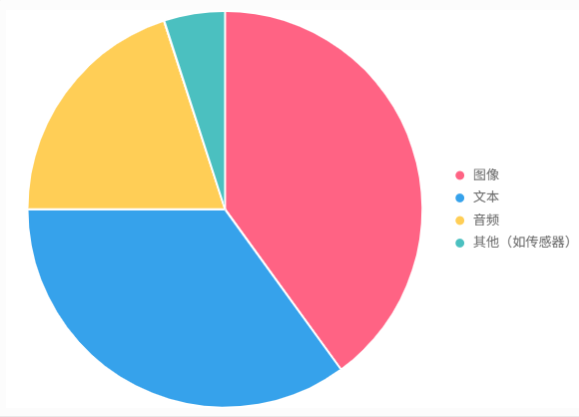
多模态学习基于Transformer架构,扩展到图像、音频等模态,核心依赖多源异构数据。例如,图像+文本对(如照片配描述)、视频+音频(如演讲配字幕)。这些数据模拟人类感官,捕捉互补信息。
- 数据规模:如ImageBind用18万亿token的多模态数据集(图像、音频、文本)。
- 对齐需求:需确保模态匹配(如图像与描述语义一致),开源数据集如LAION-5B简化此过程。
多模态数据来源占比示例图:
九、训练过程的三大阶段:编码、对齐与融合
训练分预训练、融合和微调,使用GPU集群运行数周。以下是核心步骤:
9.1 模态独立编码(Unimodal Encoding)
每个模态转为向量表示,如人类感官信号送入大脑。
- 视觉:Vision Transformer (ViT) 分割图像为补丁,e.g., GPT-4V处理照片。
- 听觉:音频转为谱图,用Wav2Vec编码。
- 文本:BERT转为词嵌入。
- 其他:如ImageBind处理深度图。
编码阶段模态处理复杂度示例图:
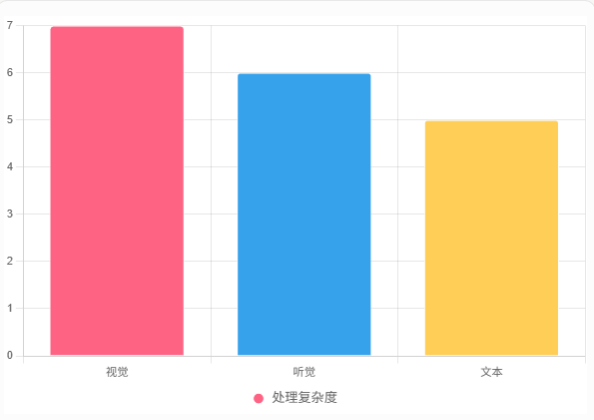
解释:视觉因图像分割复杂性最高,文本最简单。
9.2 模态对齐与融合(Alignment & Fusion)
模型学习模态关联,实现协同。
- 对比学习:CLIP用InfoNCE拉近匹配模态(如狗图+“狗”文本)。
- 跨注意力:Flamingo注入视觉到语言模型。
- 融合策略:
- 早期融合:输入层合并(如UmURL)。
- 晚期融合:独立后合并(如LANISTR)。
- 混合融合:PaLM-E中间层融合。
- 创新:Uni-Code用双向监督对齐模态。
9.3 微调与优化(Fine-Tuning)
- 微调连接层(如LLaVA)或用RLHF优化(如GPT-4o)。
- 处理缺失模态用不变表示,数据增强减少偏置。
训练进度示例图
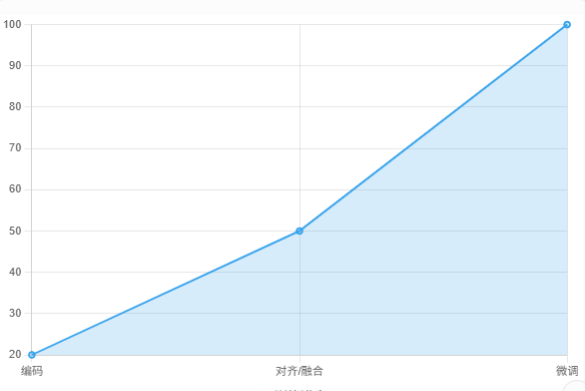
解释:训练从编码开始,融合为关键,微调完成优化。
十、实际例子:模型“学”会的过程
- CLIP:4亿图像-文本对对比学习,零样本分类。
- Flamingo:视觉注入语言,学对话。
- GPT-4o:统一架构,多模态生成。
总结
多模态学习的本质,是让机器“多感官化”。
它不仅仅是单模态能力的简单叠加,更重要的是在多源信息之间建立联系,实现 1+1>2 的智能提升。随着多模态大模型的发展,未来的 AI 将不仅仅能“看懂文字”,而是能 看、听、说、理解、推理 —— 更加接近人类的智慧。